面向C++学科文本的三元组抽取系统仿真
2023-07-03杨泽森田秀霞赵红成
杨泽森,田秀霞,赵红成
(上海电力大学计算机科学与技术学院,上海 200090)
1 引言
从电子教材中抽取知识点及它们之间的关系(三元组数据)是构建学科领域知识图谱的核心步骤之一[1,2],可为在线教学、自适应学习等场景提供可靠支持与应用[3]。然而,由于中文教材文本语义复杂,抽取难度较大,国内面向学科知识的智能抽取系统研究成果较少,因此,如何利用信息抽取技术实现知识信息的自动抽取成为互联网时代教育产业研究中亟待解决的问题[4,5]。
针对不同科目的知识文本,研究者提出了几种基于机器学习的分类方法。侯霞[6]等人尝试利用多校联合人工标注的方法建立C++知识点的前驱和后继关系,但需要消耗大量人力和时间;韩萌[7]等人提出了一种基于特征增强的三元组抽取方法来获取学科中知识点之间的关系;吴呈等人[8]根据中文表达的特点,在预处理步骤引入文本化简理念,解决因语句过长导致的抽取效果降低的问题。然而,上述模型无法捕获重叠分布的知识间的深层逻辑。
经调研分析发现,C++学科具有专业性强,知识分布嵌套重叠的特点,如图1所示的三种重叠类型,现有模型无法处理SEO与EPO重叠类型的语句,而且该学科无高置信度的数据集供模型训练。
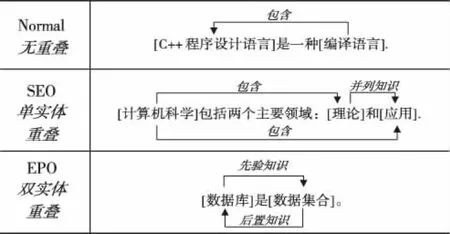
图1 三元组在文本中的重叠类型
针对上述挑战,本文以C++学科为例,设计基于远程监督方法的数据集构建流程,将简单数据增强(EDA)算法对数量少的关系样本进行数据扩展,得到较高置信度的数据集,并针对知识点重叠问题提出了一种基于实体映射的三元组抽取系统EPM(Entity Pair Mapping)。该模型分为两个子任务,首先借助改进的指针网络标注框架对句中知识点进行标记,再结合双通道注意力机制为每对实体分配一个或多个关系类型。
2 基于实体映射的三元组抽取系统
2.1 数据集构建
从百度百科、维基百科及书籍类网站爬取21016句词条文本以及38本C++学科经典电子教材,经过分句分词以及远程监督的对齐匹配初步获得了大量样本。电子教材文本偏重于对基本概念和专业词汇的纵向描述,实体多为“指针”、“strcat()函数”和“double数据类型”等名词,知识层次明显;通过百科词条获取到的文本偏重于对知识点的横向扩展,实体多为“环境变量”、“数据库”和“Dev-C++”等边沿知识。由于C++学科的实体关系标注任务涉及到对整个C++知识体系的掌控,与数位C++学科教师进行了深入交流,考虑知识的广度与深度,设计了如表1与表2所示17种实体类型及7种关系类型。并完成对上述标注样本的人工标记。

表1 实体类型设计

表2 关系类型设计
2.2 数据预处理
2.2.1 词库设计
整合百度输入法与搜狗输入法官网提供的C++领域专业词集,在Gowild科技开源的8000万条百科三元组中进行遍历查询,扩充知识词汇。考虑到C++体系中包含的大量函数名词难以在百科知识中查询得到,本文在C++函数官方介绍文档设计了基于规则的爬取方法,获得2546个C++函数实体。整合后得到包含5372个词汇的C++专业词库。
2.2.2 实体归一化
从不同来源获取到的数据对同一实体的描述可能有不同的名称,例如“C++”与“C++程序设计语言”含义几乎一致,知识的统一表述对于模型理解文本含义具有重要意义。针对C++电子教材,首先借助Jieba工具完成语句分词,再根据式1完成所有信息含量的计算

(1)
sumnodes表示层次结构的总节点个数,hypo(C)表示概念C的所有下位词数量,deep为层次结构最大深度,deep(C)为概念在所有结点层次的深度。
以两个概念的信息含量为自变量,计算概念间的语义距离:
Dis(C1,C2)=IC(C1)+IC(C2)-2IC(LCA(C1,C2))
(2)
LCA(C1,C2)表示两个概念的最近公共父节点,计算距离越小,两个词汇所含信息越相近,以C++专业词库中的词为基准,合并同义词的词向量,使数据样本的表述规范化。最终完成了对423个同义词的归一化。
2.2.3 数据增强
数据集关系类型发现,class6与class7类型所对应的语料极少,模型对于此类关系的学习能力差。为了扩展样本,首次将Wei等人[9]提出的数据增强(EDA)技术应用于C++学科。EDA技术在以下四个步骤中完成数据增强:
1)同义词替换(SR):从句中随机选择n个不是停用词的词。用随机选择的同义词之一替换这些单词中的每一个。
2)随机插入(RI):在句子中随机找一个不是停用词的随机词的同义词。将该同义词插入句子中的随机位置。重复n次。
3)随机交换(RS):随机选择句子中的两个单词并交换它们的位置。重复n次。
4)随机删除(RD):以概率p随机删除句子中的每个词。
上述步骤均为基于词汇的增删换改,在具体实现过程中,通过引入C++专业词库,避开对相关实体进行操作。
通过该方法,将 class6 扩展了 3 倍,将 class7 扩展了 2 倍。结果显示,在大多数情况下,EDA增强的句子与原句表达语义不变。
2.3 EPM系统设计
此系统的目的是抽取给定句x中的所有知识三元组,其中可能存在大量重叠或嵌套三元组。图2显示了模型的整体架构,包括编码层,映射层和关系分类层。
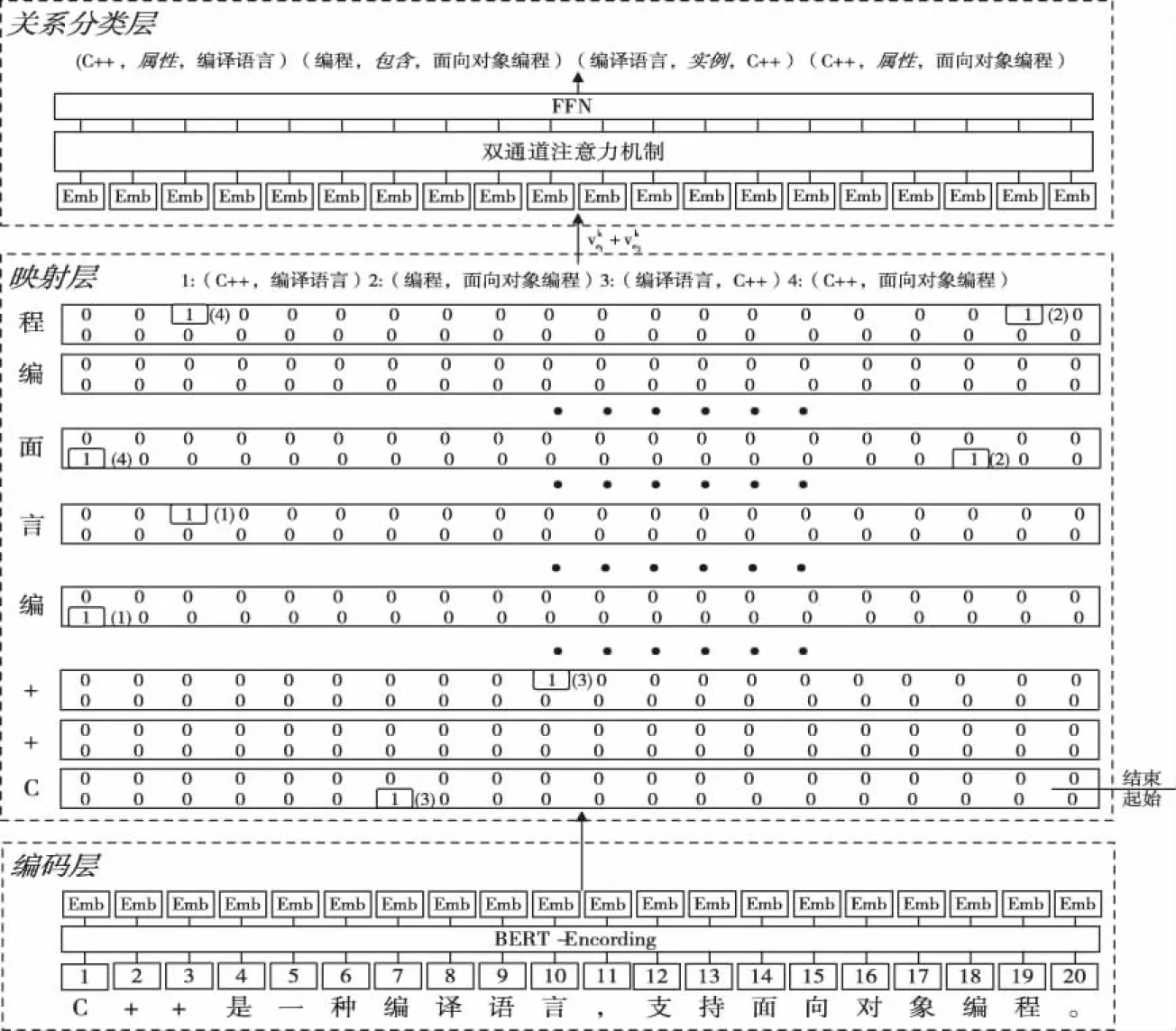
图2 EPM系统架构图
定义目标函数
P((e1,r,e2)|x)=P((e1,e2)|x)P(r|e1,e2,x)

(3)
其中,N为句子长度,X是句x包含的所有字集合。通过该转换可将三元组的抽取拆分为两个子任务:第一个子任务是实体映射。本文认为,句中每个字都有可能是尾实体e2的位置,为了充分利用位置信息,为句中每个字构建一个标记器fe2(x)=e1,分别识别给定句中与当前e2匹配的e1。如果输出为None,意味着当前位置不是e2,或者无相应e1与之匹配。若有输出,则必以实体对的形式输出。第二个子任务是关系分类,模型引入双通道注意机制充分学习语义信息。通过关系分类器f(e1,e2)=r为每对实体分配若干关系类型。
2.3.1 BERT编码层
BERT(Bidirectional Encoder Representation from Transformers)由N个相同的Transformer块堆叠而成[10-12]。将Transformer块表示为Trans(x),其中x代表输入向量。在本模型中,BERT编码层提取句子级特征信息xj。
h0=SWS+WP
(4)
hα=Trans(hα-1),α∈[1,A]
(5)
其中WS是词汇嵌入权重矩阵,Wp是位置嵌入权重矩阵,S是输入语句中词索引的一元向量矩阵,p表示输入序列中的位置索引,hα是隐藏状态向量,即第α层输入句子的上下文表示,A为Transformer块的数量。
2.3.2 映射层
映射层为基于Vinyals等人[13]提出的指针网络(Pointer-Network)标记方案。在该方法中,句子中实体的开始和结束位置被标记为1,其它位置被标记为0。1之间的内容是实体所占据的位置。与序列标注方法相比,减少了指针网络方法的计算量。此外,由于指针网络使用先验信息,因此当输出严重依赖输入时,它可以提高模型的准确性。每个指针标记器的定义如下

(6)

(7)

为了使用尽可能少的标签来表达更多信息,构造了一套映射坐标系来解决上述问题。具体而言,它将实体提取问题视为确定二维坐标点位置的问题。如图2中的映射层所示,水平轴表示句x的编码,用于预测头实体的开始和结束位置;纵轴表示尾实体在x中的位置映射,为每个字分别构建一个开始位置标记器和结束位置标记器。例如,在1号实体对的预测过程中,将起始位置坐标系中的(1,4)位置标记为1,即将句子中的第1个字“C”标记为头实体e1的起始位置,第4个字“编”被标记为尾实体e2的起始位置;同时在结束位置坐标系执行同样的标注过程。最终定位实体“C++”和“编译语言”此方法弥补了以下缺点:传统的序列标记方案只能分配唯一的标签。为了实现实体对的映射的任务,修改等式(6)-(7)如下所示:

(8)

(9)
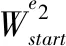
pθ((e1,r,e2)|x)=

(10)

2.3.3 关系分类层
将映射层抽取到的实体对以加和平均的方式嵌入句子编码中,形成关系分类层的输入。

(11)

考虑到C++学科知识点众多,语义复杂,模型难以全面学习到句子表达的信息。为了扩展模型对句中各成份信息的学习能力,引入了双通道注意力机制应用于关系分类步骤。
双通道自注意力机制[14]使用两个通道来学习句子的不同组成部分。模型将在整个训练过程中充分学习编码层句级别语义信息,快速完成对参数空间的搜索,最后,模型输出二维权重矩阵。
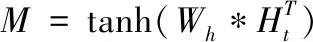
(12)

(13)

(14)

2.3.4 损失函数
采用多个二分类交叉熵损失函数训练模型,并将两个子任务损失相加得到模型的联合损失,通过最小化联合损失以学习模型中的参数。

(15)
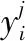
3 仿真研究
3.1 实验设置
在本次实验中的数据采用上文构建的C++知识数据集,以 8:2 的比例划分为训练集和测试集。编码层使用Keras-Bert模型进行微调。主要参数配置如下:CPU:Intel Core i9-9900K,内存:32G,操作系统:windows 10。
3.2 参照模型
本文选取文献[15],文献[16]与文献[17]三个同样基于指针网络框架的方法作为本实验的基准模型。为了规避BERT编码器的引入对模型的贡献,对Bi-LSTM版本的模型也进行了实验。
3.3 结果分析
3.3.1 整体结果
表3展示了本文模型与参照模型的对比实验。EPM的性能在F1分数和精度方面优于其它模型,获得了F1值高于基线模型1.2个百分点的提升。实体映射方法重视实体的位置信息,同时预测首尾实体使实体的依赖关系更加紧密,弥补了传统的指针标记方法过于稀疏的弊端,且避免了匹配实体造成的误差。

表3 EPM在C++知识数据集上的对比实验
为了进一步验证系统各部分的影响,通过改变训练的独立性和注意力机制通道数量,形成不同版本的模型。每个版本模型实验结果如表4所示。

表4 EPM在C++知识数据集上的消融实验
联合训练的方法对该模型起到了显著的增益作用,比独立训练版本提高了3.92个百分点。表明实体识别和关系分类能够通过共享编码层及损失联合优化的方法达到共同学习、相互促进的目的。双通道注意机制在所有通道数的注意力机制中效果最好,验证了适量通道数有助于模型学习到更丰富的知识信息,但过多通道数易使模型学习到冗余信息,对测试造成干扰。
3.3.2 实体关系抽取模型训练结果
在关系类型的预测中,不同关系类型展现出了不同分类效果,如表5所示,在所有7种关系类别中,预测效果最好的关系类别为先验知识(class 2)与后置知识(class 3),其F1值分别为0.873与0.874。其共同特点为上下位逻辑性强,标注样本条目多,验证了本文模型更善于处理上下位逻辑的关系类别。但是,同样属于逻辑关系且训练样本数量充足的包含(class 1)类别与并列知识(class 4)类别抽取性能极为有限,F1值仅为0.587与0.32。通过对错误样本进行分析发现,模型无法准确区分句中“包含”关系与“并列知识”关系,例如表2中class 1与class 4展示的相关例句,其句型均为“A和B是C”句式,且实体类型均属于基础概念,前者突出A与B为C的子集,后者突出AB之间的并列关系,两种关系类型相似的表达方法使得模型无法学习到足够多的特征信息进行有效区分。

表5 实体关系抽取模型训练结果
此外,对于别称(class 5)类别,其句式特点鲜明,如表2中class 5例句所示,常伴随括号出现,因此分类性能较高;实例(class 6)与操作(class 7)为经EDA数据扩充后的结果,其F1分数分别提升了3.77%与2.58%,验证了此数据增强方法对于促进模型的充分学习是十分有效的。
3.3.3 知识重叠对模型性能的影响
如图3所示,在所有三种类型的重叠三元组中,本文模型最擅于处理SEO类别,F1分数实现了5.17个百分点的提升。但处理EPO类的优势不明显,原因是对于两个实体都发生重叠时标注指针也会发生重叠,模型仅依靠设定阈值来为每对实体分配若干关系不足以使模型学习到句子的深层含义。
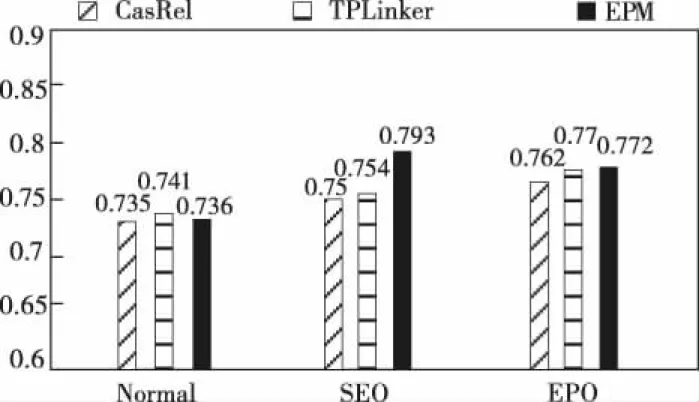
图3 实体重叠抽取对比试验
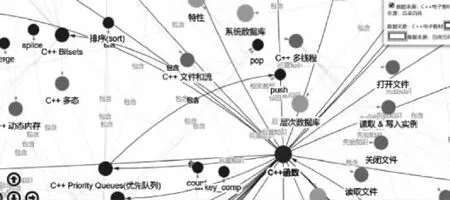
图4 基于InteractiveGraph的数据可视化
3.3.4 基于InteractiveGraph的数据可视化
利用EPM系统对菜鸟教程等教程网站文本展开知识抽取,经过人工修正后,同本文构建的数据集合并构成C++知识网络源数据。借助InteractiveGraph工具实现知识网络的可视化。
4 结束语
本文以C++学科为例详述了一种知识数据集的构建方法,引入EDA理念进行数据增强,并针对数据特点提出一种有效解决实体重叠问题的三元组提取系统EPM,该系统使用实体映射方法来提取实体对,在关系分类组件中嵌入双通道的注意力机制,仿真结果验证了该模型的有效性,对于读者设计其它学科知识图谱有一定参考意义。下一步将开展自适应学习、智能推荐等工作的研究。
