A Survey on Negative Transfer
2023-03-09WenZhangLingfeiDengLeiZhangandDongruiWu
Wen Zhang,Lingfei Deng,Lei Zhang,,and Dongrui Wu,
Abstract—Transfer learning (TL) utilizes data or know ledge from one or more source domains to facilitate learning in a target domain.It is particularly useful when the target domain has very few or no labeled data,due to annotation expense,privacy concerns,etc.Unfortunately,the effectiveness of TL is not always guaranteed.Negative transfer (NT),i.e.,leveraging source domain data/know ledge undesirably reduces learning performance in the target domain,and has been a long-standing and challenging problem in TL.Various approaches have been proposed in the literature to address this issue.However,there does not exist a systematic survey.This paper fills this gap,by first introducing the definition of NT and its causes,and reviewing over fifty representative approaches for overcoming NT,which fall into three categories: domain similarity estimation,safe transfer,and NT mitigation.Many areas,including computer vision,bioinformatics,natural language processing,recommender systems,and robotics,that use NT mitigation strategies to facilitate positive transfers,are also reviewed.Finally,we give guidelines on NT task construction and baseline algorithms,benchmark existing TL and NT mitigation approaches on three NT-specific datasets,and point out challenges and future research directions.To ensure reproducibility,our code is publicized at https://github.com/chamwen/NT-Benchmark.
I.INTRODUCTION
A common assumption in traditional machine learning is that the training data and test data are drawn from the same distribution.However,this assumption does not hold in many real-world applications.For example,two image datasets may contain images taken using cameras with different resolutions under different light conditions;different people may demonstrate strong individual differences in brain-computer interfaces [1].Therefore,the resulting machine learning model may generalize poorly.
A conventional approach to mitigate this problem is to recollect a large amount of labeled or partly labeled data,which has the same distribution as the test data,and then train a machine learning model on the new data.However,many factors may prevent easy access to such data,e.g.,high annotation costs and privacy concerns.
A better solution to the above problem is transfer learning(TL) [2],or domain adaptation (DA) [3],which tries to utilize data or know ledge from related domains (called source domains) to facilitate learning in a new domain (called target domain).TL was first studied in educational psychology to enhance a human’s ability to learn new tasks and to solve novel problems [4].In machine learning,TL is mainly used to improve a model’s generalization in the target domain,which usually has a very small number or no labeled samples.Many different TL approaches have been proposed,e.g.,traditional TL [5]–[8],traditional deep TL [9],[10],and adversarial deep TL [11]–[13].
Unfortunately,the effectiveness of TL is not always guaranteed,because the following assumptions could be violated:1) task correlation,i.e.,the learning tasks in the two domains are related/similar [14],[15];2) domain correlation,i.e.,the source domain and target domain data distributions are not too different [2],[16];and,3) ideal joint error,i.e.,a suitable hypothesis can be applied to both domains [17],[18].Violations of these assumptions may lead to negative transfer (NT),i.e.,introducing source domain data/know ledge in an undesirable manner decreases learning performance in the target domain,as illustrated in Fig.1.NT is a long-standing and challenging issue in TL [2],[14],[16].

Fig.1.An example of NT in semi-supervised TL.In the first row,we transfer clipart airplane images to real airplane images.The TL algorithm achieves much better performance than supervised learning on the target domain labeled data only.In the second row,we transfer from face images to real airplane images.NT occurs if TL results in worse performance;otherwise,it is a positive transfer.
Interestingly,NT was not first studied in machine learning;instead,it has been a widely studied topic in educational psychology [19],[20].Take language learning for example,NT occurs when learning in one context hurts performance in another context,and is caused by contrasts in vocabulary,pronunciation,and syntax.Positive transfer,the opposite of NT,occurs when learning in one context improves the performance in another.
Recently,NT has been found in various machine learning applications,e.g.,computer vision,bioinformatics,natural language processing,and robotics.For instance,in robot trajectory tracking [21],NT occurs when transferring from an unrelated experience,which may lead to wrong or dangerous operations.In brain-computer interfaces [8],large individual differences make it impractical to train a classifier on a source subject and then use it directly on a target subject.
In summary,when source domains are weakly related,or even unrelated,to the target domain,brute-force sharing of them may decrease target domain learning performance.Even more dangerously,the source domains or models may be malicious,e.g.,suffering from data poisoning or back door attacks [22].In this case,the target model’s performance may significantly degrade,or even be easily manipulated by the attacker,after TL.Therefore,studying NT facilitates more reliable and safer transfers in real-world applications.
The following fundamental problems need to be addressed for positive TL [23]: 1) what to transfer;2) how to transfer;and,3) when to transfer.Roughly speaking,determining“what to transfer”explores which part of know ledge can be shared across domains,“how to transfer”considers the algorithm details of the TL approach,and “when to transfer”examines whether the source data/know ledge should be transferred or not for a particular application scenario.Most TL research[3],[24] focuses only on the first two problems by implicitly assuming that the source and target domains are related to each other,whereas all three should be taken into consideration to avoid NT.
To our know ledge,NT in TL was first studied in 2005 [14],and received increasing attention recently [16],[25],[26].Various ideas,e.g.,finding similar parts of domains and evaluating the transferability of different features/tasks/models,have been explored.Though very important,there does not exist a comprehensive survey on NT so far.
This paper presents the first comprehensive survey on NT in weakly-supervised learning.More than 50 representative approaches for coping with NT are systematically reviewed.We hope it can attract more research interests to this important area,and eventually ensures positive transfer.
A.Scope
This survey focuses on NT theorems,techniques for determining when to transfer,approaches for avoiding NT under theoretical guarantees,and approaches for mitigating NT.Articles that do not explain their approaches from the perspective of NT are not included,in order to make it more focused on dealing with NT.Furthermore,different from existing TL surveys [2],[27],which separately introduce feature/instance/model/relation based TL,we categorize current approaches related to NT according to three key questions: when,what,and how to transfer,with domain similarity estimation,safe transfer,and NT mitigation as the corresponding areas.These distinguish this survey from previous TL surveys.
Readers who want to have a comprehensive understanding of TL can refer to [2],[3],[18],[23],[27].Specifically,[2] is one of the earliest and most classical TL surveys,[3] introduces the evolutions of TL in the last decade,[27] is the latest comprehensive survey on TL,and [18] focuses on theory advances of DA.Reference [23] is a book on TL.
B.Outline
The remainder of this paper is organized as follows.Section II introduces background know ledge in TL and NT.Section III reviews methodologies for handling NT,including domain similarity estimation,safe transfer,and NT mitigation strategies.Section IV describes representative applications that need to deal with NT.Section V provides NT-specific benchmarks and experiments.Section VI presents summaries and discussions.Finally,Section VII draws conclusions and points out future research directions.
II.BACKGROUND KNOWLEDGE
This section introduces some background know ledge on TL and NT,including the notations,definitions of NT,causes of NT,and related fields.
A.Notations and Definitions
The main notations are summarized in Table I.
In TL,the condition that the source and target domains are different (i.e.,S ≠T) implies one or more of the following:
1) Heterogeneous Feature Spaces:The feature spaces are different,i.e.,XS≠XT.
2) Heterogeneous Label Spaces:The label spaces are different,i.e.,YS≠YT.
3) Conditional Shift:The marginal distributions of the features are the same,but the conditional distributions are different,i.e.,PS(X)=PT(X) andPS(Y|X)≠PT(Y|X).
4) Covariate Shift [28]:The feature conditional distributions are the same,but the marginal distributions of the features are different,i.e.,PS(Y|X)=PT(Y|X) andPS(X)≠PT(X).
5) Label Shift [29]:The label conditional distributions are the same,but the marginal distributions of the labels are different,i.e.,PS(X|Y)=PT(X|Y) andPS(Y)≠PT(Y).
6) Generalized Label Shift [30]:The label conditional distributions of the original data transformed bygare the same,but the marginal distributions of the features are different,i.e.,PS(g(X)|Y)=PT(g(X)|Y) andPS(Y)≠PT(Y).
7) Expansion Assumption [31]:The feature conditional dis-tributions are different,and the target data distribution has good continuity within each class and good separability among different classes,i.e.,PS(Y|X)≠PT(Y|X) andPT(Y=k|neighborhood ofX)≥cPT(Y=k|X),wherec>1 is a constant.

TABLE I MAIN NOTATIONS IN THIS SURVEY
This survey considers all above differences,i.e.,heterogeneous TL for different feature spaces,open set TL for different label spaces,TL for covariate shift or conditional shift,and TL under the label shift,generalized label shift or expansion assumption.
TL aims to design a learning algorithmA(S,T),which utilizes data/information in the source and target domains to output a hypothesis (model)h=A(S,T),with a small expectedwhereℓis a task-specific loss function.
B.Definition of NT
There are several qualitative descriptions for NT.Rosensteinet al.[14] first discovered NT in TL through experiments,and concluded that NT occurs if the tasks between domains are too dissimilar.Pan and Yang [2] found that when the source domain and target domain are unrelated,a direct transfer may be unsuccessful;even worse,it may hurt learning performance in the target domain,which is referred to as NT.Wanget al.[16] introduced a mathematical definition of NT recently.
We use the following definitions of NT in semi-supervised TL and unsupervised TL,respectively.
Definition 1(Negative Transfer in Semi-Supervised TL):Let S be a labeled source domain,T={Tl,Tu} be a target domain with some labeled samples Tland unlabeled samples Tu,Abe a TL algorithm,A′be a machine learning algorithm from the parameter space Gwith the same type of classifier/regressor asA,ϵTbe the test error in the target domain,A(S,T)be a learning algorithm between S and T,andA′(∅,T)be a machine learning algorithm trained only on the target domain labeled samples.Then,NT occurs if
i.e.,NT comes from source data and/or the TL algorithm ifand from the TL algorithm only if ϵT(A(S,T))>
Note that the above definition of NT is algorithm-specific,i.e.,one should compare a TL algorithm with a machine learning algorithmA′for the same type of classifier or regressor with and without the source data [16].For instance,a feature adaptation-based TL strategy with support vector machine(SVM) [32] as the classifier should be compared with the original SVM algorithm to judge whether NT occurs.Additionally,A′should be adequately optimized in its parameter space G.
In unsupervised TL,the target domain is completely unlabeled,so ϵT(A′(∅,T)) cannot be computed,and the basic baseline is a random guess.
Definition 2 (Negative Transfer in Unsupervised TL):Let S be a labeled source domain,Tube a target domain with some unlabeled samples,Abe a TL algorithm,A′be a machine learning algorithm from the parameter space G with the same type of classifier/regress or asA,ϵTbe the test error in the target domain,andA(S,Tu) be a learning algorithm between S and Tu.Then,NT occurs if
In other words,in unsupervised TL,NT occurs when the target test error of TL is larger than a random guess,or the error of a baseline algorithm of the same type.
C.Causes of NT
Previous research has attributed NT to various causes.For example,Rosensteinet al.[14] pointed out that NT occurs if the tasks in different domains are too dissimilar,indicating that the domain similarity or the divergence between two distributions is a crucial cause.Wanget al.[16] argued that except for domain divergence,the TL algorithm and the size of the labeled target data may also contribute to NT.
The causes of NT can also be revealed by observing the factors of successful TL.Ben-Davidet al.[17] developed a theoretical bound for DA
where ϵT(h) and ϵS(h) are respectively the expected error ofdH∆H(Xs,Xt)is the domain divergence between the two domains,and λ is a problem-specific constant.NT occurs hypothesishin the source domain and the target domain,when the following terms are too large: 1) the expected error in the source domain;2) the discrepancy between the source and target domains;and,3) the error of a shared hypothesis between the two domains.The components involved are the source domain S,the target domain T,the domain divergenced,and the TL algorithmθ.
Summarizing all results above,we propose the following four causes of NT:
1) Large Domain Divergence:Arguably,the divergence between the source and target domains is the root of NT.TL approaches that do not consider minimizing the divergence,whether at the feature,parameter,classifier,or target output level,are more likely to result in NT.

Fig.2.Approaches for dealing with NT.
2) Poor Source Data Quality:Source data quality determines the quality of the transferred know ledge.If the source data are inseparable,class-imbalanced or very noisy,then a classifier trained on them may be unreliable.Sometimes the source data have been converted into pre-trained models,e.g.,to reduce the transmission cost,and/or for privacy-protection.An over-fitting,under-fitting,or poisoned source domain model may also cause NT.
3) Poor Target Data Quality:The target domain data may be noisy and/or non-stationary,with an open or compound domain boundary,or include open classes and label shift,which may also lead to NT.
4) Inappropriate TL Algorithm:No TL algorithm is universally optimal.Each has its assumptions and specific application scenarios.Choosing an inappropriate TL algorithm for a particular application may result in NT.Additionally,almost all TL algorithms have some hyper-parameters to tune,e.g.,the trade-off between ϵS(h) anddH∆H.Using non-optimal hyper-parameters may also lead to NT.
D.Related Fields
Several research fields are closely related to NT,including but not limited to: machine unlearning,multi-task learning,lifelong learning,and adversarial attacks.
1) Machine Unlearning:Aims to preserve data privacy in trained models by unlearning sensitive samples [33],[34].There are two main techniques: a) Removing sensitive data and retraining on the remaining data [34];and,b) Approximately unlearning by modifying the pre-trained weights under an unlearning criterion by gradient ascent [35].From the approximate unlearning perspective,promoting NT on the private data facilitates privacy preservation.
2) Multi-Task Learning:Solves multiple learning tasks jointly,by exploiting commonalities and differences across them[36].Similar to TL,it needs to facilitate positive transfer among tasks to improve overall learning performance on all tasks.Previous studies [37],[38] have observed that conflicting gradients among different tasks may induce negative interference.
3) Lifelong Learning (Continual Learning):Learns a series of tasks in a sequential order,without revisiting previously seen data.While the goal is to master all tasks in a single model,there are two key challenges,which may lead to NT.First,the model may forget earlier know ledge when trained on new tasks,known as catastrophic forgetting [39],[40].Second,transferring from previous tasks may hurt the performance of later tasks.
4) Adversarial Attacks:Reveal the vulnerability of machine learning models.Some adversarial attacks poison the source data,so that the target domain learning performance is significantly degraded,or the target output can be manipulated by a back door [22].Specific adversarial attacks targeting at TL models have also been proposed [41].
Taking into account these related fields,our review mainly focuses on overcoming NT in TL,i.e.,improving TL performance in the target domain.
III.METHODOLOGY
This section introduces existing approaches for alleviating or avoiding NT from the perspectives of when,what,and how to transfer.
As shown in Fig.2,we categorize existing approaches into three groups,namely:
1) Domain Similarity Estimation:Domain similarity indicates the closeness between a source domain and the target domain,or the transferability of a particular source domain.Existing approaches can be categorized into three groups: a)Feature statistics based,which estimates the domain similarity based on the feature statistics;b) Test prediction based,which estimates the domain similarity based on the test performance of the source models in the target domain or a domain classifier;and,c) Fine-tuning based,which estimates the domain similarity based on the fine-tuning framework.
2) Safe Transfer:Safe transfer aims to overcome NT with theoretical guarantees,regardless of how dissimilar the source and target domains are.There are two categories of such approaches: a) Safe classification transfer,which avoids NT in classification problems through max-min gain or performance gain;and,b) Safe regression transfer,which avoids NT in regression problems through output limit or error restriction.
3) NT Mitigation:NT mitigation focuses on alleviating NT,based on the assumption that the source domain has some similarity with the target domain.There are four main directions:a) Data transferability enhancement,which includes domain/instance/feature/class level transferability enhancements of the source and target domains;b) Model transferability enhancement,which enhances source model training and target model adaptation;c) Training process enhancement,which enhances TL algorithm training by hyper-parameter tuning and gradient correction;and,d) Target prediction enhancement,which enhances target prediction by pseudo labeling,entropy regularization,etc.
To determine when to transfer,representative approaches of domain similarity estimation are reviewed.For what and how to transfer,representative approaches of safe transfer and NT mitigation are introduced.
Note that these three categories of approaches use different strategies to alleviate or overcome NT.They complement each other,and can be combined for better performance.
A.Domain Similarity Estimation
Domain similarity (or transferability) estimation focuses on when to transfer.Accurate estimation of this similarity helps to decide whether the source data/know ledge should be transferred or not,and determine which strategy should be used to deal with NT,e.g.,not transfer at all when the similarity is too low,and transfer when different domains have adequate similarity.
This subsection only reviews estimation strategies for determining whether the source know ledge should be transferred or not.Approaches that reweight or select different source domains are introduced in Section III-C-1 “Domain-level transferability enhancement”.
Existing estimation approaches can be categorized into three groups: feature statistics based,test performance based,and fine-tuning based,as summarized in Table II.

TABLE II APPROACHES FOR DOMAIN SIMILARITY ESTIMATION
1) Feature Statistics Based Domain Similarity Estimation:The original feature representation and its first-or high-order statistics,such as mean and covariance,are direct and important inputs for measuring the domain distribution discrepancy.Some widely used domain discrepancy measurements are maximummean discrepancy (MMD),KL-divergence,correlation coefficient,etc.
MMD [42] is a nonparametric divergence measure,and can be computed directly from the feature means in the raw feature space or a mapped reproducing kernel Hilbert space(RKHS).Empirically,the MMD between the source and target domains can be computed via
whereϕis a kernel function,andx s,iandx t,jare source and target domain samples,respectively.Wang and Carbonell [43]proposed an extension of MMD by simultaneously considering a source domain’s MMD-based proximity to the target domain and its transferability to other source domains.
Similar to MMD,KL-divergence [61] has also gained growing popularity [44],[45].For instance,Gonget al.[44] proposed a rank of domain (ROD) approach to rank the similarities of the source domains to the target domain,by computing the symmetrized KL divergence weighted average of the principal angles.
Correlation coefficient,clustering quality,or scatter matrices,have also been used.The correlation between two highdimensional random variables from different distributions can be used to evaluate the distribution discrepancy.For example,Lin and Jung [46] evaluated inter-subject similarity in emotion classification via the correlation coefficient of the original feature representations from two different subjects.Meiseles and Rokach [60] introduced a clustering quality metric,mean silhouette coefficient [62],to assess the quality of the target encodings produced by a given source model.They found that this metric has the potential for source model selection.To fully utilize the source label information,Zhang and Wu [47] proposed a domain transferability estimation (DTE)index to evaluate the transferability between a source domain and a target domain via between-class and between-domain scatter matrices
Additionally,the Hilbert-Schmidt independence criterion[63],Bregman divergence [64],optimal transport,Wasserstein distance [65],etc.,have also been used to measure the feature distribution discrepancy in conventional TL.
2) Test Prediction Based Domain Similarity Estimation:The domain similarity can also be measured from the test prediction.There are three types of such approaches: target performance,domain classifier,and consensus focus.
One straightforward strategy is to assume there are some labeled samples in the target domain,and if a source domain classifier performs well on labeled target data,then the domains should be similar.Xieet al.[48] proposed selective transfer incremental learning (STIL) to remove less relevant source (historical) models.STIL computes the following Qstatistic as the correlation between a historical model and the new ly trained target model
wherefiandfjare two classifiers.is the number of samples for which the classification result isyibyfi(y i=1 ifficlassifies the example correctly;otherwiseyi=0),andyjbyfj.STIL then removes the less transferable historical models,whose Q-statistics are close to 0.This strategy was also used in [49].
The above approaches require the know ledge of a sufficient number of labeled target samples,or the trained target model,which may not always be available.Another practical strategy is to train a domain classifier to determine which domain each sample comes from,and then define a similarity measure from the classification error [17],[51].Ben-Davidet al.[50] proposed an unsupervised A-distance to find the minimum-error classifier
where H is the hypothesis space,ha domain classifier,and ϵ(h) the domain classification error.The A-distance should be small for good transferability.Unfortunately,computingdA(µS,µT)is NP-hard.To reduce the computational cost,they trained a linear classifier to determine which domain the data come from,and utilized its error to approximate the optimal classifier.However,A-distance based approaches neglect the differences in the label spaces and only consider the marginal distribution discrepancy between domains,which may degrade their estimation precision.Wu and He [52] proposed a novel label-informed divergence between the source and target domains,when the target domain is time evolving.This divergence can measure the shift of joint distributions,which improves the A-distance.
Similar to the domain classifier strategy,Zuoet al.[66]introduced an attention-based domain recognition module to estimate the domain correlations.Given thei-th source domain withKcategories,it redefines the instance labels of each source domain byand trains a domain recognition model from them.The learned weight of thei-th domain is
wherentis the target training batch size,andthe domain label of a target instancexjfrom the domain recognition model.The authors verified that the learned domain weights are highly correlated with oracle target performance.
Recently,an unsupervised domain similarity estimation strategy,consensus focus [53],was proposed to weight the given source models.It assumes there areMpre-trained source modelsand some unlabeled target samples Tu.It first computes a consensus quality of multiple source models
wherep i(S) is a vector of confidences thatx ibelongs to different classes,predicted by model S,andis the number of domains in whichp iis larger than a pre-defined confidence threshold.Then,it defines a consensus focus to quantify the contribution of a source modelSmto the consensus quality of all source models S
The consensus focus can be used to estimate the weight of each source model
whereNmis the number of samples in them-th source domain.Compared with target performance based approaches,or domain classifier based approaches,this strategy requires fewer resources and is more computationally efficient.
3) Fine-Tuning Based Domain Similarity Estimation:Finetuning is a popular deep TL technique that adapts a pre-trained deep model to the target domain,by freezing its lower layers and re-training the higher layer parameters with some labeled target samples [9],[67].Domain similarity estimation approaches in this line of work include label based approaches,as well as label and feature representation based approaches.
The first strategy considers the correlation between the predicted target label and the true target label.Tranet al.[54]developed negative conditional entropy (NCE),which measures the amount of information from a source domain to the target domain,by evaluating conditional entropy between the pseudo target labels and the real target labels.Nguyenet al.[55] proposed log expected empirical prediction (LEEP),which improves NCE by using soft predictions of the target samples.Given a source modelθand a target domain Tlwithnllabeled samples,LEEP can be computed by
Another strategy considers the learned feature representations and the real target labels simultaneously.Afridiet al.[56] introduced a mutual information based approach,by computingI(Yt,Z|),whereZandare the feature and pseudo labels obtained from a pre-trained model,respectively.Baoet al.[58] developed an H-score to characterize the discriminability of feature representations for classification using the sample covariance matrix.Ibrahimet al.[59] improved the accuracy of covariance matrix estimation in the H-score by introducing a regularized covariance matrix.Youet al.[68] proposed a logarithm of maximumevidence (Log ME),which computes the similarity by maximizing the marginal likelihood by optimizing some Bayesian statistics.Huanget al.[57] developed a transfer rate (Trans Rate) strategy by computing the mutual information with coding rate
whereYtare the labels of the target samples,andR(Z,ϵ) is the rate distortion ofH(Z) to encodeZwith an expected decoding error less thanϵ.They showed that Trans Rate has appealing performance in selecting the source data,source model architecture,and even network layers.
Generally,fine-tuning based strategies are only proposed for fine-tuning TL so far.Extending them to other TL approaches is a promising future direction.
B.Safe Transfer
Safe transfer focuses on positive transfer with theoretical guarantees,and can be used regardless of whether the source and target domains are similar or not.Safe transfer explicitly avoids NT in its objective function,i.e.,the TL algorithm should perform no worse than its counterpart without transfer.
As shown in Table III,there are only a few safe transfer approaches.Some of them consider only classification problems,whereas others consider only regression problems.

TABLE III EXISTING SAFE TRANSFER APPROACHES
1) Safe Transfer for Classification:Safe transfer for classification can be achieved through max-min gain,or optimizing performance gain.
For the former,Liet al.[25] proposed a safe weakly supervised learning (SAFEW) approach for the semi-supervised DA.Assume the target hypothesish∗can be constructed from multiple base learners in the source domain,i.e.,are theMsource models and αi∈[0,1].The goal is to learn a predictionhthat maximizes the performance gain against the worst baselineh0,which is trained on the labeled target data only,by optimizing the following objective function:
i.e.,SAFEW optimizes the worst-case performance gain to avoid NT.Note that,the basic assumption that the target hypothesis can be represented by multiple source learners may not always hold in real-world applications.
For the performance gain strategy,Jamalet al.[69] proposed a deep face detector adaptation approach to avoid NT by maximizing the performance gain from the source detector to the target one,by minimizing the following residual loss function
2) Safe Transfer for Regression:TL in regression problems is also an important research topic [72]–[74].Safe transfer for regression can be achieved through output limit,error restriction,and adaptive transfer.
For the output limit strategy,Kuzborskij and Orabona [70]introduced semi-supervised TL based on the regularized least squares (RLS) approach [32] with biased regularization to avoid NT.The original RLS algorithmsolves the following optimization problem:
They also theoretically verified that the proposed approach is equivalent to the RLS approach trained solely in the target domain when the source domains are unrelated to the target domain.
For the error restriction strategy,Sorockyet al.[71] derived a theoretical bound on the test error and proposed a Bayesianoptimization based approach to estimate this bound to guarantee positive transfer in robot trajectory tracking.Firstly,they bounded the 2-norm of the tracking error of the target robot using the source module by
whereEt,sis the transfer function of the robot tracking system,andydthe desired output of the source module.Given the baseline target tracking error et,b,this bound can guarantee positive transfer ifSinceydis fixed and known,the authors established a Gaussian Process model to estimateand compute the error bound,guaranteeing positive transfer.
For the adaptive transfer strategy,Caoet al.[15] proposed a Bayesian adaptive learning approach to realize safe transfer.It assumes the source and target data obey a Gaussian distribution with a semi-parametric transfer kernelK
wherekis a valid kernel function.ς(x n,x m)=0 ifx nandx mare from the same domain,and ς(x n,x m)=1 otherwise.The parameterρrepresents the dissimilarity between the source and target domains.By assumingρis from a Gamma distribution with shape parametersband the scale parametersμinferred from a few labeled samples in both domains,(20) can be transformed tok(x n,x m) α,whereαis the similarity between domains and is computed as
The transfer kernel is defined from the domain similarity.When α →0,only the shared parameters in the kernel function are transferred.When 0<| α|<1,it serves as a weight to adjust the influence of the source data.In other words,this approach can adaptively determine which setting the problemfalls into and avoid NT.
In summary,although safe transfer avoids NT with theoretical guarantees,there are relatively few such approaches,and most of them considered parameter-based shallow TL,whereas deep learning based TL becomes more popular recently.Future research on deep learning based safe transfer is desired.
C.NT Mitigation
In most TL problems,the source and target domains have some similarity,and the main task is to mitigate NT.This can be achieved by data transferability enhancement,model transferability enhancement,training process enhancement,and target prediction enhancement,as shown in Table IV.
1) Data Transferability Enhancement:The transferability of the source and the target domain can be enhanced by improving the data quality from coarse to fine-grained,at the domain level,instance level,feature level,or class level.
i) Domain level transferability enhancement:There are three directions to enhance domain level transferability: a)domain selection and weighting,b) domain decomposition,and,c) intermediate domain construction.

TABLE IV APPROACHES FOR NT MITIGATION
The first is usually used when there are multiple source domains.In multi-source DA,selecting the most similar ones to the target domain,or a weighted aggregation of all source domains,may achieve better target learning performance than simply using all source domains [66],[143].Similarity estimation approaches introduced in Section III-A can be applied to each source domain,and then the similarities can further be utilized to reweight or select source domains.
To decide how to transfer with multiple sources,some studies computed the similarities of multiple source domains by solving a convex optimization problem[75],[76].For example,Ahmedet al.[75] optimized the weights of the source domains using only pre-trained source models.They first developed a TL loss function Ltarrelated to the weight of each source modelS m.Then,the domain weights are optimized by
With the learned weights,the target model can select domains with high similarity,or weight the source model predictions.Similar ideas were also investigated in [73],[76].In multi-source DA [76],the weights are computed by optimizing the distance between the convex combination of the source distributions and the target distribution.In regression DA [73],the weights are estimated by adversarial training,which can be further utilized to optimize the weighted squared loss and weighted domain classification loss.
The second strategy is domain decomposition,which decomposes the source and target domains into different parts,and facilitates know ledge transfer based on them.These approaches include subdomain adaptation and intra-domain adaptation.
Zhuet al.proposed subdomain adaptation [77] to align finegrained sub-distributions rather than global distributions.They decomposed the source and target distributions into subdomains by the samples’ categories,and minimized the following divergence metric
wherepkandqkare the distributions of thek-th class of the source and target domains,respectively.By minimizing (23),the distributions of relevant subdomains from the same class are brought closer.
Similar to the subdomain strategy,Kimand Kim[78] proposed a semi-supervised intra-domain adaptation approach to accommodate the intra-domain discrepancy,i.e.,the unlabeled target data are far from the labeled ones after TL.They decomposed the target domain into aligned and unaligned parts,and then minimized the intra-domain discrepancyd(S∪Tl,Tu)to move the unaligned target subdomain toward the aligned clusters.
The third strategy is to construct one or more intermediate domains to bridge the source and the target domains,when their distribution discrepancy is too large.Approaches include distant TL,domain mixup,and gradual DA,as illustrated in Fig.3.

Fig.3.Illustration of distant transfer,domain mixup,and gradual DA.Best viewed in color.
Distant TL,or transitive TL [79],[80],aims to bridge different source and target domains through one or more intermediate domains when they share little common know ledge.Tanet al.[80] introduced a selective learning algorithm(SLA) to identify target-related data from the source and intermediate domains based on the assumption that similar data can be reconstructed via the same auto-encoder.SLA re-weights the source and intermediate data and performs the following two optimizations alternatively:
a) Minimize the classification error on the labeled data and the prediction entropy on the unlabeled data to train a better auto-encoder.
b) Fix the auto-encoder and minimize the reconstruction error on all domains to adjust the weights,i.e.,to select a proper subset of data that are related to the target domain.
Their experiments showed that SLA effectively reduced the large domain discrepancy,by using data in different label spaces as intermediate domains.
There are very few distant TL approaches;however,this strategy has demonstrated great potential in transferring know ledge between two very different domains.
Domain mixup constructs intermediate domains by augmenting the source and target data.Naet al.[81] proposed FixBi,which applied a fixed ratio-based mixup to augment multiple intermediate domains between the source and target domains.Letbe a pair of input samples and their corresponding one-hot labels in the source domain,andbe a pair in the target domain.Domain mixup is achieved by
where λ is a fixed ratio,e.g.,0.7.The above process is repeated twice with two mixup-ratios λ1and 1−λ1to generate two intermediate domains close to the source domain and the target domain,respectively.A similar idea was investigated in [82],which adopts mixup in the source and target hidden representations.
Gradual DA [83],[84] assumes domain shift happens gradually,and there exist a sequence of unlabeled intermediate domainsI1,...,IMfrom the source domain to the target domain.Kumaret al.[83] proposed a self-training strategy to gradually adapt from S to T through theseMintermediate domains to generate the final target model
whereS T(·,·) denotes the self-training process,and the domain sequence has auxiliary unlabeled data.However,in practice,it is challenging to separate the extra unlabeled data into intermediate domains.To accommodate this problem,Chen and Chao [84] proposed a coarse-to-fine framework to discover a sequence of intermediate domains when they are not already available.
In summary,domain level transferability enhancement is aimed at removing irrelevant or malicious source domains.It is an effective way to mitigate NT when the domain shift is large.
ii) Instance level transferability enhancement:Instance selection and instance weighting are frequently used in TL [2],[3],[27].They can also be used to mitigate NT.
For instance selection,Seahet al.[85] proposed a predictive distribution matching (PDM) regularizer to remove irrelevant source samples.It iteratively infers the pseudo-labels of the unlabeled target domain data and retains the highly confident ones.Finally,a support vector machine (SVM) or logistic regression classifier [32] is trained using the remaining source domain data and the pseudo-labeled target domain data.Active learning [86],[87],which selects the most useful unlabeled samples for labeling,can also be used to select the most appropriate source samples [88],[89].Penget al.[88]proposed active TL to optimally select source samples that are class balanced and highly similar to those in the target domain.It simultaneously minimizes the MMD and mitigates NT.If the unlabeled target domain samples can be queried for their labels,then active learning can also be integrated with TL for instance selection [144],[145].
For instance weighting,Xuet al.[90] partitioned source data into components by clustering,and assigned them different weights by iterative optimization.Yanget al.[91] proposed a curriculummanager embedded in the domain discriminator loss to optimize the weight of each source sample with a constraint on the sum of weights.Wanget al.[16] developed a discriminator gate to achieve both adversarial adaptation and class-level weighting of the source samples.For a specific source samplex iand its predicted labely,they input(x i,y) into a discriminatorD(x i,y) and calculated the weightw(x i,yi) byD(x i,y)/(1−D(x i,y)),which represents the distribution density ratio of the two domains.Then,they optimized the following weighted supervised learning loss to mitigate NT:
whereCandFare respectively the classifier and the feature extractor.The overall architecture is illustrated in Fig.4.It has a theoretical guarantee that L(C,F) is an unbiased estimate of the target classification error [146].Similar ideas were also investigated in regression transfer [92],[93].For instance,Garcke and Vanck [92] focused on inductive TL with kernel ridge regression,and proposed model and distribution based weight estimation strategies to alleviate the negative influence of unrelated instances.
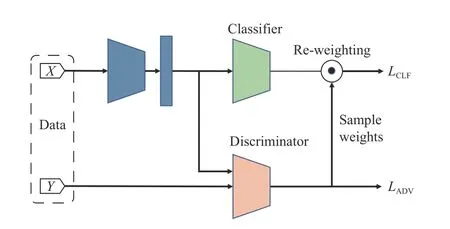
Fig.4.Wang et al.’s [16] instance weighting strategy for mitigating NT in semi-supervised TL.The source and target domains share the same feature extractor.The source samples and their predicted labels are concatenated and input to the discriminator.The target model is trained with a weighted classification loss and an adversarial loss.
iii) Feature level transferability enhancement:These approaches usually focus on feature space decomposition,or improving the transferability of feature representations.
The former decomposes each domain into common and domain-specific features,instead of seeking a single feature space that can represent all domains well.Longet al.[94] proposed dual TL to decompose the feature space into common feature clusters and domain-specific feature clusters,through non-negative matrix tri-factorization:
whereXSis the source domain feature matrix,UandUSare respectively common and domain-specific feature clusters,VSis a sample cluster assignment matrix,andHis the association matrix.The common part is shared across domains to bring different distributions closer,whereas the domain-specific part maintains domain-specific know ledge.The sharing level can be controlled by the similarity between the two domains,thus helping mitigate NT.Shiet al.[95] improved dual TL by introducing a similarity graph strategy.A latent space strategy was also investigated in heterogenous TL [96]by learning two different feature mappings.
Another prominent line of work,particularly used in deep TL,is to enhance feature transferability during feature extractor learning.Yosinskiet al.[147] defined feature transferability based on its specificity to the domain in which it is trained and its generality.Multiple approaches have been proposed to compute and enhance feature transferability [97]–[100].For example,Chenet al.[98] found that features with small singular values have low transferability in deep network fine-tuning.They thus proposed a batch spectral shrinkage strategy to reduce NT,by suppressing the small singular values of the feature matrices with the following regularization term:
whereFdenotes the feature representations,kis the number of singular values to be penalized,and σ−irefers to thei-th smallest singular value.The overall architecture is illustrated in Fig.5.
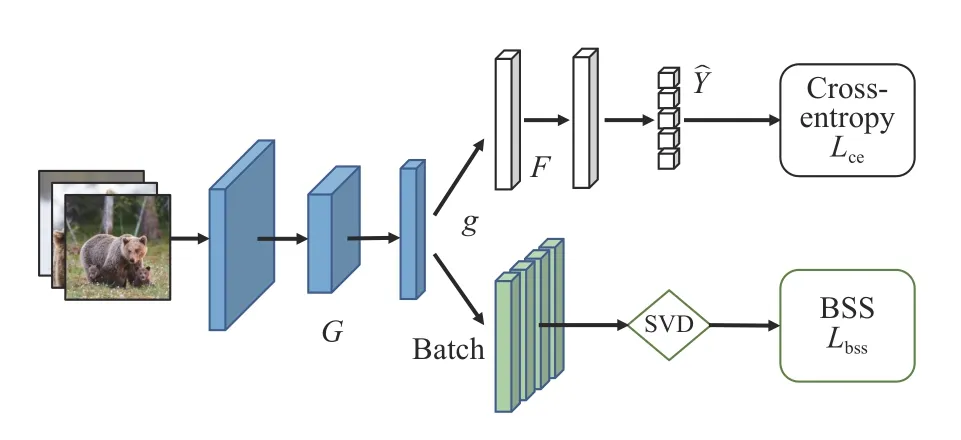
Fig.5.Chen et al.’s [98] batch spectral shrinkage strategy to enhance feature transferability.The source and target domains share the same feature extractor G.Singular value decomposition (SVD) is performed on the extracted features.The target model is trained by minimizing a source classification loss and a batch spectral shrinkage loss.
In addition,multi-view representations may also benefit feature transferability [101].To alleviate the NT phenomenon caused by intra-domain shift with multi-view features,Liet al.[101] proposed a dynamic classifier alignment strategy to dynamically re-weight multi-view features based on an auxiliary importance classifier.
Unfortunately,focusing only on improving the feature transferability may lead to poor discriminability.It is necessary to consider both feature transferability and discriminability to mitigate NT.To this end,Chenet al.[99] proposed enhancing feature transferability with guaranteed discriminability,by using batch spectral penalization regularization on the largest few singular values.Some other works [7],[148],[149] also investigated the balance between feature transferability and discriminability.
iv) Class level transferability enhancement:Most TL approaches assume that the source and target domains share the same label set and label distributions [6],[12],i.e.,YS=YTandPS(Y)=PT(Y).However,these assumptions may not always hold in many real-world applications [30],[102],[104].If the source and target domains have different label spaces,then a TL algorithm that transfers the outlier source classes to the target domain would mis-align the features of outlier source classes to certain target classes,migrating harmful know ledge from the source domain to the target domain and hence leading to NT [106],[107].If the source and target domains have the same label space but large label shifts,then the source model could classify most target samples wrong,leading to severe NT [102],[103].
The following scenarios have been studied:
a) Close set TL with label shift [29],[30],[102],where the source and target domains share the same label space,same conditional distribution,but different label distributions,i.e.,YS=YT,PS(X|Y)=PT(X|Y),andPS(Y)≠PT(Y).Label shift is common in many real-world scenarios,e.g.,the source domain has a balanced label distribution whereas the target domain has severe class-imbalance.Liptonet al.[29] proposed three strategies,shift detection,weight estimation,and classifier correction,to accommodate label shift.Liet al.[103] found that the source model trained with a simple balance sampling strategy can significantly reduce label shift in source-free TL.Combeset al.[30] expanded the label shift concept,by weakening the conditional distribution assumption.They tried to find an intermediate feature representation for both domains,instead of using the original input space.
b) Open set DA [104] or partial DA [107],where the source label space is a superset of the target label space,i.e.,YT⊂YS.Busto and Gall [104] tackled open-set DA using a class mapping from the source domain to the target domain.For partial DA,Zhanget al.[105] proposed a weighted adversarial nets based approach to identify source samples that are potential outliers.Caoet al.[106] proposed a selective adversarial network (SAN) with multiple class-wise domain discriminators,each matching the source and target data for a specific class,to identify and remove outlier source classes to mitigate NT.Caoet al.[108] proposed an example transfer network,which solves partial DA by adding source sample transferability weighting to the source classifier loss function.
c) Universal DA [109],where the source and target label spaces share some common classes,but each also has its own private classes,i.e.,YT∩YS=Y,YSY ≠∅,and YTY ≠∅.The main strategy for mitigating NT is to f ilter out unrelated source data belonging to the outlier label space YSYT.Youet al.[109] proposed a universal DA network,which quantifies instance-level transferability to discover the common and private label sets,and promotes adaptation in the common label set.Saitoet al.[110] introduced an entropy separation loss to align the target samples in common categories while keeping the target private categories far away from the source.Kunduet al.[111] investigated source-free universal DA,by using an instance-level weighting mechanismto remove the target domain private classes.He and Wu [150] proposed a label alignment approach for different set (universal) DA in EEG-based brain-computer interfaces.The basic idea is to align each class in the source domain to a randomclass in the target domain.Even though the two classes may be different,the alignment still improves DA performance.
2) Model Transferability Enhancement:Model transferability enhancement can be performed in source model training and target model adaptation.
i) Source model training enhancement:Due to the data transmission cost and/or privacy concerns,the source domain may only provide a pre-trained model,instead of its data.Training a source model with high transferability can alleviate NT when fine-tuning in or adapting to the target domain.The enhancement can be achieved through transferable batch normalization (BN),adversarial robust training,and training multiple source models.
The first technique is to introduce a transferable batch normalization module to improve traditional normalization,e.g.,BN [151],under domain shifts.Liet al.[112] first revealed that the mean and variance of the BN layer contain domain specific characteristics,and proposed adaptive BN (Ada BN)to adapt the representation across different domains.Wanget al.[113] proposed transferable normalization (Trans Norm)to reduce domain shift in BN,which is usually used after the convolutional layer to enhance model transferability.Letμandσbe the mean and variance of a BN layer.Trans Norm first quantifies thei-th (i=1,...,c) channel distance of the source and target domains in a layer as
whereϵis a small constant for numerical stability.Then,it computes a distance-based probabilityαto represent the transferability of each channel
With all αiestimated in a particular layer,the adapted features of the source and target domains with Trans Normare computed byz=(1+α)BN(x).In other words,model transferability can be enhanced by assigning more transferable channels with higher weights.The applications of Trans Normin CNN and the residual block are illustrated in Fig.6.Tanget al.[114] further proposed Cross Normand Self Norm,and showed that they performed best when plugged after the concatenation operation in a residual module.

Fig.6.Trans Norm[113] in CNN and residual block.
Another way to enhance the source model transferability is to improve its robustness to adversarial examples [152],usually accomplished by adversarial robust training.Adversarial examples are slightly perturbed inputs aiming to fool a machine learning model [153],[154].An adversarially robust model that is resilient to such adversarial examples can be obtained by replacing the standard empirical risk minimization loss with a robust optimization loss [152]
whereδis a small perturbation,εa hyper-parameter to control the perturbation magnitude,andθthe set of model parameters.Several recent studies [115]–[117] found that adversarially robust models have better transferability.Lianget al.[115] empirically verified that adversarially robust networks achieved higher transfer accuracies than standard Image Net models,and increasing the width of a robust network may increase its transfer performance gain.Salmanet al.[116]found a strong positive correlation between adversarial transferability and know ledge transferability;thus,increasing adversarial transferability may benefit know ledge transferability.
In addition,training multiple source models can also improve the model transferability.Laoet al.[118] showed that training multiple source models can increase the stability of the predictions in the optimization process.They defined a hypothesis disparity (HD) to measure the inconsistency among the predictions of two modelshiandhj
whered(·) is the cross-entropy between the prediction probability distributions of two hypotheses.With multiple source models,the estimated HD can be used to regularize target hypotheses learning.
ii) Target model adaptation enhancement:Such approaches mainly include parameter selection and parameter regularization.
Parameter selection focuses on identifying and selecting transferable parameters from the source model.For example,Hanet al.[121] proposed transferable parameter learning(Trans Par) to select valuable parameters from the source pretrained networks.Parameters in the feature extractor,domain discrepancy measurement module,and source classifier were divided into transferable and untransferable ones.The transferable parameter ratio of a certain moduleτis computed as
wheredAis the A-distance defined in (7).If the A-distance between two domains is large,then the ratioτis small,and there is little domain-invariant information.The parameter selection strategy was also investigated in SVM based parameter transfer [119],and tree boosting based parameter transfer[120].
Parameter regularization uses parameters from the source classifier,BN statistics,gradient distribution,etc.,as reference for regularization.An intuitive way is to reuse the source classifier parameters as the starting-point for the target,e.g.,2-normpenalty [122] or direct parameter sharing [123]between the target classifier and the source classifier.However,direct parameter sharing followed by fine-tuning suffers from over-fitting due to the limited size of labeled target data.To handle this problem,Liet al.[124] constrained the discrepancy between the outer layer outputs (i.e.,extracted feature maps) of the source and target models.Specifically,given a pre-trained source model with parameterw∗and input l abeled target datathey trained new model parameterswby optimizing
where the first termis the supervised training loss,and the second characterizes the feature map difference between the source and target models when trainingfwith the labeled target data.The overall architecture is illustrated in Fig.7.
Youet al.[125] proposed co-tuning to fine-tune the source model when the label spaces of the source and target domains are different,by learning the relationship between the source and target categories through a pre-trained source model.Zhanget al.[126] proposed side-tuning,an additive learning approach.For a given new target task and a source model,it trains a new task-specific model based on the pre-trained model and combines them for testing.
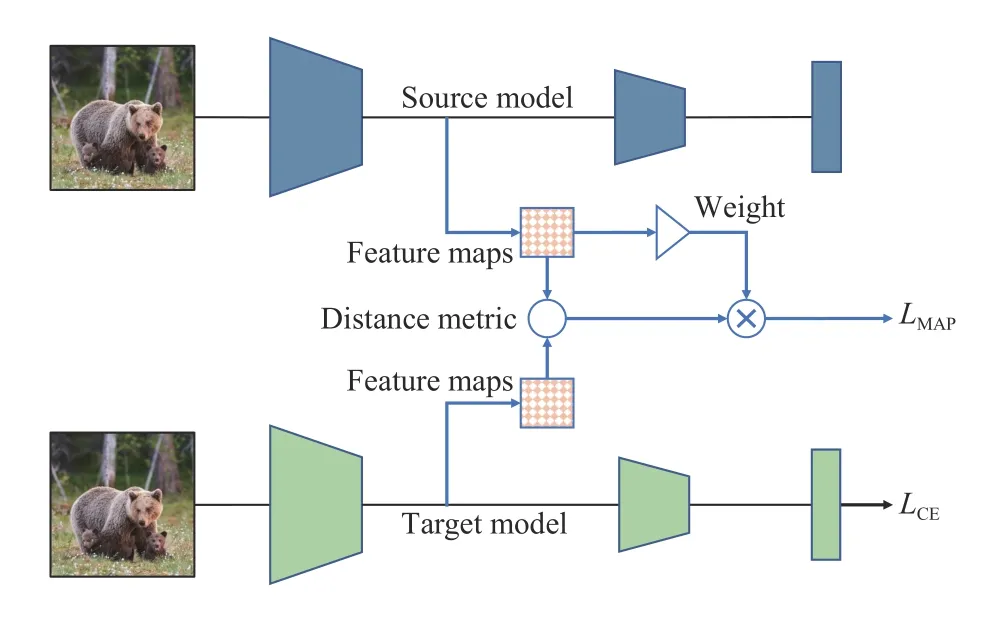
Fig.7.Li et al.’s [124] model adaptation approach based on feature map with attention.The feature maps are generated from convolutional filters of an outer network layer.They regularized the target model adaptation by referencing to the source feature maps under a distance metric.The target model is trained to minimize a cross-entropy loss LCE and a feature map regularization loss LMAP.
Some other works extracted information from the parameters of BN [127] and gradient distribution [128].For example,Ishii and Sugiyama [127] explored parameter regularization with BN statistics.They assumed the source and target domains share the same network architecture,i.e.,an encoder with a BN layer as the backbone,and proposed a BN-statistics matching loss,which computes the mean KL divergence between the target feature distribution and the approximated source feature distribution
whereθrepresents parameters of the encoder,is a mini-batch from the target data,Cis the channel number of the input features to BN,and µcand σcare the BN statistics of thec-th channel evaluated from the target mini-batch.By minimizing this loss,the target BN module can be regularized near the source BN parameters.
Transferability enhancement approaches are especially useful in transferring from pre-trained deep learning models.Enhancements to source model training and target model adaptation may be combined for better performance.
3) Training Process Enhancement:In traditional deep TL and adversarial deep TL,it is routine to design a TL loss like L=Lce+λLdiv,where Lceis the cross-entropy loss of the source or target domain to maintain the discriminability,Ldivis a domain divergence loss measured by MMD,domain discriminator,2-normdistance,etc.,to maintain the transferability,and λ is a hyper-parameter to balance the discriminability and transferability.Some approaches treat λ as a preset constant [6],[10];however,multiple studies have found that an inappropriate λ affects the success of TL and even leads to NT [129]–[131],[133],[134].Since different losses may have different step sizes and directions during gradient descent optimization,there are two categories of approaches to balance them: hyper-parameter tuning and gradient correction.
The first strategy is hyper-parameter tuning.Since there is usually no target-related validation set in TL,applying an algorithmto another scenario without hyper-parameter tuning easily leads to NT in practice.This phenomenon has been found in many parameter sensitivity experiments [7],[10].Some studies tried to estimate a suitable weight to mitigate NT [129].For example,Yoon and Li [129] proposed a parameter-based TL approach with a linear combination of empirical loss and regularizer based on pre-trained weights.They showed that NT arises when λ is too large,and thus,computed the weight by using the source target difference and the discrepancy between the target training and test data.Some other works mitigated this problemby dynamically tuning λ during the training process [11],[13],[130].For instance,the classical domain-adversarial neural network (DANN) [11]gradually changes the balance parameter from 0 to 1 by
wherepis the ratio of the current iteration number to the maximumiteration number in the training progress.
In addition to Lceand Ldiv,there are many other losses,e.g.,entropy minimization [142],virtual adversarial training [155],and consistency regularization [31].When there are multiple losses in the objective function,it is very important to determine their weights properly.Youet al.[132] proposed deep embedded validation to select the weight hyper-parameters.
The second strategy is gradient correction,which balances the gradient descent directions of different losses to avoid conflicts.Wanet al.[133] considered overcoming NT in deep TL
where Ω(w,ws) is the squared-Euclidean distance between the source and the target weights.The gradient of L(w) is∇J(w)+λ×∇Ω(w,ws).They found that NT may happen when the angle between the gradient direction of the regularization∇Ω(w,ws)and the gradient direction of the empirical loss∇J(w)is greater than 90◦.Then,as depicted in Fig.8,they reestimated a new descent direction of regularization
The final corrected descent direction iswhich can balance empirical loss minimization and parameter regularization.Lvet al.demonstrated that the gradient correction strategy was always better than the fine-tuning baseline.A similar gradient correction approach for unsupervised DA was proposed in [134],where a set of Pareto optimal solutions were obtained from optimizing all training objectives cooperatively.

Fig.8.The descent direction correction strategy in [133].
4) Target Prediction Enhancement:Pseudo-labeling is frequently used in TL when the target domain has few labeled samples but many more unlabeled samples.However,due to domain shifts,the pseudo labels are usually noisy,which may cause NT.Soft pseudo-labeling,selective pseudo-labeling,clustering enhanced pseudo-labeling,and entropy regularization,could be used to solve this problem.
Soft pseudo-labeling assigns each unlabeled sample to different classes with different probabilities,rather than a single class,in order to alleviate label noise [135]–[137].In traditional shallow TL,Dinget al.[137] introduced a label propagation strategy based on the target soft labels.In multi-adversarial DA [135],the soft pseudo-label of a target sample is used to indicate how much it should be emphasized by different class-specific domain discriminators.In deep unsupervised DA,Geet al.[136] proposed a soft softmax-triplet loss based on the soft pseudo-labels,which outperformed hard labeling.
The main motivation of selective pseudo-labeling is to select the unlabeled samples with high confidence as the training targets.For instance,Guiet al.[138] developed an approach to predict when NT would occur.They identified and removed noisy samples in the target domain to reduce class noise accumulation in future training iterations.Wang and Breckon [139] proposed selective pseudo-labeling to progressively select a subset containingmnt/Thigh-probability target samples in them-th iteration,whereTis the number of iterations of the learning process.Their experiments showed that this simple strategy generally improved the target prediction performance.
Clustering enhanced pseudo-labeling explores the unsupervised clustering information to enhance target prediction[123],[139]–[141].For example,Lianget al.[123] developed a self-supervised pseudo-labeling approach to accommodate inaccurate adaptation network outputs.It first performs weightedk-means clustering on the target data to get the class means
where θt=ft(gt(xt)) denotes the learned target network parameters,gt(·) is the feature extractor,ft(·) is the classification layer,and δk(·) is thek-th element in the soft max output.Withµk,the pseudo-labels can be updated by a nearest centroid classifier:
The centroids and pseudo-labels can be optimized iteratively to obtain better target predictions.In addition to introducing clustering ideas into the target predictions in a self supervised manner,some other works took the source data into consideration and aimed to match the class centroids[141] or prototypes [139] of different domains to enhance the target predictions.
Entropy regularization constrains the target predictions to be similar to their one-hot encodings [142],[156].For example,Lianget al.[123] introduced an information maximization loss by maximizing the mutual information between the target representationsXtand the target pseudo outputs
IV.APPLICATIONS
NT has been reported and studied in multiple applications,including computer vision,bioinformatics,natural language processing,recommender system,robotics,etc.This section briefly reviews the background,effects,and approaches to handling NT in some representative areas.
A.Computer Vision
Computer vision applications include object recognition[123],image segmentation [121],action recognition [158],face verification [69],etc.TL is popular in computer vision,where domain shifts caused by camera types,light conditions,scenario changes,etc.,are common.Unfortunately,NT is also prone to happen.Deep networks pre-trained on a common dataset (e.g.,Image Net) may contain target-unrelated biases,which could cause NT.One solution is to find a criterion for target-related pre-trained model selection [68].Another idea is to find a safe gradient descent direction to balance different losses [133].In addition,images from multiple source domains may have different styles,such as clipart and painting [159],which may be hard to transfer,leading again to NT.Finding a proper source selection criterion is important [53].
B.Bioinformatics
Bioinformatics applications include brain-computer interfaces [46],clinical analysis [160],coronavirus diagnosis [161],drug response prediction [162],etc.NT is also prevailing in bioinformatics due to individual differences,non-stationary signals,hardware differences,or poisoned source domains[163].Particularly,individual differences can be very large due to the complexity of the human physiological system,making it difficult to align the conditional distributions.Selecting target-related subjects [47],[162],data alignment[150],[164],finding related intermediate domains to bridge different domains [161],and active learning [145],have been shown helpful.
C.Natural Language Processing
Multilingual models have demonstrated success in processing tens or even hundreds of languages simultaneously[165].However,not all languages can benefit from this training paradigm.Studies [166] have revealed that,in multilingual models,especially when transferring from high-resource language models [165],the models trained from different languages may introduce language-specific know ledge to the target model,leading to inaccurate language translation or biased paragraph comprehension.One solution is parameter softsharing [167],which re-weights and combines classifiers trained on multiple source domains based on the relationship between the source and target domains.Meta-learning [166]and gradient vaccine [38] are also feasible approaches.
D.Recommender System
TL has been used to solve data sparsity and cold-start problems in recommender system,e.g.,web search ranking [168],behavioral targeting [169],and collaborative recommendation[170].NT may happen when user preferences and itemfeatures of different platforms are dissimilar or inadequately accommodated.In these cases,the recommender systemmay disturb users by recommending useless information.Finding common and domain-specific latent rating patterns simultaneously [168] can effectively handle this problem.Another idea is to re-weight know ledge learned from different source domains based on their relatedness [171].Zhanget al.[170]proposed a selective transfer strategy,which transfers knowledge only when the source and target domains share overlapping items.
E.Robotics
Transferring prior experience can facilitate learning in robot tracking [21],autonomous driving [172],intelligent fault diagnostics [173],and multi-agent learning [174].However,NT may happen when transferring from an unrelated system[21],[71],or adapting to unknown target environments [173],[175],leading to wrong or even dangerous operations.Sorockyet al.[71] guaranteed positive transfer by constraining the theoretical bound on the robot’s trajectory tracking error when transferring the source know ledge to the target.Using an attention mechanism[172],which re-weights the know ledge learned from previous tasks to help train a new task,has also been explored.Liet al.[176] avoids NT when adapting to unknown environments by a class weighted strategy,which removes unrelated source classes and encourages the transfer of the shared classes.
V.BENCHMARKS AND EXPERIMENTS
Many aforementioned approaches introduced their motivations from the perspective of avoiding or overcoming NT;however,most of them only demonstrated their superiority on existing datasets by showing performance improvement over existing TL approaches.Dedicated benchmarks to study NTshould be constructed to facilitate fair and comprehensive comparisons.This section discusses the strategies to construct negative tasks and baseline algorithms in studying NT,and compares over 20 conventional TL approaches and NT mitigation approaches on three NT-specific datasets.To our know ledge,no similar studies exist in the literature.

TABLE V STATISTICS OF THE THREE DATASETS
A.Negative Task Construction
To explicitly study NT in experiments,the impact of NT should be easy to observe,which requires the discrepancy between different domains to be large enough.This can be done by selecting tasks with significant shifts,or modifying existing datasets’ (e.g.,Domain Net and Vis DA-2017) marginal distributions,conditional distributions,and/or model decision boundary to increase the divergence [53],[121].
Specific approaches include:
1) Utilizing Prior Know ledge on Tasks:Generally,transferring from a poorly performing or unrelated source domain is more likely to degrade the target learning performance.Such prior know ledge is available in many applications,e.g.,a lowquality image dataset,or a poor-performing source subject in brain-computer interfaces.
2) Modifying Marginal Distributions:This strategy increases marginal distribution divergence between domains.Perturbations such as randomrotation and randomsalt and pepper noise can be added to cause misclassification for neural networks [16],[177].Affine transformations,e.g.,translation,scale,and rotation,on data distributions may also increase divergence [178].
3) Modifying Conditional Distributions:This strategy increases the conditional distribution divergence between domains.One implementation is data poisoning [53],i.e.,randomly choosing certain samples to shuffle their labels,or changing their labels to outliers.
4) Modifying the Model Decision Boundary:This strategy simulates the transfer from malicious source domains.Adversarial examples,obtained from adversarial attacks [41] or backdoor attacks [22],can be used to induce NT.
B.Baseline Algorithms
For fair and complete comparisons,we suggest that different baselines should be considered in studying NT,according to different TL scenarios:
1) Target Domain With Some Labeled Samples:In this scenario,four baselines may be included: a) a model trained in the source domain and applied directly to the target domain[12];b) a model trained only in the target domain;c) a model trained with the source and target domain samples combined[157];and,d) a model trained in the source domain and then fine-tuned in the target domain [69],[133].
2) Target Domain With Some Unlabeled Samples but no Labeled Samples at All:This scenario is widely studied in unsupervised DA.Three baselines may be included: a) randomguess;b) a model trained in the source domain and applied directly to the target domain [12],[53];and,c) a semisupervised model obtained by combining the labeled source data and unlabeled target data [179].
3) Target Domain Without Any Labeled or Unlabeled Samples:Two baselines may be included in this challenging scenario: a) the randomguess;and,b) a model trained in the source domain and applied directly to the target domain [12].
C.Experiments
To better understand how to construct NT tasks and evaluate the performance of some representative TL and NT mitigation approaches,we conducted extensive experiments on one synthetic dataset,and two real-world datasets on object recognition and emotion recognition.
1) Datasets:One synthetic dataset,Moon,and two realworld datasets,Domain Net and SEED,were used in our experiments.Their statistics are given in Table V.
i) Moon:A synthetic dataset generated by scikit-learn1https://scikit-learn.org/,which contains 9 domains with 2 categories.The target domain has 600 two-dimensional samples,generated by functionmake_moons(n_samples=600,noise=0.1).Several common geometric transformations [178] were applied to the target distribution to generate different source domains.Specifically,five affine transformations (translation,scale,rotation,shear,and skewed) to introduce marginal distribution shifts,and three additional transformations (noise,overlapping,and subclusters) to introduce conditional distribution shifts.Finally,we obtained nine domains,including the original distributions(Or) and eight transformed distributions: Translation (Tl),Scale (Sl),Rotation (Rt),Shear (Sh),Skewed (Sk),Noise(Ns),Overlapping (Ol),and Sub-clusters (Sc).Fig.9 shows the synthetic target domain and its transformed source domains.
ii) Domain Net [159]:A challenging object recognition dataset,containing 0.6 million images belonging to 6 domains spanning 345 categories.To reduce the computational cost,we first extracted 40 common classes used in [180],and selected three domains: Clipart (C),Infograph (I),and Painting (P).Then,20% instances in each domain were randomly sampled to construct the final NT-specific Domain Net,resulting in 1049,1462 and 1912 instances for Domains C,I and P,respectively.This dataset contains three domains with large feature shifts and an intrinsic label distribution shift across domains,making it suitable for NT study.
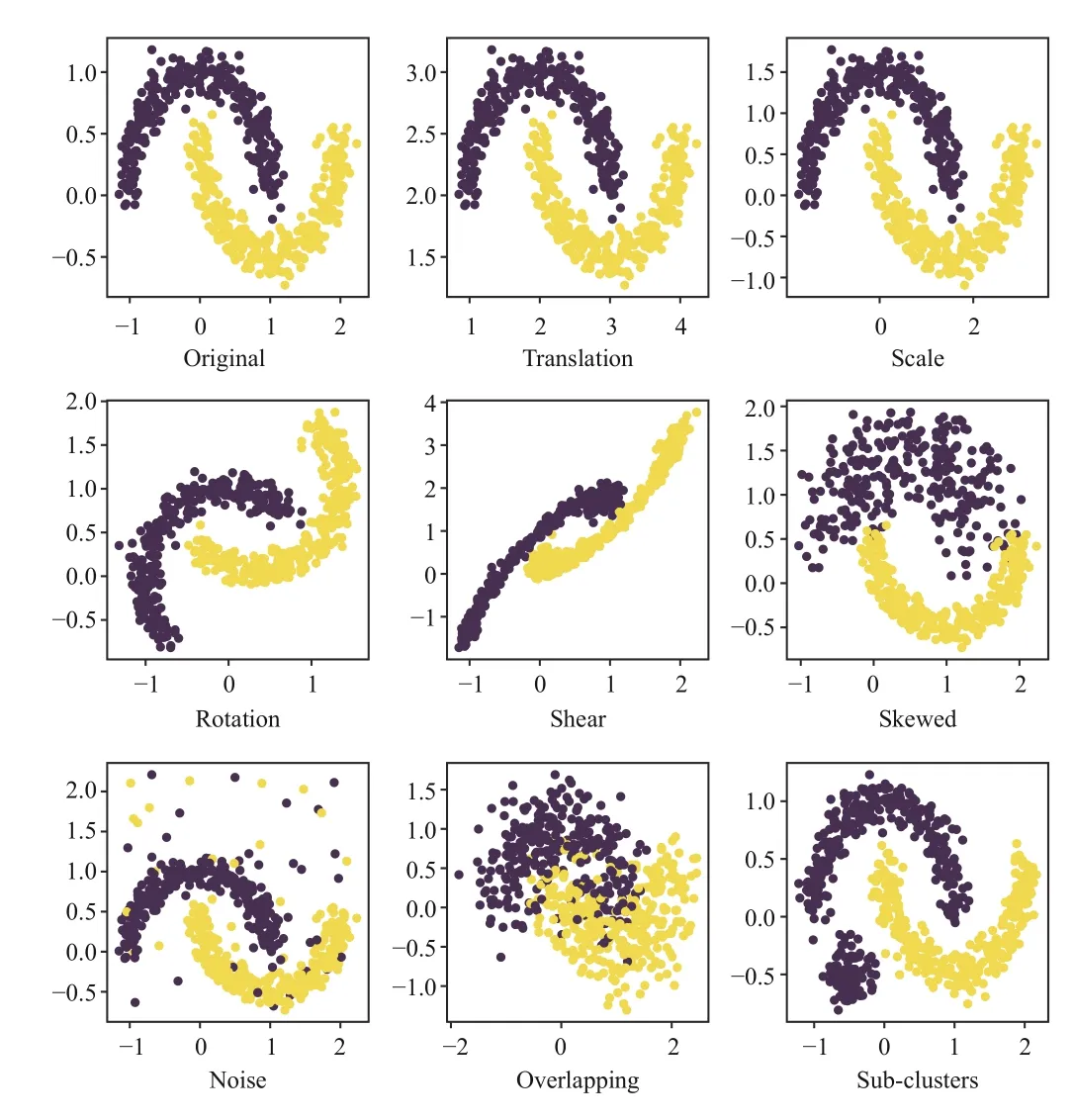
Fig.9.The synthetic Moon dataset,including the original target data and their replicas under eight transformations: translation,scale,rotation,shear,skewed,noise,overlapping,and sub-clusters.
iii) SEED2https://bcmi.sjtu.edu.cn/seed/seed.html:an electroencephalogram(EEG) based emotion recognition dataset,which contains 15 healthy subjects,each recorded with positive,neutral and negative emotions stimulated by video clips.Only the first three subjects,each with 3394 samples,were selected to construct a subset.We used the 310 pre-computed differential entropy features [181],extracted from different EEG channels in five frequency bands.Due to large individual differences,this dataset is suitable for evaluating NT mitigation approaches.
2) Experimental Settings:To provide a comprehensive study of NT,we evaluated several conventional TL approaches and NT mitigation approaches in both unsupervised TL and semi-supervised TL settings.The classification accuracy on the target unlabeled data was used as the performance measure.
i) Unsupervised TL:In this scenario,the target domain is completely unlabeled in unsupervised TL.We compared 12 TL approaches from three categories:
a) Baselines:including the randomguess,support vector machine (SVM) [32] and deep neural network (DNN).The randomguess approach predicts the target data as the dominant class of the source domain.The latter two were trained in the source domain and directly tested in the target domain.
b) Conventional TL approaches:including KMM [5],JDA[6],DAN [10],DANN [11],and CDAN [13].The first two are representative conventional instance and feature based approaches,respectively.The others are classical deep TL approaches.
c) NT mitigation approaches:including FixBi [81],ATDOC [182],MCC [142],and SHOT [123].
Note that on Domain Net,the inputs of SVM,KMM and JDA were the backbone features trained from DNN.SVM was the baseline for detecting NT for KMM and JDA,and DNN for other deep TL approaches.
ii) Semi-supervised TL:In this scenario,the 5% labeled target domain samples were used as the training set,and the remaining 95% unlabeled ones as the test set.Similarly,we compared 11 TL approaches from three categories:
a) Baselines:including T (training a DNN model only with the labeled target data) and S+T (training a DNN model with the source data and the labeled target data).
b) Conventional TL approaches:including fine-tuning(retraining a pre-trained source model head classifier with the labeled target data) [9],DAN,DANN,CDAN (these three were trained with the source and target labeled data combined),and ENT [156] by entropy minimization.
c) NT mitigation approaches:including MCC [142],SHOT[123],MME [157] and APE [78].
For fair comparisons,all above deep TL approaches were configured with the same backbone architecture.On Moon and SEED,we used a backbone with two fully connected layers (64 hidden units),each followed by a BN layer and ReLU activation.On Domain Net,the backbone was the pre-trained Res Net-50 [183].Following [123],we replaced the original fully connected layer with a bottleneck layer (1024 units) and a task-specific classifier layer.Additionally,a BN layer was added after the bottleneck layer.
All deep TL approaches were trained from scratch by minibatch gradient descent,with batchsize 32,momentum0.9,and initial learning rate 0.01.The initial fine-tuning learning rate was 0.001.The number of training epoches was 5 for SHOT,and 50 for all others.Additional algorithm-specific parameters were set according to their respective references.
D.Experimental Results on Moon
Table VI shows the accuracies when transferring from different transformed source domains to the target domain.The red down arrows indicate NT.For SVM and DNN baselines,the target accuracies were lower than 85% with translation(Tl),rotation (Rt),and shear (Sh) transformations,indicating they can introduce more marginal distribution shifts.The target test accuracies of DAN,DANN,and CDAN on Rt→Or and Sh→Or improved considerably,indicating these TL approaches were robust to rotation and shear transformations.Interestingly,when the source domains were transformed by noise (Ns),overlapping (Ol) and sub-clusters (Sc),DNN achieved over 99% accuracy,whereas neither DAN,DANN or CDAN achieved positive transfer.
In summary,these results demonstrate that neither KMM,DAN,DANN or CDAN can always ensure positive transfer,and each can fail in certain circumstances.
E.Experimental Results on Domain Net and SEED
Table VII shows the performances of 12 unsupervised TL approaches on Domain Net and SEED.KMM,JDA,DAN,DANN and SHOT always had positive transfer on Domain-Net,whereas CDAN,FixBi,ATDOC and MCC may not.Particularly,SHOT outperformed other TL approaches consider-ably.On SEED,which includes large individual differences(domain shifts),no TL approach can always achieve positive transfer.Sometimes,the classification accuracies were even worse than the randomguess baseline.
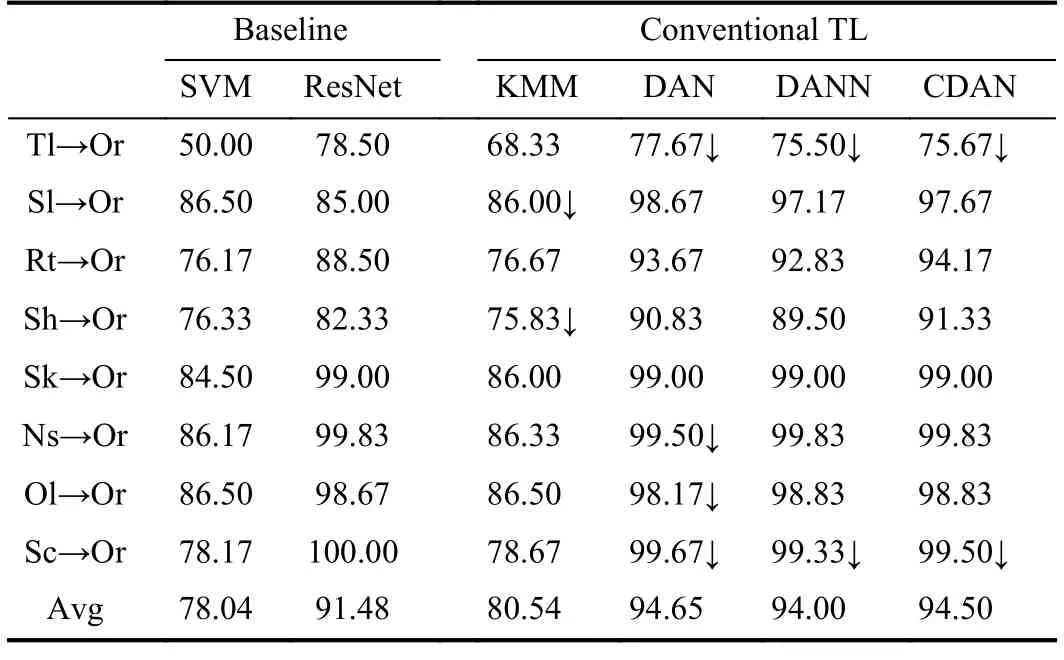
TABLE VI CLASSIFICATION ACCURACIES (%) OF DIFFERENT UNSUPERVISED TL APPROACHES ON MOON
Table VIII shows the performances of 11 semi-supervised TL approaches on Domain Net and SEED.Again,no approach can always achieve positive transfer.Particularly,DANN and CDAN resulted in severe NT on both datasets,consistent with the observations in [78],[157].Notably,S+T performed much better than T with only 5% labeled target data,suggesting the importance of acquiring source domain when the labeled target data is scarce.
Next,we added noise to the source labels to further enlarge the domain shifts.For noise rate 0.1,we randomly selected 10% of the source samples and changed their labels to a different class randomly.We compared five unsupervised TL approaches (DNN,DAN,DANN,MCC,and SHOT) and five semi-supervised TL approaches (T,S+T,Fine-tuning,ENT,and APE) when transferring Subject 1 to Subject 2 with three repeats on SEED.The average results when increasing noise rate from 0.0 to 1.0 are shown in Fig.10.In unsupervised TL,when the noise rate was small,most TL approaches outperformed the DNN baseline,especially MCC.In semi-supervised TL,S+T seemed to be a very strong baseline.Only Fine-tuning can sometimes outperformit.
In summary,these results demonstrated that our constructed datasets can be used for studying NT.Ultimately,none of our evaluated algorithms can always avoid NT.While a lot more research is needed to understand and overcome NT,we give some application guidelines in the next section.
VI.SUMMARY AND DISCUSSIONS
Some summaries,suggestions and discussions are presented in this section.
A.Method Comparison
According to the scheme shown in Fig.2,we have introduced the domain similarity estimation,safe transfer,and NT mitigation approaches.To summarize,Table IX compares their characteristics and differences.
Several observations can be made from Table IX:
1) Most studies focused on NT mitigation and domain similarity estimation.
2) Research on mitigating or overcoming NT spread across many different categories of TL,indicating that this topic has received extensive attention in TL.
3) NT mitigation research mainly focuses on data transferability enhancement.As large pre-trained models are becoming more popular,model transferability enhancement deserves more research.
4) Most safe transfer strategies were based on model adaptation,considering only the algorithmfactor.Domain divergence and target data quality should also be considered in future research.
5) Most approaches only considered two or three NT factors.All four (domain divergence,source data quality,target data quality,and TL algorithm) should be considered simultaneously to further boost the target learning performance.
6) Most NT mitigation approaches made domain correlation and common latent space assumptions.In contrast,some domain similarity estimation approaches and safe transfer approaches did not make any assumptions about the source and target domains.
B.Guidelines for Coping With NT
We suggest first deciding whether to transfer by estimating the domain similarity,or utilizing prior know ledge about the tasks.Then,there are three options:
1) Do not transfer if the domains are too dissimilar,or unrelated.
2) If the domain similarity cannot be estimated,then safe transfer is recommended.
3) Otherwise,determine what and how to transfer according to what the source domains provide,e.g.,data or pretrained models,and then choose an NT mitigation approach or safe transfer to deal with NT.
C.Challenges
Challenges on handling NT include:
1) Limited Positive TL Settings and Paradigms:Most of the reviewed safe transfer approaches are parameter-based TL in a semi-supervised setting.For other settings,e.g.,unsupervised TL and few-shot TL,integrating existing strategies like performance gain,error restriction,or output limit,is still a problem.For other paradigms,e.g.,feature-based DA,multisource DA,and lifelong learning,designing paradigm-specific safe TL strategy still needs further research.
2) Generalization Bounds for NT:The generalization bounds of unsupervised and supervised TL have been well studied [18],[23].However,there have not been studies on the generalization bounds for NT.Although we give NT definitions in Section II-B,it is still a challenge to provide a theoretical generalization bound.
3) Limited Interpretability:The interpretation of NT and positive transfer is challenging and rarely studied.For a particular task,if positive transfer happens,then which factor contributes the most: high-quality source data,algorithmdesign,or the training scheme? If NT occurs,then what are the causes behind it: source domain transferability,target dataquality,or inappropriate TL algorithmdesign?
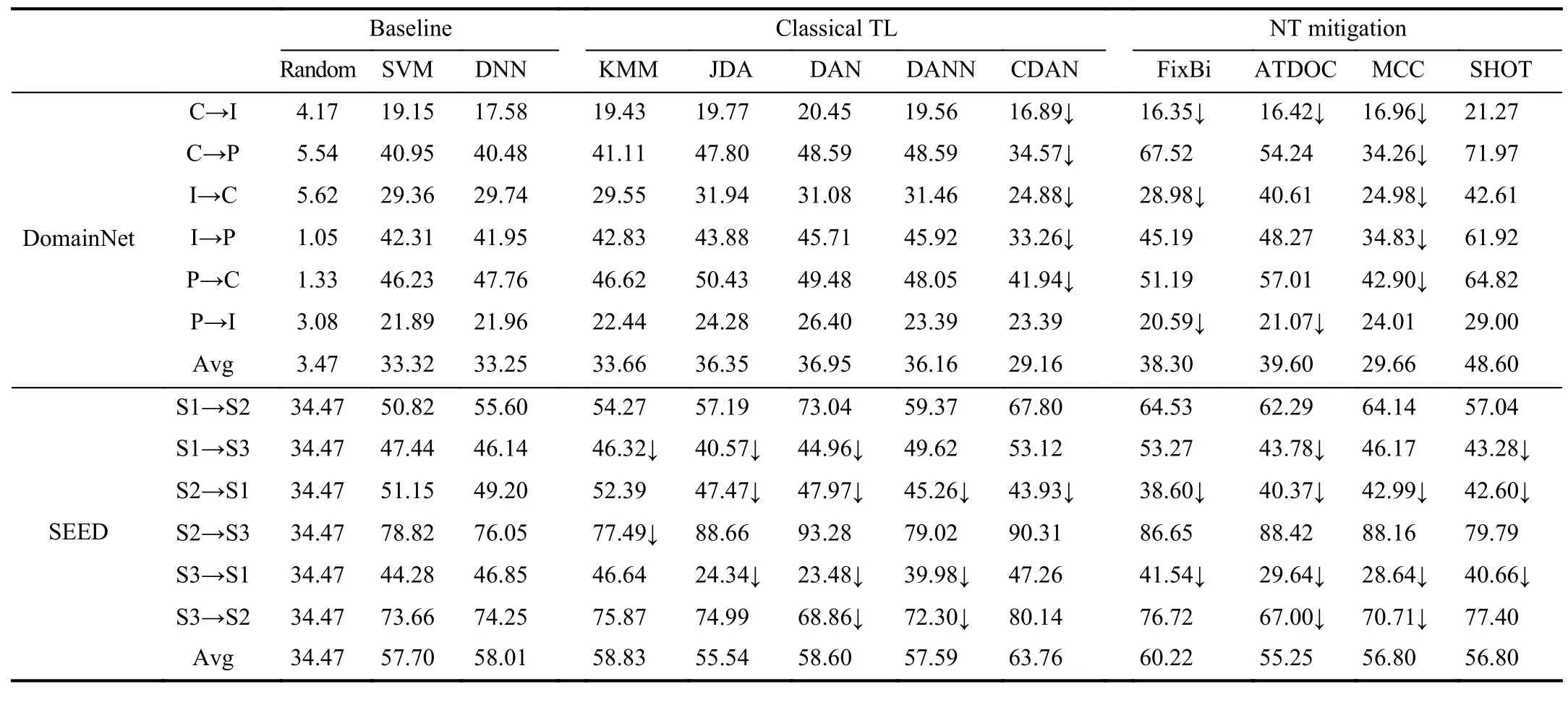
TABLE VII CLASSIFICATION ACCURACIES (%) OF UNSUPERVISED TL APPROACHES ON DOMAINNET AND SEED

TABLE VIII CLASSIFICATION ACCURACIES (%) OF SEMI-SUPERVISED TL APPROACHES ON DOMAINNET AND SEED WITH 5% LABELED TARGET DATA
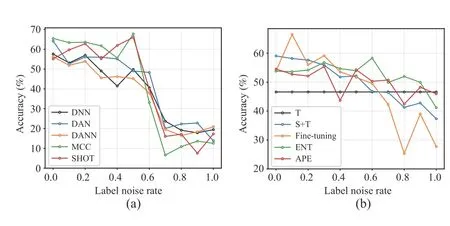
Fig.10.Classification accuracy when transferring Subject 1 to Subject 2 on SEED under different noise rates.(a) unsupervised TL;and,(b) semi-supervised TL.The target label rate was fixed at 5%.
4) Algorithm Reproducibility:The ideal approach to handle NT is safe transfer,which can overcome NT with theoretical guarantees,regardless of whether the source and target domains are similar or not.However,few safe transfer approaches have released their code,so it is hard to compare or improve based on them.
VII.CONCLUSIONS AND FUTURE RESEARCH
TL utilizes data or know ledge from one or more source domains to facilitate learning in a target domain,which is particularly useful when the target domain has very few or no labeled data.NT is undesirable in TL,and has been attracting increasing research interest recently.This paper has systema-tically categorized and reviewed over fifty representative approaches for handling NT,from three perspectives: domain similarity estimation,safe transfer,and NT mitigation.Some basic concepts,e.g.,the definition of NT,the causes of NT,and related research fields,are also introduced.To our know ledge,this is the first comprehensive survey on NT.
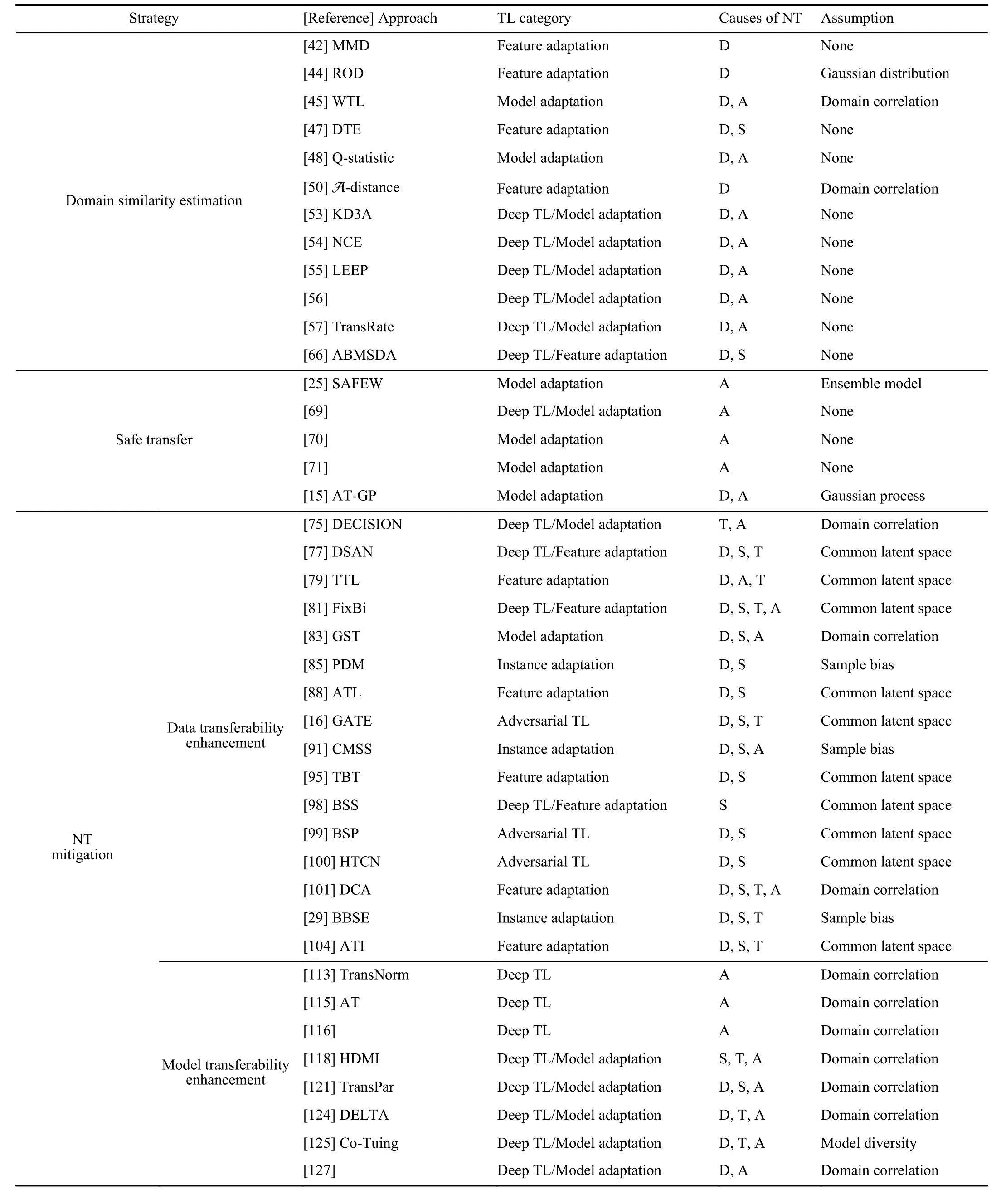
TABLE IX COMPARISON OF APPROACHES FOR ACCOMMODATING NT.“TL CATEGORY”GROUPS ALL APPROACHES INTO FIVE CATEGORIES [3]:INSTANCE ADAPTATION,FEATURE ADAPTATION,MODEL ADAPTATION,DEEP TL,AND ADVERSARIAL TL.“CAUSES OF NT”INCLUDES FOUR ELEMENTS MENTIONED IN SECTION II-C: DOMAIN DIVERGENCE (D),SOURCE DATA QUALITY (S),TARGET DATA QUALITY (T),AND TRANSFER ALGORITHM (A).“ASSUMPTION”LISTS THE KEY ASSUMPTIONS OF EACH TL APPROACH
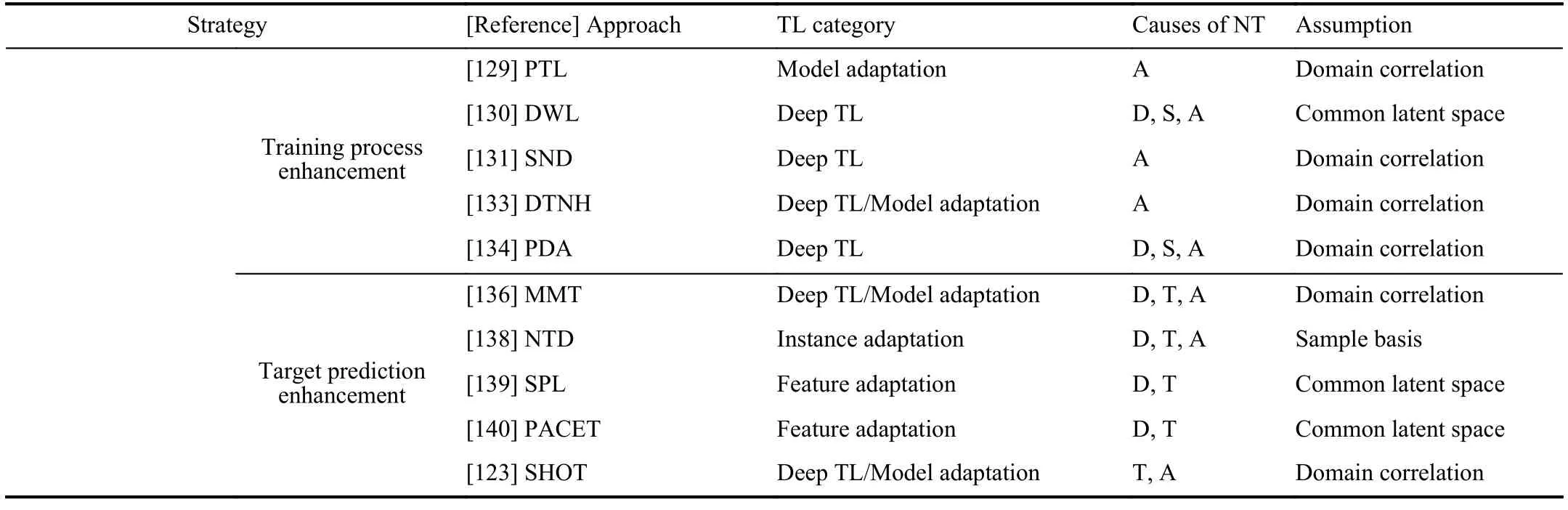
TABLE IX COMPARISON OF APPROACHES FOR ACCOMMODATING NT.“TL CATEGORY”GROUPS ALL APPROACHES INTO FIVE CATEGORIES [3]:INSTANCE ADAPTATION,FEATURE ADAPTATION,MODEL ADAPTATION,DEEP TL,AND ADVERSARIAL TL.“CAUSES OF NT”INCLUDES FOUR ELEMENTS MENTIONED IN SECTION II-C: DOMAIN DIVERGENCE (D),SOURCE DATA QUALITY (S),TARGET DATA QUALITY (T),AND TRANSFER ALGORITHM (A).“ASSUMPTION”LISTS THE KEY ASSUMPTIONS OF EACH TL APPROACH (CONTINUED)
Future research directions include:
1) Positive Transfer in Novel and More Challenging Scenarios:Existing approaches mainly consider known and stable target domains.However,in practice,the target domain could be open and more challenging,including continuous data streams,unclear domain boundaries,heterogeneous features,unseen/unknown categories,class imbalance,etc.Novel positive transfer approaches are needed in such scenarios.
2) Safe Transfer in New TL Paradigms:Safe transfer focuses on positive transfer with theoretical guarantees.However,most existing safe transfer approaches consider only parameter based TL.More TL paradigms need to be considered,e.g.,feature based DA,multi-source DA,few-shot TL,regression TL,and lifelong learning.
3) Interpretable Positive Transfer:The interpretability of TL is challenging and rarely studied,especially for neural network based approaches [97].Interpretable positive transfer seeks to understand which factors facilitate or degrade target learning performance,allowing researchers to choose and design better positive transfer strategies.
4) Source Free Positive Transfer:Due to privacy and security concerns and regulation,many times,TL needs to be performed without access to the source data.Multiple algorithms[53],[75],[111],[123],[127] have been proposed to mitigate NT in source free TL,but more with theoretical guarantees are needed.
ACKNOWLEDGMENT
We thank to Mr.Zirui Wang of the Carnegie Mellon University for insightful discussions.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- The Distribution of Zeros of Quasi-Polynomials
- Straight-Path Following and Formation Control of USVs Using Distributed Deep Reinforcement Learning and Adaptive Neural Network
- Prescribed-Time Stabilization of Singularly Perturbed Systems
- Visual Feedback Disturbance Rejection Control for an Amphibious Bionic Stingray Under Actuator Saturation
- Optimal Formation Control for Second-Order Multi-Agent Systems With Obstacle Avoidance
- Dynamic Target Enclosing Control Scheme for Multi-Agent Systems via a Signed Graph-Based Approach