基于多任务联合学习的跨视角地理定位方法
2023-05-24王先兰周金坤
王先兰,周金坤,穆 楠,王 晨
(1.武汉邮电科学研究院,武汉 430074;2.四川师范大学 计算机科学学院,成都 610101;3.南京烽火天地通信科技有限公司,南京 210019)
0 引言
跨视角地理定位(cross-view geo-localization)指从不同视角(如地面、无人机(Unmanned Aerial Vehicle,UAV)、卫星视角)检索相似度最高的图像,将无地理标记的图像与数据库中有地理标记的图像进行匹配,从而实现定位任务[1-4],被广泛应用于航空摄影、机器人导航、精准交付[5-6]等领域。在数字地图时代,通常需要估计给定图像的空间地理位置,随着计算机视觉技术的发展,基于跨视角图像匹配的跨视角地理定位技术成为一种有效且稳定的解决方案。早期的跨视角地理定位研究是基于地面视图(平行视角)和卫星视图(垂直视角)之间的图像匹配[7-13]。然而,这两个视图图像的成像方式有很大不同:摄像机于地面的拍摄角度近乎平行于地平线,与卫星的拍摄角度近乎垂直于地平线。由于地面和空中视图之间视点的剧烈变化会导致严重的空间域差(domain gap)问题,因此,跨视图地理定位仍然是一项非常具有挑战性的任务。
随着无人机技术的发展,它已被广泛应用于各个领域,如植被细分[14]、车辆监测[15]、建筑提取[16]等。与传统的地面图像相比,无人机图像的遮挡物更少,它提供了接近45°视角的真实视点。倾斜视角相较于平行视角更接近垂直视角,这更适合跨视角地理定位。因此,为了弥补地面-卫星跨视角地理定位方法的不足,Zheng 等[17]引入无人机视角,通过无人机图像与卫星图像匹配解决跨视角地理定位的问题。此外,它还可适用于两个新应用:1)无人机定位,即给定无人机图像,在参考卫星图像中检索相同位置的图像;2)无人机导航,即给定卫星图像,在无人机图像中找到它经过的最相关位置图像,如图1 所示。其中:A 表示给定无人机视图,查询对应卫星视图,执行无人机定位任务;B 表示给定卫星视图,查询对应无人机视图,执行无人机导航任务。然而,无人机视图(倾斜视角)和卫星视图(垂直视角)之间的图像匹配算法仍处于探索阶段。目前,用于上述两种应用的现有跨视角地理定位方法[17-25]大多只学习基于图像内容的视点不变特征,并没有考虑无人机与卫星视图之间的空间对应关系。
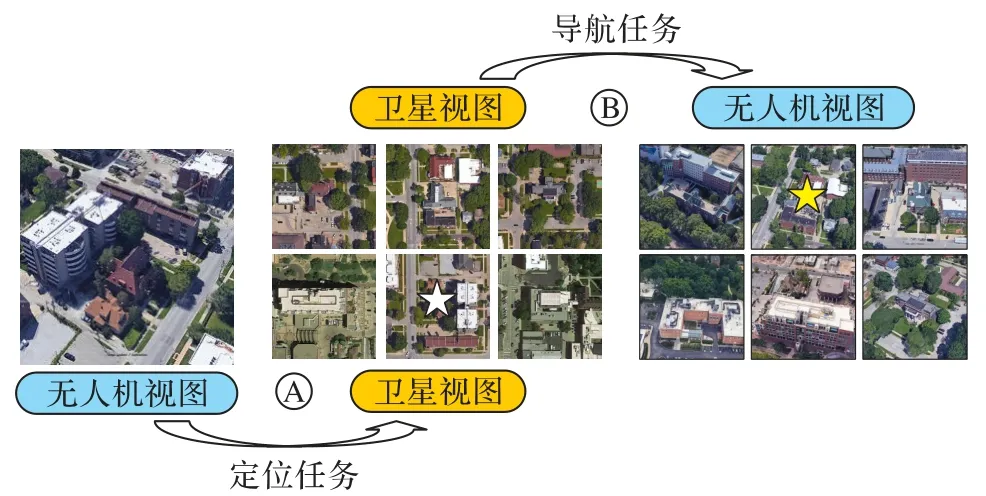
图1 无人机图像定位和导航任务示意图Fig.1 Schematic diagram of UAV image localization and navigation tasks
Zheng 等[17]将无人机视角引入跨视图地理定位问题中提出的University-1652 数据集包含了地面街景、无人机、卫星三个视图的图像。他们首次将跨视角图像匹配方法应用在无人机视图与卫星视图的匹配中,取得了不错的效果,实现了无人机定位和导航任务。但该方法忽略了邻近区域的上下文信息,因此Wang 等[18]采用方形环特征切分策略实现了上下文信息的端到端学习。He 等[19]基于显著性特征将特征划分为前景与背景,利用背景特征作为辅助信息,使图像更具鉴别性。Ding 等[20]提出了一种基于位置分类的跨视角图像匹配方法,缓解了卫星图像与无人机图像之间输入样本不平衡带来的影响。为了减小图像缩放、偏移对图像匹配的影响,Zhuang 等[21]改进了Wang 等[18]提出的方形环特征切分策略,此外还利用注意力机制提取更加有效的特征;Dai 等[22]引入Transformer 作为骨干网,提取图像的热力图,然后基于热力图进行特征切分、对齐、匹配,以增强模型理解上下文信息和实例分布的能力。田晓阳等[26]首次将视角转换方法引入无人机-卫星跨视角地理定位中,在LPN((Local Pattern Network)[18]检索模型基础上显著提升了无人机定位和导航性能;但该方法将视角转换模型割裂地视为视点不变特征检索模型和预训练模型,两个模型的训练彼此独立,未充分发挥神经网络的联合学习功能。周金坤等[25]在统一的网络架构下学习全局和局部特征,以多监督方式训练分类网络并执行度量任务,同时提出多视角平衡采样策略以及重加权正则化策略来缓解数据集视角样本不平衡导致的训练问题。以上方法均直接提取无人机视图和卫星视图间几何一致且显著的视点不变特征,但依然难以消除域差过大带来的视觉外观畸变、空间布局信息缺失等影响。因此,本文将视角转换方法应用于无人机与卫星图像间的跨视角地理定位中,采用视角转换模型与视点不变特征提取模型联合训练的方式,为无人机定位和导航任务提供新的思路。
本文针对视点不变特征与视角转换方法割裂导致的性能提升瓶颈问题,从决策级层面出发,以深度特征对抗决策为基础,提出了多任务联合学习模型(Multi-task Joint Learning Model,MJLM)。MJLM 的主要思想是在一个聚合框架体系内联合处理跨视角(无人机-卫星视图)图像生成任务以及检索任务,实现基于视角转换与视点不变特征方法的融合。具体来说,本文将给定的一对无人机图像和卫星图像映射到它们的潜在特征空间并建立联系,使用这些特征来完成这两个任务。一方面,后置检索任务确保生成卫星图的内容和纹理无限接近于真实卫星图;另一方面,前置生成任务使MJLM 在两个视域之间学习几何一致的特征,初步弥合空间域差,这将有利于无人机定位任务。MJLM 是一个端到端的方法,通过无人机图像创建类似真实的卫星图,并同时匹配相应的真实卫星图从而实现无人机定位任务。此外,不同于地面与卫星视图间的相关工作[13,27-29],本文通过探索无人机-卫星目标场景的几何结构,使用经逆透视映射(Inverse Perspective Mapping,IPM)坐标变换后的无人机图像作为跨视角生成对抗网络(Cross-View Generative Adversarial Network,CVGAN)的输入,因为透视变换后的图像与卫星图像的空间布局更为接近。
本文的主要工作如下:
1)提出了无人机视图与卫星视图间的跨视角图像生成模型。
2)结合显式的基于IPM 的坐标转换方法与隐式的生成对抗方法,在不依赖任何先验语义信息的情况下,基于无人机图像生成内容真实、平滑且几何空间一致的卫星图像。
3)提出了多任务联合学习模型MJLM 实现无人机定位任务。该模型联合考虑图像生成和检索任务,将两个任务集成到一个聚合架构中,将视角转换方法应用在卫星与无人机间的跨视角匹配任务中,初步弥合了空间域差,实现了与视点不变特征方法的融合。
4)在最新提出的无人机数据集University-1652 上进行了大量实验验证,结果显示本文方法相较于基线方法有了很大的性能提升,相较于现有跨视角地理定位方法取得了最优性能。此外,实验结果表明本文方法可以作为现有工作的补充,与先进方法融合可以进一步提高性能。
1 多任务联合学习模型
本文提出的多任务联合学习模型MJLM 由前置图像生成模型(网络架构如图2 所示)和后置图像检索模型组成。首先,通过IPM 将无人机图像进行坐标转换,使它的内容映射到近似于卫星视角的投影卫星图,实现无人机图像从倾斜视角到垂直视角的初步转换;然后,将投影卫星图通过CVGAN 生成内容保留、纹理真实的生成卫星图(垂直视角);最后,通过后置检索模型进行生成卫星图与真实卫星图的图像匹配,学习更显著的视点不变特征。MJLM 将这些模块聚合在一起,相互激励,实现端到端的无人机定位。
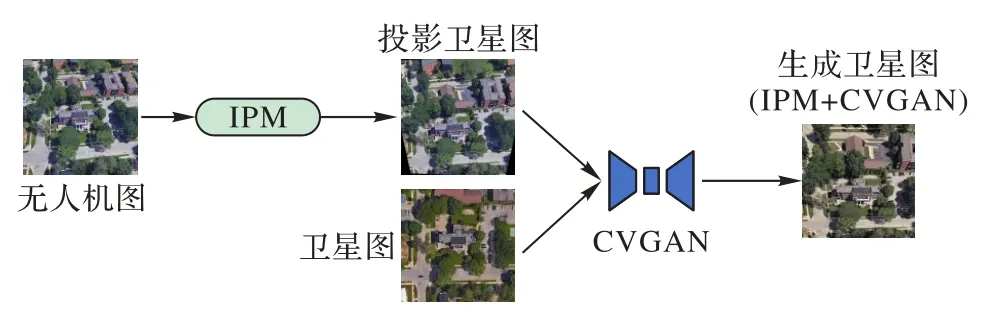
图2 基于视角转换的前置图像生成模型Fig.2 Proactive image generation model based on view transformation
1.1 基于IPM的坐标变换
无人机视图与卫星视图由于视角不同,存在着巨大的空间域差,直接采用神经网络隐式地学习不同视角域的映射可能会存在收敛过慢、拟合效果不好等问题。本文采用了一种基于IPM 的坐标转换算法,显式地通过IPM 将无人机图像映射为卫星图像,可以粗略地缩小两个视域的几何空间域差。
透视变换可以看成是一种特定的单应性变换,可以将同一个三维物体分别投影到2 个不同投影平面下的2 幅图像联系起来。常采用逆透视映射实现这种二次投影变换。逆透视映射在数学上为透视变换的逆过程,可以消除由于透视效应引起的“近大远小”问题,将具有透视形变的斜投影图变为正投影图。
考虑到数据集University-1652[17]中的图像并未提供摄像机参数或者平面位置的任何信息,无法根据摄像机参数模型进行逆透视映射。而数据集中提供了以每个目标建筑点为中心的无人机视图和卫星视图,所以本文可以利用对应点对单应变换法进行逆透视映射。
令无人机图的像空间坐标系统绕Y轴旋转φ,绕Xφ轴旋转ω,绕Zφω旋转κ后可以得到与卫星图像空间坐标系平行的坐标系(如图3 所示),经平移即可实现两者重合。则两者关系如式(1)所示:
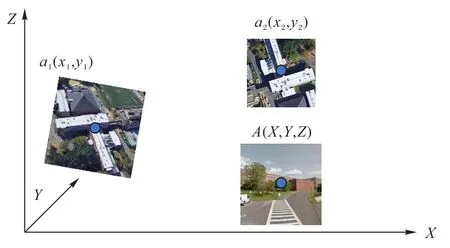
图3 无人机定位场景的IPM示意图Fig.3 Schematic diagram of IPM of UAV localization scene
其中:T=[xt yt zt]T是平移矩阵;RφRωRκ为3 × 3 的旋转矩阵,可表达为:
经变换得:
其中:A={aij}3×3为透视变换矩阵;[x',y',1]T为转换后的目标点坐标,即无人机图Is通过透视变换生成的投影卫星图Ips。
将式(3)变换为等式形式,输入图像与输出图像的对应关系为:
其中:(x,y)为源图像坐标,即无人机图Iu(斜向视角)坐标;(x',y')为目标图像坐标,即投影卫星图Ips(垂直视角)坐标。
按照对应点对单应变换法原理,只需要找到变换前后的4 个点对坐标并求出透视变换矩阵即可实现无人机视角到卫星视角的逆透视映射,其中4 个点中任意3 点不能在同一直线上。
透视变换的实质是将图像重新投影到另一个平面上。为了便于透视变换的训练,前置生成模型将转换后的无人机图像大小限制为与卫星图像大小相同。本文会在在源图像和目标图像之间找到4 个基本坐标点对,将透视变换矩阵A中的a33设为1,对8 个未知量解8 个方程,得到映射矩阵,最后对剩下的点进行反向映射插值。鉴于张建伟等[30]提出的对于不同倾斜视角,仅改变a31、a13两个参数即可实现各个角度的正投影结论,本文结合University-1652 数据集的无人机图像数据特性,在找到可靠的其他6 个参数的情况下,根据54 个倾斜视角仅需计算出54 套a31,a13参数组合,再结合输入无人机图像的角度类别参数,即可计算出54 组通用透视变换矩阵A参数,大幅节省了透视变换矩阵的计算量,提高了实时性。
通过透视变换得到的投影卫星图Ips与真实卫星图Is较为相似,且图像满足斜向视图和垂直视图的几何空间对应关系。但是,透视变换假设世界是扁平的,任何三维物体都会违背这一假设,投影卫星图的外观畸变仍较为明显。透视变换只能进行粗粒度的几何结构匹配,还不足以完全消除两个视图之间的几何空间域差。如图4 所示,投影卫星图有较明显的失真,转换后的目标建筑在垂直视角中不是矩形,而是梯形,且会出现黑色缺失区域。因此,为了弥合显式的透视变换带来的一定程度的外观畸变,1.2 节以CVGAN 作为图像生成模型,以透视变换后的投影卫星图Ips作为输入,以建筑类别作为条件,结合真实卫星图Is,对图像内容及纹理进行细粒度的匹配及修复,合成出更平滑且真实的生成卫星图G(Ips)。
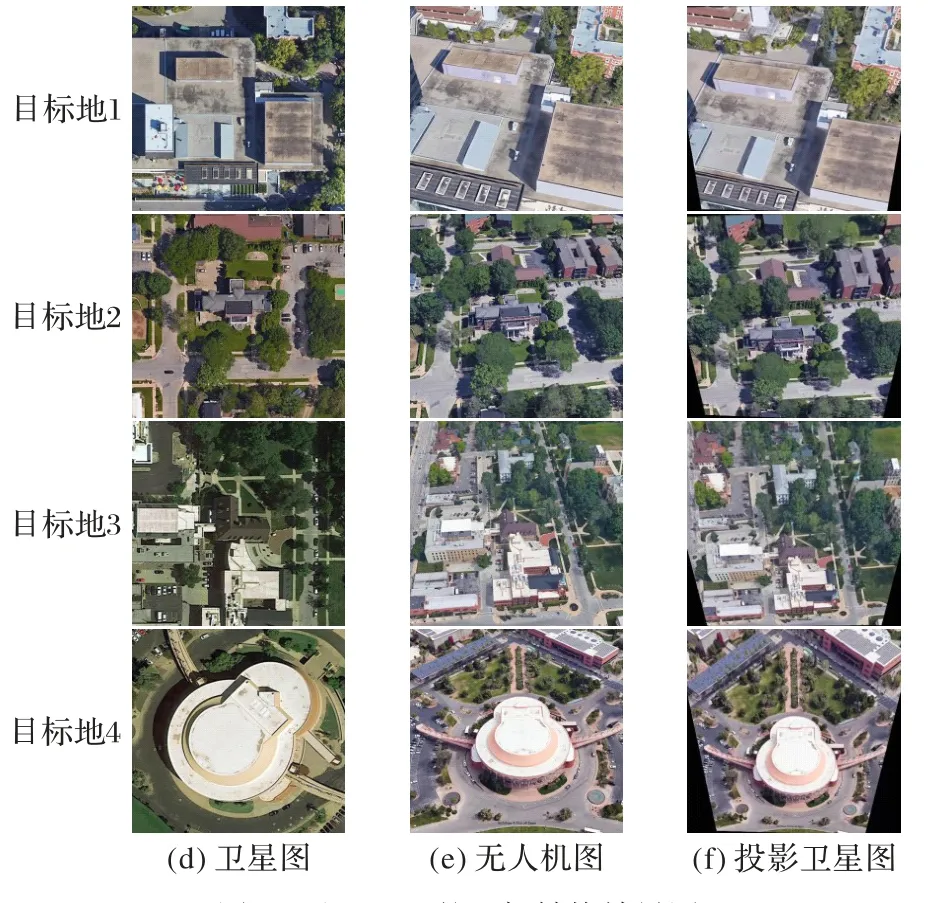
图4 基于IPM的坐标转换效果图Fig.4 Effect diagram of coordinate transformation based on IPM
1.2 跨视角生成对抗网络
生成对抗网络(Generative Adversarial Network,GAN)由于能够生成高度真实的图像而被广泛应用于计算机图像合成领域。一般通过对两个对立的网络:生成器G(Generator)和判别器D(Discriminator)进行对抗训练,实现网络整体生成性能的提升。
条件生成式对抗网络(conditional GAN,cGAN)是在GAN 基础上的扩展和改进,通过引入条件约束来实现有监督的学习方式,解决了生成数据样本随机以及无法针对指定域建模的缺点,使模型的数据生成具备可控性和目的性。这些特点使cGAN 适用于特定视域间的跨域图像转换生成。
本节基于cGAN 架构、残差采样模块、网络瓶颈层(bottleneck)并结合自注意力机制构建了一个跨视角生成对抗网络CVGAN,它能够基于无人机图像内容生成内容保留、外观真实且几何一致的卫星视角图像。
CVGAN 主要由生成器G以及判别器D构成。训练流程如下:
1)生成器G将经逆透视映射后的投影卫星图Ips作为输入,并将它转换成极尽真实的生成卫星图。在该情况下,逆透视映射是必要且有效的预处理步骤,因为转换后的图像的整体轮廓与真实卫星图像相似,减少了生成器G弥合无人机视图及卫星视图几何空间域差的一些负担。
2)判别器D对生成卫星图G(Ips)及真实卫星图Is进行判别,判断输入图像的真假。
3)判别器D的反馈结果会不断促使生成器G合成出难以与真实卫星图区分的图像。
1.2.1 生成器模型设计
1)模块组成。
受现有图到图生成器模型网络[18-21]的启发,将生成器G构造为U-Net 架构[22],以更好地进行图片还原。因为基于U-Net 结构的跳跃连接技巧允许大量的低频信息跳过瓶颈层在编、解码器网络间进行快捷传递。如图5 所示,U-Net 结构主要由下采样模块(downsampling block)和上采样模块(upsampling block)构成,为了能够充分挖掘特征图的潜在特征,本文在最深层特征图(512,32,32)的尺寸维度下,于下/上采样模块间构造了潜在特征挖掘模块。
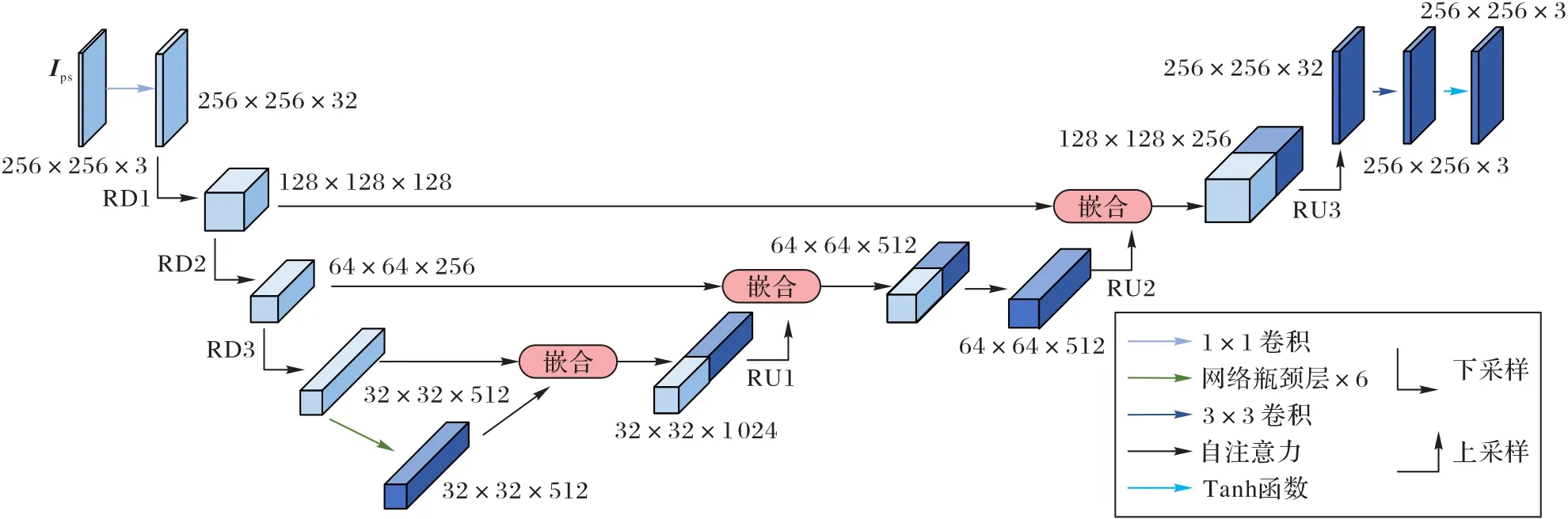
图5 生成器架构示意图Fig.5 Schematic diagram of generator architecture
鉴于残差网络在特征提取领域的广泛应用,且为了能够与检索分支建立一定程度的潜在特征联系性,便于特征还原与分类,生成器内部模块的网络采用了与检索分支骨干网(backbone)ResNet-50 类似的残差网络设计。
所以生成器内部主体由3 个残差下采样模块(Residual Downsampling,RD)、6 个网络瓶颈层(bottleneck)及3 个镜像的残差上采样(Residual Upsampling,RU)模块构成,本文将3 个残差下采样模块以及6 个网络瓶颈层合称为编码器GE,3 个残差上采样模块即为解码器。此外,于第一个残差上采样模块之后,在64 × 64 尺寸的特征图上添加了自注意力模块[23]。文献[31]的研究表明,该自注意力模块有助于学习图像中的全局依赖关系。
2)数据流说明。
①三个残差下采样RD 模块(如图6(a))对特征图进行图像编码,旨在挖掘它的深层特征。RD 模块采用残差网络设计,可以使特征图在训练过程中融合不同层次的特征信息,增强梯度的传播,同时减轻神经网络的退化。

图6 生成器网络细节示意图Fig.6 Schematic diagram of generator details
如图6(a)所示,RD 模块主体由两个1×1 Conv 和1 个3×3 Conv 构成,第一个1×1 Conv 主要作用是通过卷积对特征图进行下采样,使特征图的尺寸减半。步长为2,通道数为C1(RD1 中,C1=C,保持维度不变;RD2 与RD3 中C1=C/2,先进行了一次降维)。3×3 Conv 主要作用为扩大感受野,它并没有改变特征图的尺寸与维度。第二个1 × 1 Conv 对特征图进行了一次升维。所以特征图每经过一层RD 均会使其长宽减半、维度扩增。其中RD1 与RD2、RD3 不同的是,由于RD1 的第一个1×1 Conv 没有进行降维,所以RD1 输出维度为输入维度4 倍。
②特征图经过RD 后,在维持同等分辨率及通道数的情况下,6 个网络瓶颈层(如图6(b))会进一步挖掘它潜在的表示特征。
③生成器G采用残差下采样RD 模块的镜像模块——残差上采样RU 模块(如图6(c))对深层的特征图进行上采样,还原它的特征表示,从而使生成器G的输入/输出图像(投影卫星图Ips/生成卫星图G(Ips))保持相同的尺寸。RU 为RD 的镜像模块,但由于上下采样细节不同,RU1、RU2 相较于图中的RU3 而言,在Upsample 及3×3 Conv 间去除了1×1 Conv、批归一化(Batch Normalization,BN)层、整流线 性单元(Rectified Linear Unit,ReLU)层。RU1、RU2 的上采样维度变化仅为RU3 的一半,即1/4。由于U-Net 架构,每次上采样前要将下采样特征图与经过网络瓶颈层的上采样特征图进行嵌合,相较于下采样,上采样多进行了一次降维操作。
投影卫星图Ips(3,256,256)在进入残差下采样模块前,须先经过1×1 Conv 进行升维,即对每个像素点,在不同的通道(channels)上进行线性组合(信息整合),在保持特征图尺度不变的前提下大幅增加非线性特性(利用后接的非线性激活函数)。特征图在经过残差上采样模块后,还需经过3×3 Conv 及Tanh 函数进行降维和激活,最后还原成生成图像。
3)网络结构参数说明如表1 所示。其中:在Ips的特征尺寸“(3,256,256)”中,“3”表示投影卫星图Ips的维度即通道数,“(256,256)”表示特 征图的尺寸,即长和 宽;“1 × 1 Conv(32,256,256)”表示经过1 × 1 卷积后的特征图维度和尺寸分别为32、256 × 256;“(enc1)残差下采样模块RD1(128,128,128)”表示经过残差下采样模块(即图中的RD1)后的特征图维度和尺寸分别为128 与128 × 128,该特征图表示为(enc1);“+嵌合(enc3)残差上采样模块RU1(256,64,64)”表示特征图先与(enc3)进行拼接,再经过RU1。

表1 生成器网络结构参数Tab.1 Network structure parameters of generator
4)值得注意的是,与常见的后激活(post-activation)方式不同,本文在网络瓶颈层及所有基于残差网络设计的网络模块(如RD、RU)均采用了前激活(pre-activation)方式,即在卷积之前进行归一化和激活处理(BN+ReLU)。在这种结构中,反向传播基本符合假设,信息传递无阻碍;BN 层作为前激活方式,起到了正则化的作用。文献[32]中也证实了这一点。本文还在每个卷积层之后均使用谱归一化(Spectral Normalization,SN)[33],生成器的谱归一化可以有效抑制参数幅度的异常波动并避免梯度消失或爆炸[31],有利于对GAN的训练;在所有残差下采样和上采样模块间,本文使用“跳跃连接(skip connections)”作为提高网络收敛性的技巧,它能够保存输入图像的空间布局信息,并将其转换为目标视图图像。
1.2.2 判别器模型设计
为了能够有效建模图像高频特征信息,需要将注意力视野放在局部图像块中的结构上。因此本文将判别器D构造为PatchGAN[25],它能够对图像中的每个N×N块进行分类。判别器主要由斜率为0.2 的带泄露修正线性单元(Leaky Rectified Linear Unit,Leaky ReLU)以及4 × 4 Conv 构成,其中4 × 4 Conv 步长为2,如表2 所示。它的输入分别为真实卫星图Is以及生成卫星图G(Ips)。对于给定的Ws×Ws卫星图,判别器D将会下采样到更小patch 的空间尺寸,并将每个patch 进行真假分类。PatchGAN 的功能类似于生成器G的编码器,只不过最后输出的是判别图像对真伪的概率。这种判别器有效地将图像建模为马尔可夫随机场,假设像素之间的独立性大于一个patch 直径,可以理解成是一种纹理/风格的损失学习模型。该采样策略有益于合成出更加真实的生成卫星图G(Ips)。由于生成卫星图中的语义特征如街道、树木及建筑物均为重复的局部细粒度特征,所以全局一致性相较于局部特征显得不那么重要,因此判别器D更加注重细粒度特征的判别。
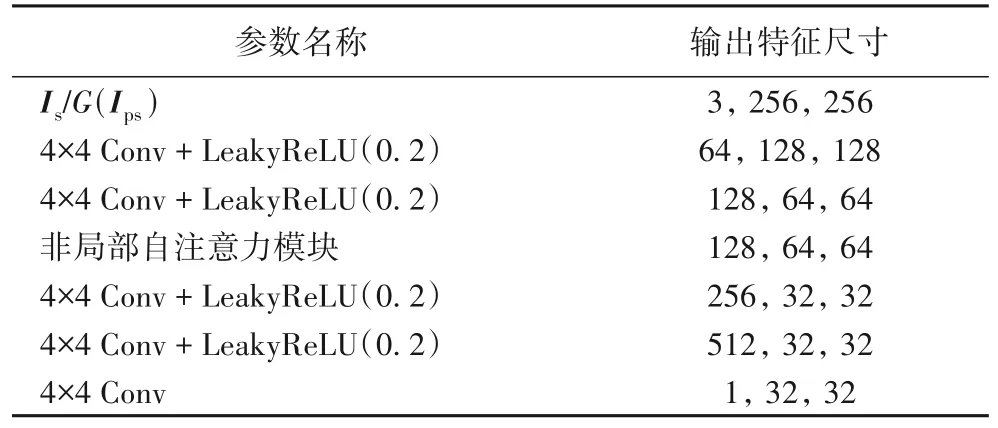
表2 判别器网络结构参数Tab.2 Network structure parameters of discriminator
与生成器类似,本文对尺寸为64 × 64 的特征图作了非局部自注意力模块处理,且在每个卷积层之后使用谱归一化,将每个单独的特征正则化到为1 的谱半径。当然,在生成器和鉴别器的最后一层1×1 Conv 后不使用谱归一化。我们从经验中发现,生成器和判别器的谱归一化可以在每次生成器更新时减少判别器更新,从而显著降低训练的计算成本。该方法也表现出更稳定的训练行为。
1.3 图像检索模型
MJLM 的整体网络架构如图7 所示。1.1 与1.2 节介绍了前置图像生成模型,本节将介绍后置图像检索模型。该模型的目标是通过将给定的无人机图像与卫星图像数据库进行匹配来定位它的位置。后置图像检索模型选择了多视角多监督网络(Multi-view and Multi-supervision Network,MMNet)[25]作为视点不变特征提取模型,其中MMNet 的骨干网为ResNet-50。
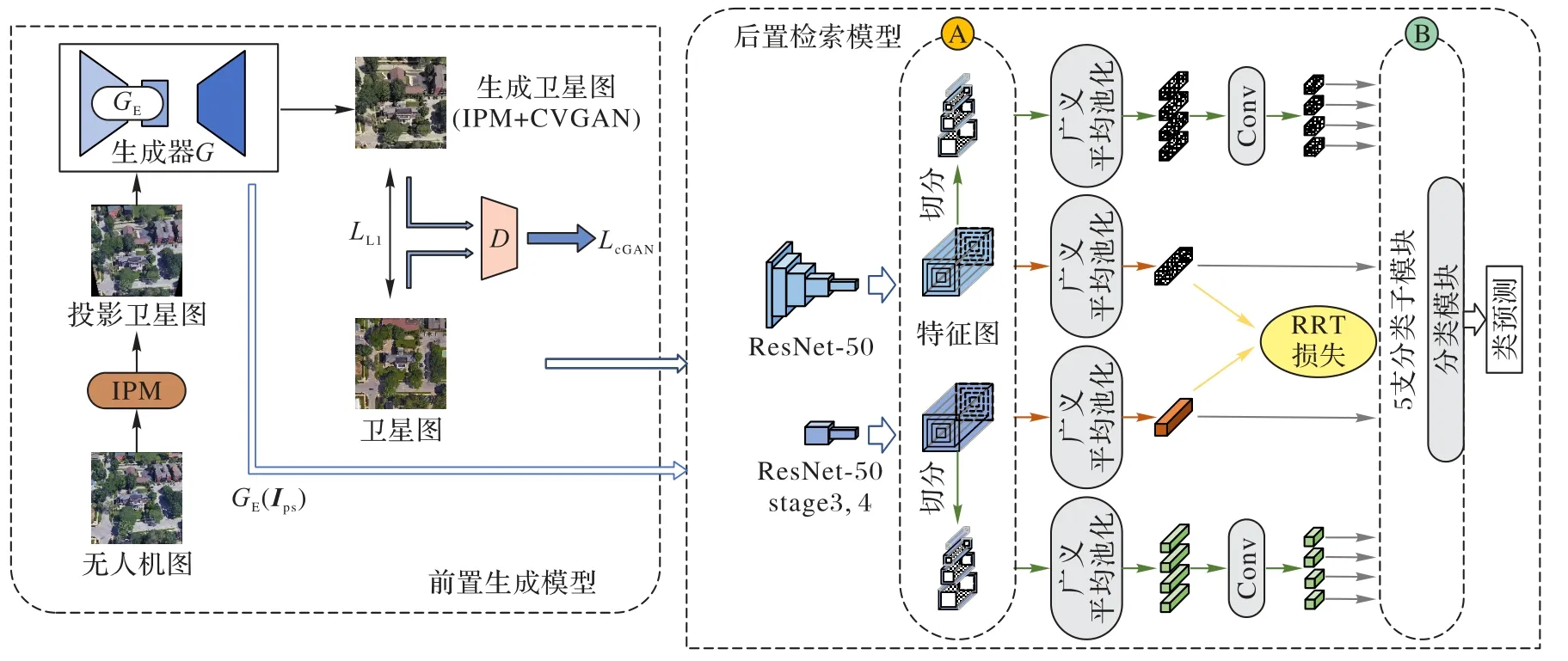
图7 MJLM架构示意图Fig.7 Schematic diagram of MJLM architecture
该模型主要由多监督学习、多尺度特征融合、重加权正则化策略及多视角平衡采样策略四个部分组成。首先,该模型融合卫星视角和无人机视角,在统一的网络架构下学习多尺度融合特征,再以多监督方式训练分类网络并执行度量任务。具体来说,MMNet 主要采用了重加权正则化三元组(Reweighted Regularization Triplet,RRT)损失学习全局特征,该损失利用重加权和距离正则化加权策略来解决视角样本不平衡以及特征空间结构紊乱的问题。同时,为了关注目标地点中心建筑的上下文信息,MMNet 对特征图进行方形环切割获取局部特征。然后,分别用交叉熵损失和RRT 执行分类和度量任务。最终,使用加权策略聚合全局和局部特征来表征目标地点图像,从而完成无人机定位和导航任务。因此,在逆透视映射和跨视角生成对抗网络之后,利用MMNet将多监督学习、多尺度特征融合、重加权正则化策略及多视角平衡采样策略融入本文的多任务学习方法中。
同时,为了更好地衔接前置生成模型以及后置检索模型,本文方法将CVGAN 中编码器GE的潜在特征图GE(Ips)作为MMNet 无人机分支的输入(MMNet 无人机分支原输入为无人机图像),这样可减少解码器解码过程中的信息缺失,保留最原始的潜在特征以及编码器GE的特性。但由于生成器G与骨干网的特征提取网络不同,输出特征图的尺寸与维度并不相同。具体来说,为了能够保证两个分支输出的尺寸与维度相同,MJLM 将GE(Ips)作为Resnet-50 stage3 的输入而不是stage 0 的输入,这也是CVGAN 深层特征尺度设定为(32,32,516)的一方面考虑。
多任务训练设置的核心思想为:通过使用潜在学习特征GE(Ips)来连接图像生成任务与检索任务,使前置生成模型与后置检索模型在训练时相互作用与加强。后置检索模型本身仅能隐式地学习图像间的视点不变特征。图像生成任务中学习到的特征提供了一个明确的跨域转移映射,能够帮助后置检索模型获得更好的图像匹配性能。反之,后置检索模型迫使前置生成模型学习最终对图像匹配有用的特征——这就产生了内容保留、外观真实且几何一致的生成图像。
1.4 多任务学习
MJLM 的目标是联合前置生成模型以及后置检索模型进行多任务学习。相较于两个模型独立训练,多任务学习方式需要同时对两个模型进行训练。首先通过建立总损失函数将两个模型联系起来;然后利用反向传播来降低损失,实现基于跨视角图像匹配任务的梯度下降。
为此,本文设计了以下损失函数:
其中:LcGAN、LL1、Lret分别为cGAN 损失、L1 损失和检索损失;LcGAN、LL1、Lret分别为MJLM 中各损失的权重。
在训练时,MJLM 以对抗性的方式动态更新生成器、判别器、MMNet 三个网络的权重:
其中:G、R、D分别表示生成器、MMNet、判别器。
接下来将介绍这三部分的损失函数定义。
1)cGAN 损失。对于图像生成任务,cGAN 损失如下:
当判别器D试图将图像分类为真(Is)或假(G(Ips))时,生成器G一直尝试通过生成真实图像来最小化损失。对应的投影卫星图Ips作为生成器G和判别器D的条件。
2)L1 损失。L1 损失使预测的生成图像G(Ips)与真实卫星图像Is之间的特征距离最小。
L1 损失为生成器产生的生成图像G(Ips)与真实卫星图像Is像素级距离差(pixel-by-pixel difference)的绝对值之和。输入的无人机图像不是原始图像,而是透视投影变换后的图像,它的外观与真实卫星图比较相似,因此可以使用L1损失。
即使LcGAN能够实现有效的监督效果,但是LL1能够帮助网络有效捕捉图像的低频特征信息,从而使图像生成网络得到收敛。
3)检索损失。MMNet 损失由交叉熵损失和RRT 损失[25]构成,RRT 损失定义如下:
MJLM 沿用了MMNet 所采用的MBM 采样策略。在一个训练批次中,选择P类ID 的目标建筑图像,每类ID 选择γ幅无人机视图,1 幅卫星视图。因此一个批次中,共有P× (γ+1)幅图像。(i,j,k)表示每次训练批次中的三元组;对于每张图像i,Pi是与之对应的正样本;Ni是与之相对应的负样本;分别表示正负样本对之间的距离分别代表每个正负样本对的正则化权重;αp、αn为正负样本的缩放系数。
2 实验与结果分析
2.1 实验设置
2.1.1 数据集
本文考虑新提出的无人机定位及导航任务数据集University-1652[17],由44 416 和137 218 对顶视图卫星图像和全景街景图像组成。这是目前为止唯一包含无人机视图和卫星视图图像的数据集。图像描绘了乡村和城市的街道场景。对图像的方向进行归一化处理,使北方向对应于卫星图像的顶部和街道图像的中心。每个建筑都与三个不同视角的图像相关联(如图8 所示),包括一个卫星视图图像,54 个不同高度和角度的无人机视图图像,以及一个或多个地面视图图像。本文利用卫星图像(垂直视角)和无人机图像(斜向视角)实现无人机视觉定位任务。对于大多数为倾斜视角的无人机视图数据集,使用透视投影变换能提高跨视角图像匹配性能和效率。

图8 University-1652数据集图像示例Fig.8 Samples of images from University-1652 dataset
2.1.2 实验细节
1)IPM。
University-1652 数据集使用合成的无人机图像代替真实的无人机图像。具体方法是将飞行轨迹设置为螺旋曲线。摄像机围绕目标飞行3 圈,飞行高度从256 m 下降到121.5 m。飞行视频以每秒30 帧的速度录制,每15 帧无人机视角视频中截取图像,生成54 幅无人机图像。因此,相同序列号的无人机图像在不同目标建筑位置上的角度和高度几乎相同,所以本文选择相同目标建筑的4 个点进行逆透视映射。具体来说,将一幢建筑物的无人机图像与对应的卫星图像进行尺度不变特征变化(Scale-Invariant Feature Transform,SIFT)[34]关键点匹配预处理,并确定对应的4 个视角点靠近卫星图像边缘的位置。鉴于张建伟等[30]提出的对于不同倾斜视角,仅改变a31和a13两个参数即可实现各个角度的正投影结论。本文结合University-1652 数据集的无人机图特性,在找到其他可靠的6 个参数的情况下,根据54 个倾斜视角仅需计算出54 套a31,a13参数组合,再结合输入无人机图像的角度类别参数,即可计算出54 组通用透视变换矩阵A参数,它可将54 个斜投影视图转换为54 个正投影视图。对于其他目标建筑而言,同样的序号选择与第一个基准建筑相同的单应性矩阵即可。
2)CVGAN。
本文使用Adam 优化器在PyTorch 中实现模型训练。动量参数β1和β2分别设置为0.5 和0.999,生成器和判别器网络的学习速率(learning rate)均设置为0.000 1。所有输入图像的分辨率均为256 × 256。通过随机水平翻转、随机裁剪以及随机旋转对真实卫星图及投影卫星图进行数据增强。此外,本文将像素强度值(pixel intensity values)归一化到[-1,1]。在训练期间,本文遵循GAN 优化的相关标准。具体来说,本文交替对两个网络进行参数更新,在每个训练周期中,先对生成器参数进行固定,训练判别器,使其尽可能区分真实数据与生成数据;再固定判别器参数,训练生成器,使其尽可能生成真实的数据。
3)MMNet。
MMNet 的骨干网采用了微调的ResNet-50,在ImageNet数据集上对ResNet-50 进行了预处理。本实验中,对于无人机分支,无论是训练还是测试,均以前置生成模型生成的特征图GE(Ips)为输入,其中前置生成模型的输入为256 × 256的无人机图像;对于卫星分支,输入的是256 × 256 的卫星图像。在训练时,使用随机水平翻转、随机裁剪以及随机旋转来增加数据的多样性。ResNet-50 stage4 下采样层的步幅由2 调整为1,以增加骨干输出的特征图的大小,这是图像检索中常见的技巧。本文采用多视角平衡采样策略,训练批次设置为32,γ设置为3,即一个批次中随机选取8 类目标地点图像,每类图像包含3 幅无人机视图和1 幅卫星视图。在反传过程当中,本文采用随机梯度下降法优化参数,momentum设置为0.9,weight_decay为0.000 5。骨干网初始学习率设为0.001,分类模块学习率为0.01,经过80 个epoch 完成训练。对于RRT 损失中的超参数,按经验分别设αp=5,αn=20。在测试过程中,利用欧氏距离度量Query 图像和Gallery 集中候选图像之间的相似性。本文模型在Pytorch 上实现,所有实验都在NVIDIA RTX 2080Ti GPU 上进行。最后,设置各个损失函数的权值为:λret=800,λL1=80,λcGAN=1。
2.1.3 评价指标
1)图像生成模型评价指标。对于图像生成任务,本文使用均方根误差(Root Mean Square Error,RMSE)、峰值信噪比(Peak Signal to Noise Ratio,PSNR)、结构相似性(Structural SIMilarity,SSIM)和锐度差(Sharpness Difference,SD)指标。这些指标根据原始几何空间属性量化了生成卫星图和真实卫星图的像素级差异。
2)图像检索模型评价指标。实验中,使用K-召回率R@K和平均精确率(Average Precision,AP)评估模型的性能。如果在Top-K的Ranking List 中查询图像的真实匹配图像出现在(K+1)图像之前,则R@K设置为1;否则,将其设置为0。较高的R@K表明网络性能较好。对于无人机定位任务,无人机视图数据库中有54 幅匹配图像。因此,为了尽可能全面地评估匹配结果,将AP 用作第二评估指标。AP 评估指标综合考虑了所有真实匹配图像的位置。
2.2 前沿方法对比
相较于ORB(ORiented Brief)[35]、SIFT、加速鲁棒特征(Speed-Up Robust Features,SURF)[36]这些基于传统手工特征的方法,可以发现基于深度特征的方法大幅提升了跨视角图像匹配的性能,取得了不错的效果。
在University-1652 数据集上进行了广泛的实验,通过和9 个具有竞争性的前沿方法进行比较以评估本文模型的性能。如表3 所列,与文中方法作对比的9 个前沿方法分别为:加权软边界三元组损失[10]、实例损失[17]、LCM(cross-view Matching based on Location Classification)方 法[20]、SFPN(Salient Feature Partition Network)方法[19]、LPN 方法[18]、PCL(Perspective projection transformation+Conditional generative adversarial nets+LPN)[26]、FSRA(Feature Segmentation and Region Alignment)方 法[22]、MMNet 方法[25]、MSBA(Multiscale Block Attention)方法[21]。由于MJLM 是为了无人机定位任务而提出的,且逆透视映射方法适用于倾斜视角至垂直视角的坐标变换,所以前置生成模型只做了无人机至卫星视图的图像生成任务,本文仅讨论MJLM 在无人机定位任务上的性能表现。

表3 University-1652数据集上MJLM与前沿方法的性能比较 单位:%Tab.3 Performance comparison between MJLM and state-of-the-art methods on University-1652 dataset unit:%
MJLM 在无人机定位任务中(无人机视图→卫星视图)的R@1 为87.54%,AP 为89.22%。相较于性能最好的MSBA 方法,MJLM 在无人机定位任务中的R@1 指标提升了1.07%,AP 指标提升了0.76%,这些数据表明MJLM 在University-1652 数据集上的无人机定位任务中优于现有的最佳方法。
此外,MJLM 方法可以作为前沿方法的补充,当MJLM 的前置生成模型与LPN 结合时(IPM+CVGAN+LPN),可以发现在无人机定位任务的R@1 和AP 指标上较LPN 上分别提高了5.65 和6.31 个百分点。由此看出多任务联合学习方法可以有效提高无人机定位模型的匹配性能。
如图9 所示,MJLM 模型在无人机定位任务中均成功检索到了对应的卫星图,并在ranking-list 中排第一。

图9 无人机定位任务结果图Fig.9 Result graphs of UAV localization tasks
2.3 消融实验
2.3.1 联合训练对前置生成模型的影响
对于前置生成模型,考虑了以下消融实验,结果如表4所示。

表4 University-1652数据集上前置图像生成模型的消融实验结果Tab.4 Ablation study results of proactive image generation model on University-1652 dataset
1)将经过IPM 的投影卫星图与输入的卫星图像进行浅层特征比较(记作i)。
2)对前置生成模型单独进行训练(记作ii),为了探究在没有检索任务联合训练下的图像生成质量。
3)将前置生成模型联合后置检索模型同时进行训练,本文分别采用LPN(记作iii)和MMNet(记作iv)作为后置检索模型,以确认不同检索分支网络模型对联合训练是否有较大的影响。
通过对比表4(i)与(ii)可发现,经过CVGAN 后可得到更加真实的卫星视角图像。对比表4 w/o R 与w/ MMNet 消融实验结果可发现,联合训练确实有利于图像生成任务。原因是,多任务的学习方式会反向促使生成对抗网络学习更优秀的特征,最终同时提高两项任务的性能。通过对比表4 w/LPN 与w/ MMNet 消融实验结果可发现,检索分支采用不同网络模型,对图像生成质量影响不是特别大,但结合全局与局部特征进行多监督学习的MMNet 确实更有利于生成高质量的卫星图。
2.3.2 前置生成模型对后置检索模型定位效果的影响
为了在University-1652 数据集上研究了前置生成模型的不同组件对后置检索模型的定位性能影响,进行以下消融实验,结果如表5。

表5 University-1652数据集上后置图像检索模型的消融实验结果 单位:%Tab.5 Ablation study results of posterior image retrieval model on University-1652 dataset unit:%
1)放弃显式的IPM 变换,将未经过投影映射的真实无人机图作为CVGAN 的输入(记作i),这意味着仅利用CVGAN进行隐式的学习训练。
2)放弃CVGAN 中生成器G的解码器和判别器D,直接将编码器编码的潜在特征GE(Ips)作为后置检索模型中无人机分支的输入(记作ii),这意味着前置生成模型几乎仅使用了显式的IPM 变换,不能对图像进行内容和几何特征增强,可以看出效果并不太好。
3)仅放弃CVGAN 中的判别器D,意味着放弃了LcGAN,仅基于L1 损失LL1去预测生成卫星图(记作iii)。这意味着生成器没有经过和判别器的博弈训练,直接生成卫星图。因为它不能利用生成对抗训练的学习能力,生成的卫星图显得并不真实,但由于LL1至少一定程度上支持图像检索任务,所以这种修改对精度的降低不是特别明显。
4)将生成的图像G(Ips)作为MMNet 的无人机分支输入,而不是传递编码器GE的潜在网络瓶颈层特征(记作iv),可观察到性能的下降。因为生成图像相较于深层网络瓶颈层特征GE(Ips)多了解码再编码的过程,自然会丢失很多细粒度信息。
通过对比表5 的MMNet、(i)、(ii)三个消融实验可发现,CVGAN 和IPM 单独使用,效果提升并不明显,其中IPM 对R@1 的提升效果较强,CVGAN 对AP 提升明显一些。而当IPM 与CVGAN 联合训练后,效果提升非常明显。综上所述,表5 的结果表明,前置生成模型确实有利于提高整体匹配性能。
2.4 任务性能分析
2.4.1 拍摄距离对定位的影响
University-1652 数据集中卫星图像的要素比例是固定的,而无人机图像的要素比例随着无人机到地理目标的距离和角度而动态变化。本文采用距离地理目标不同距离的无人机图像作为查询图像,研究距离变化对MJLM 的影响。如表6 所示,当无人机图像在距离地理目标的中度距离拍摄时,获得了最佳性能。当无人机距离地理目标较近时,与使用全部无人机图像作为查询图像相比较,结果仍然具有竞争力。通过大量观察,可得出原因,即这些图像在要素比例上非常接近卫星图像;另外一个可能原因是,这些无人机图像主要为目标建筑,没有额外的树木和其他建筑干扰物。

表6 University-1652数据集上拍摄距离对定位性能的影响 单位:%Tab.6 Influence of shooting distance on localization performance on University-1652 dataset unit:%
2.4.2 偏移不变性
在现实场景中,查询图像和真实匹配的卫星图之间的目标位置通常会有偏移。为了探究MJLM 是否能够应对这种现实应用场景的挑战,在测试过程中验证MJLM 对位置偏移的鲁棒性,实验结果见表7。具体来说,将查询图像以像素为单位向右平移0~50 像素,保持Gallary 集中的图像不变,0表示不对查询图像进行偏移。实验结果表明,当偏移量从0缓慢增加时,模型性能没有特别明显的变化。在30 像素的偏移量内,性能只是略微下降,即使偏移量达到50,也依然具有竞争力。如图10 为MJLM 与当前性能较好且权威的LPN 的对比结果,可以看出,随着偏移量的增加,模型的衰减比现有模型的衰减要小得多,这说明模型对位置偏移的鲁棒性更强。2.4.3 旋转不变性

图10 偏移不变性消融实验对比图Fig.10 Comparison map of offset-invariance ablation experiment

表7 University-1652数据集上偏移不变性的验证结果 单位:%Tab.7 Verification results of offset-invariance on University-1652 dataset unit:%
由于University-1652 数据集中的卫星视图是北向(图片0 度方向朝北)的,而无人机视图的方向是随机的。在训练阶段,旋转增强仅仅应用于卫星视图分支,而无人机视图不受影响。为了验证MJLM 的旋转不变性性能,本文通过实验将查询图像进行旋转来进行跨视角匹配。实验结果如表8所示,其中0°表示没有旋转的输入查询图像。对于无人机定位任务,MJLM 仍然实现了有竞争力的性能目标,而没有显著的性能下降。此外,本文还尝试在Query 集和Gallery 集上旋转不同的角度,以进一步测试模型的性能。实验结果表明,该模型对旋转变化具有良好的可扩展性。

表8 University-1652数据集上旋转不变性验证结果Tab.8 Verification results of rotation-invariance on University-1652 dataset
3 结语
本文从决策级层面出发,通过多任务联合学习方法实现跨视角地理定位任务。在一个聚合框架体系内联合处理跨视角(无人机-卫星视图)图像生成任务以及检索任务,实现基于视角转换与视点不变特征方法的融合。具体来说,MJLM 将给定的一对无人机图像和卫星图像映射到它们的潜在特征空间并建立联系,使用这些特征来完成这两个任务。通过在University-162 数据集上的大量实验,表明了MJLM 相较于前沿方法的先进性,此外还可作为前沿方法的补充,更进一步提升跨视角地理定位的性能。消融实验验证了前置生成模型与后置检索模型联合训练的有效性。另外考虑MJLM 工程应用场景的鲁棒性,从拍摄距离、偏移不变性、旋转不变性等角度进行了实验,同样验证了模型在准确性和鲁棒性方面的良好表现。
下一步工作将继续探索如何进一步提高无人机图像与与卫星图像的匹配精度及鲁棒性,以及如何利用无人机图像作为中间桥梁,提高地面街景图与卫星图像的匹配精度。
