Loop Closure Detection via Locality Preserving Matching With Global Consensus
2023-03-09JiayiMaKainingZhangandJunjunJiang
Jiayi Ma,,Kaining Zhang,and Junjun Jiang,
Abstract—A critical component of visual simultaneous localization and mapping is loop closure detection (LCD),an operation judging whether a robot has come to a pre-visited area.Concretely,given a query image (i.e.,the latest view observed by the robot),it proceeds by first exploring images with similar semantic information,followed by solving the relative relationship between candidate pairs in the 3D space.In this work,a novel appearance-based LCD system is proposed.Specifically,candidate frame selection is conducted via the combination of Superfeatures and aggregated selective match kernel (ASMK).We incorporate an incremental strategy into the vanilla ASMK to make it applied in the LCD task.It is demonstrated that this setting is memory-wise efficient and can achieve remarkable performance.To dig up consistent geometry between image pairs during loop closure verification,we propose a simple yet surprisingly effective feature matching algorithm,termed locality preserving matching with global consensus (LPM-GC).The major objective of LPM-GC is to retain the local neighborhood information of true feature correspondences between candidate pairs,where a global constraint is further designed to effectively remove false correspondences in challenging sceneries,e.g.,containing numerous repetitive structures.Meanwhile,we derive a closed-formsolution that enables our approach to provide reliable correspondences within only a few milliseconds.The performance of the proposed approach has been experimentally evaluated on ten publicly available and challenging datasets.Results show that our method can achieve better performance over the state-of-the-art in both feature matching and LCD tasks.We have released our code of LPM-GC at https://github.com/jiayi-ma/LPM-GC.
I.INTRODUCTION
SIMULTANEOUS localization and mapping (SLAM) system is an enabling technology for mobile devices to accomplish self-localization and map construction [1],[2].Generally speaking,the trajectory calculated directly via the frame-to-frame visual odometry is prone to generate drift by virtue of errors in each pose estimation.To resolve the problem,the loop closure detection (LCD) module is introduced.It identifies re-observations during navigation,followed by i)recovering an Sim(3) pose from a closed-loop event ii) optimizing the pose graph by incorporating the recovered Sim(3)pose as a constraint.As such,effective LCD methods can help with providing accurate pose estimation,as well as mapping the environment with global consensus.The paper in hand mainly discusses how to search closed-loop events,and focuses on appearance information captured by exteroceptive cameras.
Appearance-based LCD is achieved via visual place recognition [3],and is typically composed of two components:candidate frame selectionandloop closure identification.The former operation,to a large degree,greatly coincides with the image retrieval task due to its trying to search the most similar visual entry into an already captured database,viz.,pre-visited camera observations.This step aims to find as many valid candidate frames as possible to acquire a high recall rate.Most state-of-the-art approaches devote themselves to searching for a more reasonable representation for images.This has transformed from aggregating local descriptors [4]–[6],to directly train a network with ranking-based or classification losses [7]–[10].The former approaches are usually constructed on the bag-of-words (BoW) scheme [11].It is achieved by first quantizing the descriptor space viak-means clustering[12] to produce visual words,then coupling with the widely used term-frequency inverse-document-frequency (TF-IDF)technique to generate visual word histograms that represent the incoming sensory measurements.Due to the neglect of spatial information of scenes,the performance of the initial BoW strategy would degenerate when repetitive or similar structures appear.This drawback impels the research community to adopt more sophisticated solutions [13]–[16] which enhance spatial information by altering the encoding pattern.
With regard to loop closure verification,it is also known as geometric consistency checking module,aiming at mining geometric relationship between candidate pairs and enhancing the precision of the LCD system.It is achieved by first searching for reliable correspondences between image pairs and then recovering the camera pose through the calculation of fundamental or essential matrix [17].In the process of reliable correspondence construction,a putative set is first established as per local descriptor similarity.Later,false matches of the putative set are filtered via a feature matching approach.The most broadly utilized algorithm in this process is RANSAC [18].It optimizes the maximum consensus loss by alternating between hypothesis and verification,which ends with describing the mapping relationship of putative correspondences via a parametric model.This technique is effective when the geometric model between an image pair is rigid.Yet in LCD tasks,the existence of camera distortion would lead tonon-rigid deformationwhilst dynamic occlusions and similar structures such as trees,cars and buildings would result ina high out lier ratio[19].These two factors make the performance of RANSAC degenerate severely.Thus using RANSAC would cut down both accuracy and efficiency when challenging scenes appear in the LCD task.
The contributions of this paper are three-fold:
1) A state-of-the-art deep local descriptors (i.e.,Super-features [20]) proposed for image retrieval is applied in the LCD task.However,in image retrieval,its coupling with aggregated selective match kernel (ASMK) [16] needs to extract descriptors of all database images in advance,which cannot be directly applied in LCD where the database scales up with the navigation of a robot/vehicle.So we incorporate an incremental strategy within Super-features+ASMK,which is demonstrated both computationally and memory-wise efficient and can yield great LCD performance.
2) To tackle the drawback of RANSAC,a novel feature matching approach called locality preserving matching with global consensus (LPM-GC) is proposed to efficiently establish reliable correspondences in complex LCD scenes,e.g.,image pairs with many repetitive patterns and large mismatch proportions.Specifically,LPM-GC aims to retain the local neighborhood information among putative matches and make the motion vectors across the whole image consistent with each other.A solution with closed formis further deduced which enables our model to realize feature matching in only a few milliseconds.
3) Extensive experiments are performed to measure the performance of the proposed approach on both feature matching and LCD tasks.We show that our approach can acquire impressive results in long-term traversal.
The remainder of the paper is organized as follows.Section II introduces related work in the context of LCD in brief.Section III presents our proposed LCD system in detail,including candidate frame selection using Super-features +ASMK,and loop closure identification using LPM-GC.Section IV gives comprehensive experimental results and comparative evaluation against existing advanced LCD approaches.The whole paper ends with conclusion remarks outlined in Section V.
II.RELATED WORK
The state-of-the-art LCD methods typically put attention on how to select candidate frames more effectively,whereas the verification process is scarcely studied.RANSAC is typically regarded as the default setting to remove mismatches.To give the readers a deeper understanding of the points of interest in our work,we first review prevalent LCD approaches and then give an introduction to feature matching methods [21].
A.Candidate Frame Selection
There are two classification criteria for the candidate frame selection techniques.One is judging whether the algorithmadopts on-line or off-line strategy,and the other is determining whether the algorithm is image-based or sequence-based.Often,off-line methods train visual dictionaries in advance,according to which BoW vectors are calculated directly to represent images [4],[22]–[25].For example,a probabilistic model over the BoW representation is employed in FAB-MAP[22],[23],where a Chow Liu tree is additionally involved to determine the probabilities of co-occurrence of visual words.Later,to make LCD more compatible with the realtime requirement,[4] proposes to construct the visual dictionary based on binary descriptors.On-line strategies refer to building visual dictionaries on the fly,and they become increasingly popular on account of their scene-agnostic abilities[26]–[28].For example,Angeliet al.[26] constructed on-line dictionaries by performing comparison between each new descriptor and its nearest visual word.Distances greater than a pre-defined threshold would lead to new word generation.iBoW-LCD [28] proposes to save a binary dictionary in the form of a hierarchical tree.Then the update of the dictionary is performed by adding or deleting visual words based on the similarity of binary descriptors.Tsintotaset al.[27] proposed to generate on-line visual words via a tracking approach,followed by a voting scheme to determine candidate frames.
Image-based and sequence-based strategies are distinguished by the smallest unit in a system,respectively.The former takes each image as an individual and judges whether a loop-closing pair appears in it,while the latter takes the image continuing in time as a group and determines whether a loopclosing pair arises in it [5],[29]–[31].For example,[30] utilizes an on-line dictionary.The input image stream is partitioned into places based on a simple feature matching scheme and visual words of each place are yielded via a clustering technique.As what is done in [27],candidate frames are finally identified based on a voting scheme.In PRE-VieW [31],an off-line dictionary is adopted and a new sequence is instigated if there are enough new visual words observed.Then candidate frames are searched from sequence-to-sequence,to image-to-image matching,in L2-normscoring.
Recently,the convolutional neural networks (CNNs) have been adopted to tackle the LCD task [6],[8]–[10],[32],[33].Existing approaches mainly focus on how to boost the performance of image representation via CNN.They may generate global descriptors via CNNs directly,or via deep local features coupled with BoW-related strategies.However,regardless of the way in which the candidate frame selection session is conducted,the subsequent processes of feature matching as well as pose estimation are still based on local features.Therefore,designing networks to extract local features suitable for LCD-related tasks is another worthwhile research topic.

Fig.1.An overview of the proposed LCD system and detailed introduction can be found in Section III-A.CNN is ResNet50 excluding the last convolutional block,while LIT stands for an iterative module exploited to extract Super-features.q is the ID of the query image,and ξ equals to f·T with f and T standing for the frame rate (Hz) and non-search time (s),respectively.Due to the sequential nature of LCD data,images captured consecutively would have high visual commonality.So to prevent false-positive detection from happening among them,we only add images with IDs smaller or equal to q −ξ to the database.
B.Loop Closure Identification &Feature Matching
Feature matching is a fundamental problem in many computer vision problems [21],[34].In particular,RANSAC [18]is the most commonly utilized approaches for feature matching in LCD tasks.But its parametric-model-based and resampling-based nature limit its performance in scenes with nonrigid deformation or gross outliers.Although considerable variants [35]–[38] have been proposed to improve its performance,the drawback mentioned above still exists.To address this issue and model in high dimension representation,numerous non-parametric techniques are investigated and have shown promising performance in both rigid and non-rigid matching [39]–[42],but the optimal solution is challenging to determine due to the large search space particularly when massive outliers and/or dynamic objects exist in the image pairs.In addition,another strategy,termed as graph matching,is widely studied as well,which achieves feature matching by optimizing a quadratic programming problem[43],[44].Nevertheless,its low efficiency cannot guarantee the real time requirement of LCD tasks.For the sake of fast matching,some methods are lately published based on local information consistency [45]–[48].In particular,Zhanget al.[49] proposed the local motion and structure consensus for robust feature matching during loop closure verification.
A lso,during recent years,learning-based methods are increasingly investigated to address feature matching problem and achieve encouraging performance.In addition to implement feature detection and description,many researchers try to identify reliable matches and/or estimate the camera pose information by means of deep convolutional networks.Yiet al.[50] performed a first try to simultaneously conduct inliers/outliers recognition,as well as pose estimation.Maet al.[51] designed a high-dimensional feature based on local information for each putative correspondence,followed by feeding the features into a network to identify inliers/outliers.Sarlinet al.[52] introduced a neural network that is able to achieve feature matching by constructing a flexible context aggregation mechanism based on attention,and it can learn priors over geometric transformations and regularities of the 3D world through end-to-end training from image pairs.In our work,a novel algorithm for matching complex scenes in the LCD task is designed,and our experiments demonstrate its significant improvements comparing with the competitors.
III.METHODOLOGY
This section illustrates the proposed LCD system.As the schematic diagram shown in Fig.1,given a query image,two procedures involving updating and querying the database are performed one after another.Then the identified candidate frame would constitute an image pair with the query one,followed by being transferred into the stage of geometric confirmation which is achieved via our LPM-GC.A loop-closing event is confirmed only when an adequate number of matches are retained as well as the temporal consistency test is passed.Note that notations in different subsections of this section are mutually independent except for special illustrations.
A.Candidate Frame Selection via Super-Features &ASMK
Super-Features:Often,ASMK is coupled with handcrafted local descriptors to generate global embeddings of images.Recently,some literatures show that learned local descriptors can highly outperform the handcrafted ones [20],[53].Thus in this paper,we exploit a learned one dubbed Super-features proposed infeature integration-based retrieval(FIRe) [20] to achieve candidate frame selection.It is obtained from the middle level of a network and trained directly on the features themselves.In the following,we would first give a brief introduction to its background.
Given an image,an ordered set of Super-features of it can be extracted via a module called local feature integration transformer (LIT).To be specific,ResNet50 without the last convolutional block serves as the backbone to firstly extract local features U={ul∈RD,l=1,2,...,L} of images.Then LIT can be formulated as a function Φ(U):RL×D−→RN×dthat takes as input the set of local features and outputsNSuper-features.It is defined as an iterative module witht∈[1,T]
where ϕ(·) is the core function appliedTtimes and Q0=n=1,2,...,N}is initialized with a set of learnable templates.Equation (1) indicates that Super-features are progressively formed by iterative refinement of the templates,conditioned on the local features U from the backbone.
Specifically for ϕ(·),it is inspired by the Transformer architecture [54] which takeskey,query1In the introduction of “Super-features”,the term“query”refers to the input of the Transformer architecture,which has different meaning with that in image retrieval and LCD.andvalueas inputs.In our case,keyandvalueare respectively calculated via layer normalization and the corresponding linear projection functionsK(·) andV(·) on the local features ul∈U in each iteration,whilequeryis calculated via layer normalization together with another linear projectionQ(·) on eachin thet-th iteration.The three linear projection functionsK(·),V(·) andQ(·)respectively project the input to dimensionsdk,dvanddq,and we setdk=dv=dq=d=1024 as per FIRe.Formally,in thetth iteration,the attention scores of each component ofkeyover all ones ofqueryare given by
Finally,the Super-features are generated by performing whitening and L2-normalization on QT.Intuitively,each Super-feature is a function over all local features in U,invariant to permutation of its elements.Thus the set of Super-features is ordered,based on which the whole network can be trained by comparing Super-features with the same ID among images with the same landmark.
In most deep image retrieval approaches,local features boil down to the localized map activations of a neural network,where the optimization of the network is performed on the global feature aggregated by these local ones.In this case,training actually happens on the global feature while testing acts on local feature matching.This makes a discrepancy between training and testing,meanwhile leading to the redundancy of the local features.FIRe addresses the above mentioned two issues by training on the local features themselves,which eventually leads to the compactness of Super-features.
Incremental ASMK:After obtaining local descriptors,ASMK is exploited for indexing and retrieval.Note that we use the binarized version of it to improve computational and memory-wise efficiency for the LCD task.Suppose we have obtained a set X={x|x ∈Rd} ofn=|X|d-dimensional local descriptors of an image,where |·| denotes the cardinality of a set.Based on ak-means quantizer,a visual codebook C={c1,c2,...,ck} comprising |C|=kvisual words is acquired in advance.We denote byq(x) the nearest neighbor word for each local descriptorx,and denote by Xc={x|x ∈X:q(x)=c} the subset of descriptors in X that are assigned to the visual wordc.Denoting by X and Y the local descriptors of imagesXandY,while CXand CYthe words occurring in the two images respectively,then their similarity can be calculated by
Taking itemsw.r.t.X for illustration,Φ(Xc) is an aggregated vector representation of local descriptors in X assigned to the same visual wordc.σ(·) is a scalar selectivity function,andis a normalization factor.Denoting an aggregated residual for a visual wordcbythen Φ(Xc) can be calculated by a normalized aggregated residual∥V(Xc)∥.Regarding σ(u),it is defined as a threshold polynomial selectivity function
ASMK enjoys saving memory requirements and searching efficiently by exploiting an inverted file indexing structure.Since the scale of the database increases with the navigation of a robot/vehicle,we revise the vanilla inverted file2https://github.com/jenicek/asmkto an incremental one to make it applied in LCD,and show an example of it in Fig.2.Specifically,we denoteInewthe image to be inserted into the inverted file.Then the update of the inverted file starts by searching the nearest neighbor of each descriptor ofInewfrom the codebook.As the gray block shown in Fig.2,each word in the codebook is attached with a list and if a word occurs in an image,the ID of the image would be recorded in the corresponding list.Regarding the blue one,each image also corresponds to a list,recording the IDs of words occurring in each image and their accumulated binary residuals.Thus whenInewoccurs,the inverted file is updated by renewing the gray and the blue blocks,respectively.Similarly,the procedure of querying starts by first extracting the descriptors of the query imageIqand then searching the nearest neighbor of each descriptor from the codebook.Based on the gray block shown in Fig.2,database images which have the same words withIqare first identified,then similarity calculated by (4) would be performed based on the information recorded in the blue block.Intuitively,the indexing latency and the memory footprint of our incremental ASMK strategy are proportionate to the number of non-empty ASMK clusters of the codebook,i.e.,the number of words with at least one assignment.This property is related to the compactness of the used descriptor.Thus exploiting Super feature can improve computational and memory-wise efficiency of the candidate frame selection stage,which is demonstrated in the experimental part.

Fig.2.An example illustrating the structure of the inverted file exploited in our incremental ASMK.The gray block records which images each word occurs in,while the blue one records the words appearing in each image and their corresponding binary residuals.
Overall,there are three elements that guarantee high execution speed and low memory consumption of our candidate frame selection strategy: the compact Super-features,the binarilized version of ASMK,and the incremental inverted file.In this paper,we extract Super-features by the official model and set ϕ=3, γ=0 to conduct the calculation in ASMK.
How to Perform Candidate Frame Selection?Not all images captured before the query one (Iq) would be added to the database.This is because they share more or less co-visibility areas withIqdue to the sequential nature of the incoming instances in LCD.If detection is triggered among them,false-positive events would occur unavoidably.To address this issue,we first denoteqthe image ID ofIq,andrthe image ID of any image captured before the query one.Since no LCD events would occur at the start of a traversal,we only consider the case ofq>ξ,whereξequals tof·T withfand T standing for the frame rate and non-search time,respectively.Then only whenr=q−ξ is satisfied wouldIrbe applied to update the inverted file.In other words,updating starts whenq=ξ+1.When the procedure of updating is finished,similarity measurement in (4) would be performed betweenIqand the database.Finally,the most similar database image would constitute a candidate pair withIqand be sent to the stage of geometric verification.
B.Loop Closure Identification via LPM-GC
The second stage of our framework involves a geometric confirmation step.It is achieved by feature matching,serving to test whether the image pair has consistent relative planar geometry.For this,we first build a putative set by coupling the descriptor similarity with a ratio test [55].Then our interest lies in how to filter the false correspondences in the set.Mathematically,we denote bySp=the putative set with xiand yibeing the coordinates of the keypoints.If (xi,yi)constitutes a true correspondence,we call xi/yian inlier,otherwise an outlier.Our LPM-GC functions as a filter,which guarantees as many inliers are recognized as possible.
1) Locality Preserving Matching:Locality preserving matching (LPM) [45] is proposed for effective mismatch removal.The main contribution of it is that it does not need any advance estimation for the transformation between two images and can realize accurate correspondences in real time.In the following,we would revisit it in brief.
Generally speaking,the local neighboring information of a keypoint would not change freely in spite of local non-rigid deformation.As such,we can distinguish inliers and outliers in accordance with the consistency of local neighboring information.This leads to a cost function of
where I is the inlier set,the first term means that the pairwise distance of a true correspondence should be retained,the second term penalizes the outliers,λcontrols the trade-off between the two terms,Nxis theKnearest neighbors of x,d(·,·) is a distance measuring function,and |·| denotes the cardinality of a set.With the cost function defined in (6),the optimization problem can be given by
Thus our goal is to find an optimal solution I∗which can minimize the cost function in (6).
Generally,d(·,·) can be defined in the form of L1-normor L2-norm.But this kind of distance between a point pair can not be retained well due to the existence of non-rigid transformation (e.g.,scale change) between an image pair.To ease this concern,the output ofd(·,·) is defined in a discrete domain
andd(yi,yj) has a similar definition.
2) LPM With Global Consensus:As can be seen from the cost function defined in (6),LPM only concentrates on preserving the local neighborhood structures of putative matches.Therefore,its ability of distinguishing outliers and inliers would decrease when the scenes are complex,for example,image pairs involving many repetitive patterns or a large number of mismatches,leading to wrong judgements on loop closure verification.To address this issue,we design a global consensus based on LPM,termed as LPM-GC,to promote the matching accuracy.In the following,we first introduce two strategies to improve the neighborhood structure characterization [45],and then detail the consensus of global motion structure.
Multi-Scale Strategy:As the locations of keypoints in an image are typically not subject to uniform distribution and different putative sets have various proportion of outliers,the optimal value of neighbor numberKcould vary,and using a fixedKwill reduce the robustness.Therefore,by considering a multi-scale neighborhood strategy,i.e.,the cost functionCin (6) can be rewritten as
By using the definition of the distance in (8),we can simplify the cost function in (9) as follows:

Fig.3.Illustration of the consensus of neighborhood topological structure.The put ative match (x i,y i) (connected by bold lines) is an inlier in the left(blue) and an outlier in the right (red).Centring on x i and y i,the points within the pink circle are their K nearest neighbors,where the pink ones represent their local support,e.g.,common elements in and ,while green for otherwise.
where the first and second terms reflect the length and orientation consistency between miand mj,respectively.This definition results ins(mi,mj)∈[−1,1],and a largers(mi,mj) indicates higher consensus.As per (11),a two-level local topological costd(mi,mj) can be defined as
Consensus of Global Motion Structure:In terms of the fact that correct loop-closing pairs are always the image pairs captured within a few meters,the length of motion vectors between putative matches should maintain a high degree of consensus.As Fig.4 shows,the first row successively depicts the loop closure events where the robot is in the ideal case,goes ahead,turns right,and turns left.To characterize the consensus of (xi,yi) with respect to the whole putative setSp,we calculate the lengths of the motion vectorsand normalize them into [0,1] to deal with scale changes,denoted asThe bottom of Fig.4 illustrates the distribution offrom 0 to 1.Clearly,the lengths of motion vectors associated by inliers in these four scenes all have high consensus,while those of outliers always scatter randomly.
Based on this observation,we develop a global consensus factordgc(xi,yi) to refine the original cost function.We first adopt a clustering strategy such as mean shift [56] to clusterand subsequently obtain several clustersautomatically without requiring to set the cluster numberJin advance.Note that in the mean shift clustering,there is a parameterrused to assign the points around a clustering center with radiusrto that cluster.The value ofrcan influence the consensus degree of the motion vectors.A largermeans the inclusiveness of each cluster is high,leading to a low consistency,and vice versa.
As we can see,whenlibelongs to a large cluster, αiwill be large,which means that the putative match (xi,yi) has a large degree of consensus with respect to the whole putative setSp.
Based on the support value αi,we can finally define the global consensus distanced gcas follows:
where the numerator of the exponent in the Gaussian function,i.e.,characterizes the prior of (xi,yi).Ideally,a loop-closing pair should have two same images,then we haveli=0 for a true match (xi,yi),and the corresponding global consensus distance will be minimized,i.e.,d gc(xi,yi)=0.
Considering the multi-scale strategy in (10),the local topological cost factor in (12),and the global consensus factor in(14),we obtain our final cost function as follows:
3) A Solution with Closed Form:We associate each putative correspondence (xi,yi) with a binary codepito indicate its correctness.Specifically,pi=1 suggests (xi,yi) constitutes a pair of inliers whilepi=0 means a pair of outliers.In this case,the objective function in (15) can be simplified withto
where

Fig.4.Illustration of the global consensus in loop-closing pairs.Top: feature matching results of loop-closing pairs (only inliers provided).Middle: motion fields of four different scenes in the top row,where the head and tail of each vector correspond to the spatial positions of two corresponding feature points in the two images (blue: inliers;red: outliers).Bottom: distribution of the lengths of motion vectors.For each bin,we overlap the inlier and outlier probabilities,where the one with smaller probability is shown in the outer layer.
The final inlier set is determined by the optimal solution of p in (16).Intuitively,reflect the neighborhood structures of each correspondence,which can be calculated in advance with regard to the known information of local neighborhood.As such,the only unknown variable in (16) ispi.To optimize the cost function and make it minimum,pishould be set to 1 when>λ while 0 when.This is≤λ equivalently a simple linear assignment problem,i.e.,optimizing a truncated loss without any regularization term[57].This kind of solver results in a closed-formsolution forpi,and we formally summarize it as
which subsequently leads to the optimal inlier set of
The pipeline of our LPM-GC is summarized in Algorithm1.

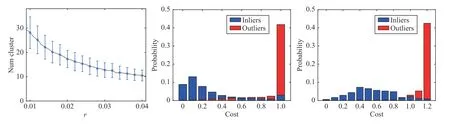
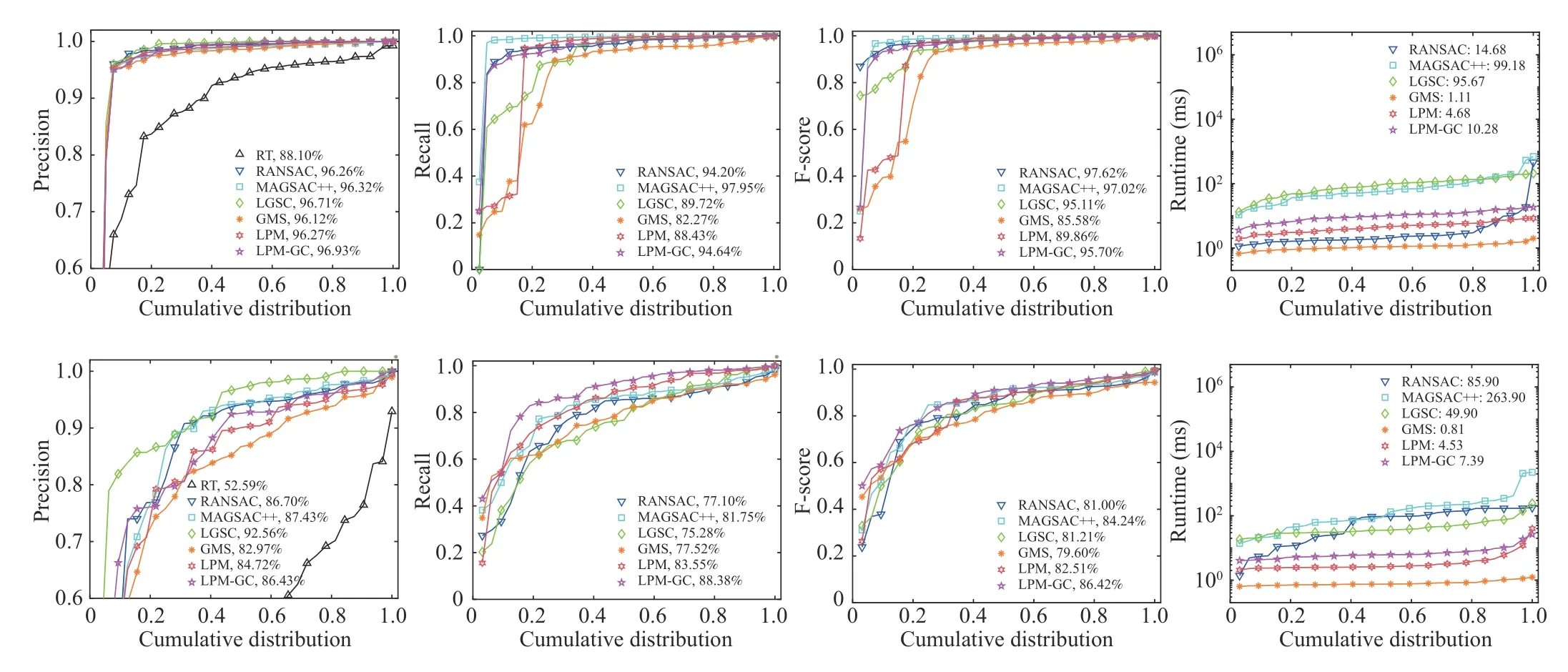
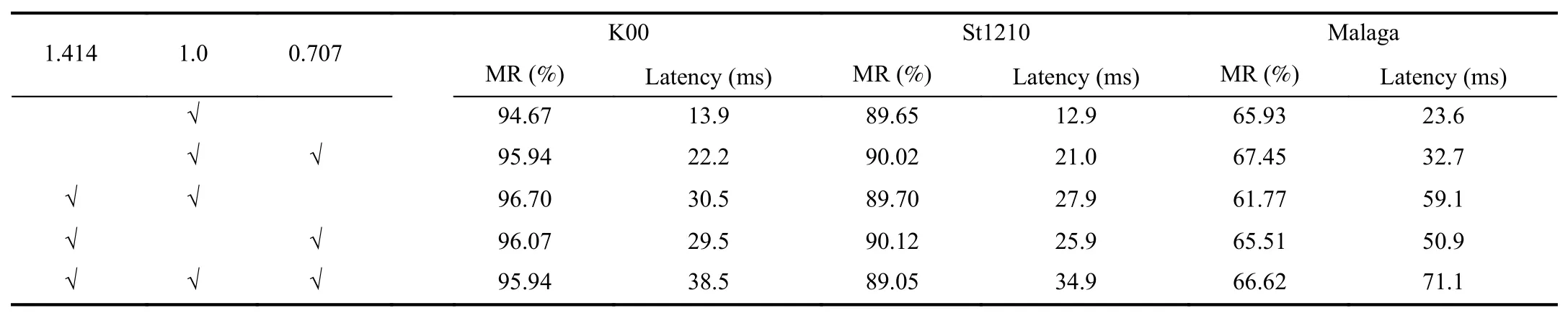
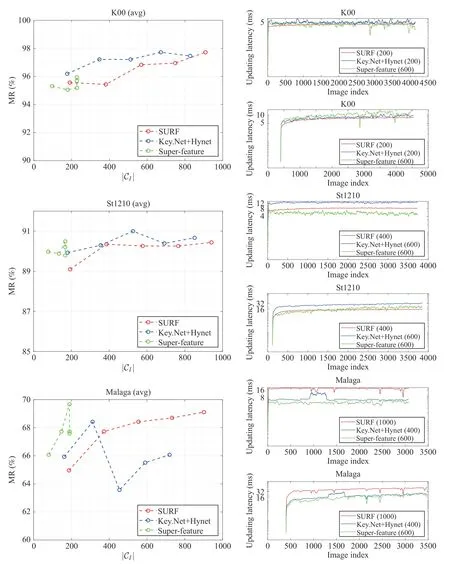
4) Computational Complexity Analysis:ForNpoints,the time complexity of searchingKmnearest neighbors for each of themis aboutO((Km+N)logN).Because the correspondingKm(m If the cardinality of the inlier set | I∗| preserved by LPM-GC is sufficient enough (i.e.,|I∗|>σ1),the image pair is most likely to represent the same scene.Nevertheless,it does not mean a loop-closing pair could be verified due to the existence of strong perceptual aliasing examples (i.e.,several distinct places look similar).For this,only loop-closing events that persist over time are retained.This operation is termed as temporal consistency check and we follow the way in [6] to achieve it.Specifically,we use the vector e to record how many times each database image is marked as a loop-closing event.As such,the temporal consistency factor θrof the reference imageIrcan be denoted as where er,ejrespectively indicate ther-th,j-th elements of thevector e (i.e.,the image ID of a database image),andNTrepresents the number of images acquired up to timeT.A larger θrindicates a higher probability of the occurrence of a falsepositive event.So far,the trigger of a loop-closing event is confined to two conditions: i) | I∗|>σ1ii) θr<σ2. TABLE I INFORMATION OF THE USED DATASETS In this section,the performance of our method is evaluated with the state-of-the-art competitors in both feature matching and LCD tasks.Next,we first give a brief introduction of the experimental setup in our work,and then illustrate our results.We run our codes on an Intel(R) Core(TM) i9-9920X CPU @3.50GHZ machine with three TITAN RTX GPUs.All operations are conducted on CPU excluding the extraction of Super-features. Datasets:Ten challenging sequences are selected for evaluation,and their detailed information is shown in Table I.Due to the rich visual information including high resolution and frame rate provided by the recorded data,the scenes in KITTI sequences [58] are relatively easy to allow successful loop closure identification.In contrast,K02 is the most challenging one among the four due to the existence of dynamic cars and illumination changes.St.Lucia [59] involves long-termtraversals,suffering from large illumination changes and plenty of dynamic occlusions (cars and pedestrians).The frame rates of the four sequences in it are downsampled to 3 Hz to avoid high content overlap among consecutive images.Regarding Malaga [60],images in it are collected on repetitive and very close roads,which easily leads to strong perceptual aliasing examples.It is collected by a stereo camera and only the right camera measurements are chosen for evaluation.All sequences introduced before are car-mounted trajectories,while CC [23] is a ground one collected by a mobile robot.Loop-closing pairs in it are equipped with wide baseline or large depth difference due to the variable speed of the robot.It also comprises stereo images and we adopt the streams recorded by the left camera to evaluate. Ground Truth:In the case of LCD,ground truth (GT) is composed of a binary matrix to suggest the relationship between an image pair.Specifically,if a true loop-closing event happens between imagesIiandIj,then GTijis equal to 1 otherwise to 0.It is initially produced in accordance with GPS information,where image pairs captured shorter than a distance metric range of 40 meters are labelled as true loopclosing events.Nevertheless,this would lead to false labels for some image pairs,typically when two images look similar,yet the captured distance surpasses the GPS’s threshold.To tackle this problem,the combination of proximity in space and equality in appearance is considered in [10] to generate refined GT.Concretely,the GT files are refined by manually checking each labeled pair and we exploit human-labeled GT matrices provided in [10] for evaluation. Evaluation Metrics:Both feature matching and LCD tasks adoptPrecisionandRecallfor evaluation.The former is the ratio between true positives and all system identifications,whereas the latter is that between true positives and ground truth.Additionally,F−socre=(2·Precision·Recall)/(Precision+Recall)is applied for comprehensive evaluation in feature matching,and thethe maximum recall rate at 100% precision(MR) is used in LCD.In the evaluation of LCD,tuples of precision and recall are generated by the varied threshold σ1.Meanwhile,an identification would be regarded as a true positive when it locates within 10 neighboring frames of the true loop-closing examples indicated by GT. Implementation and Parameter Illustration:In the procedure of geometric verification,we extract top-500 SURF [61]features for each image.A thorough parameter illustration of our approach is presented in Table II.We set those of ASMK,LPM-GC (excludingr,λ) and LCD (excluding T,σ1) according to [16],[45] and [6],respectively,while that of T in LCD is set empirically.Later,we would vary the value of σ1to generate different tuples of (Precision,Recall) in the LCD task,thus we denote its value by “”in the table. To determine the optimal values ofrandλin LPM-GC,we create a small dataset (LCD) by collecting 32 true loop-closing pairs from the LCD datasets shown in Table I.Then putative sets of these image pairs are created by SIFT and ratio test(RT) with a threshold of 1.5,and true correspondences are identified by manually checking each of the putative match.Experimental results are shown in Fig.5.Whenrvaries from 0 to 0.04,the left plot illustrates the average clusters formed inthe 32 different scenes according to the length of motion vectors.We conduct a group of experiments and foundr=0.02 can achieve stable performance on loop-closing pairs.Thus we setr=0.02 in the subsequent experiments.In this case,the number of clusters is approximately equal to 17.Afterwards,considering the objective function of our LPM-GC defined in (16),we report the distribution ofci(i.e.,the cost of neighborhood topological structure) and(i.e.,the cost of neighborhood topological structure with global consensus constraint) in the middle and right plots of Fig.5.Clearly,the separability between inliers and outliers has been enhanced by introducing the global consensus constraint.According to the results in the right plot of Fig.5,we set λ=0.8 to discriminate inliers and outliers. TABLE II PARAMETER ILLUSTRATION To evaluate the performance of LPM-GC on feature matching,six feature matching methods involving RT in SIFT [55],RANSAC [18],MAGSAC++[38],LGSC [47],GMS [46] and LPM [45] are selected for comparison.For this,another dataset (VGG) is created in the same way whereLCDis created.The detailed information of the two datasets is as follow: -VGG:This dataset is made up of 40 image pairs collected in [62],mainly composed of situations with wide baseline or image pairs with homography transformation.We select 30 image pairs for evaluation,where the average size and inlier ratio of the putative sets attain 744 and 80.14%,respectively. -LCD:This dataset is composed of 3 2 image pairs collected from the LCD datasets shown in Table I.Scenes in this dataset are challenging for feature matching due to the existence of similar structures and dynamic occlusions.The average size and inlier ratio of the putative sets attain 351 and 52.59%,respectively. Intuitive Results:Fig.6 presents intuitive feature matching results of seven methods in three common LCD situations extracted fromLCD.The first one describes an outdoor situation with strong illumination changes and similar structures(trees),the second one includes camera distortions,repetitive patterns (windows) and a dynamic occlusion and the third one shows a simple scene occurring commonly between a loopclosing pair but also with some similar structures.The corresponding precisions,recalls and F-scores are labelled in the image pairs.From the results,we can see that since the existence of illumination changes and similar structures mentioned above,the discrimination capability of SIFT descriptors is poor,and that is why the precisions of RT are unsatisfactory.Regarding the parametric methods RANSAC and MAGSAC++,their F-scores are extremely poor in the second scene.It is because the lowinlier ratio and non-rigid deformation caused by the camera distortion make the mfail to estimate a good solution.It seems that the graph-based method LGSC is not good at recalls in the three scenes,which is possibly caused by its strict condition of identifying an inlier.GMS achieves feature matching based on a statistic framework.Thus to get a satisfying result,the size of the putative set should be large.In the challenging scenes,some false matches also have consistent local information,which would lead vanilla LPM to preserve the mincorrectly.By introducing the global constraint in our LPM-GC,the weakness of LPM could be improved and that's why LPM-GC performs marginally better than LPMin the three scenes. Quantitative Results:A more comprehensive quantitative evaluation result is illustrated in Fig.7.It can be seen that the performance of RANSAC and MAGSAC++drops dramatically inLCD.Compared with recall,both LGSC and GMS are better at precision.Conversely,our LPM-GC is better at recall,but it yields a notable boost in both precision and recall compared with LPM.Overall,LPM-GC has high F-scores in the two feature matching datasets,which indicates its capability of generating satisfying precision-recall trade-off. The runtime statistics of different methods are presented in the fourth column of Fig.7.It can be seen that RANSAC is fast when dealing withVGG,but becomes slowinLCD.MACSAC++and LGSC are slowin both datasets.GMS spends very little time but its results on precision and recall metrics are not satisfying.Due to the requirement of mean shift clustering,LPM-GC generally costs several milliseconds more than LPM,but it is still fast and only needs about 10 ms in average to establish reliable matches,which can satisfy the real time requirement of LCD. The response score of a Super-feature can be reflected by its L2-norm.To perform ASMK,a codebook of 65536 clusters is first learned by extracting top-1000 Super-features from each training image of SfM-120k [63] (involving totally 20000 images) at a single image scale.The testing configuration of FIRe involves restricting the input image to a maximum resolution of 1024 pixels and extracting Super-features from the image at 7 resolutions/scales{2.0,1.414,1.0,0.707,0.5,0.353,0.25}.This costs about 101.1 ms for a K00 instance with the resolution of 1024×311 (downsampled from 1241×376),which cannot satisfy the real time requirement for the LCD task.So in order to guarantee both performance and efficiency,we experiment with different image pyramids on K00,St1210 and Malaga.The results are shown in Table III.It can be seen that the image pyramid of [1.0,0.707] can achieve a trade-off between MR and latency,thus we choose it to conduct the subsequent experiments. Fig.5.Parameter analysis.Left: the change of cluster number with respect to the radius parameter r.Middle: the distribution of ci in (16) (i.e.,the cost of neighborhood topological structure).Right: the distributi on of ci+in (16) (i.e.,the cost of neighborhood topological structure with global consensus constraint).For each bin,we overlap the inlier and outlier probabilities,where the one with smaller probability is shown in the outer layer. Fig.6.Fromtop to bottom,intuitive feature matching results of seven approaches including RT [55],RANSAC [18],MAGSAC++[38],LGSC [43],GMS[46],LPM [45] and our LPM-GC.The inlier percentages are 52.03%,30.77% and 69.18% in the three scenes,respectively.In each group of results,the head and tail of each arrow in the right motion field correspond to the positions of two corresponding feature points in the left image pair (black=true negative,blue=true positive,red=false positive,green=false negative).For visibility,the true negatives are not shown in the left image pairs.The corresponding precisions,recalls and F-scores are labelled in the image pairs. We also want to show how Super-features achieve memory wise efficiency in the LCD task.As analyzed earlier,the memory footprint of a database imageIcan be measured by the number of non-empty ASMK clusters in it,i.e.,clusters with at least one assignment which can be denoted as |C(I)|.We choose the other two features,involving a handcrafted one(SURF) and a learning-based one (Key.Net [64]+Hynet [65])3https://github.com/axelBarroso/Key.Net-Pytorchfor comparison.The codebooks in the three settings (SURF,Key.Net+Hynet,Super-features) are learned accordingly in the way described before.We vary the number of features extracted before aggregation in {200,400,600,800,1000} and show the results in Fig.8.Three conclusions can be drawn from the results.First,when extracting more than 600 features,Super-features at most use 228.11,167.20 and 189.86 clusters of the codebook on K00,St1210 and Malaga,while the number of clusters used by SURF and Key.Net+Hynet scales up with that of extracted features.This can reflect the compactness of Super-features,which is beneficial to memory saving in the LCD task.Second,the updating/querying latency in ASMK is closely related to the number of used clusters.Thus using Super-features can satisfy the real time requirement of LCD task.Third,the advantage of Super-features can be shown in more challenging scenes where dynamic occlusions (St1210) or similar structures (Malaga)appear. Fig.7.Quantitative feature matching performance of LPM-GC and five competitors on VGG (top) and LCD (bottom).As the putative set is constructed on SIFT and RT,we show the curve of RT in the precision plot,which also reflects the inlier rate.The coordinate (x,y) on the curves means that there are 100∗x percents of image pairs which have precisions,recalls,F-scores or runtime no more than y. TABLE III LCD RESULTS ON DIFFERENT IMAGE PYRAMIDS Evaluation with Varied Feature Matching Methods:Different feature matching methods including RANSAC,LPM and LPM-GC are exploited to conduct geometric confirmation to demonstrate the superiority of LPM-GC in the LCD task.All evaluations are carried out with 600 Super-features extracted,and the results are shown in Table IV.It can be seen that RANSAC performs consistently worse than the other two approaches on all datasets excluding K06,meanwhile with more running time cost.As for LPM,it performs marginally worse than LPM-GC on all datasets excluding K00 and St1545.The performance gap attains largest on CC.Overall,through using LPM-GC,we can significantly improve MR with an extremely low cost of efficiency. Efficiency Analysis of The LCD Pipeline:Before,only one candidate frame (k=1) is searched for each query image to perform geometric verification.This procedure only costs about 9.0 ms via LPM-GC,thus we want to continue to explore how the performance would change when we increase the number of candidate frames.Table V shows the LCD results ofk=1,3,5.It can be concluded that MR generally tends to increase as the number of selected candidate frames grows.But a largerkalso leads to lower efficiency.We observe that executing LPM-GC three times only costs 26.5 ms,meanwhile leading to satisfying performance on MR.So afterwards we would only discuss under the case ofk=3 the efficiency of our LCD system together with comparative results with other state-of-the-art LCD approaches. The runtime plots of each component of our LCD system on K00 and Malaga datasets are presented in Fig.9.Specifically,“Extracting”involves extracting Super-features of the query image and the image used for updating the inverted file,thus it is actually performed twice.Similarly,“Matching”involves extracting SURF features for two images as well as performing LPM-GC three times.In addition to the fact that the querying time grows as the database expands,the executive time of other parts remains stable.Overall,totally 141.8 ms and 160.4 ms would be cost when performing LCD on K00 and Malaga,respectively. Failure Cases:The navigation paths of four sequences involving K00,St1410,Malaga and CC,together with the respective identified loop closure events of them,are depicted in Fig.10.It can be observed that false-negative events would unavoidably occur when the appearance changes significantly.For example,instances captured at the same crossroad with different orientations,or scenes dominated by dynamic occlusions,may both lead to failure of loop closure identification. Fig.8.Performance versus memory footprint and executive latency for SURF,Key.Net+Hynet and Super-feature.Left: |C I| shows the average number of clusters per image used in ASMK (proportionate to memory usage).Right: For Super-feature,we showits executive time of extracting 600 features.For the other two,we show their executive time of the cases where i) better performance than Super-feature-600 appears with relatively few features extracted,or ii) the best performance of itself is achieved if no result is better than Super-feature-600.Relevant information has been labelled in the legend. TABLE IV MR (%) WHEN USING DIFFERENT FEATURE MATCHING METHODS FOR LOOP CLOSURE IDENTIFICATION.“MEAN LATENCY”INDICATES THE AVERAGE RUNNING TIME OF ONE MISMATCH REMOVAL.THE BEST RESULTS ARE LABELLED IN BOLD TABLE V MR (%) WHEN DIFFERENT NUMBER OF CANDIDATE FRAMES IS EXPLOITED FOR LOOP CLOSURE IDENTIFICATION.“MEAN LATENCY”SHOWS THE AVERAGE RUNNING TIME FOR EXECUTING LPM-GC ONCE,THREE TIMES AND FIVE TIMES,RESPECTIVELY Fig.9.Executive time per image for each main processing step of LCD system,measured on datasets with relatively large resolutions. Fig.10.Illustration of the LCD task.From left to right: true positive,robots’ trajectory,and false positive.Fromtop to bottom: K00,St1410,Malaga,and CC.The black trajectory is acquired from GPS logs,and the results of loop closure identification are obtained under the maximum recall rate at 100% precision.We label the loop closure pair as red hollow points,along with connecting themvia a blue line.The red and green solid points are the specific illustrations of true-positive and false-negative detections,respectively. Comparative Results:Table VI shows the comparative results of our approach against the state-of-the-art LCD techniques.Specifically,the reproducing results of [10],[28],[31],[66] are cited from [10];those of [8] are cited from [8];those of [27] are reproduced by ourselves on the basis of available codes.It can be seen that our approach can yield the best results on all datasets expect for CC.The performance gaps among different methods on KITTI sequences are relatively smaller than those on St.Lucia sequences.It is due to the fact that instances in KITTI datasets comprise abundant prominent features,which makes it relatively easy for approaches to identify true loop-closing pairs.However,when scenes turn more challenging in St.Lucia datasets,the superiority of our feature-matching-based LCD approach comes into being.The remarkable performance on St.Lucia datasets also hints that our method has the potential to be put to long-term driving tasks.As for Malaga,nearly all approaches yield poor results on it by virtue of extremely high similarity of scenes.Regarding CC,we perform marginally worse than FILD++and ESA-VLAD,but still achieve a satisfying result. In this paper,an effective method for the LCD task is introduced.We first perform candidate frame selection based on Super-features as well as an incremental ASMK strategy,and then achieve geometrical verification via a proposed feature matching technique termed as LPM-GC.From the experimental results we found that the combination of Super-features and ASMK can achieve both computational and memory-wise efficiency in the LCD task.As for LPM-GC,it focuses on recognizing reliable matches between image pairs on the basis of retaining local neighborhood information and global spatial consensus among the feature points,and hence it can deal with complex scenes in LCD such as image pairs with many repetitive patterns or large mismatch proportions.More importantly,our LPM-GC has a closed-form solution which can fulfill the verification of one image pair in only a few milliseconds,enabling the whole system to operate more efficiently.Through experiments,it is concluded that our feature matching-based LCD pipeline has great potential in the long-term SLAM system. TABLE VI COMPARATIVE RESULTS OF THE MAXIMUM RECALL RATE AT 100% PRECISION.ROLD INDICATES THE BEST APPENDIX DERIVATION OF (10) According to (8),the square items in (9) can be simplified and the cost function can be rewritten asC.Temporal Consistency

IV.EXPERIMENTAL RESULTS
A.Datasets and Settings

B.Results on Feature Matching
C.Analysis on Super-Features and ASMK

D.Results on Loop Closure Detection




V.CONCLUSION

杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- A Survey on Negative Transfer
- Three-Way Behavioral Decision Making With Hesitant Fuzzy Information Systems:Survey and Challenges
- Data-Driven Control of Distributed Event-Triggered Network Systems
- Driver Intent Prediction and Collision Avoidance With Barrier Functions
- Distributed Nash Equilibrium Seeking for General Networked Games With Bounded Disturbances
- Position Measurement Based Slave Torque Feedback Control for Teleoperation Systems With Time-Varying Communication Delays