基于生成对抗网络的声呐图像超分辨率算法
2023-06-26程文博
程文博
(1.中国船舶集团有限公司第七一〇研究所,湖北 宜昌 443003;2.清江创新中心,湖北 武汉 430076)
0 引言
随着对湖泊、江河和海洋的探索不断深入,对于各类水底地形的刻画需求也日益增加。目前可通过水下无人潜航器[1]装配侧扫声呐得到水底地形原始图像,通过超分辨率处理,可以获得更加精细且清晰的地形图像,这样不仅对水下环境的感知和后续的自主决策至关重要,还能提升图像中小目标的探测和识别效果。
图像超分辨率(Super-Resolution,SR)是在20世纪60年代由HARRIS 等人[2]首次提出的,他们采用线性插值算法,提高了图像的空间分辨率。目前主流的超分辨率算法主要有2 种:1)基于图像插值的方法;2)基于深度学习的方法。SR 算法的概述如图1所示。基于插值的算法是最早被应用于图像超分领域的,其中最邻近元法[3]由SCHULTZ等人提出,此方法相当于让图像经过一个高通滤波器,可以保留图像的一部分边缘特征。由HOU 等人提出的双线性内插法[4],是对插值点附近的4 个相邻像素进行加权求和作为插值点的像素值,权值的大小与插值点和相邻像素点的距离成反比,所以重建后的图像细节较差,边缘较模糊。LI 等人提出的三次内插法[5],是对插值点附近的16 个相邻像素点进行加权求和作为插值点的像素值,因此重建图像的边缘特征会更平滑。

图1 超分算法概述图Fig.1 Schematic diagram of SR algorithm
随着各行各业对超分辨率的需求不断增加,基本的插值算法已经不能满足需求,各种新的SR算法如雨后春笋,而现如今深度学习的应用日益广泛[6-7],基于深度学习的SR 也得到了迅速的发展。2014年,香港中文大学的董超等人[8]首次将卷积神经网络用于超分领域中,提出了超分辨率卷积神经网络(Super-Resolution Convolutional Neural Network,SRCNN),通过简单的3 层卷积结构,完成了图像从低分辨率输入到高分辨率输出的转化,相较于传统的插值算法,性能有了一定的提升。随着生成对抗网络[9]的兴起,生成对抗网络在图像的重建中取得了较好的成绩,也逐渐被应用于图像超分领域,LEDIG 等人[10]提出了SRGAN,首次使用生成对抗网络来训练SRResNet,使其生成的高分辨率图像看起来更加自然,相较于SRCNN 有更好的视觉效果。2018年,ZHANG 等人[11]提出了残差密集网络,充分利用了所有层的特征,然后通过特征融合机制极大限度的保留了特征,得到了更好的重建效果。WANG 等人[12]为了进一步提升生成图像的质量,更好的保留原有的细节信息,在网络中引入了残余稠密块(Residual-in-Residual Dense Block,RRDB)取代了残差块。哈尔滨工程大学的梁雪灿[13]在条件生成对抗网络[14](CGAN)的基础上提出了SR-CGAN 和一种带有梯度惩罚的深层生成对抗网络(DGP-SRGAN),前者可以有效地控制超分辨率图像输出,后者对保留细节和提高纹理起到了一定的作用。SOH[15]等人在2020年提出了一种基于元学习的超分算法训练过程——MZSR,该方法利用元学习“学习怎样去学习”的特性,在一定程度上解决了小样本和大量迭代训练的问题。
综上所述,传统插值算法存在着图像整体平滑的问题,处理后图像中小目标的边缘模糊。本文采用了基于生成对抗网络的超分算法,可以在保留纹理细节的情况下,将低分辨率图像转化为高分辨率图像输出,通过对图像声呐实测数据进行处理,验证了方法的有效性。
1 本文方法及原理介绍
1.1 网络结构及预处理
本文中生成模块的基本架构是SRResNet,但是对于中间的非线性映射结构做出了调整,本文的非线性映射结构由17 个残余稠密块构成,其中每个RRDB 均由3 个稠密块(Dense Block,DB)组成,每个DB 则由3 个conv-LeakyRelu 模块和1个卷积层构成。本文中的判别模块采用VGG128[16]网络。
生成模块的结构如图2所示,RRDB 和DB 的结构分别如图3和图4所示。

图2 生成模块结构图Fig.2 Generate module structure

图3 RRDB 结构图Fig.3 RRDB structure
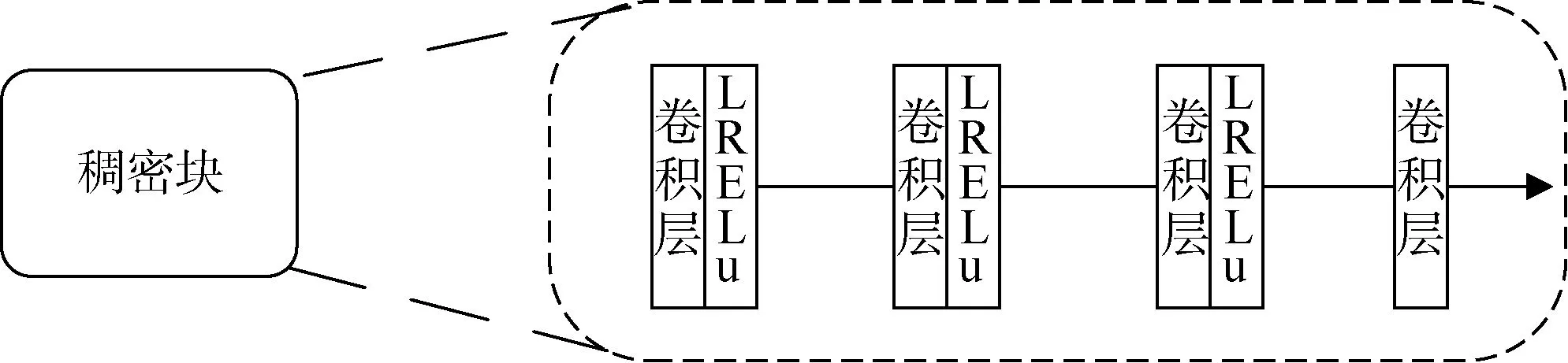
图4 DB 结构图Fig.4 DB structure
在图像识别领域,卷积层的作用往往是减少或者维持输入特征图不变来达到提取特征的目的,而在生成对抗的超分算法中则是使用上采样来增加输入特征图的大小,从而使输入的低分辨率图像变成高分辨率图像输出。本文采用转置卷积的方法来达到上采样的效果。转置卷积计算过程如图5所示。
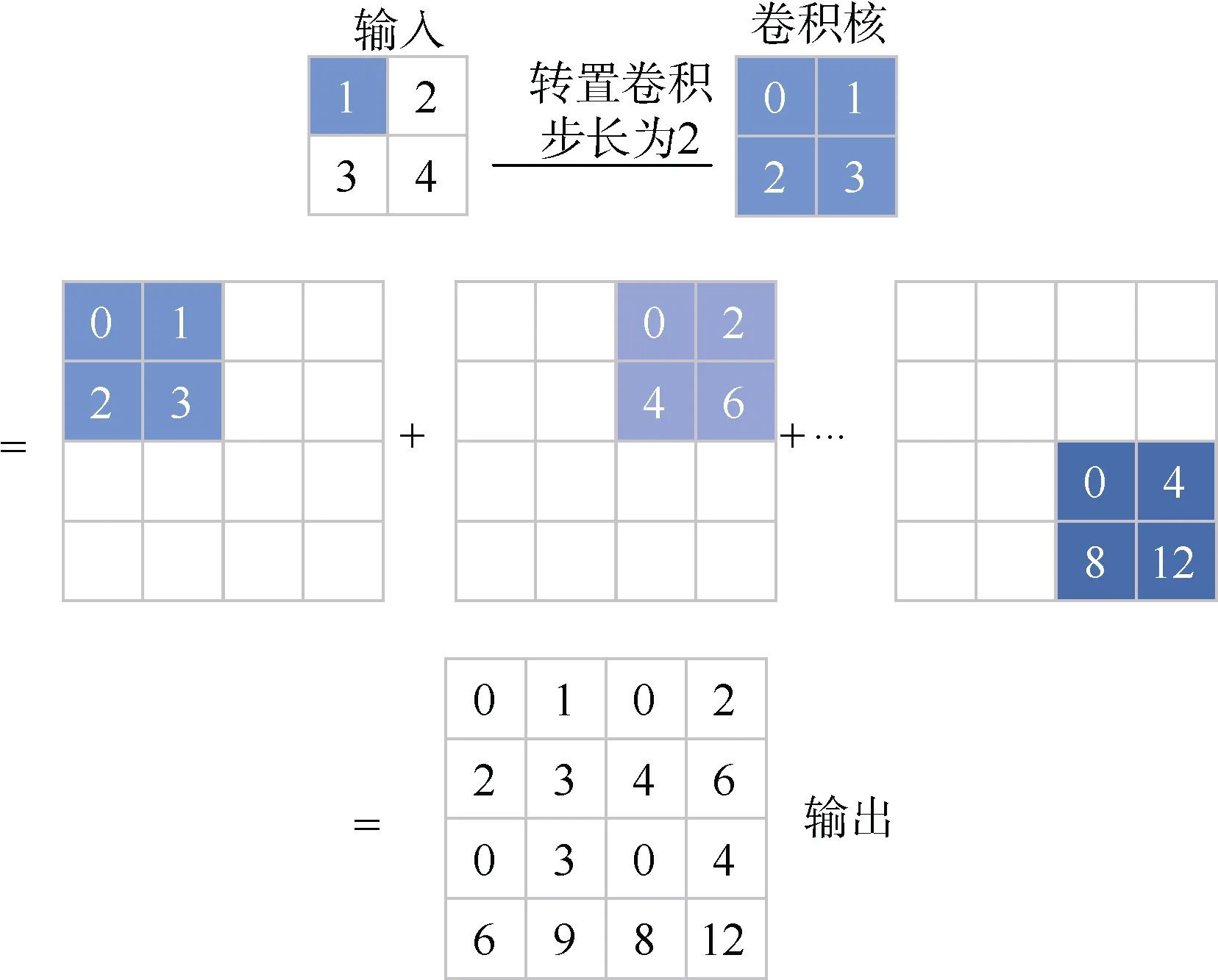
图5 转置卷积计算过程Fig.5 Transposed convolution calculation process
从图5中可以看出,转置卷积的计算过程就是kernel 核与输入的特种图中,逐个元素相乘,放在对应位置,得到不同的特征矩阵,然后逐一相加得到最终的输出。此处的例子stride=2,所以滑动的步长是2。
1.2 损失函数
生成模块的损失函数可以分为3 个部分:内容损失、像素损失、对抗损失。其中内容损失用到的是VGG19 经过激活函数之前的卷积层的输出特征图作为计算的输入,使得其更偏重于纹理上的损失,而像素损失更偏向于像素层面的损失。其总体损失函数公式为
式中:LG为总损失;Lcotent为内容损失;LGL为对抗损失;Lpixel为像素损失。
Lcotent损失函数的公式为
式中:VGG()为经过VGG19 后第20 层的输出结果;xiLR为生成模块输入的低分辨率图像;xiSR为xiLR经过生成模块后输出的高分辨率图像。
Lpixel损失函数的公式为
式中:G(xi)为经过了生成模块的输出;y为原始高分辨率图像。像素损失就是计算二者之间的平均绝对误差。
LGL损失函数的公式为
式中:N为每次训练的样本个数;yi为labels;p(yi)为将样本识别为正确的概率。
1.3 评价指标
在现有的图像处理算法里,一般常用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity,SSIM)作为图像质量好坏的评价指标。PSNR 公式为
式中:yi为真实值;为估计值。
从上式中可以看出,MSE 为处理后图像和原始图像的均方误差,所以MSE 的值越小代表处理后的图像与原始图像越相似。因此,当PSNR 越大时,说明处理之后的图像失真程度越小。
SSIM 的公式为
式中:μimg1是img1的平均值;μimg2是img2的平均值;σimg12是img1的方差;σimg22是img2的方差;σimg1img2是img1和img2的协方差;c1=(k1L)2,c2=(k2L)2,这2 个常数是用来维持计算稳定的;L是图像像素值的最大值255;k1=0.01;k2=0.03。
SSIM 是衡量2 幅图像相似度的指标,SSIM 的值越大,表示图像失真程度越小,说明图像质量越好.但是,对于图像而言,人眼直观感受仍是最直接的衡量标准。
2 实验结果与分析
2.1 实验环境
本文中的实验部分均使用Python 中的深度学习框架TensorFlow 完成。
实验设备环境如表1所示。
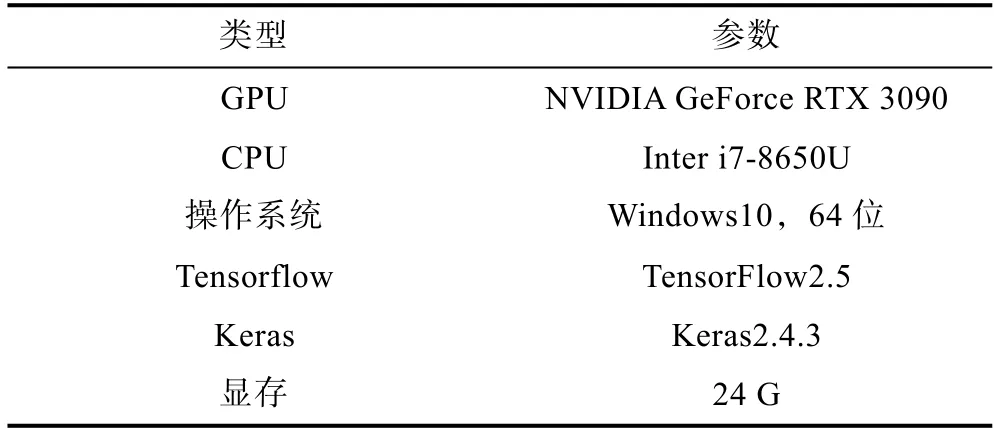
表1 实验设备环境Table 1 Test equipment environment
2.2 实验结果与分析
本文中用到的高分辨率(High Resolution,HR)数据集为开源数据集DIV2K,对其进行降采样处理得到分辨率降低4 倍的低分辨率(Low Resolution,LR)数据集DIV2K_LRX4,通过上述数据集对网络进行预训练。完成预训练后,通过同样的处理方式将湖试取得的侧扫声呐图像降采样得到LR 数据集,用得到的LR 数据集和处理前的侧扫声呐图像数据集对完成预训练的网络进行微调。
完成数据集构建并搭建完网络后,开始进行网络参数设置。其中,batch_size 设置为8,生成模块输入图像的维度为32×32×3,判别模块输入图像的维度为128×128×3,预训练网络迭代500 000次,后续训练固化网络迭代次数设为200 000 次,网络训练采用Adam 优化算法,网络预训练时初始学习率设置为0.002,迭代次数每增加200 000 学习率乘0.5,后续训练固化时网络训练的初始学习率设置为0.000 1,迭代次数每增加50 000 学习率乘0.5。
训练完成后用2 张低分辨率的样本图像来测试网络的超分辨率性能,并与其他的超分算法作对比,如线性插值算法、SRGAN、三次插值算法。图6为样本图,测试样本1 与测试样本2 经过上述算法处理后输出的图像分别如图7和图8所示。

图6 测试样本Fig.6 Test samples

图7 样图1不同超分算法效果对比Fig.7 Comparison of effects of Sample Figure 1 with different SR algorithms

图8 样图2不同超分算法效果对比Fig.8 Comparison of effects of Sample Figure 2 with different SR algorithms
分别计算经过超分算法处理过后的图像和原始HR 图像之间的PSNR 和SSIM 值,将得到的结果整理如表2所示。
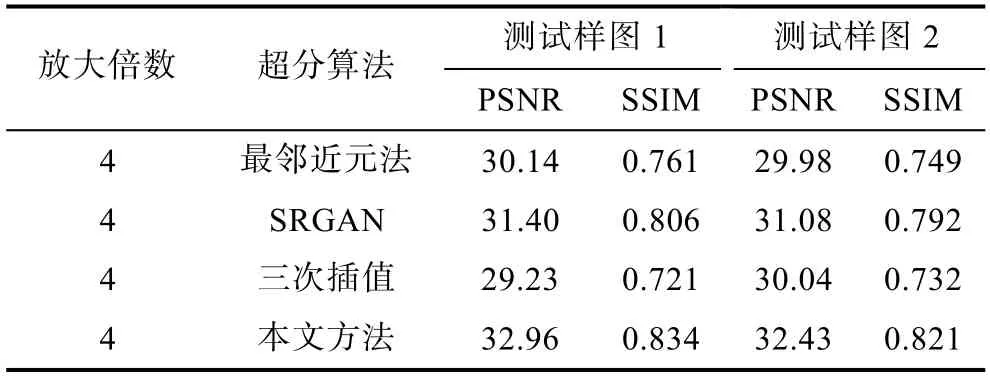
表2 各方案PSNR/SSIM 处理结果对比表Table 2 Comparison of PSNR/SSIM values in different methods
从图7和图8可以直观地看出使用本文方法得到的超分辨率图像视觉效果最好,目标的边缘细节更加清晰,目标特征得到了突出体现。从表2中计算得到的PSNR 和SSIM 数据也可以看出,本文方法的 PSNR 和 SSIM 要明显优于插值算法和SRGAN。
结合图7、图8和表2可验证本文所述方法可以在一定程度上解决侧扫声呐图像中目标模糊的问题,在有效地保留原始图像中原有特征的同时,还可提升图像中小目标的边缘细节及小目标本身的清晰度,为后续目标精准识别等过程提供了实现基础。
3 结束语
本文提出了一种基于生成对抗网络的侧扫声呐图像超分辨率处理方法。实测数据处理表明:该方法可有效解决侧扫声呐图像分辨率低、小目标细节模糊、边缘不清晰等问题。通过与传统的插值算法和SRGAN 做效果对比,可以看出本文所述方法可有效避免插值算法带来的图像整体平滑的缺点,且相较于SRGAN 而言,该方法图中目标的细节更清晰、边缘更加突出,为后续的侧扫声呐图像的目标检测与识别打下了良好的基础。对检测与识别网络而言,如果待检测图像中小目标的特征更明显,边缘更鲜明,检测出目标的概率和识别目标种类的准确率也会更高。
