基于神经网络的汽车驱动轴故障率预测
2023-05-31张陈佳
张陈佳
同济大学汽车学院,上海 200092
0 引言
随着汽车销量的持续增长,市场上的汽车质量问题也出现激增,消费者对于汽车质量问题的抱怨越来越大。根据今年市场监管总局发布的2021年汽车产品召回情况通知,数据显示2021年我国总计实施汽车召回230次左右,涉及的车辆近900万,分别比上一年增加约17%和29%,而涉及汽车召回的质量问题往往比较严重,这些数据还不包含市场服务活动。2021年汽车销量总计约2 000万辆,这些数据显示汽车质量问题还是很多,汽车零部件故障率高,其中驱动轴召回数量占比约6%。这些问题不仅会影响汽车制造商和供应商的形象,而且对这些相关公司会产生巨大的经济损失,对消费者的驾驶体验甚至是人身安全会造成影响。
因此对于汽车零部件质量情况的分析与预测非常重要,汽车零部件故障率是汽车零部件产品质量的关键评价指标。如果对汽车零部件故障率能够应用有效的方法进行预测,那么能够及时地掌握产品的故障率发展趋势以及产品的质量情况。针对这些批量性质量问题如果能够及时发现,则可采取相应有效措施进行问题遏制,那么对于产品质量问题的出现能够掌握更多的主动权,能够及时联合汽车厂商对于质量问题进行快速处理,防止问题进一步扩大蔓延,减少影响范围,进而减少经济损失。
现在汽车行业内对于产品故障率预测的研究非常少,针对汽车的售后可靠性数据的分析,绝大部分公司还只是停留在相对比较简单的统计范围,基本没有进行进一步的分析研究。汽车的售后可靠性数据能够真实反映出汽车及其零部件的质量情况,根据这些真实可靠性数据能够更加准确地对产品故障率进行预测研究。现在对产品故障率预测的研究方法主要分为3类:第一类是基于物理模型的预测方法,模型比较复杂,预测误差较大,主要有灰色预测法等。其中杜文然等[1]研究建立了基于灰色模型的动车组的百万公里故障率的预测模型;王瑞奇等[2]提出了一种基于经验模态分解、支持向量机和灰色模型结合的装备故障率预测模型;朱明等[3]建立了受温度、湿度等影响的电梯故障率的灰色预测模型。第二类是基于统计可靠性的预测方法,模型的精确性比较差,预测稳定性比较差,主要有威布尔模型和回归模型等。其中Zhang等[4]提出了一种基于威布尔的广义更新过程模型,利用一些关键测试参数预测了民用飞机APU的故障率;郭利进等[5]提出了多元线性回归融合模型,预测了制氧系统设备的故障率;Motiee等[6]基于4种回归模型建立了管道的故障率预测模型。第三类是基于历史数据库的预测方法,需要数据比较准确,预测准确性比较高,主要的方法有支持向量机、随机森林、神经网络等。其中胡毅等[7]提出了基于经验模态分解和支持向量机的飞机故障率预测模型;Molawade等[8]建立了基于随机森林模型的软件故障率的预测模型;贺德强等[9]利用IPSO-BP神经网络模型预测了列车车轮的故障率;Dong[10]利用Matlab软件建立了基于BP神经网络模型的无人机飞行控制系统的故障率预测模型;Xu等[11]建立了基于遗传算法优化BP神经网络模型的航空电子系统的故障预测率模型等。
通过对于这些文献以及汽车零部件故障率特点的分析研究,发现神经网络在产品故障率预测方面研究比较多,其中很多文献分析认为神经网络模型相比其他模型的预测性能优良,预测稳定性比较高,而汽车有大量真实的售后可靠性数据,可以根据这些历史数据使用神经网络模型来进行汽车零部件的故障率预测[12-13]。本文以某车型的驱动轴为例进行研究,基于BP神经网络建立了驱动轴故障率的预测模型,针对神经网络容易陷入局部极小值等不足,使用遗传算法对BP神经网络模型进行了优化,进一步提高了BP神经网络模型的预测性能,并且使用GA-BP模型的预测结果和线性回归模型、随机森林模型的预测结果进行了对比分析,最后还对故障率的影响因素进行敏感性分析,确定对驱动轴故障率影响最大的影响因素。
1 模型理论和方法介绍
1.1 BP神经网络理论
人工神经网络是模拟人脑神经网络的一种简化模型,它是由多层神经网络层构成,并且网络层的神经元之间相互关联,神经网络本质上是通过不断学习进而确定神经元之间的连接强度。通过大量的数据训练学习,神经网络模型可以学习掌握到数据的变化规律,从而确定神经元之间的权值与阈值,最终形成相应的模型。它不需要预先假设数据的函数,这样可以避免假设的函数造成的误差,而汽车故障率的影响因素比较复杂,如果通过假设数据函数来建立模型,这样可能会造成很大的误差,这个函数往往不能代表数据。神经网络模型具有很强的训练学习能力、误差容错能力和泛化能力,因此神经网络模型的适用范围非常广泛,很适合用来进行汽车零部件故障率的预测。
BP神经网络是误差反向传播的多层前馈神经网络,它主要由输入层、输出层和隐含层构成,如图1所示。BP神经网络具有很强的非线性拟合能力,简单的三层网络结构就能实现对任意非线性函数的拟合。BP算法的学习过程分为信号的正向传播过程和误差的反向传播过程,在正向传播过程中,信号通过输入层输入,经过隐含层,最后在输出层输出信号,在正向传播过程中权值阈值保持不变,当输出层的输出信号经过误差函数计算得到的数值和设定值对比过大时,则进行误差的反向传播。在误差反向传播过程中,误差信号由输出端开始逐层向前传播,通过相关学习算法和学习率调整各个神经元之间的连接权值和阈值,这些参数修正以后再开始进行第二次的正向传播,通过计算误差值再进行第二次的反向传播,这样反复进行正向和反向传播过程,直到误差值满足设定要求。
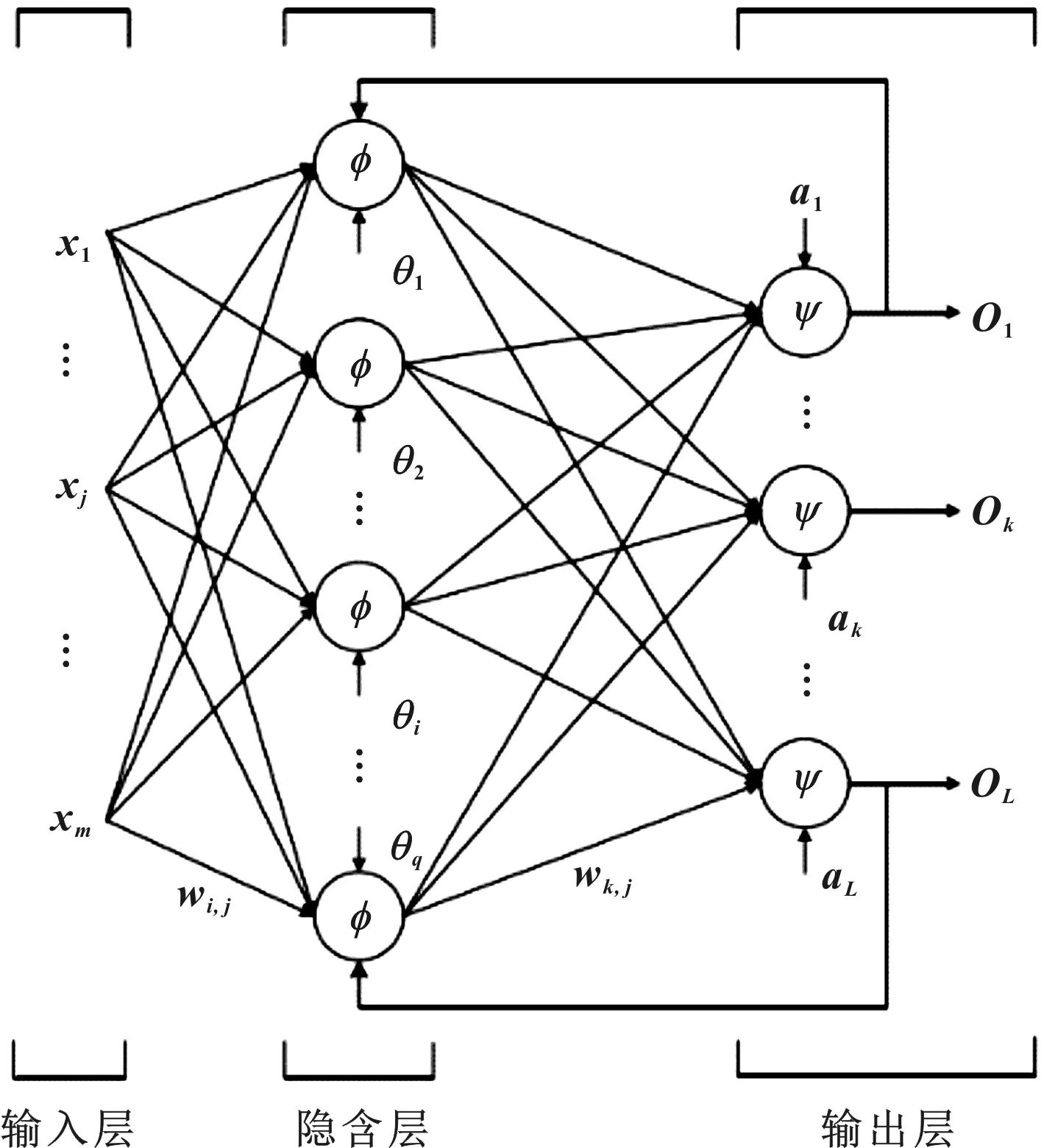
图1 神经网络结构
1.2 遗传算法理论
遗传算法是一种基于生物进化论的自然选择和基因遗传学的生物进化相结合的全局寻优算法,模拟自然界中的“优胜劣汰,适者生存”法则,按照相应的适应度函数的评估,对相应的个体进行选择、交叉和变异操作,使得适应度好的个体被保留,适应度差的个体被淘汰,新的种群相比上一代就越来越优良,直到最后满足要求。BP神经网络对于权值和阈值非常敏感,初始权值和阈值在很大程度上影响BP神经网络的泛化能力,因此利用遗传算法来对BP神经网络的初始权值和阈值进行优化,可以找到最优的权值和阈值个体,这样可以有效提高BP神经网络的收敛速度,并且减少BP神经网络的陷入局部最优解的可能性,遗传算法和BP神经网络的结合可以使得模型的预测能力显著提高。遗传算法优化BP神经网络模型的具体步骤如下:
(1)初始化种群。生成初始种群,使用浮点编码方法对BP神经网络模型中的权值和阈值进行编码,将一个网络中权值和阈值依次排列生成一个染色体,需要确定种群规模和遗传次数。
(2)确定适应度函数。适应度函数在遗传算法中非常关键,适应度函数被用来对个体进行评估优劣性,根据适应度函数的评估来决定对个体进行选择、交叉、变异遗传操作,适应度高的个体遗传到下代种群的概率较大,适应度低的个体遗传到下代的概率较低,这里把均方误差的倒数作为适应度函数,其中Yd和Y分别表示期望值和真实值:
(1)
(2)
(3)遗传操作。根据适应度函数来对个体进行适应度评估,进而根据评估结果来对个体进行遗传操作,其中适应度低的个体需要通过选择、交叉和变异遗传操作来进行进化,经过遗传操作就可以生成新的种群,再继续进行适应度评估。
选择操作。选择操作的目的就是使得适应度高的个体进入下一代的概率更高,而适应度低的个体进入下一代的概率更低,这里选取轮盘赌选择法,个体选择的概率和适应度成正比,这样可以满足选择要求。
交叉操作。根据交叉概率把两个个体的部分结构进行互换从而形成新的个体,通过交叉操作有可能形成优良个体。
变异操作。根据变异概率在个体的一个或者多个位置进行基因值改变,这样可以增加种群的多样性。
(4)计算适应度函数值,评估新的种群的适应度,如果满足条件则终止计算,进而输出最优的权值和阈值到BP神经网络模型。
(5)BP神经网络模型使用遗传算法输出的最优解作为初始权值和阈值,采用训练样本对BP神经网络模型进行训练,最后使用训练完成满足要求的BP神经网络模型对驱动轴故障率进行预测验证。
遗传算法过程如图2所示。

图2 遗传算法过程
2 研究对象介绍
驱动轴是汽车传动系统的重要零件,它连接着变速箱和车轮,通过发动机传递给变速箱的扭矩,继续通过驱动轴传递给车轮。汽车一般性都有4根驱动轴,驱动轴有传递动力和辅助转向的作用。驱动轴由移动端、中间轴、固定端3个部分构成。移动端连接着变速箱,可以进行一定距离的伸缩和满足20°左右方向的摆角,移动端主要的节型是三球销型;固定端连接着车轮,可以满足45°左右的摆角,固定端内部由保持架、钢球、钟形壳和星型套组成。移动端和固定端内部都有润滑油脂,外部用橡塑护套来进行密封,护套用夹箍来进行固定夹紧。
驱动轴的故障模式主要分为3类:第一种是漏油。因为驱动轴两端是有橡塑护套密封,护套比较容易破损,从而导致漏油。护套的破损可能产生于驱动轴生产到汽车维修的整个过程中,而有的漏油是由于卡箍没有夹紧而导致的漏油,可能是由于外力碰撞导致的卡箍松脱,也可能是驱动轴生产过程就没有夹紧导致。第二种是异响。驱动轴内部结构比较精密,对于零件的粗糙度、尺度和硬度等都有很高的要求,一旦某些因素没有满足要求,零件内部就可能发生异响。因为驱动轴在汽车行驶的过程中两端都在不停地做运动,比如如果内部尺寸过小,那么内部零件就可能会存在间隙,运动过程中就会产生撞击异响。异响也可能来源于驱动轴和其他零件的相对运动中,其中驱动轴和车轮的轮毂通过花键进行连接,这两个零件如果尺寸没有匹配好,那么就可能也会产生异响。第三种是抖动。抖动的原因比较复杂,可能是因为移动端内部零件的尺寸或者硬度等没有满足要求而导致。驱动轴的故障原因可能产生于驱动轴的生产过程,也可能产生于汽车的整车装配过程,也可能产生于汽车的使用过程等。因为驱动轴的护套比较容易受到外力而破损,从而导致驱动轴故障的产生原因比较难确定。
3 影响因素确定
本文所用的数据是来自S公司的J平台车型的驱动轴售后保修数据,根据J平台车型驱动轴的分析数据来看,漏油故障占比约86%,抖动问题和异响问题占比约14%,而其中抖动异响问题中很大一部分也是由于漏油造成的,因此如果能够解决漏油问题,那么对J平台车型驱动轴故障率降低有很大帮助,漏油问题产生的环节比较复杂,可能产生于驱动轴生产到维修过程中任何一个环节。根据售后数据的分析、失效件的分析记录、漏油的鱼骨图分析(图3)和相关的FMEA分析等,最终排除相关性较低的因素,确定有10个主要影响因素:行程里程、行驶时间、整车厂质量水平、维修站质量水平、卡箍夹紧力、驱动轴工作摆角、汽车发动机排量、汽车最大扭矩、行驶地区道路状态、行驶地区温度情况。
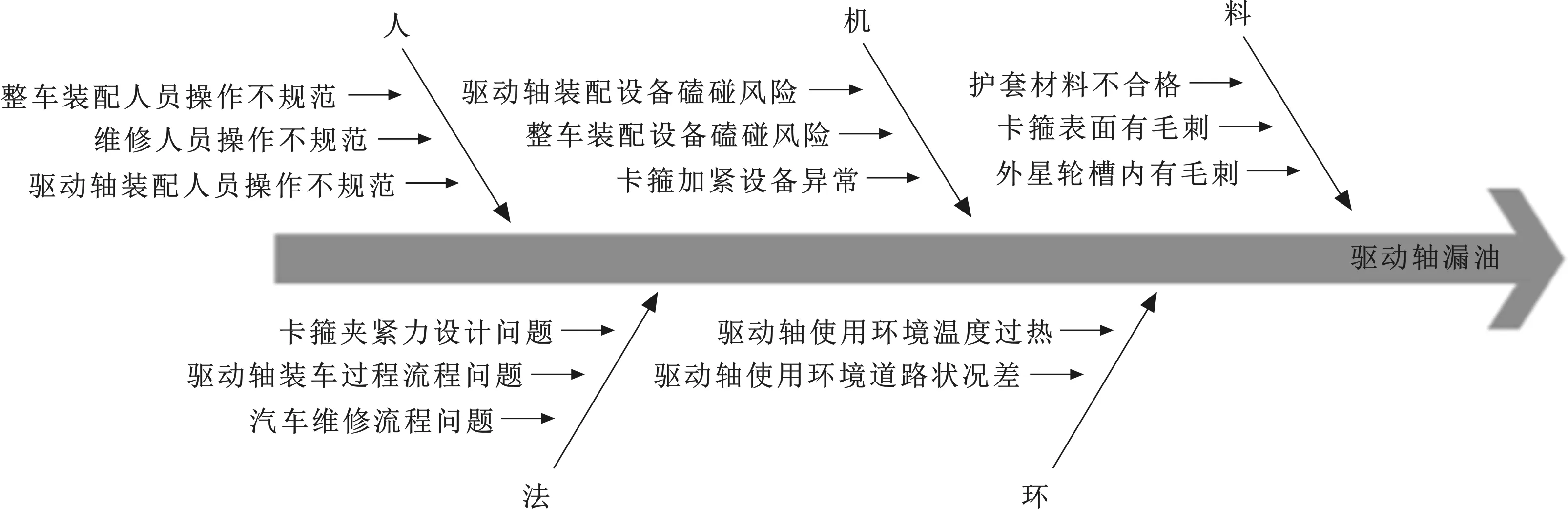
图3 驱动轴漏油鱼骨图分析
4 预测流程
遗传算法优化BP神经网络的过程有3个主要步骤:第一步就是确定BP神经网络的参数,如网络层结构、隐含层节点数量、学习率等;第二步就是确定遗传算法的参数,如种群规模、变异概率等;第三步就是把遗传算法对BP神经网络的初始权值阈值进行优化,通过选择、交叉、变异等方法进行进化,最终得到最优的初始权值阈值。再把这些值输入BP神经网络作为训练的初始权值阈值,然后通过大量学习训练,不断修正权值阈值,最终得到驱动轴故障率预测模型[14]。
5 模型参数选择
神经网络层数:相关文献研究表明1层的隐含层结构就可以对任意函数实现良好拟合,而输入层和输出层基本都是选择1层结构,因此本文选择的网络结构就是经典的3层网络结构。
学习率:根据相关的文献资料,一般的学习率选择0.01~0.10,通过使用这个区间不同的学习率代入模型进行测试,结果发现学习率为0.10的预测效果是最好的,并且训练时间短。
各层节点:输入层和输出层节点数是根据要研究的问题来确定的,本文输入因素是10个,因此输入层节点数选择为10,输出的结果就是故障率,因此输出层节点数选择为1。对于隐含层的节点个数,现在研究领域内还没有统一的确定标准,本文参考如下经验公式来确定隐含层节点个数,其中h、m、n分别是隐含层节点数、输入层节点数、输出层节点数,a是1~10之间的整数:
(3)
根据公式(3)得到h的取值为5~14,将这个区间的不同取值代入模型进行测试。最后结果表明隐含层节点数为6的模型的预测结果是最好的,预测精度最高。
模型算法:通过对最速下降法、拟牛顿法和LM算法的验证比较,结果发现LM算法预测结果更好,不容易陷入局部极小值,并且算法速度快,因此选择LM算法作为训练算法。
传递函数:隐含层和输出层的传递函数选择Logsig函数。
误差函数:使用均方误差函数MSE作为模型的误差函数。
遗传算法参数:通过把不同的参数值代入模型分别进行测试,最后根据模型的预测情况来选择最合适的参数值,其中种群的规模选取30,变异概率选取0.1,交叉概率选取0.4,进化代数选取100。
6 预测结果分析对比
首先在MATLAB中建立相应的程序,将确定好的模型参数输入程序中,对训练数据进行归一化处理,然后把数据导入模型中进行训练预测。图4为BP和GABP模型预测结果对比,其预测误差对比如图5所示,预测拟合度分别如图6和图7所示。
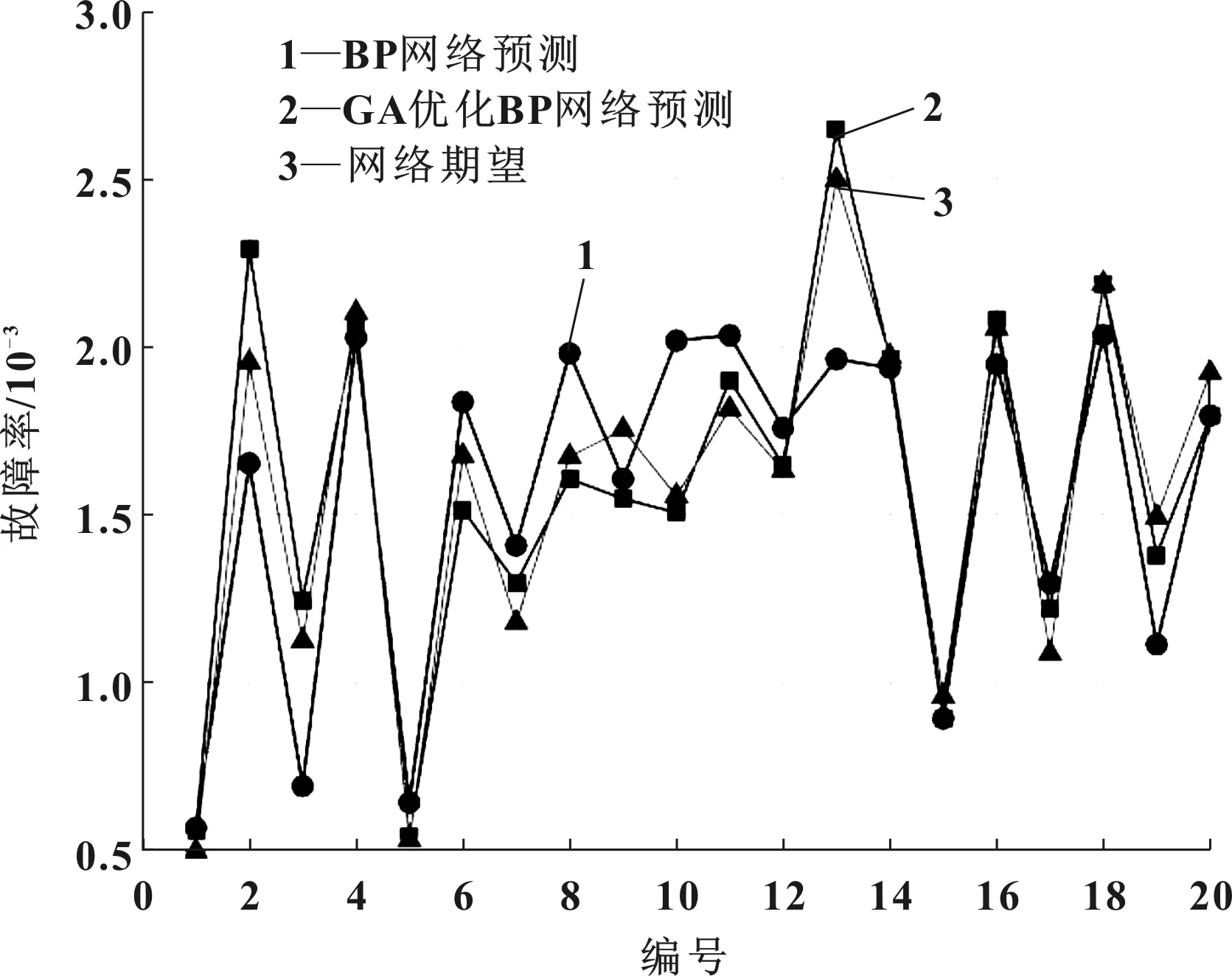
图4 BP和GABP模型预测结果对比
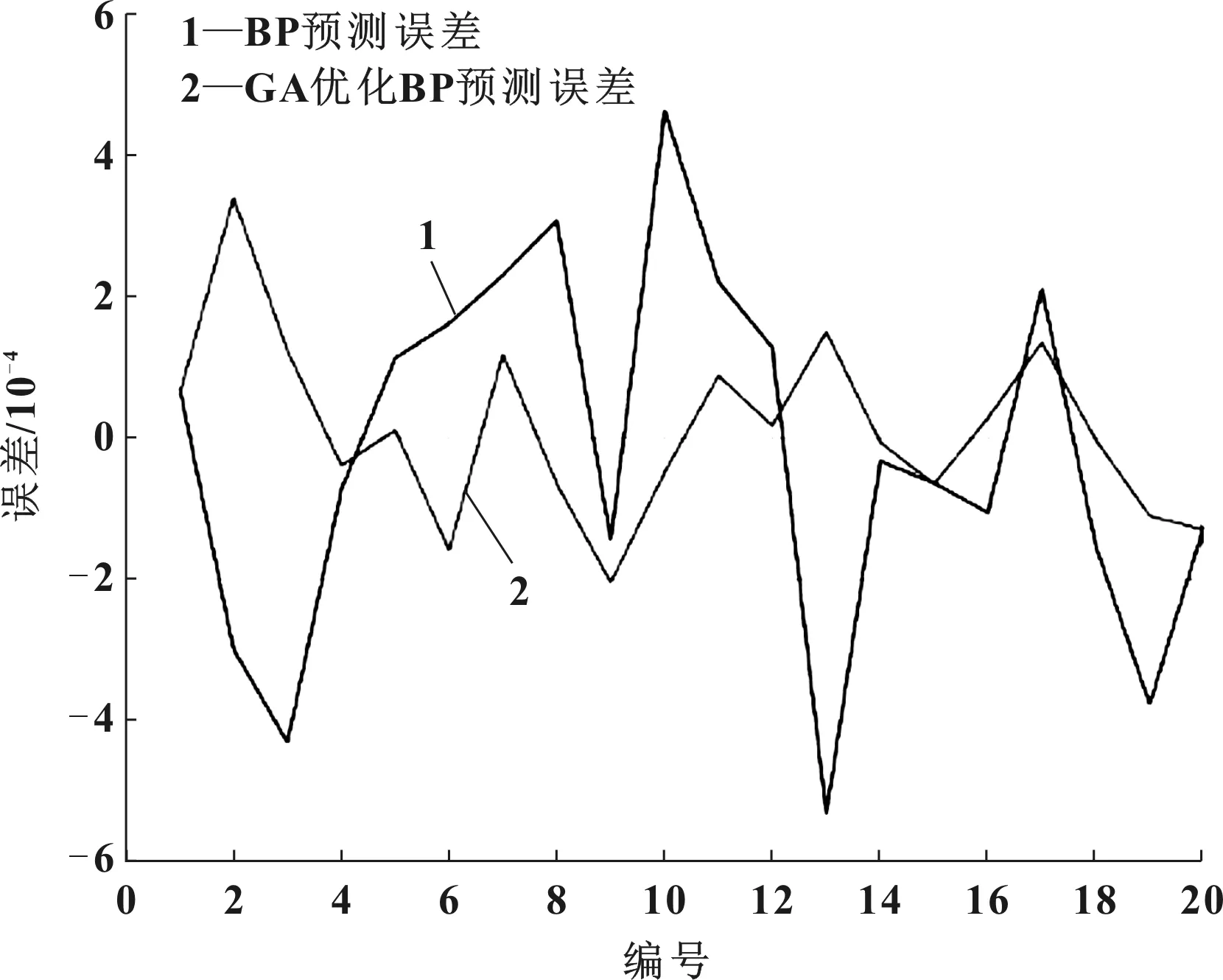
图5 BP和GABP模型预测误差对比
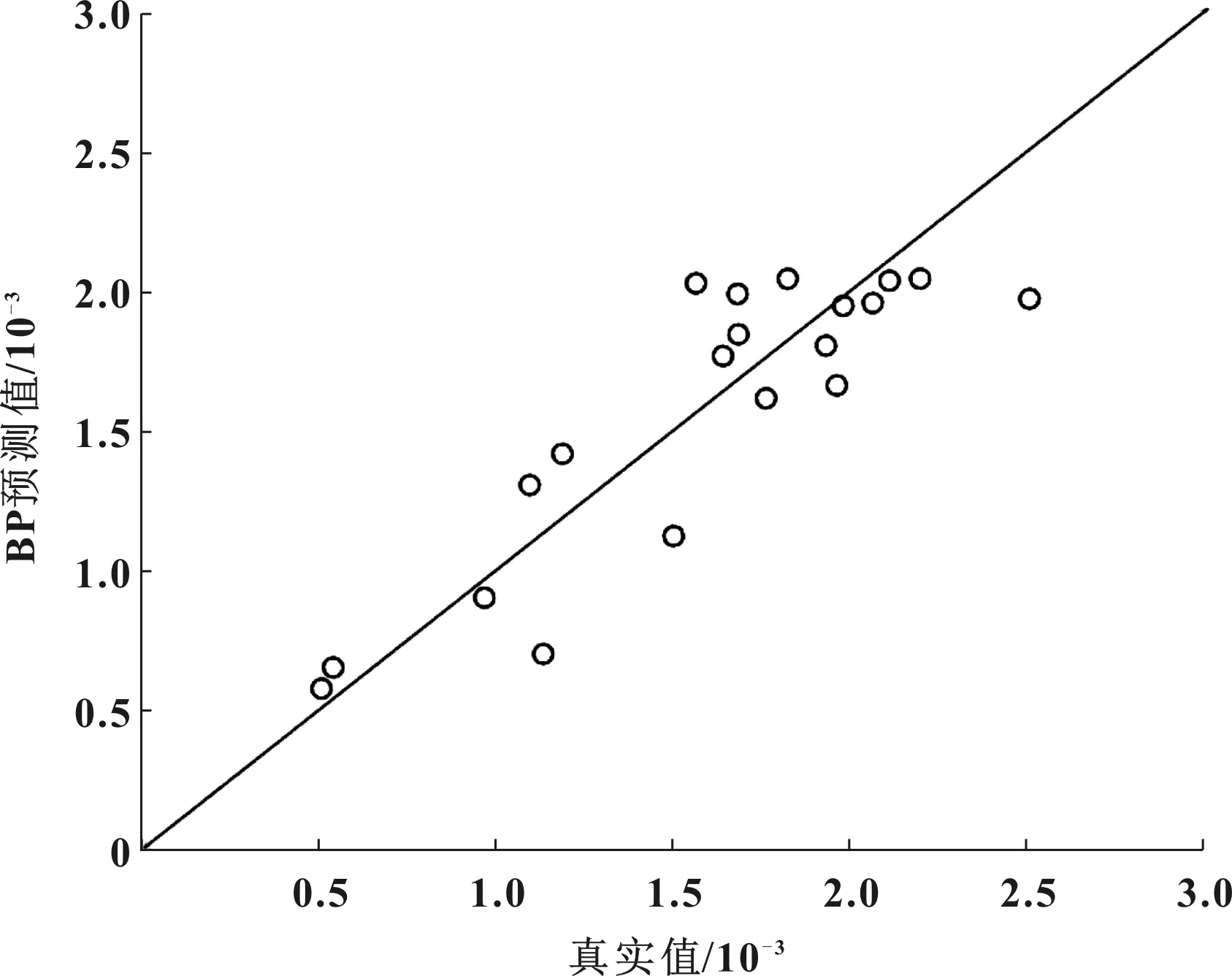
图6 BP模型预测拟合度
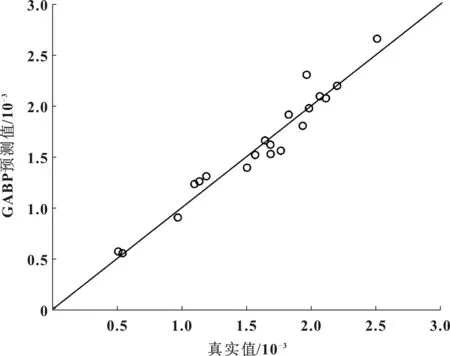
图7 GABP模型预测拟合度
由图4的BP和GABP模型预测结果对比可以看出,两个模型预测曲线和实际值曲线都比较接近,而GABP预测值相对BP预测值和实际值更加接近,说明GABP模型的预测精确度更高。由图5的预测绝对误差可以看出,GABP模型相对BP模型的预测误差更小,误差波动小,预测稳定性更高。由图6和图7的拟合度结果可以看出,BP预测模型的拟合度是87.8%,而GABP模型的拟合度是97.3%,GABP模型的预测拟合度相对BP模型提升很多,说明GABP模型预测性其中能有显著提升。
表1为BP和GABP模型的预测结果评价标准值。其中MAE是平均绝对误差,MARE是平均相对误差,MSE是均方误差,MSRE是均方相对误差,R2是拟合度。由表可以看出,MAE、MARE、MSE和MSRE这几个评价指标,GABP模型的数值都比BP模型的低很多,而GABP模型的拟合度比BP模型的拟合度提高很多,从这些分析可以得出结论,遗传算法对该BP模型有很好的优化效果,GABP模型的预测性能显著优于BP模型,预测精确度高,预测误差小,预测稳定性高。
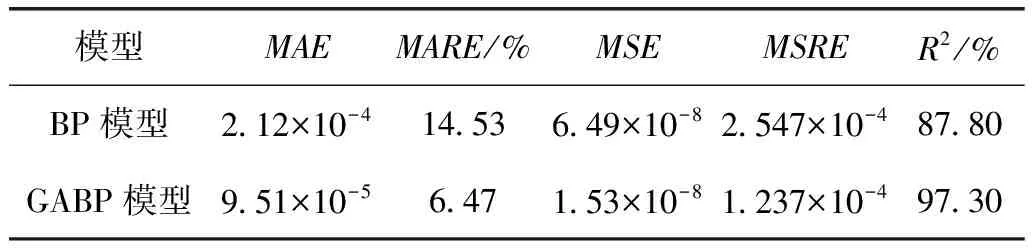
表1 BP和GABP模型的预测结果评价标准值
图8是线性回归模型预测结果,图9是随机森林模型预测结果,表2是GABP、线性回归和随机森林模型预测结果对比。从数据中可以看出MARE、MSE和MSRE数值都是GABP模型最低的,其次是随机森林模型。GABP模型的均方误差是1.53×10-8,随机森林模型的均方误差是2.67×10-8;GABP模型的拟合度是97.30%,随机森林模型的拟合度是83.95%。从这些模型的预测结果分析对比可以看出,GABP模型是预测性能最高的,预测精确度高,预测误差小;其次是随机森林模型预测性能良好,但是比GABP模型预测效果差;最后是线性回归模型的预测性能较差。
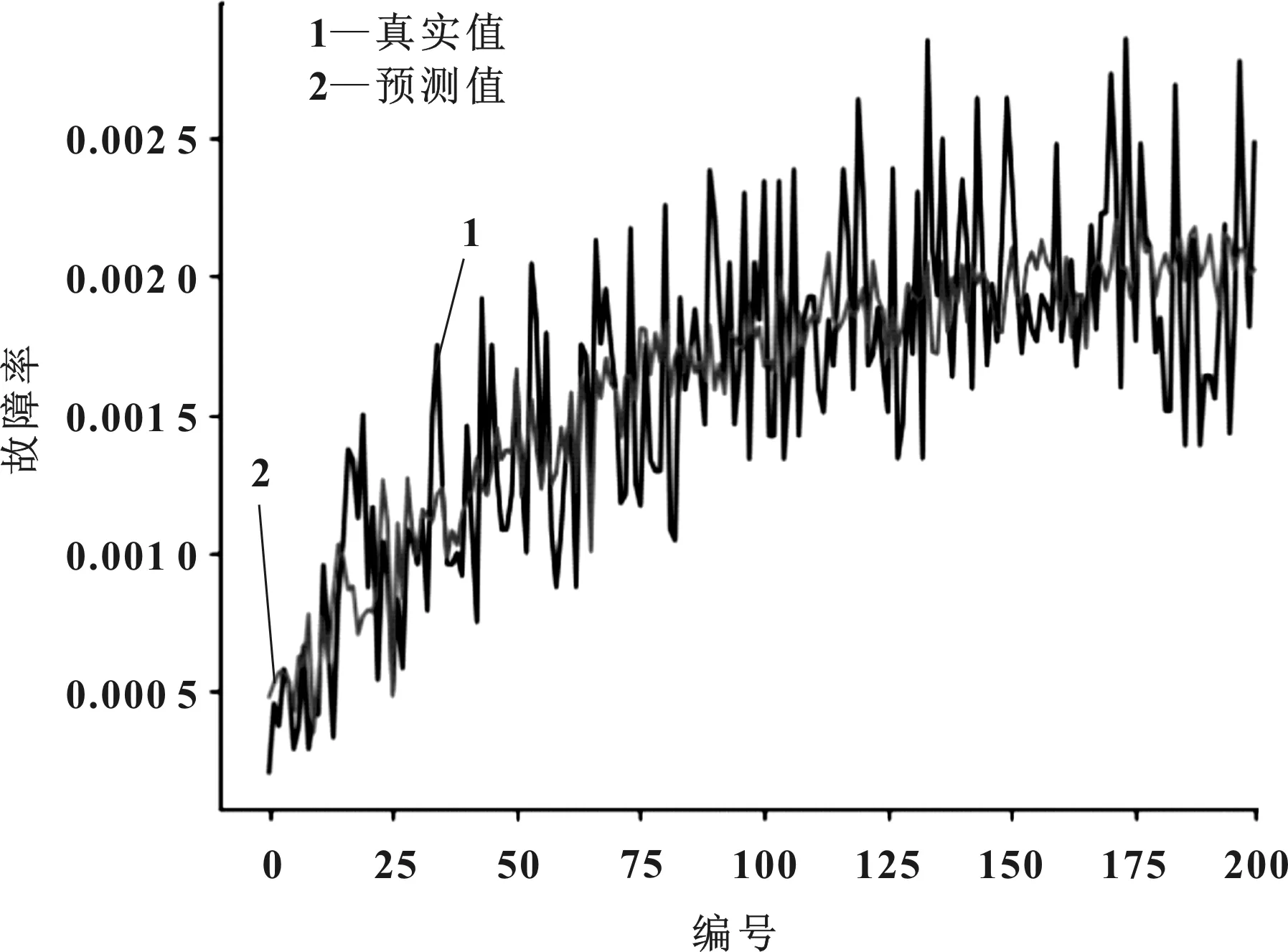
图8 线性回归模型预测结果
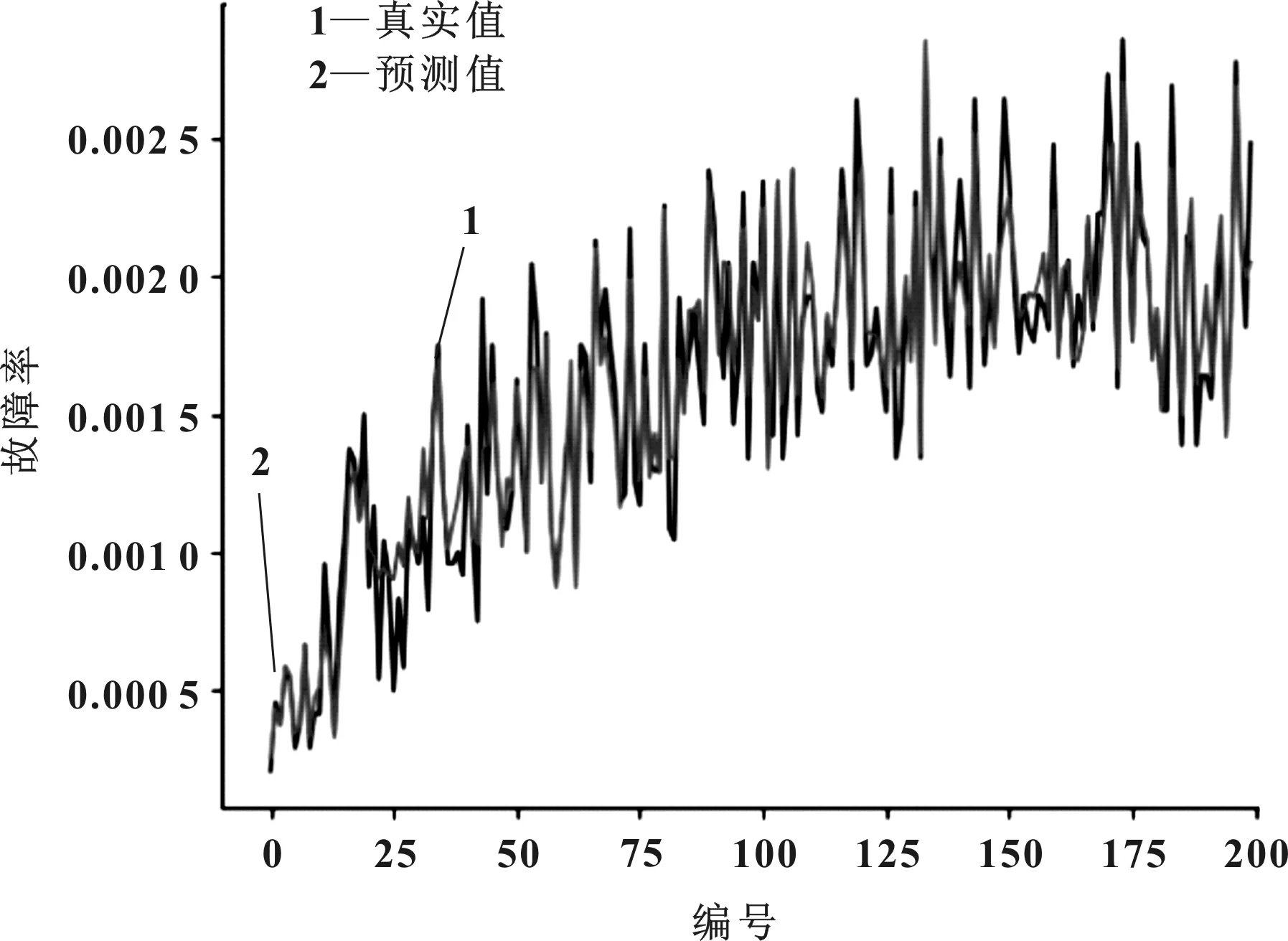
图9 随机森林模型预测结果

表2 GABP、线性回归和随机森林模型预测结果对比
7 敏感性分析
Garson算法是一种基于BP神经网络模型的敏感性分析方法,因为BP神经网络的训练就是通过不断调整权值来达到减少预测误差的,权值的数值一定程度上反映了输入参数对输出值的影响程度,而通过对权值进行相应的算法计算就可以得出这些输入参数对模型的影响程度,而Garson算法就是研究领域内认可的比较好的一种敏感性分析算法。Garson算法的公式如下:
(4)
式中:Rij为输入信号的相对重要性;wij为输入层到隐藏层的权值;wik为隐藏层到输出层的权值;i=1,2,…,N;k=1,2,…,M;N、M分别为输入信号和输出信号的个数。
根据敏感性分析方法进行计算,结果见表3。由表可知,对驱动轴故障率相对贡献度最高的3个因素是工厂建成时间(13.31%)、行驶里程(5.22%)和卡箍夹紧力(5.20%),该结果说明整车工厂的生产管理水平是该车型平台驱动轴故障率的最关键影响因素。因此则需要对该关键影响因素进行质量控制,从而降低故障率[15]。
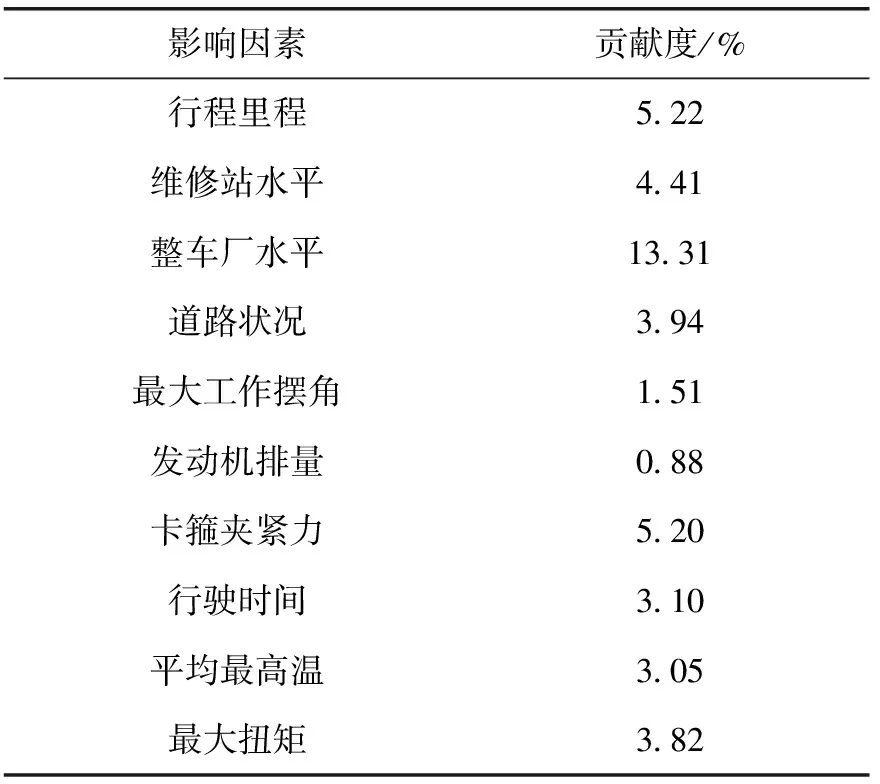
表3 敏感性分析结果
8 结论
(1)对于J平台车型的驱动轴而言,行程里程、行驶时间、整车厂质量水平、维修站质量水平、卡箍夹紧力、驱动轴工作摆角、汽车发动机排量、汽车最大扭矩、行驶地区道路状态和行驶地区温度情况是主要的故障率影响因素。
(2)提出了一种基于遗传算法优化BP神经网络的驱动轴故障率预测模型,预测平均误差在10%以内,该模型具有良好的预测性能,具有较高的预测精度和较好的预测稳定性,可以为汽车公司对于零件故障率的预测提供一定的参考。
(3)遗传算法GA对于BP神经网络模型预测性能有明显的优化作用,预测平均相对误差从14.53%优化到6.47%,均方误差从6.49×10-8优化到1.53×10-8,拟合优度从87.80%优化到97.30%。
(4)整车工厂质量水平是J平台车型驱动轴故障率的关键影响因素,其相对贡献度是13.31%,如果能对该因素进行严格的质量改善,那么可以显著提高该平台车型驱动轴质量水平以及降低故障率。
