基于改进YOLOX-Nano的农作物叶片病害检测与识别方法
2023-07-01李康顺杨振盛江梓锋王健聪
李康顺,杨振盛,江梓锋,王健聪,王 慧
(1 华南农业大学 数学与信息学院,广东 广州 510642;2 东莞城市学院 人工智能学院,广东 东莞 523419;3 深圳信息职业技术学院,广东 深圳 518172)
中国是一个农业大国,作为国家发展的根本,农业在国家经济总量中占有很大的比重。如今全球粮食供给偏紧,农业是国家战略性、基础性核心产业,在农作物的生长发育过程中,气候环境、病虫迫害、病菌侵染等严重影响其产量和品质。目前常见的农作物病害有上千种,传统的依靠人工识别农作物病害,不但耗费时间精力,而且效率低。精确迅速地辨识出农作物病害有助于及时救助,对降低农作物病害带来的产量和品质影响具有重大意义。
随着深度学习技术在物体分类方面的深入研究与计算机图像处理能力的增强,计算机视觉技术也应用在农作物病害识别上,并且取得许多成果。刘翱宇等[1]提出一种基于深度残差网络的植物病害检测网络,引入Focal Loss 损失函数,对植物病害图像的检测平均准确率高达97.96%。Srdjan 等[2]将深度卷积神经网络用于植物病害识别,能够区分植物叶片与周围环境,并能够区分健康叶片与13 种不同的植物病害,在开发模型测试中,单类病害的识别平均准确率高达96.3%。Albattah 等[3]提出了一种改进的CenterNet 网络,以DenseNet-77 为基础网络对病害样本图片特征进行提取,在Plant Village 数据集上训练,然后分别对番茄、葡萄等在内的14 种植物26 类病害及健康叶片进行识别,检测精度比当时精确率最高的EfficientNet 网络更高。刘洋等[4]针对PlantVillage 数据集14 种植物中的26 种病害对比研究了2 个轻量级网络系统MobileNet 和Inceptionv3,结果表明MobileNet 模型的程序数量更小,执行速率也更快,可部署于安卓操作系统中,在手机端也实现了图像识别。Saleem等[5]对Xception 网络精修后,选择性能提升最明显的Adam 优化器,对PlantVillage 数据集中的26 种植物病害进行检测,准确率达到了97.81%。孙俊等[6]使用AlexNet 作为基础网络,然后通过批归一化方法、引入全局池化层和减少特征图量等方式,共获得了8 种改进模式,对PlantVillage 数据集14 种植物的26 种病害特征进行了鉴别,效果最好的检测模式平均准确度超过了98.1%。李书琴等[7]提出了一种基于轻量级残差网络,通过缩减网络卷积核数目和轻量级残差模块减少网络参数,网络参数大幅减少的同时,在PlantVillage 数据集上的检测精度达到98.45%。
上述深度学习方法不仅在检测准确度方面有了较高的提升,也有向低内存、少参数量改进的趋势,从而达到高精度识别、迅速检测、易部署移动端的目的。然而,检测精度提升的同时,网络参数量也在不断增多,网络深度和宽度也不断加深,浮点运算量加大从而带来较高的延迟,实时检测的效果较差。人工智能公司旷视科技提出的YOLOXNano[8],有着参数量小、浮点运算快、延迟低、易部署移动端的优势且检测精度保持着中高水平。本文在原始YOLOX-Nano 网络结构的基础上进行改进,在不显著增加网络内存和运算参数量的基础上,提出一种混合卷积注意力模块CBAM[9]、Mixup数据增强策略[10]、Focal Loss 分类损失函数[11]和本文设计的基于CenterIOU 回归损失函数的改进YOLOX-Nano 模型。
1 材料与方法
1.1 数据集的获取
试验所需要的所有病害图片数据来自于公开数据集PlantVillage 网站(http://plantvillage.psu.edu),数据集记录包含54 309 张图像,这些图像涵盖了14 种作物:苹果、蓝莓、樱桃、玉米、葡萄、柑橘、桃、甜椒、马铃薯、覆盆子、大豆、南瓜、草莓和番茄。考虑到应尽可能研究某一类农作物的多种病害(3 种及以上),因此剔除数据集内仅含健康叶片的农作物数据和仅有2 类病害的农作物数据,最终在公开数据集上精心挑选苹果叶片图像4 645 张,其中,苹果黑星病1 000 张、苹果黑腐病1 000 张、苹果松锈病1 000 张、健康叶片1 645 张;玉米叶片4 354 张,其中,玉米灰斑病1 000 张、玉米锈病1 192张、玉米大斑病1 000 张、健康叶片1 162 张;葡萄叶片4 369 张,其中,葡萄黑腐病1 180 张、葡萄轮斑病1 076 张、葡萄褐斑病1 383 张、健康叶片1 000张;马铃薯叶片3 000张,其中,马铃薯早疫病、马铃薯晚疫病、健康叶片各1 000 张;草莓叶片4 218张,其中,草莓叶焦病2 218 张,健康叶片为2 000张;番茄叶片18 835 张,其中,番茄疮痂病1 404张、番茄早疫病1 000 张、番茄晚疫病1 909 张、番茄叶霉病1 000 张、番茄斑枯病1 771 张、番茄红蜘蛛损伤1 676 张、番茄斑点病2 127 张、番茄黄叶曲叶病5 357 张、番茄花叶病毒病1 000 张和健康叶片1 591 张,共计6 类农作物27 种病害,保证各类样本间数量均衡。此外,考虑到真实场景背景复杂的情况,数据集添加了无叶片背景图像1 143 张。试验样本图像如图1所示。

图1 PlantVillage 部分数据集Fig.1 Partial dataset of PlantVillage
1.2 数据预处理网络训练参数设置
首先将所有样本图像的分辨率转变成416×416,使用标注工具LabelImg 将所有样本按Pascal VOC 数据集的标注,生成.xml 类型的标注文件。此外,从试验数据集图像中随机选择60%样本(约23 235张)用于训练模型,20%的样本(约7 675 张)用来验证,20%样本(约7 675 张)用于测试。
试验运用迁移学习,让YOLOX-Nano 在大规模公开数据集Image Net 上进行训练,获得一个收敛的预训练权重,然后利用这个预训练权重迁移到改进的YOLOX-Nano 网络模型中进行参数调优。训练过程中超参数设置为每批量样本数为32,1 次遍历完全部训练集数据称为1 次迭代,批量设置为100。采用随机梯度下降(Stochastic gradient descent,SGD)优化算法调优网络参数,初始学习率设置为0.01,动量因子为0.9,每经过10 次迭代训练,将学习率降低1/10,模型迭代1 次保存1 次权重。
1.3 基于改进YOLOX-Nano 的农作物叶片病害检测与识别
1.3.1 YOLOX-Nano 网络 YOLOX-Nano 作为YOLOX 系列的最轻量化版本,对比YOLOX-X、YOLOX-L、YOLOX-M、YOLOX-S、YOLOXDarknet 和YOLOX-Tiny 高性能版本,其通过降低网络的宽度和深度、减少模型运算的参数量、取消训练时Mixup 数据增强方式等改进,使网络结构更简单,速度更快。
YOLOX-Nano 的结构如图2a 所示,整个YOLOX-Nano 可以分为3 个部分,分别是CSPDarkNet 主干提取网络[12]、特征金字塔网络(Feature pyramid network,FPN)[13]和路径聚合网络(Path aggregation network,PAN)[14]中间层以及YoloHead 输出层。
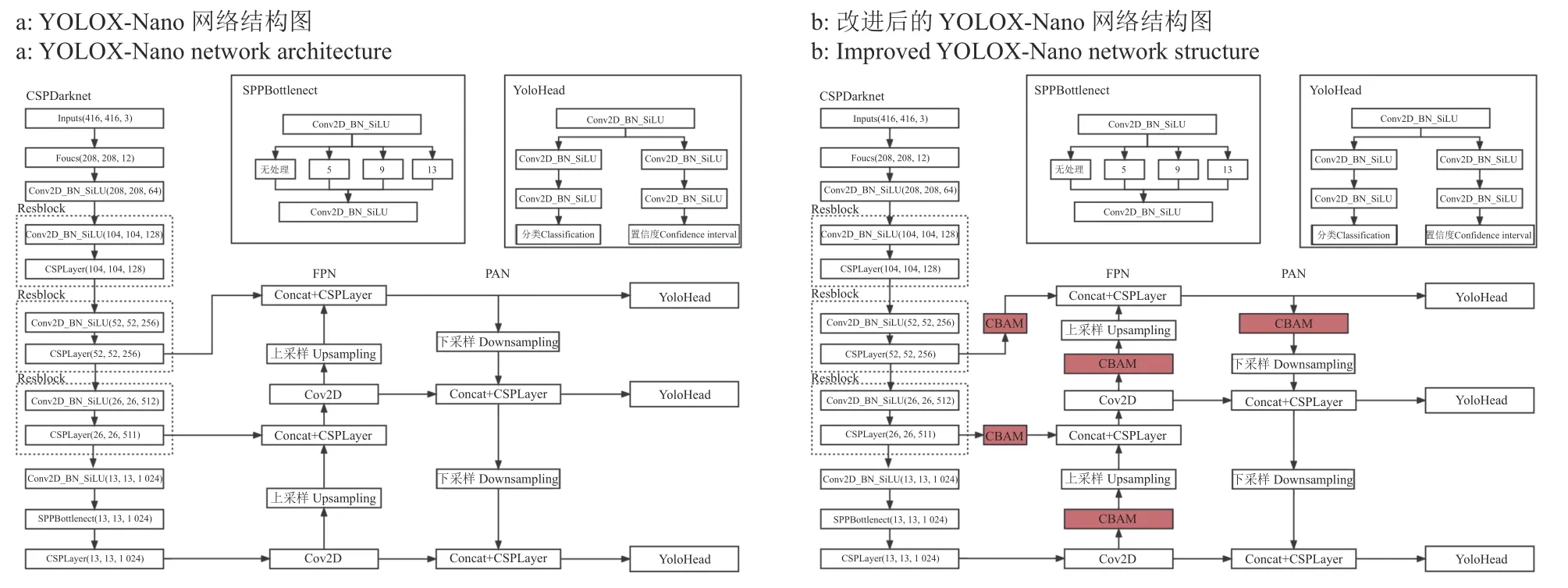
图2 YOLOX-Nano 网络结构和改进后的YOLOX-Nano 网络结构Fig.2 Network structure of YOLOX-Nano and improved YOLOX-Nano
输入的图片首先在CSPDarkNet 进行特征提取,提取到3 个特征层进行下一步网络的构建,FPN 是YOLOX-Nano 的加强特征提取网络,在主干部分获得的3 个特征层会在这一部分进行特征融合,获取不同尺度的特征信息。在FPN 部分,已经获得的有效特征层被用于继续提取特征,在PAN 层中,网络会对特征进行阶段上采样和下采样操作实现特征融合。YoloHead 是YOLOX-Nano 的分类器与回归器,输入图片通过CSPDarkNet、FPN 和PAN 层已经获得了3 个加强特征层,每一个特征图看作每一个特征点的集合,而YoloHead会对特征点进行判断,判断特征点是否有物体与其对应。YOLOX-Tiny 的YoloHead 被分为了2 部分,分别实现检测和分类操作,最后在预测阶段将两者整合输出结果。
由于YOLOX-Nano 宽度和深度较浅,没有充分学习输入特征向量通道与空间之间的重要程度关系,对近似的难分辨目标预测效果较差,其次数据集内多种农作物病害图像样本复杂多样,二分类交叉熵损失(Binary cross entropy loss,BCELoss)作为分类损失函数将困难样本和容易样本赋予相同的权重进行训练,这样造成一些困难样本分类效果不理想,GIOU 损失函数对2 个候选框没有相交时,IOU=0,不能反映两者的距离大小,也无法精确反映两者的重合度大小,不利于梯度回传和学习训练,致使密集病害定位缺失。
综合以上问题,本文在YOLOX-Nano 模型混合了卷积注意力CBAM 模块,引入了Mixup 数据增强方式来充实样本集,让网络训练地更充分,最后分类损失函数将BCELoss 替换为Focal Loss,回归损失函数将GIOU Loss 替换为CenterIOU Loss,改进后的YOLOX-Nano 网络结构图如图2b 所示。
1.3.2 混合卷积注意力机制CBAM 模块 在农作物病害检测与识别任务中,农作物叶片病害特征大体相似,只有细节部分略有差异。YOLOXNano 作为浅层模型,检测精度不够高,这是需要注意的地方。
注意力机制是运用在深度学习模型中常见的小技巧,是实现网络自适应注意的一个方式,核心重点是让网络关注到它需要关注的特征,忽略不重要的特征,主要分为通道注意力机制和空间注意力机制,卷积注意力机制结构如图3所示。卷积注意力机制的前半部分为通道注意力机制,通道注意力机制先针对输入进来的单个特征层,依次执行全局平均池化方法和全局最大池化方法,之后再针对平均池化和最大池化的结果,利用共享的全连接层进行处理,然后再对处理后的2 个结果进行相加,之后再通过Sigmoid 激活函数,得到输入特征层中每一条通道的加权值(0~1)。将这个权值乘上原输入特征层即可得到经过通道注意力机制处理后的特征图。卷积注意力机制的后半部分为空间注意力机制,首先对通过通道注意力机制处理的特征层每一个特征点的通道取最大值和平均值,之后将这2 个结果进行堆叠,利用通道数为1 的卷积核卷积调整通道数,再经过Sigmoid 激活函数,获得输入特征层每一个特征点的权值(0~1),然后将这个权值乘上原输入特征层即可得到最终处理的特征层。
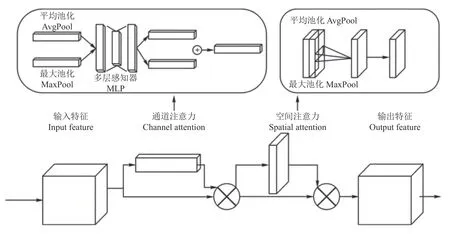
图3 CBAM 卷积注意力机制结构Fig.3 Structure of CBAM convolutional attention mechanism
本文引入CBAM 注意力机制模块,结合通道注意力机制和空间注意力机制,对输入的特征层分别进行通道注意力机制和空间注意力机制的处理,卷积注意力机制对不同通道的特征图进行权重的重新分配,加强网络结构深层信息提取,让网络关注到它需要关注的特征,忽略不重要的特征。
输入图像经过主干特征提取网络后获得3 个有效特征层,在构建FPN 层上采样前首先将经由加强特征提取网络的3 个有效特征层送入CBAM 模块,自动学习特征通道之间的相关性,输出3 个尺度的检测结果,再经过卷积层提取特征。随后进行PAN 的构建,在PAN 融合的下采样前,把主干特征网络获得的3 个有效特征层,再经过CBAM 注意力机制模块进行融合,然后经过另一个卷积模块再一次提取特征,将最后一个有效特征层卷积,最终获得3 个特征。
1.3.3 引入Mixup 数据增强策略 Mixup 是一种混类增强的数据增强策略,它可以将不同类的图像进行混合,从而扩充训练数据集。Mixup 数据增强策略原理是假设batchx1是一个批次的图像样本,batchy1是该批次图像样本对应的标签;batchx2是另一个批次图像样本,batchy2是另一个批次图像样本对应的标签,λ是由参数为α、β的Beta 分布计算出来的混合系数。
由此可以得到Mixup 原理公式为
以玉米病害图像为例,在训练时先读取1 张样本图像,图像两侧填充,放大图片到416×416(图4a),再随机选取1 张样本图像,也放大到416×416(图4b)。然后设置1 个融合系数,如0.5,将2 张图像加权融合,最终得到完整的图像(图4c)。

图4 Mixup 数据增强策略示意图(以玉米灰斑病为例)Fig.4 Schematic diagram of mixup data enhancement strategy(Take corn Cercospora zeaemaydis as an example)
在YOLOX 中以Mosaic 为基础,Mixup 策略作为一种额外的数据增强策略,在浅层模型用Mixup 数据增强策略会降低平均精确率(Average precision,AP),所以YOLOX-Nano 没有使用Mixup 数据增强策略。本文使用Mixup 数据增强策略,加大样本数据量防止模型欠拟合。根据图5中的Beta 分布概率密度曲线,当α=β= 1 时,等于(0,1)均匀分布;当α=β< 1 时,表现为两头的概率大,中间的概率小,当α=β→0 时,相当于{0,1}二项分布,要么取0,要么取1,等于原始数据没有增强,本试验随机设置Mixup 参数α=β∈[0.1,0.9],就可以得到多样化的λ∈(0,1)区间内的概率分布,使数据增强更具有随机性,模型更具有鲁棒性。
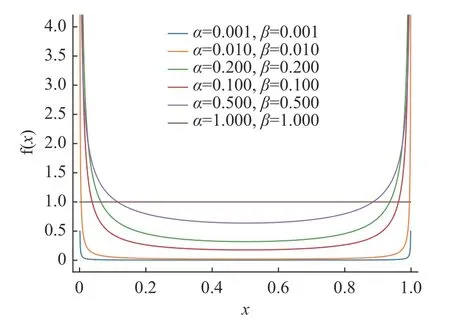
图5 α 和β 相同时的Beta 分布概率密度曲线Fig.5 Probability density curve of beta distribution while α and β were equal
1.3.4 分类损失函数的改进 一个好的损失函数对于网络参数调优达到事半功倍的效果。由于多种农作物叶片病害纹理特征大致形似,模型对一些病害样本计算的分类置信度产生偏差,进而影响样本分类效果,造成错误分类病害的情况。
基于以上计算样本分类置信度偏差的问题,YOLOX-Nano 将分类损失函数由BCE Loss 损失函数替换为Focal Loss 损失函数,其能控制容易分类和难分类样本的权重,通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本,让容易样本对损失产生贡献小,难样本对损失产生贡献大。
Focal Loss 分类损失函数公式定义如式(4)所示,表示预测值,y表示真实值,γ (γ≥0) 表示调节因子。设pt表示预测某真实标签的概率,定义如式(5) 所示,范围为[0,1]。由式(4)、(5) 归纳后Focal Loss (FL) 损失函数公式如式(6)所示:
与交叉熵函数损失函数相比,公式(6)多了一个(1-pt)γ系数,实质是对交叉熵损失函数的优化。如图6所示,可以通过改变γ调节因子的值,从而控制容易分类和难分类样本对损失的贡献。由公式(6)可知,若某样本类别概率pt趋于1,说明预测值p^接近于真实值y,这类样本就属于容易区分的样本,此时系数(1-pt)γ趋于0,对损失贡献极少。

图6 Focal Loss 函数曲线Fig.6 Focal Loss function curve
1.3.5 回归损失函数的改进 YOLOX-Nano 在回归候选框时仍使用GIOU 损失函数,本文根据数据集图片样本特点,设计出利于回归候选框的CenterIOU 损失函数。
如图7所示,已知候选框中心点(xpre,ypre)、真实框中心点(xtag,ytag)与最小外接矩形中心点(xct,yct)。根据公式(7)计算候选框和真实框的IOU,式中,BOX交集、BOX并集分别表示候选框和真实框的交集和并集;构造候选框中心点和真实框中心点两点的一般直线方程Y=Ax+By+C;根据公式(8)计算最小外接矩形中心点(xct,yct)到两框中心点的直线距离(Distance);最后代入公式(9),得到候选框回归损失。
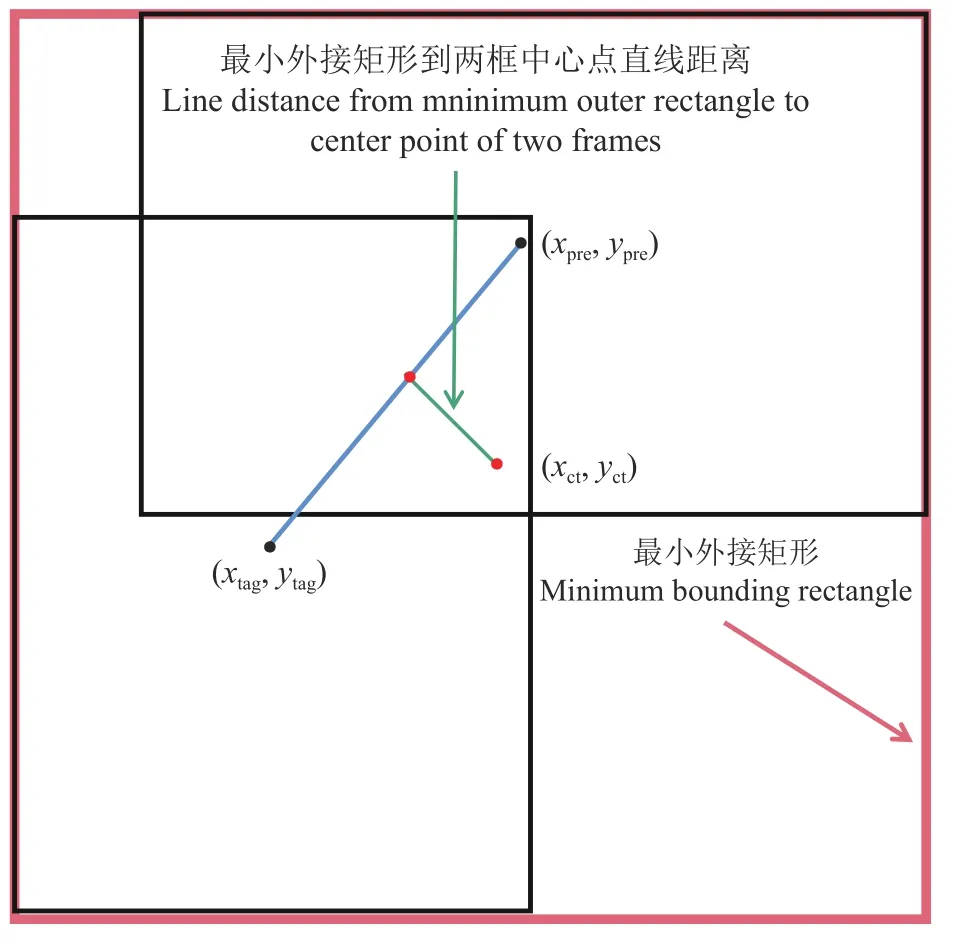
图7 CenterIOU 损失函数图解Fig.7 Diagram of CenterIOU loss function
由于定位损失函数更换为CenterIOU 损失函数,较原GIOU 函数让网络学习到预测框和目标框的相对位置,网络在反向传播时能更好地调优回归参数。
1.4 病害检测系统的设计
为获取实际状态下病害检测所需时间,对比网络改进前后的效果,以训练好的模型为基础,开发手机端病害识别系统。利用IOS 官方的Core ML Tools 模型转换库将训练好的pth 格式模型转换为IOS 平台使用的格式。前端界面提供图库、识别、保存3 个按钮,对应调用相册上传识别图片、快速识别作物病害、保存识别记录3 种功能。编译后生成安装文件部署在iPhone 8 手机,显示如图8所示。

图8 病害检测系统界面Fig.8 Interface of disease detection system
1.5 评价指标
对于农作物叶片病害检测,需要网络具有高精确率和实时性。本文采用 COCO mAP@[0.50:0.05:0.95][15-16]作为农作物病害检测评价指标来综合评估模型对苹果、玉米、苹果、玉米、葡萄、马铃薯、草莓、番茄6 类农作物的27 种病害和无叶片背景图像的检测性能,即分别在IOU 阈值设置以0.05 的步距从0.50 开始遍历至0.95,取这些阈值条件下评估所得到的平均准确率(Average precision,AP)及其均值(Mean average precision,mAP)。mAP 与准确率(Precision,P)、召回率(Recall,R)有关,其计算公式如下所示:
式中,TP 表示被模型预测正确的正样本数,FP 为被模型预测错误的正样本数,FN 为被模型预测错误的负样本数,M为类别总数,AP(k)为第k类平均准确率。
将训练好的模型部署移动端系统后,检测单张样本图像所消耗的平均时间(包含程序加载图片所耗时间和检测时间)作为实时性指标,单位为 s。参数量指标指深度网络模型中可训练参数的个数,以百万为单位,表示为1×106。
2 结果与分析
2.1 改进方法性能分析
使用YOLOX-Nano 模型为基础网络,分别引入CBAM 卷积注意力机制、Mixup 数据增强策略、使用Focal Loss 替换原分类损失函数BCELoss,本文设计CenterIOU 损失函数替换原回归损失函数GIOU 作为改进网络。
2.1.1 融合CBAM 卷积注意力机制 YOLOXNano 对农作物病害叶片检测与识别的精度较低,单张样本图片检测精准率仅为97.97%,其原因是6 种农作物27 类病害的叶片病态特征表现比较相似。通道注意力可对特征图的不同通道赋予不同特征,选择性增大不同病害斑点特征通道的权重值;空间注意力对同一特征图不同位置特征点给予不同权重,区别对待特征图内部像素点。
引入CBAM 卷积注意力机制模块后,虽然模型参数量由0.92×106增加到0.96×106、单张样本推断时间增加18 ms,但平均精确率由97.97%提升到98.89%,提升了0.92 个百分点,在很大程度上提升了对两者叶片病害识别的准确率。两者结合可总体提升识别准确率,表明了CBAM 模块区别相似物体的有效性。
利用Grad-CAM[17]工具可视化进入FPN 层前第一个CBAM 卷积注意力机制[18],明确对特征提取的效果。由于玉米病害的样本特征更为接近,可视化效果更佳,本文以玉米灰斑病样本、玉米锈病样本、玉米大斑病样本和健康玉米样本为例进行展示,如图9所示,引入卷积注意力机制前,网络对样本特征提取较随机,对叶片病害区域特征点关注不够。引入CBAM 卷积注意力机制后,网络在前向传播过程中,重要特征通道逐渐占有更大的比重,能让网络学习到需重点关注的部分,使改进的YOLOXNano 模型可以更高效地提取图像难区分的特征信息。

图9 Grad-CAM 可视化添加CBAM 前后玉米叶片特征提取的热力图Fig.9 Grad-CAM visual characteristic extraction thermal diagram of corn leaf before and after adding CBAM
2.1.2 训练引入Mixup 数据增强策略 使用Mixup 数据增强策略训练的网络模型单张样本图片检测时间较改进前平均减少了4 ms,其检测准确率却增加了1.02 个百分点,一方面减少了检测推断所用时间,另一方面可以提高对农作物病害检测精度,可见引入Mixup 数据增强策略扩充数据集可以提升农作物病害检测的效率,模型可以训练更充分,减少推断时间。
2.1.3 引入Focal Loss 损失函数试验 由式(6)可知,调节因子γ可以控制样本对损失的贡献,从而影响到病害分类的性能。试验中通过调节γ值来检测病害分类的效果,试验结果表明,γ取0 时mAP为97.97%,γ取1 时mAP 为98.69%,γ取2 时mAP 为99.02%,γ取3 时mAP 为98.42%,γ取4 时mAP 为97.32%,mAP 随γ值的增大呈现先升高后降低的趋势,当γ设置为2 时,mAP 最大,检测效果最好。
图10a、10b 是选取γ为2 时Focal Loss 损失函数和原BCELoss 损失函数在训练和测试阶段的分类损失的变化曲线,可以发现,改进后的YOLOX-Nano分类损失总体趋势都是低于YOLOX-Nano 的。

图10 训练阶段(a)和测试阶段(b)分类损失变化曲线图Fig.10 Classification loss curve during training(a) and test(b) phases
改进后的YOLOX-Nano 网络训练到100 个迭代结束,训练和测试阶段均呈现出持续下降的趋势,且还存在下降空间,说明网络仍在学习,分类精度仍有上升的可能性,而曲线逐渐趋于稳定,说明网络过拟合已经没有学习必要。
2.1.4 引入CenterIOU 损失函数 不同的回归框损失函数对检测精度带来不同程度的影响。试验通过比较GIOU 和本文设计的CenterIOU 损失函数的性能,来确定最适合的回归损失函数,最终试验表明使用GIOU 的YOLOX-Nano 在mAP50、mAP50:95的检测精度分别为98.23% 和97.97%,而使用CenterIOU 损失函数的YOLOX-Nano 在mAP50、mAP50:95的检测精度分别为98.53%和98.20%,较改进前分别提高了0.30 和1.23 个百分点,本文设计的CenterIOU损失函数与YOLOX-Nano 网络组合后,在数据集上对不同阈值表现得更好,能够明显地提高农作物病害的检测精度。
2.2 YOLOX-Nano 改进前后总体性能分析
改进后的YOLOX-Nano 模型参数量虽然增加了0.06×106,单张图片检测时间增加了11 ms,但是改进后的YOLOX-Nano 网络对所有农作物病害的平均检测精度达到了99.56%,较改进前精度(97.97%)提升了1.59 个百分点。改进后的模型对苹果松锈病、葡萄黑腐病、马铃薯早疫病、马铃薯晚疫病、番茄叶霉病、番茄斑枯病和番茄黄叶曲叶病的识别精度都达到了100%,对玉米灰斑病识别精度(98.66%)稍低,主要原因是玉米大斑病与灰斑病病害症状相似,不易判断,导致出现错分类现象。
同时,无叶片背景图这一类别存在背景中包含叶片的情况,模型能检测出叶片的存在,进而导致2 个模型对无叶片背景图识别精度都表现较低,这也证明了本模型没有出现过拟合的现象,改进的网络有很好的农作物病害检测与识别能力。
图11是改进前后网络训练平均精度和训练迭代的效果图,可见在训练10 个迭代时,改进的YOLOXNano 就能比改进前产生整体较高的mAP,预训练权重很快适应改进网络,趋于平稳,直到100 个迭代训练结束,最终改进后的YOLOX-Nano 精度更高。

图11 模型改进前后网络精度随迭代次数变化曲线图Fig.11 Curve of network accuracy changing with number of iterations before and after model improvement
2.3 不同算法的对比试验
本文还与现阶段较成熟的轻量型模型ResNet-18、MobileNet-v2、YOLOv4-Tiny、YOLOX-Tiny[19-24]进行对比,试验结果如表1所示,改进后的YOLOX-Nano 检测准确率较其他轻量型网络高出1.0~2.2 个百分点。在真机测试的检测时间对比中,本文提出方法的优势更加明显,单张样本图片检测时间仅需0.187 s,较其他各类模型节省大约20~240 ms 的计算时间。不仅如此,在参数量方面,本文方法较ResNet-18 减少了91.3%、较YOLOv4-Tiny 减少了83.9%、较YOLOX-Tiny 减少了80.7%、较MobileNet-v2 减少了72.0%,更小的参数量意味着更少的部署成本,因此改进后模型的综合性能非常优秀,对于农业应用具有明显的优势。

表1 与主流轻量型网络性能对比Table 1 Performance of the model versus mainstream lightweight network
2.4 病害检测系统识别效果
为验证本网络移动端部署可行性和所提出网络的实际分类效果,从试验数据集中,随机取出50张图片,录入手机端系统进行识别,手机端检测部分结果如图12a、12b 所示。经检测,所有图片病害全部识别准确,置信度保持在99.4%以上,最高置信度表现在苹果、葡萄和马铃薯3 种作物的病害检测,均保持在99.8%以上,实际运行最多耗时0.324 s,最少耗时0.169 s,平均耗时为0.187 s。此外,从苹果、玉米、葡萄、马铃薯、草莓、番茄6 类农作物病害样本中各筛选5 张田间拍摄照片进行检测,部分检测结果如图12c、12d 所示,所有病害依然识别准确,仍保持着99%以上的置信度,识别速度并未减弱,也无漏检错检的情况。可见本改进模型的检测效果和运行速度都保持着较高的水平,同时达到了精度和速度的平衡。

图12 病害检测结果展示Fig.12 Display of disease detection results
3 结论
相对于人工诊断农作物病害,利用计算机视觉方法检测农作物病害具有成本低、准确率高、时延短的优点。本文通过在YOLOX-Nano 分类模型中引入空间和通道注意力机制和Mixup 数据增强策略,将分类损失函数更换为Focal Loss,提出一种改进的YOLOX-Nano 优化网络,利用此网络对农作物病害数据集进行训练与测试,得出以下结论。
1) 改进的YOLOX-Nano 网络对PlantVillige 数据集中6 种农作物27 种病害的检测总体mAP 达到了99.56%,较YOLO-Nano 基础网络提升了1.59 个百分点,单张图片平均检测时间为0.187 s,仅仅较基础网络增加11 ms 的推断延迟,达到了精度与速度的平衡,而且网络参数量为0.98×106,利于植保无人机设备和移动端设备的部署。
2) 卷积注意力机制可以对不同通道的特征图进行权重的重新分配,加强网络结构深层信息的提取,对于很多细粒度特征的提取具有很好的效果,此外Mixup 数据增强策略对一些小型网络也能起到促进作用;Focal Loss 能控制容易分类和困难分类样本的权重,通过减少易分类样本的权重,在训练时更专注于难分类的样本,让容易样本对损失贡献小,难样本对损失贡献大。
3) 本文提出的CenterIOU 损失函数对本数据集训练具有促进作用,也可以推广应用到其他数据集。
