基于共享注意力的多智能体强化学习订单派送
2023-05-24黄晓辉杨凯铭凌嘉壕
黄晓辉,杨凯铭,凌嘉壕
(华东交通大学 信息工程学院,南昌 330013)
0 引言
近年来,随着互联网高速发展,人们的出行方式有了很大改变。“网约车”走入了人们的生活,随时随地约车、方便快捷且舒适等特点使“网约车”迅速成为人们出行的热门之选。随着需求的不断增长,网约车平台也面临着一项难题,即如何高效地将订单派送给合适的司机。高效的订单派送能极大地优化交通资源分配,同时提高司机及平台收入,并提高用户体验及出行效率,对交通拥堵的情况也略有改善[1-3]。现今,强化学习方法受到了广泛的关注,主要被用于解决序列决策问题,并且在解决极其复杂的决策问题方面取得了巨大的成功[4-7]。例如Mnih 等[8]提出了一种新的智能决策方法,称为深度Q 网络(Deep-Q-Network,DQN),它可以储存训练中的经验,直接从历史经验中学习成功的策略。Rashid等[9]提出了一种新颖的基于价值的强化学习方法,可以端到端进行集中的训练,以分散的方式执行策略,称为混合Q 值网络(Q-learning MIXing network,QMIX)。QMIX 设计了一个神经网络来整合每个智能体的局部值函数得到联合动作值函数,确保整体最优解和个体最优解的一致。基于此,De Lima 等[10]提出将QMIX 用于订单派送,取得了不错的效果;但是,该算法忽视了车辆与车辆之间的关联,单纯地认为车辆与车辆是完全独立的个体,从而导致车辆基于贪婪的原则选择订单,可能错失整体的更优解。本文提出一种基于共享注意力的多智能体强化学习(Shared Attention Reinforcement Learning,SARL)算法,在不改变先到先服务的原则下,融入共享注意力模块,让车辆与车辆互相关注、合作,以获得整体更优解。
本文的主要工作如下:将订单匹配问题建模为以最快送达时间为目标的马尔可夫决策过程,并基于此提出了SARL算法;设计了一个共享注意力模块,将注意力机制与多智能体强化学习相结合用于订单派送;最后在不同规模的数据集上验证了本文算法的优越性以及泛化能力。
1 相关工作
目前基于强化学习的订单派送算法主要分为两类:基于价值网络的单智能体强化学习算法和基于多智能体的强化学习算法。
1.1 基于价值网络的单智能体强化学习算法
该方法主要将整体订单信息输入控制中枢,然后由控制中枢经过学习和训练后分配给合适的车辆完成订单。如图1 所示,智能体读取环境状态信息,通过价值网络对状态和可行动作进行评估,选择其中一种动作执行;动作改变环境,环境给出新的状态和执行该动作的奖励,以此循环。这种方法的特点就是集中训练、统一分配,控制中枢会根据价值网络进行学习,评估每一个动作将带来的影响价值,然后根据价值选择合适的动作。

图1 深度强化学习流程Fig.1 Flow of deep reinforcement learning
Pan 等[11]开发了一种新的深度强化学习算法,称为层次强化定价(Hierarchical Reinforcement Pricing,HRP)。HRP 解决了由于高维空间和时间依赖而产生的复杂性问题,减少了输入空间和训练损失。与现有算法相比,HRP 算法提高了收敛性,取得了更好的性能。Tang 等[12]提出了小脑价值网络(Cerebellar Value NETwork,CVNET)模型,该模型将地图分层平铺,然后通过小脑嵌入组合在一起,帮助网络学习比经纬度更抽象的概念比如街道、小区、城市等;其次针对不同区域比如市中心或者郊区网络能自适应学习并结合不同地图精度来获得更准确的状态表达。Wang 等[13]提出了基于行动搜索的深度Q 网络学习方法,为了提高模型的适应性和效率,还提出了一种相关特征渐进迁移的方法,并证明了先从源城市学习到分配策略,然后再将它迁移到目标城市或者同一个城市的不同时间的方法,比没有迁移的学习效果更好。van Hasselt 等[14]提出了一种新的时差学习算法——多Q 学习(Multi Q-Learning,MQL)。MQL 算法试图通过使用多动作值函数近似来提高值估计的稳定性。Chilukuri 等[15]提出了时间约束网络中联合路由和调度的深度强化学习(deep REinforcement learning method for joint routing and sCheduling in time-ConstrainEd network,RECCE)算法,用于集中控制时间受限网络中的联合路由与调度,不同于其他启发式算法在每个时间间隙中考虑相同的调度标准(如松弛性、相对截止日期),RECCE 利用深度强化学习应用不同的标准在每个时隙中转发数据包,结果表明RECCE 效果显著。
1.2 基于多智能体的强化学习算法
多智能体强化学习主要是让每一个智能体做自己的决策,一般执行三种任务,完全合作任务(订单派送一般被认为是完全合作任务)、完全对抗任务和混合任务。每个智能体会根据相应值网络学习出一个价值,再通过特定网络将价值组合得到联合动作-状态的总奖励值。Rashid 等[9]提出的QMIX 网络将联合作用值估计为每个智能体值的复杂非线性组合,这些值只以局部观察为条件,在结构上强制每个智能体的联合动作值是单调的,这使非策略学习中的联合动作值更易最大化,并保证了集中式和分散式策略之间的一致性。针对QMIX 的局限性,Son 等[16]提出了分解变换协作多智能体强化学习(Q-learning to factorize with TRANsformation for cooperative multi-agent reinforcement learning,QTRAN)。QTRAN 摆脱了结构约束,采用了一种新的方法将原来的联合作用值函数转换为易于分解的联合作用值函数,并且具有相同的最优作用。QTRAN 保证了比QMIX 更通用的因子分解,因此比以前的方法覆盖了更广泛的多智能体强化学习任务类别。Cui 等[17]提出了一种基于协调度的合作多智能体强化学 习方法(Cooperative Multi-Agent Reinforcement Learning method based on Coordination Degree,CMARL-CD),并对其在更一般情况下的动态特性进行了分析,结果表明CMARL-CD 在不需要估计全局价值函数的情况下实现了智能体之间的协调。每个智能体估计自身行动的协调度,这代表了成为最优行动的潜力。Liu 等[18]提出了COPA,一个教练-选手框架,假设教练对环境有全局观,并通过分配个人策略来协调只有部分观点的球员。具体来说,采用教练和球员的注意力机制;提出一个变分目标来规范学习;设计一种自适应的沟通方式,让教练决定何时与选手沟通。Luo 等[19]提出了一种新的基于动作级联的策略优化方法,将电动汽车重新定位的动作分解为两个后续的、有条件依赖的子动作,并使用两个连通网络来求解制定的多智能强化学习任务。Zhou 等[20]提出了一种基于多智能体强化学习的分散执行订单调度方法,以解决大规模订单调度问题。与以前的协作多智能体强化学习算法不同,所有智能体在联合策略评估的指导下独立工作,因为智能体之间不需要通信或显式合作。
2 问题及符号定义
本文是一个在线学习问题,首先将问题建模为马尔可夫决策过程G=(N,S,A,R,P,γ),其中N、S、A、R、P、γ分别为智能体的数量、状态集、动作空间、奖励函数、转移概率函数、折扣因子。它们的定义如下:
智能体数量N:将每辆空闲车辆视为一个智能体,每个智能体有自己独立的决策,它的目标是将发送订单的乘客送到目的地;智能体之间彼此独立,只负责自己的决策。
状态转移概率函数P(st+1|st,at):S×A→[0,1],它表示当前状态采取联合行动时转移到下一个状态时的概率。
在强化学习过程中,需要度量每一个动作以及车辆联合动作的价值:
联合总价值Qtot:表示总体价值,即所有智能体执行动作后产生的共同价值,它的大小表示整体行为的好坏。
3 基于共享注意力的多智能体强化学习算法
SARL 算法的整体框架主要分为两层:第一层为计算个体价值的智能体网络;第二层为计算联合价值的共享注意力模块。
3.1 计算Qi的智能体网络
SARL 的框架如图2 所示:第一层网络采用DQN 估计个体价值,采用DQN 的优势是可以更准确地估算个体价值。如果乘客或者车辆不在地图上,所有坐标信息都会被设置为0,每位乘客都会与一辆汽车配对,作为整体行动的一部分。网络将为每个乘客匹配车辆并估算个体价值,并输出具有最大个体价值的动作。整体损失函数为:
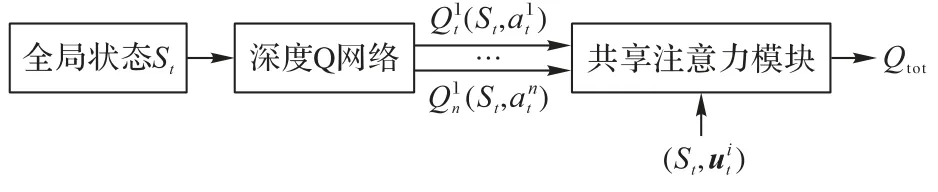
图2 SARL的整体框架Fig.2 Overall framework of SARL
G为Huber 损失函数,定义如下:
Huber 损失函数的优势在于当对动作价值的估计有噪声时,例如出现经验回访池中没有的状态-动作对,它对噪声是鲁棒的,在这种情况下可以防止梯度爆炸。Huber 损失结合了平均绝对误差和均方误差的优点,对异常点更加鲁棒。
3.2 共享注意力模块
共享注意力模块是对多头注意力机制的改进,框架如图3 所示。Qtot的计算公式如下:

图3 共享注意力模块Fig.3 Shared attention module
接下来,对N个智能体的联合价值Qh求和,得到:
其中:H是多头注意力的头数,也就是说,共享注意力模块首先利用单头注意力计算出联合价值Qh,再将这个过次重复H次,将结果加在一起得到联合总价值Qtot。C(s)是训练中的固有噪声,可以通过输入全局状态St的神经网络学习获得。
在第一层DQN,对每个智能体输入同样的全局状态St而不是智能体个体的观察值,这样做的目的是每个智能体在学习状态时都可以考虑到其他智能体位置从而做出选择,以便多智能体之间的合作。
在第二层共享注意力模块,把共享特征向量(除第i个智能体以外的所有智能体的状态信息)作为输入而不是个体的观测值,这样可以让网络通过Softmax 学习车辆之间的动作、位置的相似性,让智能体选择动作时更关注其他智能体的选择和位置,达到选择更优联合价值的目的。
4 实验与结果分析
4.1 实验设置与评价指标
为了对本文算法进行评估和对比,采用了文献[3]中的一个模拟环境。本文使用地图为网格地图,如图4 所示,每条边代表一条街道,每个交叉点表示路口,每个交叉点表示附近范围的集合即车辆只在交叉点处接送乘客。每条道路上都有汽车通行所需时间成本,成本代表了不同交通条件在内的因素,根据现实路况模拟生成。
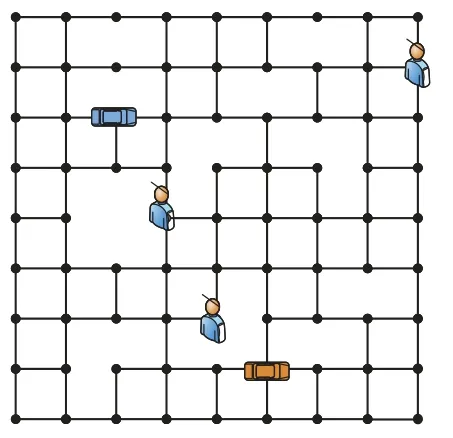
图4 网格地图Fig.4 Grid map
实验分为3 个部分:1)在100×100 的地图上进行了6 组车辆与乘客数量不同的训练及实验;2)为了验证本算法在不同大小城市的泛化能力,将100×100 的地图上训练的模型,在10×10 及500×500 的网格大小上进行实验;3)评估了数量不同的车辆和乘客的性能,也就是说,车辆和乘客的数量是根据地图大小在一个范围内随机分配的。
为了保持结果的客观性,所有实验及对比实验使用同一批参数,训练次数相同。
评价指标为实验1 000 次以上每轮实验平均花费时长以及提升率:时长代表这一次实验该网格地图中所有乘客都被车辆送达目的地所花费的时间;提升率表示SARL 算法时间效率对比其他算法最优时间效率所提升的百分比,即(次优算法消耗的时间-SARL 算法消耗的时间)/次优算法消耗的时间。
4.2 对比算法
本实验对比算法如下:
Random[10]:完全随机匹配车辆给乘客,不作任何调度。
Greedy[10]:非基于学习的贪婪算法,遵循先到先服务策略,因为提前要求用车的乘客会获得更高的优先级,每位乘客都会按距离贪婪地匹配一辆车。
IDQN(Individual Deep-Q-Network)[10]:为了有效地为乘客匹配车辆,为每辆车(即智能体)执行一次DQN 算法,根据价值来选择合适的动作以获得最大奖励。
QMIX[9]:该算法采用一个混合网络对单智能体局部值函数进行合并,并在训练学习过程中加入全局状态信息辅助来提高算法性能。
4.3 不同地图尺寸的实验
首先在100×100 网格地图上共选择6 组车乘组合(P、C表示在固定人车网格地图中每回合初始的乘客数量和车辆数量)进行实验,训练模型;为了验证模型的泛化能力,在10×10 以及500×500 网格上进行同样的6 组实验。表1 为平均每次实验所花时长对比,其中:加粗表示最优结果,下划线表示次优结果。可以看出SARL 算法平均每次实验所花时长始终最短,在所有车乘组合中都超越了几种对比算法。

表1 在不同尺寸地图上的实验对比Tab.1 Experimental comparison on different size maps
在100×100 网格上,对比其他算法最优时间,在车乘组合为(20,25)时,SARL 提升率达到最大,为18.03%;在10×10 网格上,在车乘组合(20,25)时,SARL 提升率达到最大,为18.42%;在500×500 网格上,在车乘组合(9,4)时,SARL提升率达到最大,为10.08%。这说明SARL 可以在一种地图大小上训练,然后在另一种地图大小(无论是更大或是更小)上进行测试,并且表现良好,说明相比QMIX 等算法,SARL能更好地推广到不同大小地图,验证了其泛化能力。
4.4 车辆和乘客组合可变情况下实验结果
本节实验中,车辆与乘客在一个区间里随意变化,这比固定车辆与乘客组合更现实,也更难,因为模型必须适应更多变的环境因素。在10×10 的网格地图上,车辆与乘客在数量1 至10 随机变化,即Pmax=10,Cmax=10;在500×500 的网格地图上,车辆与乘客在1 至20 随机变化,即Pmax=20,Cmax=20。结果如表2 所示,可以看出在10×10 网格上,SARL 算法相比QMIX 算法的提升率达到了6.28%;在500×500 网格上,SARL算法相比QMIX 算法的提升率达到了1.24%。这说明即使面对车辆和乘客组合可变的复杂情况,SARL 算法在实验中依然优于对比算法,在更复杂更现实的情况下依然性能稳定。

表2 车辆和乘客组合可变时的效率对比Tab.2 Comparison of efficiency with variable vehicle and passenger combinations
5 结语
多智能体强化学习近年来作为人工智能领域的一种热门算法,被广泛应用于车辆调度、订单派送等问题,并取得了不错的进展。基于此,本文提出了SARL——一种新的多智能体强化学习框架用于订单派送,并添加了一个共享注意力模块以此达到车辆彼此关注、合作的目的。结果表明SARL在时间效率性能上超越了所有对比算法,而且值得注意的是,SARL 在多车合作的实验场景下表现也很优异。
在接下来的研究,一方面准备优化实验的模拟器,用真实数据来训练模拟器;另一方面,考虑在框架中加入知识迁移,以达到更好的泛化的目的。
