基于深度学习特征点的单目视觉SLAM
2023-03-29田祥瑞周佳蒙吴旭琴
徐 鹏,田祥瑞,2,周佳蒙,吴旭琴,2
(1. 南京航空航天大学,江苏 南京 210016;2. 通信网信息传输与分发技术重点实验室,河北 石家庄 050081)
1 引言
同步定位与地图构建(Simultaneous Localization and Mapping,SLAM)是指移动机器人在未知环境中,依靠自身的传感器获得感知信息,递增的创建一个与周围环境相一致的地图,同时利用创建的地图实现自主定位[1-2]。SLAM的实现途径根据使用的传感器,主要分为声呐SLAM、激光SLAM和视觉SLAM(VSLAM),相较激光雷达,相机具有信息量大、灵活性高、成本低等优点[3]。视觉SLAM一般由前端(视觉里程计)、后端优化、回环检测和建图四个模块组成[4],如图1所示。视觉图像中点特征的提取与匹配是实现SLAM的基础,传统的角点提取方法包括Harris[5]、FAST[6]、Shi-Tomasi[7]等,但Harris检测出的角点会出现信息丢失、位置偏移、聚簇等情况,FAST算法检测得到的角点数量多且不确定、存在尺度问题、不具有方向信息。为了提高算法的鲁棒性,特征点提取算法在角点检测算法的基础上又进行了改进,如SIFT[8],SURF[9],ORB[10]等。特征点由关键点和描述子组成,关键点是指特征点在图像中的位置,描述子则描述了关键点周围的信息,如关键点周围像素值在多个方向上的梯度信息。

图1 视觉SLAM框架图
传统特征点提取方法较适应于光照变化小、静态、刚体且没有人为干扰的场景[11],主要原因之一是人工设计的稀疏图像特征有很多的局限性,难以最优地表达图像深层次信息。因此,研究者提出了用深度学习提高SLAM算法鲁棒性的方法[12],深度学习模拟人脑的逻辑分析,将浅层的特征信息组合成更抽象的高层特征,与传统图像算法相比,可以获取更深层次的图像信息[13]。深度学习与传统SLAM融合的一般方式是采用神经网络代替传统SLAM中的一个或多个模块,如Yifan Xia等人将深度学习模型PCANet(principal Component Analysis Net)提取的图像特征用于回环检测[14],何元烈等人结合批规范化、深度残差和级联修正线性单元模块设计了一种快速、精简的卷积神经网络模型(Fast and Lightweight Convolutional Neural Network,FLCNN)[15],Yann LeCun等人利用卷积神经网络学习小图像块之间的相似性,解决了传统方法中双目立体匹配运算速度慢、匹配精度低的问题[16],Ronald Clark和Sen Wang等人提出了一种基于端到端训练的VINeT网络模型[17]。在特征提取方面Daniel DeTone、Tomasz Malisiewicz等人做出了卓越的贡献,2016年他们设计了卷积神经网络HomographyNet来直接估计图像之间的单应性,与基于ORB特征点的传统单应性估计算法进行对比,证明了深度学习方法的灵活性和适用场景的广泛性[18]。2018年,Daniel等在MagicPoint[19]的基础上提出了SuperPoint,SuperPoint是一个在编码器部分共享参数,在解码器部分分别计算关键点和描述子的深度学习算法,且更适应光照变化条件下的图像匹配[20]。
本文首先分析了基于SuperPoint网络的深度学习特征点提取算法,实现了SuperPoint网络的自监督训练,然后设计了深度学习特征点与传统视觉SLAM相融合的方法,最后进行了实验对比分析。
2 基于SuperPoint的特征点提取算法
SuperPoint是基于自监督训练的特征点检测和描述子提取方法,SuperPoint由一个编码器和两个解码器组成,如图2所示。
SuperPoint在编码器中采用了类似于VGG的结构,实现了关键点和描述子的参数共享,从而减少了计算量,这与传统特征点首先检测关键点然后计算描述子的方式不同。检测关键点的解码器输入为W/8×H/8×128的张量信息,一个像素点对应原始图像中不重叠的8×8区域大小的像素信息,通过Softmax函数将关键点提取问题转换为分类问题,判断每个8×8像素大小的区域中是否有关键点,并找到关键点的位置。然后将图像大小由W/8×H/8变为W×H,同时通道数从64变成1,即可在输入图像中找到对应的关键点。计算描述子的解码器输入为W/8×H/8×128,经过两个256通道的卷积层,然后用双三次差值把W/8×H/8×256变成W×H×256,最后通过L2范数归一化即可得到描述子。
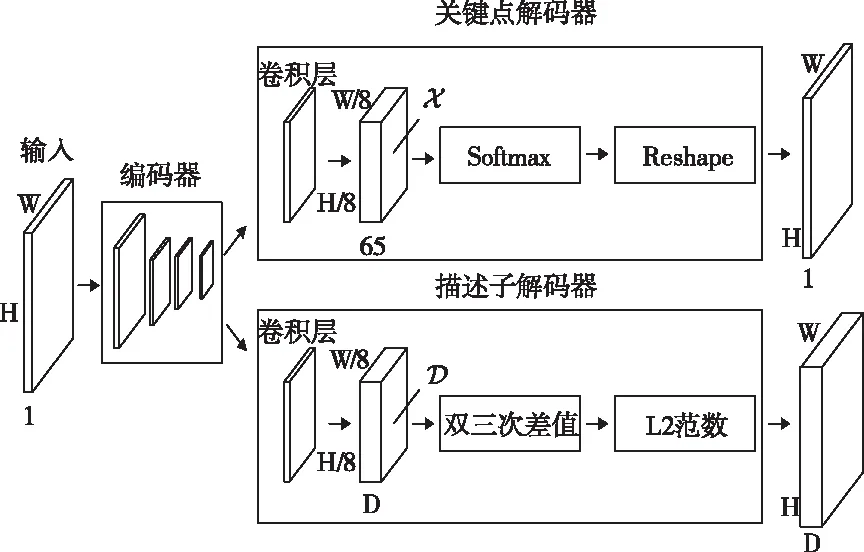
图2 SuperPoint网络结构图

图3 SuperPoint的训练过程
由于难以在图像上准确地标注出所有的特征点,因此SuperPoint算法使用了自监督的方式训练神经网络。训练过程如图3所示。首先,用合成数据集Synthetic Shapes训练MagicPoint,Synthetic Shapes是由代码合成的具有角点的简单几何形状,如直线、多边形、立方体,星形等。然后用训练好的MagicPoint去标注COCO数据集,从而得到一个标注好关键点的数据集训练SuperPoint。训练过程采用了Homographic Adaptation方法,该方法可以提高算法在实际图像上的泛化能力。
3 深度学习特征点与传统SALM的融合
视觉里程计和回环检测都涉及到图像信息的处理,可以与深度学习相融合,从而提高算法的鲁棒性和准确性。SuperPoint可以同时提取到关键点并生成描述子,将关键点应用于光流法视觉里程计,将描述子构建词袋模型后应用于回环检测,完成基于深度学习特性点的SLAM。
3.1 基于深度学习特征点的光流法视觉里程计
融合深度学习特征点的视觉里程计算法流程如图4所示,首先对图像做初处理,使其能够输入到SuperPoint网络得到特征点信息。由于描述子是256维的float32型的浮点数,用描述子进行特征点匹配时计算量大,所以提取出特征点概率最高的前1000个关键点,采用金字塔LK光流法[21]跟踪灰度图上的关键点。为减少误匹配,在光流法中加入了RANSAC算法,用匹配的关键点解算本质矩阵E,进而求解相机的位姿,若求解成功,则将位姿加入轨迹图,否则跟踪失败。图中红色框为基于深度学习的特征点提取部分,该部分在后文中以接口程序代替。
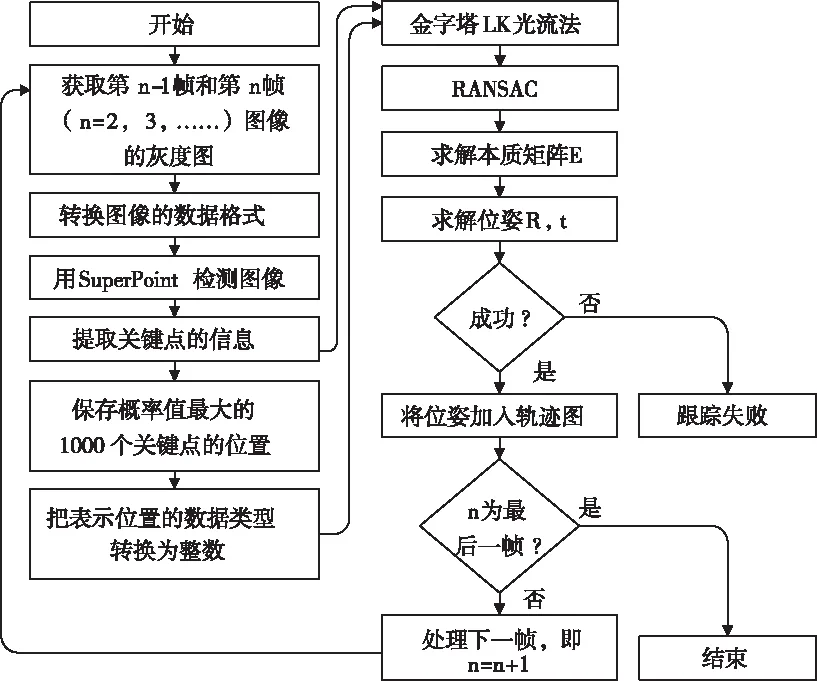
图4 视觉里程计流程图
3.2 词袋模型的建立与回环检测
SuperPoint与传统算法输出的描述子相似,也可用于构建词袋模型。词袋模型通过确定一幅图像中出现了哪些在字典中定义的单词来描述整幅图像,从而将一幅图像中的所有描述子转化成一个向量,避免了直接比较描述子[20],且向量表示的是特征的有无,与物体的空间位置和排列顺序无关,可以增强算法鲁棒性。
基于深度学习描述子的词袋模型构建方法如图5所示,K为聚类数量,L为词袋模型层数。将特征点提取过程中得到的描述子放在一个列表中进行聚类,构建可以容纳KL个单词的词袋模型。
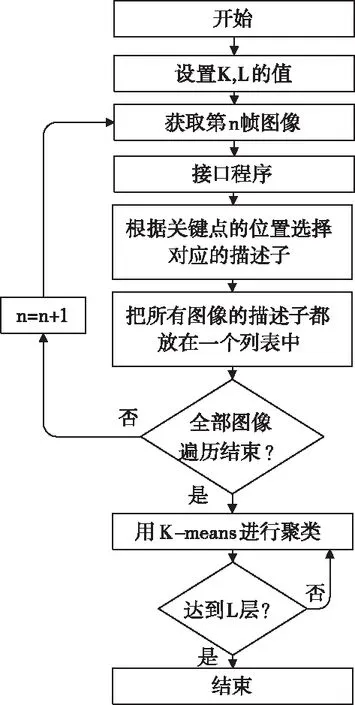
图5 词袋模型的构建方法
词袋模型构建以后,将测试图片的所有描述子与词袋模型中的节点进行对比,从而把每张图片中的描述子信息转换成对应的向量,即图像M可以得到对应的向量m,图像N可以得到对应的向量n。然后计算两个向量之间的余弦相似度,如式(1),若得到的相似度大于设定的阈值,则判断为回环,否则认定没有形成回环。
(1)
3.3 基于SuperPoint的SLAM
视觉里程计在估计相机的位姿时,只考虑相邻图像之间的关联,因此会导致累积误差,SLAM引入回环检测模块能提供时间间隔较远的一些约束,可以提高SLAM系统在长时间下定位和建图的准确性。SuperPoint在计算特征点时同时得到关键点和描述子,将其分别应用于视觉里程计和回环检测,算法流程如图6所示,通过接口程序完成基于SuperPoint的特征点提取,将关键点输出给金字塔LK光流法完成位姿求解,将描述子输出给词袋模型转化为向量,根据余弦相似度完成回环检测,若是回环,则将位姿的数值设定为初次到达该位置时的位姿,并将位姿加入轨迹图,从而消除视觉里程计的累计误差。
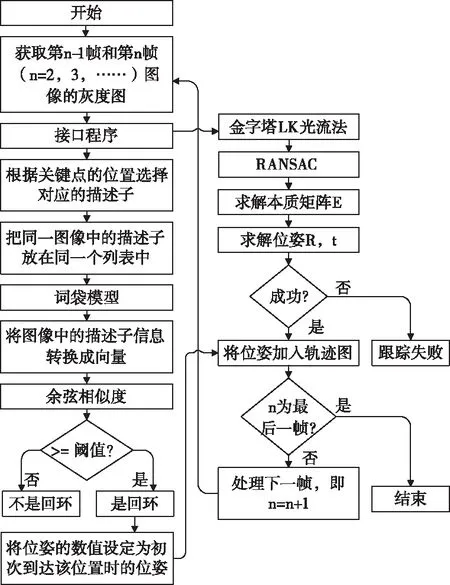
图6 基于光流法的SLAM系统设计
4 实验
为了验证所提方法的有效性,在公开数据集和光照变化数据上进行了对比分析。实验采用的电脑配置为Inter Core i7-8700CPU,NVIDIA GeForce GT 1080,系统版本Ubuntu16.04,深度学习框架采用TensorFlow1.6。实验比较了基于FAST、Harris、Shi-Tomasi和SuperPoint的视觉里程计算法在KITTI数据集中的性能,其中尺度信息通过融合KITTI数据集的真实位姿信息得到。在开源数据集New College和City Centre中比较了采用ORB、SIFT和SuperPoint的回环检测算法。为进一步比较所提算法在光照变化情况下的性能,将其与ORB_SLAM2做了对比试验。
4.1 视觉里程计实验
FAST算法设置的阈值为50,窗口大小为21×21,采用的类型是FAST_FEATURE_DETECTOR_TYPE_9_16,Harris算法与Shi-Tomasi算法设置的角点数量为500,可接受的最小特征值为0.01,角点之间的最小距离为10,窗口大小为21×21,计算导数自相关矩阵时的邻域范围是4,SuperPoint的窗口大小是11×11。选用KITTI数据集中包含真值的图像序列00至10共11组数据进行对比试验。
图7为其中两组数据的轨迹示意图,(a)和(b)分别是01序列和05序列在xz平面内的轨迹图,从轨迹图上可以直观地发现采用SuperPoint的视觉里程计优于采用传统方法的视觉里程计。
采用绝对轨迹误差(absolute trajectory error,ATE)进行定量评估,计算如式(2)所示,在用时间戳对齐估计位姿和真实位姿之后,绝对轨迹误差直接计算在时间戳i上估计的位姿Pest,i和真实的位姿Pref,i之间的差值,然后用式(3)计算绝对轨迹误差[21]。

图7 不同视觉里程计算法得到的轨迹图

(2)

(3)
表1展示了KITTI数据集中图像序列00至10数据集采用不同算法得到的绝对轨迹误差。从表中可以看出,SuperPoint-VO的平均绝对轨迹误差比FAST-VO减少了27.5%,比Harris-VO减少了32.8%、比Shi-Tomasi-VO减少了24.0%。

表1 视觉里程计在KITTI数据集上的绝对轨迹误差
4.2 回环检测
在New College和 City Centre数据集进行回环检测实验,该数据集由牛津大学移动机器人团队构建,分别有1073对图像和1273对图像,每对图像由左右两侧的相机分别采集,实验中将数据集对应分为奇数组和偶数组。分别采用ORB、SIFT、SuperPoint算法计算得到相似矩阵,并采用热图形式表示,颜色越浅,图像的相似度就越高。如图8所示。从图中可以直观地看出,采用SuperPoint的回环检测能在New College和 City Centre中有真实回环的地方检测出较高的图像相似度,且与没有形成回环的图像相似度相差较大。

图8 各算法结果对比图
为进一步评估各方法,在City Centre数据集上设计了对比实验,图9展示了各个算法在不同阈值下的PR值,当召回率较小时,每个算法的准确率都为1,且随着召回率的增大而减小。
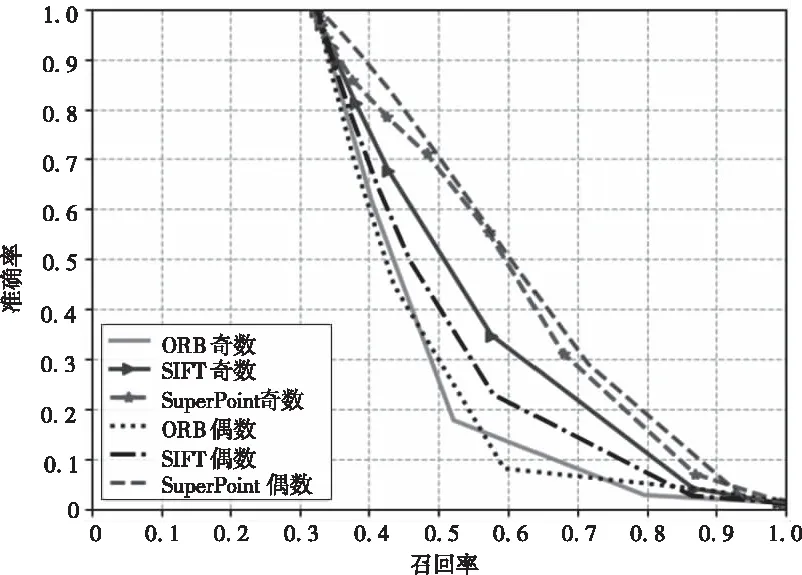
图9 各算法在City Centre上的PR图
选取召回率为0.5时对比各方法的准确率,如表2所示,此时采用SuperPoint的回环检测准确率比采用SIFT、ORB的回环检测提高了23%、41%。
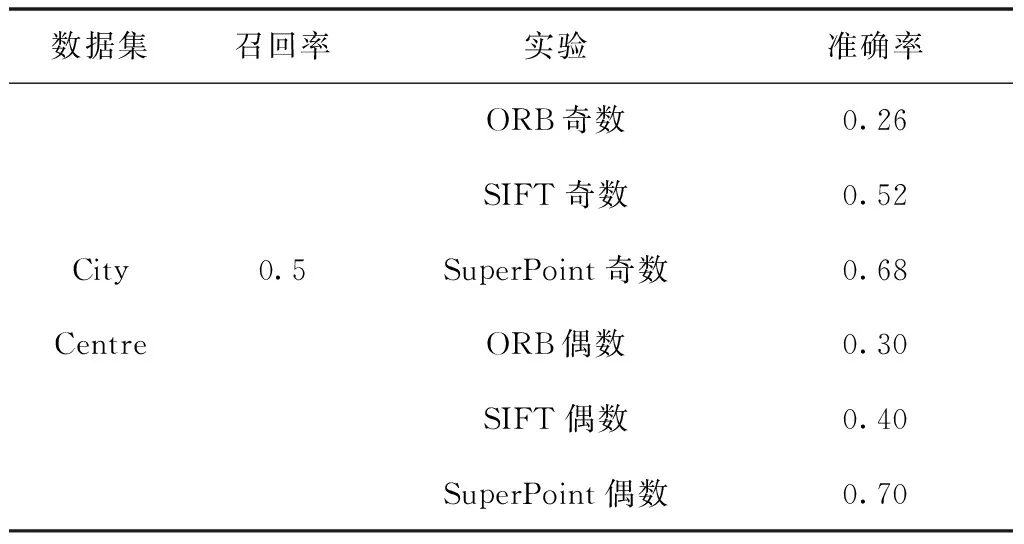
表2 召回率相同时各算法对应准确率
4.3 基于深度学习特征点的SLAM实验
为验证融合视觉里程计和回环检测的SLAM系统的效果,选取KITTI数据04和06序列进行实验。表3对比了选取04序列数据集在有无回环检测时的绝对轨迹误差、相对位移误差和相对旋转误差。通过比较可以看出,加入回环检测之后,绝对轨迹误差减少了5.1%,相对旋转误差减少了1.0%,相对位移误差减少了12.8%。

表3 有无回环检测的比较结果
图10分别展示了06序列数据集在有无回环情况下的轨迹图,图中灰色虚线代表真实轨迹,从真实轨迹可以看出在右上角形成了回环(红色框内),加入回环检测的视觉里程计的轨迹更接近真实轨迹。
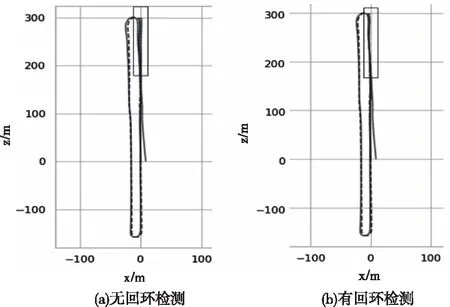
图10 06序列数据集的SLAM轨迹图
4.3 光照变化下的SLAM实验
为了比较在光照变化条件下的算法性能,本文搭建了基于大疆M210 RTK V2的物理实验平台,相机采用大疆Z30,帧频为30FPS。在白天和黑夜不同光照条件下分别使用大疆航点飞行模式设定飞行任务,采集图像数据,实验平台、场景如图11所示。

图11 实验平台与实验场景
实验不考虑真实尺度,结果如图12所示,在白天强光照下,ORB_SLAM2和SuperPoint_SLAM都能得到预期实验结果,在黑夜弱光下,ORB_SLAM已无法提取到足够特征点完成初始化,而SuperPoint_SLAM依然可以正常完成轨迹解算。由此表明,基于SuperPoint的SLAM相比于传统ORB_SLAM2更适应光照的变化。

图12 光照变化下对比实验
5 结论
本文分析了基于深度学习的特征点提取算法,将其与视觉里程计融合,采用KITTI数据集,其绝对轨迹误差与传统方法FAST-VO、Harris-VO、Shi-Tomasi-VO相比分别减少了27.5%、32.8%和24.0%。在数据集New College和City Centre上,采用基于深度学习特征点的回环检测算法准确率比基于SIFT、ORB的回环检测提高了23%、41%。将基于深度学习特征点的回环检测和视觉里程计相融合,加入回环检测后的SLAM绝对轨迹误差减少了5.1%、相对旋转误差减少了1.0%,相对位移误差减少了12.8%。在光照变化的情况下SuperPoint_SLAM优于ORB_SLAM2。深度学习特征点能够表达更深层次的图像信息,融合深度学习特征点的SLAM具有更高的精度与鲁棒性。
