基于改进深度强化学习的边缘计算服务卸载算法
2023-05-24曹腾飞刘延亮王晓英
曹腾飞,刘延亮,王晓英
(青海大学 计算机技术与应用系,西宁 810016)
0 引言
随着互联网与无线通信技术的发展,现代信息社会逐渐迈入了万物互联的物联网时代[1]。以超高清视频、虚拟现实(Virtual Reality,VR)、自动驾驶等为代表的各类新兴移动互联网业务大量涌现。根据中国互联网信息中心(China Internet Network Information Center,CNNIC)发布的《第48 次中国互联网发展状况统计报告》,截至2021 年6 月,我国网民规模达10.11 亿,较2020 年12 月增长2 175 万,互联网普及率达71.6%,较2020 年12 月提升1.2 个百分点[2]。随着用户数大幅增长,人们对于网络多媒体资源的需求也迅速增长:我国网络视频用户规模达9.44 亿,较2020 年12 月增长1 707万。这些数字表明人们对于计算型多媒体资源的需求增多,由于云端服务器通常远离用户侧,用户从中获取计算后的数据往往会导致较高的时延,仅依靠云服务的计算方式无法有效响应如此庞大的资源需求。因此,也诞生了一种新的计算模型——边缘计算(Edge Computing,EC)[3]。通过将服务资源从云端迁移到边缘节点上,EC 可以有效降低时延,这使EC 成为提升计算型服务质量(Quality of Service,QoS)的一种重要方法。
然而,由于当前边缘节点资源有限,通常不能在同一时隙内向区域内的所有用户提供服务,进而不能同时满足用户对于低时延的要求。因此,将云与边缘节点结合进行计算成了当前主要的研究方向。然而,由于边缘节点的资源有限,位于云端的计算型服务不能全部转移到边缘节点上,边缘节点需要自行决定应该从云端卸载哪些服务,而如何提高卸载服务效率来满足低时延的要求成了当前面临的问题。相关研究者针对此类问题进行了分析[4-9],但这些工作只考虑了边缘节点有限的计算资源,却未考虑到边缘节点中存储容量有限的问题,因为资源和服务需要占据实际空间,许多计算型服务需要缓存所需服务资源至边缘节点以满足用户的需求。例如,自适应视频流(Dynamic Adaptive Streaming over HTTP,DASH)[10]中,视频文件以多个视频块的形式存储在云端或边缘节点中,每个块以不同的码率编码,DASH 作为计算型多媒体服务,需要设计算法提升用户的体验质量(Quality of Experience,QoE)。在DASH 中使用由客户端实现的码率自适应技术(Adaptive Bitrate Streaming,ABR)算法[11],将网络吞吐量等信息作为输入,输出下一视频块码率级别,视频服务应根据用户所处的网络环境从边缘节点缓存中获取合适码率的视频块提供给用户。另外,由于边缘节点存储资源有限,当大量用户从边缘节点请求流媒体服务时,将导致边缘节点的计算与存储资源负载过大等问题,因此需要同时考虑以上两者的约束条件,提升EC 的服务卸载效率。
近几年,深度强化学习(Deep Reinforcement Learning,DRL)[12]算法被广泛使用。DRL 算法具有诸多优势,它能从训练的经验中学习并预测最佳行为,而且能适应不同的网络环境。最具代表性的深度强化学习算法为深度Q 学习[13]。尽管已经有将深度Q 学习应用到EC 的相关工作[14-15],但仍无法解决因动作空间过大以及存在非法动作导致的模型总体收益降低等问题。本文将计算型服务卸载问题建模为马尔可夫决策过程(Markov Decision Process,MDP),在实现深度Q 网络(Deep Q-Network,DQN)[16]算法的基础上降低算法的动作空间大小,并提出了基于改进深度强化学习的边缘计算服务卸载(Edge Computing and Service Offloading,ECSO)算法。本文主要工作如下:
1)将边缘计算服务卸载问题建模为存储空间以及计算资源限制的MDP,同时将算法在边缘计算服务卸载中节省的时间消耗视为奖励。但由于本问题中的概率转移矩阵在实际情况下难以实现,需要进一步在MDP 基础上实现深度强化学习算法。
2)提出了基于改进深度强化学习的ECSO 算法。相较于原DQN 算法,本文提出了一种新的动作行为,规避了非法动作,优化了动作空间的大小,进而提升了算法的训练效率;同时,本文运用动态规划的思想提出了动作筛选算法,针对单一服务的动作进行筛选与组合,以便得到理论收益最大的最优动作集;并通过本文提出的动作筛选算法得到最优动作集,进而通过比例的方式梯度下降更新网络参数,优化算法决策。
3)将ECSO 算法分别与DQN、邻近策略优化(Proximal Policy Optimization,PPO)[17]以及最流行(Most Popular,MP)[18]算法进行仿真实验对比。结果表明本文ECSO 算法能显著降低边缘计算处理时延,相较于DQN、PPO 以及MP 算法,ECSO 的算法奖励值分别提升了7.0%、12.7%和65.6%,边缘计算传输时延分别降低了13.0%、18.8%和66.4%。
1 相关工作
边缘计算服务卸载作为边缘计算的一个重要领域,近年来被人们广泛关注。部分研究者将这类问题视为MDP,利用最优化方法进行求解。文献[4]中提出了一个由用户和网络运营商联合通信计算(Joint Communication Computing,JCC)资源分配机制组成的综合框架,在提供优质通信的同时最小化资源占用;文献[5]中提出了一种用于分配资源的框架,该框架结合了通信以及计算要素来解决移动边缘云计算服务的按需供应问题;文献[6]中提出了一种基于强化学习的状态/动作/奖励/状态/动作(State-Action-Reward-State-Action,SARSA)算法,以解决边缘服务器中的资源管理问题,降低系统成本,并作出最佳的卸载决策;文献[7]中探究了DQN 及PPO 算法在基于多输入多输出(Multiple-Input Multiple-Output,MIMO)的移动 边缘计 算(Mobile Edge Computing,MEC)系统中的计算型服务卸载问题,目标是在随机系统环境下最大限度地降低移动设备的功耗及卸载延迟;文献[8]中提出了一种深度强化学习方法将任务分配到不同的边缘服务器进行处理,以便将包括计算服务延迟和服务故障损失在内的服务成本降至最低;文献[9]中针对车联网中车对外界的信息交换(Vehicle to Everything,V2X)网络的资源分配问题进行研究,并使用Double DQN 来解决资源分配问题。然而,这些工作都基于一个未定的假设——边缘节点能卸载并执行所有类型的计算型任务。事实上,边缘节点的存储空间通常有限,并且各服务缓存策略并不一致,因而在实际中很难有效地应用。
而对于这类服务卸载问题来说,云服务器与边缘节点任务的分配效率以及多媒体的QoS 是需要考虑的,例如,文献[19]中提出了一种名为BitLat 的ABR 算法以提高用户在线视频的QoS。而基于资源受限的MDP 建模的服务卸载问题在很多情况下属于NP-hard 问题[20],常规的搜索方法已经不适用于解决此类问题,因而近年来不断有学者针对边缘节点的服务卸载问题提出优化理论,并取得了不错的效果。文献[21]针对移动边缘计算上的在线计算与服务卸载问题,使用适应性遗传算法(Adaptive Genetic Algorithm,AGA)优化深度强化学习的探索过程,相较于对比算法,它所提出的DRGO 算法能更快地收敛并得到更好的卸载策略。文献[22]针对5G 边缘网络中的计算服务卸载问题,提出了一种高效可靠的多媒体服务优化机制,并利用博弈理论对问题进行求解,有效提升了网络传输性能。文献[23]中通过扩宽服务缓存的作用,实现了一种基于缓存服务和计算卸载的联合优化算法;但该算法假定计算型服务是可分割的,而本文假定每个计算型服务为最小单元,并通过增加服务数量来表示它是可分割的,改进文献[23]的算法以解决本文的问题。
因此,不同于以上工作,本文提出了一种基于改进深度强化学习的DRL 算法——ECSO 算法。通过对边缘节点可用存储资源及计算资源加以限制,并基于MDP 模型实现DRL算法,以解决状态概率转移难以预测的问题;同时,基于本文给出的动作筛选算法得到最优动作集,降低算法动作空间的大小,进一步优化算法决策过程,进而满足边缘计算服务卸载过程中对低时延的要求。
2 服务卸载模型
本章将分别介绍系统模型、MDP 以及边缘服务卸载的定义和描述。
2.1 系统模型
在本文的模型中,边缘节点有着计算资源F以及存储空间C,计算资源F用于服务计算,存储空间C用于缓存服务数据。本文定义计算型服务集合为κ={1,2,…,K},时隙集合为Γ={1,2,…,T}。每个服务都有两个属性(ck,fk),分别表示此服务所需空间以及此服务所需计算资源,假定每个单独的服务都是不可分割的。本文设定单一k服务带来的下载时延为边缘节点使单一k服务减少的传输时延为用户发送请求到边缘节点的传输时延定义为,由于边缘节点算力有限,因而会带来额外的执行时延设定t时隙服务k的请求数量为为用户对单一服务k的请求提供数量,表明当边缘节点提供单一服务k时,多个用户请求服务k这一类服务。本文定义的环境存在实际应用,例如,当社会热点新闻出现时,会引发大量用户关注,此时多个用户将请求相同的数据内容,当边缘节点缓存这类数据内容时,就可以直接向这些用户提供服务[18]。边缘节点不会缓存不在本地提供的服务,每一时隙边缘节点采取不同的策略来进行服务卸载,且单一时隙内总能完成回传数据的任务。
系统模型如图1 所示,本文的目标是解决单个边缘节点的边缘计算服务卸载问题。
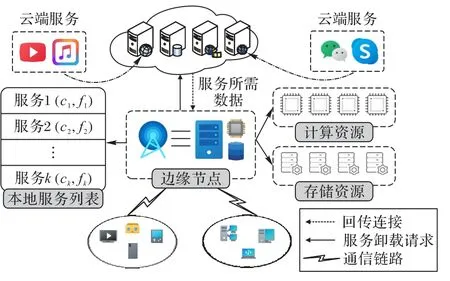
图1 边缘计算服务卸载模型Fig.1 Edge computing service offloading model
在该模型中,边缘节点拥有相应的计算资源以及存储资源,并且边缘节点可以记录所有服务。系统模型中存在两类过程:服务卸载过程以及边缘计算过程。在服务卸载过程中,当边缘节点未缓存k服务时,从云端下载相关数据需要的下载时延为若边缘节点满足服务k的需求且可以提供服务时,用户无须再上传数据至云端计算,而只需向靠近用户侧的边缘节点发送指定服务的卸载请求数据,这个过程的时延为整个过程消耗存储空间ck,完成服务卸载过程。而在边缘计算过程中,当边缘节点向用户提供已完成卸载的服务时,消耗计算资源fk,并消耗执行时延完成计算。由于边缘节点靠近用户侧,当边缘节点卸载计算型服务时,边缘节点可降低的传输时延为完成边缘计算过程。此时如果针对单一服务k有多个服务请求时,则需要分别向多个用户提供计算型服务k,因此资源消耗也会增加,同时累计降低的传输时延也会增加。
2.2 马尔可夫决策过程
在此系统模型中,本文将边缘计算服务卸载问题建模为MDP,下面将分别介绍状态空间、动作空间以及奖励方法。
2.2.1 状态空间
状态是对当前系统环境的描述,而状态空间是所有可能状态的集合。在本文定义的问题中,状态是时隙开始时的系统状态,系统状态由缓存状态和请求状态组成。
设定边缘节点t时隙下的服务缓存状态为矩阵Mt,如果边缘节点在时隙t内缓存提供服务k,其缓存状态=1,否则=0。同样的,边缘节点的请求状态矩阵设为Dt=[],其中代表用户对于服务k在t时隙内的请求数量。边缘节点需要缓存数据和服务计算,但存储空间及计算资源有限。因此,存储空间和计算资源需要分别满足式(1)和式(2):
本文考虑到用户的请求可能针对同一个服务的不同类型,当边缘节点对服务k进行服务卸载时,不同类型的服务请求需要缓存并计算多份数据,因而存储以及计算资源约束需要考虑请求数量矩阵Dt,具体到每一服务即为由于缓存状态在t时隙开始时仍为t-1 时的状态,因此t时隙的状态空间为St=(Mt-1,Dt)。
2.2.2 动作空间
动作空间就是一系列边缘节点可能采取的动作的集合。本文定义动作矩阵At=其中∈{-1,0,1}。对于每个边缘节点=1 表示边缘节点在时隙t-1 不提供服务k,而在时隙t内提供服务k。在这一动作中,用户会向边缘节点发送服务k的卸载请求,这个过程耗时边缘服务器将会从云端下载服务所需服务数据,经过下载所需时延之后提供服务k;=-1 表示边缘节点在时隙t-1 时在本地提供服务k,而在时隙t内不在本地提供服务k。在这一动作中,由于边缘节点只需删除相关服务数据,因此不会产生额外的时延;而=0 表示边缘节点不采取任何改变状态的行为,在时隙t的服务提供状态与在时隙t-1 相同。
设 |κ|为总服务数量,由于动作空间为一系列边缘节点可能采取的动作的集合,因此动作空间的总大小为3|κ|,然而动作空间中也有许多无意义的动作,例如当=0 且-1 时,表明边缘节点并未缓存提供服务k所需的数据,但边缘节点仍要删除这些数据。这些动作即“非法动作”。设π为满足存储空间及计算资源限制的所有策略的集合,那么这些动作可以表示为
状态转移概率是策略制定后当前状态转移到新状态的概率。对于(Mt-1,At)来说,转移概率是确定的;但由于状态空间还包括请求状态Dt,它会随着时间的推移而随机变化,状态转移概率难以精确估测。这是边缘计算服务卸载问题不能直接用MDP 来解决的根本原因。
2.2.3 奖励方法
奖励方法R(s,a)就是边缘节点从状态s执行动作a之后得到的激励值,正向激励有利于提高边缘节点在此状态下执行动作a的概率;负向激励则降低边缘节点在此状态下执行动作a的概率。
2.3 问题定义
由2.2 节的奖励方法可知,奖励代表着边缘节点在系统模型中总共降低的边缘计算处理时延。总处理时延越低,意味着边缘节点越能满足用户对于低时延的要求,因此目标是最大化边缘节点所获取的长期奖励,由式(4)给出:
s.t. 式(1),(2)
其中:γt是衰减因子,随着时间的变化不断减小;Rt=表示t时隙内所有服务的奖励之和。
3 ECSO算法
本章将介绍ECSO 算法的具体实现以及优化过程。传统DRL(如DQN)可以作为此类问题的解决方法,但相较于DQN,ECSO 算法能更有效地降低边缘计算处理时延,因而更适合解决此类问题。
3.1 基于MDP的DRL实现
上述MDP 不能直接应用的原因是状态转移概率难以预测,且传统MDP 的建模方案在一定程度上受到状态空间和动作空间大小的限制。而DRL 算法可以很有效地解决这类问题,因为DRL 算法可以不用预先输入任何数据,主要依靠不断的环境探索和经验回放来得到对应环境下执行动作的奖励,并依据这些奖励优化模型参数。本文以DQN 为例实现DRL 算法。
DQN 的目标就是得到执行动作后的预计奖励,即Q 值。DQN 将边缘节点的状态作为其深度神经网络的输入进行训练,得到所有动作的Q 值,以此改进依赖于表格的传统强化学习算法。由此,它省略了以表格记录Q 值的过程,直接通过深度神经网络生成Q 值,解决了无限状态空间的问题。它的探索策略E为ε贪心策略,设定随机概率为p,如式(5)所示:
使用ε贪心策略进行探索可以避免算法陷入局部最优状态。本文算法采用递减ε贪心策略,它的参数会随着训练迭代数的增加而递减,这种策略在训练前期能够探索更多的动作可能性,而后期也可以使算法减少采取随机动作的可能性,这有助于算法的稳定。
DQN 使用两个神经网络进行训练:一个是需要训练的主网络,一个是用于生成Q 值的目标网络。DQN 通过损失函数来训练模型参数。损失函数为目标网络的估计值Qr(s,a)和主网络的输出Q(s,a)的平方差,如式(6)所示:
γ是应用于下一步奖励的衰减系数;Q'(s',a')是目标网络中对状态s'执行动作a'所得到的单步奖励估计值,而则是下一步状态s'中拥有最高Q 值估计的动作a'。
3.2 动作筛选
目前未经修改过的动作空间大小为3|κ|,这个数值会随着总服务数量的增大而呈指数型增长,当服务数量过多时,模型训练将会非常困难。其次,定义的动作空间仍包括非法动作,非法动作的Q 值无意义,算法执行和学习无意义的非法动作反而会影响它的稳定性,因此需要采取措施优化动作空间,以提高训练效率。
算法1 动作筛选算法。
对于算法1,i与j从1 开始逐渐迭代到最大值,这是为了寻找并优先组合能够带来收益、且所要求的资源最小的动作,并在后续迭代中从动作集中去除对于资源要求较大的动作。如果ck大于边缘节点所剩余的空间i,或是fk大于边缘节点剩余的计算资源j,那么服务k就不能在边缘节点本地提供,因而筛选后的动作集保持不变。当边缘节点剩余的存储空间和可用的计算资源满足服务k的需求时,边缘节点可以作出两种选择:提供服务k,并令Rmax+=rk;或者不提供服务k,令Rmax保持不变。
算法1 的目标是尽可能在提供更多服务的情况下最大化各服务动作带来的奖励,而算法1 本质上可视为动态规划问题进行求解,求解后得到的动作集合即为能带来最大奖励值的动作集合。
3.3 更新方法
得到最优动作集后,由于主网络和目标网络输出的是单一动作xk的Q 值,而不是整体Xt的Q 值,因此不能使用整个Xt的Q 值代替xk更新。由于Xt由筛选后的xk组成,因此,针对每个动作行为xk更新损失值的损失函数也需作出改变。对于t时刻候选动作列表Xt,根据式(6)所示的形式,定义式(8):
对于Q(St,Xt),分别计算其中每个xk动作产生的Q 值,Q(St,Xt)为其中所有动作行为Q 值之和,如式(10)所示:
为了得到动作列表Xt中每个xk的损失值,本文使用占比的方式计算每个xk的损失值,如式(11)所示:
本质上,边缘节点执行的是各服务k的动作xk。依据算法1,每一次筛选得到的最优动作集取决于各动作xk预期的奖励,对应的是主网络预测的Q 值。这一时隙得到的最优动作集与上一时隙中得到的最优动作集会因为主网络参数的更新而发生更改,各xk之间也相互独立,因而无须考虑各服务动作xk的组合情况,也不会导致算法性能下降。
按照以上方法求解每个xk的损失值,就可以在更改动作空间之后使用动作行为的损失值梯度下降更新主网络。
3.4 算法流程及实现
ECSO 算法流程如图2 所示,主网络与目标网络有着相同的网络结构,由于定义了新的动作行为xk,主网络与目标网络的输出值均为xk的Q 值而不是原有动作空间的Q 值。首先,算法会根据探索策略随机选择执行动作或是Q 值最高的行为执行动作,根据算法1 筛选动作行为xk放入动作列表Xt中,并将元组(St,Xt,Rt,St+1)作为经验存入回放经验池中。之后算法随机取出一批经验来训练主网络。目标网络则输出动作列表的Q 值Q'(St+1,X')。接着算法根据主网络输出的每个Q(St,xk)以及目标网络输出的Q'(St+1,X')依次计算每个xk的损失值。并依次梯度下更新损失值,以此训练主网络,且每隔一定频率更新目标网络的网络参数。算法2给出了ECSO 算法实现的伪代码。
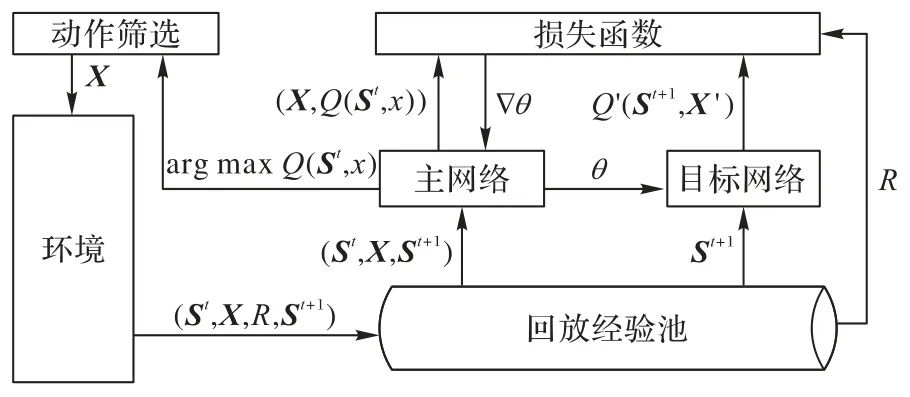
图2 ECSO算法流程Fig.2 Flow of ECSO algorithm
算法2 ECSO 算法。
依据本文提出的ECSO 算法,通过定期更新网络参数,优化目标网络对于边缘节点服务采取的动作集合Xt,从而达到优化边缘节点服务卸载决策的目的。
4 仿真实验与结果分析
本章将介绍ECSO 算法的实验环境以及参数设定,然后与其他DRL 算法以及传统算法进行对比,根据结果验证本文ECSO 算法更适合解决边缘计算服务卸载的问题。值得说明的是,本文在实验中对所有算法均设置了存储和计算资源的条件限制。
4.1 实验参数设置
本实验使用TensorFlow[24]运行算法。本次实验模拟考虑50 个服务,计算所需资源fk在[0.5,2.5] GHz 内随机取值,储存所需资源ck在[0.2,2] GB 内随机取值,边缘节点减少的传输时延在[2,5] s 内随机取值,假定服务所需的计算资源充足且充分利用,则它的执行时延用户发送请求到边缘节点的传输时延取值取决于请求数量的多少。下载时延即为下载该服务数据需花费的时间,而带宽决定了下载速率的理论上限,考虑到单位的换算,服务对应的下载时延=8ck/Bandwidth,取带宽为8 Gb/s。本文假设服务的请求频率遵循齐夫分布[25],则平均请求数量如式(12)所示:
其中:r(k)是服务k的请求频率的排名;N是用户数量,在实验中取值为150;在齐夫分布中通常取V=0.1;λ为数据分布的指数特征,在实验中取λ=1;设定边缘节点总计算资源为10 GHz,边缘节点总存储资源为10 GB。
4.2 性能分析
4.2.1 云端计算与边缘计算性能对比
为了验证实验环境下边缘计算与直接由云端响应的服务性能差异,本文将两者进行了对比分析。
ECSO-EC(ECSO-Edge Computing):依照本文提出的算法以及模型进行运算,缓存的服务由边缘节点提供给用户,其他服务由云端进行响应。
ECSO-CC(ECSO-Cloud Computing):训练过程不变,只是边缘节点不再向用户提供缓存服务,转而由云端直接进行响应和运算,因而不考虑缓存服务带来的下载时延以及计算时延,因此不会降低传输时延。
从图3 可以看出,在训练的开始阶段,由云端直接响应的性能优于由边缘节点缓存并提供服务的性能,这是由于边缘节点的决策还尚未被完全优化,边缘节点提供的服务并不能降低更多的时延。随着训练回合的增加,算法能够更好地决策,边缘节点也能优先向用户提供占用资源少、请求数量多的服务,因而ECSO-EC 算法能够积累到较多正向的奖励值。ECSO-CC 算法积累的奖励值代表边缘节点提供计算型服务时带来的额外时延,同样随着回合数的增加而趋于较低的值。此时由边缘节点提供计算型服务相比直接由云端响应所降低的总处理时延更高。这也表明了由边缘节点缓存并提供服务所带来的性能提升。
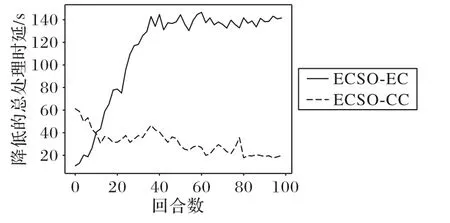
图3 云端响应和边缘计算的性能对比Fig.3 Performance comparison between cloud computing and edge conputing
4.2.2 边缘计算中不同算法之间性能对比
本节将对比不同回合中算法的奖励值以及单一回合中不同时隙下降低的传输时延。本文的ECSO、DQN 和PPO 这三种DRL 算法以及传统MP 算法介绍如下:
ECSO:算法每时隙输出自身对各个动作的预测价值,并将它们作为动作筛选算法的输入,从而得到最优动作集。边缘节点每时隙按照最优动作集提供或卸载服务。
DQN[16]:算法根据式(5)的ε 贪心算法探索得到动作并更新网络参数。边缘节点依据神经网络预测值提供以及卸载服务。
PPO[17]:算法在开始阶段探索并积累动作轨迹,并且每一时隙更新动作轨迹的优势以及回报,一旦积累一定数量时,开始更新网络策略。边缘节点根据其中执行者网络的预测值提供或卸载服务。
MP[18]:边缘节点根据用户每个时隙中服务请求数量的积累计算每个服务的流行度,每一时隙中提供流行度最高的服务。由于MP 算法不具备学习能力,进行多个回合的实验不会对MP 算法的表现带来提升。因而对于传统算法,本文只对比单个回合内200 次时隙所能降低的传输时延。最终用于对比的奖励值定义为算法最终降低的传输时延与缓存计算服务带来的各类时延之差。
本文的目标为最大化迭代后的奖励值。图4 为三种DRL算法在100 次迭代中的奖励值对比,奖励值定义如式(3)所示,是验证算法性能的重要指标之一。从图4 中可以看出,本文实现的算法最终稳定的奖励值整体要高于DQN 算法,而PPO 算法前期由于需要积累动作轨迹以便积累完成后学习,因此在前30 次迭代中探索得到的奖励很低;ECSO 算法相较于DQN 算法收敛更快,这是因为ECSO 算法会预先筛选动作,排除非法的动作并执行最优动作。PPO 算法探索环境得到的奖励并不稳定,这是因为在它积累完动作轨迹之后需要从回放经验池中随机取出一批样本进行学习,由于存在针对非法动作的奖励惩罚,这就使PPO难以短时间平稳所获得的奖励。而DQN 以及ECSO 算法因为使用ε贪心策略进行探索,它们探索得到的奖励能较为平缓地增长。由于优化了算法的动作空间,一定程度上规避了非法动作带来的负奖励,ECSO 算法在100次迭代内的整体收益高于DQN 算法。PPO 算法由于收敛缓慢,虽有上升趋势,但整体收益仍不及前两者。
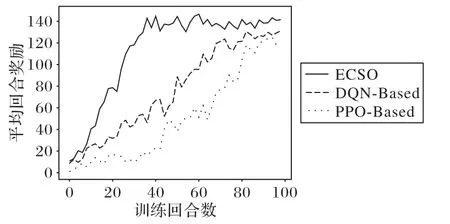
图4 训练回合奖励对比Fig.4 Comparison of rewards in different training epochs
图5 为单一迭代中200 个时隙下几种算法累计减少的传输时延。DQN 算法以及ECSO 算法能够较快地收敛,而PPO算法却收敛缓慢,最终固定在一个较低的值。这是因为前两者通过ε贪心策略的探索能够快速达到局部最优解,从而迅速适应环境;而PPO 算法则需要预先积累,在轨迹积累达到一定数量后开始训练算法中的执行者以及评论者网络,而前期完成的动作轨迹中势必存在非法行为带来的负奖励,因此PPO 算法在一次迭代中所减少的传输时延存在较大波动且数值相对较低。而对于MP 算法,累计降低的传输时延逐渐增加,但它的速率提升十分缓慢且低于三种DRL 算法的积累值,因而最终效果不及ECSO 的算法。而从算法200 个时隙的迭代来看,ECSO 算法相较于其他三种算法能显著减少数据传输时延。
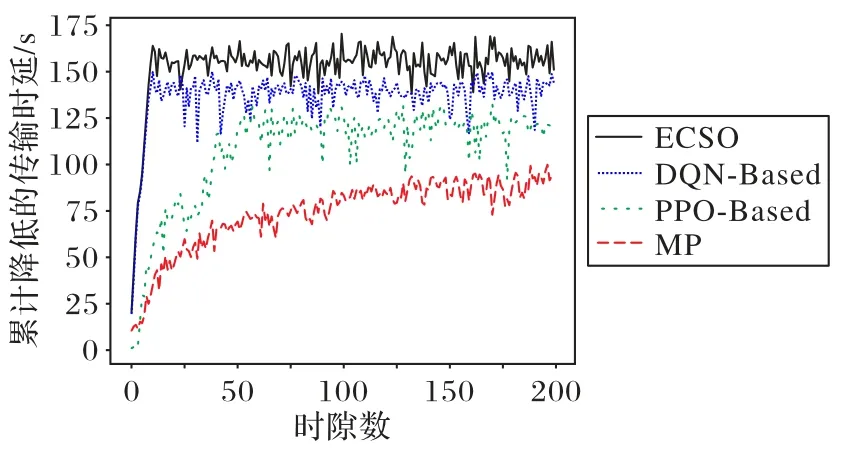
图5 累计减少的传输时延对比Fig.5 Comparison of transmission latency reduction
表1 为本文实验的四种算法训练至稳定后最终的性能表现。可以发现,相较于DQN 算法,ECSO 算法的总奖励值提升了7.0%,边缘计算传输时延降低了13.0%,验证了算法优化的有效性;所提算法相较于PPO 算法,总奖励值提升了12.7%,边缘计算传输时延降低了18.8%,说明ECSO 算法相较于PPO 算法更适合解决本文的边缘计算服务卸载问题。而本文所提算法相较于传统算法中的MP 算法总奖励值提升了65.6%,边缘计算传输时延降低了66.4%,验证了DRL 算法的有效性。
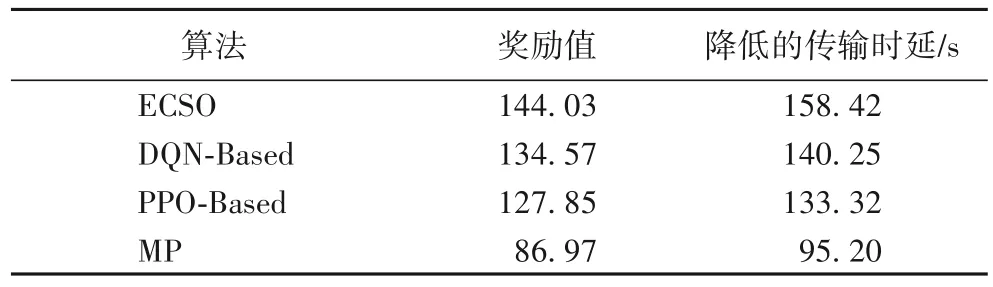
表1 四种算法训练至稳定后最终的性能对比Tab.1 Final performance comparison of four algorithms after training to stability
4.3 不同实验参数对于算法性能的影响
低时延是边缘计算服务卸载的基本应用要求。为探究不同实验参数对本文算法降低传输时延的影响,本节以算法奖励值作为本文三种DRL 算法的性能指标,以MP 算法最终降低的传输时延与缓存计算服务带来的各类时延之差为传统算法的性能指标,在同一实验环境中对于单一参数采取不同的值进行模拟实验,并分析所得结果。为了减小随机生成的数据可能导致的结果偏差,每个设定的参数分别运行10 次算法,并对算法趋于稳定后得到的结果取均值作为最终数据。
4.3.1 资源限制对于算法性能的影响
图6(a)、(b)分别为算法在不同储存空间以及计算资源限制下所能够降低的总处理时延。
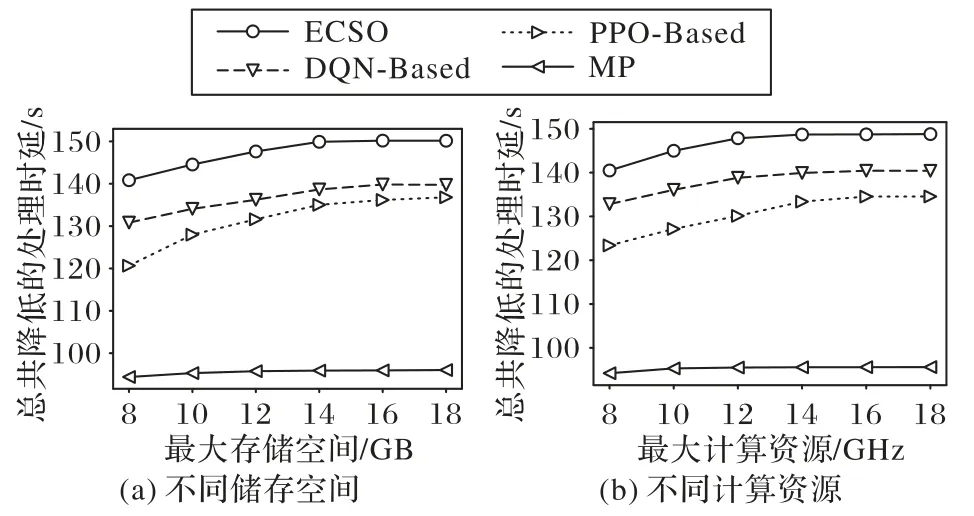
图6 不同储存空间和计算资源下降低的时延对比Fig.6 Latency reduction comparison under different storage space and computing resource
从图6 中可以看出,无论是存储空间还是计算资源的仿真实验,随着资源的增多,三种DRL 算法所降低的时延均呈现上升趋势,但增长速率越来越低。这是因为当存储空间或是计算资源增加时,能够缓存更多所需的服务数据或是提供更多的计算型服务。以存储空间为例,存储空间的提升使边缘节点能够缓存更多的用户所需服务的数据,因而可以更加充分地利用边缘节点剩余的计算资源。但在存储空间提升到一定量之后,存储空间不再是限制边缘节点提供边缘计算服务的因素,计算资源的不足使缓存服务无法在边缘节点处完成计算,因而导致所降低的计算时延逐渐减少直至趋于稳定。此时再提升边缘节点的存储空间也不会进一步降低其边缘计算处理时延。而对于MP 算法来说,随着资源的增多,其降低的时延没有明显的变化,这也说明了DRL 算法相较于传统MP 算法更能适应实验环境的变化。
4.3.2 平均请求数量对于算法性能的影响
由式(3)可知,服务的请求数量会影响算法的奖励值,进而也会对算法性能产生影响,如式(12)所示,有两个因素影响着各服务的平均请求数量:用户的数量以及齐夫分布参数λ的取值。
图7 为各类算法在不同用户数的情况下能够降低的边缘计算处理时延。由图7 可知,各类算法对于用户数呈现较强的线性关系,说明随着服务平均请求数量的增加,边缘计算处理时延降低得也越多。
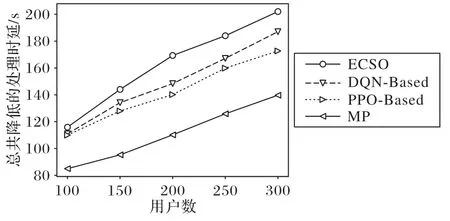
图7 不同用户数量下降低的时延Fig.7 Latency reduction under different number of users
图8 为ECSO 算法在不同λ取值下降低的边缘计算处理时延(Total)以及对于每个服务所能平均降低的时延(Average)。由图8 可知,随着λ的增大,算法所能降低的处理时延越来越少。这是由于随着λ的增大,每个服务的平均请求数量也随之降低,进而导致算法所能降低的时延更少。但总共降低的时延越多并不意味着对于每个服务的请求所平均降低的时延越多,因此本文将算法总共能降低的时延与服务请求数量相除,得到算法对于每个服务请求所能平均降低的时延。由图8 可以看到,随着λ的增大,每个服务平均降低的时延反而越多。这是因为λ的增大会导致用户对各类服务的请求更集中,下载服务数据所导致的下载时延也就越低,因而对于每一请求,平均降低的时延也越多。
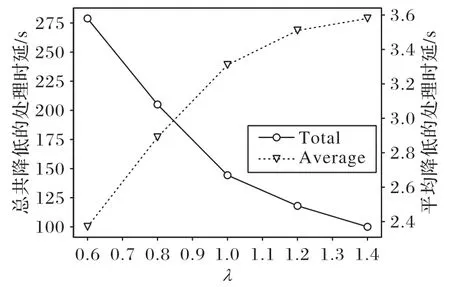
图8 不同λ参数下降低的时延Fig.8 Latency reduction under different λ parameters
5 结语
本文研究了存储空间以及计算资源限制情况下的边缘计算服务卸载问题。首先将问题建模为马尔可夫决策过程,旨在最大化长期奖励,也就是边缘节点长期所降低的处理时延;其次提出了ECSO 算法,在DQN 算法的基础上提出了一种新的动作行为,将动作空间大小从3|κ|减少到了 ||κ,避免非法动作影响的同时对动作进行筛选,得到最优动作集合,提升模型的训练收益;最后通过仿真实验模拟,对比不同算法在同一实验环境下所能降低的边缘计算处理时延。结果表明,本文ECSO 算法相较于DQN、PPO 以及MP 三种算法能更有效地降低计算服务卸载带来的时延消耗。由于在实际应用中单一考虑边缘节点进行服务卸载的效率还有待进一步提升,因此未来还将考虑多边缘节点下的协同服务卸载与计算问题。
