基于CSI和K-means-SVR的多指纹库室内定位方法
2023-05-24裴生雷
王 逸,裴生雷,2*,王 煜
(1.青海民族大学 物理与电子信息工程学院,西宁 810007;2.人工智能应用技术国家民委重点实验室(青海民族大学),西宁 810007;3.天津大学 智能与计算学部,天津 300350)
0 引言
随着新一轮智慧城市的兴起,公众Wi-Fi 作为一项惠民工程,几乎普及到了我们周围的各个角落。尤其是在旅游景点中,绝大部分都已经实现了Wi-Fi 全覆盖,当游客的智能设备连接到景点的Wi-Fi 后,就能充分体验景点的各种个性化服务,如地图导览、景点介绍、实时讲解等。在游客享受更好服务的同时,景点也可以通过Wi-Fi 收集数据,包括每天服务人数、游客景点内轨迹分析、游览时间喜好、享用服务频次、游览时长等。通过分析这些数据,可以大幅提高景点的服务质量和应急响应能力。与蜂窝信号相比,Wi-Fi 信号传输速率更快、成本更低,并且使用频段在全球范围内都不受限制[1],所以景点全覆盖的Wi-Fi 网络将会受到更多游客的青睐。景点若想使用Wi-Fi 数据获取游客的游览轨迹、游览时长、游览喜好等数据,就要使用Wi-Fi 定位技术获取游客的位置。虽然室外定位技术非常成熟,如北斗定位系统[2]和蜂窝定位系统[3],都能实现非常精准的定位。但是,国内有许多重要的景点并不在室外,如故宫、兵马俑、黄鹤楼等,还有全国各地的生态、文化景点,游客更加需要旅游导览、实时讲解等服务,所以更需要室内定位来确定游客的位置,为游客提供更好的服务。但室内定位技术发展并不迅速。与外部环境不同,室内环境因有许多障碍物,导致北斗卫星信号的强度在室内也会大幅下降;而且为了保护历史古迹,许多古迹景点的蜂窝信号强度并不理想,尤其是在绝大部分Wi-Fi 覆盖的景点,Wi-Fi 信号强度要远强于蜂窝信号,所以在这些景点使用Wi-Fi 定位将会更加精准。
传统的Wi-Fi 室内定位使用接收信号强度(Received Signal Strength Indication,RSSI)数据,相较于传统的RSSI 室内定位[4-7],信道状态信息(Channel State Information,CSI)数据不仅在时间上具有稳定性,并且不同位置CSI 数据的特性变化明显,因而受到了广大学者的关注[8-10]。Wang 等[11]提出了RSSI 与CSI 相结合生成的混合指纹库的定位方法。孟俊剑等[12]用序列最小优化(Sequential Minimal Optimization,SMO)算法建立降维特征与相应位置的回归模型,并对位置进行预测。Dai 等[13]提出了基于K 近邻(K-Nearest Neighbor,KNN)算法的CSI 室内定位,但是每次定位都需要在线和指纹库的所有数据进行逐个对比匹配,定位效率不高。田广东等[14]利用了CSI 成簇分布的特性,使用了K 均值(K-means)聚类算法对CSI 数据进行特征提取,然后使用KNN 算法定位。党小超等[15]提出了CSI 的支持向量机(Support Vector Machine,SVM)回归的室内定位方法。这些基于CSI 的室内定位方法都分为离线阶段和在线阶段,其中离线阶段建立指纹库[16],在线阶段进行指纹匹配,最终实现定位。Rao 等[17]提出了DFPhaseFL 系统,首先从信道状态信息测量中提取原始相位信息,然后去除相位偏移,得到滤波后的校准相位信息,最后进行定位。然而,上述方法在两个阶段中采取的策略各有优缺点,尤其是离线阶段都使用单指纹库导致模型训练复杂度提高;而在线阶段,预测点数据需要与指纹库中所有数据进行匹配,定位效率不高。
Wi-Fi 室内定位应用场景多样,但是对于旅游景点等复杂场景下的应用,会受到时间段等因素的影响,导致人流量在不同时间、不同区域骤增或骤减。面对这些情况,传统的室内定位方法因受单指纹库的影响,无法充分利用系统资源。尤其是在线定位阶段,使用传统定位方法定位时需要与每个指纹点进行匹配,即使是闲置指纹点也要进行多次匹配,导致指纹库运行缓慢、延迟较高、体验较差。
本文将K 均值聚类算法与支持向量回归(Support Vector Regression,SVR)算法相结合,提出了一种多指纹库定位方法。根据不同位置CSI 信号的簇分布特点,将定位指纹点存入多个指纹库,进而在多指纹库中分别建立模型,实现位置预测。该方法不仅能提高定位精度,而且能有效提高定位效率,每次定位都无须与所有指纹库中的数据进行匹配,可以把闲置的指纹库所使用的系统资源分配给繁忙指纹库,避免了系统资源的浪费。
1 指纹定位系统
在Wi-Fi 室内定位场景中,通过收集CSI 信息和对象位置坐标实现指纹定位系统,进而为用户提供位置服务,满足用户在特殊场景下的位置需求。
根据指纹定位系统在不同场景的应用需求,本文提出的多指纹库定位方法具体流程如图1 所示。首先,基于CSI 成簇分布的特点,利用K-means 算法对训练样本进行聚类以获取k个簇的CSI 数据,进而基于k个簇分别建立指纹库;然后在k个指纹库中分别训练SVR 模型;最后,由SVR 进行位置精准预测。

图1 定位流程Fig.1 Flow of positioning
2 CSI原始数据处理
2.1 CSI数据描述
CSI 作为定位系统的数据源,其原始数据以复数矩阵的形式存在。采用CSI Tool[18]读取CSI 数据,每个CSI 数据包所能提取的CSI 子载波个数为30,并可以用矩阵H表示CSI 信息。每个CSI 数据为p×q× 30,其中:p为发射天线数量,q为接收天线数量,子载波个数为30。
为了有效利用CSI 数据,通过数据结构分解得出相应的数据。将CSI 信号定义为:
若第k个子载波上的幅度表示为‖Hk‖,相位表示为∠Hk,那么每一个子载波上的CSI 可表示为:
由于相位信息受频偏影响不能精确提取,本文方法仅提取幅值作为指纹信息:
CSI 的幅值在距离无线接入点(Access Point,AP)点不同的位置时,有不同的特性。如图2 所示,横坐标表示3 条链路的子载波索引,纵坐标为它们的幅值,3 条线代表3 根天线接收到的CSI 数据,当靠近AP 点位置测量CSI 数据,3 根天线的信号表现出了相似的特性;但当在距离AP 较远的位置进行测量时,3 条链路的曲线不再相似,并且链路之间的差异性变大;即使是同一条链路,幅值也有很大的变化,这说明CSI幅值对于位置的变化非常敏感。

图2 靠近和远离AP的CSI信号Fig.2 CSI signals close to AP and away from AP
2.2 数据预处理
采集数据后会生成一个样本维度为Ntx×Nrx×N的CSI数据,其中:Ntx为发射天线数,Nrx为接收天线数,N为子载波数量。由于原始数据中有1 根发射天线、3 条链路,每条链路上的子载波数量为30,所以每个CSI 信号的维度为1×3×30。为了获取有效的高维信息,使用主成分分析(Principal Component Analysis,PCA)算法将数据的N维信息通过线性变换投影到K1维空间中,其中N维是数据本身的维度,K1维是低维。通过该方法,实现了Ntx×Nrx×N列的数据降维,获取了有效的CSI 信息,保证了数据质量。
3 结合K-means和SVR的定位方法
3.1 基于CSI数据簇分布特点的聚类分析
依据文献[19]的实验分析,CSI 数据呈现成簇分布的特点,并且认为超过80%的CSI 幅值向量只存在4 个以内的分簇。因此考虑应用K-means 算法实现CSI 数据分簇,该算法采用距离来衡量样本之间的相似性,将降维后的CSI 数据划分成k个簇,其中,μi是簇Ci的均值向量:
K-means 算法的本质就是寻找k个质心来最小化平方误差E,E越小说明数据相似度越高,将CSI 幅值相似度较高的样本进行聚簇。
3.2 建立多指纹库
经过K-means 得到k个类别,构建k个指纹库[R1,R2,…,Rk],每个指纹库包含F个样本的CSI 指纹。设F={r1,r2,…,rn},n是指纹信息的个数,CSI 数据经过PCA 降维后,指纹属性集为[λ1,λ2,…,λi]。将F个样本包含的CSI指纹属性分别与坐标对应,对应坐标P={(x1,y1),(x2,y2),…,(xn,yn)},对 应后建 立多指纹库[R1,R2,…,Rk],其中:
3.3 构建基于多指纹库的SVR模型
建立多个指纹库后,每个指纹库里都存入了不同位置的CSI 样本数据,然后在每个数据库中分别建立SVR 回归模型进行定位。基于SVR 回归算法的核心思路在于用回归的想法找出CSI 幅值和位置的关系[20]。在高维空间中,用非线性映射的方法寻找一个最优超平面,以此来替换原本的非线性关系。
建立了k个指纹库后,分别使用每个指纹库的数据集,{(ri,xi)|i=1,2,…,n} 和{(ri,yi)|i=1,2,…,n}。基于SVR 算法,利用CSI 的幅值信息与坐标信息的关系,建立函数fx和fy。在x轴上建立线性回归估计函数:
其中:w为权值向量;φ(r)将低维度的CSI 指纹信息映射到高维空间;b是定值。
SVR 的标准形式为ε-SVR,其中ε为不敏感损失函数。SVR 的风险泛化函数R(w)如式(9)所示,其中CSIam是幅值的特征信息。
确定参数w和b时为了损失最小,所以解决最优化问题可化为:
约束条件为:
其中:αi表示拉格朗日乘子。由式(14)得到x轴坐标的计算函数,y轴同理。通过这种方法,在多个指纹库中训练出不同的SVR 回归模型,进行位置预测。
3.4 利用SVR模型实现位置预测
基于SVR 模型的位置预测过程:首先在测试点收集CSI指纹信息,然后进行指纹信息预处理;接着与离线阶段K-means 生成的簇心作距离度量,进而将测试点归入最相似的指纹库中;最后利用离线阶段所训练的SVR 模型进行预测,分别预测出x轴与y轴的位置坐标。
当预测位置与本身位置不同时,即存在误差,设预测点坐标为(x,y),实际坐标为(x1,y1),预测点坐标与实际坐标直线距离为Dis,如式(15)所示,用两坐标的直线距离来表示误差。
4 实验与结果分析
4.1 实验设置
本文提出的多指纹库室内定位方法面向实验室场景进行实验分析与验证。该实验室长8 m,宽6 m,将实验参考点划分标记为0.6 m×0.6 m 大小的方格,采集12 个点的位置坐标与CSI 数据,位置平面图如图3(a)所示,其中位置5、6、7、8与位置9、10、11、12 中间有一堵墙作为障碍物。

图3 实验环境的布局平面以及采集设备Fig.3 Layout plan and acquisition equipment of experimental environment
在实验中,数据采集阶段使用3 台联想ThinkPad T400 笔记本电脑作为显示器,如图3(b)所示。每台笔记本电脑都运行32 位Ubuntu Server 10.04(LTS)操作系统,并配置了Intel 5300 802.11n 无线网卡。AP(或监视器)使用在2.4 GHz 频段的通道6 上运行的接口wlan0 与用户通信,使用接口eth0 与服务器通信。服务器使用eth1 连接到Internet。数据处理阶段采用笔记本电脑的CPU 为Core i7-11800H@2.30 GHz,操作系统为Ubuntu 20.04.3。
4.2 实验分析
为了验证本文算法在不同实验环境中的定位误差以及定位效率,设计了不同参考点数量的误差分析实验与不同算法的误差分析实验。采用累积分布函数(Cumulative Distribution Function,CDF)图来表示定位误差的大小,并利用定位误差累计概率分布和平均误差对实验结果进行评价。
4.2.1 不同参考点数量误差分析
为了验证不同样本数对本文算法性能的影响,分别测试了在100、300、700 个样本点情况下的定位误差,使用CDF 图表示在不同样本数量情况下的误差,如图4 所示,在样本数为700 时的平均误差为0.95 m,样本数为300 时的平均误差为1.8 m,样本数为100 时的平均误差为2.1 m。

图4 不同样本数量的CDF图Fig.4 CDF diagram of different sample numbers
4.2.2 算法性能比较
为了验证本文算法的性能,分别与文献[15]提出的SVR算法、传统的单指纹库的KNN 回归算法、支持向量分类(Support Vector Classification,SVC)算法以及DFPhaseFL 系统作比较。实验在样本数量为700 的情况下计算了定位误差的累积分布,如图5 所示。从图5 可以看出,本文提出的K-means-SVR 算法在定位误差为0.6 m 以下的百分比达到了35%,定位误差在1.2 m 以下的百分比达到了70%,平均精度为0.95 m,明显优于其他四种算法。

图5 定位算法误差比较Fig.5 Error comparison of positioning algorithms
从表1 中可以看出,本文提出的K-means-SVR 算法在定位误差为[0,0.6] m 时的概率为35%,定位误差在[0,1.2] m的概率为70%,定位误差明显小于其他四个算法。同时,定位误差在[0,4] m 的范围时K-means-SVR 算法的平均误差最小,达到了0.95 m。可见本文的K-means-SVR 算法相比文献[17]所提出的DFPhaseFL 系统、文献[15]所提出的SVR 算法以及传统的SVC、KNN 算法,在性能上有了显著的提高。
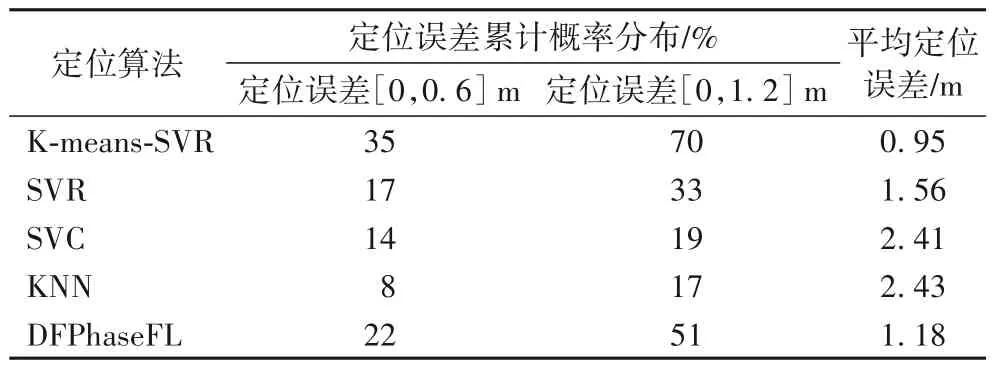
表1 样本数量为700时不同定位算法的性能对比Tab.1 Performance comparison of different positioning algorithms when sample unmber is 700
5 结语
本文提出了一种基于CSI 的多指纹库定位算法,在CSI数据成簇的特性上,将样本聚为3 类,分别建立指纹库,再用SVR 进行预测,不但提高了定位的精准度和定位效率,而且解决了人流量骤增导致定位精度下降、定位缓慢、闲置定位点多次匹配进而造成内存浪费等问题。然而,该算法仅仅使用了CSI 的高维信息,并未充分挖掘CSI 的低维信息。因此,下一步将充分利用CSI 的低维信息结合高维信息,探索动态环境下Wi-Fi 室内定位方法。
