基于多粒度信息编码和联合优化的篇章级服务事件序列抽取方法
2023-06-25程钦男莫志强曹斌范菁单宇翔
程钦男 ,莫志强 ,曹斌* ,范菁 ,单宇翔
(1.浙江工业大学计算机科学与技术学院,杭州,310023;2.浙江中烟工业有限责任公司信息中心,杭州,310009)
篇章级别的服务事件序列抽取是服务文本理解中的一项重要任务,旨在从给定的服务文本中发现服务事件之间的顺序序列关系,其中,以自然语言描述的形式对服务过程进行表示的文本称为服务文本.服务文本中的服务事件由服务事件触发词和服务事件论元构成[1],服务事件触发词标志着事件的发生,服务事件论元指的是参与者、时间、地点等服务事件属性,本文中服务事件由服务事件触发词来表示.篇章级别的服务事件序列由给定服务文本中的一系列服务事件基于事件发生的先后顺序排列构成,其任务表示如图1所示.图1左边是自然语言描述的服务文本,其中服务文本中的服务事件已经得到了标注;图1 右边是基于人工注释的篇章级服务事件序列:using →violating →faces →described →carry.

图1 服务事件序列抽取任务Fig.1 The task of service event sequence extraction
服务事件序列抽取相关的研究具有一定的现实应用价值.例如,事件序列可以帮助故事理解系统在任意的叙述背景下预测接下来会发生什么[2];医学临床诊断中抽取的事件序列可以帮助医生进行病情的诊断和预测[3];从菜谱或维修手册中抽取的事件序列可以帮助语音助手回答过程相关的问题,构建更加智能的语音助手[4].
目前,与服务事件序列抽取相关的研究工作可以分为过程抽取和事件时序关系抽取两类.过程抽取旨在从给定的文档中抽取流程图,流程图的节点表示事件或者动作,边表示其连接的两个节点之间的关系,存在顺序、选择、并行三种关系[4-5].事件序列可以看作事件之间只存在顺序关系的特殊流程图.在过程抽取的相关研究中,研究重点在于节点的抽取以及节点之间选择和并行关系的抽取,对于顺序关系,其认为和文本描述的顺序一致.在某些情况下这只是一个存在问题的假设,如图1 所示,基于人工注释得到的真实服务事件序列(using→violating→faces→described→carry)与文本描述的顺序(described →faces →violating →using →carry)不一致.
第二类相关工作是事件时序关系抽取,旨在判断事件对之间的时序关系[6-7].基于事件时序关系抽取的研究可以间接获得事件序列,其方法分两步:第一步是事件对之间的时序关系抽取,第二步是基于事件对,对时序关系抽取的结果构建事件序列.事件时序关系抽取研究往往关注同一个句子或者相邻句子中事件的时序关系识别,无法建模篇章级别的事件时序关系,需要在事件时序关系抽取的基础上做进一步研究.
针对以上两类相关工作存在的问题,本文提出一种篇章级别的服务事件序列抽取方法.该方法由三个模块构成:(1)多粒度上下文编码模块;(2)联合优化模块;(3)全局推理模块.多粒度上下文编码模块使用基于BERT(Bidirectional Encoder Representations from Transformers)[8]和BiLSTM(Bidirectional Long Short‐Term Memo‐ry)[9]的神经网络模型和多头注意力机制(Multi‐Head Attention Mechanism,MHA)[10]来获得服务文本中具有丰富语义信息的服务事件向量表示.联合优化模块通过联合训练Pairwise 局部任务和Listwise 全局任务挖掘服务事件的顺序序列关系.全局推理模块对联合优化模块输出的服务事件序列进行事件关系冲突消解,得到无冲突的服务事件序列作为输出.
目前尚没有公开数据集可直接用于服务事件序列抽取任务的评估,本文从基于事件时序关系抽取公开数据集TimeBank(TB)[11],AQUAINT(AQ)[12],Platinum(PL)[13]和MATRES[14]中抽取数据,构建了可用于该任务评估的数据集.实验结果证明了本文提出方法的有效性.
本文的贡献:
(1)提出篇章级别的服务事件序列抽取任务并给出了该任务的形式化定义,旨在从给定的服务文本中建模所有服务事件的顺序序列关系,得到一组按照服务事件发生顺序排序的服务事件集合.
(2)首次引入Pairwise 和Listwise 方法用于挖掘服务事件序列.
(3)基于事件时序关系抽取公开数据集TimeBank,AQUAINT,Platinum 和MATRES,构建了可用于服务事件序列抽取任务评估的数据集,并进行了实验验证和分析.实验结果证明了本文提出方法的有效性.
1 相关工作
与服务事件序列抽取相关的研究工作可以分两类,过程抽取和事件时序关系抽取.下面分别对这两类相关工作进行具体的介绍.
1.1 过程抽取过程抽取研究旨在从给定的文档中抽取流程图,流程图的节点表示事件或者动作,边表示其连结的两个节点之间的关系,存在顺序、选择、并行三种关系.事件序列可以看作事件之间只存在顺序关系的特殊流程图.现有的过程抽取研究主要可以分为基于规则的过程抽取方法研究[15-16]、基于专业资源或者自然语言处理工具的过程抽取方法研究[17-20]、基于传统机器学习的过程抽取方法研究[21-22]、基于神经网络或者强化学习的过程抽取方法研究[4-5,23].这些研究的重点在于节点,即动作或事件的抽取以及节点之间的选择和并行关系的抽取,对于顺序关系,其认为和文本描述的顺序一致.对于过程性文本,如菜谱、维修手册等,这种假设是成立的.但是对于非过程性文本,比如有些文本为了强调事件的结果会先描述事件的结果再描述事件的起因和经过,显然这种情况下事件真实发生的顺序与文本描述的顺序不一致.
1.2 事件时序关系抽取事件时序关系抽取研究旨在判断事件对之间的时序关系,基于事件时序关系抽取可以间接得到事件序列,即先得到文档中所有事件对的时序关系,然后基于事件对时序关系构建得到事件序列.现有的事件时序关系抽取研究主要可以分为基于人工特征的事件时序关系抽取研究[24-26]、基于语法或者句法规则的事件时序关系抽取研究[27-28]、基于神经网络的事件时序关系抽取研究[6-7].但是这些相关研究都关注同一句子或者相邻句子中的事件时序关系识别,无法建模篇章级别的事件时序关系,同时,也没有考虑跨句子级别的上下文信息.由于文档中的事件分散在各个句子中,显然跨句子级别的上下文信息有助于事件时序关系识别.
目前只有很少的研究利用跨句子级别的上下文信息进行事件时序关系抽取.Tourille et al[29]构建两个独立的分类器,一个用于句子内时序关系的识别,一个用于句子之间的时序关系识别.Cheng and Miyao[30]在文本依赖路径上使用BiLSTM 进行建模,并提出公共根的假设来链接跨句事件之间的依赖路径来引入跨句信息处理跨句事件对.尽管这些研究引入了跨句子级别的上下文信息但不能直接用于事件序列抽取任务,它们往往关注事件对之间时序关系的判断,在此基础上需要进一步研究建模文档中所有事件的顺序序列关系.
受相关工作的启发,本文提出一种篇章级别的服务事件序列抽取方法.针对过程抽取研究中事件的真实发生顺序与文本描述顺序不一致的问题,本文提出多粒度信息编码来结合篇章级别的上下文信息,丰富服务事件向量的语义表示,充分建模服务事件之间的上下文依赖关系.针对事件时序关系抽取研究中无法建模所有事件的顺序序列关系的问题,本文提出联合优化的方式,通过联合训练Pairwise 局部任务和Listwise 全局任务来充分挖掘所有事件的顺序序列关系.
2 模型方法
篇章级别的服务事件序列抽取旨在发现给定服务文本所有服务事件的顺序序列关系,具体地,本文给出服务事件序列抽取任务的形式化定义.给定服务过程文本d=(sent1,sent2,…,sentn)表示服务过程文本d包含n个句子,senti=表示第i个句子包含n个词,基于服务文本d的上下文信息预测得到该文本对应的服务事件序列标签y=(event1,event2,…,eventn),其中,eventi∈E,E表示文档d中的服务事件集合.
本文提出的篇章级服务事件序列抽取模型,称为基于多粒度信息编码和联合优化的服务事件序列抽取模型(Document‐Level Service Event Sequence Extraction Based on Multi Granularity Information Encoding and Joint Optimization),模型的架构如图2 所示,主要包含三部分:多粒度上下文编码模块、联合优化模块、全局推理模块.模型以服务文本作为基本输入单元,多粒度上下文编码模块使用基于BERT 和BiLSTM 的神经网络模型与多头注意力机制,获得富含丰富语义信息的服务事件向量表示;联合优化模块通过联合训练Pairwise 局部任务和Listwise 全局任务,挖掘服务事件之间的顺序序列关系;全局推理模块对联合优化模块输出的服务事件序列进行事件关系冲突消解,得到无冲突的服务事件序列作为输出.

图2 本文模型的架构图Fig.2 The overall framework of our algorithm
下面简单介绍事件冲突关系.基于间接的方式构建事件序列,即先对事件对之间的时序关系进行判断,再基于事件对时序关系构建事件序列.对于事件对时序关系,ei,ej表示服务文本中的任意两个服务事件,before 和after 表示两类事件顺序序列关系,(ei,ej,before)表示ei在事件序列中排在ej之前,(ei,ej,after)则相反.假定模型对事件对(ei,ej)(ej,ek)(ei,ek)作出如下时序关系判断:(ei,ej,before)(ej,ek.before)(ek,ei,before)不满足传递性约束,显然,基于时序关系(ei,ej,before)(ej,ek.before)可以推断(ek,ei,after).使用全局推理模块对存在冲突的事件对时序关系进行删除,该模块的具体实现方式在3.2.4 进行具体介绍.
2.1 多粒度上下文编码模块针对服务文本中描述的服务事件执行顺序与服务事件的真实发生顺序不一致导致事件序列抽取效果差的问题,需要充分考虑服务事件之间的上下文依赖关系,本文提出多粒度上下文编码模块(Multi‐Granularity Context Encoding Module,MGCE),通过聚合不同粒度(句子级别和跨句子级别)的词向量嵌入表示来获得富含上下文信息的服务事件向量表示,MGCE 模块包含下述几个部分.
2.1.1 字符级别的嵌入层MGCE 模块以服务文本作为基本输入单元,首先使用BERT 预训练语言模型对文本进行编码表示,使用BERT 是因为其编码输出能够建模词的语义信息,同时在各种自然语言处理下游任务中的表现较好,基于BERT 预训练语言模型可以获得每个单词的词嵌入向量表示.上述编码过程可以形式化为:
2.1.2 句子级别的嵌入层尽管基于BERT 预训练语言模型的输出向量包含一定的上下文信息,模型还需要获取特定于具体任务的上下文信息.鉴于BiLSTM 能够捕获句子中特定于具体任务的上下文信息,本文使用一个单层的BiLSTM模型对上一层的输出做进一步的编码表示.上述编码过程可形式化为:
其中,表示第i个句子中第n个词经由BiLSTM模型输出的词向量嵌入表示.
2.1.3 跨句子级别的嵌入层为了获得服务文本中不同句子之间服务事件的上下文依赖关系,本文使用MHA 来编码跨句子级别的上下文特征信息,使用MHA 是因为BiLSTM 模型的编码信息会随着序列长度的增加而产生信息丢失,而MHA 不受距离限制,可以编码长距离的序列信息.对基于BERT 预训练语言模型的输出使用MHA 进行再编码,获得跨句子级别的上下文特征表示,上述过程可形式化为:
其中,表示第i个句子中第n个词经由MHA 层输出的词向量嵌入表示.
2.1.4 特征融合层基于上述字符级别的嵌入层、句子级别的嵌入层以及跨句子级别的嵌入层输出,可以获得不同粒度的词向量表示,但是考虑到不同特征的词嵌入向量表示对最后的服务事件时序关系判断任务的贡献是不同的,本文没有采用简单的相加或者拼接的方法,而是采用门机制对不同粒度的特征信息进行加权相加.定义门机制如下:
其中,g表示门机制的注意力权重向量;W和b表示需要学习的权重和偏置项参数,用来计算得到注意力权重向量g;⊙表示元素智能相乘法;表示经由特征融合层后第i个句子中第n个词的词向量嵌入表示.
2.2 联合优化模块经由多粒度上下文编码模块可以获得服务文本中富含上下文特征信息的词向量嵌入表示,本文采用和MATRES[11]一样的处理方式,用事件触发词来表示事件,即将事件触发词对应的词向量表示作为事件向量表示.接下来构建联合优化模块去挖掘服务事件之间的顺序序列关系,如图2 所示,联合优化模块包含两个子任务:Pairwise 局部任务和Listwise 全局任务.
2.2.1 Pairwise 局部任务Pairwise 局部任务通过间接的方式构建得到服务事件序列:首先获得服务文本中所有两个服务事件对的时序关系,再基于事件对时序关系构建得到篇章级服务事件序列.本文使用Pairwise 局部任务为模型提供一个局部视角,判断事件之间的相对顺序关系.
E表示服务文本d对应的服务事件集合,ei和ej表示服务事件集合E中的任意两个服务事件.Pairwise 局部任务的输入为服务文本中的任意服务事件对(ei,ej),该事件对由服务事件集合中的服务事件随机两两组合得到;输出为事件对对应的顺序序列关系(ei,ej,before)或(ei,ej,after).Pairwise 局部任务本质上是一个分类任务,所以使用两层的多层感知机(Multi‐Layer Perceptron,MLP)神经网络作为分类模型.对于每个服务事件对,将基于MGCE 模块输出的事件词向量表示进行拼接,然后将拼接得到的向量输入MLP 模型,得到事件对顺序序列关系的预测概率.上述过程可以形式化为:
其中,W1,W2和b1,b2分别表示权重矩阵和偏置向量,σ表示sigmoid 激活函数,tanh 表示双曲正切激活函数.rei,rej表示服务事件ei,ej经由MGCE模块得到事件词的特征向量表示,r表示事件对(ei,ej)的顺序序列标签且r∈{before,after},p(r|ei,ej)表示事件对(ei,ej)的顺序序列关系的条件概率.Pairwise 局部任务的损失函数定义为:
其中,xn,yn分别表示第n个训练事件对以及其对应的顺序序列标签,表示模型给出的顺序序列关系的预测值,I(⋅),θL分别表示指示函数和参数,Dn表示服务文本的数量.Pairwise 局部任务的训练目标是最小化损失函数L(θL).
2.2.2 Listwise 全局任务受Cao et al[31]的启发,我们意识到,虽然Pairwise 局部任务可以通过间接的方式构建得到服务事件序列,但是该方法忽略了事件序列建模是基于服务事件列表这一事实,仅仅基于Pairwise 局部任务构建事件序列会让模型的学习目标变成最小化服务事件对顺序序列关系分类的误差,而不是最小化服务事件序列排序的误差,这会导致模型的效果变差.为此,本文额外提出了Listwise 全局任务,该任务的思想与学习排序中的ListNet[31]相似.首先,训练得到一个打分模型,由模型对每个服务事件进行打分,再基于模型给出的事件分数进行排序得到最终的服务事件序列.本文同样使用两层的感知机神经网络作为打分模型,将服务文本中的每个事件经由MGCE 层得到的特征向量表示输入打分模型,得到该事件对应的分值.上述过程可以形式化为:
其中,W1,W2和b1,b2分别表示权重矩阵和偏置向量,re表示服务事件e经由MGCE 模块得到的特征向量表示.本文使用smoothL1损失函数,其定义如下:
2.2.3 联合训练在模型的训练阶段,采用联合训练的方式训练Pairwise 局部任务和Listwise 全局任务.定义联合损失函数如下:
其中,λ是超参数,用来维持Pairwise 局部任务损失L(θL)和Listwise 全局任务损失G(θG)之间的平衡.
2.2.4 全局推理模块在测试阶段,Listwise 全局任务可以在整个事件序列中拟合事件的排序值,然后结合Pairwise 局部任务的输出来获得完整的事件序列.但是,基于Pairwise 的方式获得的事件序列存在无法满足传递性约束的冲突,本文使用全局推理模块来进行事件关系冲突消解.全局推理模块使用的是整数线性规划(Integer Linear Programming,ILP),该方法被许多研究人员用于解决冲突,强化全局一致性[32],而本文仅用于处理传递性约束.
首先,设定表示一个二元指示变量,当且仅当模型对事件对(ei,ej)的顺序序列关系预测为r∈R时其值为1,其中,R表示事件对顺序序列标签集合R={before,after}.例如表示ei在事件序列中排在ej之前,表示模型对事件对(ei,ej)顺序序列关系预测为r的条件概率输出.为了排除存在冲突的事件对关系预测的影响,获得全局最优的预测结果,本文定义如下的整数线性规划的目标函数:
需要满足如下的约束条件:
约束条件(13)表示在所有事件对顺序序列关系中只能满足一个关系,当其中一个事件对关系的二元指示变量值为1时,其余事件对关系的二元指示变量值为0.约束条件(14)表示事件对(ei,ej)的顺序序列标签为r1且事件对(ej,ek)的顺序序列标签为r2时,事件对(ei,ek)的顺序序列标签r3必须满足此约束条件.
3 实验
3.1 实验参数设定在模型的训练阶段,使用BERT 预训练语言模型对服务文本进行编码表示,最大序列长度设置为256,batch_size 设置为8.使用BiLSTM 模型、多头注意力机制进一步编码时,BiLSTM 模型的输入维度设置为768,hidden_size 设置为64,多头注意力机制的head 参数设置为8.训练过程中使用随机梯度下降优化算法训练模型,学习率设置为0.0006,为了防止过拟合引入dropout 机制,dropout 比率设置为0.5.
3.2 实验数据集目前还没有公开数据集可以直接用于从服务文本中提取服务事件序列,本文基于事件时序关系,抽取公开数据集TimeBank(TB),AQUAINT(AQ),Platinum(PL),MA‐TRES 中的数据,构造一个可以用于服务事件序列抽取任务评估的数据集.该数据集由三列内容构成,如表1 所示,分别表示文本标题、文本内容以及该文本对应的服务事件序列标签.TB,AQ和PL 三个数据集中包含了许多的新闻文档,并且文档中包含的事件词已经被标注.MATRES数据集中标注了上述三个数据集每个文档中事件对的时序关系,基于MATRES 提供的事件对时序关系标注可以构建得到TB,AQ,PL 三个数据集中每个文档对应的事件序列标签,以此作为新的数据集来评估事件序列抽取任务,相关数据集的统计信息如表2 所示.对于该数据集的标注过程,选择TB,AQ,PL 三个数据集中的全量数据进行人工标注,由两组研究生分别对相同的文档基于MATRES 数据集提供的事件对时序关系标签标注其对应的事件序列.如果人工标注的事件序列结果存在差异,则双方讨论得到一致的结果,此标注过程可以确保本文构建数据集的准确性.

表1 本文构造的数据集信息Table 1 The information of the dataset constructed in this paper

表2 相关数据集的统计信息Table 2 The statistics of the related dataset
实验过程中,TB 和AQ 为训练数据集,PL 为测试数据集,同时,从训练集中随机选取20%的数据作为验证集用来调整超参数.
3.3 评价指标为了与已有的相关研究进行对比,从两个角度对实验结果进行评估.具体如下.
(1)从局部角度对实验结果进行评估,对应Pairwise 局部任务,该任务本质上是关于事件对顺序序列关系的二分类任务.采用准确率(Accu‐racy)、精确率(Precision)、召回值(Recall)和F1‐score 作为Pairwise 局部任务的评价指标.
(2)从全局角度对实验结果进行评估,对应Listwise 全局任务.传统的排序模型通常根据归一化累计折损增益(Normalized Discounted Cu‐mulative Gain,NDCG)和平均精度(Mean Aver‐age Precision,MAP)进行评估,但这两个评价指标都关注排名前k位的文档,这对于文档检索任务来说是有意义的,但不适用于事件序列抽取任务,因为本文关注的是所有事件的顺序序列关系[3].采用最长公共子序列(Longest Common Subsequence,LCS)作为Listwise 全局任务的评价指标,字符串的子序列指的是从原始字符串中删除一些字符(也可以不删除)但是不改变其他字符相对顺序的新字符串.该评价指标先计算模型给出的事件序列预测结果与其真实结果的最长公共子序列,再计算最长公共子序列的长度占其真实事件序列长度的百分比.假定模型给出的预测结果为ypred,真实结果为ytrue,该评价指标对应的计算形式如下:
3.4 基线方法选择以下方法作为基线方法.
(1)排序模型(文本顺序)[13]:该方法基于事件真实发生顺序与文本描述顺序一致的假设,基于事件在文本中出现的顺序来对事件进行排序.使用该基线方法是想通过对比实验来证明进行事件序列抽取的必要性.
(2)基于BiLSTM 的Pairwise 方法[5]:在事件时序关系提取相关研究中,BiLSTM 模型被大量使用且取得了不错的效果.选取该方法作为基线方法,且在模型实现上与Han et al[5]相同.
(3)学习排序模型ListNet[3]:Jeblee and Hirst[3]基于排序模型ListNet,从医学临床文本中生成临床事件的时间线,即事件序列.为了对比实验的公平性,本文没有使用额外的语言学特征,特征表示是基于BiLSTM 模型完成的.
3.5 实验结果分析
3.5.1 实验1:从局部角度验证模型的性能局部视角的对比实验结果如表3 所示,表中黑体字表示最优性能.由表可见,本文方法的局部评价指标均优于基线方法:与Text order 相比,本文模型的Accuracy 提高15.64%;与ListNet 相比,本文模型的Accuracy 提高8.23%;与基于BiLSTM的pairwise 方法相比,本文模型的Accuracy,Pre‐cision,Recall,F1‐score 分别提高3.09%,4.47%,4.01%,4.24%.证明了本文方法的有效性.

表3 局部视角对比实验的结果Table 3 Comparative experimental results of the local perspective
3.5.2 实验2:从全局角度验证模型的性能除了局部角度,本文还从全局角度验证了模型的性能.全局视角的对比实验结果如表4 所示,表中黑体字表示结果最优.由表可见,本文方法的全局评价指标也均优于基线方法.

表4 全局视角对比实验的结果Table 4 Comparative experimental results of the global perspective
3.5.3 实验3:消融实验为了验证模型中不同模块的作用,还进行了消融实验,实验结果如表5和表6 所示,表中黑体字表示结果最优.在多粒度上下文编码模块中不使用BiLSTM 模型,即不考虑句子级别的上下文信息,无论是从局部评价指标还是全局评价指标来看,模型的性能都出现下降.同理,在多粒度上下文编码模块中不使用多头注意力机制,即不考虑跨句子级别的上下文信息,模型的性能也出现了下降.这两组消融实验的结果进一步证明了多粒度上下文编码模块的必要性,即在事件序列建模时结合多粒度的上下文信息能够提高模型的性能.
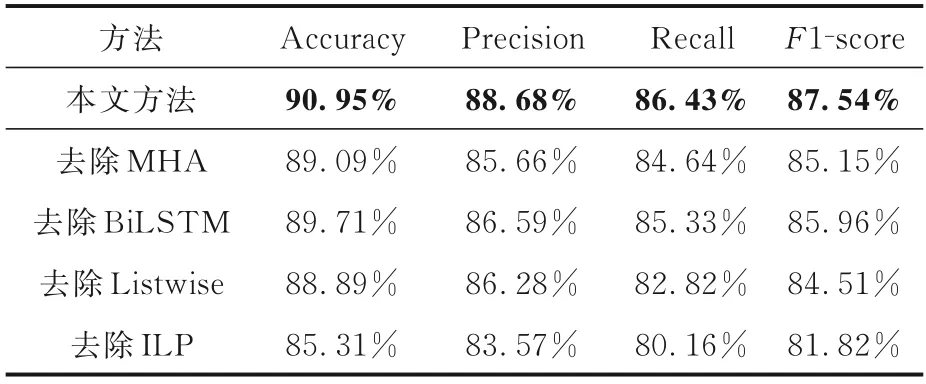
表5 局部视角的消融实验结果Table 5 Ablation experiment results from local per⁃spective

表6 全局视角的消融实验结果Table 5 Ablation experiment results from global per⁃spective
本文还对比了多任务联合优化和单任务训练方式下的模型性能,其对应的实验结果也如表5和表6 所示,表中黑体字表示结果最优.在模型的训练阶段去除Listwise 全局任务,只训练Pairwise局部任务,无论是从局部评价指标还是全局评价指标来看,模型的性能均出现了下降,进一步证明多任务联合优化的方式可以更好地建模事件之间的顺序序列关系.
为了验证全局推理模块的有效性,本文对比了是否采用ILP 对模型性能的影响,实验结果也如表5 和表6 所示,表中黑体字表示结果最优.由表可见,不采用ILP时,无论是从局部角度还是全局角度来看,模型性能均出现了不同程度的下降,可能是因为模型给出了不符合事件顺序关系传递性约束的预测,没有使用ILP 进行事件关系冲突消解不符合传递性约束的事件顺序关系,使模型的性能出现了下降.
4 结论
本文提出了篇章级别的服务事件序列抽取任务及其形式化定义,旨在从给定的服务文本中建模所有服务事件的顺序序列关系,得到一组按照事件发生顺序排列的服务事件集合.对于该任务,本文提出一种基于多粒度信息编码和联合优化的篇章级服务事件序列抽取模型.首先,使用多粒度信息编码模块学习,得到富含上下文特征信息的服务事件向量表示,再利用联合优化模块提取服务事件顺序序列关系,最后,通过全局推理模块进行事件冲突消解得到篇章级别的服务事件序列.为了评估本文提出的方法,从基于事件时序关系提取公开数据集TimeBank,AQUAINT,Platinum,MATRES 中抽取数据,构建了可用于篇章级服务事件序列抽取任务评估的数据集,实验结果证明本文提出的方法的有效性.未来将进一步丰富服务事件序列数据集,或引入常识性知识库来进一步提升篇章级服务事件序列抽取模型的性能.
