基于Spark的WOA-BP水稻产量预测
2023-07-01陈志浩王建华龙拥兵兰玉彬刘军和熊弘依肖方军肖艺铭
陈志浩 ,王建华,龙拥兵,兰玉彬,刘军和,熊弘依,肖方军,肖艺铭
(华南农业大学 电子工程学院(人工智能学院)/国家精准农业航空施药技术国际联合研究中心/岭南现代农业科学与技术广东省实验室,广东 广州 510642)
水稻作为人类主要粮食之一,受众十分广泛,遍布亚、欧、非洲以及热带美洲,全球约一半的人口以稻米作为主食,因此水稻的产量问题一直备受关注,水稻产量预测也成为当前水稻生产中的一个重要研究方向。当前作物估产方面,主要有气象产量预测法、遥感技术和统计动力学模拟法[1],通常使用多元线性回归、决策树、神经网络等构建模型;水稻产量受多种因素影响,如气候、病虫害、农药化肥使用量等,导致产量数据呈现非线性分布,预测效果整体较差。
现今我国的水稻主要有早、中、晚3 种水稻,水稻的分布位置与气候条件密切相关,光照、温度、风向、水分等因素的变化会影响水稻的生长,进而影响水稻的产量。比如,气温变化会对水稻花器官分化、发育以及水稻同化物合成、累积、转运及分配过程产生影响;水稻在孕穗期和灌浆期对水分变化最为敏感,在这期间水稻缺水会阻碍分蘖穗的形成,并影响谷粒的灌浆充实程度;水稻从孕穗期到出穗期叶面积较大,蒸腾强度达到高峰,蒸发量过大会对水稻生长造成影响;水稻属喜阳短日照作物,光照强度直接影响水稻同化物的形成速率,进而影响产量[2-5]。当前,在气象估产方面,国内外学者已进行了相关的研究,比如,刘洪英等[6]利用四川省南充市1989—2018年气象数据和水稻单产数据,采用线性回归方法建立了基于气象因子的水稻产量预报模型;高俊杰等[7]利用1982—2020年广东省肇庆市高要区气象因子与早稻产量的数据,采用逐步线性回归方法建立了早稻产量预报模型;Chutia 等[8]利用1990—2012年水稻作物产量数据和周天气数据,建立了阿萨姆邦13 个地区的水稻产量预测模型;Kaeomuangmoon等[9]通过研究泰国77 个区域的气候数据变化,利用Rice4cast 平台预测季节性KDML 105 水稻的产量;Traore 等[10]使用决策分析针对萨赫勒地区气候条件进行水稻估产;Jha 等[11]通过作物动态模型根据每日气象数据对尼泊尔水稻产量进行估产;Dhekale 等[12]针对印度克勒格布尔市日降雨量数据,采用CERES-Rice(DSSATv4.5)模型进行水稻产量预测;Nain 等[13]针对印度哈里亚纳邦卡尔纳尔地区的气象及水稻产量数据,使用多元线性回归等不同统计方法对该地区的水稻产量进行预测;Guo等[14]通过气象和水稻产量等农艺性状数据,分别使用反向传播神经网络和偏最小二乘法构建模型,预测华东地区的水稻产量;杨北萍等[15]通过长春市2 个地区的气象、水稻遥感及产量数据,使用随机森林算法对2 个地区的水稻产量进行预估;徐强强等[16]通过浙江省台州市椒江区的气象及水稻产量数据,使用指数平滑法对该地区早稻产量进行预测。其他作物方面,路智渊等[17]通过气象因子结合固原市小麦产量进行回归分析,进行小麦产量预测;马凡[18]基于气象数据及安徽省小麦产量,构建小麦产量预测模型。以上方法不同程度地存在模型精度低、预测区域级别过大、模型优化时间过长等缺陷,如模型的误差超过10%,预测区域的级别为国家或省市,使用群智能算法等优化神经网络时间过长等。为了解决上述问题,本文提出一种基于Spark 的鲸鱼优化算法-反向传播神经网络(Whale optimization algorithm-backpropagation,WOA-BP)水稻产量预测方法。首先,以县/市/区作为研究区域级别,避免研究区域范围过大和数据量太少的问题,可以很好地反映气象因素对县/市/区级别水稻产量的影响,在研究小区域水稻产量时更具有参考意义;此外,BP 神经网络具有优良的非线性映射能力,利用其构建水稻产量模型能够提升模型的预测效果,同时利用WOA 对BP 网络的权值和偏置值进行优化,改善BP 神经网络收敛慢、易局部收敛等缺陷,能够进一步提升模型的效果,避免误差较大等问题;最后,将现有的大数据技术与农业和人工智能进行结合,利用大数据Spark 框架,搭建Spark 集群,将改造后的WOA-BP算法在集群环境下实现并行化运算,减少算法优化过程的时间开销,充分发挥大数据技术的优势,实现对水稻产量与气象数据的快速建模以及县/市/区水稻产量的精准预测。
1 材料与方法
1.1 试验环境
模型的训练在TensorFlow 框架下完成,优化算法在Spark 集群下运行,其中Spark 集群由3 台相同配置的联想台式电脑组成,硬件环境:联想3148 主板、AMD Ryzen5 3 600 6-Core 双线程CPU、16 GB DDR4 3 000 MHz 内存、TP-LINK 路由器,软件环境:Ubuntu16.04 系统、TensorFlow2.8、Spark3.2.0、Python3.7,编程语言为Python;通过路由器将3 台电脑构成局域网,按照1 主节点2 子节点搭建Spark 集群环境,Spark 集群模式为Standalone 模式。
1.2 数据来源与处理
本文以广东省西部地区4 座城市(湛江、茂名、阳江、云浮)23 个区县2000—2020年水稻的单产(每667 m2)数据及该地区的气象因素作为研究对象,其中,该区域的水稻单产数据共计482 条,数据来源于广东省统计局历年的《广东农村统计年鉴》;气象因素选取2000—2020年每年3—10月的每月气温(最高、最低、平均),土温(最高、最低、平均),露点温度(最高、最低、平均),积温,降水量,蒸发量和太阳辐射量,来源于欧洲中期天气预报中心(ECMWF)的气象数据。为了降低后期BP 神经网络模型结构的复杂程度,通过主成分分析 (Principal component analysis,PCA) 对影响因素进行降维,降维后累积方差贡献度保持在0.95 以上;此外为了加快BP 神经网络的收敛,需对数据进行归一化处理,归一化公式如下:
式中,X为当前元素,X'为X归一化后的值,MIN、MAX 分别为X整体数据集中所有元素的最小值和最大值,Xmin与Xmax为当前所在列的最小值与最大值。
1.3 BP 神经网络和WOA 算法
BP 神经网络是1986年由Rumelhart 等[19]提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络之一。BP 神经网络学习过程分为输入信息正向传播和误差反向传播2 个阶段[20]。
WOA 算法是由澳大利亚学者Mirjalili 等[21]于2016年提出的新型群智能寻优算法,该算法主要分为座头鲸识别并包围猎物、螺旋泡网攻击、鲸鱼根据同类位置随机搜索捕食3 个阶段;WOA 算法已经被运用到复杂函数优化、路径规划、图像分割和光伏模型等领域,并取得显著效果[22]。
1.4 基于Spark 的WOA-BP 算法并行化
Spark 是一个基于内存运算的大数据计算框架,在时间性能上优于MapReduce,Spark 为了能够实现高并发和高吞吐率的数据处理过程,封装了弹性分布式数据集(Resilient distributed datasets,RDD)、累加器、广播变量3 大数据结构,应对不同场景下数据处理,其中,RDD 是Spark 中最基本的数据单元,同时也是1 个不可变、可分区且支持并行计算的数据集合。RDD 用于支持Spark 框架的并行计算,而累加器以及广播变量则用于数据同步,其中累加器是1 个只写变量,变量一旦被修改,该变量在所有节点的值将同步更新;广播变量是1 个只读变量,当变量被广播后,成为该节点的局部变量,节点修改该变量不会影响其他节点[23-24]。
由于WOA 算法优化BP 神经网络时,存在大量迭代计算,除鲸鱼自身的信息不一样外,每头鲸鱼在寻找自身最优解以及更新自身位置信息的过程中,所有更新逻辑均相同,因此,结合Spark 并行计算框架,实现基于Spark 的WOA-BP 算法并行化,减少算法的时间开销。图1为基于Spark 的WOA-BP 算法的并行化流程图,算法的具体步骤如下。
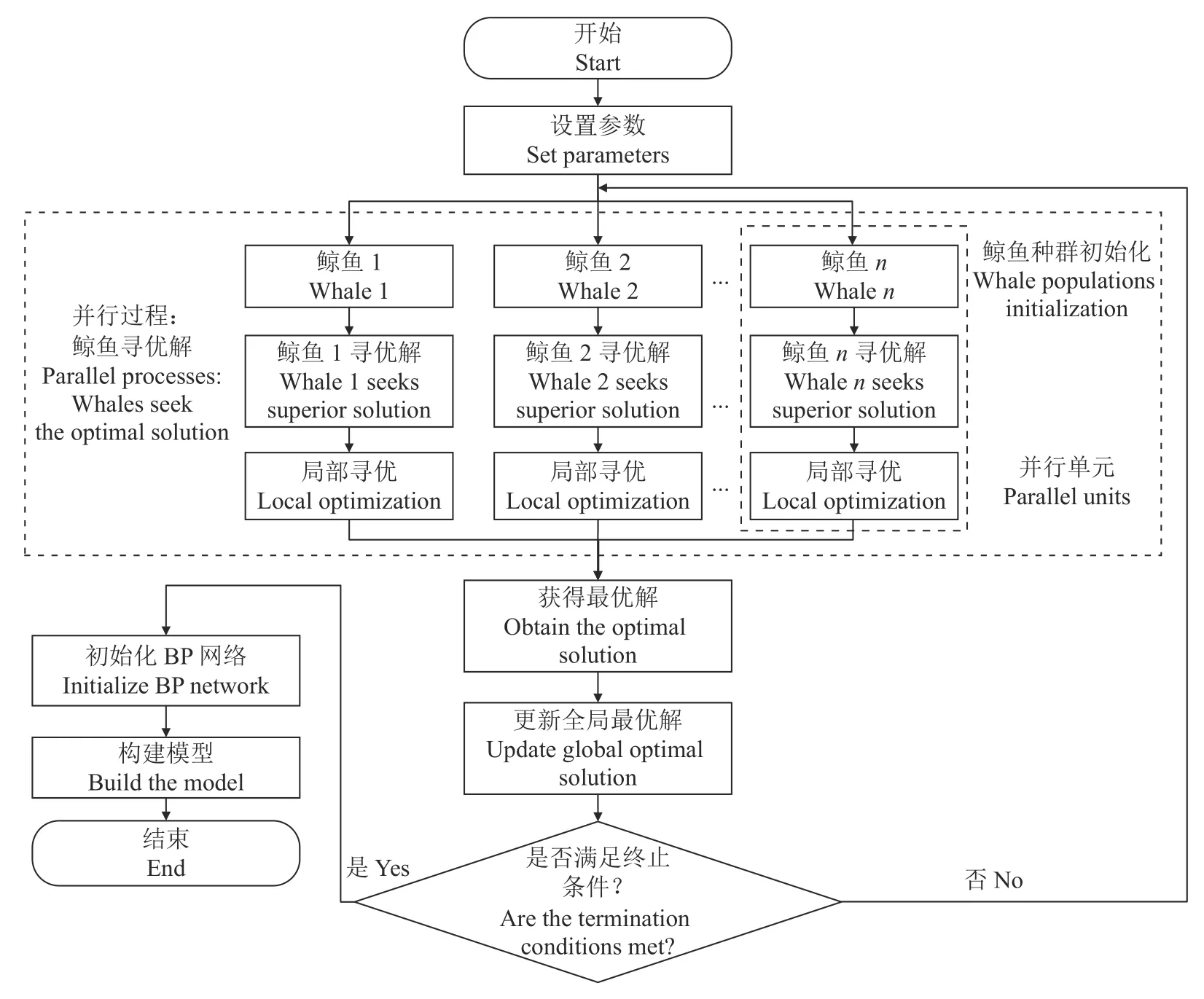
图1 WOA-BP 算法的并行化流程Fig.1 The parallelization process of the WOA-BP algorithm
1)设置相关参数:设置种群规模,如鲸鱼数量n,参数维度d等,同时设置Spark 广播变量。
2) 初始化种群:创建含d个元素的一维零数组,通过该数组构建RDD,之后通过map 算子进行种群的初始化,实现并行化初始化操作,减少时间开销。
3)更新鲸鱼位置和适应度:更新每头鲸鱼的位置信息,并进行越界检查,之后计算该鲸鱼的适应度(Fitness),以样本的均方根误差(Root mean square error,RMSE)作为适应度,计算公式如下:
式中,n为样本数,m为网络输出层输出个数,yij为样本的实际值,y'ij为网络的实际输出值。
4)更新全局最优解和最小适应度:通过sortBy算子获取最小适应度以及该适应度对应的鲸鱼位置信息,更新全局最优解。
5)终止条件判断:若不满足终止条件,则程序继续执行,否则,通过collect 算子收集各个分区的数据,完成算法的优化阶段,得到全局最优解。
6)构建BP 神经网络:利用全局最优解对网络的权值和偏置值进行初始化,构建模型。
2 结果与分析
2.1 基于WOA-BP 水稻产量预测
本文以广东省西部地区2000—2020年县/市/区水稻单产及气象数据为基础,按照3∶1∶1 进行数据集划分:2000—2012年数据作为训练集,2013—2020年数据作为验证集(50%) 和测试集(50%),通过BP 神经网络建模,分别使用粒子群优化算法 (Particle swarm optimization,PSO) 和WOA 对BP 神经网络进行优化,得到BP、PSOBP、WOA-BP 3 种产量预测模型,之后对模型的预测结果进行反归一化。图2是3 种模型预测值与真实值的绝对误差对比,由图2可以清晰看出,WOA-BP模型的曲线整体上更加贴近横坐标,即测试集样本的整体绝对误差小于另外2 种模型的。表1为3 种模型的预测精度对比,可以明显看出,与传统BP 模型相比,经WOA 优化后的产量预测模型的平均绝对百分比误差(Mean absolute percentage error,MAPE) 减少了1.286 个百分点,平均绝对误差(Mean absolute error,MAE) 减少了4.338 kg,RMSE 减少了7.462 kg。虽然PSO-BP 模型相较传统BP 模型在精度上有一定提升,但效果明显不如WOA-BP。此外,试验过程中发现,相同种群规模下,WOA 与PSO 2 种算法的优化时间相差较大,其中WOA 为26 637 s,PSO 为48 518 s,WOA 比PSO 少了约45%的时间开销,显然WOA 的时间性能更优。因此,WOA 在算法优化的时间开销以及模型效果上均优于PSO,故本文采用WOA-BP 对广东省西部地区县/市/区的水稻产量进行最终建模。
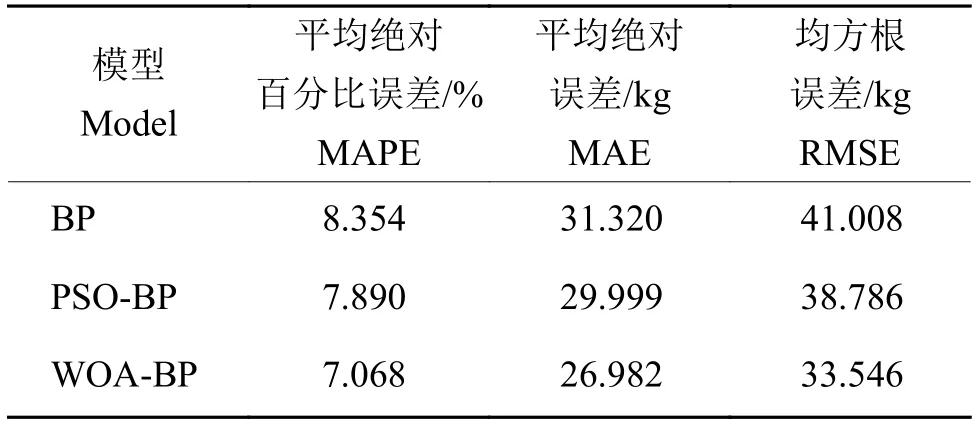
表1 3 种模型精度对比Table 1 Precision comparison of the three models
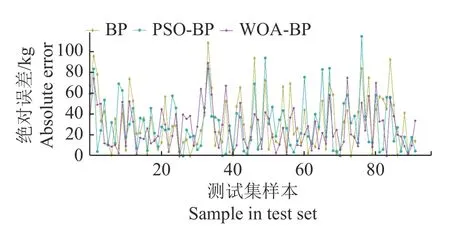
图2 3 种模型的绝对误差Fig.2 Absolute error of the three models
2.2 基于Spark 的WOA-BP 算法时间性能
由表1和图2的结果可知,经WOA-BP 算法得到的预测模型效果最佳,但算法的优化时间仍旧较长,故在此基础之上,结合Spark 并行计算框架,减少优化过程的时间开销。因此,使用3 台台式主机按照1 主节点2 子节点的形式搭建Spark 集群,同时改造WOA-BP 算法实现并行化,并按照2 倍物理核数的规则对RDD 进行分区,提升集群整体的并行度,充分利用CPU 性能。表2为不同节点性能对比及配置信息,图3为不同节点算法运行时间对比,由表2和图3可以清晰看出,随着节点数量的增加,算法的优化时间随之减少,其中3 节点比2 节点和1 节点分别减少了21.4%和39.3%的时间开销,大幅度缩短算法的优化时间。同时与“2.1”中非Spark 的WOA 的优化时间相比,减少了44%的时间开销,充分体现算法与Spark 框架结合后的优势,真正实现对水稻产量与气象数据的快速建模。

表2 不同节点数量性能对比及配置信息Table 2 Performance comparison and configuration information under different node number
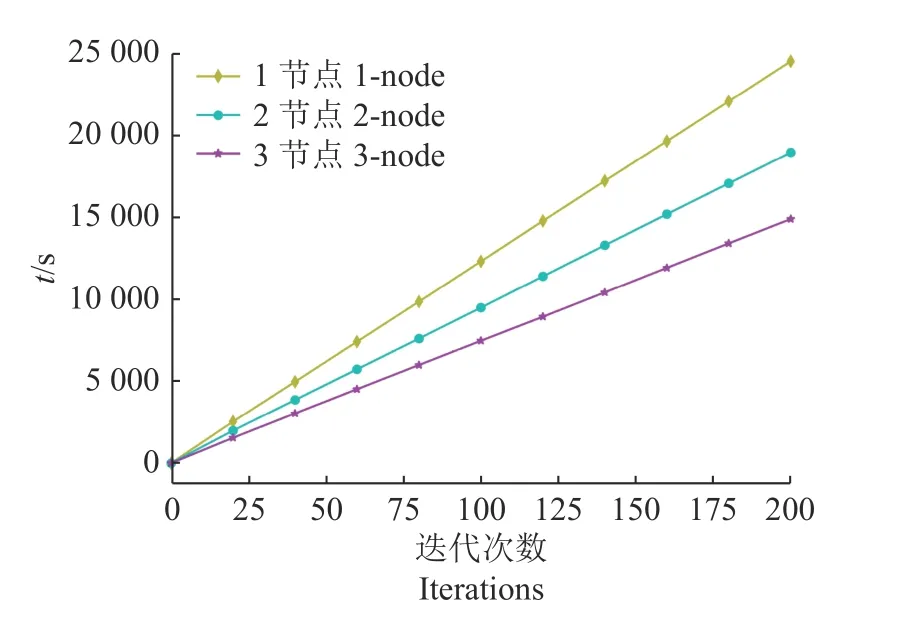
图3 不同节点数时间开销对比Fig.3 Time overhead comparison under different node number
3 结论
本文以广东省西部地区所有县/市/区作为研究区域,针对气象因素对水稻单产的影响,提出一种基于Spark 框架的WOA-BP 水稻县/市/区级别的单产预测方法。首先通过WOA 对BP 神经网络进行优化,避免BP 神经网络收敛慢、易局部收敛等缺陷,提升BP 模型的整体预测精度;其次,结合Spark 并行计算框架,实现WOA-BP 算法并行化,加快WOA-BP 算法的运算速度,减少算法的时间开销;最后通过WOA-BP 算法得到的最优解对网络进行初始化并构建网络模型,之后进行水稻单产的预测。测试集的预测结果表明,该模型的预测精度较高,预测结果较精确,论证了该方法的可行性及有效性;同时,该模型可以很好地反映气象因素对广东省西部地区县/市/区水稻单产的影响情况,对研究广东西部县/市/区乃至整个广东的水稻单产具有一定的借鉴意义。
