基于抽象语法树和图匹配网络的代码作者身份识别
2023-04-29郭迪骁周安民刘亮张磊
郭迪骁 周安民 刘亮 张磊
摘要:源代码作者身份识别有助于解决恶意代码攻击溯源、代码剽窃、软件侵权等问题,本文提出一种新的基于图匹配网络和抽象语法树的源代码作者身份识别方法.首先,通过删除注释、统一换行符、制表符预处理源代码,消除不同集成开发环境和代码布局的影响;然后,基于数据增强抽象语法树将源代码转换为树结构,添加不同类型的边构建代码特征图,不仅关注语法和句法特征,还提取了代码中数据流和控制流特征;接着使用特征图训练图匹配神经网络,生成源代码的图嵌入特征向量;最后,使用孪生神经网络对输出的两个图嵌入特征向量进行计算,识别源代码作者身份.实验结果表明,本文的方法在包含1000位程序员的Google Code Jam数据集上达到了95.60%的准确率,与现有的源代码作者身份识别方法相比,提高了准确率和扩展性.
关键词:代码样式;去匿名化;抽象语法树;图神经网络;孪生神经网络
收稿日期: 2022-07-08
基金项目: 四川省科技计划项目(2021YFG0159&2022YFG0171);四川大学专职博士后研发基金(2021SCU12136)
作者简介: 郭迪骁(1998-),男,重庆永川人,硕士研究生,研究方向为恶意代码分析.
通讯作者: 张磊. E-mail: zhanglei2018@scu.edu.cn
Code authorship attribution based on
abstract syntax tree and graph neural network
GUO Di-Xiao,ZHOU An-Min,LIU Liang,ZHANG Lei
(School of Cyber Science and Engineering, Sichuan University, Chengdu 610065, China)
Source code author identification aids to solve problems such as malicious code attack traceability, code plagiarism, software infringement, etc. In this paper, the authors proposed a novel code de-anonymization model, which is based on the Graph Matching Network and Abstract Syntax Tree. First, the source code is preprocessed by removing comments, unifying newlines and tabs to eliminate the influence of different IDEs and code layouts features. Then, the source code is converted into a tree structure based on the data-augmented abstract syntax tree, the different types of edges are added to build the code feature graph, which not only focus on syntactic features, but also extract the data flow and control flow information. The feature graph is then used to train the graph matching neural network to generate the graph embedding feature vector of the source code; Finally, the output graph embedding feature vectors are calculated by the Siamese network to identify the source code author attribution. The experimental results show that our method finally achieved 95.60% accuracy on the Google Code Jam dataset containing 1000 programmers. Compared with the existing de-anonymization model, it has improved accuracy and extensibility.
Code stylometry; De-anonymization; Abstract syntax tree; Graph neural network; Siamese network
1 引 言
源代码作者身份识别是根据程序员独特的编程风格识别程序员身份的过程.源代码作者身份识别在软件取证和安全分析领域有很大作用,尤其是对于恶意代码作者追踪溯源;例如,可以从反编译的二进制文件中提取程序员的特征.此外,源代码的作者身份识别有助于剽窃检测[1]、作者争议[2]、版权侵权[3]和代码完整性调查[4].源代码作者身份識别有两个主要步骤:特征提取和身份分类识别.特征提取是提取代表作者独特属性的软件指标或特征.分类识别则是将这些特征输入算法以构建能够区分作者身份的模型.
现有的源代码作者特征提取方法主要是基于人工定义特征提取和利用深度学习自动提取[5].Krsul等[6]是第一个引入程序员编程风格特征的人,他们定义了60个特征,并把他们分为三类:编程布局特征(例如空格和括号)、编程风格特征(例如平均变量长度和变量名称)和编程结构特征(例如数据结构的使用和每个函数的代码行数).Frantzeskou等人[7]介绍了使用字节级N-gram特性进行源代码作者身份归属的方法,他们的工作受到N-gram在文本作者身份识别中成功使用的启发,对于每个作者,他们把可用的训练源代码样本接起来形成一个大文件提取该文件中使用最频繁的N-gram的集合作为程序员的身份特征,使用N-gram使该方法可以实现跨编程语言.Lange等[8]第一个考虑结合基于文本的特征和基于软件的特征来识别源代码作者身份,他们使用特征直方图分布来寻找实现最佳识别准确率的特征组合.Caliskan-Islam等人[9]引入抽象语法树的概念并且重新定义了语法特征,他们提取抽象语法树节点二元组,语法树的深度等特征,并且提出特征评估和特征选择过程.Wang等人[10]为解决提取特征维度过大的问题提出代码动态特征,主要是提取代码运行时功能函数的内存消耗,时间消耗和函数调用.人工定义特征提取需要手工定义特征集,这需要较强的编程知识,生成的代码作者特征大多为稀疏向量表示,需要进一步的特征评估和特征选择,并且这种方法很难处理大规模的程序员集合.
利用深度学习自动提取特征无需先验知识,可以解决特征数过多的问题而且适用于大规模的程序员集合.Bogomolov等人[11]在抽象语法树的基础上提出路径上下文(三元组,由两个叶子节点之间的路径和对应于开始和结束叶子的标记组成),并将路径特征分别和随机森林和Code2Vec模型结合.Alsulami等人[12]利用LSTM和BiLSTM,实现自动从源码中提取相关特征,他们的模型使用深度优先搜索算法遍历AST,将AST简化为向量表示,然后传递到深度学习模型.Abuhamad等人[13]利用词嵌入和TF-IDF处理源代码,使用基于CNN的深度学习过程来提取用于作者身份识别的特征.从而实现大规模的代码作者身份识别.
与上述工作不同,本文提出一种基于抽象语法树和图匹配网络的源代码作者身份识别方法,针对输入的源代码,首先进行预处理,消除不同集成开发环境和代码布局的影响;然后通过本文提出的数据增强抽象语法树将源代码转换为树结构,通过添加不同类型的边构建代码特征图;使用特征图样本训练图匹配神经网络,生成代码的图嵌入特征向量,最后使用孪生神经网络对图嵌入特征向量进行计算,识别两份源代码是否属于同一作者.本文的主要工作和贡献包括以下几方面:(1)提出一种基于图神经网络的去匿名化模型,结合抽象语法树和图匹配网络对源代码作者特征进行提取,使用孪生神经网络对匿名源代码作者身份进行识别.(2)提出一种基于数据增强抽象语法树的构建程序特征图的方法.该方法不仅提取源代码的句法和语义特征,而且提取数据流和控制流特征.本文构建特征图的方法可以轻松扩展到其他编程语言.(3)本文使用了三种图神经网络,通过对Google Code Jam数据集和GitHub数据集的实验和评估,表明本文的方法在识别准确率和稳定性上优于当前的其他方法.
2 研究方法
2.1 方法概述
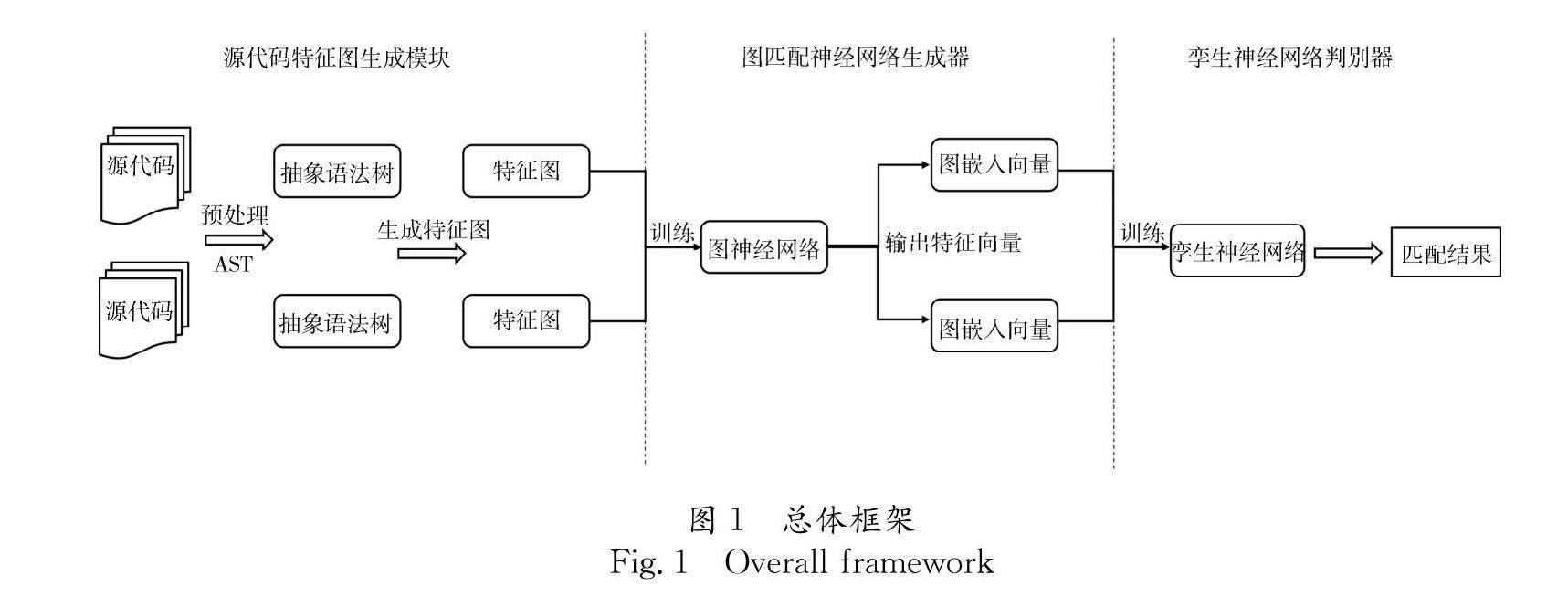
本文提出一种新的匿名代码作者身份识别方法,基于抽象语法树和图匹配神经网络来提取程序员的编程特征,最后使用孪生神经网络作为判别器识别代码作者身份,本文提出的总体框架图如图1所示,包含三个部分:源代码特征图生成模块,图匹配神经网络生成器和孪生神经网络判别器[14].
(1)源代码特征图生成模块:预处理源代码消除不同集成开发环境的影响,基于提出的数据增强抽象语法树将源代码转换为树结构,并通过添加不同类型的边构建代码特征图.
(2)图匹配神经网络生成器:使用特征图样本训练图匹配神经网络,图匹配网络通过对输入的图样本对进行学习和更新,使用图池化生成源代码的低维图嵌入特征向量.
(3)孪生神经网络判别器:使用孪生神经网络对图匹配网络输出的两个图嵌入特征向量进行计算和判断,识别两份代码是否属于同一作者.
2.2 数据增强抽象语法树
抽象语法树(Abstract Syntax Tree,AST)是表示编程语言抽象语法结构的树,AST不太容易受到开发工具的影响.另外,由于AST是树状结构,很容易转换为图这种数据结构,结合图神经网络可以很好地学习和提取源代码这种非欧几里得数据的特征.
传统的AST生成模块针对源代码中的变量、常量等只会生成对应的类信息,比如在Python的AST模块中,针对变量a只会返回变量类ast.name,变量名a只会作为name类的id值,针对常量只会返回ast.constant类,而常量的值存储在类的value中,但是在代码作者身份识别中,变量、函数名等命名方式是很重要的程序员身份特征,需要进行提取,为此本方法设计了一种新的AST生成方式称为数据增强抽象语法树(data-augmented AST),通过遍历AST节点类型的value和id值,将源代码中的变量和常量也提取出来,作为对应类的子节点,充分提取程序员的编程特征.图2和图3分别显示了一段简单的Python源代码以及使用本文方法生成的抽象语法树结构,可以看到变量a,b和常量等数据都作为节点表示了出来.
另外,对于样本中的源代码,本方法进行了预处理操作,包括删除源代码中的注释和源代码调用的内部函数,统一代码中的换行符、制表符和空格等,预处理操作相当于不提取源代码的布局特征(包括空格长度,制表符长度,空行占比等),经过本文实验验证,上述的布局特征對于程序员指纹身份识别的准确率几乎没有影响,但是会增加特征数量和模型训练时间,消除这些布局特征可以消除不同集成开发环境的影响,还可以减少特征数,防止过拟合.
2.3 基于抽象语法树构建图
AST仅仅包含源代码的句法特征,为了完整地提取程序员的编程特征,本方法设计一种基于AST的构建特征图的方法,特征图的主干是源代码的AST,图的节点v是AST节点或其关联的属性节点,本文根据代码的信息流在特征图中定义了以下几种不同类型的边.
Child-Parent: 连接非叶子节点和它的子节点,可以加快模型训练过程中的信息传递.
Token: 连接终端节点和另一个终端节点,这个边包含AST树的深度信息.
Nextuse: 连接变量节点和它下一次出现的节点,这个边可以提取AST中的数据流信息,增加图的特征信息熵.
为弥补AST只包含语法特征的缺点,除了上述的几种类型的边外,本方法还增加了几种类型的边去表示代码的控制流信息和不同程序员的循环编码习惯,为了实现编程语言的可扩展性,本文主要考虑主流编程语言中常见的几种控制流,包括顺序执行,While循环,For循环和If语句,具体细节如下.
If边:在AST中,一个If类型的节点有两个或三个子节点,第一个属性表示If的条件,第二个表示当条件成立的执行体,第三个表示条件不成立或Else的执行体.为此,本文添加了两种边,分别连接条件语句和条件成立和不成立的循环体.
While边:在AST中,While类型的节点有两个子节点,一个条件节点,一个循环体节点,本文添加一个While条件到循环主体的边,一个循环体到循环条件的边模拟循环执行过程.
For边:For节点具有两个子节点,For条件节点和For循环主体节点.与While节点类似,本文在For节点的两个子节点之间添加两种类型的边,分别连接条件节点和循环主题节点以及循环主体节点和条件节点.
顺序执行边:在Python中,语句的顺序执行存在于诸如方法主体或循环主体之类的代码块中.与前面提到的控制流节点不同,顺序执行的代码节点可以具有任意数量的子代.因此本文在每个语句子树的根与其下一个同级之间添加顺序执行边,表示代码的顺序执行关系.四种控制流边如图4所示.
2.4 图匹配神经网络
传统的图神经网络一般处理的都是图节点的分类[15],而图匹配网络是在图的级别上对不同的图进行处理.本文使用Li等[16]提出的两种图相似学习模型:一种是基于标准GNN的图嵌入模型,另一种是同时对两个图进行联合学习的图匹配网络模型来检测图神经网络在代码身份识别中的可行性.图嵌入模型包括三个部分:编码器,传播层和聚合层.编码器将节点和边特征映射到初始节点和边向量[17],传播层将一组节点映射到新的节点表示,聚合器将节点集作为输入,计算图级别的嵌入向量.本文选择GCN和GGNN两种图嵌入模型.图匹配神经网络(Graph Matching Networks,GMN)在编码器和聚合层都和图嵌入模型类似,最主要的区别在传播层.GMN可以在图信息传播中共同学习一对图的对应节点信息,即跨图更新特征向量. 图5说明了图嵌入模型和图匹配网络模型之间的区别.
2.5 孪生神经网络判别器
本文构建基于深度神经网络架构的身份判别器.分类任务中使用的传统DNN假定类的数量是固定的(本应用中即假定程序员数量是固定的),这极大地阻碍它扩展到识别新的程序员.本文使用孪生神经网络架构[18]构建身份判别器,它将两个特征向量(例如,匿名代码的特征和已知程序员的特征)作为输入,经过基础子网络生成新的一对特征向量,然后使用判别器计算两个向量的余弦距离得到一个相似度得分,通过比较该分值是否大于预设的阈值Threshold,判断匿名代码是否由该已知程序员编写.由于这种架构与数据集中的类数量不相关,因此可以很容易地将其扩展到新的程序员,孪生神经网络判别器的结构如图6所示,它由三个主要部分组成,两个基础网络和一个匹配器.两个相同的基础网络负责从输入特征向量中抽象出高层特征向量,匹配器负责计算两个高层特征向量的相似度得分. 本方法中两个基础子网络是具有四层隐藏层的DNN模型,匹配器由subtract层、全连接层和softmax层组成.
3 实验结果和分析
3.1 实验环境与数据
本文使用常用的Google Code Jam竞赛存档中的Python源代码作为评估的基准数据集.GCJ比赛内容包含一系列的算法问题,参赛者必须在指定时间内解决,参赛者允许使用任意自选的编程语言和开发环境来解答问题.因为GCJ这项比赛的参赛者几乎包含了所有国家和地区的不同教育水平的编程者,能够很好地模拟真实场景.本文爬取2008-2020年Google Code Jam已归档的所有数据集,筛选不是Python以及提交未通过的代码.最后根据程序员数量和每个程序员对应的代码数将数据集分为不同的子集,如表1所示.具体来说,D50表示共有50位程序员并且每个程序员对应的代码数大于30.随着程序员数量的增长,平均每个程序员拥有的代码数量也在减少,代码的作者身份识别也变得更困难.
本文用Pytorch和其扩展库PyTorch Geometric实现GCN、GMN和GGNN模型,批训练大小设置为64,训练轮数设置为30.图匹配网络层数设为4层,图池化嵌入向量维度为400,学习率为0.001,使用Adam优化器[19].对于孪生神经网络判别器,基础网络为具有4层隐藏层的DNN深度神经网络,每层的神经元为400,300,200和100,Dropout Rate设为0.2,激活函数使用Relu.本文分别使用AST、Javalang和Pycparser生成 Python、Java和C的数据增强抽象语法树.
3.2 实验结果
本文使用准确率作为评估指标,定义为正确分类的代码样本占总代码样本的比例,只使用准确率而不是其他评估指标(例如精度和召回率)是因为数据集中平衡了每个类的代码样本数量.将本文提出设计的方法与其他的源代码身份识别方法[9,10,20]进行比较,具体的实验结果如表2所示.
可以看到,本文的方法在准确率上优于现有的其他技术,例如,在100数量级的程序员身份识别中,本文的方法能够达到97.50%的准确率,比Caliskan-Islam、Hozhabrierdi和Ningfei Wang分别高出19.84%,12%和0.66%.另外,本方法适用于大规模程序员身份识别,在D1000样本集中也有突出的表现,在现有模型中识别准确率最高,达到了95.60%的准确率.本文提取的特征结合AST句法特征、语法特征和控制流特征,使用图神经网络学习和生成特征向量,通过图神经网络和注意力机制解决特征数过多的问题,防止过拟合,提高了身份識别的效率和准确率.
本文的方法很容易扩展到其他编程语言,为了验证本方法的可扩展性,我们又分别爬取Google Code Jam在2008-2020年的所有Java和C代码,按照相同的处理步骤对样本进行清洗,构建了包含Python,Java和C三种语言的数据集,每种编程语言都分为50,100,500和1000四种不同规模的数据集,每个数据集中每个作者的样本数都要多于8份源代码.本文统计了不同编程语言每份代码样本的平均代码行数,具体信息如表3所示.
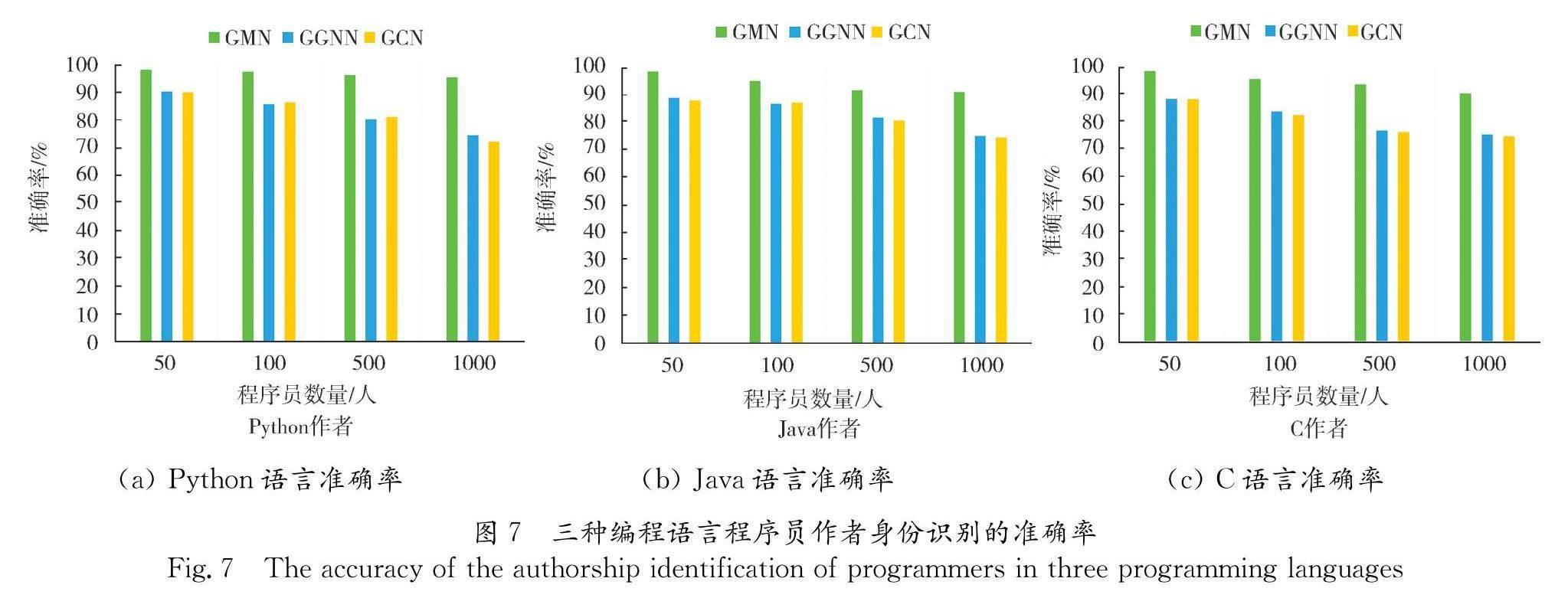
本文分别使用GCN、GGNN和GMN[21]三种图匹配神经网络对三种编程语言不同数据集进行实验.图7报告了在源代码作者身份识别过程中不同图匹配神经网络(GCN、GGNN和GMN)在不同语言和数据集的识别效果.在图7a中,本文的方法对50名Python程序员的作者身份识别实现了98.2%的准确率.随着将实验扩展到更多程序员,
准确率仍然很高,1000名程序员的准确率达到95.6%.给定相同的实验配置,Java编程语言获得了类似的结果,如图7b所示,当程序员人数为50名程序员时,作者身份识别准确率达到98.16%,在将实验扩展到更多程序员后,本文对500名程序员实现了91.30%的准确率,对1000名程序员实现了90.6%的准确率.最后,对于C程序员,图7c显示,50名程序员的作者身份识别准确率达到98.37%,100名程序员的准确率达到95.56%,总共500名程序员的准确率达到93.2%,1000名程序员的准确率达到90.2%.这些结果表明,图匹配神经网络能够学习代码作者特征的深度表示,另外无论使用何种编程语言,都能够实现大规模的作者身份识别.从图7中还可以明显地看到使用GMN网络的准确率始终比GGNN和GCN高,而且程序员规模越大越明显,这是因为GMN在传播过程中会联合学习两张图之间的信息,使用注意力机制来更新图节点和图边的权重,通过增加时间和内存开销增强特征学习能力.
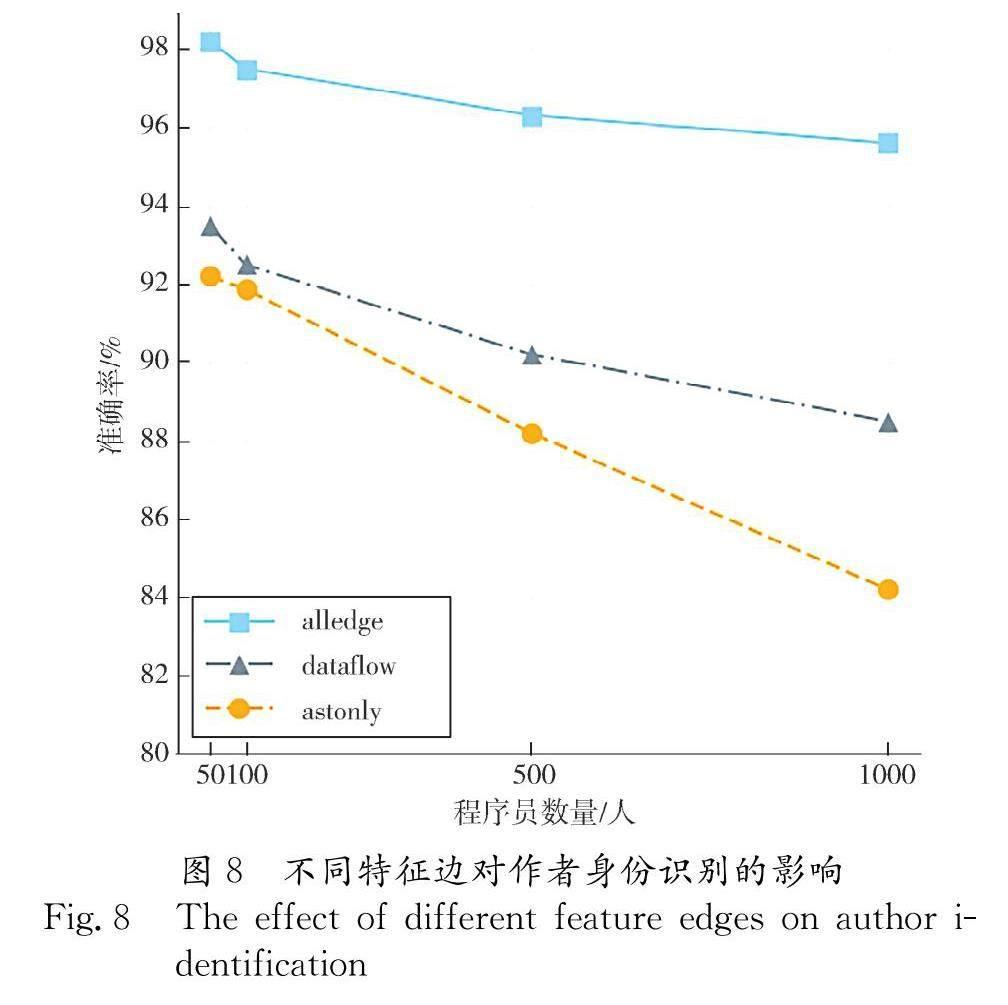
本文探究了基于数据增强抽象语法树构建特征图时不同边对作者身份识别的影响.实验选取的数据集是Python编程语言的GCJ数据集,分别为包含50,100,500和1000位程序员四种不同规模.特征图构建方法分别采用只使用AST基本边,AST基本边添加数据流边,AST基本边添加数据流和控制流边(即包含所有类型的边),实验的结果如图8所示.
从图8中可以看到,只使用AST基本边构建特征图的方法(astonly)在Python数据集的识别准确率最低,在1000位程序员数据级中只有84.2%的准确率,在AST基础边上添加数据流边(dataflow)的识别准确率在1000位程序员数据级中可以达到88.5%的准确率,包含了所有类型的边的构建特征图的方法(alledge)准确率最高,在1000位程序员数据级中可以到达95.6%的准确率.这是因为随着包含的特征边类型的增加,弥补了数据增强AST只包含语法特征的缺点,增加了程序员特征提取的数量.
除了GCJ数据集,本文还选取GitHub数据集测试本方法的识别准确率.收集的GitHub数据集包含GitHub-Java和GitHub-C,GitHub-Java由40位作者的2827个Java程序文件组成,每个程序文件平均有76行代码.GitHub-C数据集通过爬取在2020年11月到12月之间做出贡献的作者的C程序,本文通过删除注释来预处理这些C文件,然后消除了由于功能有限而少于30行代码的文件,生成的数据集包含67个作者的2072个C文件,每个文件平均有88行代码.使用GMN网络进行实验的结果如图9所示.
图9显示了GitHub数据集中60名C程序员使用本方法进行识别时的96%准确率和40名Java程序员使用本方法进行识别时96.3%的准确率.这个结果表明本文的方法在处理真实世界的数据集时仍然有效.与GCJ数据集相比,结果显示出一些识别准确率的下降.这种下降是因为GitHub存储库的贡献者可以从其他来源复制代码段甚至代码文件;这种基本事实问题会影响作者身份识别过程的结果,这也说明本文使用的数据集的真实性.
最后,本文探究了代码混淆对本方法的影响.本文使用的Stunnix混淆工具是一种流行的C/C++混淆器,它在保留其功能和结构的同时进行复杂的字符串替换.本实验针对100位作者的C数据集,其中源代码文件使用Stunnix工具进行混淆,然后进行模型的学习判断,实验结果如表4所示.
本文的方法能够在100个作者的整个Stunnix混淆数据集上达到94.96%的准确率,实验结果表明本文的方法是健壮的并且可以抵抗一定的现成的混淆器.
4 结 论
本文提出一种基于抽象语法树和图神经网络的程序员指纹身份识别方法.首先,将图匹配神经网络引入到源代码身份识别中,为了将代码转换为图结构,本文提出数据增强AST并设计一种基于AST的构建代码特征图的方式,它充分利用程序的控制流信息和数据流信息,通过添加不同种类的边生成程序员的身份特征指纹;然后,通过图匹配网络学习和提取程序员的低维特征向量;最后,使用孪生神经网络对源代码作者身份进行识别.本文在Google Code Jam和GitHub数据集上评估了本文的方法,实验结果表明本文的方法在准确率、编程语言扩展性和大规模的程序员集合方面都胜过以往的方法,提高了源代码作者身份识别的准确率和鲁棒性.
本文的评估方法中,默认代码都是由一位程序员作者编写而成的,但是在实际的编码环境中,编程代码要复杂很多,通常由许多任务和多个程序员作者共同完成,本文设计的模型没有考虑源代码由多个程序员共同编写的情况.这是我们未来可以继续研究的方向.
参考文献:
[1]Burrows S, Tahaghoghi S M M, Zobel J. Efficient plagiarism detection for large code repositories [J]. Software Pract Exper, 2007, 37: 151.
[2]Wilcox L J. Authorship: the coin of the realm, the source of complaints [J]. JAMA, 1998, 280: 216.
[3]Frantzeskou G, Stamatatos E, Gritzalis S, et al. Identifying authorship by byte-level n-grams: The source code author profile (scap)method [J]. Int J Digit Evidence, 2007, 6: 1.
[4]Malin C H, Casey E, Aquilina J M. Malware forensics: investigating and analyzing maliciouscode [M]. [S.l.]: Syngress, 2008.
[5]Kalgutkar V, Kaur R, Gonzalez H, et al. Code authorship attribution: methods and challenges[J]. ACM Comput Surv, 2019, 52: 1.
[6]Krsul I, Spafford E H. Authorship analysis: identifying the author of a program [J]. Comput Secur, 1997, 16: 233.
[7]Frantzeskou G, Stamatatos E, Gritzalis S, et al. Effective identification of source code authors using byte-level information [C]//Proceedings of the 28th International Conference on Software Engineering. Shanghai: IEEE Computer Society, 2006.
[8]Lange R C, Mancoridis S. Using code metric histograms and genetic algorithms to perform author identification for software forensics [C]//Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation. London:ACM, 2007: 2082.
[9]Caliskan-Islam A, Harang R, Liu A, et al. De-anonymizing programmers via code stylo-metry[C]// Proceedings of the 24th USENIX Security Symposium. Washington: Usenix Association, 2015: 255.
[10]Wang N, Ji S, Wang T. Integration of static and dynamic code stylometry analysis for programmer de-anonymization[C]//Proceedings of the 11th ACM Workshop on Artificial Intelligence and Security. Toronto: Springer Verlag, 2018: 74.
[11]Bogomolov E, Kovalenko V, Rebryk Y, et al. Authorship attribution of source code: A language-agnostic approach and applicability in software engineering[C]//Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. [S.l.]: ELECTR NETWORK Association for Computing Machinery, Inc, 2021.
[12]Alsulami B, Dauber E, Harang R, et al. Source code authorship attribution using long short-term memory based networks [C]//European Symposium on Research in Computer Security. Oslo: Springer, Cham, 2017: 65.
[13]Abuhamad M, Rhim J, AbuHmed T, et al. Code authorship identification using convolutional neural networks[J]. Future Gener Comp Sy, 2019, 95: 104.
[14]Guo D, Zhou A, Liu L, et al. A method of source code authorship attribution based on graph neural network [C]//Proceedings of 2021 Chinese Intelligent Automation Conference. Zhanjiang: Springer, 2022.
[15]Gori M, Monfardini G, Scarselli F. A new model for learning in graph domains[C]//Proceedings. 2005 IEEE International Joint Conference on Neural Networks. New York: IEEE, 2005.
[16]Li Y, Gu C, Dullien T, et al. Graph matching networks for learning the similarity of graph structured objects[C]//International Conference on Machine Learning. Long Beach:International Machine Learning Society, 2019.
[17]Cho K, Van Merri?nboer B, Bahdanau D, et al. On the properties of neural machine translation: encoder-decoder approaches[C]// Proceedings of SSST 2014 - 8th Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar: ACL, 2014: 103.
[18]Chopra S, Hadsell R, Yann L C. Learning a similarity metric discriminatively, with application to face verification[C]// Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05). San Diego: IEEE, 2005: 539.
[19]Kingma D P, Ba J. Adam: a method for stochastic optimization [C]// Proceedings of the 3rd International Conference on Learning Representations. San Diego, United states: ICLR, 2015.
[20]Hozhabrierdi P, Hitos D F, Mohan C K. Python source code de-anonymization using nested bigrams[C]//IEEE International Conference on Data Mining Workshops (ICDMW).Singapore: IEEE, 2018: 23.
[21]Li Y, Tarlow D, Brockschmidt M,et al. Gated graph sequence neural networks[C]// Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico:ICLR, 2016.
引用本文格式:
中 文: 郭迪骁,周安民,刘亮,等. 基于抽象语法树和图匹配网络的代码作者身份识别[J]. 四川大学学报: 自然科学版, 2023, 60: 063001.
英 文: Guo D X,Zhou A M,Liu L,et al. Code authorship attribution based on abstract syntax tree and graph neural network [J]. J Sichuan Univ: Nat Sci Ed, 2023, 60: 063001.
