基于RCNN-ABiLSTM的机械设备剩余寿命预测方法
2023-03-09闫啸家梁伟阁田福庆
闫啸家, 梁伟阁,*, 张 钢, 佘 博, 田福庆
(1. 海军工程大学兵器工程学院, 湖北 武汉 430033; 2. 大连舰艇学院导弹与舰炮系, 辽宁 大连 116016)
0 引 言
对机械设备进行预测和健康管理(prognostics and health management, PHM)有利于提高其安全性,防止灾难性事故发生[1]。而剩余寿命(remaining useful life, RUL)的准确预测是PHM研究领域中的关键任务[2],可以为设备维修建立最佳维护策略提供决策支持[3]。
RUL预测可以动态感知机械设备健康状态的未来变化,目前较为流行的有模型驱动的预测方法、数据驱动的预测方法和混合驱动的预测方法三类[4]。模型驱动和混合驱动的预测方法需要通过已知的力学原理和机械原理建立明确的数学模型,进而分析设备的性能退化过程[5]。然而大型机械设备的结构复杂,使用环境和故障模式多样,建立精确的性能退化模型代价过高,应用范围受到极大限制。而数据驱动的预测方法仅通过对设备运行过程中的监测数据进行性能特征挖掘,从而展现内外部环境所导致设备性能的劣化,该方法规避了机械设备复杂机理的数学建模,逐步成为RUL预测的研究热点。
数据驱动的预测方法主要分为统计分析和机器学习两类方法[6]。统计分析方法通过对设备失效时间数据进行统计分析,利用参数估计构造RUL的分布函数,然后通过分布拟合随机变量的关系实现RUL预测[7]。黄亮等[8]通过融合机械设备的历史退化数据和实时监测数据,建立了多阶段Wiener过程性能退化模型,从而实现发动机RUL的预测。袁庆洋等[9]利用电机温度作为退化特征,建立了多段Wiener过程模型以预测电机RUL。冯磊等[10]提出了半随机滤波-期望最大化算法,成功解决了隐含退化过程的RUL在线预测问题。Kundu等[11]综合考虑了模型参数估计过程中设备的工作参数和监测信号,从而建立威布尔加速损伤回归模型来描述不同工作状态下设备的故障特征。Zhang等[12]利用设备融合监测信息建立了基于Gamma退化过程的RUL预测模型。王泽洲等[13]在传统Wiener退化模型中引入扩散系数与漂移系数的比例关系,从而实现漂移系数和扩散系数的同步更新。Wu等[14]基于随机系数Wiener过程对复杂机械设备的RUL进行预测,具有更高的预测精度和更低的预测不确定性。然而,随着智能传感器的发展,通常使用多种组网传感器收集多源数据来全面反映设备运行状态,统计分析方法难以从信号差异大、采样策略多和数据价值低的大数据中提取退化特征信息,同时基于耦合多维变量的RUL分布求解难题仍未解决。以深度学习为代表的机器学习可以对原始监测数据进行特征提取和训练,不必构建具体的退化模型便可模拟性能退化过程,同时深度学习方法克服了浅层机器学习方法[15]难以提取深度特征的缺陷,通过对多传感器性能参数组成的多维数据进行深度特征提取,充分利用学习时间序列蕴含的信息对RUL进行更为精确的预测。
深度循环神经网络(recurrent neural network, RNN)适用于处理时间序列,从中挖掘反映设备性能退化的潜在特征,而其衍生模型长短期记忆(long short term memory,LSTM)网络可以解决RNN模型无法学习长时间特征关系及梯度消失等问题[16],对于解决设备的RUL预测问题具有明显优势。Zheng等[17]通过多层LSTM堆叠以构建深层LSTM结构,提高了RUL预测精度。王鑫等[18]通过多层网格参数搜索,对LSTM预测模型优选参数,并利用飞机故障试验对方法的有效性和实用性进行了验证。Sheng等[19]构建了可以挖掘不同退化状态信息的多尺度LSTM,具有更好的预测性能。宋亚等[20]提出自编码器与双向LSTM(bidirectional LSTM, BiLSTM)网络融合模型,对于高维海量状态监测数据的处理获得了较好的效果。孙世岩等[21]使用扩增后的数据训练BiLSTM网络,解决了训练样本数量不足的问题,同时准确描述了轴承的退化趋势。Chen等[22]利用卷积神经网络(convolutional neural network, CNN)提取监测数据的空间特征,从而对设备的RUL进行准确的预测。尽管LSTM在处理时序性数据时表现出良好的效果,但面对长时间序列时难以捕捉关键退化信息,从而导致性能退化时间点的识别准确率较低。
为了解决上述问题,本文提出一种基于残差CNN和注意力BiLSTM网络(residual CNN-attentional BiLSTM network, RCNN-ABiLSTM)的RUL预测模型。首先,利用CNN从多维传感器信号中提取深度特征向量,同时利用残差网络结构有效解决深层CNN带来的梯度消失问题;其次,针对传感器数据的前后序列相关性,利用BiLSTM学习CNN所提空间特征的退化信息,捕获时间序列中长距离相关特征,并借助注意力机制计算时间特征的重要性程度,加强关键时间特征对RUL预测的表达,从而有效提高模型RUL预测准确度。
1 模型理论
1.1 RCNN
传统CNN的结构如图1所示,主要由卷积层、池化层和全连接层组成[23]。卷积层能够提取输入数据的特征,池化层对卷积层所提特征按照特定规则进行选择和过滤,而全连接层一般与输出层进行连接,相当于传统前馈神经网络的隐藏层,实现最后的输出维度变换。模型可以从多维样本中自适应提取空间特征,易于实现样本重构和特征提取,可以有效获取性能退化信息[24]。
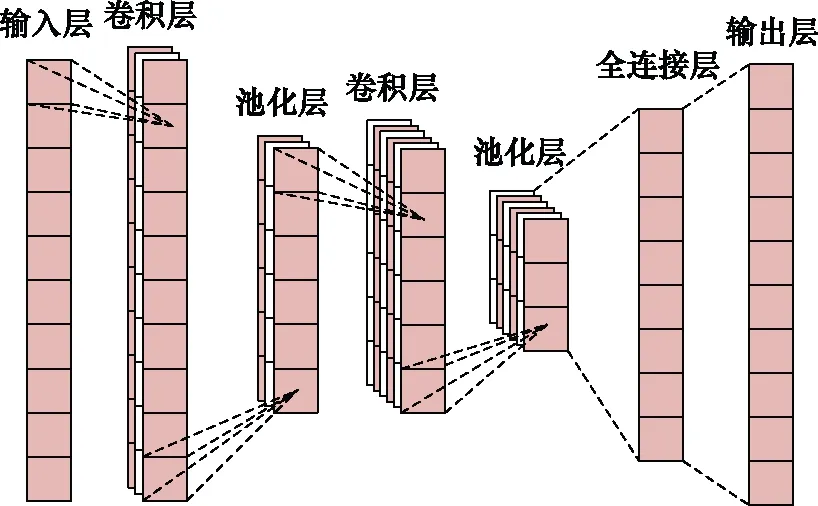
图1 CNN结构Fig.1 Structure of CNN
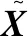
(1)
式中:W1、W2和W3分别为单向残差模块3个卷积层的权重矩阵;f(·)表示批归一化(batch normalization, BN)操作和ReLU激活函数的函数映射;⊗为卷积运算。则单个模块的非线性映射函数为
(2)
对式(2)求偏导,可得
(3)
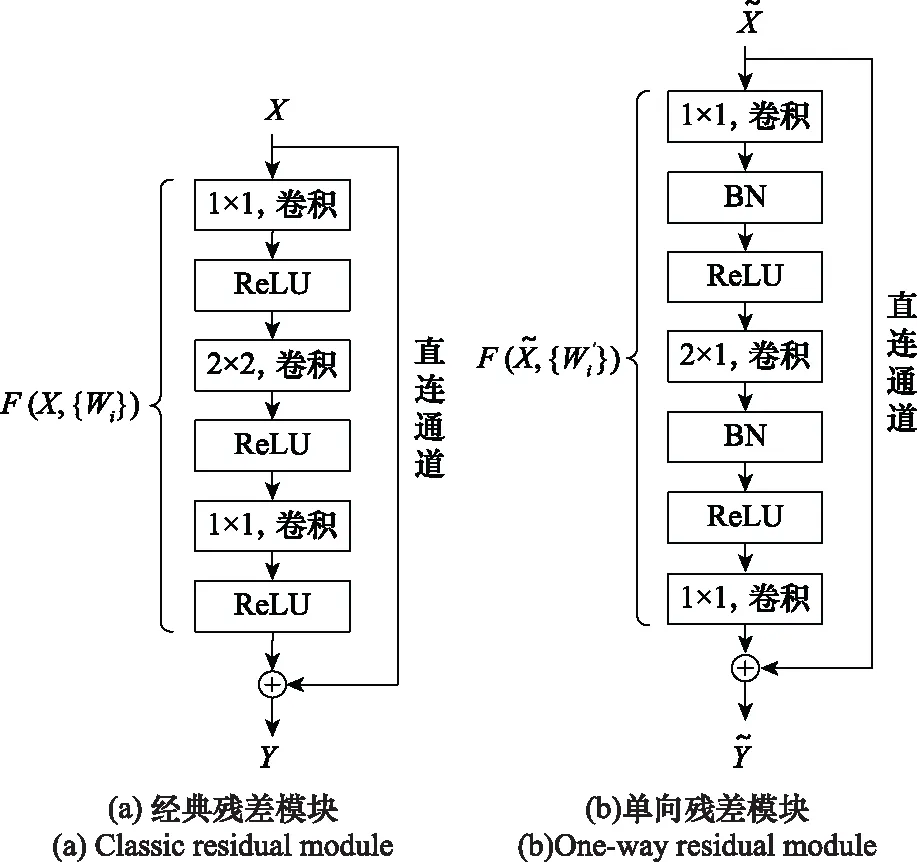
图2 ResNet模块Fig.2 ResNet module
由式(3)可知,通过构建输入到输出的直连通道可以有效解决梯度消失的问题。对比图2(a)和图2(b),根据全寿命周期数据集特点,单向残差模块将经典残差模块第2个卷积层的卷积核尺寸由2×2替换为2×1。同时,实际卷积过程实现了卷积核的单向移动,不会对时间序列的前后相关性进行破坏,即对机械设备传感器数据的单一时间序列进行信息融合,不改变数据的时序关系,进而提取与RUL相关联的特征。
1.2 BiLSTM网络
RUL预测的主要途径是从机械设备传感器数据中学习与设备性能退化的时空信息,而RNN可以充分利用数据的时间相关特性对时域序列数据进行处理,然而当单一时序数据的长度很大或时间很短时,RNN会存在梯度消失、梯度爆炸等问题[27]。
LSTM引入记忆细胞概念,由输入门、遗忘门、选择门和输出门4个相互连接的结构组成,通过比较记忆信息和当前信息,选择重要信息,遗忘次要信息,使网络获得更强的记忆能力,能够缓解长序列RNN训练过程中梯度消失与爆炸的问题,其网络拓扑结构如图3所示。
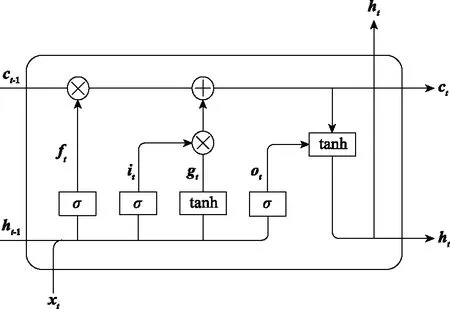
图3 LSTM网络结构图Fig.3 LSTM network structure diagram
其中,ht-1、ht分别为t-1时刻和t时刻的隐藏状态;ct-1、ct分别为t-1时刻和t时刻的门控单元状态;xt为t时刻的输入。遗忘门ft负责对上一节点输入的信息进行选择性遗弃;输入门it将记忆信息与当前信息进行融合,输入至选择门gt中;选择门gt对融合信息进行选择性记忆;输出门ot决定当前门控单元状态对隐层输出的影响。当前门控单元状态ct受上一时刻门控单元状态、遗忘门、输入门和选择门共同影响,而记忆单元的输出由输出门ot和门控单元状态ct共同决定,具体计算过程如下所示:
(4)
式中:Wf和bf、Wi和bi、Wg和bg以及Wo和bo分别为遗忘门、输入门、选择门和输出门的权重和偏置矩阵;σ(·)为Sigmoid激活函数,将输出变换到[0,1]区间内;tanh(·)为双曲正切激活函数,将输出变换到[-1,1]区间内。
记忆单元或称门控单元是LSTM网络的核心,通过若干记忆单元构成前向传播链式结构[16],可以实现信息的统筹和传递。由式(4)可知,记忆单元可以对信息流进行精准的控制,通过整合所有时刻内部状态信息和输入信息,保证模型训练过程中梯度下降的稳定性。为了加深对原始时间序列特征提取的层次,进一步提高模型输出的准确性,将两个方向不同的独立的LSTM叠加在一起构成BiLSTM网络,具体结构如图4所示。

图4 BiLSTM网络结构图Fig.4 BiLSTM network structure diagram
将xt输入至前向层,从0时刻到t时刻正向计算出向前隐含层的输出hf;输入至反向层,从t时刻到0时刻反向计算出向后隐含层的输出hb。最后,将前向层和反向层的输出结果输入至全连接层,得到最终输出h:
h=f(hf,hb)
(5)
式中:f(·)是全连接层的映射函数。
2 机械设备RUL预测模型
2.1 预测模型概述
在机械设备RUL预测中,性能退化规律的重要信息主要存储于历史时间序列中。传统机器学习方法一般根据先验知识从时间序列中选取与性能退化相关特征,这种方法会破坏历史数据的时序性,导致预测精度较低。而RCNN不仅能够充分挖掘数据潜在规律,自动提取重要特征,而且可以改善深层CNN训练过程中梯度消失的问题。基于注意力机制的BiLSTM网络能够更好地从RCNN所提取特征中学习性能退化的规律,更容易捕获时间序列中长距离相关特征,当RUL预测中输入时间序列过长时,注意力机制可以通过对输入特征赋予不同的权重,利用有限运算资源从大量信息中筛选出关键信息,过滤或弱化其他冗余信息,使模型更加关注对性能退化影响大的特征,以此来解决时间序列过长导致的信息丢失问题。因此,本文提出的RCNN-ABiLSTM机械设备RUL预测方法,能够利用融合模型深入挖掘传感器数据中丰富的规律信息与退化趋势,提高RUL预测的精度。
2.2 RCNN-ABiLSTM结构
本文所设计并构建的RCNN-ABiLSTM结构如图5所示。该模型主要由输入层、特征提取层、时间序列信息学习层以及输出层组成。将机械设备传感器数据输入至单向残差模块中,通过反复卷积操作加深网络深度,将所提多维特征图输入至全连接层获得最终输出,完成时间序列深度特征的提取。BiLSTM模块从所提特征中学习机械设备随时间变化的规律,注意力模块通过引入权值概率来突出注意力集中的时间段,同时加强各段之间的联系以帮助网络捕获关键时间序列信息。最后,利用输出层对当前RUL做出精准预测。
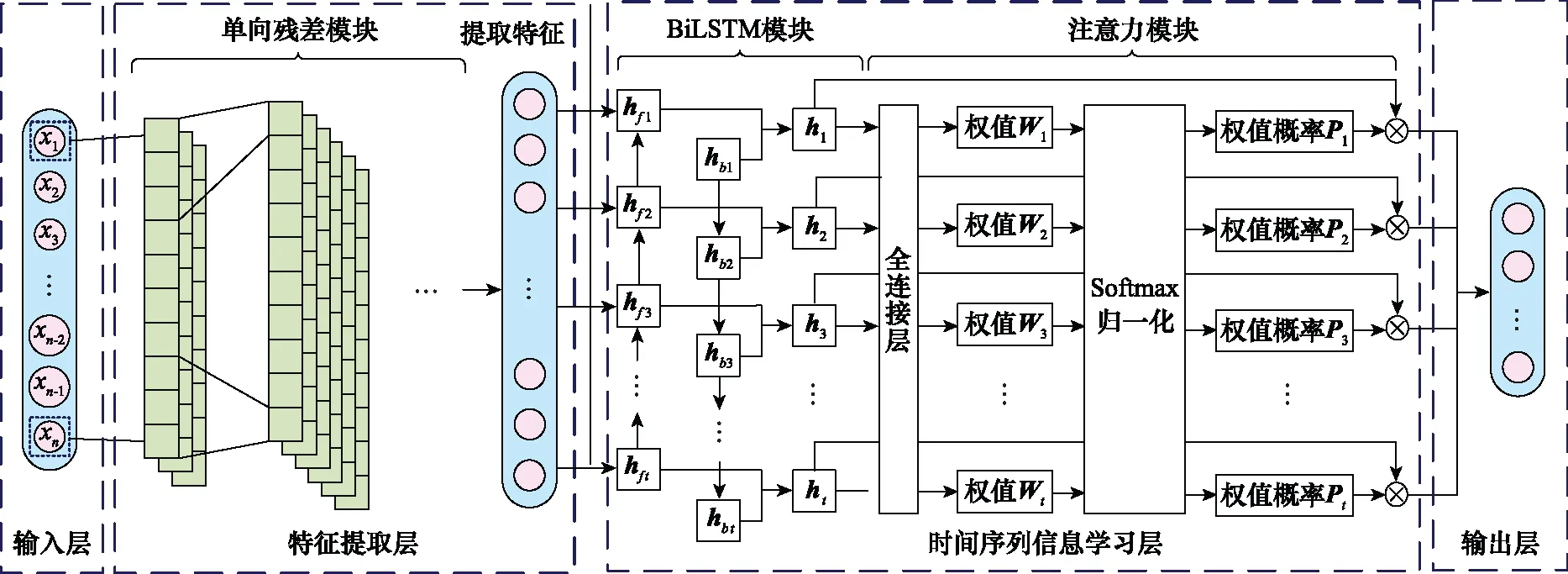
图5 RCNN-ABiLSTM模型结构图Fig.5 Structure of RCNN-ABiLSTM model
2.2.1 输入层
输入层负责将机械设备历史传感器数据输入至预测模型中。记运行工况和不同类型传感器监测数据为相关特征时间序列矩阵X=(x1,x2,…,xT)=(x1,x2,…,xN)T,展开可表示为
(6)
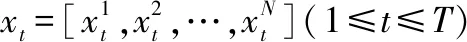
2.2.2 特征提取层
特征提取层负责提取输入时间序列的特征。通过构建若干单向残差模块组成RCNN框架,同时在模块中添加最大值池化层,以保留更多的数据波动信息。经过卷积和池化操作后原始数据被映射到隐层特征空间,选取ReLU激活函数进行激活,搭建全连接结构将其转换为一维结构,并简化参数以提高训练速度。输入为单个时间序列,构建3层残差模块结构如图6所示,其计算过程为
R1=F(X⊗W1+b1)=ReLU (X⊗W1+b1)
(7)
P1=max (R1)+b2
(8)
R2=F(P1⊗W2+b3)=ReLU (P1⊗W2+b3)
(9)
R3=F(R2⊗W3+b4)=ReLU (R2⊗W3+b4)
(10)
Ho=Sigmoid (R3×W4+b5)
(11)

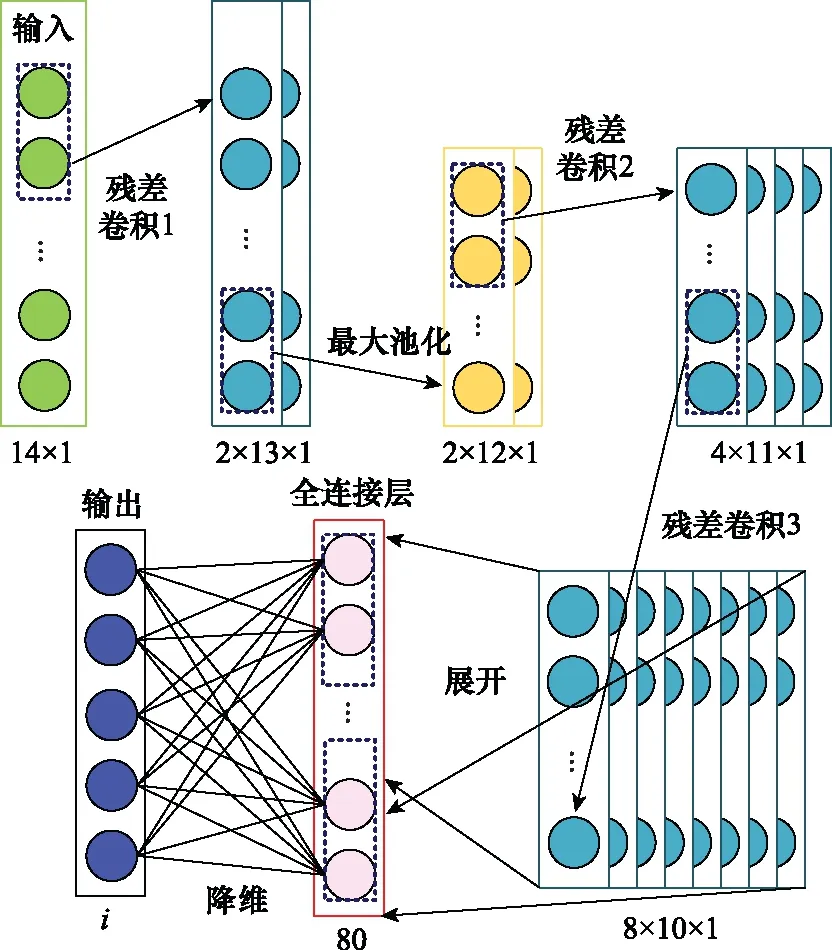
图6 特征提取层结构Fig.6 Feature extraction layer structure
由图6可知,假设输入数据的大小为14×1,卷积核的数目为2,首先经过残差卷积操作1后,变为大小为2×13×1的两个特征图;其次经过尺寸为2×1的最大值池化操作后,得到2×12×1的输出;然后经过残差卷积操作2和3后,得到大小为8×10×1的输出;之后将输出节点展开为全连接层,利用激活函数计算出特征提取层的最终输出,从而实现提取特征降维。
2.2.3 时间序列信息学习层
对于机械设备RUL预测任务,作为输入的传感器数据特征是一段连续的具有强相关性的时间序列,从而要求网络具有一定的“记忆功能”,通过学习前后信息的差异对当前设备的RUL进行判断。特征提取层可以从不同角度挖掘数据特征,但难以学习具有明显时间相关性的序列信息。因此,在特征提取层后添加了BiLSTM模块和注意力模块,使得网络可以对时间序列信息进行学习。如图5所示的时间序列信息学习层,将BiLSTM模块的输出作为注意力模块的输入,解决长时间序列信息丢失的问题。
BiLSTM模块:BiLSTM从前后两个方向对RCNN提取的深度特征进行学习。如图5所示,将每个时刻t的特征输入至前向层和反向层,得到前向输出hft和后向输出hbt,最终通过式(5)计算出BiLSTM模块的输出ht,t∈[1,T]。
注意力模块:记t时刻内剩余寿命标签为Y=(y1,y2,…,yt,…,yT)。首先通过全连接神经网络计算ht的特征权重参数Wt,用来表示由ht所得目标值Y′与Y的相关性,突出注意力集中的时间段,然后利用Softmax函数实现权重归一化,得到所有特征权重之和为1的权值概率Pt,最后根据权值概率对输入ht进行加权求和,计算出注意力模块的输出st。所述计算过程如下:
Wt=tanh (wht+b)
(12)
(13)
(14)
式中:w为全连接层的权重系数;b为偏差向量。
2.2.4 输出层
将注意力模块的输出作为输出层的输入,通过全连接层计算出设备的剩余寿命预测值Y′=[y′1,y′2,…,y′t,…,y′T]T,计算公式可表示为
y′t=Sigmoid (wost+bo)
(15)
式中:y′t为第t时刻模型的预测值;wo为权重矩阵;bo为偏置系数;激活函数选择Sigmoid函数。
3 验证与分析
3.1 数据集介绍
美国航空航天局的C-MAPSS航空发动机数据集[28]是RUL预测领域应用最为广泛的公共数据集之一,包含了不同故障模式和工作条件下涡扇发动机从正常运行到故障失效的4组传感器监测数据,且将21种传感器作为能够表征发动机运行状况的典型指标。每组数据由训练集、测试集和RUL标签组成,训练集包含发动机整个寿命周期的全部数据,测试集只包含测试发动机从初始状态开始前一部分的数据,RUL标签是与测试集相对应的发动机最后监测时刻的RUL。其中,各个数据文件中包含不同数量的发动机,每台发动机带有不同程度的初始磨损,因此每台发动机监测数据的序列长度也不同,4组监测数据的具体信息如表1所示。
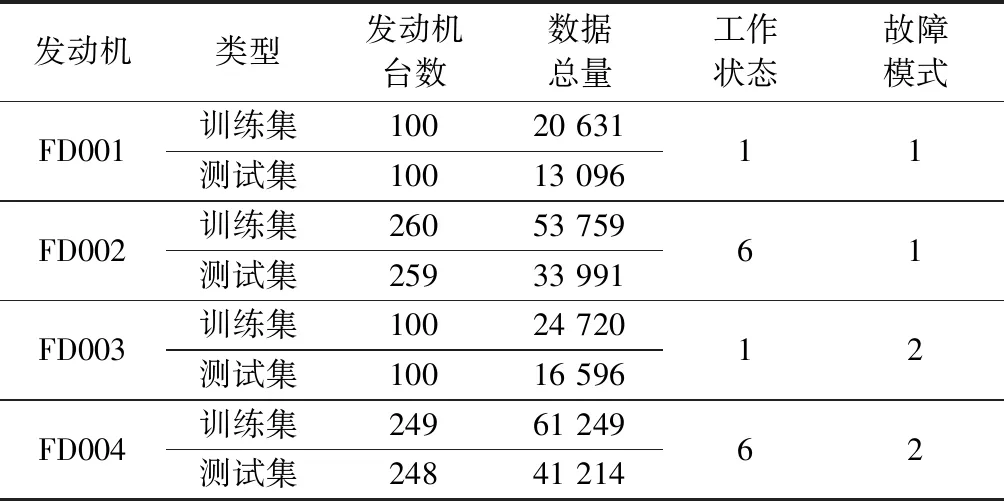
表1 航空发动机数据集
3.2 验证过程及结果分析
3.2.1 数据预处理
本文以FD001为例展示验证的具体过程。观察到数据集中setting_3与7个传感器数值无变化,为提高计算速度,剔除无意义数据,同时将运行周期也作为输入特征之一,即可得到17个输入特征的数据集。其次,原始数据含有大量高斯随机噪声,首先使用窗宽为10的滤波函数对数据进行降噪处理,以降低数据的波动。
由于多维监测数据具有不同的量纲,所以在模型构建前须进行归一化预处理。本文选用最小-最大标准化方法将数据统一至[0,1]范围内,具体公式如下:
(16)
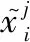
为了利用有限的序列深入挖掘性能退化规律,同时将时间序列转化成BiLSTM网络擅长处理的三维输入格式,采用滑动时间窗分割方法对归一化后的数据进行处理。这样既可以充分保留相邻序列之间的时间相关性,又可以提高训练集样本的数量,使模型具有更高的鲁棒性和泛化能力。记发动机原始时间序列长度为T,特征维度为N,利用窗宽为S的滑动窗沿着时间序列滑动,将每滑动一个步长所截取的时间序列叠加至第3个维度,形成(T-S,S,N)的三维张量,计算过程如下:
X1:T-S=x1:1+S⊕x2:2+S⊕…xi:i+S…⊕xT-S:T
(17)
式中:X1:T-S为转换后的三维张量;xi:i+S为从第i个时间周期开始长度为S的序列;⊕表示窗口内数据在第3个维度的连接,从而形成三维张量。
发动机在运行初期状态良好,性能退化量可忽略不计,但到了使用末期,发动机的性能会随着时间的延长而急剧下降。如果将发动机性能迅速劣化之前监测数据的标签设置为总运行周期减去当前运行周期数,会增加剩余寿命预测结果的滞后性。因此,可以认为发动机开始急速退化之前的RUL保持不变,即为训练集的RUL标签设置阈值,使之成为分段线性函数。研究表明,将训练集RUL标签突变临界值设置为第130个运行周期预测效果较好[29],RUL标签设置结果如图7所示。
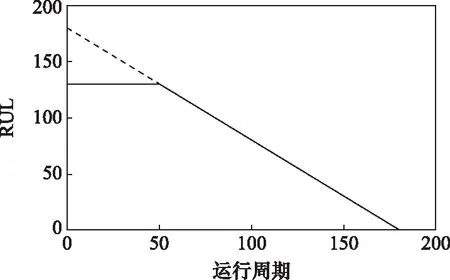
图7 RUL标签设置Fig.7 RUL label setting
3.2.2 超参数设置
本模型所涉及的主要超参数有:网络结构、学习率、批尺寸、迭代次数、Dropout率等。模型超参数对模型性能的优劣有较大的影响,因此通过调节单个参数来使得模型预测误差最低,从而获取最优超参数组合。
同时,为了准确反映不同超参数模型在测试集的预测值与真实值之间的误差距离,采用均方误差MSE作为评价指标来调节超参数:
(18)
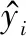
以批尺寸参数为例,模型超参数调节过程如图8所示。由图8可知,批尺寸为64时MMSE最小,因此64是模型最合理的批尺寸参数。其中,MMSE为30次实验结果所得MSE的均值。表2是通过30次重复实验获得的最优超参数组合,表中其他超参数设置方法均按上述方法进行。
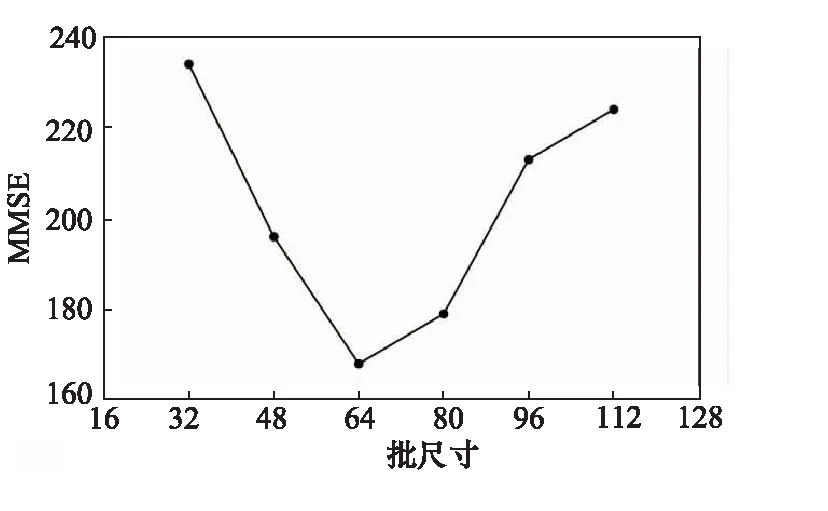
图8 不同批尺寸试验结果(MMSE为30次试验结果所得MSE的均值)Fig.8 Different batch size test results (MMSE is the mean of MSE obtained from 30 trials)
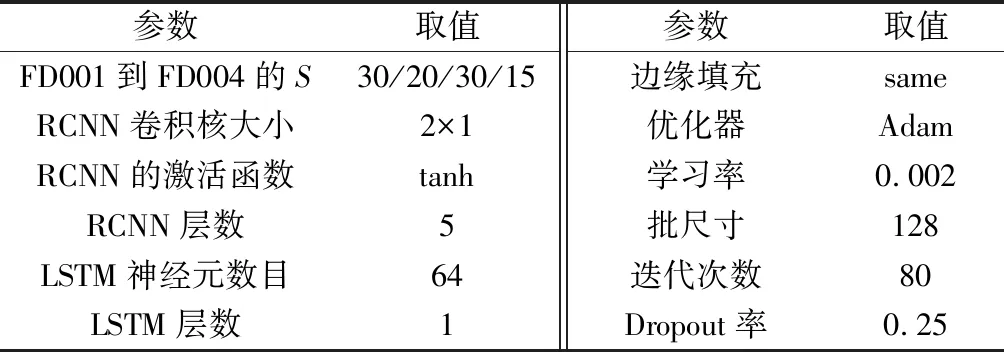
表2 最优超参数组合
3.2.3 模型训练与结果分析
将预处理后的高维时间序列输入RCNN进行特征提取,原始数据共有17个特征,经过5个残差单元和最大值池化操作后数据维度降低至7,然后将降维特征输入到BiLSTM中进行时间信息学习。将训练集按照7:1的比例划分为训练集和验证集,若验证集的误差在连续10个训练时期内没有下降趋势时,为防止模型过拟合,提前停止训练。训练过程中的测试误差与训练误差变化情况如图9所示,训练与测试的评价指标随着训练时期数的递增而逐渐趋于平稳与一致,训练误差从1 852降低至234,测试误差从1 794逐渐减小至263。
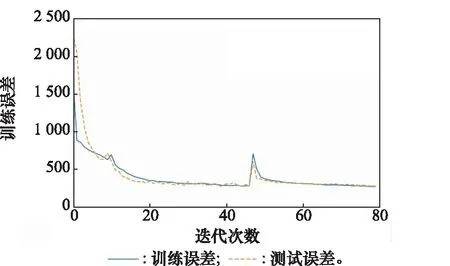
图9 RUL预测训练误差与测试误差曲线图Fig.9 RUL prediction training error and test error curves
将测试集输入至训练后的模型中,RUL预测结果如图10所示。
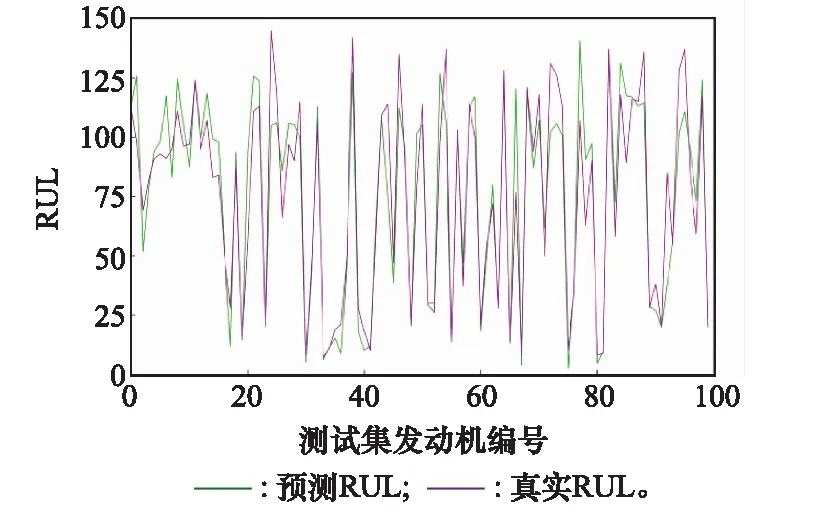
图10 FD001测试集RUL预测结果Fig.10 FD001 test set RUL prediction results
为比较RUL大小对模型预测的影响,将FD001测试集中所有的发动机根据真实RUL值从大到小进行重新排序,结果如图11所示。当RUL值较大时,发动机处于健康状态,表明设备运行状况良好。由图11可知,发动机刚开始运行时,RUL预测误差较大,同时波动较为剧烈且表现出明显的滞后性。但经过长时间运行后,预测RUL收敛在真实RUL周围,预测性能显著增强。因此,设备历史信息越充分,性能退化信息越明显,模型的预测误差越小。
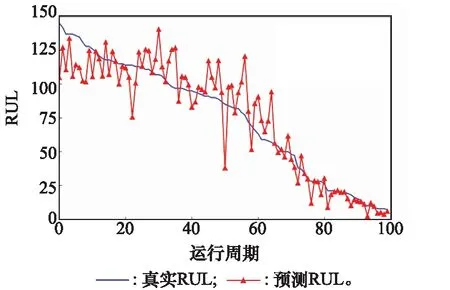
图11 FD001发动机重新排序预测结果Fig.11 FD001 engine reordering prediction results
在FD001数据集中随机选取4个发动机的连续RUL预测结果,如图12所示。由图可以看出RCNN-ABiLSTM模型的深层卷积结构能够有效提取引擎退化的深度特征,即使引擎刚开始运转时历史数据较少,难以预测RUL大小,模型预测值也较为接近临界值130。随着运行周期的增加,发动机的性能退化量逐渐积累,BiLSTM可以学习时间序列前后的时序关系,同时注意力机制自适应选取性能退化关键时间点。模型通过融合二者在空间和时间特征学习的优势,有效提升较长时间段的预测精度。由图12可知,在发动机性能退化中后期,模型能够较好的拟合真实性能退化曲线,RUL预测结果愈发精确且稳定性较高。因此,本文所提模型有较强的空间深度特征提取能力和较长时序特征的记忆能力。
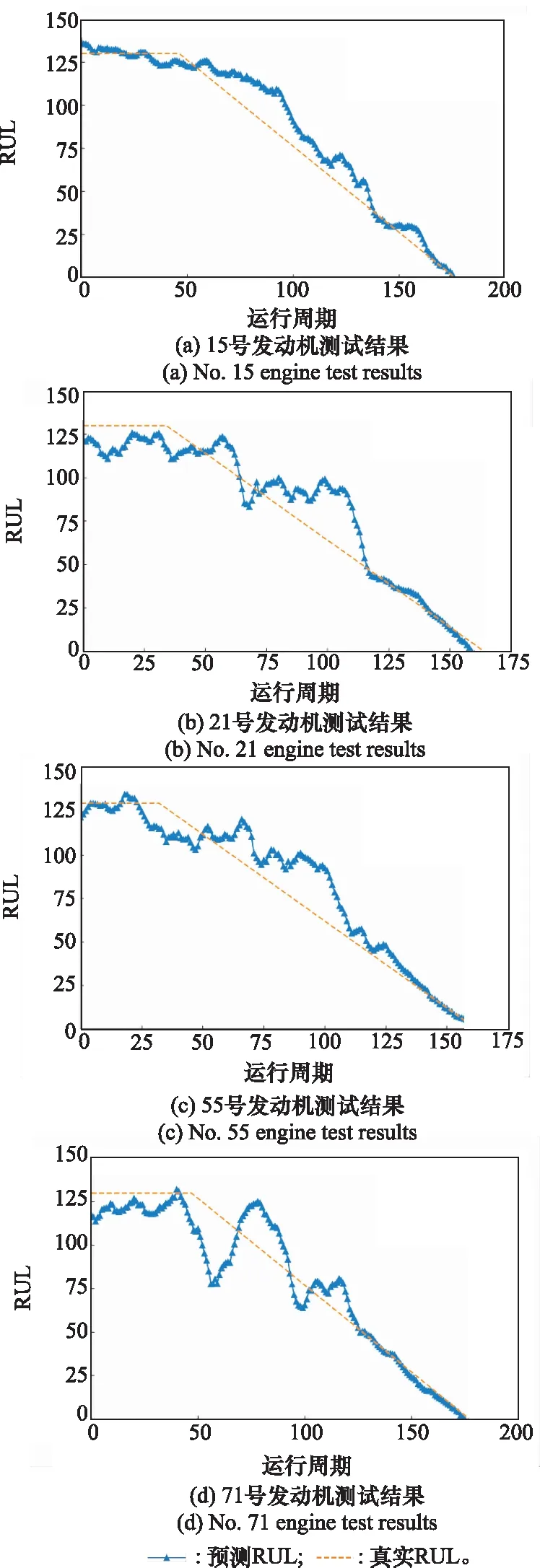
图12 4台发动机RUL预测结果Fig.12 Four engines RUL prediction results
3.3 模型对比分析
为了客观评估不同模型在测试集上的准确度和泛化能力,采用均方根误差RMSE和评分函数Score对RUL预测效果进行评价[15]。
RMSE用于衡量预测值同真实值之间的偏差,其计算公式为
(19)
由于发动机较高的安全性要求,不及时维修造成的灾难性后果所引起的成本远大于过度维修资源的成本,因此评分函数对高估RUL的情况施加更高的惩罚。Score分数越低,表明模型的预测性能越好,计算公式如下:
(20)
为了验证提出的RCNN-ABiLSTM融合模型进行发动机RUL预测的有效性,分别构建了支持向量回归[15]、CNN[15]、LSTM[17]、CNN-LSTM[30]、Autoencoder-BiLSTM[20]作为对比模型,所得结果如表3所示。由表3可知,相较于浅层机器学习方法和单层深度学习模型,文献[30]中提出的CNN-LSTM虽然在子集FD003上表现略逊于LSTM,但在复杂多故障模式条件子集FD002和FD004上预测效果更好。文献[20]中提出的Autoencoder-BiLSTM将自编码器作为特征提取工具,同时利用BiLSTM捕捉双向长程依赖特性,相较于CNN-LSTM误差,预测结果进一步提升,但在FD002和FD004上表现出明显的预测滞后性。RCNN-ABiLSTM考虑到注意力机制提取长时间序列关键退化信息的优越性,在所有的测试集上预测精度显著提升。结果表明,本文所提出的融合模型不仅有效降低了RUL预测误差,而且对于运行条件复杂和故障模式多变的发动机传感器数据,能够准确寻找到退化时间点,提高设备的使用安全性。
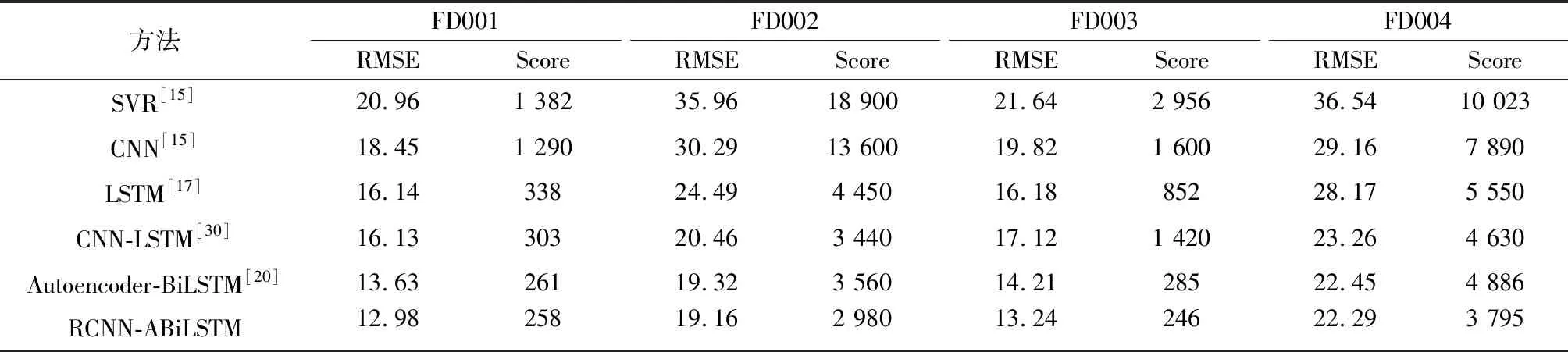
表3 不同预测模型对比结果
4 结 论
针对机械设备监测数据呈现出非线性、多维度、大规模等特点,关键退化信息容易淹没在长时间序列中,本文提出一种基于RCNN与ABiLSTM的机械设备RUL预测方法,通过CMAPSS数据集对模型进行多方面验证与测试,试验结果表明:
(1) 设备历史信息越充分,性能退化信息越明显,模型的预测误差越小。
(2) RCNN-ABiLSTM模型通过RCNN模型深度挖掘多维监测数据的退化特征,同时ABiLSTM可以学习时间序列前后的时序关系,利用注意力机制自适应选取性能退化关键时间点。模型通过融合二者在空间和时间特征学习的优势,有效提升较长时间段的预测精度。
(3) 相较于浅层机器学习方法、单层深度学习模型和多层深度学习模型,利用RCNN-ABiLSTM模型对运行条件复杂和故障模式多变的多维机械设备监测数据进行处理,能够准确寻找到退化时间点,提高设备的使用安全性。
