ORBTSDF-SCNet:一种动态场景在线三维重建方法
2023-05-06李翔宇张雪芹
李翔宇,张雪芹
(华东理工大学信息科学与工程学院, 上海 200237)
三维模型已经越来越多地被应用于各种领域,例如医疗、电影、建筑业和虚拟现实(Virtual Reality,VR)等,其中三维重建是制作三维模型的重要手段之一。三维重建是指通过对真实世界的扫描绘制三维模型。早期的三维重建有主动式扫描重建和被动式扫描重建,这些方法通过采集环境或物体数据,然后进行离线重建。同步定位与重建系统(Simultaneous Localization and Mapping, SLAM)在一定程度上克服了离线重建的局限性[1]。Izadi 等[2]提出首个在线三维表面重建SLAM 算法Kinect Fusion,该算法基于RGB-D 相机和 TSDF(Truncated Signed Distance Function)方法实现了实时重建。随后,Endres等[3]提出RGBDSLAM_V2 算法,该算法综合了图像特征提取、闭环检测、点云、octomap 等技术,在ICL-NUIM 数据集的4 个起居室序列kt0~kt3 上的实验结果表明绝对位姿误差(Absolute Trajectory Error,ATE)的均方根误差(Root Mean Square Error,RMSE)平均值为0.121 m。但该算法的实时性较差,相机必须慢速运动。Whelan 等[4]提出的Kintinuous算法是对KinectFusion的改进,该算法的位姿估计采用迭代最近点法(Iterative Closest Point,ICP)和直接法,并首次使用变换图,在闭环检测时,对三维刚体重建做非刚体变换,使得闭环中两次重建的结果能够重合。该算法在ICL- NUIM 数据集的4 个起居室序列中,平均ATE RMSE 为0.111 m。之后,Whelan 等[5]提出Elastic Fusion 算法,该算法基于实时密集视觉RGBD SLAM 进行表面重建,其传感器估计算法采用不断优化重建地图的方式,提高重建和位姿估计的精度。其在ICL- NUIM 数据集的4 个起居室序列上的实验表明,其平均ATE RMSE 达到0.035 m。然而RGBDSLAM_V2 和Elastic Fusion 输出的都是三维点云模型,而不是mesh 模型,无法直接作为三维模型应用,kintinuos 能够输出三维mesh 模型,但是位姿误差较大。同时,上述方法都无法实现有移动物体干扰情况下的场景有效重建。
为了解决具有移动物体干扰下的场景在线重建问题,一部分研究者提出结合SLAM 与深度学习/网络的重建方法。Zhang 等[6]提出了一个三维点云重建方法FlowFusion,该算法使用光流残差与深度学习网络结合来描述点云中动态物体的语义,可以同时完成场景中动态和静态物体分割、相机运动估计以及静态背景点云重建。在TUM 数据集中walking_static与walking_xyz 两个动态序列上的实验结果表明,其ATE 的RMSE 平均值为0.194 m。Scona 等[7]提出了一种鲁棒RGB-D SLAM 方法StaticFusion,该算法在估计RGB-D 相机位姿的同时分割当前帧图片中的静态像素,将当前帧像素的静态概率当做一个连续的变量,和位姿一起联合优化,用于构建静态场景的面元地图,在检测运动物体的同时实现了背景的点云重建。在TUM 数据的6 个动态序列上的实验表明,ATE 的RMSE 平均值为0.083 m。Long 等[8]在StaticFusion 识别动态物体基础上提出了RigidFusion方法,该方法将所有动态部分视为一个刚性部分,同时使用动态和静态部分的特征计算位姿,在自制数据集上的实验结果表明ATE 的RMSE 平均值为0.0795 m。随着基于深度学习的目标检测[9]和实例分割技术的发展,Mask RCNN[10]与RGB-D SLAM 结合的系统Mask Fuison[11]被提出。Mask Fusion 能够识别和分割场景中的不同对象,并给它们分配语义类标签,实现了跟踪和点云重建。在TUM 数据的6 个动态序列上的实验表明,ATE 的RMSE 平均值为0.055 m。上述方法在一定程度上解决了具有移动物体干扰场景下的在线重建问题,但是精度不够高,同时其输出的是点云,而非构造完整的三维模型。Li 等[12]提出了一个基于实例分割的三维重建框架SplitFusion。该方法使用一阶实例分割网络YOLACT分割移动物体与背景,使用非刚性ICP 进行位姿追踪,并对两者分别进行模型重建,在TUM 数据集的两个动态序列上ATE 的RMSE 平均值为0.129 m。
目前针对具有移动物体干扰的三维场景重建系统的研究仍然较少。针对该问题,本文提出一个全新的在线三维重建框架ORBTSDF-SCNet,该框架采用深度相机或双目相机获取重建物体及场景的深度图与RGB 图,基于ORB_SLAM2 实时获取位姿信息,将表面重建算法TSDF 与深度图相结合,实现了在线三维模型重建;为了消除场景中移动物体对场景重建的干扰,提出基于SCNet 实例分割网络抠除移动物体,实现了移动物体干扰下的高精度场景三维重建。
1 相关工作
1.1 ORB_SLAM2
ORB-SLAM2[13]系统是目前主流的SLAM 系统,在位姿估计中具有很高的精度。SLAM 具有3 个线程:实时跟踪特征点的Tracking 线程、局部BA(Bundle Adjustment)优化线程和全局Pose Graph 的回环检测与优化线程。其中,Tracking 线程主要负责提取当前帧的ORB(Oriented Fast and Rotated Brief)特征点,与最近的关键帧进行比较、计算特征点的位置并估计相机位姿。本文提出的方法主要采用ORB_SLAM2 的Tracking 线程实现高精度位姿估计,Tracking 线程的基本组成如图1 所示。
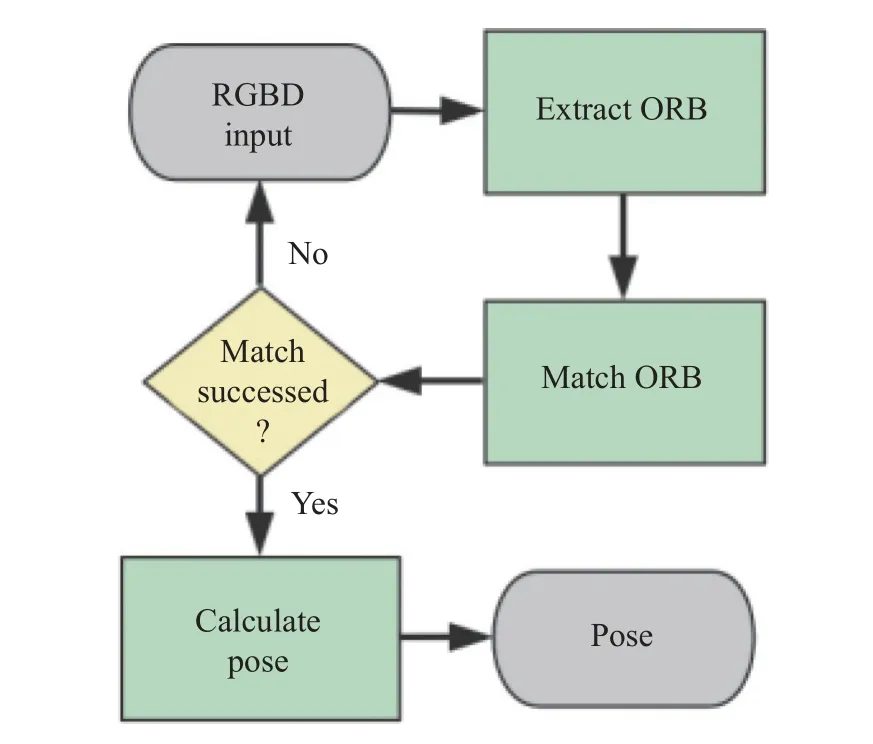
图1 Tracking 线程的基本组成Fig.1 Basic composition of tracking thread
当ORB 系统获取RGBD 图像后,进行Oriented FAST 角点特征选取,然后根据提取的特征进行ORB 匹配。ORB 特征匹配需要先计算Oriented FAST角点的BRIEF (Binary Robust Independent Elementary Feature)描述子,特征点的匹配与关联通过重投影进行。匹配时,将图像中的像素点根据初始位姿投影至当前帧获得投影点,并把在该投影点附近搜索得到的与原ORB 特征点的BRIEF 描述子的汉明距离最近的点作为特征匹配点。在ORB 系统得到当前帧与前一帧或者局部地图的匹配点对后,使用图优化框(General Graph Optimization,g2o)优化相机位姿,若判断成功则输出位姿,反之,跟踪失败则回到最开始重新获取RGBD 图像。
1.2 TSDF
TSDF 是一种利用结构化点云数据并以参数表达表面的表面重建算法,可以高效准确地实现在线三维重建。其原理如图2 所示。
图2 中,TSDF 首先在一个全局三维坐标中建立格式化体素立方体,每一个立方体都包括值与权重两个量。TSDF 遍历深度图,根据像素点坐标、深度值及相机内参与位姿得到每个像素点对应的体素立方体坐标,并根据式(1)~式(3)计算该立方体的权重与值。

图2 当前帧表面点云映射到立体体素Fig.2 Depth map to TSDF mesh
式中:下标i为当前帧;i−1 为上一帧;Wi(x,y,z) 为体素立方体的权重;max weight 为最大权重,默认为2;sd fi为根据深度数据计算得到的体素立方体到物体表面的真实距离;max truncation为截断范围,默认为0.06mdi(;x,y,z)为到物体表面的真实距离除以截断范围的体素值;Di(x,y,z)为带有权重信息的最终体素立方体的值。
计算得到Wi(x,y,z) 与Di(x,y,z) 后,提取体素立方体中Wi(x,y,z) 大于体素权重阈值Wmin,且Di(x,y,z)等于0 的等势面,即可得到重建的mesh 模型。
1.3 SCNet
SCNet 是Vu 等[14]提出的一个基于Mask RCNN、Cascade RCNN[15]与HTC(Hybrid Task Cascade)[16]架构改进而来的实例分割网络,具有良好的分割性能和较好的运行速度。SCNet 由Backbone、区域生成网络(RPN)和级联网络构成,其网络结构如图3 所示。
图3 中示出的“G”、“Pool”、“B”、“FR”、“M”分别指代全局一致模块、全局池化层、Box 分支、FR(Feature Relay)模块和Mask 分支。SCNet 采用Restnet 50 作为Backbone,在RPN 前引入全局一致模块,以充分利用全局上下文信息分类、检测和分段子任务之间的相互关系。与HTC 相比,SCNet 的级联结构只在最后一个池化层才输出Mask 分支,使得SCNet 速度更有优势。FR 模块将Box 特征与Mask 特征紧密耦合,改善Mask 预测性能,弥补速度提高降低的准确度。最后,三级Box 分支通过FR 模块、Mask 分支和全局一致模块融合得到最终结果。
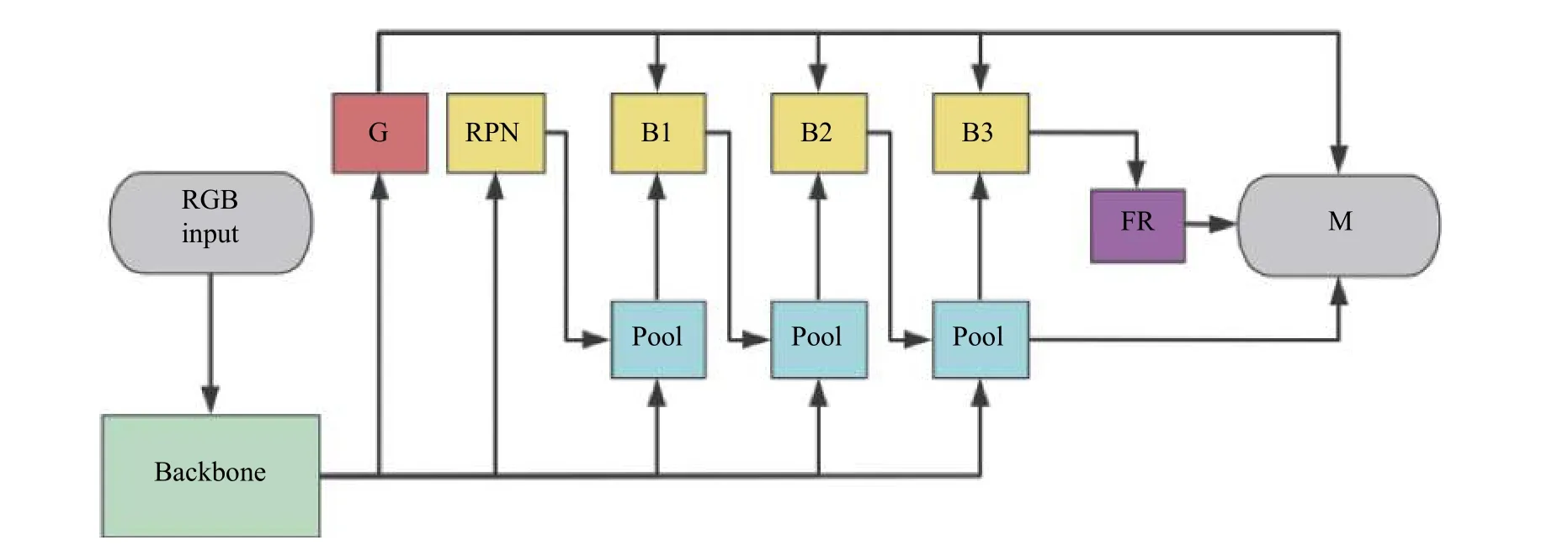
图3 SCNet 网络结构Fig.3 Network structure of SCNet
2 ORBTSDF-SCNet 三维重建方法
针对有动态物体干扰的高精度在线三维场景重建容易出现重建失败、重建出现拖影、重建精度不高等问题,本文提出结合ORB_SLAM2、TSDF 与SCNet 网络的ORBTSDF-SCNet 系统框架,结构图如图4 所示。其中,蓝色部分为ORBTSDF 模块,包括ORB_SLAM2、TSDF 系统,主要用于获取位姿和重建模型;黄色部分为SCNet 模块,主要用于检测和分割出移动物体;绿色部分为中间数据处理模块,主要用于传输和处理ORBTSDF 与SCNet 之间的RGBD 图像,抠除移动物体。
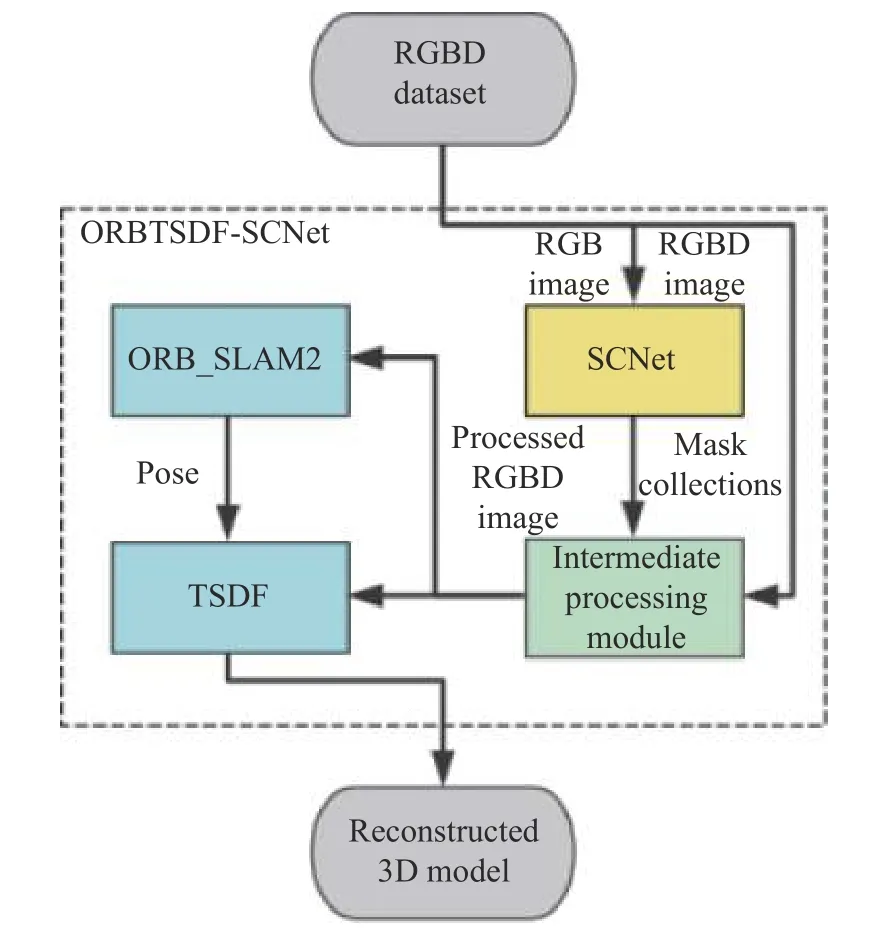
图4 ORBTSDF-SCNet 结构图Fig.4 Structure of ORBTSDF-SCNet
ORBTSDF-SCNet 的工作原理如下:
(1)来自深度相机的RGBD 图像流,将RGB 图像流传给SCNet 网络,将RGBD 图像流传给中间数据处理模块。
(2)SCNet 对输入的RGB 图像进行移动目标检测与实例分割,得到含有多个检测目标的Mask 图合集。
(3)Mask 图合集传给中间处理模块,对分割实例进行膨胀并做抠图处理,抠除实例后的RGBD 图传给ORB-SLAM2 与TSDF。
(4)ORB-SLAM2 对RGB 图进行ORB 特征选取与匹配,计算得到位姿。
(5)TSDF 将RGBD 图经过位姿参数与相机内参运算转化,计算得到体素立方体数据,生成三维重建结果。
由于通常出现在室内的移动物体是人,因此本文将人作为重建现场的移动物体。
2.1 ORBTSDF
针对SLAM 系统只能输出点云,不能直接生成三维模型,本文提出结合ORB-SLAM2 和TSDF 的三维重建算法ORBTSDF。ORBTSDF 的重建过程流程图如图5 所示。

图5 ORBTSDF 整体三维重建流程图Fig.5 Flow chart of 3D reconstruction of ORBTSDF
ORBTSDF 接收RGBD 图像,分别传给ORB_SLAM2 与TSDF 模块。ORBTSDF 采用ORB_SLAM2 Tracking 线程的ORB 特征检测与匹配算法进行特征提取和匹配,计算图像流中各帧与第一帧的位姿差,然后传给TSDF 模块。
TSDF 首先对RGBD 图做一个简单阈值滤波,过滤掉距离深度图中过远的像素飞点。然后将其经过位姿处理后生成新增体素数据,按照式(1)~式(3)将新增数据融合进总体素数据合集。为了解决后期模型上色问题,在TSDF 体素数据中,增设一个颜色变量,保存每个体素立方体的RGB 图颜色。体素数据和颜色变量一并存入显存。
为了得到带颜色的三维重建场景,将体素数据中满足权重阈值Wmin的体素立方体以及与其对应的颜色变量分别从显存中提出,保存为.bin 的mesh 文件和.ply 的点云文件。mesh 文件主要用于三维模型生成,点云文件主要用于预览点云效果和存储颜色信息。重建模型时,采用isosurface 势面提取算法,基于mesh 文件生成三维模型;采用meshlab 三维几何处理软件,基于点云文件对三维模型进行上色处理,最终得到带颜色蒙皮的三维重建模型。
2.2 移动物体的抠除和误差优化
为了进一步解决因SCNet 算法精度问题而引起RGB 图检测和实例分割误差,以及由于深度相机内部原因而引起的深度图和RGB 图对准误差,在中间处理模块对Mask 合集图像进行膨胀处理。
首先对二值化的Mask 合集图像使用5×5 的描述子(膨胀大小)进行3 次膨胀处理;为了平滑毛刺点,再使用3×3 与1×1 的描述子分别进行1 次膨胀。将膨胀后的Mask 图像渲染为白色,同时将Mask 图像对应的RGB 图中相应区域的像素值设为255(颜色变为白色),深度值设为0,即从RGBD图中抠除了移动物体。抠除移动物体的RGBD 图传给ORBSLAM2 和TSDF,消除了移动物体对ORB 的特征提取与匹配,以及对重建造成的干扰。
2.3 算法流程
本文提出的ORBTSDF_SCNet 场景三维重建算法流程如图6 所示。
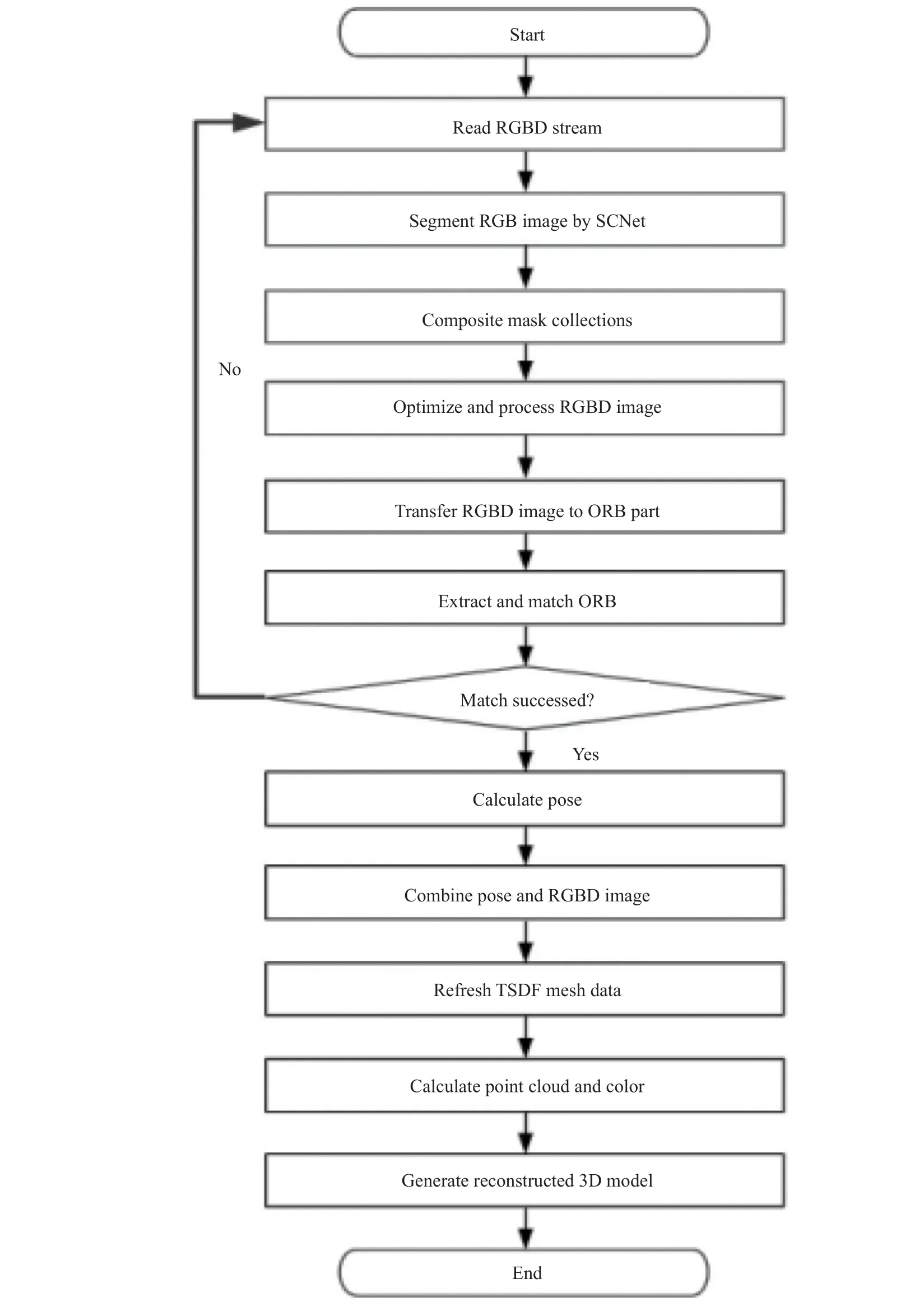
图6 ORBTSDF-SCNet 算法流程图Fig.6 Flow chart of ORBTSDF-SCNet algorithm
3 实验结果与分析
实验采用的处理器为 AMD R7 3700X@3.6 GHz,内存为 16 GB,操作系统为64 位Ubuntu16.04,运行环境为 python 3.7,GPU 为NVIDIA GeForce GTX 1080 显存为 8 G,硬盘大小为 1 TB。
3.1 实验数据集
静态数据集为Imperial College London[17]发布的ICL-NUIM 数据集。该数据集提供的起居室场景具有 3D 实况深度图、相机姿势以及高精度雷达重建的ground truth,适合在静态场景中评估相机轨迹的精准度。本文选取了起居室场景中的4 个片段:kt0、kt1、kt2、kt3。
动态数据集为TUM 数据集[18]中的办公室场景,该数据集提供有相机移动位姿的ground truth,适合在动态场景中评估相机轨迹的精准度。本文选择TUM 数据集中含有移动物体的6 个数据子集:sitting_static、sitting_xyz、sitting_halfsphere、walking_static、walking_xyz、walking_halfsphere,后续实验中分别简称为sit_static、sit_xyz、sit_hsp、walk_static、walk_xyz、walk_hsp。
这6 个数据子集均由手持摄影机拍摄,场景中都包含有移动的测试人员。测试人员一直保持在相机前方移动,在sitting 子集中,两名测试人员坐在凳子上,仅有细微的移动;在walking 子集中,两名测试人员围绕办公桌走动两圈,移动速度约为1 m/s。static 表示相机一直朝向前方拍摄,仅随拍摄人员的手有轻微抖动,x、y、z表示相机沿着x、y、z轴移动,halfsphere(hsp)表示相机沿着一个直径约1 m 的半球移动。
3.2 评价指标
位姿精度是评估重建精度的一个重要指标。位姿误差越低,重建误差越低。本文从ATE 和相对位姿误差(RPE)两个方面来评价算法重建性能。
(1)ATE 绝对轨迹误差是估计位姿和真实位姿的直接差值,通常用于评估SLAM 算法精度和轨迹全局一致性。
绝对位姿误差通常以均方根误差RMSE 表示:
式中:N为数据个数;Yi为ground truth 提供的真实值;f(xi) 为重建得出的位姿值。均方根误差的单位为mm。
(2)RPE 相对位姿误差主要描述相隔固定时间差 ∆ 的两帧的位姿相比真实位姿的差值,通常用于评估SLAM 里程计的误差。第i帧的RPE 定义如下:
式中:Qi为ground truth 提供的真实位姿;Pi为重建完成后的估计位姿,下标i代表时间或帧。
相对位姿同样以均方根误差RMSE 表示,如式(6)所示:
3.3 实验结果及分析
实验中,ORB 参数使用默认设置:nFeatures=1000,scaleFactor=1.2,nlevels=8,iniThFAST=20,minThFAST=7。在静态场景重建时,设TSDF 的权重阈值Wmin=0,即只要当一个点出现在一个体素立方体内一次就取为重建点。在有移动物体干扰的场景中重建时,设TSDF 权重阈值Wmin=100,即当一个点在100 帧中连续出现在一个体素立方体的同一位置时,将这个点作为重建的点,以避免出现大量的拖影,减小误差。SCNet 基于COCO 数据集作预训练,所有实例分割网络的检测阈值设为0.8。
3.3.1ORBTSDF 对比实验 本实验用于验证ORBTSDF 的重建精度,并与7 种重建算法进行对比。对比实验选取文献[19]所提DVOSLAM(DS)、文献[3]所提RGBDSLAM_V2(RSV2)算法、文献[20]所提MRSMap(MRS)、文献[4]所提Kintinuous(KS)算法、文献[5]所提ElasticFusion(EF)算法和ElasticFusionFrame-to-model(FTM)算法和文献[13]所提ORB_SLAM2(OS2)算法。为了进行对比实验,依据上述文献,实验使用ICL-NUIM 数据集,评价指标采用ATERMSE。实验结果如表1 所示。
表1 中,average 表示平均ATERMSE。由表1可见,本文所提ORBTSDF 算法的平均ATERMSE最低,在kt0 和kt3 上有明显优势。FTM、RSV2、DS、KS 这4 种重建算法的平均ATERMSE 为ORBTSDF的3~6 倍,MRS 重建算法的平均ATE RMSE 是ORBTSDF 的约15 倍,EF 和OS2 在4 个序列上整体重建效果比较均衡,平均ATERMSE 略高于ORBTSDF,KS 重建算法在序列kt1 和kt2 中误差最低。总体而言,本文所提ORBTSDF 重建算法是有效的。
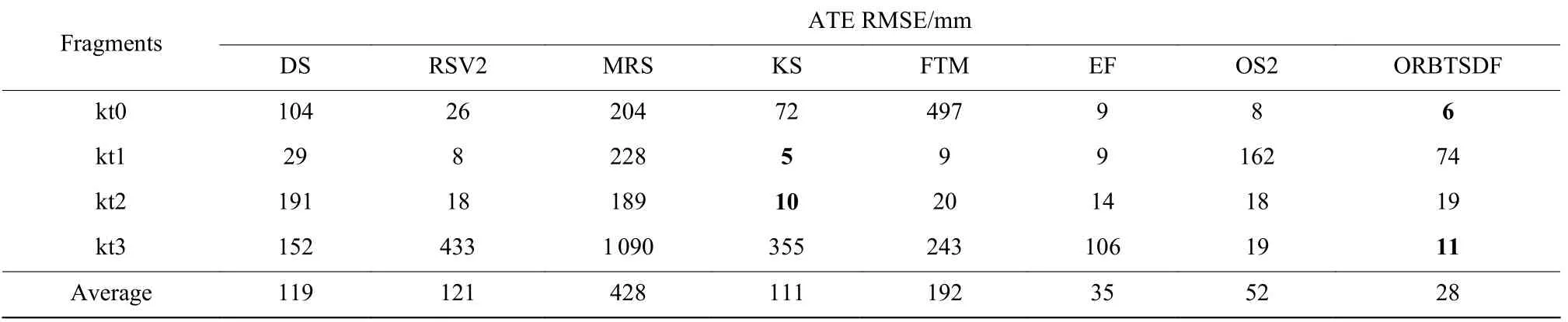
表1 在ICL-NUIM 数据集上的ATE RMSE 对比实验结果Table 1 Comparative results of ATE RMSE on ICL-NUIM dataset
3.3.2SCNet 膨胀及优化实验 为了验证采用SCNet 网络以及进行膨胀处理的有效性,在TUM 数据集中6 个序列上进行重建测试。不同方法的RMSE 实验结果如表2 所示。表中,OF 代表仅使用ORBTSDF方法,SM 代表使用ORBTSDF+SCNet 方法,SD 代表使用ORBTSDF+SCNet+膨胀处理方法。
从表2 中ATE RMSE 实验结果可以看出,与OF 方法相比,当采用SM 方法时,除sit_xyz 序列外,在其他5 个序列上ATE RMSE 都有减小;SD 方法的ATE RMSE在除了sit_xyz 外的5 个序列上分别下降约90%、64%、96%、21%、13%,平均下降约89%;SD方法与SM 方法相比较,在walk_hsp、walk_xyz 和sit_hsp 这3 个序列上ATE RMSE 分别下降了约62%、14%、12%。在sit_xyz 序列上,SM 和SD 方法的误差略低于OF 方法,是因为在该序列上人仅有小幅运动,近似为静态场景。
从表2 中RPE RMSE 实验结果可以看出,SM 方法相较于OF 方法,误差降低了约68%,SD 方法相较于SM 方法,误差降低了约27%。总体而言,本文所提重建算法使用SCNet 网络在膨胀下是有效的。
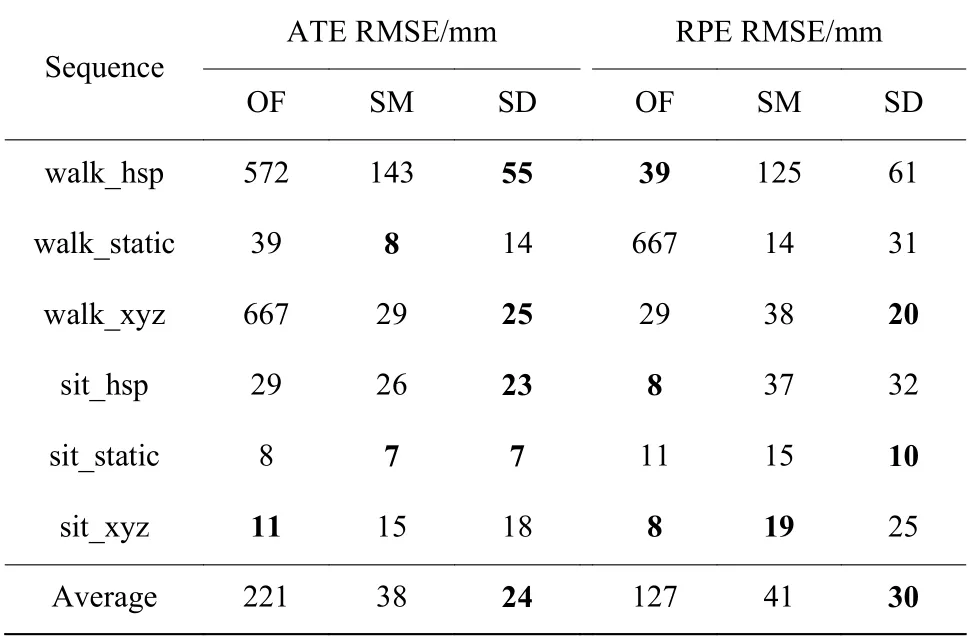
表2 TUM 数据集上不同方法的RMSE 实验结果Table 2 Comparative results of RMSE on TUM dataset with different methods
3.3.3分割网络对比实验 为了验证采用SCNet 网络的有效性,将ORBTSDF 方法分别与MaskRCNN、CascadeMaskRCNN 和HTC 结合(分别命名为MR、CMR 和HTC),与本文所提ORBTSDF-SCNet 方法进行对比,实验结果如表3 所示。
从表3 中实验结果可以看出,在static 序列下,因为相机移动幅度很小,所以4 个网络的分割误差相差不明显。但在xyz 序列和hsp 序列下,随着相机移动幅度加大,本文方法的误差相较其他网络有较为明显的降低。在walk_xyz 序列下,本文方法相较于MR、CMR 和HTC,其ATE RMSE 分别下降了约35%、0、12%,RPERMSE 分别下降了约30%、34%、2%;在sit_xyz 序列下,其ATERMSE 分别下降约25%、28%、42%,RPERMSE 分别下降约26%、9%、42%。在walk_hsp 序列下,ORBTSDF-SCNet 相较于MR、CMR 和HTC,其ATE RMSE 分别下降了约63%、46%、21%,RPE RMSE 分别下降了约73%、64%、0。在sit_hsp 序列下,相较于MR 和HTC,ORBTSDF-SCNet 的ATERMSE 分别下降了约16%和38%,RPERMSE 分别下降了约9%和7%,但高于CMR 的对应值。总体来看,在6 个序列中,ORBTSDF-SCNet 的ATE RMSE 平均值分别下降了约55%、37%、24%,RPE RMSE 平均值分别下降了约59%、50%、7%。可见,本文所提重建方法ORBTSDF结合使用SCNet 网络是有效的。
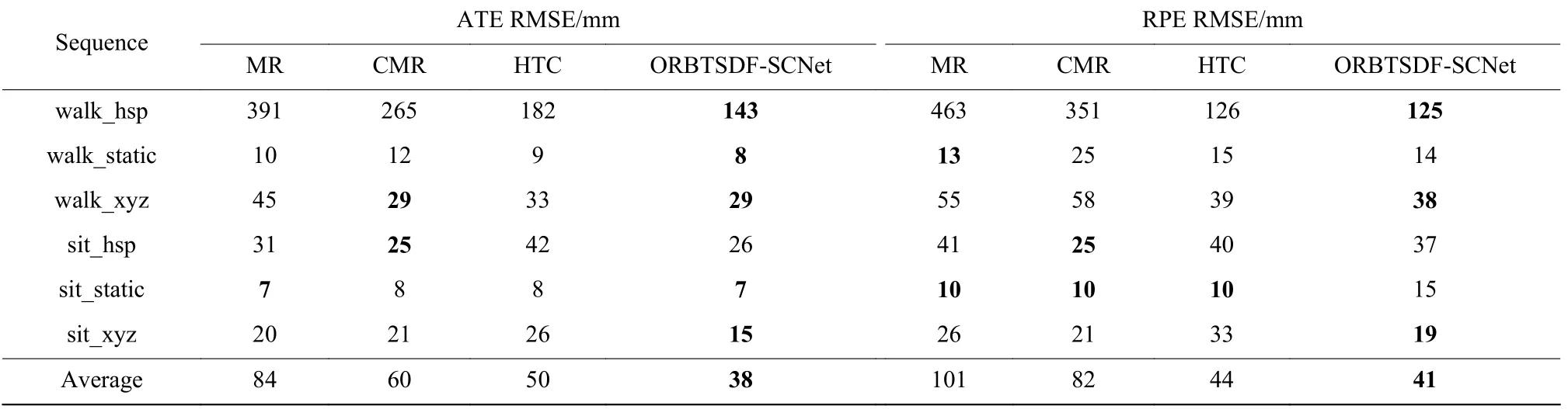
表3 TUM 数据集上不同实例分割网络RMSE 实验结果Table 3 Comparative results of RMSE on TUM dataset with different instance segmentation networks
3.3.4ORBTSDF-SCNet 对比实验 为了验证所提出的 ORBTSDF-SCNet 模型的重建有效性,将ORBTSDF-SCNet 算法分别与文献[5]所提Elastic Fusion(EF)算法、文献[7]所提StaticFusion(SF)方法、文献[11]所提MaskFusion(MF)方法、文献[6]所提Flow Fusion(FF)方法、文献[11]所提VO-SF(VS)方法,文献[21]所提Co-Fusion(CF)方法和文献[22]所提PoseFusion(PF)方法进行对比。
根据文献,SF、FF 和PF 方法使用TUM 数据集中的两个序列进行测试,因此与上述方法对比时使用相同的两个序列。实验结果如表4 所示。而VS、EF、CF 和MF 使用TUM 数据集中的6 个序列进行测试,因此与上述方法比较时使用相同的6 个序列。实验结果如表5 所示。
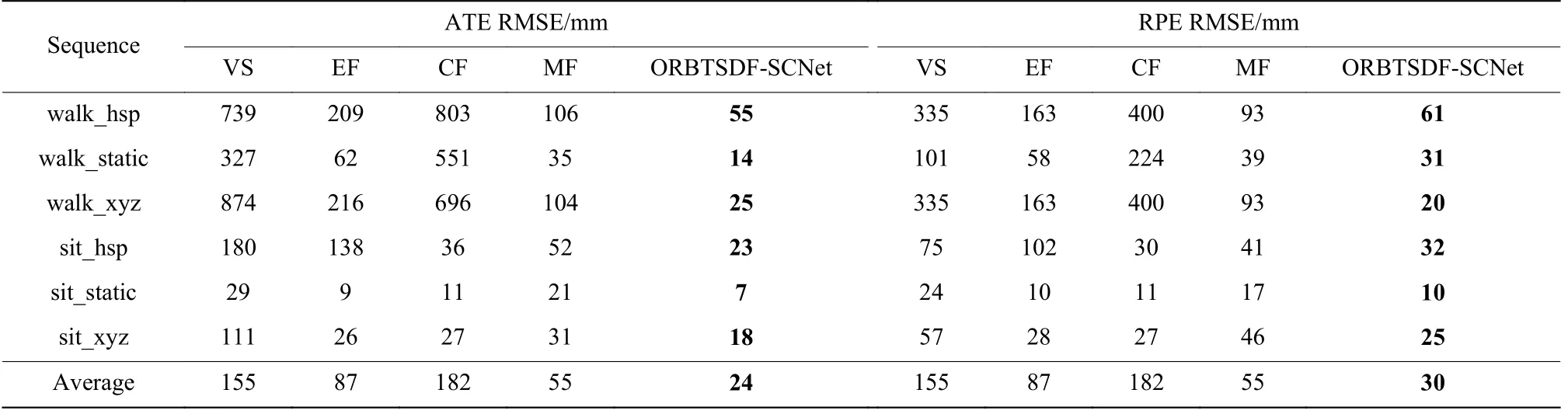
表5 在TUM 数据集六个序列上RMSE 对比实验结果Table 5 Comparative results of RMSE on six sequences of TUM dataset
从表4 可以看出,本文提出的ORBTSDF-SCNet方法在walk_sta 和walk_xyz 序列上的平均误差都为最低,平均ATERMSE 比SF、FF、PF 算法分别降低了约95%、84%和66%,PRERMSE 分别降低了约94%、87%和75%。

表4 在TUM 数据集两个序列上RMSE 对比实验结果Table 4 Comparative results of RMSE on two sequences of TUM dataset
在表5 TUM 数据集的6 个序列上的对比实验可见,使用了Mask-RCNN 的MF 相对于EF,在walk_hsp、walk_static 和walk_xyz 动态序列上的ATE RMSE 有较大的下降。本文所提RBTSDF-SCNet 方法的ATE RMSE 与PRE RMSE 在所有序列上平均值都是最低的,相对方法VS、EF、CF、MF,其平均ATE RMSE分别下降约84%、72%、86%和56%,其PRE RMSE分别下降约80%、65%、83%和45%。可见,本文所提方法在有动态物体干扰的情况下重建是有效的。
3.3.5速度性能对比实验 为了说明ORBTSDFSCNet 的重建速度,在TUM 数据集上与MF 方法进行了对比。MF 是目前在有动态物体干扰下重建位姿精度最高的在线RGB-DSLAM 方法。实验中,MF 使用默认参数设置,速度单位为fps(FramesPer Second)。
从图7 中可以看出,由于在hsp 序列中相机存在大幅度移动,因此MF 重建失败,而ORBTSDFSCNet 能够实现成功重建,平均速度为2.8fps。在walk_static和walk_xyz 两序列中,MF 的速度分别为2.5 fps 与2.3 fps,而ORBTSDF-SCNet 的速度均为2.8fps。可见,当物体移动幅度较大时,ORBTSDFSCNet 的速度性能超过MF。但是,在sit_static,sit_xyz序列中,由于物体移动幅度不大或者静止,ORBTSDFSCNet 的速度小于MF。总体而言,ORBTSDFSCNet 无论在相机移动、物体移动或静止情况下重建速度相对保持稳定。
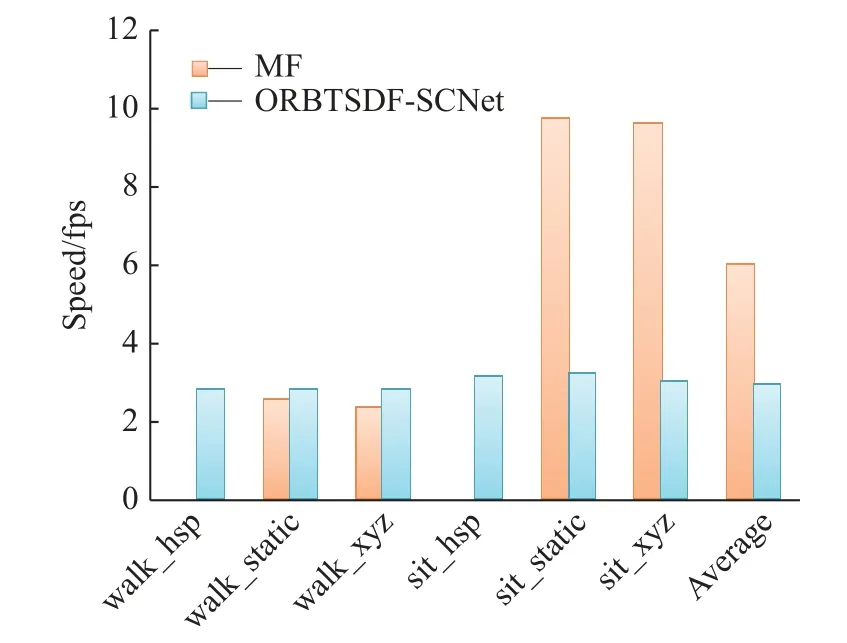
图7 TUM 数据集6 个序列运行速度对比Fig.7 Comparative results of running speed on six sequences of TUM dataset
3.3.6静态重建效果展示 为了更直观地展示ORBTSDF 方法,特别是基于TSDF 进行静态场景三维重建的效果,在ICL- NUIM 数据集进行ORBTSDF重建,以第1 序列kt0 为例,重建效果如图8 所示。
图8(a)所示为ICL- NUIM 数据集的Ground truth,图8(b)所示为kt0 序列经过ORBTSDF 重建得到的带有颜色的点云,图8(c)所示为ORBTSDF 重建得到的不带颜色的TSDF Mesh 模型,图8(d)所示为得到的带颜色的三维重建模型。
对比图8(a)与8(c)可以看出,本文所提ORBTSDF重建方法具有较高精度。对比图8(b)与8(d)可以看出,文本所提重建方法还能够较好地对颜色与细节进行重建。

图8 ORBTSDF 重建效果图Fig.8 Reconstruction effect of ORBTSDF
3.3.7动态重建效果展示 为了更直观地展示ORBTSDF-SCNet 方法在有移动干扰物下的三维重建效果,以TUM-NUM 数据集walk_xyz 序列与walk_hsp 序列为例,与EF、MF 方法的重建效果进行对比,结果分别如图9、图10 所示。
在walk_xyz 序列中,两名测试人员从办公椅上站起来,绕着办公桌走了多圈,最后坐下。在walk_hsp序列中,两名测试人员从办公椅上站起来,绕办公桌走了1 圈后并坐下,1 名测试人员站起来继续绕圈,另外1 名测试人员有各种动作。
从图9(a)中可以看到,由于EF 没有动态物体检测与剔除功能,所以画面中测试人员坐在办公桌前被重建,且左侧出现蓝色衣服测试人员的残影,同时由于动态物体的干扰,对比图9(c)可以发现EF 点云重建内容不够完整,细节不能有效重建。从图9(b)中看出,MF 在有动态物体的干扰下,几乎无法实现场景的重建,除了电脑部分外,其他部分已经基本无法辨认。因此采用本文所提方法有效排除了动态物体干扰,实现了场景的有效重建。

图9 walk_xyz 序列动态重建效果对比图Fig.9 Dynamic reconstruction effect comparison on walk_xyz sequence
从图10(a)中可以看到,由于EF 在动态物体测试人员的干扰下,非常明显地出现了位姿估计错误,导致重建了两个相交的办公桌,两个平行办公椅,并且在左侧也错误地重建了测试人员。由图10(b)可见,MF 在有动态物体的干扰下,几乎无法实现场景的重建,但采用本文所提方法(图10(c)、(d))有效排除了动态物体干扰,实现了场景的有效重建。

图10 walk_hsp 序列动态重建效果对比图Fig.10 Dynamic reconstruction effect comparison on walk_hsp sequence
4 结束语
为了实现在线重建并端到端输出三维模型,本文提出基于ORB-SLAM2 和TSDF 的重建算法ORBTSDF。同时针对高精度三维重建系统遇到动态干扰物体时容易重建失败或精度大幅下降的问题,结合SCNet 框架与ORBTSDF,提出ORBTSDFSCNet 方法,对移动的目标进行检测与实例分割,并通过对检测对象进行膨胀处理,降低RGB 图分割误差与深度图配准误差,实现对移动物体的有效抠除。在多个数据集上的对比实验结果表明,本文所提出方法对有移动物体干扰的场景能够实现有效重建。在未来,可以结合高精度分割网络,实现对多个移动目标物体进行追踪与高精度重建。
