融合VGG16和最小二乘法的露天矿卡车装载率识别研究与应用开发
2023-06-11马连成刘洪臻陆占国史晓东杨兴悦孙效玉王仁炎
马连成, 刘洪臻, 陆占国, 史晓东, 杨兴悦, 孙效玉, 王仁炎
(1.鞍钢矿业集团 齐大山铁矿, 辽宁 鞍山 114000; 2.东北大学 智慧矿山研究中心, 辽宁 沈阳 110819)
运载计量是矿山的一项日常生产管理工作,精确掌握和控制矿岩产量,对矿山生产任务完成与车铲司机绩效考核具有重要意义[1]。由于露天矿山目前所使用的车铲装运设备缺乏有效地在线计量装置,对每个工作面的矿岩采出量采用运载车数乘以约定的单车装载量进行粗略计量。这不但使露天矿生产数据严重失真,影响配矿的准确进行,同时也造成了油料消耗量与运营考核的不准确[2]。
除了人工计数和地磅称重的传统检测方法外,现有的自动化矿岩量检测方法有传感器检测方法[3]和物位计检测方法[4]。应用实践表明,传感器设备成本与故障率高,同时易受到雨雪等恶劣天气和矿山中粉尘及细碎矿渣的影响,给日常维护和生产管理带来不便。物位计检测方法需要物位计和控制仪表配合使用,对响应时间要求较高,同时测量有遮挡的运输矿岩体积较为困难。
近年来,随着视觉传感、图像处理、人工智能等技术的快速发展,将计算机视觉技术和神经网络技术应用在矿山生产过程中已成为一个新的趋势,其非接触式传感、多层次信息融合、高速建模计算等特点满足了矿山生产范围大、不间断、需及时反馈等要求[5]。TessierJ.等人提出了一种用于岩石混合物成分在线估计的通用机器视觉方法[6];Duan J.等人设计并提出了一个轻量级的U-net深度学习网络,从图像中检测颗粒并获得颗粒轮廓的概率图[7];H.HU等人提出了利用神经网络分类算法实现采矿车辆故障的早期检测[8]。
本文使用卡车装载矿岩时采集的大量图像数据作为研究对象,经过合理的图像数据预处理策略,通过VGG16深度神经网络模型以及最小二乘法数据驱动模型[9-10],实现对矿用卡车装载体积的检测。
1 数据采集和预处理
1.1 图像采集
1.1.1 露天矿图像采集
实际应用中,摄像头安装于电铲驾驶室顶部右上角,采用斜向俯视方式拍摄铲斗装载时的卡车图像,如图1所示。

图1 现场摄像头安装位置与拍摄图像
由于电铲装载具有较大的随机性,装载量波动较大,想要获取比较准确的图像样本集需要耗费大量时间,影响生产的正常进行,因此电铲实际采集主要用于测试集,测试集部分图像如图2所示。

图2 现场测试集部分图像
1.1.2 实验室环境下图像采集
深度学习需要大量数据,其体系结构也很复杂。即使同一个类别,在深度学习模型训练中也需要数以千计的标记图像。由于如此大量的数据在实际矿山中短时间内很难收集和标注,因此本文主要采用实验室环境下的电铲装载矿车图像对模型进行训练与验证。
矿山实摄的矿车型号为北重NTE200,箱斗容量为平92(堆123)m3,载重172~186 t,车尺寸为13 000 mm×7 300 mm×6 900 mm。为保证有效性,实验室矿车模型尺寸为190 mm×112 mm×100 mm,箱斗容量为300 cm3,模型尺寸与真实车型大小约为70倍关系。
为了尽可能还原现场情况,保证实验的真实性,拍摄时高度固定,拍摄视角为俯视向前斜视。采用矿车模型、电铲模型、量杯和沙土等制作实验室环境下的数据集,实验装置与材料如图3所示。

图3 实验装置图
本文采用的数据集由5 500张图像组成,其中,训练集由5种类别图像组成:装载率0%(空车)、装载率25%、装载率50%、装载率75%、装载率100%(满车),每种类别1 000张。测试集由10种类别图像组成:装载率10%、装载率20%、装载率30%、装载率40%、装载率50%、装载率60%、装载率70%、装载率80%、装载率90%、装载率100%,每种类别50张。通过试验装置采集的部分图像如图4所示。
1.2 图像预处理
图像预处理是图像检测过程中十分重要的一步,图像预处理的结果也会对模型的分类和预测效果产生直接的影响。图像预处理的目的是减小模型处理的数据量,降低图像中无用信息的干扰和特征提取的难度,进而可以提高模型训练和预测的速度,使得模型的预测稳定性和可靠性增强。本文采用小波阈值去噪、双边滤波和直方图均衡化三种图像预处理策略进行处理。
1.3 基于TFRecord格式的数据集制作
(1)TFRecords文件数据的创建
TFRecords文件包含了tf.train.Example 协议缓冲区protocol buffer,协议缓冲区包含了特征Features。首先将数据填入到Example协议缓冲,然后将协议缓冲区序列化为字符串,通过tf.python_io.TFRecordWriter class写入到TFRecords文件。
(2)TFRecords文件数据的读取
首先,创建数据流图,该数据流图由一些流水线的阶段组成,阶段间用队列连接在一起。第一阶段将生成文件名,读取这些文件名并且把它们排到文件名队列中。第二阶段从文件中读取数据,产生样本,将样本放在一个样本队列中。根据设置,也可以拷贝第二阶段的样本,使得它们相互独立,这样就可以从多个文件中并行读取。在第二阶段的最后进行排队操作,即入队到队列中去,在下一阶段出队。在开始运行这些入队操作的线程时,训练循环会使得样本队列中的样本不断地出队。
2 融合VGG16和最小二乘法的装载率模型
矿用卡车装载率检测模型主要由两部分组成:第一部分基于VGG16深度神经网络的图像预分类模型,第二部分基于最小二乘算法的矿用卡车装载率预测模型。图像经过VGG16深度神经网络图像分类模型,输出结果为所预测的每种类别的概率值。图像分类预测的分类结果及对应的概率值作为最小二乘法待拟合的数据,经过最小二乘回归模型输出结果为矿用卡车装载率的预测值。
利用融合VGG16和最小二乘法的矿用卡车装载率检测模型,可以实现对矿用卡车装载率的检测。图5展示了矿用卡车装载率的检测流程。
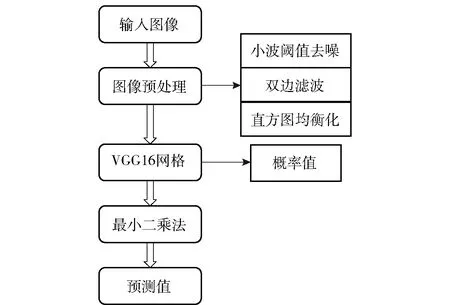
图5 矿用卡车装载率检测流程图
2.1 VGG16模型
VGG16网络的输入是固定尺寸大小的RGB的2D图像,接着依次通过一系列堆叠的、核大小为3×3的卷积层。每两个或者三个连续堆叠的卷积层,为一个网络的小的单元模块,命名为Block。每一个Block后面会接入一个Max-pooling 层,用于减小输入图像的尺寸大小,并保持网络的平移不变性。经过多个堆叠的Block单元后的输出,会接入一个三层的传统神经网络,也就是三层全连接层。最后的分类输出是一个softmax多分类器。VGG16网络结构如图6所示。
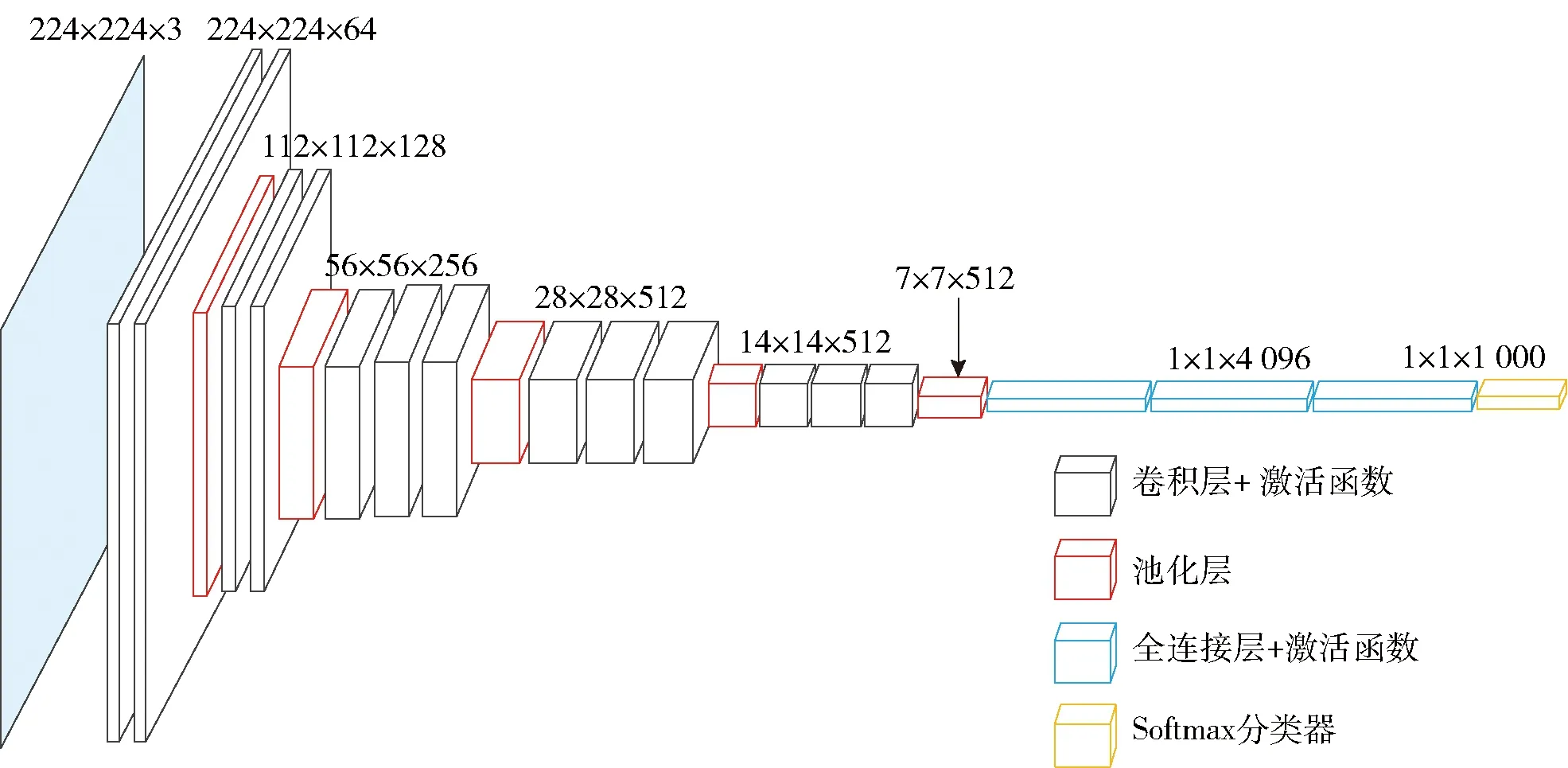
图6 VGG16网络结构图
网络中的每一个卷积层、全连接层后面使用激活函数进行非线性的映射计算。在第一个和第二个全连接层的后面还使用了dropout技术,来提高网络的泛化能力,防止网络的过拟合。
2.2 最小二乘回归模型
图像经过VGG16深度神经网络图像分类模型,输出结果为所预测的每种类别的概率值。图像分类预测的分类结果及对应的概率值作为最小二乘法待拟合的数据,输出结果为矿用卡车运载率的预测值。选取分类结果中可能性最大的前两个分类结果及其对应的概率值作为最小二乘回归模型的待拟合数据。公式(1)中的X、Y、Z即为待拟合的三个系数。
待拟合公式为:
V=(X+YC1P1+ZC2P2)×Vm
(1)
其中,V为装载矿岩体积,Vm为矿车最大装载体积,C1、C2分别为最大概率类别与第二大概率类别,P1、P2分别为最大概率类别的概率值、第二大概率类别的概率值。
3 矿用卡车装载率检测模型的训练
3.1 VGG16深度神经网络模型
目前还没有较系统的理论体系来帮助神经网络针对不同数据样本确定出更有效的参数。其中,学习率是最影响性能的超参数之一,它以一种更加复杂的方式控制着模型的有效容量,当学习率最优时,模型的有效容量最大。设置不正确的学习率可能会使得模型收敛速度过慢或震荡,甚至无法收敛。另外,随着模型可处理的数据量的增加以及电脑内存的限制,一次性将过大的样本数据输入进网络中会严重影响模型的处理速度,每次送入网络的样本数量直接影响模型分类正确率和训练总体时间,因此BatchSize大小的选择至关重要,从而实现对模型的优化以及提高网络的检测速度。本文采用控制变量法分别从学习率、BatchSize、激活函数三个方面进行大量的网络拓扑生成实验来确定最优的网络结构参数,以求网络模型达到较好的网络性能。在此过程中,选取多重相关系数R和均方根误差RMSE(root mean squared error)作为评价模型性能的指标。R是一个评价拟合好坏的指标,通过拟合结果和实测值的相关系数来反映拟合结果和实测结果的相关程度,R越接近1,拟合的回归方程越优。RMSE反映了预测数据和原始数据对应点误差大小,RMSE越接近0,拟合的回归方程越优。R和RMSE公式分别由公式(2)和公式(3)给出:
(2)
(3)
通过进行大量的网络拓扑生成实验及其对应的结果分析,选择最优的网络模型参数为:学习率0.002 5、BatchSize为30、Elu激活函数。此时,R值约为0.997 8,RMSE值约为0.013 6,网络拟合度较好,模型预测准确性良好。
3.2 最小二乘数学模型
图像经过VGG16神经网络图像分类模型,输出结果为所预测的每种类别的概率值。图像分类预测的分类结果及对应的概率值作为最小二乘法待拟合的数据,输出结果为矿用卡车运载计量的预测值。按着公式(1),通过Matlab中CFTOOL工具箱进行优化拟合,拟合结果分别如图7所示与公式(4)。
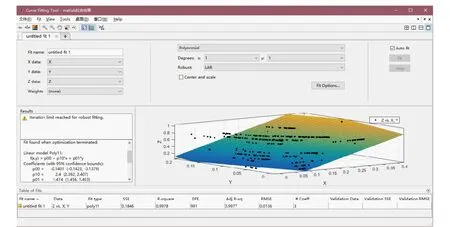
图7 最小二乘法拟合
V=(-0.240 1+2.4C1P1+1.474C2P2)Vm
(4)
4 实验结果分析评价
4.1 矿用卡车体积检测模型的评价指标
平均绝对误差MAE(mean absolute error) 和均方根误差 RMSE是衡量变量精度的两个最常用的指标,同时也是机器学习中评价模型的两把重要标尺。本文采用这2个指标对模型性能进行全面评估,其中RMSE见公式(3),MAE计算公式如下:
(5)
MAE是对各预测数据的绝对误差求平均,反映预测值误差的实际情况;RMSE是观测值与真值偏差的平方和与观测次数L比值的平方根,衡量观测值同真值之间的偏差。
4.2 矿用卡车体积检测模型的实验结果分析
对10种类别(装载率分别为10%、20%、30%、40%、50%、60%、70%、80%、90%、100%)矿用卡车装载结果进行检测分析,结果如下:
(1)预测值与实际值关联对比分析:其关联折线图如图8所示。由图可见,预测值分布在对应实际值附近且相距较小,平均误差不超过5%,证明模型预测效果较为准确。
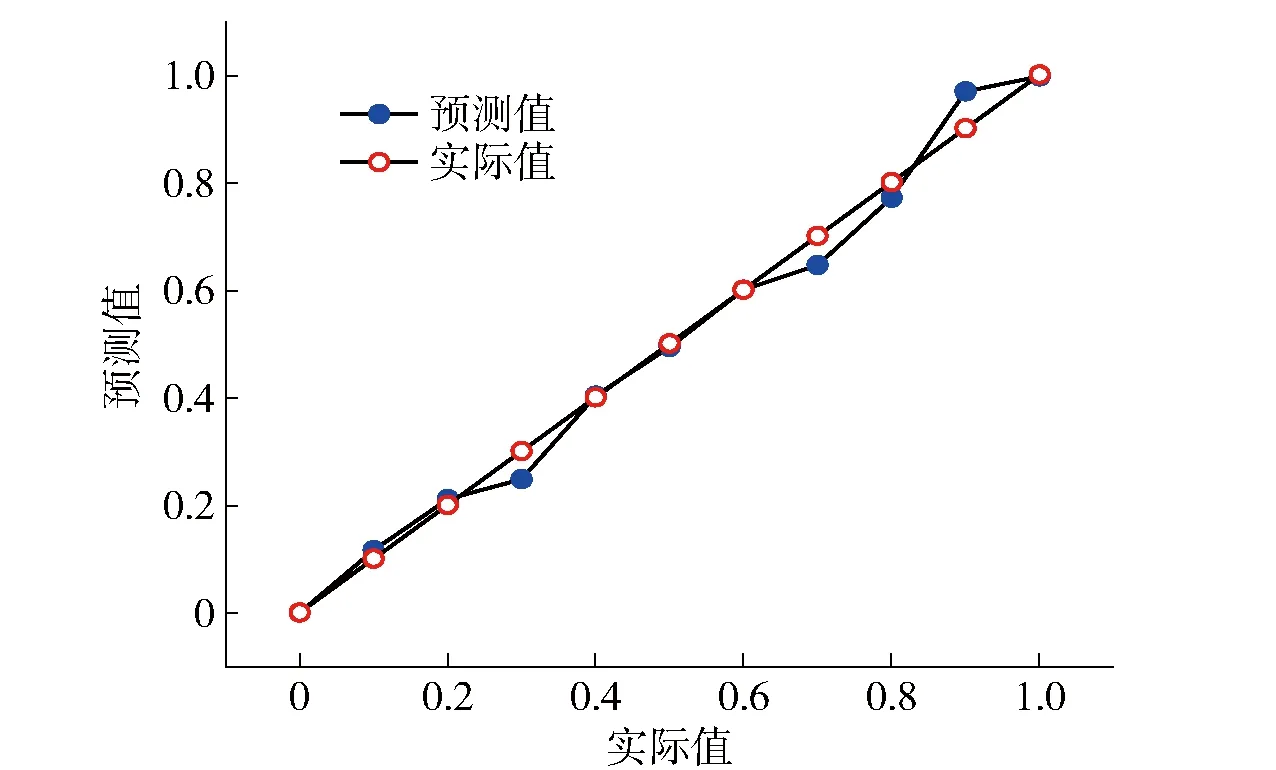
图8 预测-实际关联折线图
(2)MAE与RMSE性能分析:图9为MAE与RMSE性能直方图,由图可见,10种类别装载率的平均MAE和平均RMSE较小,分别为0.060和0.081,证明所建立的模型的性能较好。
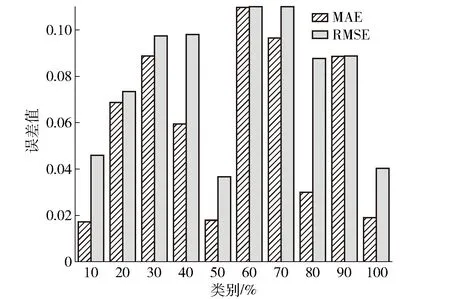
图9 模型性能指标直方图
4.3 存在问题分析
用实验室测试集检验结果很好,但用现场测试集检验误差较大。经分析,其原因主要有以下两点:一是现场样本集太少,无法有效参与样本训练;二是实验室样本集与现场样本集存在一定的误差。要达到现场应用效果,第一种方法是通过增加现场采集样本解决,这需要消耗较大的人力物力,且影响矿山的正常生产管理;第二种途径是增加现场设备与运行环境的模拟仿真,包括电铲和卡车等设备、装置矿岩物料、多视角摄像等,从当前试验基础上看,通过矿山运输装载工艺环节的仿真,将成为该领域研究的最优选择。
5 矿用卡车装载率检测系统的开发
5.1 系统开发环境
(1)开发语言:Python;
(2)软件环境:JetBrains PyCharm 2018.2.4 x64,Matlab R2018b;
(3)其他辅助开发工具包:PyQt5,OpenCV4.11;
本系统开发工作主要在PC端上完成,并打包成exe可执行文件,使其具有跨平台通用性。
5.2 系统功能模块
依据系统需求,利用融合VGG16网络和最小二乘法的矿用卡车装载率检测模型,以exe可执行文件形式展现相应功能。开发流程分为以下三个步骤:
(1)利用PyQt5辅助开发工具包实现系统界面绘制;
(2)利用Python语言实现系统界面中相应功能;
(3)打包成exe可执行文件进行调试。
依据模块化设计思想,将矿用卡车装载率检测系统模块划分如下:
(1)图像导入模块:实现图像选择和目录显示两个功能。选择本地图片作为待检测图像并显示其所在目录。
(2)图像显示模块:将所选择待检测图像显示到系统界面中。
(3)图像检测模块:基于融合VGG16网络和最小二乘法的矿用卡车装载率检测模型,将VGG16深度神经网络训练好最优网络超参数和最小二乘法中最优待拟合参数输入模型中,对所选择的图像进行装载率检测。
(4)检测结果模块:实时显示矿用卡车装载率的检测结果。
(5)日期显示模块:显示检测日期和时间。
矿用卡车装载率检测系统运行界面如图10所示。
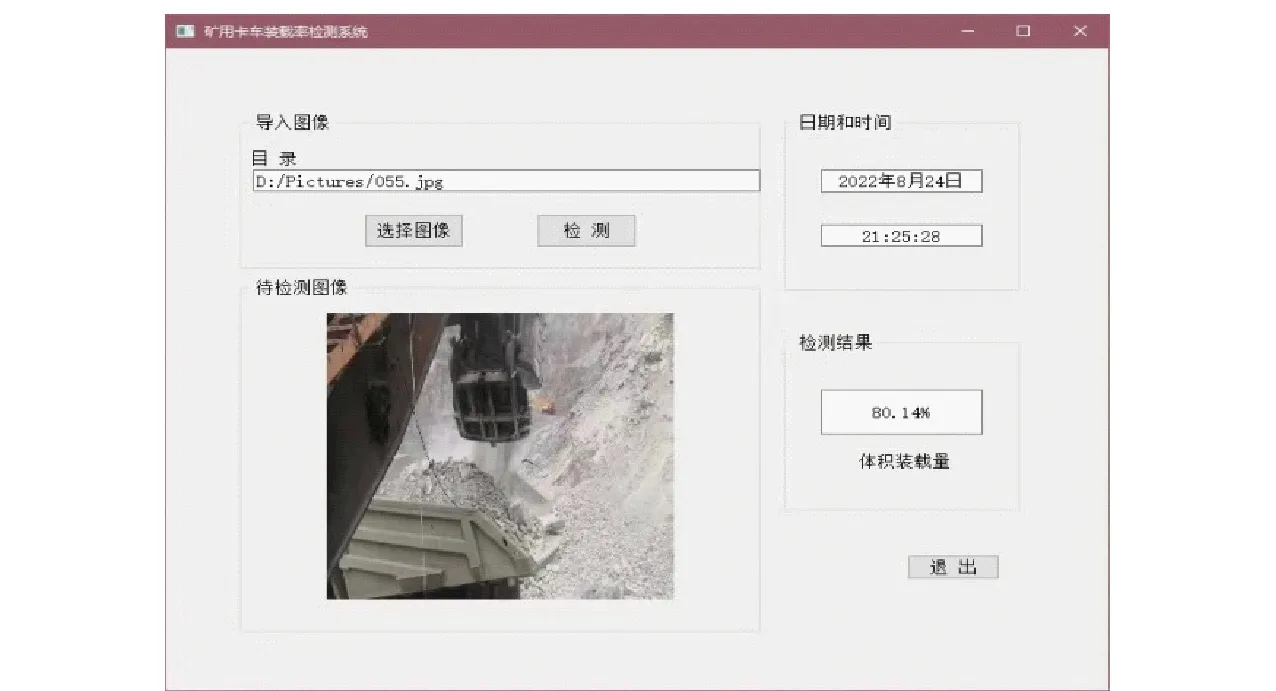
图10 系统运行主界面
6 结论
(1)融合VGG16和最小二乘法的露天矿卡车装载率识别方法,经过VGG16深度神经网络模型对矿石图像进行预分类,显示分类结果并确定每种类别可能性大小,利用分类结果以及最小二乘算法计算矿用卡车装载体积。
(2)利用实验室环境下的图像数据对模型进行验证,平均误差不超过5%,证明了本文所提出的方法具有较高的预测精度和通用性。
(3)将人工智能技术和图像识别技术引入矿用卡车装载体积的检测中,成本低廉,减少资源浪费以及人力物力的使用,提高检测自动化程度。但如何有效获取矿山真实矿车图像装载率样本,是后续应用需要进一步解决的问题。
