基于子事件的对话长文本情感分析
2023-06-25杨京虎段亮岳昆李忠斌
杨京虎 ,段亮* ,岳昆 ,李忠斌
(1.云南大学信息学院,昆明,650500;2.云南大学云南省智能系统与计算重点实验室,昆明,650500)
情感分析旨在通过计算机技术对文本的主客观性、情绪、极性进行挖掘,对文本的情感倾向作出分类判断[1].通信、电商、医疗等行业存在大量客服与客户的对话场景,随之出现了如服务满意度分析、智能代理和意图识别[2-3]等应用需求,其核心任务之一为对话长文本情感分析.然而,现有的研究集中在短文本情感分析任务,如百度AI情感分析的文本接收窗口限制在256 个字以内.针对对话长文本的情感分析,实现整个对话长文本的情感分类,仍有待深入研究.
表1 展示了一组通信业务的对话,可以看出,客服和客户在多轮对话中存在很多与文本情感无关的内容,但现有方法获取对话文本的核心情感存在困难.前两轮对话中客户表现出消极的情感倾向,而在最后一轮对话中,客户的情感倾向转变为积极.此外,客服在整体对话过程中表现出较为积极的情感,而客户则发生了较大的情感转变.

表1 一个通信业务对话的示例Table 1 A dialogue of communication business
因此,与传统情感分析任务不同,对话长文本情感分析任务存在如下挑战:(1)对话双方存在多重情感,集成困难.由于对话双方本身可能具有不同的情感,随着对话的进行,其情感还会发生变化,因此将对话双方不同的情感进行集成来确定整个文本的情感倾向,有一定的难度.(2)对话长文本的情感分析任务精度低.对话长文本篇幅长,存在大量噪声,使文本的每一部分内容对于推断整个文本情感倾向具有不同的价值,现有的方法对文本截断或随机采样,不能有效地解决该问题.(3)主流神经网络模型在短文本情感分析任务上表现优异,但受到输入文本长度的限制,对长对话文本情感分析任务的精度欠佳.
以表1 为例,最初是“客户质疑欠费”,发展到“客户要求更换套餐”,最后“客户发现误解了资费情况并致歉”,一条对话长文本由多个随时间演化的相关子事件组成.子事件是文本重要内容的句子集合,也是文本内容的集中体现[4].通过抽取子事件,将长文本转化为短文本,在保留文本重要特征的同时也解决了长文本冗余的问题.因此,本文提出子事件交互模型(Topic Subevents Interac‐tion,TSI),通过动态滑动窗口分割对话长文本,从对话长文本中抽取子事件,利用基于主题的模型LDA 获取各窗口文本的主题分布,以此度量子事件的演化过程.
预训练模型是在大规模无监督语料上训练的,具有强大的语义表示能力.百度提出ERNIE(Enhanced Language Representation with Informa‐tive Entities)[5],对BERT[6]进行改进,将句子中的短语、实体等语义单元掩码,重点学习对话类数据,将ERNIE 作为嵌入模型能更好地对对话文本建模.循环卷积神经网络(Recurrent Convolution‐al Neural Networks,RCNN)[7]能更好地获取文本上下文特征,兼有CNN 无偏模型的优点,因此,本文提出ERNIE‐RCNN 模型学习子事件的情感特征.针对对话双方具有的多重情感使子事件情感集成困难的问题,本文提出一种识别情感主体的方法来确定整个对话长文本的情感倾向.
在真实的移动运营商的通讯业务数据上的实验结果表明,本文提出的TER(Topic Sub‐events Interaction with ERNIE‐RCNN)的精确率、召回率与F1 均优于现有模型.值得注意的是,虽然TER 是基于移动通讯应用场景提出的,但微信、淘宝、论坛等媒体都有类似的对话长文本数据,因而有广阔的应用前景.
1 相关工作
1.1 长文本情感分析Pappagari et al[8]将长文本分割后输入改进的BERT 模型,获取文本特征进行分类.Xu et al[9]提出CLSTM 模型来获取长文本的整体语义信息,通过一种缓存机制存储情感特征.上述方法在长文本情感分类任务上取得了较好的效果,但没有考虑实际场景下长文本的每部分内容在推断文本情感倾向上具有的不同价值,如何在不陷入某些局部无关的文本下获得有效的核心情感是值得注意的问题.Sheng and Yu‐an[10]设计新的截断方式,将文本标题、关键词等特征进行拼接,使用多个模型联合学习.Cheng et al[11]对每篇文章提取两个主题句,结合标题等文本特征进行加权计算,最后使用投票机制完成情感分类.这些研究虽然注意了长文本的冗余性,但在建模时损失了大量文本特征,依赖带标题的文本,不适合对话长文本的情感分析.
1.2 对话文本情感分析Hazarika et al[12]考虑对话中用户情绪自我依赖关系及对话者之间的依赖关系,提出交互式对话神经网络模型,建模对话者的情感.Shen et al[13]提出分层匹配神经网络,设计双向注意力机制捕捉对话双方的情感信息并互相预测.Wang et al[14]研究通过增强的双向注意力网络,解决了通过单一问题或答案来推断情感会比较困难的问题.Hu et al[15]建模对话时人的认知与推理思维,提出语境推理网络,通过感知和认知两个阶段学习上下文信息,可以有效地获取文本情感特征.Zhu et al[16]提出以话题驱动且包含知识的Transformer 模型,解决对话文本中不同主题下相同文本具有不同情感的问题.上述研究主要基于对话之间的上下文联系进行建模,但随着对话轮次的增加,文本中的噪声、对话中双方情感的不同及变化导致文本最终分类困难的问题未能解决.
1.3 子事件检测与抽取相关研究主要分三类:命名实体识别结合特征工程、事件话题发现和文摘生成.命名实体识别结合特征工程通过对文本抽取关键词,并根据修辞状态、位置信息等来衡量句子重要性,但这类方法在建模时损失了大量情感特征,抽取的子事件缺少情感表达.周楠等[17]总结事件话题,发现基于文档和词两个角度,算法抽取的子事件存在理解性弱、不确定性高等问题.文摘生成分文本分割算法和文本摘要算法.Memon et al[18]采用文本分割实现文本不同主题的分割,但仍存在文本冗余的问题.采用文本摘要抽取子事件时,主要有生成式和抽取式两种方法,但生成式方法不适合长文本任务[19],抽取式方法无法保证子事件的连贯性与理解性.
2 TER 模型
TER 主要由输入层、嵌入层、子事件抽取层、特征学习层、特征融合层及输出层构成,模型的总体架构如图1 所示.Word2vec 与ERNIE 分别获取输入文本的静态词向量和动态词向量,静态词向量用于TSI 抽取子事件,动态词向量用于RCNN 学习文本的情感特征.在特征融合层,将前一层输出的情感特征与子事件的时序和主题特征进行融合,得到最终的情感表达,在输出层得到最终分类结果.

图1 TER 模型的整体架构图Fig.1 The structure diagram of TER model
2.1 输入层
定义1对话长文本d同时具有对话文本和长文本的特点,一个对话长文本d由二元组(D,Pd)表示,其中,D是对话长文本的内容,Pd是对话长文本的对话双方.
对于输入d={t1,t2,…,tn},ti(1 ≤i≤n)表示对话长文本的第i个句子,TER 在输入层对其进行不同的预处理,再分别输入Word2vec和ERNIE.
2.2 嵌入层嵌入层使用Word2vec 与ERNIE分别获取输入文本的静态词向量和动态词向量.静态词向量用于TSI 确定对话长文本的主题核心词,在上下文中主题词含义不会改变,且静态词向量和动态词向量相比,可以减少模型抽取子事件的时间.而学习对话长文本中的情感特征时,需考虑同一词在不同上下文中具有不同情感倾向的问题,因此使用动态词向量用于RCNN 学习文本的情感特征.
ERNIE 由文本编码器(T‐Encoder)和知识编码器(K‐Encoder)两个模块组成.文本编码器捕获输入文本的词法和语义信息,知识编码器将知识图谱中的实体信息进行嵌入和融合.
最后,使用词嵌入模型Word2vec 在数据集上进行预训练,得到子事件抽取层的词来嵌入输入,作为嵌入层的第二个模型参数.
2.3 子事件抽取层为了解决文本冗余造成的对话长文本情感分析任务精度低的问题,提出TSI 从对话长文本中抽取子事件,在降低文本冗余度的同时保留文本关键特征,以子事件的演化过程代替整个对话长文本.
注意,在实际应用场景下,子事件是由对话双方在短时间内密切讨论而形成,排除日常对话中口语寒暄的影响,以对话者之间的一问一答作为一轮对话.定义子事件应多于两轮对话.
定义2子事件s由四元组(Ps,Cs,Ts,Ds)表示,其在三轮及以上对话中描述了同一件事情.其中,Ps表示子事件的参与用户;Cs表示子事件主题信息的核心词集合;Ts表示子事件主题信息的核心词集合,记录该子事件在整个文本中的时序信息;Ds表示对该子事件内容的描述.
TSI 基于LDA 主题模型,通过动态滑动窗口抽取子事件.LDA 分为三层贝叶斯概率生成模型,由“文档‐主题‐词”构成,通过文本主题概率分布选择一种主题,再从该主题对应的词概率分布中抽取主题词.相关符号及其含义见表2.

表2 符号及含义Table 2 List of notations
TSI 的建模过程如下:
(1)利用动态滑动窗口分割文本.滑动窗口边界的计算方法如下,初始为1.
(2)由LDA 主题模型获取当前窗口下的主题词分布.
(3)文本相似性度量.设两个滑动窗口下的主题词分布分别为Z1,Z2,分别存在于Z1和Z2中的主题词为A和B,对应的词向量分别为和,由式(5)计算Simcos:
其中,ai,bi分别代表,的各个分量值.
(4)子事件检测.当δ大于等于给定阈值∂时(本文取∂=4,即在最小滑动窗口的基础上至少还进行了两轮对话)子事件成立,根据式(6)更新Wa;如果在本次滑动窗口下未检测到子事件,则Wa自增1.
通过动态滑动窗口分割文本、文本主题推断、文本相似性度量、子事件检测这四个主要步骤,可以生成文本子事件,具体步骤见算法1.

若算法1 未抽取到子事件,则由算法2 选择与文本主题最相关的子事件替代.

算法1中,窗口划分部分(第4~7 行)的时间复杂度为O(u),子事件检测部分(第8~20 行)的时间复杂度为O(u2),因此,算法1 的时间复杂度为O(u2n).由于实际中Z的长度远小于n,算法2的时间复杂度为O(un).
2.4 特征学习层RCNN 通过双向循环神经网络捕获文本上下文信息,利用最大池化层决策文本中的关键情感特征.本文使用长短期记忆网络(Long Short‐Term Memory,LSTM)替换RCNN中的RNN,LSTM 避免了RNN 模型在反向传播时的梯度消失和梯度爆炸问题,能更好地捕捉子事件长距离语义关系.
RCNN 结合文本的上下文来表示一个字,使用双向LSTM 捕获字的特征.例如,设子事件抽取层输出的子事件通过式(7)和式(8),将S输入双向LSTM 中学习输入文本的上下文语义,通过正反两个方向的LSTM 输出特征Y1,Y2;根据式(9)和式(10),将Y1,Y2进行拼接并通过激活函数tanh 得到特征Y3;最后,将Y3映射到与预设情感极性空间维度相同的空间,进行最大池化,得到该子事件对话双方的情感极性分数Y4=(Q0,Q1,Q2),Qi表示在情感极性i上的情感分数.
2.5 特征融合层从一条对话长文本中可能抽取出多个子事件,而每个子事件对于推断整个文本的情感倾向具有不同的价值.考虑子事件的主题特征和时序特征对整个文本情感倾向的影响,通过两种方式对子事件情感分数Y4进行更新.
(1)若子事件的主题与全文的主题相似,则该子事件体现了全文的中心思想,与整个文本联系更加紧密,因此该子事件对整个文本情感倾向的影响程度更大.因此,将Y4更新为Y5:
其中,主题相似性通过式(5)计算,Ns表示从该对话长文本中抽取的子事件的总数,Nst表示与该对话长文本主题相似的子事件的数量.
(2)当用户情感发生变化时,用户的最终情感极性更能代表用户情感.如式(12),如果Wb与n的比值大于给定阈值ρ(本研究取ρ=0.7),则该子事件的位置处于整个对话的结束部分,对整个文本情感倾向的影响程度更大.将该子事件的情感分数Y4更新为Y6,如式(13)所示:
其中,nsr表示用户情感波动时的情感极性数量.
为了解决对话双方具有不同情感极性的问题,在特征融合层通过确定情感主体来完成整个文本的情感分类.下面给出情感波动和情感主体的定义.
定义3情感波动I指同一用户在两个及以上子事件s中表现的不同情感极性,由二元组(Ps,IP)表示,其中,Ps表示s的参与用户,IP表示Ps在s中的情感极性.
用户情感波动的程度可以通过其对应的情感极性数量与情感变化情况来衡量.设对话双方都出现了情感波动,若其中一个用户在子事件中表现出更丰富的情感极性,则情感波动更大;若双方情感极性数量一致,则情感极性转变更大的用户情感波动更大.
定义4情感主体G指子事件s中具有更强情感特征的用户,由三元组(Ps,I,GQ)表示,其中,Ps表示s的参与用户,I表示Ps的情感波动情况,GQ表示Ps的情感分数.
模型选择情感波动的用户作为情感主体,若对话双方未出现情感波动,则选择情感分数更大的用户作为情感主体,将其作为特征融合层的输出y.
2.6 输出层将y转换为情感极性的类别,得到对话长文本最终的情感分析结果.
在模型训练过程中,本文联合学习TSI 子事件抽取模型和RCNN 特征学习模型,提升TER的分类性能.因此,损失函数分两部分:第一部分是TSI 的损失函数,如式(14)所示;另一部分是RCNN 的损失函数,如式(15)所示.
其中,D表示语料库,即M篇文章的集合;α为生成每篇对话长文本文本主题的多项式分布的Dirichlet 分布的参数;β为生成每篇文本中某个词的多项式分布的Dirichlet 分布的参数;θd是第d篇文本的主题分布,即多项式分布的参数;wdn是第d篇文本第n个词;zdn是第d篇文本第n个词的主题;P为样本总数;O为情感类别数.
3 实验
3.1 实验环境与数据硬件:Intel i9‐10850 K 处理器,NVIDIA TITAN V‐12 G.软件:Windows 10 系统,所有算法使用Pytorch 实现.
采用移动运营商通讯业务的客服客户对话数据集mobile_communications(简称mc),包含移动运营商的客服营销、客户咨询和客户投诉的20000 条对话长文本数据.每条文本有500~5000字,将其分为mc1,mc2 和mc3 三部分,用于不同的实验测试.其中,mc2 包含800 条数据,用于子事件测试;mc1 和mc3 的描述信息如表3 所示,每条文本使用人工标注情感标签,分为无情感、积极和消极三种.
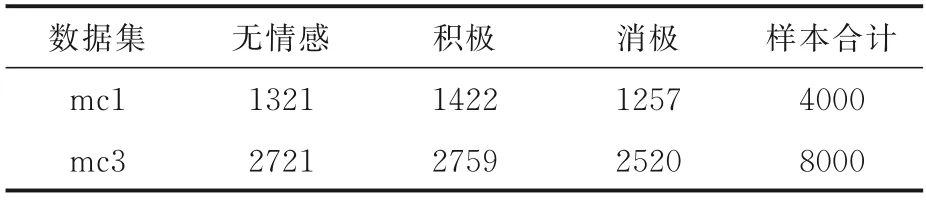
表3 实验使用的数据集描述信息Table 3 Description of datasets used in experiments
3.2 对比模型选择九个基线模型(https:∥github.com/649453932)与本文TER 进行情感分析对比实验,每个模型都使用相同的超参数.为了公平起见,对于初始学习率,各特征模型(TextCNN,TextRNN,FastText,DPCNN,Tex‐tRCNN)设为1e-3,类Transformer(Transform‐er,TodKat)模型及预训练模型(BERT,ERNIE)设为5e-5;所有模型的文本最大长度为512,dropout 为0.5.采用精确率、召回率和F1 为评价指标,最终结果为三个指标在三种情感极性分类上的宏平均值.
(1)TextCNN[20]:使用多个卷积提取多种特征,再通过最大池化层保留最重要的特征信息.卷积核大小分别为(2,3,4),每个尺寸的卷积核个数为256.
(2)TextRNN[21]:使用双向LSTM 捕捉文本长距离语义,引入多任务学习机制.每层LSTM包含128 个神经元.
(3)FastText[22]:使用分层Softmax 降低分类器的计算代价,使用N‐gram 保存近距离词序信息.隐藏层包含256 个神经元.
(4)DPCNN[23]:使用深度残差网络结构,在采样时固定特征的数量,获取文本的长距离特征.卷积核大小为3,卷积核个数为256.
(5)TextRCNN[7]:使用双向循环神经网络来最大程度地捕获上下文信息,再使用最大池化层决策文本中的关键特征.本文使用两层LSTM,每层LSTM 包含256 个神经元.
(6)Transformer[24]:使用多头注意力机制学习特征,解决文本中的长距离依赖问题.隐藏层包含768 个神经元.
(7)TodKat[16]:采用话题驱动与知识感知的Transformer 结构,预测文本每一个句子的情感倾向.本文采用投票机制预测最终情感分类结果.
(8)BERT[6]:采用双向Transformer 结构,结合掩码策略捕捉文本的词向量.隐藏层包含768个神经元.
(9)ERNIE[5]:在大规模语料上预训练并融合多源数据知识.隐藏层包含768 个神经元.
选择三种方法与TER 进行子事件抽取对比实验.从信息性、准确性和理解性三方面对四种方法进行打分和排序[25],最好为1,最差为4,将排序的算数平均值作为子事件生成性能的指标.
(1)基于特征评分的方法:综合考虑文本中句子的位置、关键词、词频等信息来构成文本子事件.
(2)TextRank:是基于图的文本排序算法,对文本构建拓扑结构图,通过抽取文本中重要度较高的句子构成文本子事件.
(3)基于序列标注的方法:使用GitHub 开源项目Jiagu(https:∥github.com/ownthink/Jiagu).Jiagu 以Bi‐LSTM 等模型为基础,在大规模语料上训练而成,通过对文本中句子的序列进行标注来抽取文本子事件.
3.3 各模型对对话长文本的情感分析实验使用mc1 测试TER 和九个基线模型在对话长文本上情感分类的性能,实验结果如表4 所示,表中黑体字表示性能最佳.
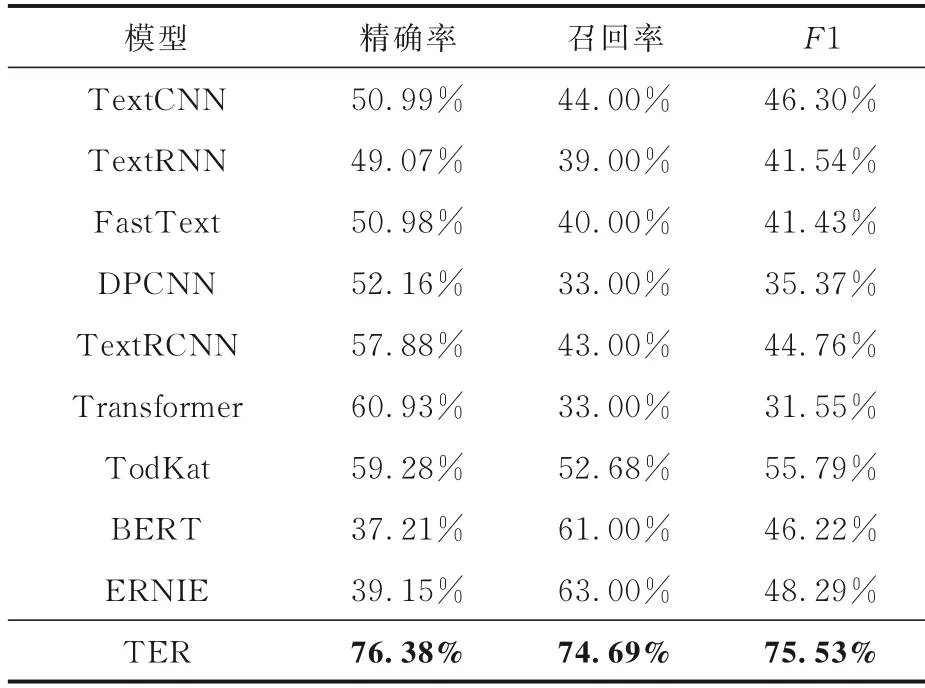
表4 各模型在对话长文本情感分析任务上的性能Table 4 Experimental results of sentiment analysis on long dialogue texts
对比各基线模型,TER 的三个评价指标均为最佳,因为其他模型在建模时损失了大量文本特征,表现较差.而TER 通过对文本抽取子事件,在降低文本冗余的同时也保留了文本的重要特征.
3.4 子事件抽取实验使用mc2 数据集测试TSI 与对比方法抽取子事件的性能,在同等条件下的评价结果如表5 所示,表中黑体字表示性能最优.由表可见,TSI 的三个评价指标都排名第一.TSI 满足本文对子事件的定义,可读性较好,所以其准确性和理解性最优.由于判断子事件的信息是否重要存在一定的客观性,评价时还需考虑子事件的文本长度,因此TSI 的信息性和对比方法相比,差别不大.

表5 TSI 和对比方法在mc2 数据集上的子事件评价指标对比Table 5 Experimental results of TSI and other methods with subevents on the mc2 dataset
3.5 消融实验为了验证TER 各模块对对话长文本情感分析任务的影响,设计两组消融实验.
(1)子事件情感分析实验:验证子事件抽取层对TER 在对话长文本情感分析任务上的有效性.TER 与九个基线模型在mc3 数据集上的对比实验结果如表6 所示,表中黑体字表示性能最优.

表6 TER 和九个基线模型在mc3 数据集上的子事件情感分析任务的性能对比Table 6 Experimental results of TER and nine base⁃line models with subevents sentiment analysis on the mc3 dataset
(2)预训练模型嵌入的实验:验证预训练模型作为嵌入层对TER 在对话长文本情感分析任务上的有效性.选择在情感分析实验中表现较好的特征模型TextCNN,DPCNN 和TextRCNN 作为代表,将BERT 和ERNIE 嵌入,对比实验的结果如表7 所示,表中黑体字表示性能最优.

表7 预训练模型嵌入实验结果对比Table 7 Experimental results of pretrained embedding
子事件决定整个对话长文本的情感倾向,由表6 可知,TER 在子事件情感分析实验中性能最佳,和表现较好的BERT,ERNIE,TextRCNN 相比,TER 的三个评价指标约高2%.与表4 对比可以发现,各对比模型对子事件的情感分析性能明显优于对话长文本,但TER 在进行对话长文本情感分析时仍保持了较高的性能,证明了子事件抽取层在TER 对对话长文本情感分析时的有效性.
表6 与表7 的两组实验结果表明,预训练模型具有强大的语义表示能力,总体优于基于特征的模型.将BERT 和ERNIE 嵌入后,三个模型各项指标均有提升,证明预训练模型能提取文本的深层语义,提升模型情感分析的性能.同时,ERNIE嵌入的效果优于BERT,证明预训练模型作为嵌入层对TER 在对话长文本情感分析中的有效性.
3.6 超参数实验对学习率设置不同的参数,观察学习率的变化对TER 性能的影响.对比模型选择上述实验中表现较好的BERT 和ERNIE,实验结果如图2 所示.由图可见,学习率过低或过高均会降低模型性能.当学习率大于5e-6 或低于1e-4时,各模型相继收敛,趋于稳定;当学习率为5e-5时,各模型的性能不再有明显的提升,对比模型逐渐逼近TER,但TER的F1 整体上仍优于其他对比模型.
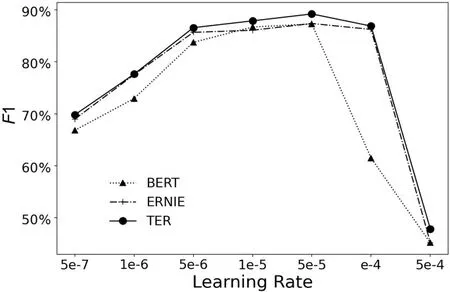
图2 学习率的变化对TER 性能的影响Fig.2 Performance of TER with different learning rates
3.7 定量分析实验定量分析TER 与对比模型对不同长度文本的情感分析结果,将mc1 按文本长度分为五部分,实验结果如表8 所示,表中黑体字表示结果最优.由表可见,TER 在不同长度文本上的性能均为最佳,且表现稳定.总体上,各对比模型在500~1000 字的文本上的准确率高于其他字数的文本,这是因为随着文本长度的增加,各对比模型建模时损失的特征也增加,而500~1000 字的文本量级,对比模型能保留大部分文本特征.

表8 各模型对不同长度文本情感分析的准确率对比Table 8 Accuracy of different models with different length texts based sentiment analysis
3.8 子事件抽取样例展示用TER 对mc1 数据集中的对话长文本进行子事件抽取,并对其中两个子事件进行可视化展示,如图3 所示.由图可见,该对话长文本中的对话双方具有不同的情感极性,且随对话的进行,情感发生了改变.TER 从该对话长文本中抽取出两个子事件,子事件一由文本1 至文本5 组成,子事件二由文本17 至文本21 组成,以子事件的情感特征作为整个对话长文本的情感分类结果.根据定义3 与定义4,客户产生了情感波动,作为情感主体,整个文本情感分类结果为积极.
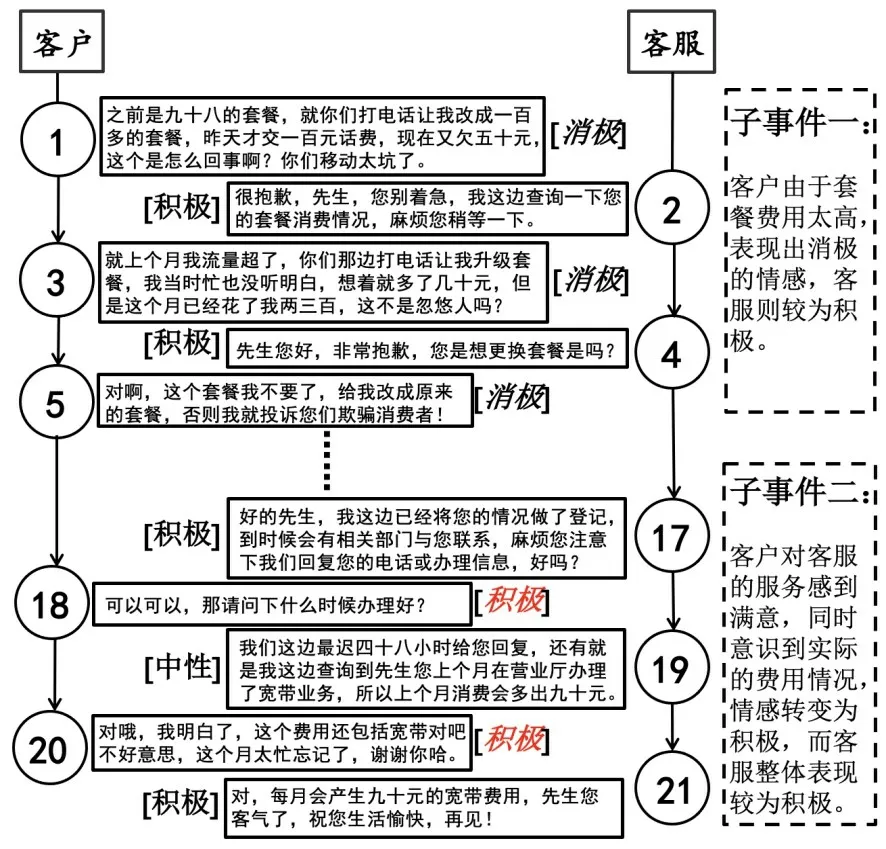
图3 子事件抽取的可视化样例Fig.3 Visual case of subevents extraction
4 结论
围绕对话长文本的情感分析任务,针对对话长文本篇幅长、对话双方情感不同、随着对话的进行情感发生变化等问题,本文首先抽取文本子事件,再集成各子事件的情感,提出一种基于TSI‐ERNIE‐RCNN 的对话长文本情感分析模型,在真实数据上的实验结果证明了该模型的有效性.
TER 模型虽然能较好地识别积极和消极情感,但和其他两类情感相比,无情感的识别更困难,降低了模型整体的精确率.接下来将探索其他深度学习模型,考虑使用多个模型联合学习,进一步提高模型的整体性能.
