基于全相位滤波器组频带鉴别的生成对抗网络声码器设计
2023-06-21黄翔东王俊芹马金英张烜溢
黄翔东,王俊芹,马金英,张烜溢
基于全相位滤波器组频带鉴别的生成对抗网络声码器设计
黄翔东1,王俊芹1,马金英2,张烜溢3
(1. 天津大学电气自动化与信息工程学院,天津 300072;2. 天津职业技术师范大学电子工程学院,天津 300222;3. 天津大学佐治亚理工深圳学院,深圳 518067)
为实现高质量、高效率、低成本的语音合成,设计开发了一种基于全相位滤波器组频带鉴别的生成对抗网络声码器APFB-GAN. 该声码器以现有的 HiFi-GAN 为参考,在生成器中,削减了 HiFi-GAN 多感受野融合模块约60%的参数. 在鉴别器中做了两点改进:一是将 HiFi-GAN 中多尺度鉴别器与多周期鉴别器替换为基于全相位滤波器组的鉴别器,克服了原有模型无法依据语音能量非均匀频带分布,灵活进行特征特征提取的缺点;二是提出基于频带加权的多窗长的短时傅里叶变换谱损失函数,配合鉴别器更好地稳定训练. 实验结果表明:APFB-GAN 声码器合成的语音质量可与 HiFi-GAN 相媲美,且其高频细节特征更为突出,模型参数只为HiFi-GAN的28.78%,在GPU 上的合成速度是 HiFi-GAN 的2.4倍.
语音合成;声码器;生成对抗网络;全相位滤波器组
文本转语音(text-to-speech,TTS)[1]是当前人工智能领域的热门研究课题,旨在实现机器像人一样流利自然地说话,该项技术可用在智能个人助理、机器人、游戏等语音交互等应用场景中.
基于神经网络的TTS语音合成分为两个阶段:第1阶段将文本转化为与语义相关联的低数据流中间表示(例如梅尔谱或各种言语特征);第2阶段通过声码器将该中间表示转化为合成语音波形.
近年来业内所提出的各类TTS声码器存在合成语音波形细节模糊、耗费资源大、合成效率不高的问题.例如,2016年,van den Oord等[2]提出的WaveNet声码器,采用了自回归卷积神经网络的结构,在合成单样点时需要所有历史样点信息,效率和合成语音质量均较差;2019年,Neekhara等[3]提出使用生成对抗网络[4-5](generative adversarial network,GAN)学习从梅尔谱到简单幅度谱的映射,并与相位估计结合来恢复语音波形;同年,Kumar等[6]提出一种基于GAN的声码器模型MelGAN,合成语音效率大大提升,然而该模型仅采用了单一的多尺度鉴别器[7](multi-scale discriminator,MSD),合成语音质量仍有较大提升空间;2020年,Yamamoto等[8]提出Parallel Wave-GAN,该声码器将多分辨率频谱差异纳入损失函数中,生成波形的质量有所改善;为进一步提升GAN声码器的语音生成质量,同年,Kong等[9]提出高保真度生成对抗网络(high fidelity generative adversarial network,HiFi-GAN),一方面在生成器设计中引入多感受野融合模块,另一方面提出多周期鉴别器(multi-period discriminator,MPD)与原有MSD进行融合,取得了高质量的语音合成效果,但是模型参数量大,合成语音也存在高频混叠问题.
鉴于以上现有声码器的不足,本文提出了基于全相位滤波器组的GAN(all-phase filter bank-GAN,APFB-GAN)模型,相比于HiFi-GAN,该网络可在减少模型参数量、缩短训练时间的同时提高合成语音质量、提升合成速度.APFB-GAN性能提升主要源于以下3方面:①在生成器设计中,适度裁剪了冗余的增强感受野的残差模块;②在鉴别器设计中,抓住MPD和MSD均为从多个频段比较真实语音和合成语音差异的本质,进而提出频带区分性更强的全相位滤波器组的鉴别器模型取代原有MPD和MSD的组合;③在鉴别器损失函数的设计中,提出附加时频变换频谱损失函数,提升对恢复语音的高频细节信息的保护.本文通过实验证明,以上3点改进措施的效果是显著的.
1 整体模型结构

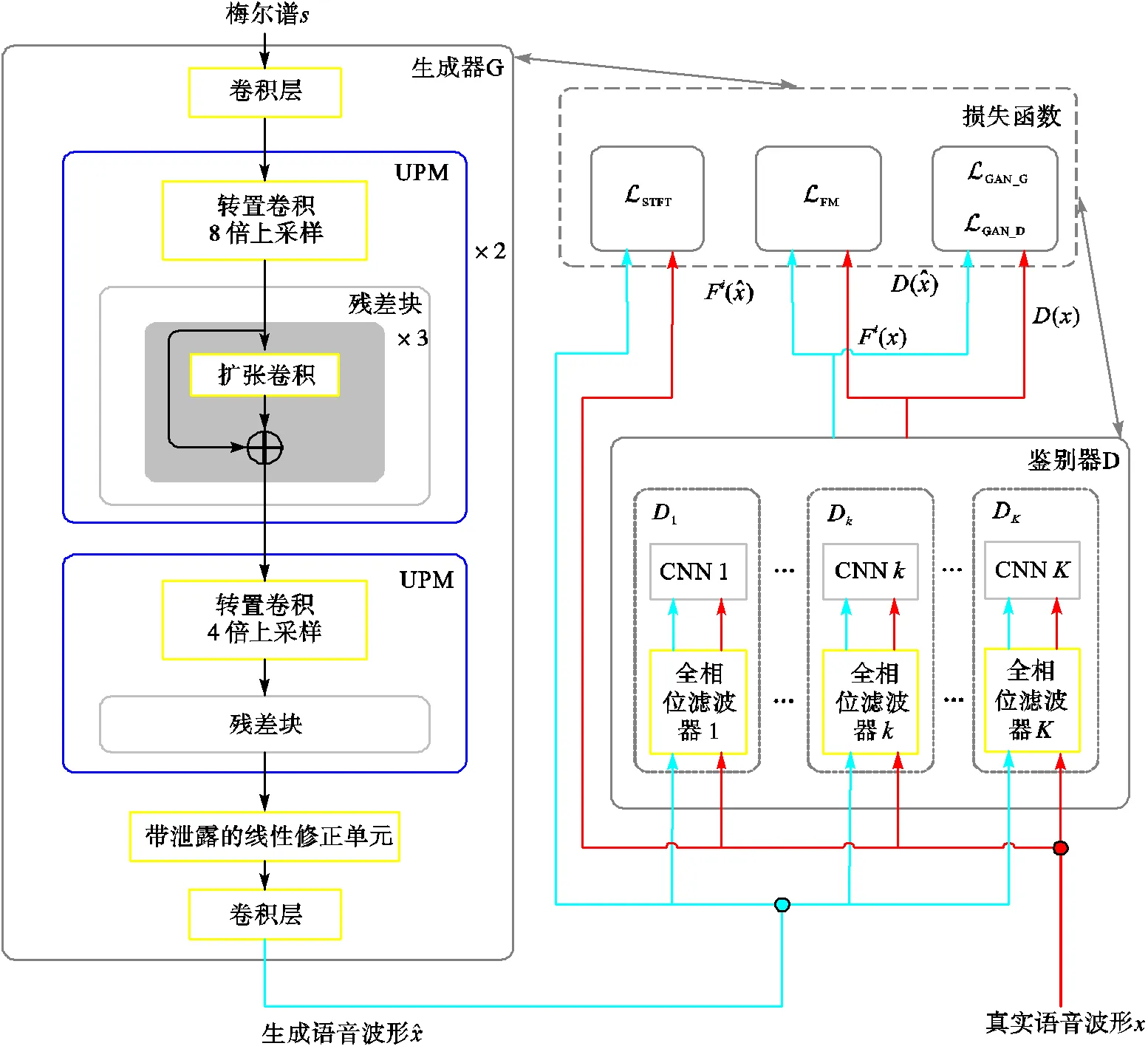
图1 APFB-GAN模型结构
2 高度裁剪的生成器设计
APFB-GAN的生成器主要由3个级联的上采样处理模块(upsampling processing module,UPM)组成.UPM是由基于转置卷积(transposed convolutional)的上采样单元和基于扩张卷积的残差块组成,其中前两个UPM对输入点的上采样倍数为8倍,第3个UPM输入采样点的上采样倍数为4倍.模型参数见表1所示,其中,输入尺寸和输出尺寸均记录了隐藏状态数和帧长的变化,为初始输入样点序列的帧长.
表1 生成器模型参数
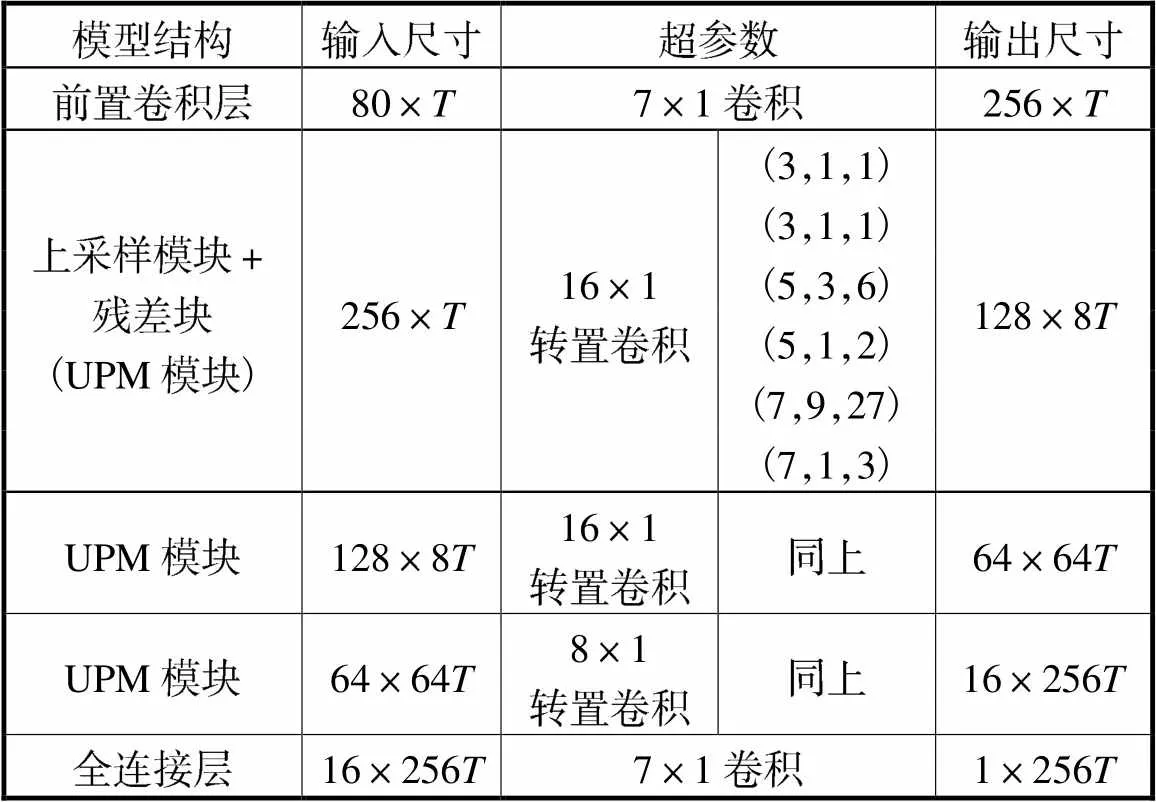
Tab.1 Generator model parameters
APFB-GAN的生成器延续了文献[9]中HiFi-GAN的生成器结构,区别在于:HiFi-GAN的生成器由4个UPM级联而成,其中前两个UPM由8倍上采样单元和包含3个并联通道的残差块组成,后两个UPM由2倍上采样单元和包含3个并联通道的残差块组成.因而APFB-GAN的生成器裁剪了1个UPM,且剩下的每个UPM裁剪了两个并联的残差块,因而所耗费的网络资源得以大幅度降低(降低70%以上,详见后面实验分析).
深层次而言,APFB-GAN中生成器的资源得以高度裁剪的原因是:APFB-GAN对鉴别器模型结构和损失函数做了根本性的改进,从而降低了训练过程中生成器模型参数更新的盲目性,使得轻量级模型生成高质量语音波形成为可能.
3 基于全相位滤波器组的鉴别器设计
3.1 现有基于GAN的声码器鉴别器的本质
MelGAN的鉴别器为多尺度鉴别器MSD,HiFi-GAN在保留MSD的基础上增加了多周期鉴别器MPD,进一步提升了语音质量.
MSD通过合并样本进行池化操作使得信号尺度发生改变,MPD通过抽取样本使得信号周期发生改变,就这两者的本质而言,都是信号在不同频率观测范围的区分反映.然而,MSD和MPD都只能设置有限的几个尺度因子和周期因子,一方面,从频带分割的角度来看,这些因子之间的鉴别信息是存在冗余的;另一方面,因为只能尝试有限的因子,因此所鉴别的信息必然是不完备的.
鉴于以上不足,本文提出基于全相位滤波器组的鉴别器来代替MSD和MPD.如图1所示,APFB的鉴别器由个子FIR滤波器组成,将这些子滤波器与简单的CNN进行级联,即可构成个子鉴别器.
3.2 全相位滤波器组的设计
笔者在文献[10]中提出单个的全相位滤波器设计法,其基本步骤如下.
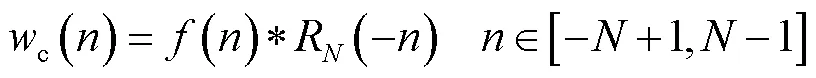

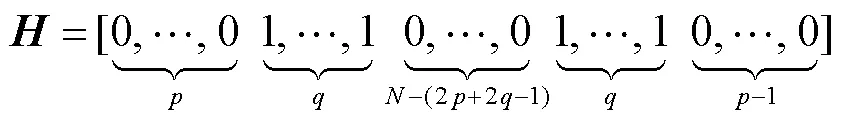
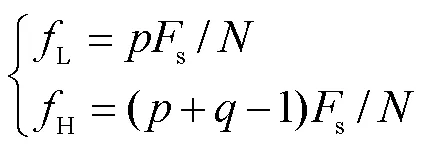
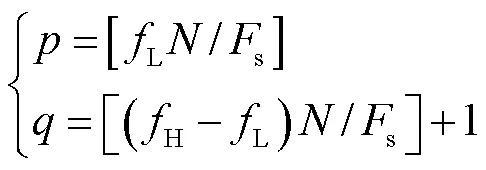


3.3 全相位滤波器组的参数设置

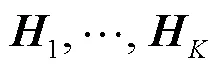
3.4 用于特征提取的CNN网络设计
APFB-GAN各子鉴别器中的CNN网络由6个一维卷积层和1个全连接层构成.对于每个卷积层,涉及数据并行分流(分流因子由输入、输出尺寸决定)、卷积核滤波(涉及滤波器长度、步长和数据填充3个超参数)操作,全连接层旨在实现数据降维.其模型参数如表2所示.
表2 子鉴别器CNN网络参数
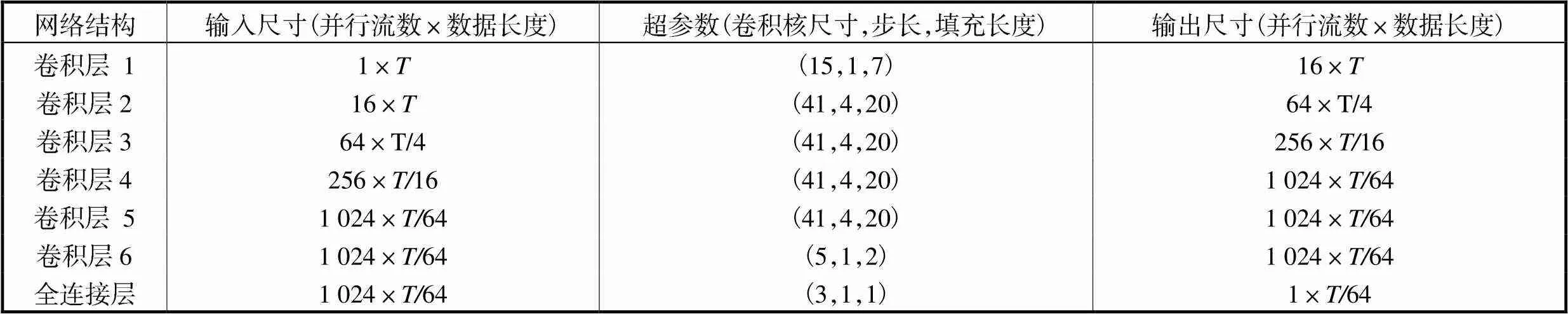
Tab.2 CNN model parameters of a subdiscriminator
3.5 APFB鉴别器的优势
与HiFi-GAN的鉴别器MSD和MPD相比,由于全相位滤波器具备边界频率位置易于控制、通带波纹小、阻带衰减大的优点[10],基于APFB的鉴别器具有以下优势.

4 损失函数
HiFi-GAN的损失函数设计包括3部分:GAN固有损失、特征匹配损失和Mel谱损失,本文提出用语音的时频谱损失替换Mel谱损失.
4.1 GAN固有损失
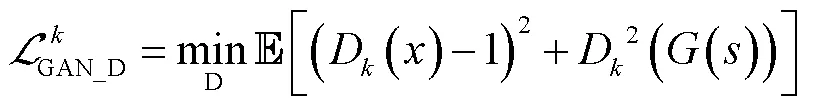
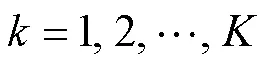
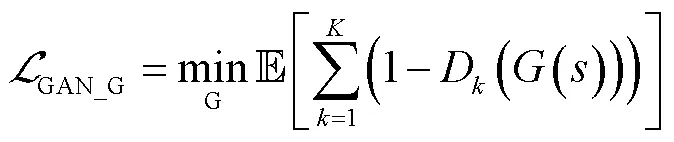
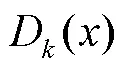
4.2 特征匹配损失
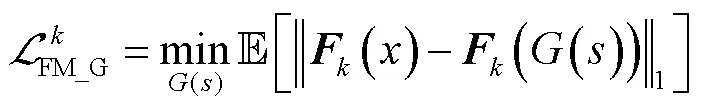
4.3 时频谱损失
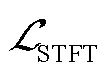

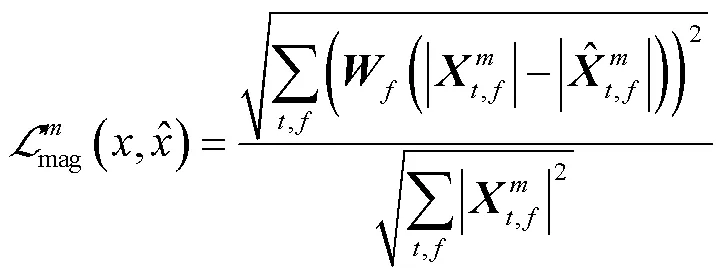


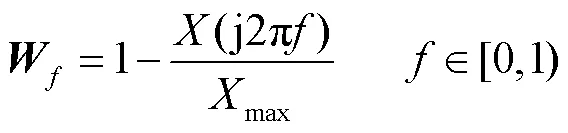
4.4 整体损失函数构造
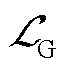
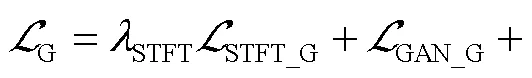

5 实 验
实验拟检验本文所提出APFF-GAN声码器3方面性能:APFF-GAN合成单说话人语音的性能;APFF-GAN合成多说话人语音的泛化能力;APFF-GAN用于端到端 TTS系统中的性能.对以上每个任务,都将APFF-GAN与现有其他4种高质量声码器模型做对比:WaveNet[12]、Fre-GAN[13]的开源实现、HiFi-GAN[14]、WaveGlow[15]的官方实现.此外,就子鉴别器中APFB对语音信号的频段划分方案进行实验对比,从而选定最佳方案.
实验硬件环境如下:单个NVIDIA GeForce RTX 3080GPU和单个AMD Ryzen 73700X 3.07GHz CPU.所有模型均使用32位浮点运算.
5.1 单说话人的语音合成质量及模型参数、合成速度的对比
选用LJSpeech语音数据集[16](包含单说话人的13100条短语音片段,总时长约为24h,16位PCM,采样频率22kHz),从中选取50条作为验证集,50条作为测试集,其余作为训练集.
对合成语音质量分别进行主观评测和客观评测.主观评测通过邀请专业听音测评人进行MOS评分,评分置信区间为95%;客观评测选用梅尔倒谱失真[17](Mel-cepstral distortion,MCD).梅尔倒谱失真计算真实语音与模型生成语音之间的相似度.MCD越大,两者差别越大,合成语音的效果就越差.
表3列出了5种声码器合成语音的主、客观评分及其在CPU、GPU上的合成速度及模型参数对比.
从表3实验数据可得出如下结论:
表3 5种声码器模型的对比结果

Tab.3 Comparison results of the five vocoder models
(1)在MOS评分方面,APFB-GAN与HiFi-GAN相比降低了0.01,这是因为APFB-GAN的生 成器是由HiFi-GAN的生成器经过剪裁得到,因而 合成语音质量有所下降;而在MCD值方面APFB-GAN表现最好,得益于鉴别器中对于语音信号进 行分频段鉴别的根本性改进,使得合成语音在频域 方面更接近真实语音,从而具有更小的梅尔倒谱 失真.
(2)在合成速度方面,APFB-GAN的CPU合成速度和GPU合成速度分别是实时语速的5.20倍、307.49倍,远高于其他对比模型;正是因为APFB-GAN模型参数远远低于其他模型,仅是HiFi-GAN1模型参数约28.78%的参数量,实现了轻量级语音合成.
以上结果反映出本文所提出的3方面技术改进是有效的.
5.2 声码器对未知说话人的推广能力测试
为测试APFB-GAN在多说话人中的推广能力,选用Hi-Fi TTS多说话人语音数据集[18](由10个不同英语口音的人所录制,包括4名男性、6名女性,总时长为296.1h,16位PCM格式,采样频率为44.1kHz).挑选其中3个人(2名女性,1名男性)的100条数据作为测试集,再挑选另外5个人(3名女性,2名男性)的200条数据作为验证集,20000条数据作为训练集.最终5种声码器对于未知说话人的合成语音质量如表4所示.
从表4可看出,APFB-GAN MOS得分为3.87,虽比HiFi-GAN低0.07,但是MCD值最低,证明了APFB-GAN可以提升合成语音的频域质量.
表4 对于未知说话人合成语音质量对比结果
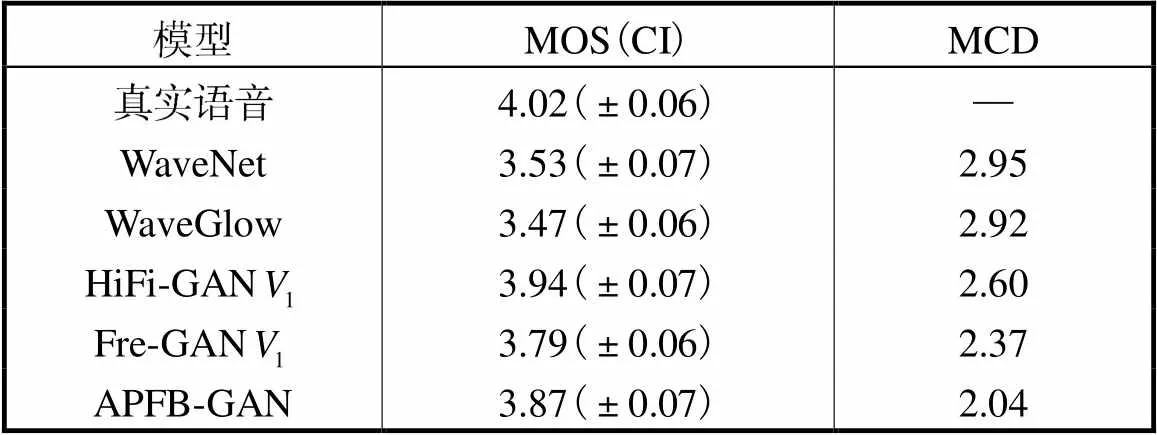
Tab.4 Comparison results of synthesis quality for un-known speakers
5.3 端到端的TTS语音合成
该部分实验旨在验证APFB-GAN应用于端到端的TTS系统时的表现.如前所述,TTS分为前端(实现文本转梅尔谱)和后端(实现梅尔谱转语音)两个阶段.在实验中,一致选FastSpeech[19]作为前端,使用其开源实现[20],FastSpeech提供梅尔谱输入到5种声码器中进行语音合成.最终APFB-GAN应用于端到端时合成语音质量比较结果如表5所示.
表5 对于端到端的合成语音质量对比结果

Tab.5 Comparison results of synthesis quality for end-to-end
从表5可看出,APFB-GAN的MOS得分为4.19,与HiFi-GAN作为声码器相差0.04分,MCD值最低,表现最好.具体地,给定文本内容“,”,图2~图4分别给出了真实语音、APFB-GAN和HiFi-GAN的TTS合成语音的梅尔谱对比,并且对局部片段细节进行了放大展示.
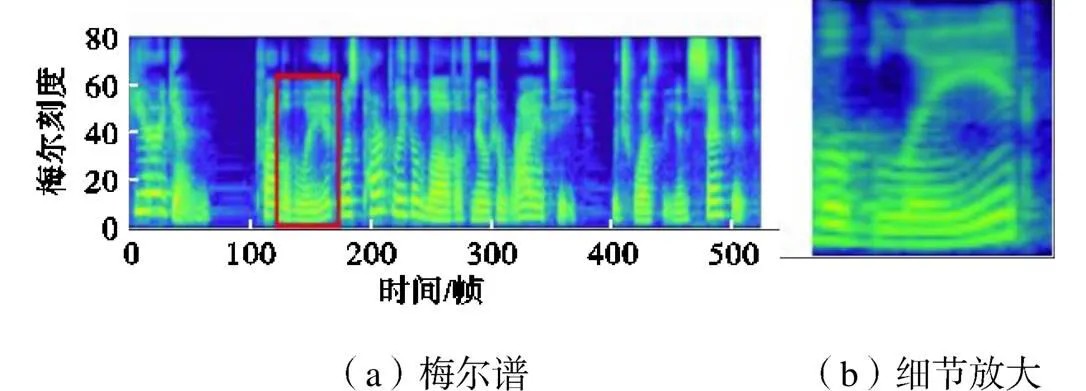
图2 真实语音的梅尔谱

图3 APFB-GAN恢复语音的梅尔谱
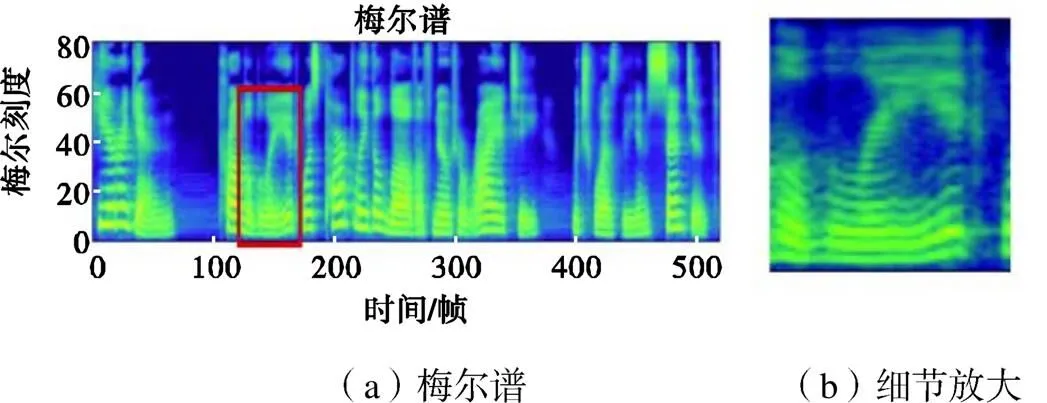
图4 HiFi-GAN恢复语音的梅尔谱
由此可以看出,图3的APFB-GAN的梅尔谱细节明显比图4的HiFi-GAN恢复细节更清晰,基本接近于图2中真实语音的梅尔谱.这反映了APFB的分频鉴别和所提出的时频谱损失函数的有效性,可以消除HiFi-GAN的高频混叠以致高频成分有所损失的问题.在频段划分中虽然在高频段的划分较为粗糙,但完整地保留了高频信息,在对应子鉴别器中可以有效获取高频特性,因而合成语音的高频部分更接近真实语音,从而梅尔谱的高频细节更为突出.
5.4 全相位滤波器组的设定
本节实验给出3种具有代表性的频段划分方案,验证不同全相位滤波器组的设定对于模型训练结果的影响.具体的方案如下:
方案1 10个频段:(0,200]Hz、(200,300]Hz、(300,350]Hz、(350,500]Hz、(500,600]Hz、(600,700]Hz、(700,800]Hz、(800,1000]Hz、(1000,1500]Hz、(1500,3400]Hz;
方案2 10个频段:(0,125]Hz、(125,250]Hz、(250,375]Hz、(375,500]Hz、(500,625]Hz、(625,750]Hz、(750,875]Hz、(875,1000]Hz、(1000,2200]Hz、(2200,3400]Hz;
方案3 7个频段:(0,250]Hz、(250,300]Hz、(300,450]Hz、(450,500]Hz、(500,750]Hz、(750,1000]Hz、(1000,3400]Hz.
这3种不同的全相位滤波器组对应的子鉴别器个数分别为10个、10个和7个.具有3种不同鉴别器方案的模型在训练后合成语音的MOS得分如图5所示.
从图中可以看出方案1的频段划分方案效果最好,方案2的线性划分会导致MOS分的下降,方案3频段划分个数少,存在频段信息丢失因而会对合成语音的质量造成损失.

图5 不同方案MOS得分对比
6 结 语
本文提出了基于APFB-GAN的声码器设计,其特色在于将基于全相位滤波器组的频带鉴别器完全取代了现有的多周期鉴别器和多尺度鉴别器,并且对损失函数做了有助于提升高频细节恢复的时频谱内容的补充,不仅提升了合成语音在频域中的质量,而且大大减少了生成器的模型参数.因而在同声翻译、网络资讯播放、有声阅读等智能语音合成的场合具有广泛应用前景.
本文研究结果表明,在深度学习网络设计中融入解释性高的信号处理模块(如全相位滤波器组),不仅可避免模型参数在收敛过程的盲目性,而且有助于真正实现高质量设计和轻量级设计的有效统一.
[1] Shen J,Pang R,Weiss R J,et al. Natural TTS synthesis by conditioning wavenet on Mel spectrogram predictions[C]//IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP). Piscataway,USA,2018:4779-4783.
[2] Van den Oord A,Dieleman S,Zen H,et al. Wavenet:A generative model for raw audio[EB/OL]. https://arxiv. org/pdf/1609. 03499. pdf,2016-09-19.
[3] Neekhara P,Donahue C,Puckette M,et al. Expedit-ing TTS synthesis with adversarial vocoding[EB/OL]. https://arxiv.org/pdf/1904.07944.pdf,2019-07-26.
[4] Goodfellow I,Pouget-Abadie J,Mirza M,et al. Gen-erative adversarial networks[J]. Communications of the ACM,2020,63(11):139-144.
[5] 张淑芳,王沁宇. 基于生成对抗网络的虚拟试穿方法[J]. 天津大学学报(自然科学与工程技术版),2021,54(9):925-933.
Zhang Shufang,Wang Qinyu. Generative-adversarial-network-based virtual try-on method[J]. Journal of Tian-jin University(Science and Technology),2021,54(9):925-933(in Chinese).
[6] Kumar K,Kumar R,de Boissiere T,et al. Melgan:Generative adversarial networks for conditional wave-form synthesis[J]. Advances in Neural Information Proc-essing Systems,2019,32:1-12.
[7] Wang T C,Liu M Y,Zhu J Y,et al. High-resolution image synthesis and semantic manipulation with condi-tional gans[C] //Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,USA,2018:8798-8807.
[8] Yamamoto R,Song E,Kim J M. Parallel WaveGAN:A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram [C] //ICASSP 2020-2020 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP). Piscataway,USA,2020:6199-6203.
[9] Kong J,Kim J,Bae J. Hifi-gan:Generative adversar-ial networks for efficient and high fidelity speech synthe-sis[J]. Advances in Neural Information Processing Sys-tems,2020,33:17022-17033.
[10] 王兆华,黄翔东. 数字信号全相位谱分析与滤波技术[M]. 北京:科学出版社,2009.
Wang Zhaohua,Huang Xiangdong. All-Phase Digital Spectral Analysis Method[M]. Beijing:Science Press,2009(in Chinese).
[11] Mao X D,Li Q,Xie H,et al. Least squares generative adversarial networks[C]//Proceedings of the IEEE In-ternational Conference on Computer Vision. Venice,Italy,2017:2794-2802.
[12] Yamamoto R. Wavenet vocoder[EB/OL]. https://github. com/r9y9/wavenet_vocoder,2020-11-02.
[13] Kim J-H. Fre-GAN-pytorch[EB/OL]. https://github.com/ rishikksh20/Fre-GAN-pytorch,2021-08-27.
[14] Kong J. HiFi-GAN[EB/OL]. https://github.com/jik876/ hifi-gan,2020-12-02.
[15] Prenger R. Waveglow[EB/OL]. https://github.com/ NVIDIA/waveglow,2020-09-03.
[16] Ito K. The LJ speech dataset[EB/OL]. https://keithito. com/LJ-Speech-Dataset/,2017-10-17.
[17] Kubichek R. Mel-cepstral distance measure for objective speech quality assessment[C]//Proceedings of IEEE Pa-cific Rim Conference on Communications Computers and Signal Processing. Victoria,Canada,1993:125-128.
[18] Bakhturina E,Lavrukhin V J,Ginsburg B,et al. Hi-Fi multi-speaker English TTS dataset[EB/OL]. https://arxiv. org/pdf/2104. 01497. pdf,2021-06-14.
[19] Ren Y,Ruan Y J,Tan X,et al. Fastspeech:Fast,robust and controllable text to speech[J]. Advances in Neural Information Processing Systems,2019,32:1-13.
[20] Ren Y. FastSpeech[EB/OL]. https://github.com/xcmyz/ FastSpeech,2022-09-16.
Design of Generative Adversarial Network Vocoder Based on All-Phase Filter Bank Discrimination
Huang Xiangdong1,Wang Junqin1,Ma Jinying2,Zhang Xuanyi3
(1. School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China;2. School of Electronic Engineering,Tianjin University of Technology and Education,Tianjin 300222,China;3. Georgia Tech Shenzhen Institute(GTSI),Tianjin University,Shenzhen 518067,China)
To achieve high-quality,high-efficiency,and low-cost speech synthesis,a generative adversarial network(GAN)vocoder based on all-phase filter bank discrimination(APFB-GAN)is designed and developed herein. The vocoder uses an existing high fidelity generative adversarial network(HiFi-GAN)as a reference and cuts the parameters of the HiFi-GAN multi-receptive field fusion module by about 60%. Furthermore,two innovations are made in the discriminator. First,the multi-scale discriminator and multi-period discriminator in HiFi-GAN are replaced with a discriminator based on an all-phase filter bank,which essentially overcomes the shortcomings of the original model that cannot flexibly extract features based on the nonuniform band distribution of speech energy. Second,a short-time Fourier transform spectral loss function based on frequency band weighted multiwindow length is proposed,and the discriminator is used to increase the stability of training. Experimental results show that the speech quality synthesized by the APFB-GAN vocoder is comparable to that synthesized by HiFi-GAN,and its high-frequency detail characteristics are highly prominent. The parameters of the proposed model are only 28.78% compared to those of HiFi-GAN,and the synthesis speed on the GPU is 2.4 times that of HiFi-GAN.
speech synthesis;vocoder;generative adversarial network(GAN);all-phase filter bank(APFB)
10.11784/tdxbz202207049
TN912.33
A
0493-2137(2023)08-0815-08
2022-07-31;
2022-12-02.
黄翔东(1979— ),男,博士,教授,xdhuang@tju.edu.cn.Email:m_bigm@tju.edu.cn
马金英,majinying@tju.edu.cn.
青海省基础研究计划面上资助项目(2021-ZJ-910).
the General Program of Foundation Research Plan of Qinghai Province,China(No. 2021-ZJ-910).
(责任编辑:孙立华)
