基于Transformer的结构强化IVOCT导丝伪影去除方法
2023-05-24郭劲文马兴华骆功宁王宽全
郭劲文,马兴华,骆功宁,王 玮,曹 阳,王宽全*
(1.哈尔滨工业大学 计算学部,哈尔滨 150001;2.哈尔滨医科大学附属第一医院,哈尔滨 150001)
0 引言
心血管疾病(CardioVascular Disease,CVD),亦称循环系统疾病,是一系列涉及循环系统的疾病,通常由粥样动脉硬化导致。据最新公开的心血管疾病数据统计,国内身患心血管疾病的人口数量已达3.30 亿,且患病人数依然在不断增长。在国内主要疾病死亡人数的统计中,CVD 占城市居民主要疾病死亡的43.81%,而在农村居民主要疾病死亡的占比更是高达46.66%[1]。随我国日益严重的老龄化趋势,CVD的死亡率依然在不断攀升,已对国民健康和社会发展造成了巨大影响。
有效的预防、检查及治疗可显著降低CVD 的死亡率,血管内光学相干断层扫描(IntraVascular Optical Coherence Tomography,IVOCT)技术凭借它针对心血管的良好成像已成为医生诊断CVD 的重要手段。IVOCT 是迄今最前沿的现代化血管成像技术之一,通过近红外光反射的血管内成像模式成像,在生物组织的成像领域展现了可靠的性能[2-3]。该技术以弱相干光干涉仪的基本原理作为理论基础,检测入射弱相干光在生物组织深浅层面背向反射或散射信号的差异,生成生物组织的结构影像。
具体而言,IVOCT 基于迈克尔逊干涉测量法并使用超高亮度二极管发射器作为光源。光源射出的光通过光纤进入光纤耦合器后形成两束光束,其中一束进入待观察物体,而另一束则进入图像信号接收系统。由两条路径反射或反向散射的光通过光纤耦合器重新集成到光束中并由检测器接收。随后测量光散射的辐射能和通过生物组织时间在不同深度组织之间的差异,进而通过显示伪色的灰度值得到生物组织影像,其中:浅色(如浅黄色和浅绿色)代表辐射较强的区域;暗色(如蓝色和黑色)代表辐射较弱的区域;绿色代表辐射平均的区域[4-6]。
在临床IVOCT 系统中,数据采集使用了包括定位(Position)、清洗(Purge)、喷入(Puff)以及回撤(Pullback)在内的4P 方法[7-9]。在数据采集过程中:定位用于确定目标位置;清洗利用造影剂清洗成像导管的管腔血液;喷入确保指引导管与冠脉同轴;回撤将近红外光传输到探头并通过导丝拖拽采集连续的截面反射信号实现管腔内影像的采集。高反射的人造物导丝会导致探头发射的近红外光发生反射,因而在拖拽的过程中,极坐标图像的导丝区域会形成高亮的月牙形伪影,且导丝的遮掩将导致所成影像的导丝后方存在贯穿整个图像的黑色矩形伪影,如图1 所示。IVOCT 检查的所有成像均会不可避免地出现上述导丝伪影,其中伪影面积约占单张影像的10%并且贯穿整个图像,伪影区域的管腔内壁组织信息无法被获取。
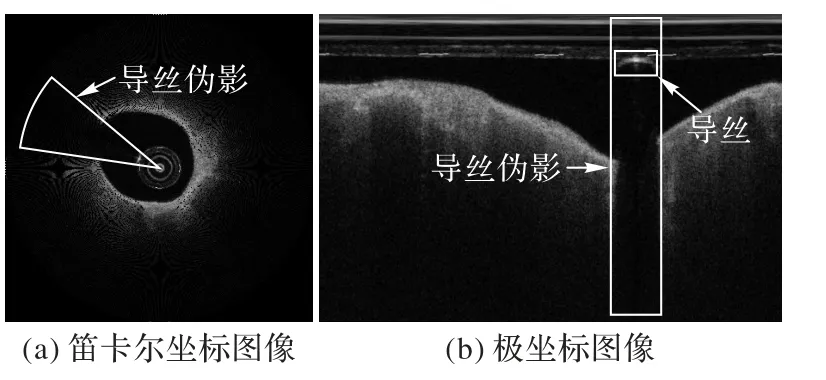
图1 IVOCT图像与导丝伪影Fig.1 IVOCT image and guidewire artifact
医生在观察IVOCT 序列时,可根据临床经验结合序列上下帧之间的影像信息和导丝伪影运动轨迹,推测导丝伪影区域的影像信息,进而分析管壁与斑块的表征并诊断CVD。但临床经验的差异可能导致不同医生对于导丝伪影区域图像信息的推测不一致。去除导丝伪影能够促进医疗影像系统的现代化和IVOCT 影像诊断CVD 的标准化,有助于医生更加准确地诊断CVD,减小误诊与漏诊的概率。
为去除IVOCT 导丝伪影,本文提出了基于Transformer 的结构强化网络(Structure-Enhanced Transformer Network,SETN),以生成器(Generator)和判别器(Discriminator)构成的生成对抗网络(Generative Adversarial Network,GAN)架构重建导丝伪影区域图像,以提高IVOCT 图像的连续性与完整性。根据IVOCT 图像管壁结构复杂以及序列上下帧具有关联性的特点,SETN 的生成器关注序列上下文信息且针对IVOCT 的管壁结构进行了强化设计。为关联上下帧特征并通过邻帧信息强化待复原区域的语义描述,SETN 使用了能够同时分析单帧空间位置和序列时序的Transformer 模块挖掘序列的上下文关联性。此外,在原始图像(ORIginal image,ORI image)主干生成网络的基础上,SETN 引入了并联的RTV(Relative Total Variation)[10]图像强化生成网络完成ORI 图像和与之对应RTV 图像导丝伪影区域的重建。RTV重建获取的结构特征被融入ORI 图像的纹理特征,用于辅助ORI 主干生成网络对导丝伪影区域的图像重建。
本文的主要工作为:1)首次提出了一种基于Transformer的结构强化网络SETN 用于去除IVOCT 图像中结构信息复杂且区域占比大的导丝伪影;2)结合IVOCT 图像结构复杂的特点,提出了在RTV 图像上提取结构特征的RTV 强化生成网络,用于在ORI 重建图像时强化IVOCT 的图像结构以提高导丝伪影去除性能;3)设计了关注时/空间域信息的Transformer 编码器,分别从单帧空间域和序列时间域的角度挖掘IVOCT 序列图像特征的上下文关联性;4)分别从伪影区域重建性能和计算机辅助诊断(易损斑块分割以及管腔轮廓线提取)的角度验证了本文导丝伪影去除方法的实效性。
1 相关工作
通过伪影去除技术提高医疗图像的成像质量在医疗影像的临床应用中具有重要意义。在放射影像检查中,由金属物植入导致X 光线衰减形成的放射状伪影可以通过去噪技术消除[11]。而IVOCT 为光学成像技术,它的伪影由近红外光的导丝反射导致部分区域无法成像。图像补全技术能有效处理区域较大且集中的图像缺失,因此本文基于图像补全技术提出IVOCT 导丝伪影去除方法。
1.1 基于传统方法的图像补全
基于传统方法的图像补全技术主要分为两类:基于补丁的方法和基于扩散的方法。
基于补丁的方法依次搜索缺失区域并填充高匹配度的补丁。Liu 等[12]使用了马尔可夫随机场模型估计并结合单应性变换以增强修复与周围区域的一致性和结构的连贯性;Ding 等[13]提出了一种利用非局部纹理匹配和非线性滤波的图像补全方法以兼顾图像强度和纹理的一致性。
基于扩散的方法将图像信息从边界扩散到缺失区域以实现缺失区域的填充。Li 等[14]提出了一种基于扩散的图像补全方法,通过定位补全区域后利用通道内和通道间变化的局部方差实现数字图像的补全;Sridevi 等[15]提出了一种基于分数阶导数和傅里叶变换的扩散图像补全方法,以解决补全中阶梯状和散斑伪影的问题。
基于传统方法的相关技术初步探索了图像补全的技术路线,并为该任务提供了清晰的解决思路,但与后续发展的深度学习技术相比,传统方法普遍存在难以应对复杂图像和高占比缺失的缺陷。
1.2 基于深度学习的图像补全
随着近年来深度学习算法的不断发展与完善,图像补全技术得到长足的发展,基于深度学习方法的图像补全技术主要采用卷积神经网络(Convolutional Neural Network,CNN)和Transformer 两种网络构架。
1.2.1 CNN
深度学习首先以普遍适用于计算机视觉(Computer Vision,CV)任务的CNN 架构引入图像补全任务。基于CNN的图像补全方法使用编码器-解码器的网络结构提取图像特征并复原图像信息。Xie 等[16]提出了一种自动编码预训练的深度网络修复模型,利用无监督特征学习实现了图像的修复;Favorskaya 等[17]使用全连接网络对去除视频序列中的伪影后的纹理进行重建;Köhler 等[18]通过卷积层学习像素破坏图像块到完整图像块的映射,进而修复特定掩码区域。
基于CNN 的方法擅长细节的重建,但受限于修复区域的尺寸等因素。随着深度学习技术的发展,以CNN 为图像生成基础的GAN 架构[19]被提出应用于图像的生成和补全任务,此类方法利用随机产生的噪声逐渐生成待修复对象,克服了CNN 方法受限于修复区域的缺点。GAN 是一个包含生成器G和判别器D(两个前馈网络)的博弈学习模型。其中,G通过真实图像训练模型参数并生成全新的图像,而D通过训练鉴别真实图像与生成图像的差异。若D无法区分生成图像与真实图像,则认为G的性能满足要求,这种关系可认为是G和D竞争的最小最大博弈。综上所述,G(D)试图最小化(最大化)对抗损失V(D,G)作为损失函数,如式(1)所示:
其中:z和x分别表示噪声Pz(z)和真实数据分布Pdata(x)采样的随机噪声向量和真实图像。
在图像补全相关方法中,G通过学习完整图像特征生成缺失区域图像信息,D鉴定生成的图像信息的可信度。Kim等[20]提出了一种聚合相邻帧时间特征的循环神经网络(Recurrent Neural Network,RNN),实现了VINet 模型修复视频;Chang 等[21]使 用了改进3D 门控卷积以及T-Patch GAN(Temporal Patch GAN ),提出了LGTSM(Learnable Gated Temporal Shift Module),最终实现了自由形式遮掩的视频补全;Lee 等[22]提出了复制并粘贴参考帧相应内容的深度学习网络框架CAP(Copy-And-Paste)以补全目标帧中缺失区域。
尽管堆叠卷积层能够使CNN 提取较抽象的高级语义特征,但依然存在全局信息获取有限、图像不同区域间语义信息相对独立等局限性。而近年提出的Transformer[23]网络架构使用注意力机制实现全局上下文信息的捕获,能获取目标相关的长距离关联性特征。
1.2.2 Transformer
Transformer 是一种基于注意力机制的网络构架,最先应用于自然语言处理(Natural Language Processing,NLP)领域。Transformer 凭借其强大的序列信息处理能力,成为了当前完成NLP 相关任务的最先进的深度学习模型。由于它在NLP领域各项任务中优异的性能表现,CV 领域的研究人员也开始探索Transformer 在CV 任务上的应用潜力。Dosovitskiy等[24]首次提出了Vision Transformer(ViT)应用于图像分类任务。而后随着Transformer 在CV 领域的快速发展,它在CV 领域得到了大规模的普及并被用于处理包括图像补全在内的各类CV 任务。
与Transformer 相比,CNN 的局部语义信息处理仅计算相邻像素间的关系,无法快速获得上下文信息,而RNN 的线性序列分析结构仅能有限地计算单向依赖的语义信息。Transformer 分析序列上下文信息不受长期依赖问题的影响,能够避免因序列过长导致的性能下降。由于在序列分析上的优势,Transformer 也被应用于图像补全工作中。Jiang 等[25]提出一个Transformer GAN 模型验证了Transformer 架构应用于图像生成任务的可行性;Zeng 等[26]提出了一个时空联合Transformer 网 络(Spatial-Temporal Transformer Network,STTN)模型,实现了对视频运动对象缺失帧的修复。
与自然图像相比,医疗图像具有图像相似度高、聚焦细微结构的纹理特征以及不同模态之间差异大的特点,因此针对任务数据特点的图像补全方法虽然在相应的各类自然图像的补全任务上具有很好的性能,但迁移至如IVOCT 图像的医疗图像补全任务上时,性能会有所下降。本文针对IVOCT影像的特性设计了SETN,使用先进的Transformer 分析序列上下文信息,且在兼顾纹理特征的同时加强了图像结构特征。
2 基于Transformer的结构强化方法
本文提出了基于SETN 的IVOCT 导丝伪影去除方法,SETN 为生成器和判别器构成的GAN 模型。
生成器的网络结构如图2 所示,包括ORI 图像主干生成网络、RTV 图像强化生成网络以及结构特征融合模块。ORI图像主干生成网络是生成器的主干网络,主要提取ORI 图像的纹理特征并针对原始图像的导丝伪影区域进行重建;RTV图像强化生成网络是生成器的并行分支网络,主要通过提取结构特征并重建RTV 图像伪影区域的方式为主干网络提供结构信息辅助ORI 图像的伪影去除;结构特征融合模块融合RTV 图像强化生成网络获取的结构特征与ORI 图像主干生成网络获取的纹理特征,为ORI 图像的解码还原提供兼顾纹理与结构的图像特征。
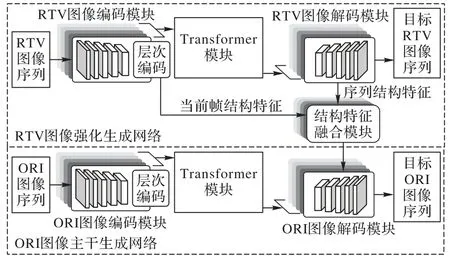
图2 SETN生成器的网络结构Fig.2 Generator network structure of SETN
SETN 使用两个T-Patch GAN 判别器分别监督ORI 主干生成网络和RTV 强化生成网络的重建结果,它的设计对于难以重建或需要精细化的区域进行了更加细节化的处理。
2.1 ORI主干生成网络
ORI 主干生成网络以未作处理的极坐标IVOCT 图像序列作为输入,重建图像缺失区域信息以完成导丝伪影的去除,包括ORI 编码模块、Transformer 模块以及ORI 解码模块。ORI 编码模块将输入序列中待去除伪影图像以单帧形式处理提取图像纹理特征;Transformer 模块由顺序连接的6 个Transformer 编辑器组成,用来建立整个图像序列各帧编码特征之间的上下文关系;ORI 解码模块根据ORI 编码模块和Transformer 模块获取的具有序列信息的特征以单帧的形式重建导丝伪影区域。
2.1.1 ORI编码模块
由于导丝伪影的尺度分布不均,为将不同尺度特征输入空间结构固定的Transformer 模块,同时防止简单的卷积堆叠破坏特征间的联系,SETN 的ORI 编码模块被设计为特征编码+层次编码的编码模式,为Transformer 模块分析序列上下文信息提供高鲁棒性的纹理特征。
特征编码对ORI 图像进行基本特征提取,为后续的层次编码提供尺度递进的纹理特征。它由5 组卷积核大小为3×3的卷积层和负斜率为0.2 的带泄漏线性整流函数(Leaky Rectified Linear Unit,LeakyReLU)激活层交替连接组成,其中卷积层的输出通道数量为[64,64,128,128,256]。
层次编码提取不同尺度的ORI 图像特征,为应对不同尺度导丝伪影的解码重建而设计实现了不同层次特征的逐帧混合,为序列各帧图像提供层次化语义特征。它的结构设计与特征编码相同,但为实现层次化特征提取,卷积层以[1,2,4,8,1]的分组方式完成分组卷积,其中每个层次编码的输出的通道数为[384,512,384,256,128]。此外层次编码相邻卷积层执行Concat 操作,以实现多级通道层次的混合。
SETN 通过特征编码与层次编码获取输入图像序列中ORI 图像的不同尺度纹理特征,为后续的Transformer 模块提供了高鲁棒性强的层次化特征向量。
2.1.2 Transformer模块
在IVOCT 图像序列中,序列上下文信息可以为导丝伪影去除提供更加丰富的语义信息。因此在单帧图像特征提取后,SETN 使用善于捕获全局上下文信息的Transformer 通过注意力机制建立序列帧之间的关联。本文设计了能够分别提取IVOCT 图像时/空间域上下文信息的Transformer 模块,在分析序列时序关联性的同时,建立单帧图像不同位置特征之间的联系。
Transformer 模块由顺序连接的6 个Transformer 编码器组成。通过不同尺度的patch 划分和flatting 操作,特征序列被转化为embedding 序列并输入至Transformer 编码器。在Transformer 编码器中,时间域特征整合器(Temporal Domain Feature Integrator,TDFI)和空间 域特征 整合器(Spatial Domain Feature Integrator,SDFI)分别从序列各帧关联性的时间域和单帧各位置关联性的空间域两个角度处理整合序列,如图3 所示,图3 中⊕代表邻层间的残差连接,通过四方格划分的方形块代表图像的patch 特征。
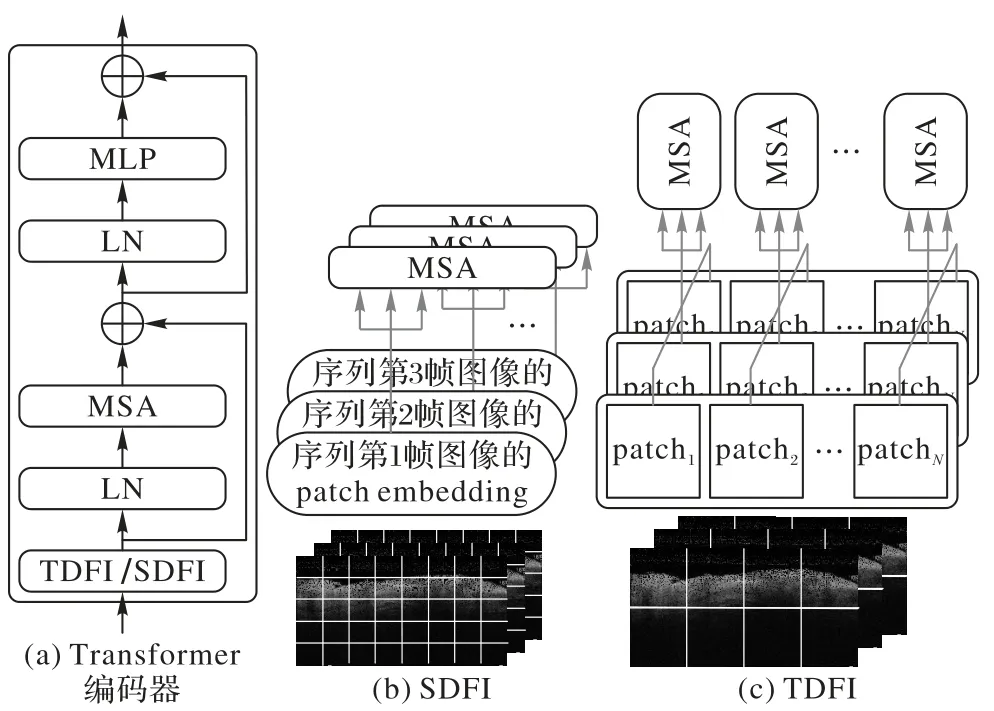
图3 Transformer编码器与时/空间域特征整合器Fig.3 Transformer encoder and temporal/spatial domain feature integrators
TDFI 按序列时序将每一帧位置相同的patch embedding排列为embedding 序列,以完成同位置patch 在序列维度上的语义特征分析,进而在上下帧图像中查找各帧patch 区域内与待重建区域相符的特征。由于时间域特征分析以全局角度在图像序列中查找注意力信息,TDFI 整合特征划分patch的尺寸设置较大(起始Transformer 编码器TDFI 的patch 尺寸设置为7×7),以增大在时序序列中查找缺失区域相关特征的感受野。
SDFI 将单帧图像的patch embedding 排列为空间维度的embedding 序列,以建立单帧图像不同位置特征之间的联系。与TDFI 相比,SDFI 关注单帧图像的空间关联性,以捕获与待重建区域有关的单帧图像内语义信息。SDFI 整合特征划分patch 的尺寸设置较小(起始Transformer 编码器SDFI 的patch尺寸设置为3×3),以获取更多的小尺度纹理描述,并在同帧图像中查找缺失区域相关的纹理特征。
由于ORI 编码模块获取的特征向量代表不同尺度特征,SETN 以不同尺度特征的Transformer 编码器完成不同尺度特征分析。在Transformer 结构中,每个Transformer 编码器的输入patch 尺寸皆以与之相连的前一个编码器的2 倍递增。
将通过TDFI 与SDFI 整合的embedding 序列并行输入Transformer 编码器,其中序列位置编码的设计遵循ViT。Transformer 编码器由多头自注意力(Multi-head Self-Attention,MSA)子模块 和多层 感知器(Multi-Layer Perceptron,MLP)子模块顺序连接组成,其中层标准化(Layer Normalization,LN)应用于每个子模块之前,残差连接应用于每个子模块之后。残差连接能够使模型关注当前模块前后差异以防止网络退化,LN 使输入数据均值方差相同以加快网络收敛。
为使Transformer 编码器具有更好的拟合能力且处理序列更加稳定,MSA 子模块集成了多个并联的自注意力(Selfattention)层,以避免单个自注意力层序列信息获取的局限性,其中自注意层通过Query、Key 和Value 三元组计算目标输入序列各embedding 之间的关联性,计算过程可具体表示为:
其中:(Q,K,V)为输入序列与可学习参数矩阵相乘得到的Query、Key 和Value 三元组;d为Query/Key 的维度(实验模型设置为32)。MSA 子模块并联多个自注意力层的计算可具体表示为:
其中:Qi、Ki和Vi分别为第i个自注意 力层的Query、Key 和Value 三元组;head为单个注意力层学习的注意力参数矩阵;WO为将多个自注意力层的拼接维度映射至输出维度的可学习参数;h为实验模型head数量,设置为8。
2.1.3 ORI解码模块
为将Transformer 模块完成序列分析后的图像纹理特征用于导丝伪影去除任务,本文设计了与ORI 编码模块中特征编码对应的ORI 解码模块以重建导丝伪影区域图像。
ORI 解码模块通过上采样将图像特征转化为ORI 图像信号。它的结构特征编码相对称,由5 层的卷积核大小为3×3 且连接LeakyReLU 激活层的反卷积层组成,其中插值使用scale_factor 设置为2 的双线性(bilinear)处理方式实现。
2.2 RTV强化生成网络
ORI 主干生成网络为导丝伪影去除提供图像细节的纹理特征,而RTV 化IVOCT 图像能够有效地表达图像结构信息。因此本文设计了RTV 强化生成网络用于重建RTV 图像的导丝伪影区域,并通过纹理特征融合模块将结构特征引入ORI 图像的导丝伪影去除。
2.2.1 IVOCT图像RTV化
RTV 强化生成网络的输入为通过RTV 化得到的RTV 图像序列。RTV 化[10]是一种图像的结构化分离方法,它的实现总变差分模型可具体表示为:
其中:I和S分别为输入原始图像和输出结构化图像;p为二维图像像素索引;λ表示结构图像与原始图像的相似权值;∇为梯度算子。
图像RTV 化的主要参数设置包括:λ∈(0,0.05],用于控制平滑的程度;σ∈(0,6],用于确定最大纹理选择;sharpness∈(0.001,0.03],用于控制图像锐化;Itermax控制转化迭代次数。不同参数值设置的RTV 化图像结果如图4 所示,与其他结果相比,图4(c)中RTV 图像纹理消除有效且结构清晰,因此本文IVOCT 图像序列的RTV 化遵循图4(c)的参数设置。
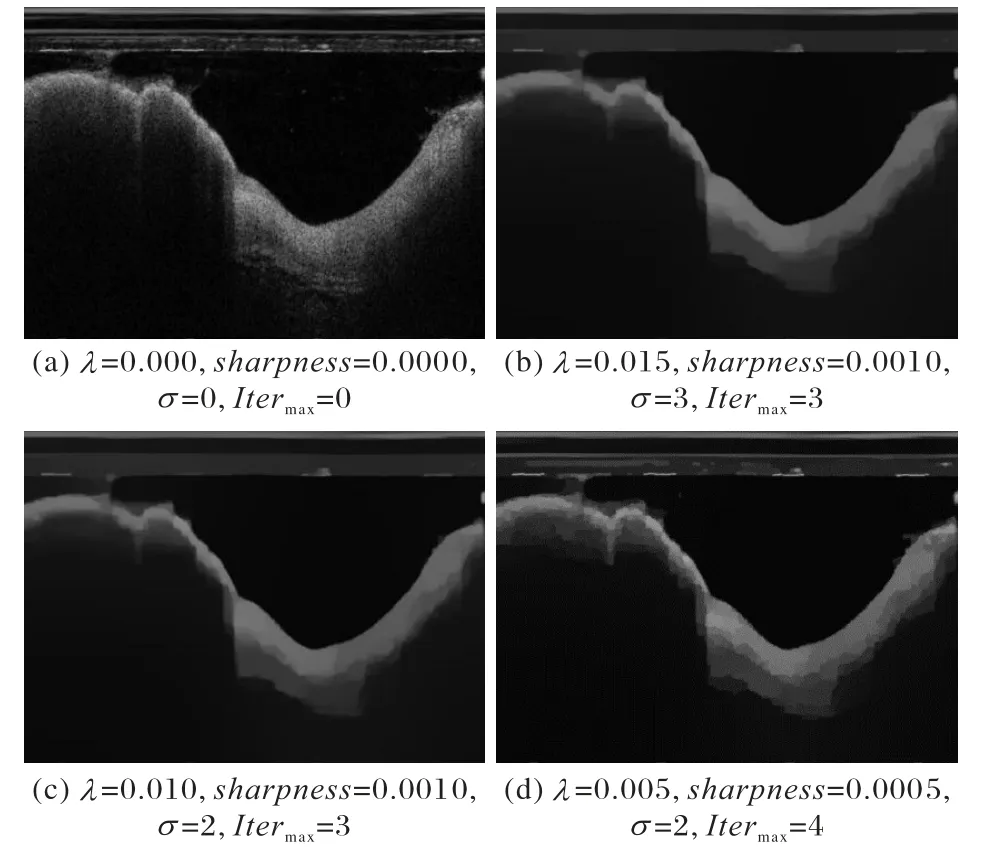
图4 IVOCT图像的RTV化结果Fig.4 RTV results of IVOCT image
2.2.2 RTV强化生成网络结构
RTV 强化生成网络的结构组成与ORI 主干生成网络相同,包括参数一致的RTV 编码模块、Transformer 模块以及RTV 解码模块,其中两个生成网络的Tranformer 模块实现参数共享以减少网络参数量。
RTV 强化生成网络的Transformer 模块亦由4 个包括TDFI 与SDFI 的Transformer 编码器组成。为保证模型效率的同时关联更丰富的高相似度值patch 特征,SDFI 将以当前帧与上、下帧共计3 帧的patch 作为输入。此外,因在较大patch上提取的结构特征能够更好地描述图像结构,输入至SDFI的初始patch 尺寸设置为7×7。
2.3 结构特征融合模块
结构特征融合模块把RTV 强化生成网络获取的结构特征融合至ORI 主干生成网络提取的纹理特征中,以在导丝伪影区域的图像重建过程中实现结构强化。
如图5 所示,待融合结构特征主要包括当前帧结构特征和序列结构特征。当前帧结构特征为RTV 编码模块最终提取的结构特征Fself,它可为修复导丝区域边界结构提供良好的性能。序列结构特征为RTV 解码模块不同尺度反卷积层计算特征及它们是时序维度获取的全局结构信息。上述序列结构特征根据下采样由深到浅获得,较深的下采样特征趋近于描述图像的整体构架,而较浅的下采样特征趋近于描述图像的细节特征。
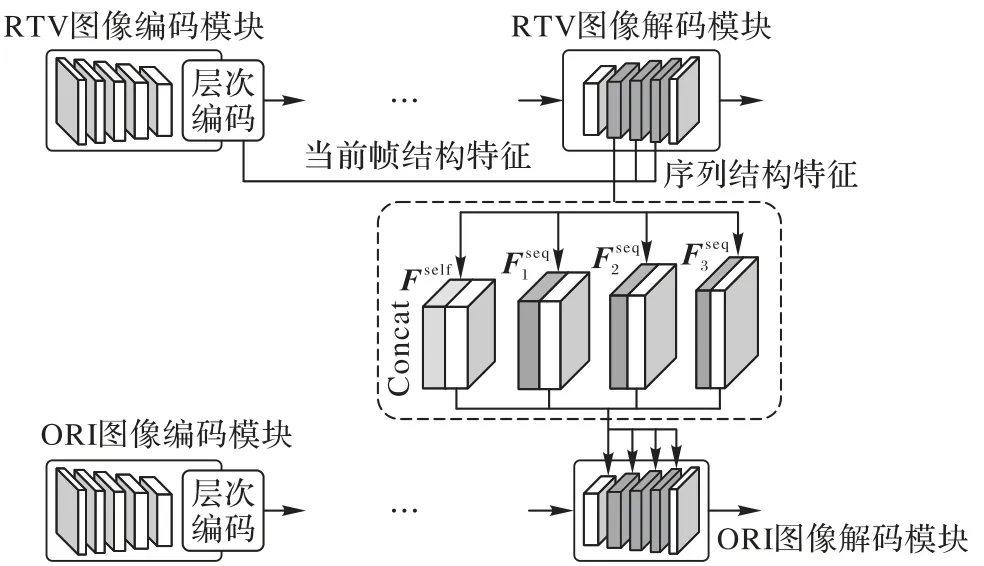
图5 结构特征融合模块Fig.5 Structural feature fusion module
结构特征融合模块将当前帧结构特征和序列结构特征融入主干网络获取的纹理特征方式如图5 所示,Fself、及与ORI 解码模块对应层的输入进行Concat 操作,Concat 所得完成结构强化的纹理特征将输入至对应反卷积层。该融合模块按照次序依次完成下采样由深到浅的不同层次特征融合。
2.4 损失函数
本文的SETN 设计采用GAN 的网络架构,因此损失函数包括重建损失函数与对抗损失函数两类,其中重建损失函数使用像素级重建损失函数(即L1 损失)。
生成器的重建对象包括ORI 和RTV 两种图像,因此重建损失函数分为ORI 重建损失和RTV 重建损失。
ORI 重建损失是针对原始图像缺失重建设计的损失,该损失计算模型输出的补全图像序列与目标图像序列的差异,其间两者的差值与待重建区域的掩码信息相乘,而后计算单个像素的平均差异,计算方式如下:
其中:Mt为ORI 图像序列的待重建区域掩码信息为完成ORI 补全的图像序列;为输入序列与掩码值的乘积,即ORI 主干网络的输入序列数据;⊙表示同或运算。
为了使补全内容在缺失边界上与原图像具有一致性,同时也使补全结果更加符合原始未缺损图像,缺失边界损失的计算方式与式(5)一致,不同在于它的掩码信息保留非待重建区域的图像,在缺失边界损失计算方式如下:
ORI 总重建损失由缺失重建损失与缺失边界损失加权相加得到,计算方式如下:
其中:λhole与λvalid分别为与两个损失函数的加权参数。
RTV 重建损失与ORI 重建损失LORI的计算方式类似,针对缺失区域和缺失边界图像设计的损失分别为与且该损失也由两个损失函数的加权相加得到,加权参数设置与ORI 重建损失一致,计算方式如下:
重建损失函数Lrec由ORI 重建损失LORI与RTV 重建损失LRTV构成,其中RTV 结构图像在补全时强化结构以辅助重建,因此两个损失的重要性需要通过加权制衡。重建损失函数Lrec计算方式如下:
其中:ω为LORI与LRTV两个损失函数的加权参数(取值范围为[0,1])。
对抗损失函数由判别器对抗损失及生成器对抗损失函数组成,其中判别器对抗损失计算方式如下:
其中:Yt为与待补全图像序列对应的Ground Truth,即无导丝伪影的IVOCT 影像序列。
生成器对抗损失分为ORI 对抗损失以及RTV 对抗损失,两者计算方式相同且加权相加,生成器对抗损失的计算方式如下:
生成器的损失由重建损失及生成器对抗损失函数加权相加得到,计算方式如下:
其中:λrec与λadv分别为Lrec与Ladv两个损失函数分配的权值。以上参数数值选定的标准通过相关经验及实验确定,具体的参数数值如表1 所示。
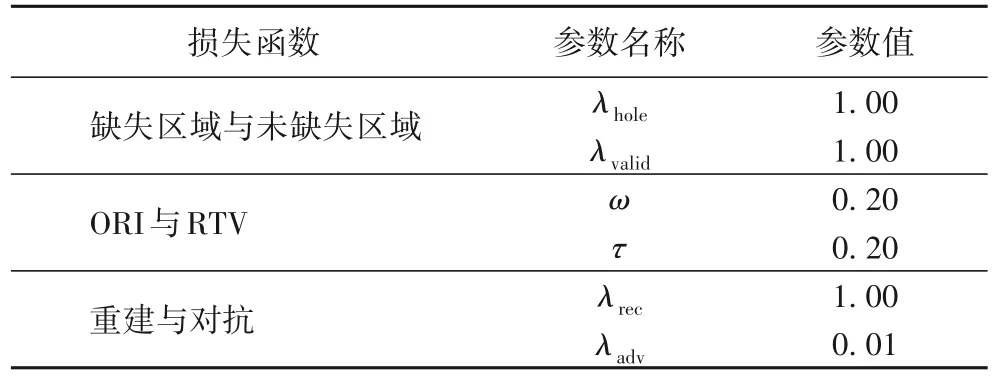
表1 损失函数参数值Tab.1 Parameter values of loss function
3 实验与结果分析
3.1 数据预处理
本文实验所用数据集由哈尔滨医科大学附属第一医院提供,包括137 组来自不同患者的IVOCT 影像序列,其中每个图像序列包括50 帧连续的IVOCT 图像。本文SETN 的输入序列长度设置为10,因此每组的数据将被分为5 段10 帧的IVOCT 图像序列,其中100 组的数据被划分为训练数据,其余组的数据被划分为测试数据。在上述序列中每帧图像均含有导丝伪影,其中导丝伪影均由专业医生标注。
为保证实验验证与分析的真实性和准确性,本文使用如图6 所示方法对IVOCT 图像序列的单帧图像分别进行预处理,以构建具有真实Ground Truth 的导丝伪影去除单帧训练数据。在图6 的添加导丝伪影的步骤中,根据导丝伪影的宽度分布统计,按图7(a)中概率分布的导丝宽度期望在拼接图像中添加不同宽度的导丝伪影(同序列图像中伪影宽度一致)。
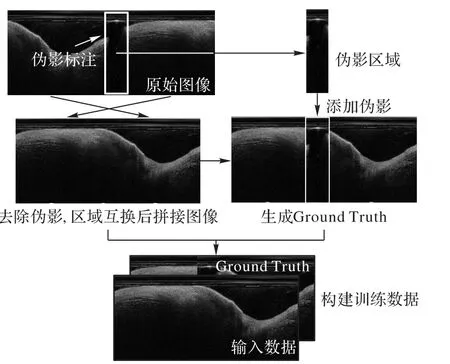
图6 IVOCT单帧图像预处理流程Fig.6 Flow of IVOCT image preprocessing
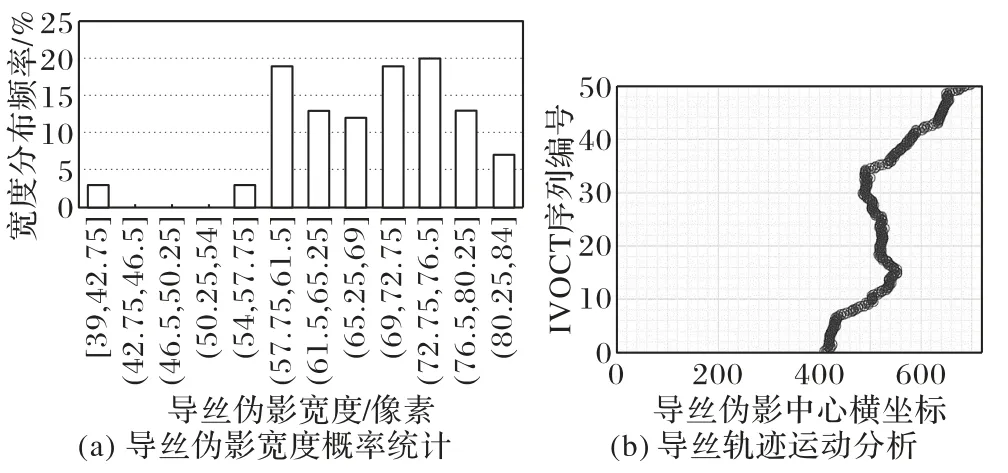
图7 伪影轨迹和宽度统计Fig.7 Artifact trajectory and width statistics
为确保IVOCT 图像序列中导丝伪影添加轨迹趋近真实伪影,本文还分析了临床数据中的导丝运动轨迹,伪影轨迹散点如图7(b)所示。图中轨迹分布在极坐标下统计,导丝运动轨迹趋近于连续的螺旋结构,运动轨迹中存在的不均匀抖动主要由自动/手动回撤速度不一致造成。预处理IVOCT序列的伪影位置分布随机选取等长度数目的连续散点位置进行映射。
3.2 评价指标
本文SETN 使用GAN 网络架构完成视频序列的图像补全,因此为有效地评估IVOCT 重建图像的质量,选择常用于评价图像补全模型的4个指标对实验结果进行评估:峰值信噪比(Peak Signal to Noise Ratio,PSNR)、结构相似性指数度量(Structural Similarity Index Measure,SSIM)、平均绝对误差(Mean Absolute Error,MAE)和弗雷 谢初始 距离分 数(Frechet Inception Distance score,FID)。
1)PSNR 是使用最广泛的衡量图像间相似程度的评价指标之一,衡量标准是计算缺失重建图像与未缺失图像之间的峰值信噪比(单位:dB),数值越大表示缺失区域重建图像的质量越好。计算公式如下:
其中:RMSE是重建图像K和原始图像I之间的累积平方误差;m和n分别为重建图像的长和宽;MAXI为未缺失图像中像素值的最大值(灰度图像MAXI=255)。
2)SSIM 是计算图像间结构相似性的评价指标,主要从亮度、对比度和结构三个角度比较。在比较两张图像之间的差异时,与PSNR 相比,SSIM 更加贴合人眼对于图像质量的判断。计算公式如下:
3)MAE 是深度学习领域常用的衡量误差指标之一,在如图像分类、图像分割等多种计算机视觉任务中均有应用。尽管它仅考虑单像素值间的差异,但在衡量图像差异上具备易于理解和解释、计算简单等优点。计算公式如下:
其中:m和n分别为重建图像的长和宽;yi和分别为未遮盖图像和重建图像的像素值。
4)FID 是从图像特征的角度衡量真实图像与生成图像间差异的计算指标,计算方式量化并比较二者特征向量之间的距离。二者的特征向量均由Inception v3 模型得到,而距离通过Frechet Distance 计算。FID 值越小表示向量分布越相似,即缺失区域重建结果的质量越高。计算公式如下:
其中:m和S分别为经验均值和经验协方差;r 和g 分别为真实数据和生成数据;Tr()表示矩阵的迹。
3.3 实验配置
本文验证SETN 有效性的实验基于Pytorch 深度学习框架并使用NVIDIA RTX 3090 GPU 服务器完成网络模型的训练。训练过程中,选用Adam 优化器优化损失函数,参数β1和β2分别设置为0.9 和0.99,训练学习率设置为0.000 01,每10 000 次迭代衰减为当前学习率的0.1。训练迭代次数为500 000,BatchSize 设置为2。输入模型的IVOCT 图像分辨率统一调整为624×336。
3.4 导丝伪影去除的实验结果
为了验证本文SETN 在IVOCT 导丝伪影去除任务上的实效性,将SETN 与图像补全方法及消融分析模型进行了图像补全性能的对比与分析,结果如表2,其中:加粗表示最优结果。
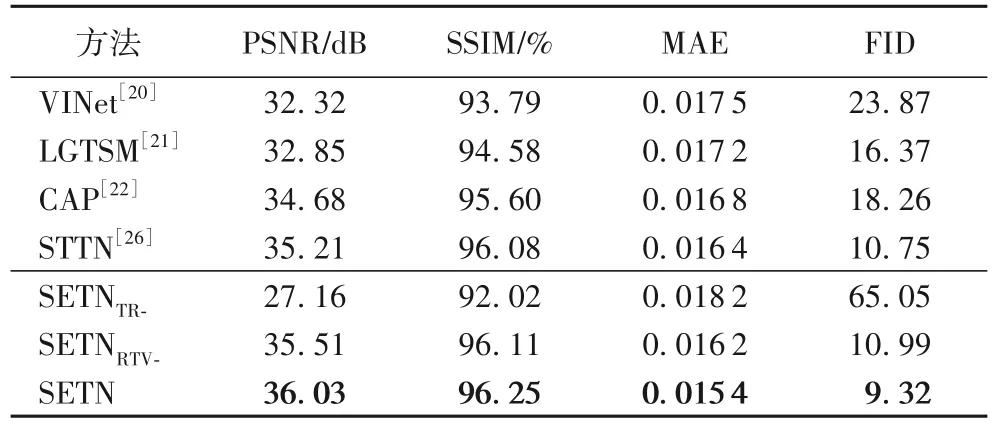
表2 导丝伪影去除的评估结果Tab.2 Evaluation results of guidewire artifact removal
由表2 可知,SETN 在PSNR、SSIM、MAE 以及FID 指标上均取得了最优性能,其中与性能最优SOTA(State-Of-The-Art)方法(STTN)相比,各指标性能增/减幅分别达到了2.3%、0.177%、6.1%以及13.3%。这表明SETN 针对IVOCT 图像特点设计的结构强化模型更适用于完成医疗图像的补全工作,且能够切实有效地去除IVOCT 图像中的导丝伪影。
为了验证本文SETN 中Transformer 模块以及RTV 强化生成网络的有效性,设计了两个SETN 变体模型并进行相应模块的消融分析实验。其中SETNTR-表示移除了SETN 生成器中的Transformer 模块,编码与解码模块直接相连完成图像重建;SETNRTV-表示移除了SETN 生成器中的RTV 强化生成网络,仅由ORI 主干生成网络完成纹理特征的提取与重建。根据表2 可知,移除Transformer 模块后,未利用序列上下文信息的SETNTR-在各项指标上性能均有下降,这说明SETN 中Transformer 模块时/空间域特征提取的设计对图像重建具有积极的意义;SETNRTV-与SETN 的实验结果对比表明,RTV 强化生成网络提取结构特征并融合至ORI 主干生成网络是有效的。
图8 给出了STTN、消融分析模型SETNRTV-与SETN 的箱式图。与STTN 相比,SETNRTV-对于时/空间域分别计算注意力的Transformer 编码器在IVOCT 导丝伪影去除任务的序列分析上效果更好。对比SETNRTV-和SETN 的箱式图可知,添加RTV 强化生成网络的生成器在导丝伪影区域的重建性能提升明显。SETN 与STTN 相比,测试数据预测的箱式图更稳定且集中,说明SETN 的导丝伪影去除更稳定可靠。
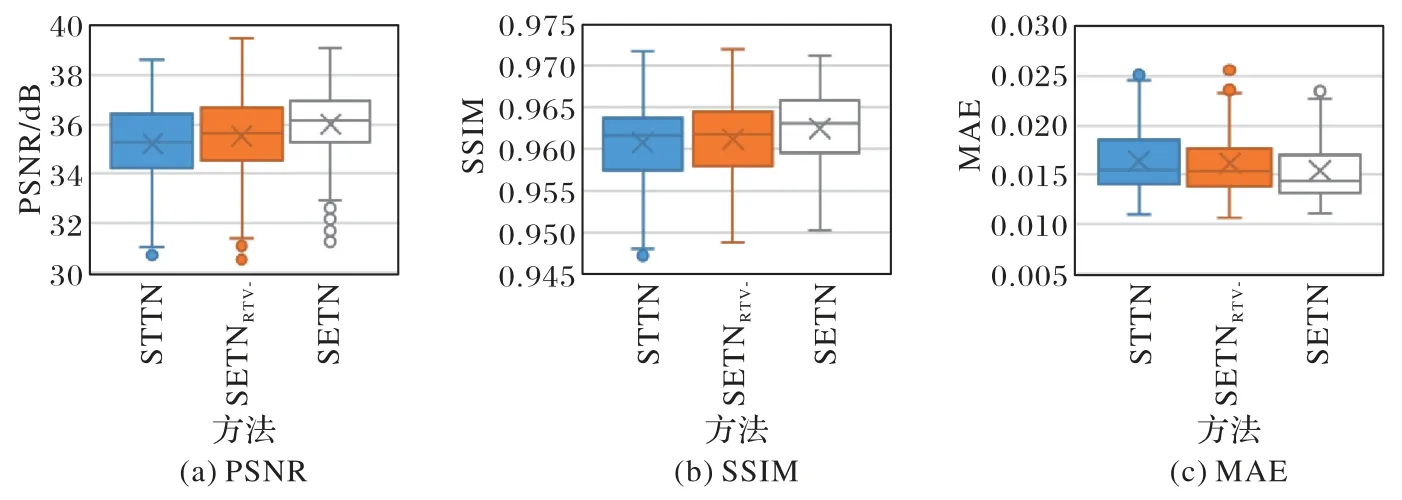
图8 实验结果箱式图Fig.8 Box plots of experimental results
图9 展示了各方法在导丝伪影区域进行的重建细节纹理。与STTN 的重建结果相比,SETNRTV-在细节纹理分布的还原上更接近Ground Truth,说明时/空间域Transformer 模块的设计能够有效地分析IVOCT 的序列信息。与STTN 和SETNRTV-相比,本文SETN 重建结果的纹理处理和明暗度的表现均更突出。在细小结构以及边界清晰度等细节上,SETN的重建结果避免了其他模型在边界上可能会出现模糊的情况,而此类细节正是医生诊断相关疾病的重要依据。而与SETNRTV-相比上述细节的提升,进一步验证了SETN 中RTV强化生成模块提取的结构特征对于纹理信息分布指导的有效性。

图9 导丝伪影区域重建结果的细节对比Fig.9 Detail comparison of reconstruction results of guidewire artifact area
导丝伪影区域重建结果整体结构的对比如图10 所示,在伪影区域图像结构较为复杂时,SETN 的重建图像在层次上更加接近原始图像,这进一步验证了SETN 通过RTV 图像特征强化结构特征的可行性。
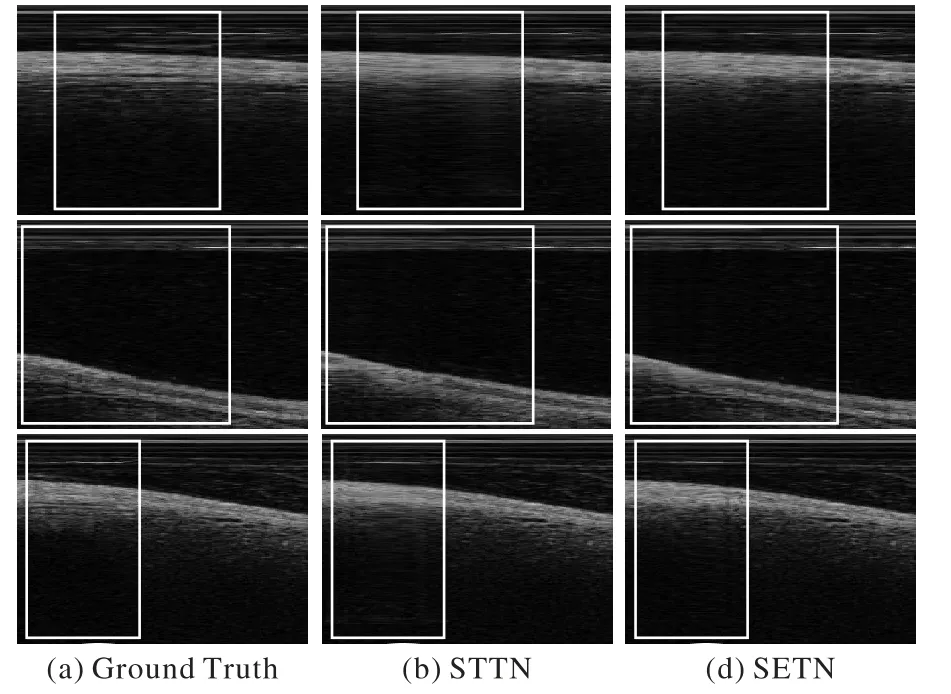
图10 导丝伪影区域重建结果结构对比Fig.10 Structural comparison of reconstruction results of guidewire artifact area
3.5 导丝伪影去除的应用
为验证SETN 去除导丝伪影对于IVOCT 图像的计算机辅助诊断工作具有积极的意义,以导丝伪影去除前后的IVOCT图像作为数据基础在下游视觉任务上进行实验,对比、分析易损斑块分割和腔体轮廓线提取任务基于SETN 去除伪影图像数据完成的优势。
3.5.1 易损斑块分割
本实验将对比导丝伪影去除前后,U-Net+ResNet50 模型对于IVOCT 图像中易损斑块的分割结果,以验证本文SETN的导丝伪影去除性能及其对于易损斑块分割任务的意义,其中易损斑块分割的评价指标包括像素准确率(Pixel Accuracy,PA)、平均像素准确率(Mean Pixel Accuracy,MPA)、交并比(Intersection over Union,IoU)、DICE系数(DICE Coefficient)、精准率(Precision)以及召回率(Recall)。
如表3 所示,分割模型在去除伪影的IVOCT 图像上进行分割的性能显著优于未处理图像,这表明导丝伪影去除工作能够提高IVOCT 图像质量,对于IVOCT 图像的易损斑块识别具有重要意义。对比STTN 和SETNRTV-处理图像的模型分割结果,本文的SETN 在PA、MPA、IoU 以及DICE 指标上达到了最优性能,这表明SETN 中的时/空间域Transformer 和RTV强化生成网络的设计均能够提升导丝伪影去除的性能。
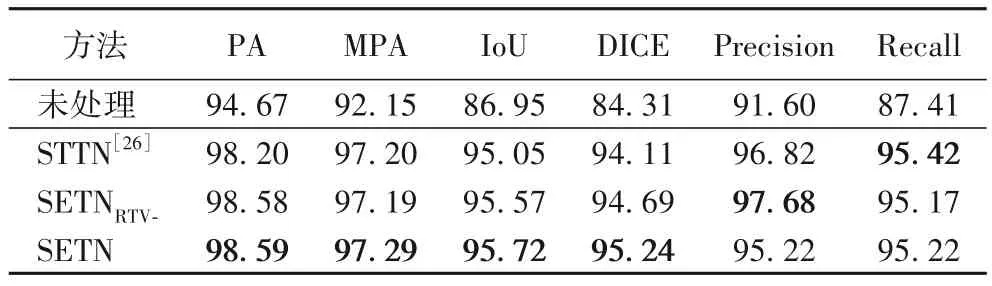
表3 不同输入的分割结果 单位:%Tab.3 Segmentation results of different input unit:%
图11 展示了SETN 导丝伪影去除前后U-Net+ResNet50的分割结果,其中:白色扇形区域代表易损斑块,灰色扇形区域代表导丝伪影。将使用SETN 处理后的影像作为数据完成斑块分割时,分割模型能够更好地定位斑块区域从而准确地完成分割,这表明去除导丝伪影有效地提高了IVOCT 数据的完整性和连续性,有利于深度学习模型完成易损斑块的特征提取。

图11 导丝伪影去除前后的分割结果Fig.11 Segmentation results before and after guidewire artifact removal
3.5.2 管腔轮廓线提取
已提出的IVOCT 图像心血管腔体轮廓线提取方法通常使用插值方法预测导丝伪影区域的腔体轮廓线,但插值方法根据边缘趋势将预测的平滑曲线作为导丝伪影区域轮廓线,因此难以预测复杂且存在尖锐的管腔轮廓。本文的SETN 通过大量具有结构复杂轮廓线的IVOCT 数据进行训练,它的导丝伪影去除结果能够真实还原腔体轮廓线。
如图12 所示(图中白色轮廓线为插值方法预测结果),插值方法在提取结构复杂的导丝伪影区域管腔轮廓线时无法实现精准的预测,而SETN 通过导丝伪影区域图像的重建精准地还原了腔体轮廓线。与STTN 相比,SETN 导丝伪影区域重建的轮廓线更接近真实管腔轮廓。SETN 通过重建伪影区域获取了完整且连续的IVOCT 影像,能为提取导丝伪影区域的管腔轮廓提供全新的应对方法。
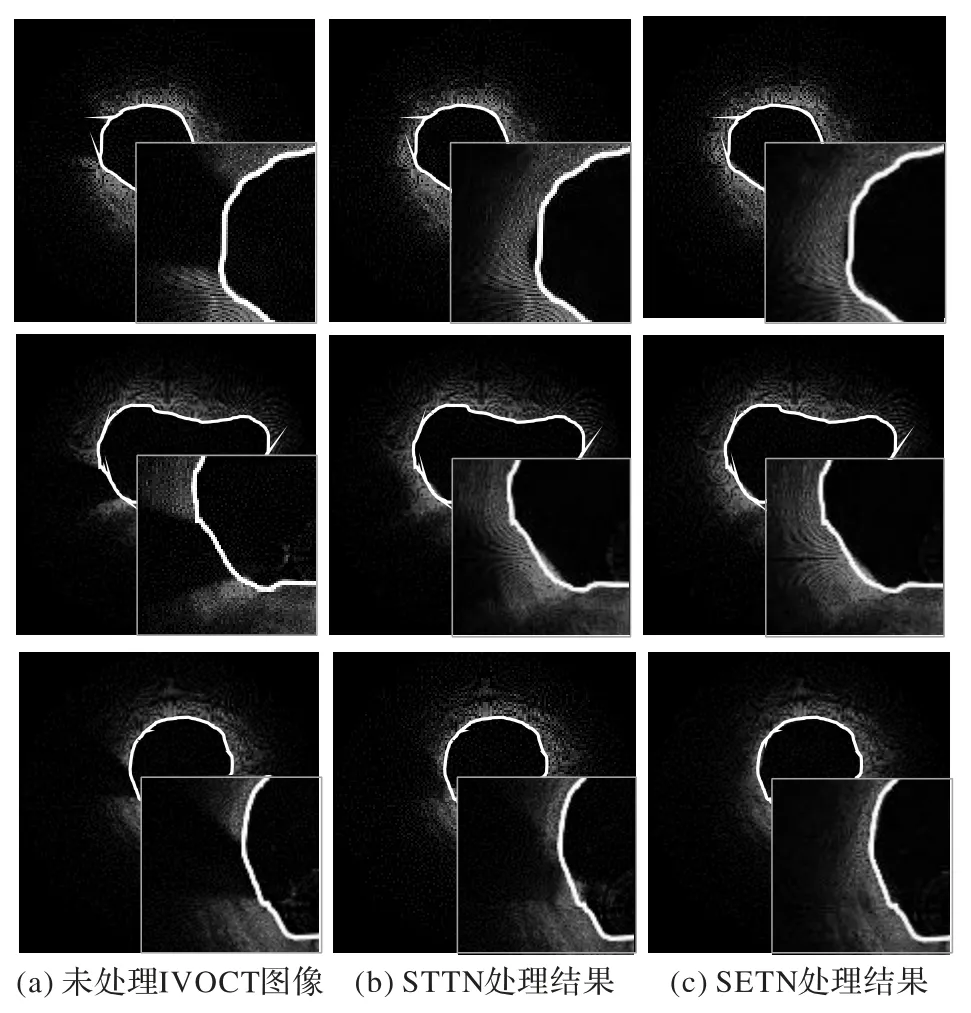
图12 导丝伪影区的域轮廓线对比Fig.12 Contour comparison of guidewire artifact area
4 结语
本文提出了一种基于Transformer 的结构强化网络(SETN),以去除IVOCT 图像中结构信息复杂且区域占比大的导丝伪影。SETN 的生成器并联了ORI 主干生成网络和RTV 强化生成网络,分别提取原始图像中的纹理特征和RTV图像中的结构特征;设计了时/空间域Transformer 编码结构,以关联单帧图像不同位置间以及序列上下文信息。导丝伪影区域的图像重建以及下游视觉任务的验证结果均验证了SETN 对于IVOCT 影像计算机辅助诊断的价值。后续工作将尝试进一步研究结构强化的融合方式,以更好地融合纹理与结构信息;其次,在IVOCT 图像分析的其他下游任务上将开展导丝伪影去除的应用;最后,将进一步探索更加先进且轻量级的网络结构,以更加高效且精准地完成IVOCT 图像导丝伪影去除。
