基于特征金字塔网络和密集网络的肺部CT图像超分辨率重建
2023-05-24申利华
申利华,李 波
(武汉科技大学 计算机科学与技术学院,武汉 430081)
0 引言
医学图像是现代医学诊断中应用频率很高的辅助工具,高分辨率(High-Resolution,HR)的医学图像能帮助医生作出更准确的诊断。医学图像超分辨率(Super-Resolution,SR)重建有两个关键要求:清晰度和真实感,只有清晰且真实的SR 图像才能有效地帮助医生观察如肺结节等是否病变。然而,硬件限制会影响医学图像的获取。为解决因传感器获取的数据稀少而造成医学图像分辨率低的问题,以及让患者尽可能少地暴露在成像时的辐射下[1],科研工作者提出了医学图像SR 重建技术。SR 重建技术作用于序列SR 图像[2]和单幅SR 图像,本文通过SR 重建技术提高单幅肺部电子计算机断层扫描(Computed Tomography,CT)图像的分辨率。如今大多数SR 重建技术都应用于普通的彩色图像,应用于医学图像重建的还较少。医学图像纹理要求更复杂,并且对图像结构的准确还原度要求更高。而低分辨率(Low-Resolution,LR)医学图像缺乏高频细节信息,难以识别病变,不利于辅助医生诊断疾病。SR 重建技术能将LR 医学图像重建为HR医学图像,辅助医生诊断疾病。因此,医学图像SR 重建技术成为图像处理中研究的热点,也是现代医学界与人工智能技术联系的一个重要方面。
传统的图像SR 重建方法有:1)基于插值的图像超分法,如最邻近元法、双线性内插法、三次内插法等。这类方法算法简单易实现,计算速度快,但产生的图像过于平滑、有伪影,高频细节无法恢复[3],生成的SR 图像清晰度有限、精度较低。2)基于重建的方法。该方法通常都是基于多帧图像的,要结合其先验的知识,如凸集投影法、迭代反投影法、贝叶斯分析法等;但是这类方法计算非常复杂,需要使用大量计算资源。3)基于机器学习的超分方法,如稀疏表示法、知识向量回归法等。4)基于深度学习的超分法,如由Dong等[4]设计的传统超分辨率卷积神经网络(Super-Resolution Convolutional Neural Network,SRCNN),通过三层卷积完成特征提取、非线性映射以及特征重建。Umehara 等[5]将卷积神经网络(Convolution Neural Network,CNN)运用于肺部CT 图像SR 重建中,并获得了优异的结果,尤其是×2 放大。Abdel-Zaher 等[6]用CNN 对乳腺CT 图像进行分析,实现了乳腺癌的自动检测系统。Priya 等[7]提出了基于CNN 的间质性肺病辅助诊断法,提高了分类识别多种肺病的诊断率。SRCNN 可通过训练集自动优化,在清晰度上有所进步;但SRCNN 会对初始图像作放大处理,所以速度较慢。为了提高训练速度,Dong 等[8]又提出了快速超分辨率卷积神经网络(Fast SRCNN,FSRCNN),以及Shi 等[9]提出的高效亚像素卷积神经网络(Efficient Sub-Pixel Convolutional Neural network,ESPCN)。以上都是单尺度前馈网络,为了使用LR 图像与HR 图像之间依赖关系,Zhang 等[10]针对医学图像SR 重建还提出了一种并行结构,使多分支之间交叉投影用于交换信息,这也是并行结构应用于单图像超分重建任务的首次尝试。基于方法的研究进入瓶颈后,科研工作者开始从深度上进一步研究。基于He 等[11]提出的残差网络,Kim 等[12]提出了非常深的超分辨率(Very Deep Super-Resolution,VDSR)网络和深度递归卷积网络(Deeply-Recursive Convolutional Network,DRCN)。此类网络通过加深网络深度来优化超分效果。此后科研工作者将拉普拉斯金字塔以及通道注意力机制这类网络结构用于医学图像SR 重建。Du 等[13]就采用迭代上采样和下采样,分层提取浅层和深层医学图像的特征,并且引入通道注意力机制,调整通道权重,抑制噪声。这类方法都是基于像素空间优化的方法,由于缺少高频信息,导致视觉模糊。为了提高视觉感知质量,有学者将生成对抗网络(Generative Adversarial Network,GAN)应用到超分辨率中,提出了超分辨率生成对抗网络(Super-Resolution Generative Adversarial Network,SRGAN)[14]。SRGAN 用内容损失和对抗损失提高了重建图像的视觉感知质量,获得了更自然的纹理;但该纹理细节并非全然真实,因此SRGAN 不太适用于医学应用或监测(所以本文实验与经典算法比较时没有选择SRGAN)。Wang 等[15]将反馈机制用于GAN 的生成器网络,将残差通道注意力机制与对抗性损失结合,使生成对抗网络的优化效果更加明显。
普通图片对细节的要求较低,对整体的要求较高。因此,普通图像SR 重建是对整体图片的分辨率重建,没有针对性。而肺部图像重点在于辅助对肺结节的判定以及肺部CT图像内部细节边缘的清晰化,应当将注意力关注到肺结节和纹理细节这样的小目标。对肺部图像的SR 重建,首先要放大图像,从视觉上帮助医生更好地判断病情;其次,帮助医疗辅助系统更准确地判定结节的位置,比如提高肺结节检测的精度,以及提高肺结节良恶性分类的准确度。医学图像SR重建区别于普通图像重建的两点是:1)重建图像要求具备真实性,不能凭空产生;2)更关注肺结节和纹理细节这类小目标的描述。
基于上述问题,本文提出了基于特征金字塔网络(Feature Pyramid Network,FPN)和密集网络的肺部图像超分辨率重建(FPN and Dense Super-Resolution,FDSR)网络。为了获得更好的医学图像超分辨率的效果,本文的主要工作有:
1)在特征提取层引入了FPN 结构。通过下采样提取小物体的特征,增强对肺部图像中小目标结节及边缘细节的关注度,继而提高对肺结节检测的精度,以及提高肺部图像超分重建后的视觉效果。
2)在特征映射层引入了残差网络与特殊密集网络结合的网络结构。充分利用LR 图像的特征,将LR 特征通过残差学习融入特征重建的卷积层;并在残差组合网络(Residual Combined Network,RCN)内部加入残差网络,避免梯度消失等问题,从而映射出与HR 图像更接近的特征图像。
1 FDSR网络
为了提高肺部图像中肺结节以及纹理细节的重建效果,进而提高肺结节的检测精度,本文提出了一种新的网络FDSR。FDSR 网络基于FPN、特殊密集网络以及残差网络实现肺部图像的SR 重建。其中FPN 用于特征提取,特殊密集网络以及残差网络的组合用于特征映射。图1 给出了完整的FDSR 网络结构,其中非线性映射由各种不同深度但长宽尺度相同的RCN 组合而成。本文的特征提取部分采用FPN提取小目标的特征,使肺结节及纹理细节的特征重建更清晰,提高小目标的分辨率。非线性映射部分结合5 块长宽结构相同、深度结构不同的网络,网络间用特殊密集网络连接,网络内部用残差网络连接。特征重建采用CNN 作最后映射。本章将从特征提取、非线性映射以及特征重建三部分介绍FDSR 网络。
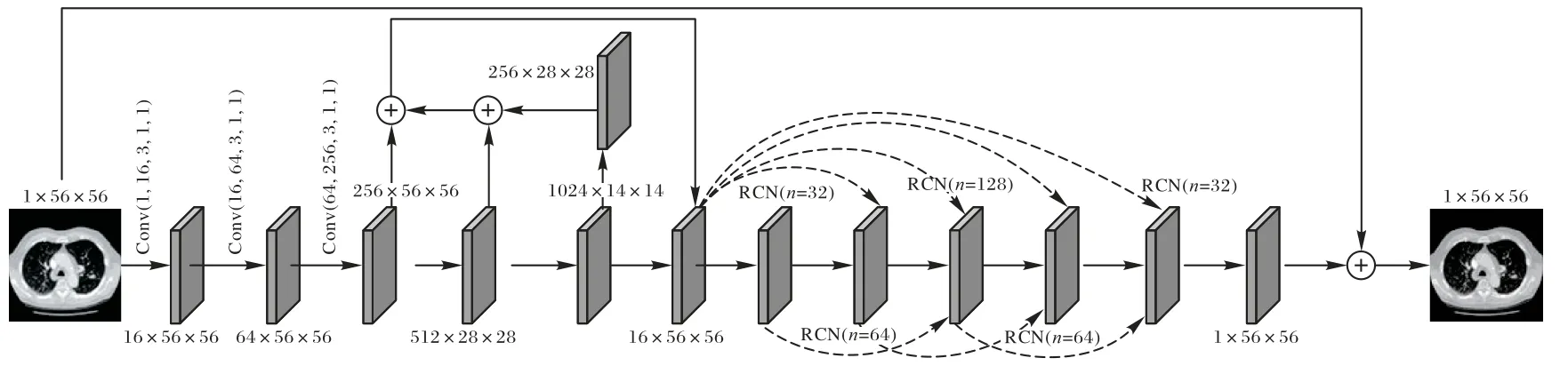
图1 FDSR网络Fig.1 FDSR network
1.1 特征提取
普通图像超分重建时特征提取采用几层卷积神经网络,准确度能达到大部分应用场景的要求。但对肺部CT 图像进行SR 重建的目的有两个:重建出HR 图像,帮助医生更好地诊断病情;提高肺结节检测辅助医疗设备的准确度。
FPN 的总体架构包括以下四个方面:自下而上网络、自上而下网络、横向连接网络以及卷积融合,目的是融合上采样后的高语义特征和浅层的定位细节特征。FPN 具体的实现方式见图2。
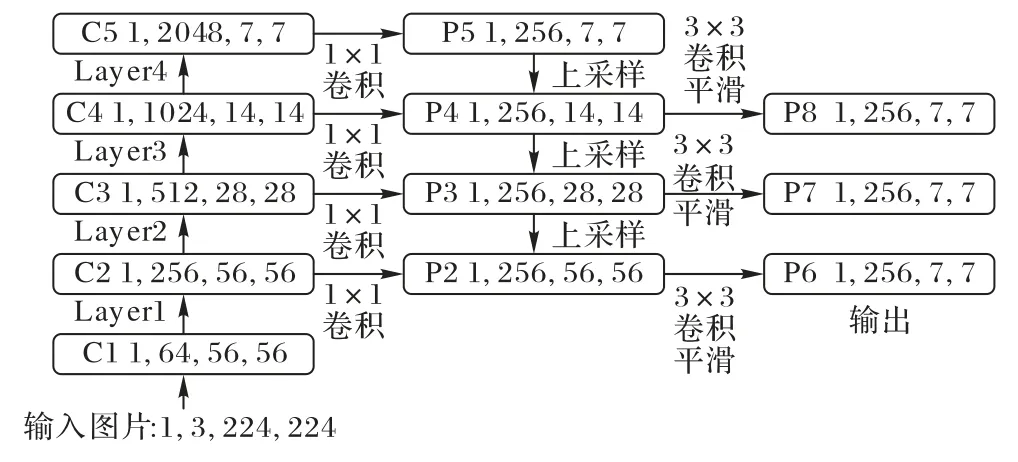
图2 特征金字塔网络Fig.2 Feature pyramid network
FPN 被应用于许多领域,比较常见的有目标检测模型。对图像进行特征提取时,大目标包含的信息会越来越多,小目标包含的信息会越来越少。而FPN 可以放大小目标物体在整张图片中的特征占比,提高对小目标物体的检测精度。FPN 本身并不是目标检测器,而是特征提取器,它通过卷积得到各个特征层,再逐步将其还原。在保证高级语义信息不丢失的情况下,解决小目标信息逐步递减的问题。
有学者将FPN 的思想用于医学图像SR 重建中,该网络能有效减少重建图像的视觉伪影,并且实现对一个模型的多尺度重建[16]。拉普拉斯金字塔超分辨率网络(Laplacian pyramid Super-Resolution Network,LapSRN)[17]有两条分支:一条为特征提取分支,专门用于特征提取;另一条为图像重建分支,逐步将小图像作上采样再融合到特征提取分支。LapSRN 与FPN 不完全相同,但对原始图像特征的重视程度一致,同样都是在特征向下提取的同时保留原始的特征。Tang 等[18]将LapSRN 与密集网络联系,设计的网络结构将非插值操作的原始LR 图像输入到网络中,用拉普拉斯网络结构逐步对LR 图像上采样,将得到×2 和×4 的图像特征融合,以逐步重建放大的HR 图像,该网络中密集网络结构用于上采样中的小模块内。本文输入网络的数据是经过插值操作的LR 图像,特征提取层采用的FPN 结构用于融合由于提取特征造成长宽倍数减小的各个特征层,目的是放大肺结节及纹理细节这类小目标的像素占比。本文提到的特殊密集网络用于连接小模块,而非小模块内部结构。
将FPN 用于肺部图像SR 重建,强化对肺结节及纹理细节这类小目标的关注度,从LR 图像块提取不同特征,以提高重建精度[19],而非在不断地卷积中逐渐忽略小目标特征。因而从整体上提升图像重建的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构 相似性(Structural SIMilarity,SSIM)值。由式(1)可知,生成最终SR 图像,不断训练权值矩阵,将传递信号反向传播,小目标的特征集合在计算中所占比例增加,能更有效地提高小目标的训练质量。
其中:w和y的上标数字表示不同层,下标表示该层特征不同的权值与特征值。网络的目的是不断降低loss,让重建的SR图像尽可能地接近真实的HR 图像。由式(1)可知,loss最终由初始的输入图像像素点和网络的各个权值矩阵计算获得。为了避免在特征提取时,大目标包含的信息越来越多,小目标包含的信息越来越少,加入FPN 结构,放大小目标在特征图中的特征占比,增大小目标在整个训练过程的权值占比。这不仅仅能对整个图像SR 重建,也能增强网络最后对细节纹理的恢复。
FDSR 的特征提取使用了FPN的思想,用2层FPN 结构提取更精细的特征,从而提高医学图像特征提取的质量,用于肺部CT 图像SR 重建。具体的特征提取结构见图3。由于SR 重建的特殊性,LR 图片中包含大量有用的特征。因此,提取完小目标的特征后,还融入初始时LR 特征,特征融合的结果为后续特征映射的输入。
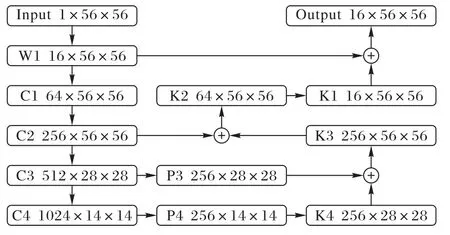
图3 FDSR的特征提取结构Fig.3 Feature extraction structure of FDSR
1.2 非线性映射
医学图像SR 重建中VDSR 巧妙运用了残差网络[20]。较深的非线性映射网络重建的最终图像效果更好的可能性更大,但过深的网络结构可能造成梯度消失的问题。VDSR 在特征重建引入了LR 图像的特征,解决了梯度消失的问题。很多学者将残差网络引入自己的深度模型,如Yang 等[21]以DRCN 作为延展,设计出了自己的深度模型,将每次迭代结果输出到最终特征重建部分。因此,FDSR 的非线性映射部分引入了残差网络的思想,最后特征重建采用了FPN 提取的初始特征。在保证特征梯度不消失的同时,还融合LR 的初始特征。
Li 等[22]构建了多尺度残差密集块(Multi-scale Residual Dense Block,MRDB),在MRDB 内部的残差小模块用到密集网络,有效地提高了重建图像的质量。Qiu 等[23]在局部结构中用到密集网络,整体结构用到残差,有效提高了重建医学图像的精确度。因此,本文的FDSR 除了用到FPN 提取初始特征外,还用特殊密集网络连接5 个RCN,具体的RCN 见图4。5 个RCN 的网络通道是对称的,目的是先加深网络的深度再降低深度,映射出更丰富的权重,提取更准确的特征,从前往后的深度分别是32、64、128、64、32,该结果是由后续多次对比实验得出。RCN 首先用一层3×3 的CNN 加深一倍的通道数,再用一层CNN 初步映射特征;然后用残差网络加深RCN 的深度;最终再融合初始特征,输出为下一个RCN 模块的输入。
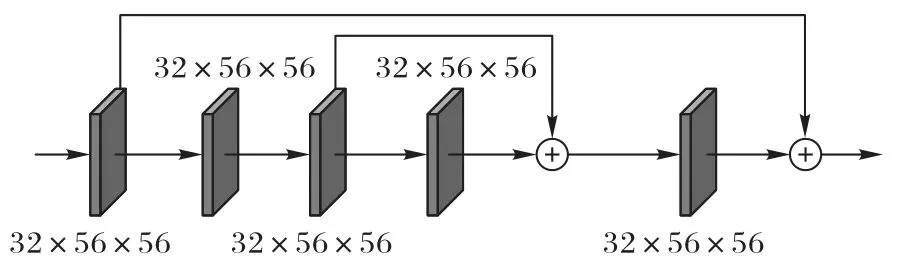
图4 RCNFig.4 RCN
在SR 重建中,LR 图像包含大量的初始特征,并且该特征对图像影响明显。因此,连接RCN 的过程中选择了和密集网络类似的网络,如式(2)所示:
其中:L的上标数字为RCN 的层级,一共有5 个RCN 结构,对应上标的1 到5,上标为0 表示1 号RCN 前一级的卷积块;L的下标output 表示卷积列结果输出,input 表示卷积列结果输入。SeqConvN表示不同的网络操作,除了SeqConv0 卷积列外,其他卷积列结构类似。
医学图像SR 重建不是由一张空白的初始图像训练而成,而是由LR 图像不断训练,无限近似HR 图像的效果,再保存最终训练好的权值矩阵集。因此,LR 图像特征尤为重要。特殊密集网络为了凸显初始特征的重要性,使每层RCN都接收到初始特征的输入特征层。每一层RCN 都会由FPN提取的初始特征作为输入的一部分,另一部分为上一部分网络的输出。图5 中,虚线箭头表示保留的密集网络剩余的一部分,作用是更好地训练RCN 内部结构。图4 将此部分的连接融入RCN 内部结构中。该特殊密集网络不仅保留了图像原有的特征、结合低层和高层特征提高图像性能,还减轻了梯度消失等问题。不同深度的RCN 特殊密集连接方式见图5。
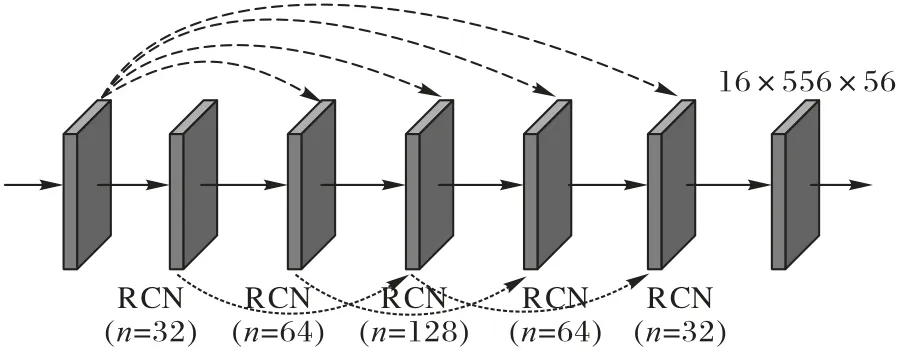
图5 RCN间的密集连接Fig.5 Dense connection between RCNs
1.3 特征重建
特征重建常用的方法有插值、解卷积、亚像素卷积。由于在特征提取模块采用了FPN,最终特征提取结束后图片的大小又恢复了原状。因此,在特征重建时仅使用基础的CNN降低维数,增加非线性,将特征映射后32×56×56 的结构转换成初始时1×56×56 的结构。最终与初始的LR 图像用torch.add 融合。具体图像融合细节见式(3):
最后成像时残差连接初始LR 图像特征,原因是在SR 重建过程中,特征都是从LR 图像中获取的,LR 图像中包含许多可有效用于HR 图像的特征。通过残差网络引入捷径连接,将输入的LR 图像直接连接到输出的SR 图像,实现身份映射。此类跳跃连接不引入额外的参数,并且几乎不引入计算复杂度,还能使网络更快收敛,解决了因深度增加导致网络退化的问题。具体特征重建细节见图6。
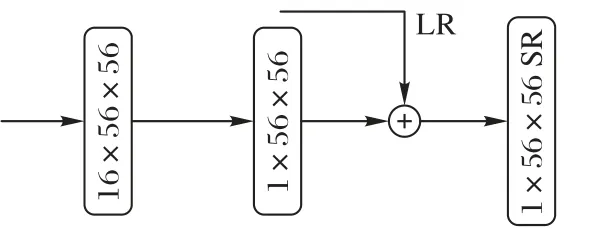
图6 特征重建Fig.6 Feature reconstruction
2 实验与结果分析
由于肺部CT 图像数据的特殊性,本文实验首先对数据集进行预处理并且根据初步实验确定参数细节,然后搭建特征提取、特征映射以及特征重建的基本网络,调整FDSR 中FPN 融合特征的次数,以及特征映射中RCN 的个数和结构,选择达到FDSR 对肺部CT 图像SR 重建效果最好的结构组合。最后对比FDSR 与其他现有常用网络的PSNR、SSIM 和视觉效果。
2.1 特征实验细节
2.1.1 训练集和测试集
本文使用的数据来源于Luna16 数据集。由于Luna16 数据集是三维的,所以需要对Luna16 中的数据进行切片,将其转换成医学图像SR 能处理的二维图片。本实验用到的切片是一个样本CT 中的一层数据,该切片根据z轴切割,按照当前z轴数据的1/2,再向下取整。做CT 扫描时,可采取正卧或仰卧,所以总是会导致图像出现翻转。将仰卧图像的x、y坐标进行倒序调整,让所有数据集中的图像都是正卧的。对像素值在[-1 000,400]的CT 图像进行预处理,将像素值截断,并且将单通道的CT 图像转换成RGB 格式后保存。
训练集采用800 张Luna16 中的肺部图像,评估集采用480 张Luna16 中的肺部图像,测试集中对比图像采用3 张肺部图像。训练集、评估集以及测试集的图像均没有交集。
2.1.2 数据预处理
FDSR 通过LR 图像重建的SR 图像与HR 图像对比,不断训练各个分支的权重,直到结果趋于稳定。因此,LR 图像就作为实验的输入数据。训练数据预处理过程见图7(a),评估数据预处理过程见图7(b)。首先用双三次插值法重构图像,保证数据集中图像的像素值都为整数。然后将HR 图片的长宽减半,再用双三次插值法利用采样点周围16 个像素的灰度值进行3 次插补,用于模拟HR 图像的退化过程。双三次插值对HR 图像进行下采样,得到相应的LR 图像[24]。构建LR 的过程用式(4)表示,构建SR 的过程用式(5)表示。
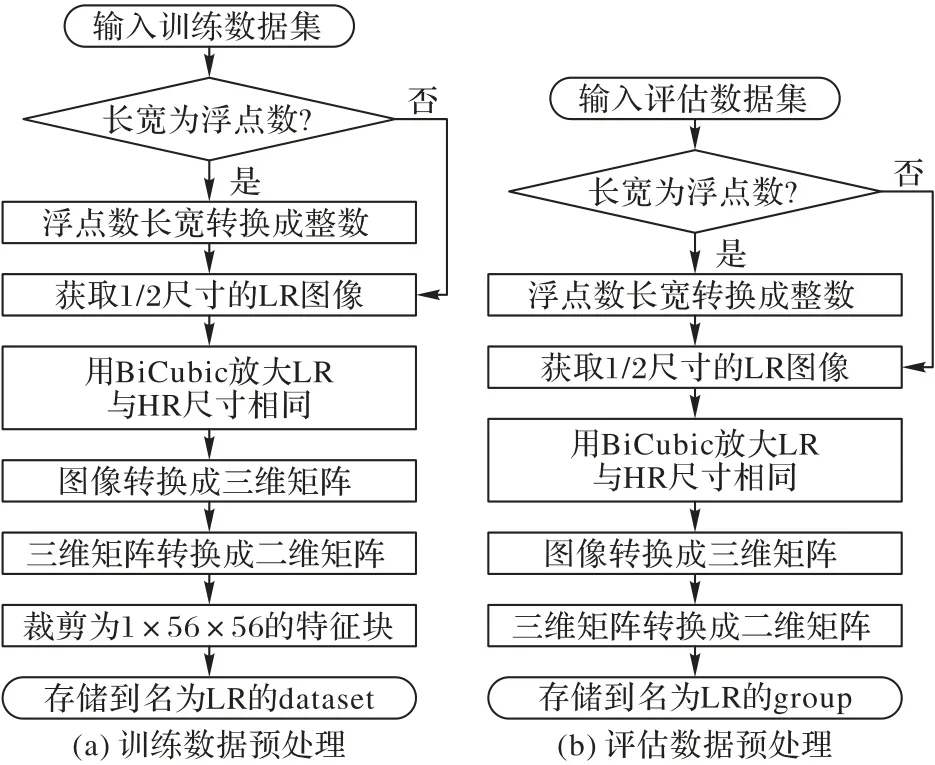
图7 训练、评估数据预处理过程Fig.7 Training and evaluation data preprocessing
其中:ILR表示LR 图像的像素值矩阵;ε代表退化比例因子,A()表示在退化比例因子为ε时对HR 图像像素值矩阵的操作;IHR表示HR 图像的像素值矩阵;ISR表示SR 图像的像素矩阵;δ代表进化比例因子,B()表示在进化比例为δ时对LR图像像素矩阵的操作。
初步处理后,一张RGB 图像的像素值数量近16×104,计算量大且训练时间长。因此,完整的图像不适用于该深度学习模型。例如DRCN 的输入是以LR 图像作插值法构建而成,这不仅增加了计算的复杂度,还丢失了原始LR 图像的一些细节。因此,在训练数据的预处理中,为了加深模型深度的同时保证训练速度不会太慢,将获取的LR 图像裁剪成56×56 的块,最后以56×56 的规格存入dataset 中。初步预处理后的HR 图像,与进一步预处理后的LR 图像实例见图8。最终对比的肺部图像与训练图像获取LR 图像的过程相同,只是不将它以56×56 的格式存储到dataset 中,而是直接将整个图片存入group。因为测试过程不需要反复多次训练,所以可以将整个图像都存入group。
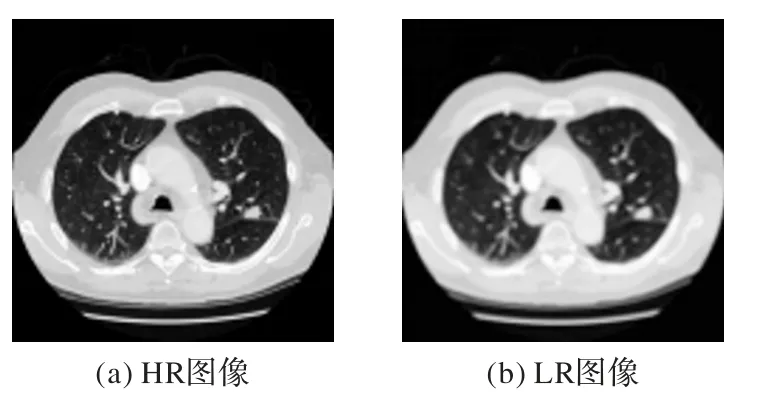
图8 HR图像和处理后的LR图像Fig.8 HR image and processed LR image
2.1.3 参数细节
训练模型时,采用optim.Adam()优化器,损失函数使用nn.MSELoss(),学习率为1×10-4,batchsize 为16。具体计算方法见式(6):
其中:xi是原始HR 图像的第i个像素值,yi是重建后的SR 图像的第i个像素值,两个参数的维度相同。
FDSR 以及常用对比网络的迭代次数由实验确定。由图9 可看出,在训练迭代次数到达250~300 时PSNR 的数值趋于平稳,因此本文训练迭代次数为300。使用的放大因子为3,num_worker 设置为8,激活函数采用ReLU。使用PyTorch 深度学习框架建立模型,并采用NVIDIA GeForce RTX 2080 Ti对其进行训练。
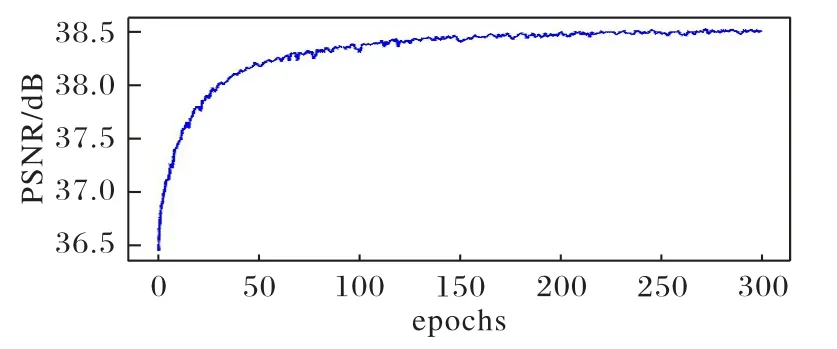
图9 PSNR与迭代次数的关系Fig.9 Relationship between PSNR and epochs
2.1.4 评价指标
为了客观评价重建图像的效果,采用图像处理评价中常用的PSNR 和SSIM。PSNR 是非常普遍的一种图像客观评价的指标,基于像素点间的误差,也就是基于敏感图像质量的评价[24]。PSNR 值越大,失真越少。
其中:RMSE为均方误差(Mean Square Error,MSE),表示两个尺寸为m×n 的原始图像像素值和重建后图像像素值的均方差。
SSIM 是一种广泛使用的适应人类视觉系统的图像质量指标。基于亮度、对比度和结构来测量图像之间的结构相似性[25]。SSIM 的取值范围为[0,1],值越大,重建图像与真实图像的结构相似性越高,图像失真越小。
其中:μx和μy表示图像x、y的均值;σx和σy表示图像x、y的标准差;C1、C2为常数。
2.2 网络结构设置
2.2.1 特征金字塔网络的比较
实验采用FPN 的目的是在重建SR 图像时,提高对肺结节及纹理细节这类小目标的关注度。实验中,训练数据存储的是56×56 的图像,因此,最多可以进行3 次特征融合。分别对1、2、3 次特征融合做对比实验:1 次融合是将28×28 的图像特征与56×56 的图像特征融合;2 次融合是在一次融合的基础上将14×14 的图像特征与28×28 的图像特征融合;3 次融合是在2 次融合的基础上将7×7 的图像特征与14×14 的图像特征融合。
其他变量相同,比较不同融合次数下测试集中HR 图像与超分辨率图像的PSNR 和SSIM 值。其中RCN 使用的个数不变,为5。表1 显示了FDSR 在不同的融合次数下测试图像的PSNR 以及SSIM 均值的结果。由表1 可以看出在融合次数为2 时,获得的SR 图像优秀的概率更高。因此,在最终FDSR 中使用2 次融合的特征金字塔网络。
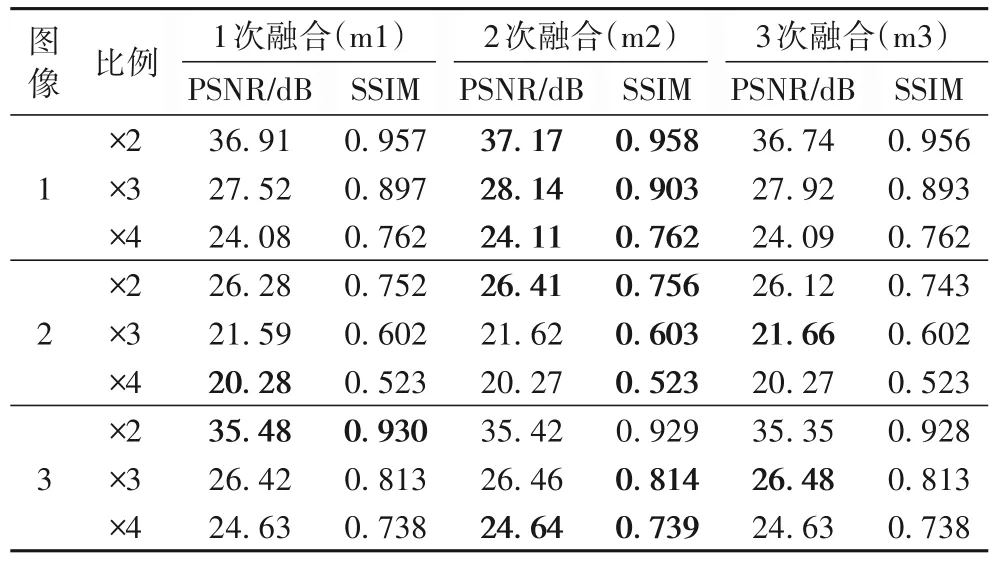
表1 测试图像在不同融合次数下的PSNR和SSIMTab.1 PSNR and SSIM of test images under different fusion times
测试数据集中的肺部低分辨率1 号图像在不同的融合次数下得到的SR 图像见图10。由图10 可以看出,不同融合次数的FDSR 重建出的SR 图像的效果都要优于BiCubic 图像。由于不同融合次数间PSNR 和SSIM 差异并不明显,所以从图像的视觉感知中图10(c)、(d)、(e)的视觉差距也不是很明显。不过本文关注点在于重建肺部HR 图像的真实清晰度,所以选择融合次数的指标依据表1 数据。
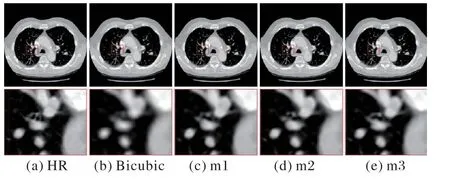
图10 不同融合次数图像比较Fig.10 Comparison of images with different fusion times
2.2.2 RCN个数比较
采用RCN 的主要目的是经组合后完成特征映射,各个RCN 之间采用特殊的密集网络连接。近来科研工作者对密集网络的研究显示,具有跳过连接和层重用的网络结构不仅有利于提高性能和速度,还能减少训练时间。RCN 内部结构是在保证梯度不消失的情况下,更准确地映射出特征。不同个数的RCN 使特征映射的深度不同。RCN 中层数由先高后低,再转换为1×56×56 的图像。由于LR 图像中含有大量HR图像的特征,最终会将1×56×56 的结果图像与原始的LR 特征融合得到最终结果。为了单独验证RCN 和连接RCN 的特殊密集网络的有效性,将RCN 组成的特征映射层替换VDSR的特征映射层构建VDSR_RCN,具体网络结构见图11。为了体现RCN 残差网络的有效性,引入Liu 等[26]提出的递归密集块(Recursive Dense Block,RDB)结构。RDB 是个小型的密集网络,也是其他将残差组合网络应用到CT 图像的超分辨率重建结构。
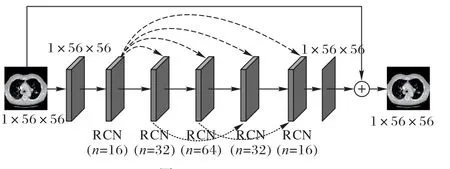
图11 VDSR_RCNFig.11 VDSR_RCN
VDSR_RCN 与VDSR、VDSR_RDB 的对比结果见表2,它们除网络结构外,其他条件均相同,训练次数都为100。由表2 可以看出,在网络层数相同情况下,用RCN 重构映射层的VDSR 网络训练效果明显优于VDSR 和VDSR_RDB,并且在某些情况下VDSR 的效果优于VDSR_RDB 的重建效果。可见残差组合网络是有效的,但也不是残差结构越多越好,适量地使用残差结构才能更好地重建图像。
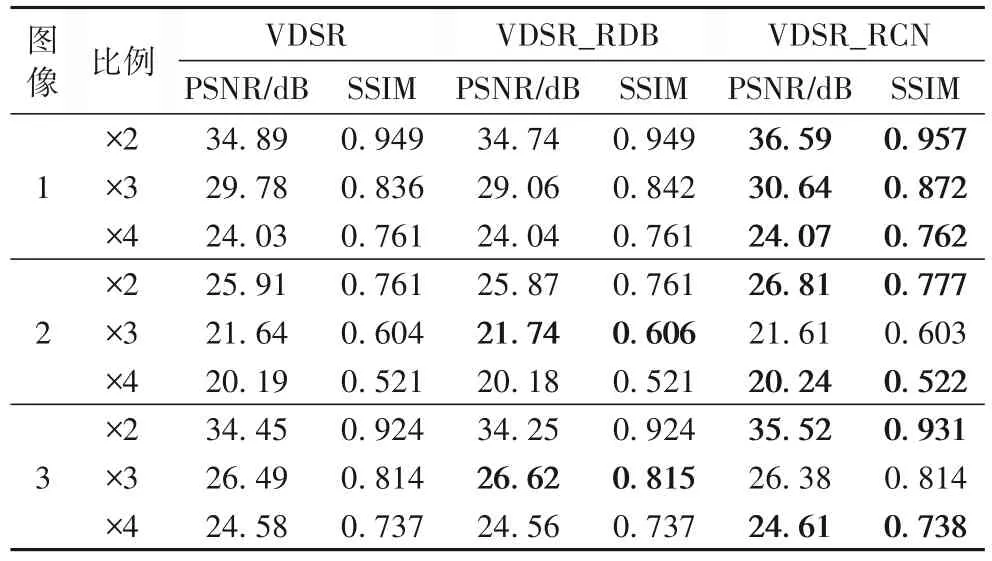
表2 VDSR、VDSR_RDB和VDSR_RCN的实验结果Tab.2 Experimental results of VDSR,VDSR_RDB and VDSR_RCN
由上述实验验证RCN 的有效性后,将RCN 用于本文实验的FDSR 中。接着对不同的RCN 个数进行比较,以得出其中结果最好的RCN 个数和结构。特征提取中融合特征的次数固定不变。而模型也不是越深就越好,与具有超过400 个卷积层的残差通道注意力网络(Residual Channel Attention Network,RCAN)[27]相比,虽然具有115 个卷积层的增强的超分辨率生成对抗网络(Enhances Super-Resolution Generative Adversarial Network,ESRGAN)[28]的PSNR 值略逊一筹[29],但它有更好的重建视觉效果。
本文对比了6 种结构个数不同的RCN:n1的结构为(32),1 个RCN;n2的结构为(32,16),2 个RCN;n3的结构为(32,64,32),3 个RCN;n4的结构为(32,64,32,16),4 个RCN;n5的结构为(32,64,128,64,32),5 个RCN;n6的结构为(32,64,128,64,32,16),6 个RCN。不同结构以及不同个数RCN 获得的PSNR 以及SSIM 见表3,可以看出,n5的PSNR 和SSIM 效果更好。可见在特征映射模块,适当的深度大小,深度先递增再递减,能训练出更精确的权值,使重建的SR 图像更接近于真实HR 图像。
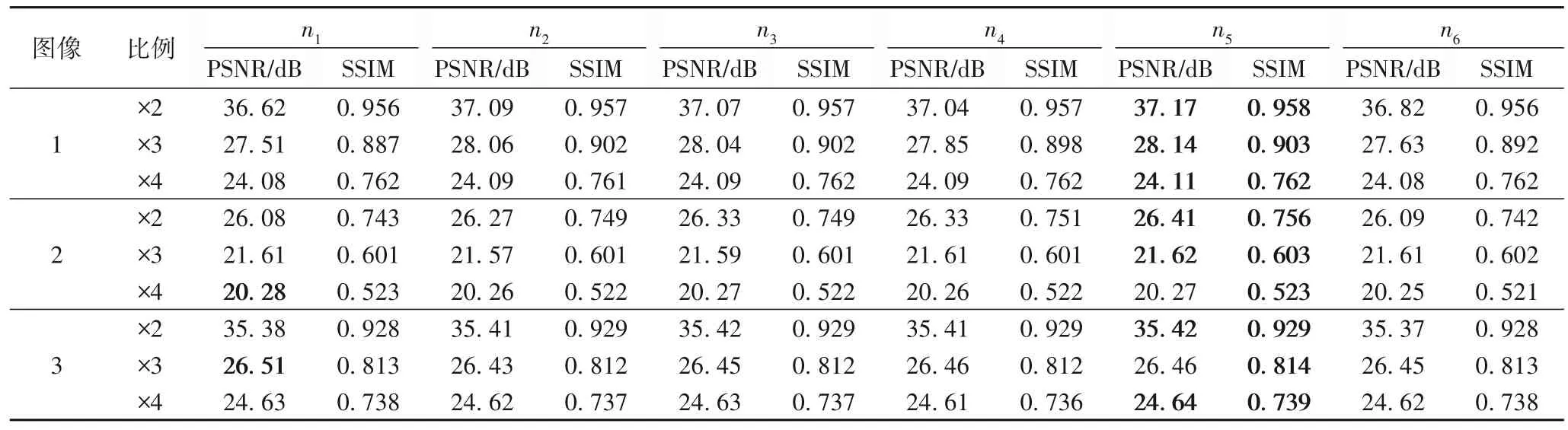
表3 测试图像在不同RCN个数下的PSNR和SSIMTab.3 PSNR and SSIM of test images under different RCN numbers
2.2.3 与现有网络的比较
根据以上实验结果,最终确定的FDSR 为表现最好的2次融合FPN 结构和5 个对称的RCN 结构。为了体现SR 重建医学图像的效果,将它与BiCubic 以及近年来国内外提出的基于深度学习的方法SRCNN、FSRCNN、VDSR 和LapSRN 进行比较。为了提高训练效率,对训练数据集进行裁剪,评估和测试数据集不进行裁剪;且所有对比方法的重建结果都基于同样的训练数据集、验证数据集、测试数据集、训练框架以及测试框架,区别在于采用不同的深度学习网络。因为SRGAN 是在感知的基础上重建出非客观存在的特征,基于特征空间优化的SRGAN 生成图像存在结构变形和伪影,不够逼真;而医学图像重视真实性,提倡重建客观事实存在的特征。因此,SRGAN 方法不适合直接用于医学图像SR 重建,未作对比。
表4 展示了FDSR 与其他常用深度学习方法的PSNR 和SSIM 对比。图12 展示了不同的深度学习模型下SR 重建图像的感知效果和对应的PSNR 值。由表4 可知,本文FDSR 深度学习结构的PSNR 相较于经典SRCNN 有0.05~1.09 dB 的提升,且与FSRCNN、VDSR 和LapSRN 结构相比都有一定的提高。利用FPN 进行特征提取,采用特殊密集网络连接RCN进行特征映射,以及利用CNN 进行特征重建,这三者组成的深度学习网络的PSNR 比经典模型的PSNR 更高,图像失真程度更小,结构相似性有一定提升。可见本文方法具有以下特点:1)由表4 可知,整体的重建上提升了PSNR 和SSIM 值;2)由图12 的视觉对比可知,特征映射时增加了对小目标特征的关注度。本文针对肺部CT 图像关注内部纹理的特点,设计优化细节的网络结构,为医学图像SR 重建提供了一种新思路。图12 圈中部分指出,从纹理细节的感知上,FDSR优于其他的对比网络,尤其是微小细节。这也是本文引入FPN 结构的主要原因:提升肺结节和纹理细节的特征占比,关注小目标的重建效果。但本文重点放在对SR 图像像素相似度数值的提升,而非提升视觉感知,所以图12 中视觉差异不是特别明显。图12(b)~(g)中,各个图像PSNR 值依次为:29.78、36.08、36.28、36.81、37.02 和37.17 dB。可见,FDSR图像的PSNR 数值更高,纹理细节重建效果更好。
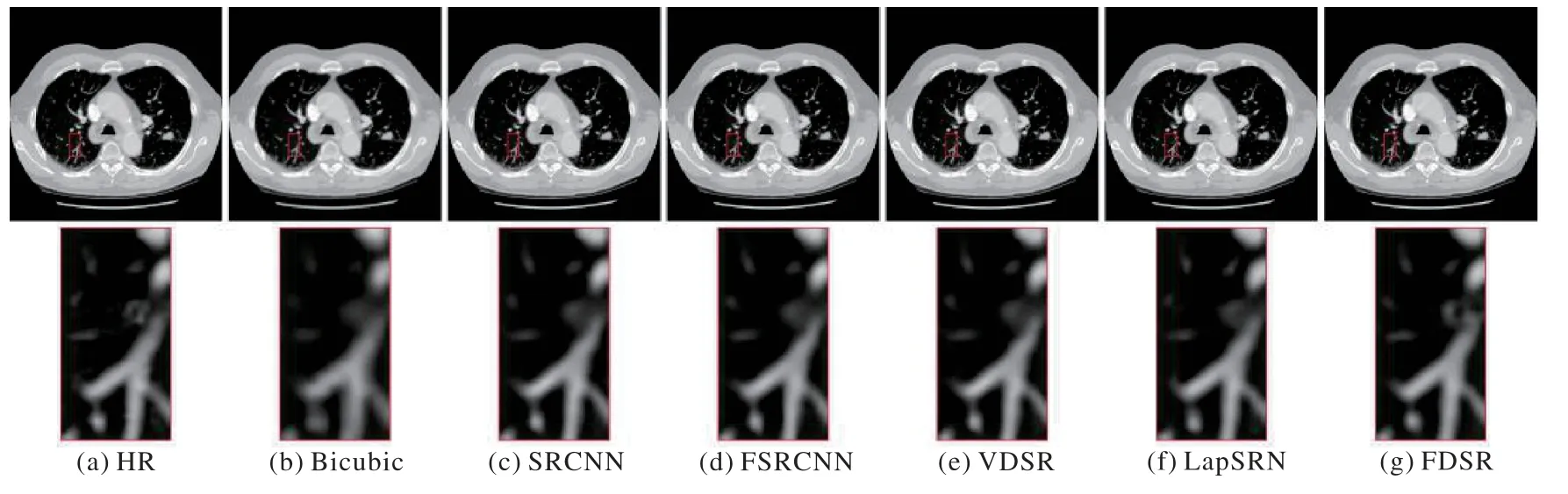
图12 FDSR与不同深度学习方法的视觉比较Fig.12 Visual comparison of FDSR and different deep learning methods
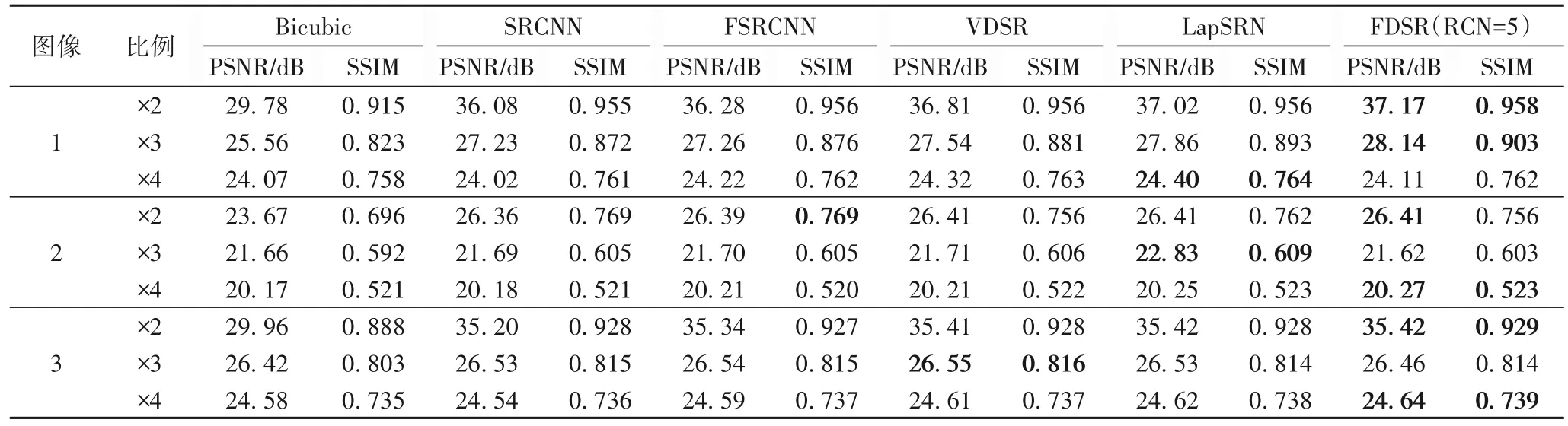
表4 FDSR与不同深度学习方法在PSNR和SSIM上的比较Tab.4 Comparison of FDSR and different deep learning methods on PSNR and SSIM
3 结语
本文提出了一种基于FPN 和密集网络的医学图像SR 重建的方法FDSR。该方法对LR 图像与HR 图像之间的残差进行重建,在特征提取部分引入FPN,增大肺结节及纹理细节这类小目标的特征占比,在特征映射部分构建RCN 结构,用特殊密集网络连接RCN,最终通过CNN 特征重建。实验结果表明,FDSR 方法较Bicubic 等传统方法以及SRCNN、FSRCNN 等基础模型有更好的重建结果,比VDSR 和LapSRN等深度较深的模型效果也更好。作为医学图像SR 重建技术,FDSR 也保证了重建基础的真实性。
后续工作可以考虑从空间注意力机制来加深对某些像素点的关注度。由于本文并未考虑到人眼的视觉特性,主要从PSNR 和SSIM 的角度优化模型,因此,观察图12 可以发现从视觉的角度判断FDSR 对比其他经典模型的优势比较微弱。下一步研究可以从视觉角度对FDSR 进一步优化:构建双分支网络,主要分支采用本文的FDSR 结构,感知分支采用肺实质分割图像做输入,融合其特征到主要分支,通过肺实质分割图像的边缘等细节信息增强特征中的高频信息,从而提高视觉感知质量。
