SSM: 基于孪生网络的糖尿病视网膜眼底图像分类模型
2023-06-25谭嘉辰董永权张国玺
谭嘉辰 ,董永权,2* ,张国玺
(1.江苏师范大学计算机科学与技术学院,徐州,221116;2.徐州市云计算工程技术研究中心,徐州,221116)
现代社会的快节奏生活使糖尿病患者成为增长速度最快的病人群体之一,截至2021年,全球共有5.37 亿成年人患有糖尿病[1].糖尿病的高血糖会损害细小的血管,导致视网膜血管肿胀,出现渗漏液和血液,这种并发症就是糖尿病视网膜病变(Diabetic Retinopathy,DR)[2],可能导致视力受损,是人类永久性失明最常见的病因之一[3-4].现在,医学上普遍认为根据相关生理指标,DR 可分为正常(normal)、轻度DR(mild DR)、中度DR(moderate DR)、重度DR(severe DR),阶段样例如图1 所示.DR 早期阶段为mild DR(图1b),可以检测到微动脉瘤的形成;moderate DR(图1c)阶段可能会出现血管肿胀和视力模糊,严重的会出现血管异常和大量的堵塞血管;severe DR(图1d)阶段已经是DR 的后期,可以检测到视网膜脱离和大的视网膜裂口,导致完全失明[5].由于DR的早期症状难以发现,所以患者需要进行定期筛查,目前主流的筛查方法是依靠临床医生进行手工诊断,通过使用眼底镜、眼底照相、荧光素眼底和光学相干断层扫描(Optical Coherence Tomo‐graphy,OCT)等方法来检测患者的病情.手工筛查十分依赖医生的经验,经验不足和长时间工作后的疲劳使医生很容易对其误诊漏诊,所以DR自动识别技术能使医生和患者都受益.近年来深度学习在医学领域被广泛应用,为了减少筛查的成本,许多深度学习模型被应用到DR 分类任务中,尤其是卷积神经网络(Convolutional Neural Networks,CNN)[6-7].
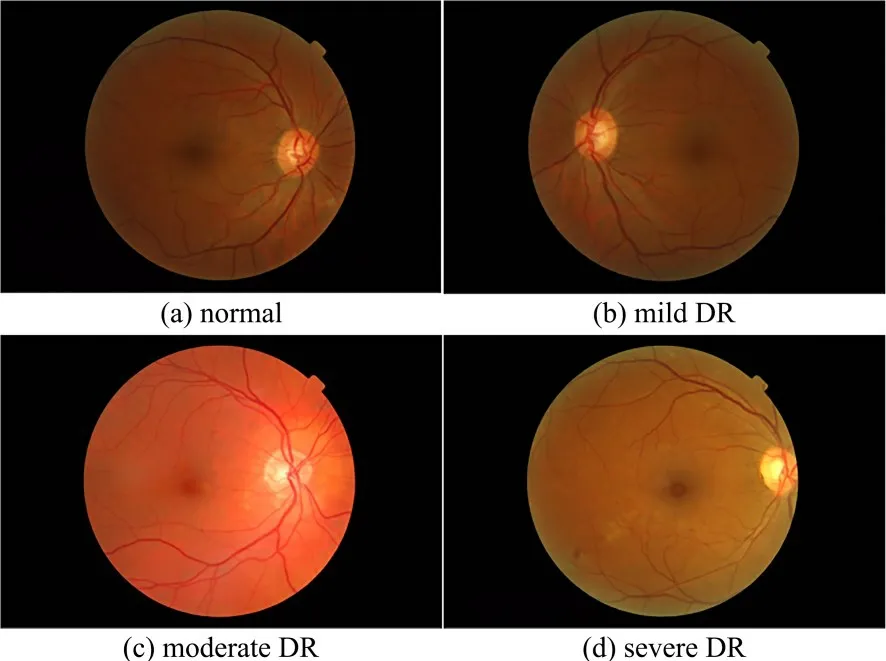
图1 DR 各阶段的样例图Fig.1 Samples of each stage of DR
DR 分类任务的主要挑战就是DR 图像数量稀缺,而且和普通图像相比,结构简单,语义单一,但图像中的浅层信息和高级特征都很重要,所以需要结合图像全局和局部信息来获取图像特征.为了解决这些问题,本文在模型架构方面选择孪生网络结构,和单支的网络相比,孪生网络只需要很少的训练数据就可以达到较高的分类效果.在特征提取方面,本文选择使用Swin‐Transformer[8]作为分支网络.传统的CNN 模型往往只关注图像的局部信息,而Transformer[9]结构更关注图像的整体信息.Swin‐Transformer 利用窗口注意力和移动窗口注意力将CNN 的思想应用到Trans‐former上,和原始的Transformer 相比,性能得到了提升.在分类方面,本文设计了一种新的MLP‐Based U‐Net(MU‐Net)分类器,以多层感知机(Multilayer Perceptron,MLP)为基础,借鉴了U‐Net[10]的结构.实验结果表明,与其他方法相比,本文提出的方法是有效的.本文的具体贡献:
(1)提出一个新的孪生网络模型Siamese Model with Swin‐Transformer and MLP‐Based U‐Net(SSM).以预训练的Swin‐Transformer 替代传统的CNN 作为分支网络,在面对高分辨率的DR 图像时,利用窗口自注意力和移动窗口自注意力来构造层次特征映射,能够高效地提取DR图像中的特征.
(2)提出了一个新的MU‐Net 分类器,以MLP 为基础,在升降维的过程中增加跳跃连接,使浅层特征和深层特征得到充分的融合,更有利于模型的判别.
(3)在数据集上以端到端的方式训练本文提出的模型,实验结果证明,在Messidor 数据集上,该模型优于目前最先进的模型.
1 相关工作
人工检测DR 图像现在有很多问题,缺乏专业的眼科医生和昂贵的费用给患者造成了许多阻碍.自动分类技术简化了诊断过程,近年来深度学习模型已成功实现了准确的DR 自动分类.
Pratt et al[11]利用简单的CNN 网络就达到了0.95 的特异度.丁蓬莉等[12]在AlexNet 的基础上设计了CompactNet 模型来对DR 进行分类.李琼等[13]也在AlexNet 的基础上设计了BNet,同时利用迁移学习和数据增强等方法达到了0.83 的准确度.Gayathri et al[14]通过轻量级CNN 从眼底图像中提取特征,再用决策树进行分类.Hossen et al[15]利用迁移学习和DenseNet 结构来对DR 图像进行分类.但是从头开始训练需要大量数据,而医学数据非常稀缺,导致模型很难得到充分的训练.随着许多大模型的提出,预训练的模型也被越来越多地应用到具体的分类任务中.Delapava et al[16]利用多种预训练模型来提取DR 图像特征,针对不同病灶分别训练不同的分类器,再将分类器集成获得最终的结果.Gupta et al[17]利用VGG19 在自己的数据集上完成预训练,再利用分类器分类.但是预训练的先验知识十分有限,为了能让模型专注于图像的关键区域,注意力机制被广泛应用到神经网络中.Yang et al[18]提出一种特征映射全局通道注意力机制(GCA),使用一种基于一维卷积核的算法并利用GCA 设计了一个用于DR 分类的GCA‐efficient 模型.Al‐Antary and Arafa[19]提出一种多尺度注意力网络,利用编码器和多尺度特征金字塔将视网膜图像嵌入高层次特征.除了传统的单支网络,Tian et al[20]提出双分支网络,在CNN 中融入通道注意力和空间注意力,加入空间金字塔池化,并且利用全局平均池化来压缩特征.现有方法主要基于CNN 和单分支结构,利用预训练和在CNN 中加注意力等方法来提升模型性能,但在样本稀缺和特征提取等方面还是存在改进空间.现有的研究表明Trans‐former 在特征提取方面比CNN 具有优势,且孪生网络在面对小样本时,和传统的单分支网络相比,在结构上有天然优势,所以本文以孪生网络和Transformer 为基础来设计模型.
2 本文方法
本文提出一个基于Swin‐Transformer 和MU‐Net 分类器的孪生网络模型SSM,其结构如图2所示.将一组经过预处理的图像对送入SSM 模型,通过参数共享的两个相同的分支网络来提取图像特征,将两个模型提取的特征拼接,再将拼接后的特征送入MU‐Net 进行分类,最后输出分类结果.分支模型摒弃了传统的卷积神经网络模型,采用最新的Transformer 架构,利用注意力机制来提取图像特征,进一步增强图像中各局部信息和全局信息之间的关系,提高网络提取特征的能力.和传统的MLP 相比,MU‐Net借鉴了U‐Net的思想,在MLP 的基础上增加了跳跃连接和网络深度,能够让分类器融合保留更多的图像信息.
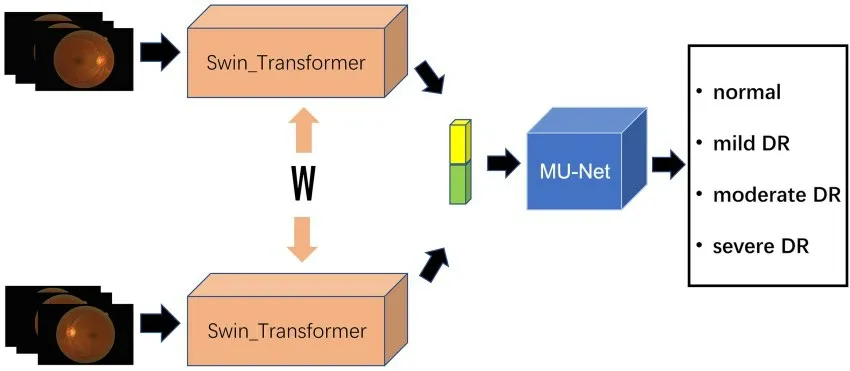
图2 SSM 的结构Fig.2 The framework of SSM
2.1 Swin⁃TransformerSwin‐Transformer 是一种拥有CNN 特性的Transformer 网络.Trans‐former 网络最先在自然语言处理领域被提出,利用其特有的注意力机制来序列建模,能够解决数据中的长依赖性问题.VIT(VisionTransformer)第一个将Transformer 引入视觉领域[21],而Swin‐Transformer 是在VIT 的基础上结合卷积特性设计的网络模型,其结构如图3 所示.
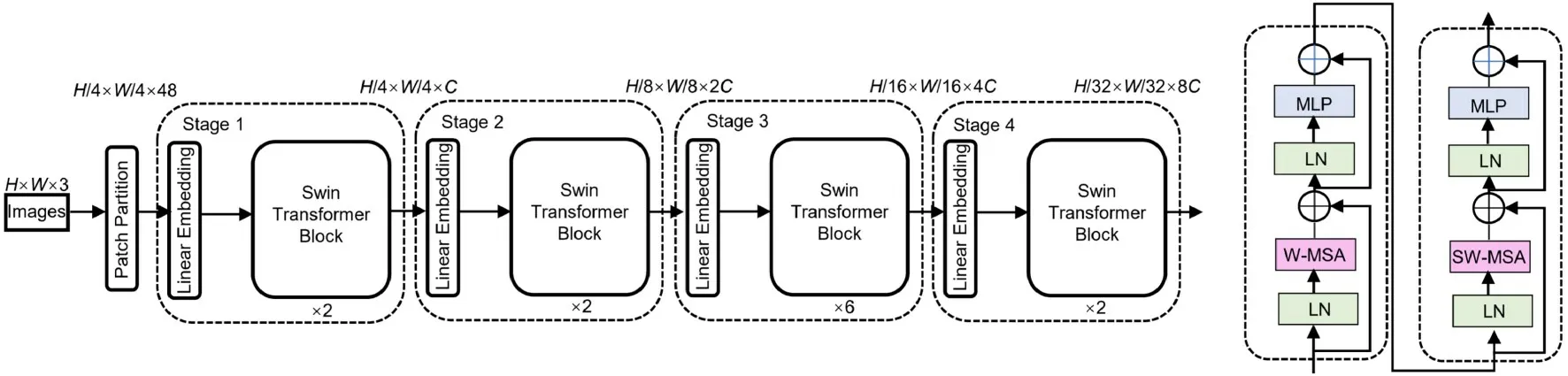
图3 Swin⁃Transformer 的结构Fig.3 The framework of Swin⁃Transformer
Swin‐Transformer 与VIT 不同,传统的VIT计算的是全局注意力,在面对大像素的医学图像时计算量巨大,训练时间开销长.Swin‐Trans‐former 借鉴了卷积窗口的思想,另辟蹊径,将图像块分成小窗口,每次只计算窗口内的自注意力,使注意力的计算复杂度随着图像的分辨率大小线性增长而不是平方级增长.同时,为了保证每个窗口之间也能进行信息交互,Swin‐Transformer 利用移动窗口的方式在下一层重新划分小窗口,使得上层不在同一窗口的区域得到信息交互.具体的移动方法是在上一层的基础上向右下角移动两个图像块,如图4 所示.
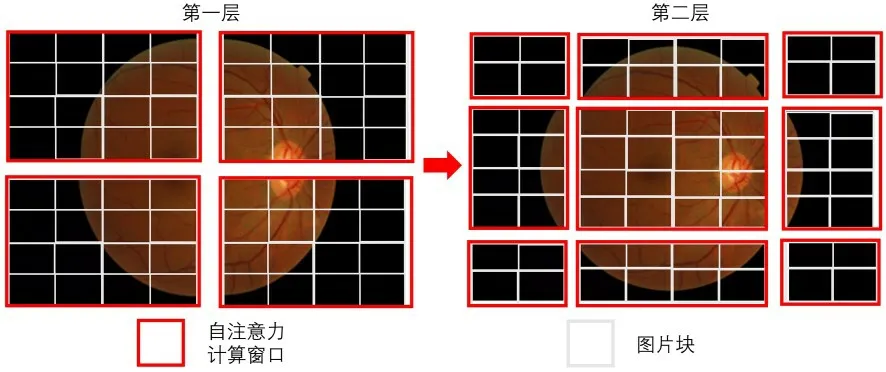
图4 Swin⁃Transformer 中的移动窗口结构Fig.4 The structure of shifting window in Swin⁃Trans⁃former
为了得到图像的全局信息,Swin‐Transform‐er 产生了一个层次特征映射,如图5 所示.随着网络的加深,从灰色轮廓的图片块开始,逐渐合并相邻区域内的图片块,使窗口内的图像块越来越多,分别采用4,8,16 倍下采样来形成一种层次化的表征,类似卷积神经网络中的池化操作.

图5 Swin⁃Transformer 的层次特征映射Fig.5 Hierarchical feature mapping of Swin⁃Trans⁃former
2.2 MU⁃Net对于高分辨率的医学图像特征,传统的MLP 分类器结构简单、训练难度大且容易丢失像素间的信息,本文利用U‐Net 的思想设计了MU‐Net 分类器.MU‐Net 的结构如图6 所示.医学图像和其他图像相比,语义简单,结构单一,但是图像中的每一种特征都很重要,其低级语义特征和高级语义特征具有同等的重要性,而利用扩张路径和收缩路径以及残差网络的特征跳跃连接能够更好地保存特征信息.
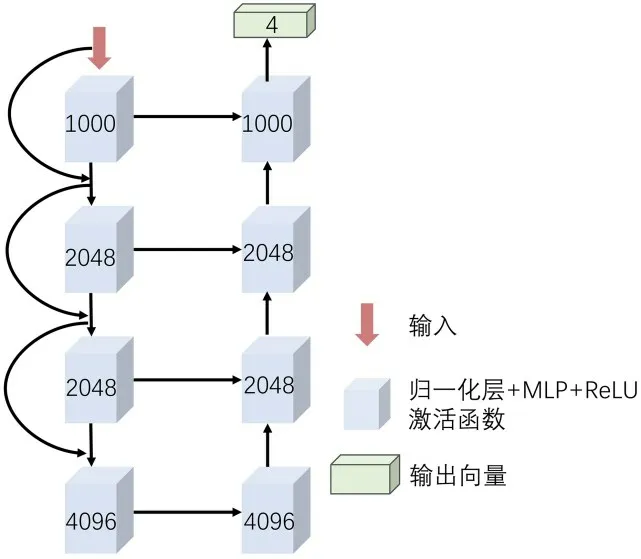
图6 MU⁃Net 的结构Fig.6 The framework of MU⁃Net
3 实验
3.1 数据集使用Messidor 数据集[22],这是由法国国防研究部资助的一个研究项目,属于2004年TECHNO‐VISION 项目.Messidor 中含有来自三个不同眼科机构的1200 张彩色眼底图像,每张眼底图像都由一个拥有45°视野的彩色3CCD摄像机取得.图像的分辨率有三种:1440×960,2240×1488 和2304×1536.1200 张图像被专家手动标注,共有normal,mild DR,moderate DR 和se‐vere DR 四个类.Messidor 数据集的具体分布如表1 所示.

表1 Messidor 数据集的具体分布Table 1 The distribution of Messidor datasets
3.1.1 数据预处理Messidor 数据集中的数据是从三个眼科机构收集而来的,所以存在光照不均衡、模糊和有噪音等情况.为了减少外在因素对实验结果的影响,对图像做了一定的预处理.具体的预处理方法如下:
(1)对比度有限的自适应直方图均衡(CLA‐HE).传统的直方图均衡是对图像全局进行操作运算,在面对图像局部区域过亮或过暗时效果欠佳,并给图像的背景区域带来一定噪声.CLAHE将图像分块,在分块计算时加入对比度限制并使用双线性插值的方法,解决了传统的直方图均衡带来的问题.
(2)高斯滤波(Gauss Filtering).高斯滤波是一种平滑的线性滤波,主要用来消除高斯噪声.对于图像中的每个像素,利用掩膜来确定相邻区域内的像素值,采用加权平均灰度值来代替模板中心的像素值.
(3)提高图片亮度和对比度.为了突出图像中的病灶特征,采用式(1)来增强图像中的像素点,增大图像中的明暗差距,提高图像的对比度:
其中,f(x)表示原像素值;g(x)表示输出像素值;α表示像素的增益,α>0,利用α来控制图像的亮度;β表示偏执,用来控制图像的对比度.
(4)裁剪背景区域.原始图像中存在大量没用的背景区域,可通过形态学操作找到眼球边缘来进行裁剪,减少背景区域对实验的影响.
DR 各阶段经预处理后的样例图如图7 所示.
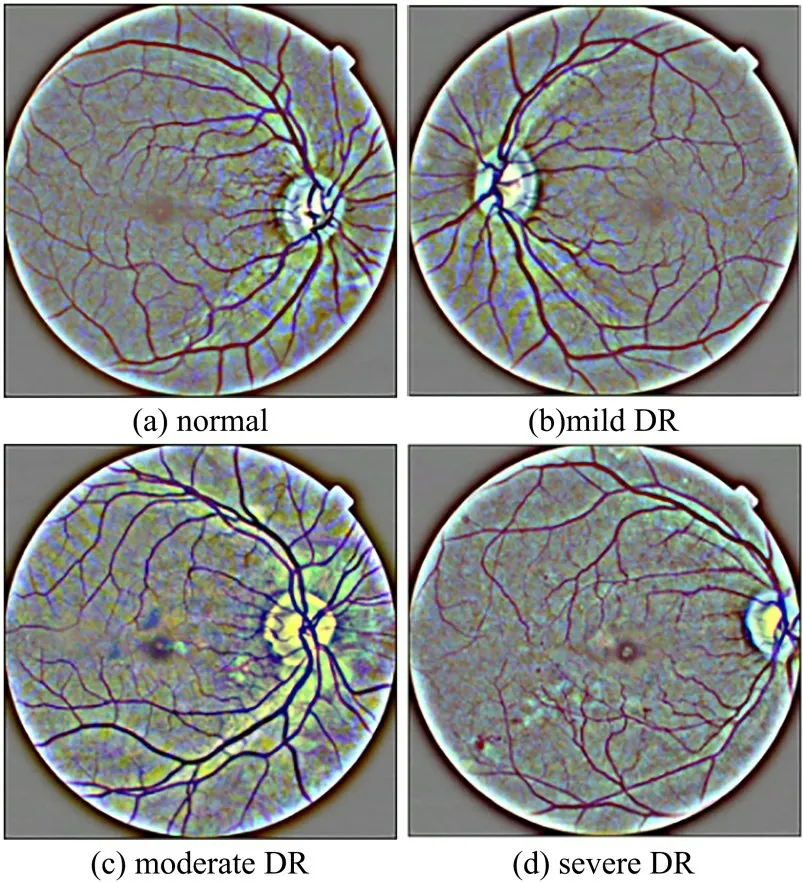
图7 DR 各阶段经预处理后的样例图Fig.7 Preprocessed samples at each stage of DR
3.1.2 数据扩增对于深度学习网络,足量的数据是模型充分训练的保证,数据过少会导致网络欠拟合,分类性能差.从表1 可以看出,Messidor数据集中不同类别的数据量十分不平衡,使模型的训练过程失去一般性,导致训练出来的模型趋向数量较多的那一类,对于数量较少的类别,判别效果会变差.针对以上问题,通过将图像进行旋转/平移等方法,对数量不平衡的类别进行扩充,保证每个类别的数量都与原始最多数量的类别相同.扩充后的数据分布如表2 所示.

表2 扩增后数据集的具体分布Table 2 The distribution of the augmented datasets
3.2 评估指标采用的评估指标为准确率(Accuracy,Acc)、精确率(Precision,P)、召回率(Recall,R)、F1 和Kappa 系数,如下所示:
3.3 实验结果和分析设计五个实验来验证SSM 模型的性能.实验使用相同的超参数:训练轮数为100,学习率为0.00001,优化器为Adam.实验配置:Windows 10,Pytorch,GPU(GeForce RTX 2080Ti).所有实验重复五次,最终结果为五次实验结果的平均值.
3.3.1 对比实验将本文提出的SSM 模型与最先进的预训练模型进行比较,实验结果如表3 所示,每个模型每类的具体结果如表4 所示,表中黑体字表示最优的结果.
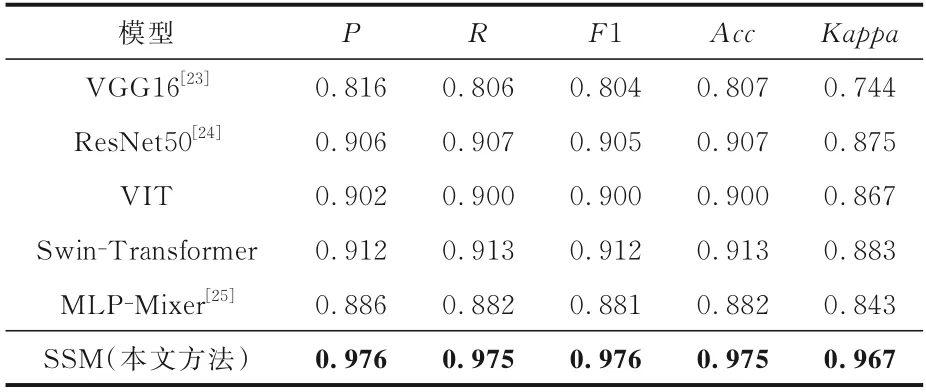
表3 本文模型SSM 和对比模型的实验结果Table 3 Experimental results of our SSM and other models

表4 本文模型和对比模型每类的实验结果Table 4 Experimental results of each category by our model and other models
由表3 可见,本文的SSM 模型和现有的预训练模型相比,性能提升十分明显.其P,R,F1,Acc,Kappa和次高的模型相比,分别提高0.064,0.062,0.064,0.062 和0.084,增幅分别达7%,6.7%,7%,6.7%和9.5%;和最差的模型相比,分别提高了0.160,0.169,0.172,0.168 和0.223,增幅达 19.6%,20.9%,21.3%,20.8%和29.9%.其中,Kappa的提升最显著,Kappa 系数和准确率(Acc)相比,能更好地处理类别不平衡问题,惩罚模型的偏向性,分类越平衡的模型得分越高.本文的SSM 模型使用孪生网络架构,每次的输入都是一组图像对,和传统模型单张图像的输入相比,这种方式可以让模型在训练过程中不停地学习不同类别图像之间的差别,同时强化同类图像的特征,是更注重区别度的学习,使模型能够平衡地区分每个类别,不会出现偏向性,这也是Kappa 系数提升最明显的原因.
分析表4 可以看出,Transformer 架构的VIT,Swin‐Transformer 和SSM 与传统CNN 和纯MLP架构的模型相比,在区分正常和患病的DR 图像时没有优势,但在具体到每个患病类别时,由于Transformer 能够利用注意力机制关注图像的全局信息,所以对含有多个相似病灶的不同图像能从全局层面进行有效区分.Swin‐Transformer 比VIT 增加了窗口注意力和层次化表示,使整个模型从一开始就能将全局信息和局部信息融合,更有利于对细微差别的关注.本文提出的SSM 又强化了Swin‐Transformer 的优势,所以在具体细分每个类时取得了最高指标.每种模型的混淆矩阵如图8 所示.
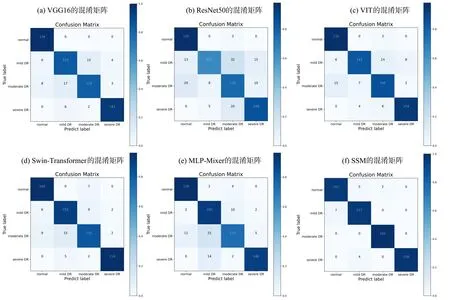
图8 各模型实验结果的混淆矩阵Fig.8 Confusion matrices of experimental results of different models
图9 展示了不同模型对同一张mild DR 图像注意力的热力图.由图可见,CNN 模型展现的注意力较极端,呈现大块连续的关注和不关注点,不够细节;VIT 和MLP‐Mixer 的注意力表现和CNN 相反,呈散点状,且很少有聚焦的关注点;Swin‐Transformer 与VIT 和MLP‐Mixer 相比,加大了关注区域和聚焦度,SSM 则是在其基础上进一步加深了对病灶区域的关注.

图9 各模型对同一张DR 图像的热力图Fig.9 The heat map of each model on the same DR Image
3.3.2 分支网络实验为了验证不同模型提取特征的能力,将SSM 模型的分支网络Swin‐Transformer 替换成VGG16,ResNet50,Trans‐former 三种不同的预训模型进行比较,实验结果如表5 所示,表中黑体字表示结果最优.由表可见,CNN 不适合作为分支网络,过度的特征融合使CNN 网络的特征爆炸,让模型丢失了重要特征,对所有特征一视同仁导致分类结果较差.VIT和Swin‐Transformer 相比,没有层次化表示和窗口自注意力,计算复杂度高,需要更多的数据来拟合,也不能充分融合局部特征,最终的结果不如Swin‐Transformer.
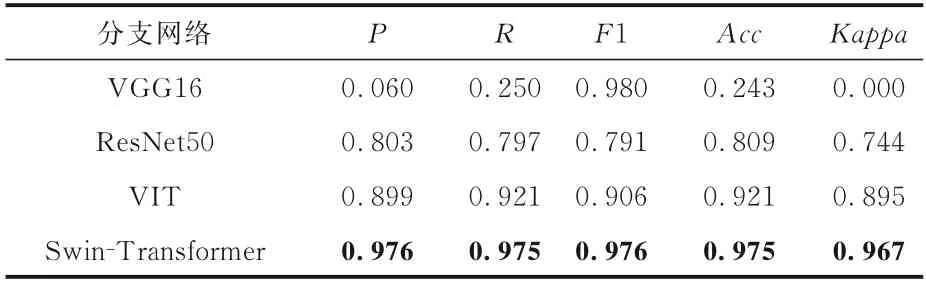
表5 不同分支网络的对比实验结果Table 5 Experimental results of different branch net⁃works
表6 展现了VIT 和Swin‐Transformer 强劲的提取特征的能力,能够在各类中提取到重要特征,而CNN 模型只能在严重程度最高的severe DR图像中提取到具有区分度的特征,这两种Trans‐former 结构的模型比CNN 模型在细化分类方面有显著的提升.其中,Swin‐Transformer 比VIT又有小部分提升.

表6 不同分支网络针对具体类别的分类结果Table 6 Classification results of different branch networks for specific classes
3.3.3 分类器对比实验本文提出一个新分类器MU‐Net,为了验证其性能,在SSM 模型的基础上更换不同的分类器来对比结果.实验结果如表7 所示,具体分类结果如表8 所示,表中黑体字表示结果最优.

表7 MU⁃Net 与传统分类器的对比实验结果Table 7 Experimental results of MU ⁃Net and other traditional classifiers

表8 传统分类器针对具体类别的实验结果Table 8 Experimental results of traditional classifiers for specific classes
由表7 可以看出,MU‐Net 比其他分类器表现出更高的分类性能,其Accuracy 和Kappa 系数比次高分类器高了0.006 和0.008,比SVM 高0.73和0.967.MU‐Net 和传统的分类器相比,能处理更复杂的特征,在升降维的过程中提取抽象的高维特征用以分类.
3.3.4 MU⁃Net 和MLP 对比实验为了分析MU‐Net 分类器的效果优于其他分类器是MLP结构分类器的天然优势还是本文提出的MU‐Net的作用,利用5.2 的四种结构,分别将MU‐Net 换成传统三层的MLP 进行对比.实验结果如表9 所示.MLP 结构的具体分类如表10 所示,表中黑体字表示最优的结果.
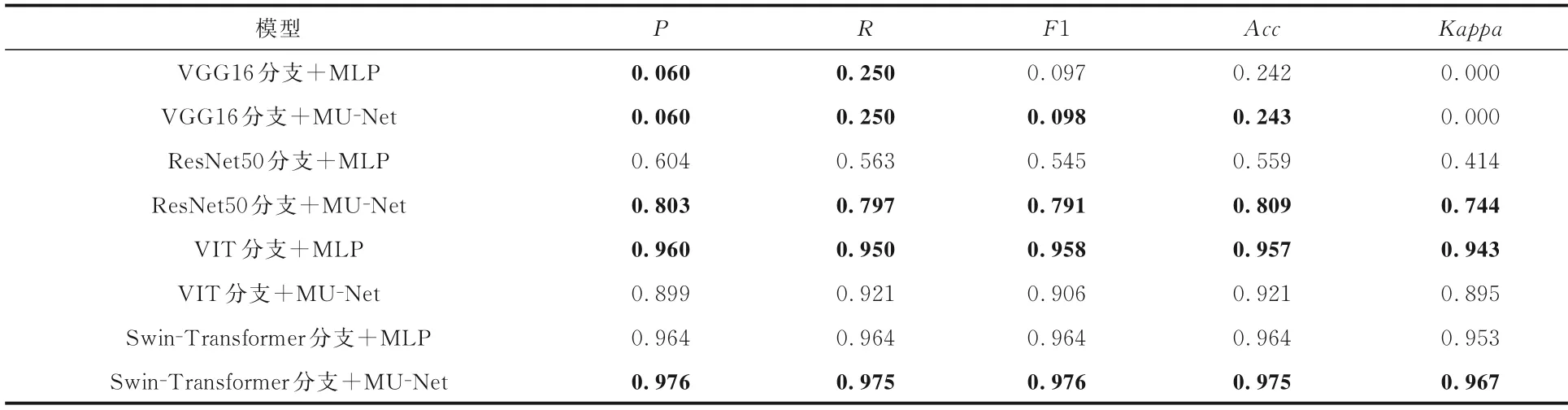
表9 MU⁃Net 和MLP 的对比实验结果Table 9 Comparison experimental results of MU⁃Net and MLP

表10 不同分支网络+MLP 针对具体类别的实验结果Table 10 Experimental results of different branch networks+MLP for specific classes
可以看出,除了以VIT 为分支网络的模型外,其余模型都是以MU‐Net 为分类器的效果更好,而VIT 网络和其他分支网络相比,需要更多的数据来训练才能发挥效果;再加上MU‐Net 比三层的MLP 参数量更多,也更难拟合,所以参数量少的MLP 反而效果更佳.综上,本文的MU‐Net 比MLP 结构的作用更显著.
3.3.5 MU⁃Net的消融实验MU‐Net利用U‐Net的跳跃连接思想,为了进一步探索MU‐Net 的作用,在SSM 模型的基础上对MU‐Net 中的跳跃连接进行消融实验,实验结果如表11 所示,不含跳跃连接的MU‐Net 的具体分类结果如表12 所示,表中黑体字表示结果最优.可以看出,带跳跃连接的MU‐Net 比不带跳跃连接的MU‐Net,各指标都有提升,证明跳跃连接在处理特征的升降维时起了重要作用,使浅层特征和深层特征得到了充分融合,并提炼出更抽象的高维特征用以分类.

表11 MU⁃Net 的消融实验结果Table 11 MU⁃Net ablation experiment
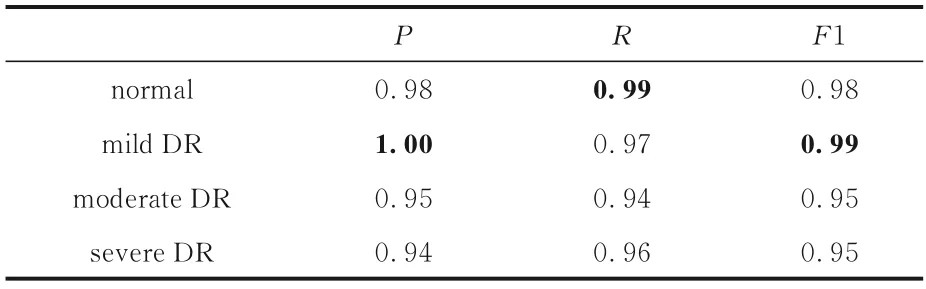
表12 MU⁃Net(无跳跃连接)针对具体类别的分类结果Table 12 MU⁃Net (no skip connection) classification results for specific classes
4 结论
糖尿病视网膜病变是糖尿病引起的重要并发症之一,现有医疗条件的简陋和专业医生的稀缺使患者很难得到及时诊断和治疗,导致患者视力严重下降甚至完全失明.虽然糖尿病视网膜病变是一种严重的慢性病,但可以通过常规筛查和有效治疗来预防,避免视力受损.随着机器学习和深度学习的发展,越来越多的分类模型被应用到医学图像领域来辅助医生进行诊断.本文提出一种孪生结构的网络模型SSM,能在少量数据上训练并对糖尿病视网膜病变图像的严重程度进行分类.在特征提取阶段,为了融合全局信息和局部信息产生层次化的特征表示,使用预训练的Swin‐Transformer 作为分支网络,利用权重共享的孪生结构充分学习不同类别之间的特征差异.在分类阶段,借鉴U‐Net 跳跃连接结构,自定义一个MU‐Net 分类器,融合浅层特征和深层特征用以分类.SSM 模型在Messidor 数据集上进行训练并测试,测试集上Precision 达0.976,Recall 达0.975,F1‐score 达0.976,Accuracy 达0.975,Kappa 系数达0.967,证明SSM 模型在糖尿病视网膜病变图像严重程度分类方面是有效的.未来会将孪生结构和MU‐Net 与更多的深度学习模型结合,并融入更多的先验特征以提高模型检测类别间细小差异的能力,使模型能够迁移到更多领域.
