结合注意力机制与深度强化学习的超短期光伏功率预测
2023-05-24丁正凯傅启明陈建平吴宏杰方能炜
丁正凯,傅启明*,陈建平,陆 悠,吴宏杰,方能炜,邢 镔
(1.苏州科技大学 电子与信息工程学院,江苏 苏州 215009;2.江苏省建筑智慧节能重点实验室(苏州科技大学),江苏 苏州 215009;3.苏州科技大学 建筑与城市规划学院,江苏 苏州 215009;4.重庆工业大数据创新中心有限公司,重庆 400707)
0 引言
太阳能作为最受欢迎的可再生能源之一,具有无污染、价格低、易获取和无运输等特点[1]。随着全球“碳达峰和碳中和”目标的提出,清洁能源得到进一步重视,其中太阳能便是备受关注的能源。太阳能发电主要是光伏(PhotoVoltaic,PV)发电,它能为世界提供清洁能源,在经济社会发展过程中减少对化石燃料的依赖,因此,光伏发电在全球范围内快速增长。太阳能虽然来源广泛,但它极易受光照随机性和昼夜周期性的影响,所以光伏发电系统发电具有不稳定性和不可控性。以上问题均可能会在电力系统的运行、调度和规划中造成严重的混乱,因此,需要对光伏发电功率进行精准预测。而精确度高的光伏功率预测同样会提高光伏电能的有效利用率以及电网运转效率,为减少经济损失提供帮助。
光伏预测研究可以通过不同的预测方法实现,包括物理方法、统计方法和深度学习。物理预测方法通常不需要历史数据,而是依赖地理信息、精确的气象数据和完整的光伏电池物理模型信息[2];然而由于地理数据分辨率低,很难得到准确的光伏组件的物理模型以及操作参数,导致物理预测方法的精确度不高。统计方法通过建立一种映射关系,使用历史数据来预测未来的功率[3];但由于光伏功率的波动性大,导致统计方法的泛化能力不强。近年来,深度学习由于有足够的特征提取和转换能力,得到了大量研究者的关注。文献[4]中提出了一种基于人工神经网络的太阳能功率预测模型,并选择气象数据作为模型的输入,但模型精度较低。光伏发电功率的预测属于时间序列预测的范畴,因此文献[5]中提出了使用基于长短时记忆(Long Short-Term Memory,LSTM)网络的深度学习方法捕捉太阳辐照度行为,利用日前天气预报数据作为预测输入;然后,利用物理理论建立了辐照度与光伏功率之间的数学模型,实现了间接预测。为进一步提高预测精度,文献[6]中提出Attention-LSTM 模型预测超短期光伏功率,利用注意力(attention)机制通过对LSTM 的输入特征赋予合理的权重来提高准确率;而且文献[7]中同样利用Attention-LSTM 模型预测短期风力发电功率。文献[8]中使用模态分解来分解序列,然后利用LSTM 预测光伏系统短期发电量。文献[9]中则利用多个深度学习模型预测多个结果,然后利用强化学习(Reinforcement Learning,RL)寻找多个预测模型的最优权重,以此来预测光伏功率值(并未直接使用强化学习预测光伏功率值)。虽然深度学习在光伏功率预测方面取得了大量的研究成果,但受光伏功率波动性以及复杂天气因素等的影响,上述模型仍具有一定的预测误差,得到准确预测结果以及泛化能力强的模型仍然非常困难。
深度强化学习(Deep Reinforcement Learning,DRL)作为深度学习和强化学习交叉的一个领域,它整合了深度学习的非线性拟合能力以及强化学习的决策能力,同样活跃在人工智能领域。DRL 在游戏[10]、机器人[11]以及其他控制决策领域得到了大量的研究及应用。在PV 领域,最近的一些研究工作已经开发了基于DRL 的模型应用于PV 系统的优化控制,并取得良好的性能。文献[12]中利用DRL 方法调度光伏电池储能系统容量,能够在连续动作空间确定具体的充电/放电量,以此确保系统的安全和经济运行。文献[13]提出的基于DRL 的光伏系统控制方法能够在部分阴影条件下获取PV 系统的最大功率点,使PV 系统高效运行,获得最大化效益。综上所述,DRL 技术已经应用于PV 系统决策控制领域,但在光伏功率预测领域的研究还不多。
针对上述问题,本文提出两种基于attention 机制的DRL模型——基于attention 机制的深度确定性策略梯度(Attention mechanism based Deep Deterministic Policy Gradient,ADDPG)模型和基于attention 机制的循环确定性策略梯度(Attention mechanism based Recurrent Deterministic Policy Gradient,ARDPG)模型来预测光伏功率,将光伏功率预测问题建模成强化学习问题,即将预测问题转化为决策问题。本文系统地研究了DRL 算法在光伏功率预测中的潜力,对ADDPG 和ARDPG 模型和其他深度学习模型进行了详细的比较与分析,验证了DRL 在PV 预测领域的可行性与可靠性。
1 相关研究
1.1 强化学习
强化学习(RL)[14]是一种通过与环境互动进行的试错学习,目标是使agent 在环境互动中获得最大的累积奖励。RL问题可以建模为马尔可夫决策过程(Markov Decision Process,MDP),如图1 所示。MDP 是五元组

图1 MDP示意图Fig.1 Schematic diagram of MDP
1)S代表状态空间。st∈S表示智能体(agent)在时刻t的状态。
2)A代表示动作空间。at∈A表示智能体在时刻t选取的动作。
3)r:S×A→R表示奖赏函数。
4)p1表示状态的初始分布。
5)P:S×A×S→[0,1]表示状态迁移概率分布函数。
经典强化学习算法如Q 学习便是将Q值存入Q 表中,但当环境过于复杂,导致空间维度过大时,经典算法便很难处理这类问题。深度强化学习(DRL)的提出,能够一定程度上解决以上问题。
1.2 深度确定性策略梯度
Lillicrap 等[15]提出了基于Actor-Critic 框架的策略梯度DRL 算法——深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG),主要用于解决连续动作空间的问题。
在强化学习中,策略梯度(Policy Gradient,PG)被用来处理连续动作空间问题,PG 直接参数化策略πθ(a|s)(θ∈Rn),则目标函数变为J(πθ)=E[G1|πθ]。Sutton 等[16]提出了如下的随机策略梯度定理:
在随机问题中,由于状态空间和动作空间的整合,随机策略梯度(Stochastic Policy Gradient,SPG)可能需要更多的样本,这也增加了计算成本。Silver 等[17]提出了确定性策略梯度(Deterministic Policy Gradient,DPG)算法,使用确定性策 略μθ:S→A(θ∈Rn),目标函 数变为J(μθ)=E[G1|μθ]。确定性策略梯度理论如下:
在DDPG 中,Actor 网络用于评估状态s下选择的动作,Critic 网 络用于评估Q(s,a)。DDPG中有一对Actor网络和Critic 网络,如图2 所示。在线Actor 网络和目标Actor 网络分别被定义为μ(s|θμ)和μ(s|θμ'),在线Critic 网络和目标Critic网络分别由Q(s,a|θQ)和Q(s,a|θQ')表示,其中θμ、θμ'、θQ以及θQ'都是网络参数。如图2 所示,agent 观察到当前状态s,通过在线Actor 网络执行动作a,动作a继而影响环境,从而agent 观察到下一个状态s'以及从环境中根据奖赏函数得到奖赏r,从而得到经验样本(s,a,r,s'),再将样本存储到经验池中。当经验池达到了一定的容量,agent 便开始学习。在线Actor 网络则根据在线Critic 网络输出的Q值,继而使用确定性策略梯度定理来更新网络参数,并不断接近最优策略来作出最优的动作,目标函数为J(θμ)=E[Q(s,μ(s|θμ)|θQ) ],它的梯度如下:

图2 DDPG模型Fig.2 DDPG model
Critic 网络是用来评估Q值的神经网络,用yi=r(s,a) +Q(s',μ(s'|θμ')|θQ')定义在线Critic 网络的目标,yi通过奖赏以及目标Critic 网络输出的Q值得出。在线Critic 网络使用以下梯度更新:
目标Actor 网络和目标Critic 网络的参数都采用软更新方法来保证算法的稳定性,如下所示:
其中:τ是一个远小于1 的正数。
1.3 循环确定性策略梯度
在传统的DDPG 方法中,多层感知器(Multi-Layer Perceptron,MLP)由多层全连接层组成,用于Actor 网络和Critic 网络。但简单的全连接层都是前向传播,并没有记忆的功能,为改善这一问题,将Actor 网络全连接层替换为LSTM 网 络。LSTM 网 络[18]是一种 改进的 循环神 经网络(Recurrent Neural Network,RNN)。由于梯度消失和梯度爆炸的问题,传统RNN 的学习能力仍然有限,实际效果往往不理想。LSTM 在对有价值信息进行相对长时间记忆的优势使它在时间序列预测中得到广泛应用。LSTM 的改进在于引入三个门的概念,结构如图3 所示。LSTM 模型含有3 个输入,分别是当前时刻输入样本xt、上一时刻的短期记忆信息ht-1以及上一时刻的长期记忆信息Ct-1;结构内部有3 个门来控制记忆信息与当前信息的遗留与舍弃,分别为遗忘门ft、输入门it和输出门Ot:

图3 LSTM模型结构Fig.3 LSTM model structure
其中:w、b为控制门的权重矩阵与偏置向量;σ为Sigmoid 激活函数。由式(6)计算得到3 个控制门的输出后,可以进一步计算得到长期记忆信息Ct、短期记忆信息ht与单元最终输出qt:
其中:tanh()为双曲正切函数;*为Hadamard 积。
循环确定性策略梯度(Recurrent Deterministic Policy Gradient,RDPG)的Actor 网络由全连接层替换为LSTM 网络,增加了记忆功能,但LSTM 的模型参数远大于全连接层的参数,会导致训练时间过长。RDPG 与DDPG 唯一不同的地方在于Actor 网络的全连接网络替换为LSTM 网络,具体模型结构可参考图2。
1.4 attention机制
attention 机制[19]模拟人类大脑如何处理信息,提高了神经网络处理信息的能力。它的本质在于学习出一个对输入特征的权重分布,再把这个权重分布施加在原来的特征上,使任务主要关注一些重点特征,忽略不重要特征,提高任务效率。在输入的序列后加入attention 网络,设输入序列向量为E=[e1,e2,…,et],则attention 机制的计算公式如下:
其中:W是权重矩阵,与输入序列E作矩阵运算再经过Softmax 激活函数,最后和输入序列相乘得出新序列E'。
attention 机制能突出重要影响的特征,减小无用的特征影响,使模型作出更优的选择,提高预测的准确度。
1.5 基于attention机制的DRL
在预测领域中,深度学习凭借强大的非线性能力以及特征提取能力表现出不错的性能。DDPG 和RDPG 作为深度学习和强化学习的结合体,同时具有这两者的优势。将预测问题建模为一个MDP 问题,即将预测问题转化为决策问题,便可通过DRL 来求解最优问题。DRL 不需要样本标签,而且是动态学习的过程。DRL 能够在一个未知的环境中,通过与环境的不断交互学习到其中的关键信息,作出最有利的决策。在光伏功率预测问题中,可以将已有的历史数据建模为一个环境,DRL 便可以在该环境中进行训练,在观察到一个未知状态后,DRL agent 能够利用所学到的经验知识作出准确的预测。
DDPG 和DRPG 模型都采用Actor-Critic 架构,其中Actor网络通过观察当前状态来执行动作,Critic 网络则评估当前状态-动作的价值函数,Critic 网络通过更新近似最优的状态-动作价值函数来指导Actor 网络执行动作,同样Actor 网络执行更优的动作使Critic 网络学到更加准确的状态-动作价值函数,Actor 网络与Critic 网络互相影响与指导,最终来作出最优的选择。
在PV 预测问题中,输入量通常为前几个时刻的历史功率数据以及当前的天气数据,其中存在对下一时刻功率影响较大的量,同样也会存在影响较小的量。传统DDPG 和RDPG 中的Actor 网络由全连接网络和LSTM 网络构成,它们很容易忽略其中的关键信息,从而导致预测精度下降。文献[6,8]的研究工作说明,attention 机制能够提高模型的光伏功率预测精度,因此,本文考虑将attention 机制加入DDPG 和RDPG 中的Actor 网络中,Actor 网络利用attention 机制捕捉状态中的重要信息,帮助Actor 网络作出最优的动作预测,即给出最准确的光伏功率预测值。
2 光伏功率预测模型建模
传统的深度学习模型如卷积神经网络(Convolutional Neural Network,CNN)和LSTM 虽然有很强的非线性拟合能力,但它们还是缺乏DRL 的决策能力,易受功率随机波动性影响,对于某些时刻不能作出准确的光伏功率预测,导致精度下降。而将attention 机制加入DRL,使得DRL agent 能够从当前观察的状态中捕捉到影响光伏功率的关键因素,从而作出准确的光伏功率预测。
本章将详细介绍基于attention 机制的DRL 的模型——ADDPG 和ARDPG。图4 是本文的研究框架。首先,从案例光伏系统收集功率数据,分辨率为5 min。此外,还引入了影响光伏功率的一些相关的气象数据,以提高预测精度和稳健性。然后,建立数据集,对数据进行预处理。最后输入ADDPG 和ARDPG 模型进行预测。
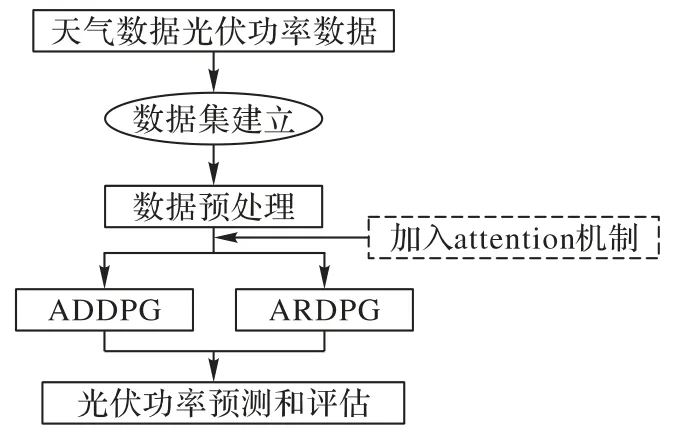
图4 本文研究框架Fig.4 Research framework of this paper
2.1 数据预处理
数据预处理过程主要包括两个任务,即异常值检测和数据标准化。模型开发前应移除数据中的异常值,因为这些异常值和低质量的数据会对模型产生负面影响,因此剔除明显不符合实际情况的值后,用线性插值法来完成代替。在数据标准化方面,采用如式(9)的最大最小值归一化,目的是使每个输入特征处于相似的尺度上,有助于在应用预测技术时通过Adam 算法找到全局最优。
其中:X为样本值,Xmin为样本中的最小值,Xmax为样本中的最大值,Xnorm即为归一化后的值。
2.2 MDP建模
使用强化学习解决问题,需要先将本次预测问题建模成MDP。在本次研究中,所有的模型预测都是单步预测,即使用前1 h 内的所有功率数据以及当前时刻的气候数据作为输入,输出即为当前时刻的预测功率。状态、动作和奖赏定义如下:
1)状态空间。状态空间如表1 所示。agent 在每个时间步上所 观察到 的状态 向量为[WSt,TEt,RHt,GHRt,DHRt,WDt,RGTt,RDTt,APt-1,APt-2,…,APt-13],包括当前时刻的天气和气候状况及前1 h 内的功率数据,以此来预测当前时刻的功率输出。状态空间由每个时间步的状态组成。

表1 状态空间Tab.1 State space
2)动作空间。动作空间由0 到22.2 的连续功率值组成(该范围根据历史数据设定)。在训练过程中,agent 根据观察到的状态输出[0,22.2]中的功率值,输出值即为功率预测值。
3)奖赏函数。奖励函数设置如下:
其中:APt表示时间步t的实际功率值;at表示agent 在时间步t执行的动作即预测功率值。如果输出动作接近实际输出功率,则奖励将接近于零,否则奖励会变小。
2.3 算法实施
一旦光伏功率预测问题转化为决策问题,就可以应用DRL 技术来解决。基于attention 机制的DRL 的预测模型的训练框图如图5 所示。在模型中,都是使用前1 h 内的所有功率数据以及当前时刻的气候数据来预测当前时刻的功率。首先将历史光伏数据以及气象数据建立成一个供DRL agent学习的环境;然后agent 观察到当前状态s,通过在线Actor 网络执行动作a即光伏功率预测值,动作a继而影响环境,从而使agent 观察到下一个状态s'以及从环境中根据奖赏函数得到的奖赏r,得到经验样本(s,a,r,s')后存储到经验池中。在线Critic 网络从经验池中随机选取一小批样本利用式(4)更新网络参数,从而逼近最优的Q值;目标Critic 网络则通过式(5)软更新网络参数。在线Actor 网络根据在线Critic 网络输出的Q值,利用确定性策略梯度即式(3)来更新网络参数;目标Actor 网络则同样通过式(5)软更新网络参数。最终Actor网络能够观察当前状态并作出最优的动作,即最准确的光伏功率预测。
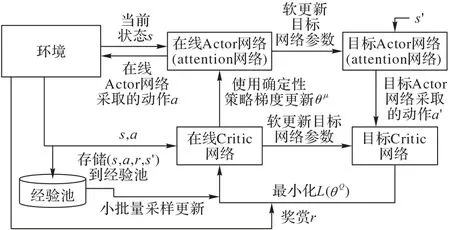
图5 基于attention机制的DRL的训练框图Fig.5 Training block diagram of DRL based on attention mechanism
2.3.1 ADDPG
图6 的attention 网络由一个全连接层以及Softmax 激活函数组成。首先,输入向量经过第一个全连接层,然后经过Softmax 激活函数得出输入向量中各个分量的权重Wi,再与输入向量作乘法得出新的向量。ADDPG 中的Actor 网络使用attention 网络代替全连接层,结构如图7 所示。使用attention 网络结构来代替图中虚线框中的结构,输入向量为观察到的状态st,经过attention 网络对状态中的各个分量施以不同的权重以捕捉其中重要的信息,从attention 网络输出经过一个全连接层再经过Sigmoid 激活函数得出功率预测值。接着便可使用ADDPG 进行光伏功率预测。
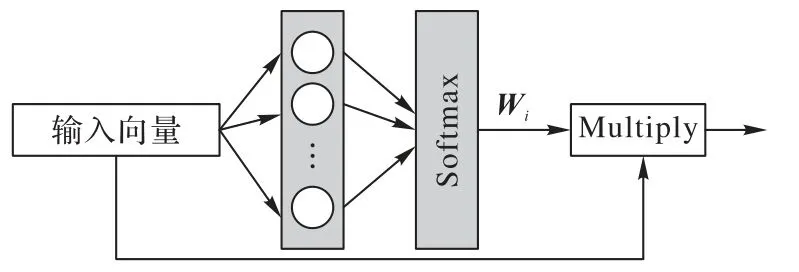
图6 Attention网络结构Fig.6 Attention network structure
首先根据式(9)将训练数据归一化,使数据都变换到相似的尺度上。然后,根据算法1 训练模型,详细训练过程描述如下:首先,随机初始化在线Critic 网络和在线Actor 网络,并将它们的参数复制给相关的目标Critic 网络和目标Actor网络;经验池D初始化为空集。对于每一次迭代,状态都会初始化为s0;在每一个时间步长上,动作at基于在线Actor 网络选取并在其中添加噪声Nt来增强算法的探索性能,然后从环境中观察到下一个状态st+1,并根据式(8)从环境中得到奖赏rt;将经验样本(st,at,rt,st+1)存储到经验池D中供算法训练;当经验池D中收集到足够多的样本后,便会从中随机选取一小批样本来更新在线Critic 网络和在线Actor 网络的网络参数。其中,在线Critic 网络的损失函数L是目标Q值yi和当前Q 值Q(si,ai|θQ)的均方误差;在线Actor 网络则利用采样的确定性策略梯度来更新网络参数。最后,目标Critic 网络和目标Actor 网络的参数都通过软更新即式(5)以保证算法训练的稳定性。
算法1 用于光伏功率预测的ADDPG 算法。
2.3.2 ARDPG
ARDPG 的Actor 网络使用attention 网络来代替LSTM 层后面的全连接层,详细结构如图8 所示。输入观察到的状态st经过LSTM 层,使用attention 网络结构来代替图中虚线框中的结构即全连接层,再经过Sigmoid 激活函数得出功率预测值。通过attention 机制,LSTM 网络能够筛选出更具有价值的信息,以此来提高预测精度。综上所述,attention 网络能够捕捉到状态之间的依赖关系,并且能够给出各个分量的权重以及降低功率的非稳定性,以此来作出准确的预测。
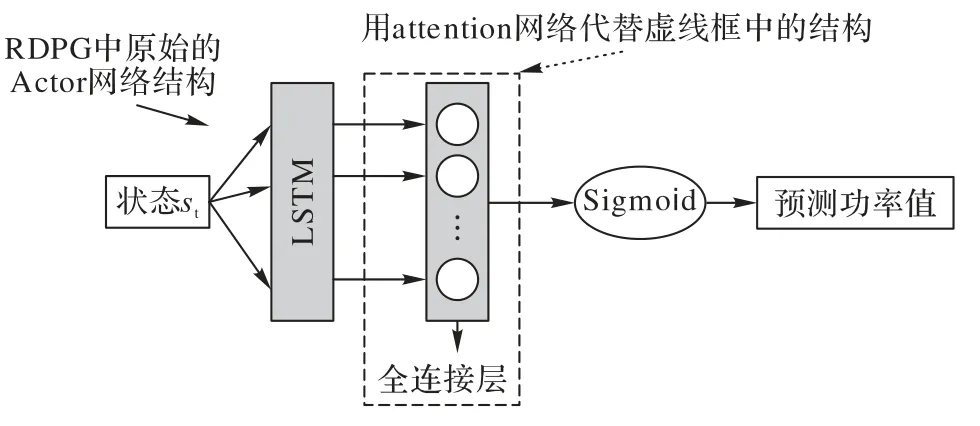
图8 ARDPG的Actor网络结构Fig.8 Network structure of Actor in ARDPG
然后便可使用ARDPG 来进行光伏功率预测。与ADDPG 类似,同样将训练数据根据式(9)归一化,将数据都变换到相似的尺度上;然后,便可根据算法1 来进行训练模型。ADDPG 和ARDPG 的唯一区别在ARDPG 在Actor 网络中使用LSTM 网络,其余的训练方式和ADDPG 都相同。
3 实验与结果分析
本文选用1B DKASC、Alice Springs 光伏系统数据[21],选取2016 年4 月1 日至2016 年6 月1 日的数据进行实验。
原始数据的分辨率为5 min,由于光伏组件在早上和晚上的功率输出明显较低,即大部分时间为0 或接近0。因此,只考虑在6:55~18:30 的功率,数据被标准化,去掉离群值,使用插值算法根据上下时刻信息对缺失值进行填充。图9显示了案例数据中连续几天的历史数据。可以看出,中午时的功率最大,上午和下午的功率相对较小,而晚上趋于0。下载的数据主要包括当前有功功率、风速、天气温度摄氏度、天气相对湿度、水平面总辐射、水平面漫射辐射、风向等。数据集被分成两部分,比例为8∶2,分别用于模型训练和测试。

图9 部分光伏数据Fig.9 Partial PV data
3.1 参数设置
通过不断的参数调整、组合与寻优,DDPG、RDPG、ADDPG 和ARDPG 的参数设置如下:学习率α为0.001,由于更加关注当前的奖赏,所以折扣因子γ设为0.1,τ为0.005,DDPG 网络的隐藏层为2 个全连接网络,分别有64 个神经元和32 个神经元,RDPG 的LSTM 为50 个神经元,attention 网络的神经元为21 个,优化算法均为Adam,经验池大小均为10 000,采样大小均为64,强化学习里的超参数为常用参数设置。
基于相同的输入变量,本文基于图4 的框架还开发了基于CNN、LSTM、BP 神经网 络(Back Propagation Neural Network,BPNN)、DDPG、RDPG、CNN+attention 和LSTM+attention 的预测模型。LSTM、CNN 和BPNN 的参数设置如下:LSTM 网络有50 个神经元;CNN 有30 个过滤器,卷积核的尺寸为2×2,步长为2;BPNN 为2 个全连接网络,分别有64 个神经元和32 个神经元,深度学习模型的学习率、优化算法都与DRL 模型相同。
3.2 评估指标
本文使用均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)和决定系数(R2)评估所提出模型的预测精度。MAE 用绝对误差表示实际值和预测值之间的平均偏差,而RMSE 表示实际值和预测值残差的标准偏差。MAE 和RMSE 都是与尺度相关的指数,并在其原始尺度中描述预测误差,值越小代表模型预测越精确。回归模型中通常使用R2来评估回归模型的预测值和实际值之间的拟合度,值越接近1 代表模型越精确。上述指标的计算公式如下:
其中:zi是时间点i的实际值;pi是时间点i的预测值;表示N个实际光伏功率值的平均值;N表示样本数。
3.3 对比分析
3.3.1 ADDPG、ARDPG与DDPG、RDPG的比较
光伏功率数据和气象数据都是连续数据,这4 个模型都能够处理连续问题,它们的奖赏如图10 所示。可以看出在前10 个episode 内ADDPG 的奖赏还在上升阶段但最终会收敛,其他三个模型的奖赏在前10 个episode 内都几乎已经趋于稳定,最终ADDPG 的奖赏略高于对比模型;ADDPG 和ARDPG 的奖赏都要比未加入attention 机制的DDPG 和RDPG的奖赏要高。这表明attention 机制能够提高模型的性能。在开始的几个episode 内奖赏都很低,这是由于前期存储经验池随机选取,一旦开始学习,这4 个模型很快便能学到数据的关键知识,并能根据当前观察到的状态来选取最优动作,即功率预测值,以得到最大的奖赏,从而作出准确的预测。

图10 四个模型的奖赏图Fig.10 Reward diagram for 4 models
图11 显示了单步预测中9 个模型(包括CNN、LSTM、BPNN、DDPG、RDPG、CNN+attention、LSTM+attention、ADDPG和ARDPG)的预测结果。其中:实线表示理想拟合线,表示预测值与真实值相等;两条虚线代表±20%的误差线,表明预测值比真实值大20%或小20%;横轴是真实光伏功率值,纵轴为光伏功率预测值。可以观察到,ADDPG 和ARDPG 的预测的准确性比DDPG 和RDPG 都要高,在±20%的误差线外的预测点都有所减少。从图11(a)、(b)对比可以看到,更多的预测点从偏离理想拟合线到集中到理想拟合线的附近。从图11(c)、(d)可以看到,RDPG 模型预测值更多地偏向+20%的误差线即预测值偏高,ARDPG 模型能够有效缓解这种情况,将预测值集中到理想拟合线附近。但RDPG 模型与DDPG 相比并没有显示出优势,这一结果与预期不符,这可能是由于单步超前光伏功率预测并不复杂,DDPG 模型足以捕获序列之间的关系。ADDPG 模型与ARDPG 模型的性能并没有明显的差距。由于ADDPG 与ARDPG 的Actor 网络利用attention 机制对观察到的状态向量进行合理的权重分配,提高了对历史光伏功率数据以及天气数据的敏感度,强化了特征提取能力,因此预测的准确性更高。
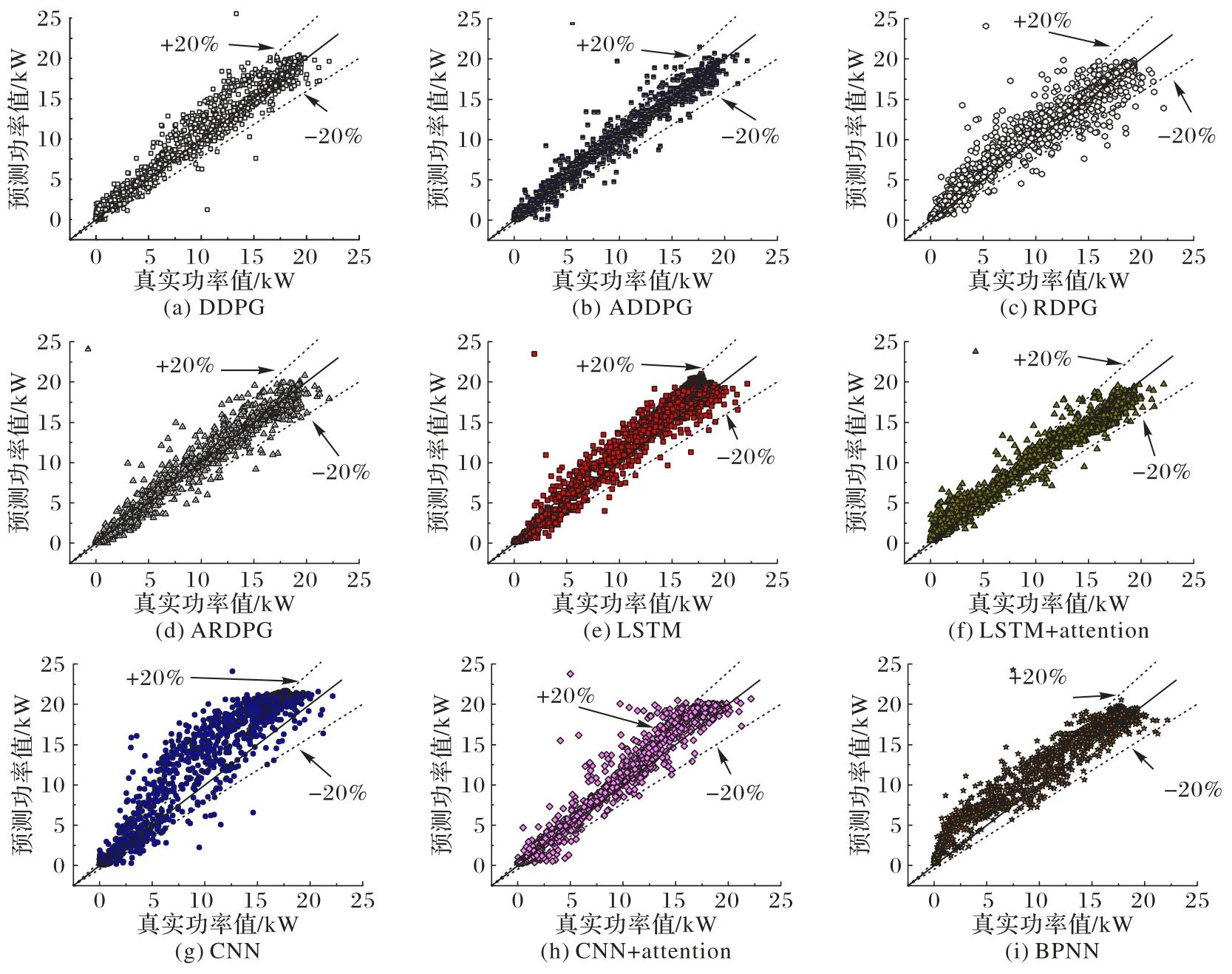
图11 九个模型的预测结果Fig.11 Prediction results of nine models
3.3.2 ADDPG和ARDPG与深度学习方法比较
图11(e)~(i)显示了单步预测中深度学习模型预测结果,从中可以观察到,ADDPG 和ARDPG 模型明显优于深度学习模型,这表明基于attention 的深度强化学习方法可以产生比深度学习方法更具前景的结果。
ADDPG 和ARDPG 模型预测的准确性相比深度学习方法均有明显提升,在±20%的误差线外的预测点减少很多。对比图11(b)、(d)和图11(e)~(i)可以看到,更多的预测点从偏离理想拟合线到集中到理想拟合线的附近。从图11(b)、(d)和(f)可以看到,LSTM+attention 模型的预测点在开始的前一段时间内超过+20%的误差线较多,ADDPG 和ARDPG 能够很好地预测在理想拟合线附近,在后一段中LSTM+attention 模型预测的结果偏向于-20%的误差线,即比ADDPG 和ARDPG 预测结果偏低。其次,LSTM 略差于DDPG模型,LSTM 本身便具有很好的记忆功能,能够较好地处理时间序列。CNN 和BPNN 都是前向神经网络,不具有记忆功能,处理时间序列能力比LSTM 要略差,因此比以上两个方法的性能要差。
从图11(e)、(g)中可以看到,原始的LSTM 和CNN 模型预测的结果都偏向+20%误差线,即预测偏高;在原始模型中加入attention 机制,从图11(f)、(h)可以直观看到,attention机制有效减少了偏高的预测点,尤其是CNN 模型,原始CNN模型更多地偏离误差线之外,attention 机制使其预测结果很大一部分都落入误差线范围以内,提高了预测精度。LSTM+attention 模型则同样利用attention 机制将经过LSTM 层输出的量进行权重分配,从关注全局到关注重点,快速得到有效的信息,从而提高预测精度。CNN+attention 模型同样筛选出重要信息、忽略无关信息,模型性能得到有效提升。在图11(i)中,BPNN 的预测结果很大一部分预测偏高。
使用3.2 节的三个评估指标来评估上述模型对测试数据的预测精度,并统计它们的训练时间(所有的计算都在Python 3.7 以及Pytorch 平台上执行),结果如表2 所示。
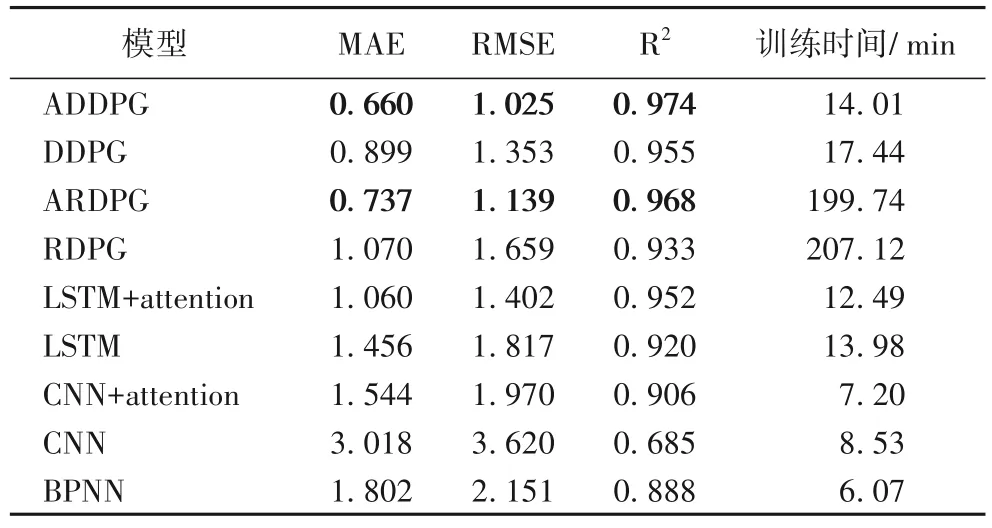
表2 测试数据的预测精度和训练时间对比Tab.2 Comparison of prediction accuracy and training time of test data
在MAE 和RMSE 的评估指标下:ADDPG 模型比DDPG降低了26.59%、24.24%;ARDPG 模型比RDPG 分别降低了31.12%、31.34%。在R2的评估指标下,ADDPG 模型比DDPG 提高了1.990%;ARDPG 模型比RDPG 提高了3.751%。可以看出,ADDPG 和ARDPG 比其他模型的预测精度都要高;而且无论是DRL 还是深度学习模型,加入attention 机制都能够更好地提升原始模型的预测精度。
DRL 的训练时间都要长于深度学习方法,其中BPNN 的训练时间最短,这是因为BPNN 结构最简单,仅由两层全连接层组成;所有模型中,RDPG 的时间成本最高,这是因为LSTM 的复杂结构使训练时间变长。同样可以看出各个模型加入attention 机制都可以略微减少训练时间,因为attention机制能使网络训练更有效率。
4 结语
本文针对超短期光伏功率预测,提出了基于attention 机制的深度强化学习(DRL)模型:ADDPG 和ARDPG,将光伏预测问题建模为MDP,再利用DRL 求解MDP。与三种常见的深度学习模型LSTM、CNN 和BPNN,加入attention 机制的深度学习模型以及未加入attention 机制的DRL 模型相比,ADDPG 和ARDPG 在RMSE、MAE 和R2上均取得了 最优结果;ADDPG 和ARDPG 在单步预测方面也都优于对比模型,验证了它们的有效性;不足之处在于ARDPG 的计算时间成本高。实验结果同时表明,在原始模型中加入attention 机制可以提高模型的性能,DRL 模型的光伏预测性能显著优于深度学习模型。未来将深入研究以提高多步预测的准确性,提出更具泛化能力的预测方案。
