用于慢性肾病早期筛查的Logistic回归应用
2023-03-02韩瑜王波周振宇杜晓昕
韩瑜,王波,周振宇,杜晓昕
用于慢性肾病早期筛查的Logistic回归应用
韩瑜,王波*,周振宇,杜晓昕
(齐齐哈尔大学 计算机与控制工程学院,黑龙江 齐齐哈尔 161000)
慢性肾病是全球十大疾病死因之一,发病率很高,且难以发现,如果可以在早期的时候就发现肾病的存在,将会大大降低因肾病而死亡的人数。首先从UCI数据库中获取早期慢性肾病患者的各项生理指标,提取出导致慢性肾病的关键变量,然后基于Logistic回归模型进行数据的拟合。最后通过5折交叉验证,模型的准确率比普通Logistic回归模型约高出了5.6%,召回率值高出了10.4%,精确率高出了1.1%,1值高出了5.8%,AUC值高出了5.2%。由此可见,可以为慢性肾病的早期筛查提供可靠的科学依据。
慢性肾病;Logistic逻辑回归;相关性分析;变量选择
Logistic回归模型是根据离散型或者连续型自变量来分析、预测离散型自变量的回归分析方法,是常见的用来处理定性变量的统计方法之一,目前在生物、医学、经济等领域应用十分广泛。随着越来越多的研究者们对Logistic回归进行研究,出现了越来越广泛的应用。有直接利用Logistic回归模型进行分类预测,比如ZHOU等[1]利用Logistic回归模型预测miRNA-疾病关联,LOPEZ-MARTINEZ等[2]在预测高血压风险中使用logistic回归模型。ROHINI等[3]使用Logistic回归模型对阿尔茨海默病分类;张祥等[4]应用Logistic回归模型建立财务预警模型对财务安全起到很重要的作用。李静等[5]、季孝等[6]分别在浸润性导管癌诊断和脓毒症早期诊断中的应用。还有在Logistic模型的基础上进行优化,例如FUKUNISH[7]阿尔茨海默氏症型痴呆症预测稀疏物流回归以及XIAO[8]利用稀疏Logistic回归模型对阿尔茨海默病进行诊断。以上这些改进的模型相比于普通的Logistic回归有更好的性能。还有将其他算法与Logistic回归模型结合使用预测的,例如DING等[9]使用随机游走提取每对CircRNA的特征,然后利用Logistic回归模型来预测新的CircRNA-disease关联。NAKAMICHI等[10]遗传算法和Logistic回归结合来估计多个单核苷酸多态性、环境因素和二元疾病特征之间的关系。
综上所述,Logistic回归模型在医学诊断上的应用十分广泛,更适合二分类的相关预测。慢性肾病已经成为全球人类共同的健康问题,由于其患病率和病死率很高,如果不能尽早的发现并治疗,会使得病情进一步恶化。目前大多数慢性肾病难以彻底痊愈,所以在早期诊断慢性肾病是很必要的,因此,本文基于Logistic回归分析对临床病例进行分析,首先以患慢性肾病的多个因素为自变量,筛选出患有慢性肾病的关键变量,其次以是否患有慢性肾病为因变量构建基于Logistic回归模型预测慢性肾病,从而为诊断早期慢性肾病提供参考依据。
1 材料与方法
1.1 数据集获取
本文使用的数据集来源于UCI(University of California Irvine)数据库中早期的400例印度人慢性肾病的各个生理指标(http://archive.ics.uci.edu/ml/datasets/Chronic_Kidney_Disease)的数据集,包括250例患有慢性肾病的人和150例没有慢性肾病的人。数据集中的自变量有定性变量也有定量变量,包括年龄(ag)、血压(bp)、尿比重(sg)、白蛋白(al)、血糖(su)、红细胞(rbc)、脓细胞(pc)、脓细胞团(pcc)、病原菌(ba)、血糖随机(bgr)、血液尿素(bu)、血清肌酐酸(sc)、钠(sod)、钾(pot)、血红蛋白(hemo)、红细胞压积(pcv)、白细胞数(wc)、红细胞数(rc)、高血压(htn)、糖尿病(dm)、冠状动脉疾病(cad)、食欲(appet)、脚肿(pe)、贫血(ane),因变量是定性变量即是否患有慢性肾病。
1.2 数据预处理
本文所研究数据集中的变量主要分为连续变量、离散变量以及一部分字符串,由于数据中常常会有含有一些噪音、不完整还有不一致的情况,为了不影响后面的分析,往往需要把控数据的质量。首先对数据进行预处理,数据预处理分为两个阶段。
第一阶段对数据进行整理,将变量中的字符串都转换为哑变量,其中rbc、pc present记为0,not present记为1;pcc、ba normal记为0,abnormal记为1;appet good记为0,poor记为1;htn、dm、cad、pe、贫血ane yes记为0,no记为1;ckd(慢性肾病)记为1,notckd(没有慢性肾病)记为0。将年龄划分为三段,第一段在0~40岁年龄段的都记为1,第二段41~65岁年龄段记为2,第三段65岁以上记为3,部分赋值如表1所示。

表1 慢性肾病影响因素赋值表
第二阶段对缺失数据进行处理,数据缺失是医学临床试验过程中经常会遇到的问题,且会影响数据分析的质量和最终决策的性能。数据缺失有很多种类型,本文数据集是临床医学数据属于随机缺失。在整理慢性肾病数据时,数据缺失情况如图1所示(红色代表数据缺失)。为了满足后续研究的需求,要对缺失数据进行填补,填补缺失数据的方法比较多,本文使用K近邻法对缺失的数据进行填补,K近邻插补法是指利用数据中与缺失值相关的无缺失值,找出距离最近的个样本,利用欧式距离函数来衡量这些样本与缺失样本之间的距离。估计值是通过对个样本对应的缺失项进行距离加权得到的。处理好的数据查看是否有异常值如表2所示,虽然标准差比较大,但是Logistic回归模型无需进行数据标准化。

图1 数据缺失情况图
2 自变量选择



表2 异常值检查

做出各个变量之间相关性的热力图如图2所示。
在进一步使用逐步回归法来消除自变量间的多重共线性,共六步删除了x15血红蛋白、x3尿比重、x4白蛋白、x20糖尿病、x11血液尿素、x19高血压六个变量,部分如表3所示。
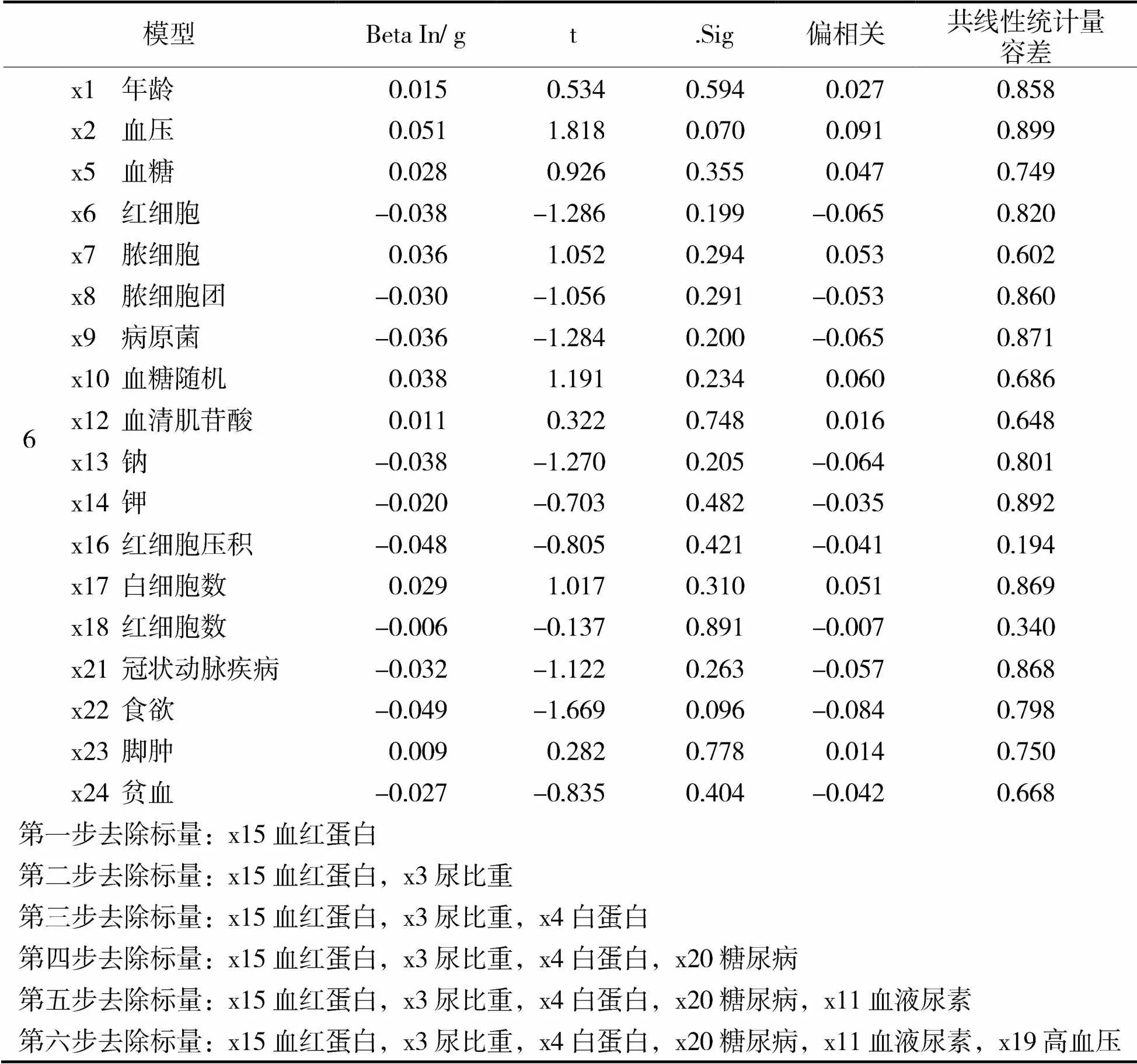
表3 消除多重共线性
第二方面为了使得在模型里面的自变量对因变量都是有意义的,那么自变量肯定是要与因变量有一定的关联关系。因此对每个自变量与因变量进行相关性分析图如图3所示,本文将绝对值小于0.25的自变量去掉,即去除x1年龄、x9病原菌、x14钾、x21冠状动脉疾病。因此最终剩下x2血压、x5血糖、x6红细胞、x7脓细胞、x8脓细胞团、x10血糖随机、x12血清肌苷酸、x13钠、x16红细胞压积、x17白细胞数、x18红细胞数、x22食欲、x23脚肿和x24贫血10个变量。
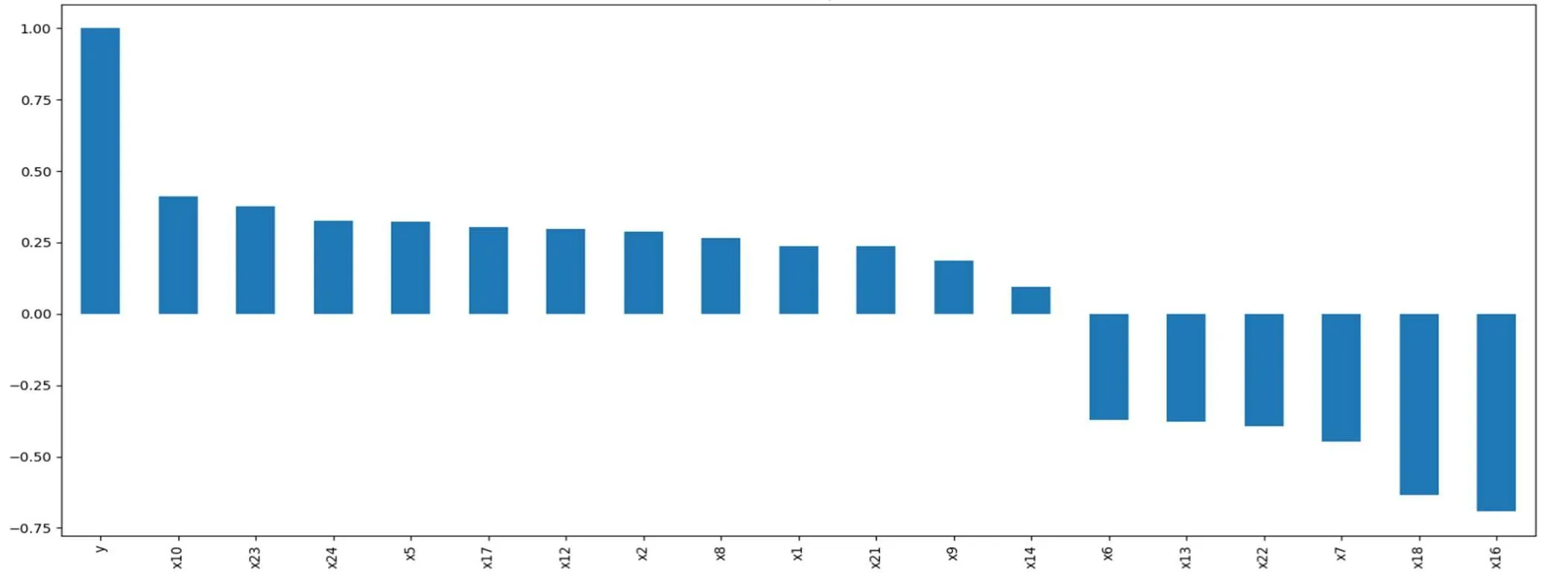
图3 各个自变量与因变量的相关性
3 建立模型
Logistic回归处理二分类问题经典的算法之一,且Logistic回归易于最优化求解。一般的Logistic回归模型时常容易欠拟合,通过不断的优化,就又会出现过拟合现象。针对过拟合问题,通常会考虑两种方法。第一种是减少特征的数量;第二种是加入正则项。在此本文用到正则化惩罚,即惩罚数值较大的权重参数,降低它们对结果的影响。




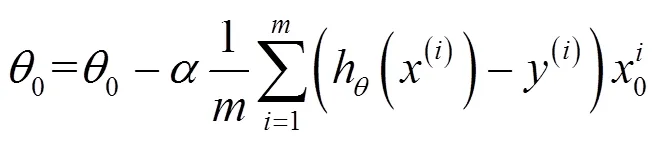

4 结果与讨论
本文使用召回率来评估我们模型的性能,与没有添加L2正则项的Logistic回归模型作对比,五折交叉五种不同正则化惩罚力度(0.01, 0.1, 1, 10, 100)的召回率如表4所示,从表中可以看出本文的模型在惩罚系数为1的时候效果是最好的,召回率达到了93%。

表4 不同惩罚系数的召回率
接下来,在全部数据集上使用L2正则化Logistic回归模型进行预测。对于逻辑回归算法来说,还可以指定一个阈值,也就是说最终结果的概率是大于多少把它当成是患病还是没有患病。这里通过Sigmoid函数将得分值转换成概率值,默认情况下,模型都是以0.5为界限来划分类别:>0.5为正例,<0.5为负例。这里的0.5是一个经验值,可以根据实际经验进行调整。因此指定9个不同阈值(0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9),得到混淆矩阵如图4所示,同时也计算得到不同阈值下的召回率。
前面使用下采样法使得样本均衡,所以阈值在0.5时效果是最好的。然而最终要在整体上进行预测,患病与没有患病的样本数量是不均衡的,因此计算出每一个阈值的召回率如表5所示,这时从表5可以看出本文的模型的阈值选0.3效果和经过下采样法的召回率是相近的。
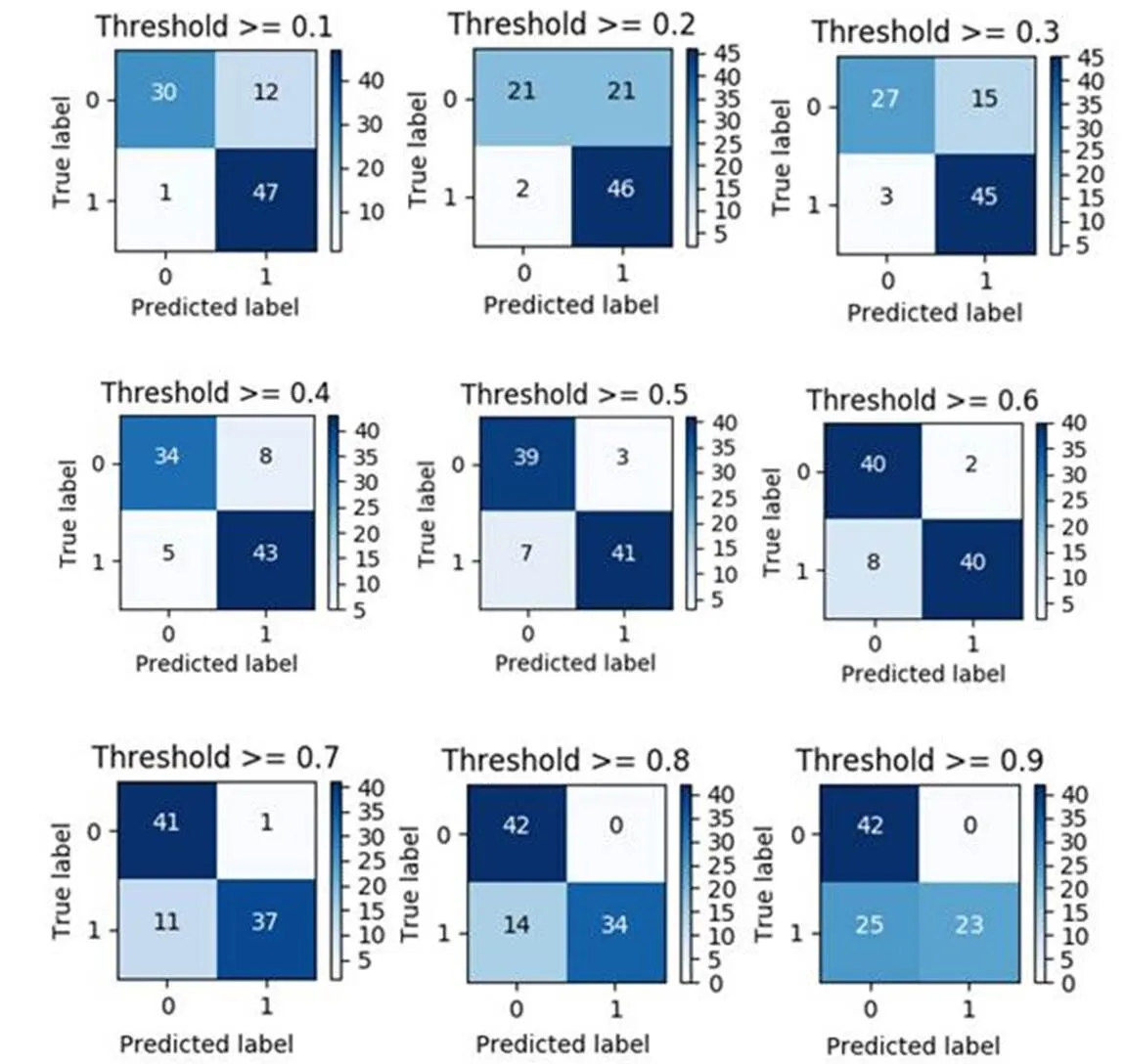
图4 不同阈值的混淆矩阵
最后在相同的数据集下,将L2正则化Logistic回归模型与普通的Logistic模型作对比如表6所示,本文模型的准确率比普通Logistic回归模型约高出了5.6%,召回率值高出了10.4%,精确率高出了1.1%,1值高出了5.8%,AUC值高出了5.2%。为了验证本文模型解决过拟合问题,使用普通的Logistic回归模型和L2正则化Logistic回归模型分别得到在训练集和测试集上的ROC曲线如图5所示,从图5(a)(红色为本文模型,蓝色为普通的Logistic模型)可以看出,普通的Logistic回归模型和L2正则化Logistic回归模型在训练集上的表现都是优异的,而图5(b)可以看出普通的Logistic回归模型在训练集上的表现好反而到了测试集表现不好,而L2正则化Logistic回归模型表现依旧优异,这个图也说明了普通的Logistic回归模型存在过拟合现象,本文模型解决了其过拟合的问题。经过上述对比分析可以看出本文模型在预测慢性肾病的性能是优于普通Logistic回归模型,同时对未来诊断慢性肾病具有一定的参考价值。

表5 不同阈值的召回率

表6 对比评价指标

图5 ROC曲线对比图
5 结论
本文使用基于Logistic回归模型进行早期慢性肾病的筛查,首先对获取到的数据进行预处理,随后在处理好的数据基础上,其次根据逐步回归法消除变量间的多重共线性,利用spearman相关系数对变量间做相关性分析,提取出对模型有意义的自变量,最后构造出用以筛查早期慢性肾病的分类模型。通过5折交叉验证,本文模型的准确率比普通Logistic回归模型约高出了5.6%,召回率值高出了10.4%,精确率高出了1.1%,1值高出了5.8%,AUC值高出了5.2%。在ROC曲线中,L2正则化Logistic回归模型在测试集上的表现也是优异的,而普通的Logistic回归模型在训练集上的表现好反而到了测试集表现不好。实验表明,该分类模型可以准确的筛查处早期慢性肾病。但是也有一些不足的地方,首先Logistic回归模型要求选择的变量之间是相互独立,但是在实际应用过程中,不能实现;其次在选取变量的时候,使用逐步回归法消除多重共线性,是在局部的思想下进行,可能会删除一些重要的变量。未来的研究可以寻找样本较多的数据集,将模型应用在别的疾病上,研究提取特征的算法,同时不会降低模型的性能。
[1] ZHOU S, WANG S, WU Q, et al. Predicting potential miRNA-disease associations by combining gradient boosting decision tree with logistic regression[J]. Computational Biology and Chemistry, 2020, 85(C): 107200.
[2] LOPEZ-MARTINEZ F, SCHWARCZ A, NUNEZ-VALDEZ E R, et al. Machine learning classification analysis for a hypertensive population as a function of several risk factors[J]. Expert Systems with Applications, 2018, 110: 206-215.
[3] ROHINI M, SURENDRAN D. Toward Alzheimer's disease classification through machine learning[J]. Soft Computing, 2020, 25: 2589-2597.
[4] 张祥,陈荣秋. 财务预警模型的变迁[J]. 华中科技大学报(社会科学版),2003, 17(4): 73-76.
[5] 李静,吴国柱,王芳,等. Logistic回归模型在不典型浸润性导管癌诊断中的应用[J]. 中国现代医学杂志,2022, 32(02): 69-73.
[6] 季孝,吴跃波,谢璐涛,等. 基于logistic回归模型的血常规参数在脓毒症早期诊断的价值[J]. 中国卫生检验杂志,2022, 32(16): 2001-2004, 2008.
[7] FUKUNISHI H, NISHIYAMA M, LUO Y, et al. Alzheimer-type dementia prediction by sparse logistic regression using claim data[J]. Computer Methods and Programs in Biomedicine, 2020, 196: 105582.
[8] XIAO R, CUI X, QIAO H, et al. Early diagnosis model of Alzheimer′s disease based on sparse logistic regression[J]. Multimedia Tools and Applications, 2021, 80: 3969-3980.
[9] DING Y, CHEN B, LEI X, et al. Predicting novel CircRNA-disease associations based on random walk and logistic regression model[J]. Computational Biology and Chemistry, 2020, 87: 107287.
[10] NAKAMICHI R, IMOTO S, MIYANO S. Statistical model selection method to analyze combinatorial effects of SNPs and environmental factors for binary disease[J]. International Journal on Artificial Intelligence Tools, 2006, 15(5): 711-724.
Logistic regression applied research for early screening of chronic kidney disease
HAN Yu,WANG Bo*,ZHOU Zhen-yu,DU Xiao-xin
(College of Computer and Control Engineering, Qiqihar University, Heilongjiang Qiqihar 161006, China)
Chronic kidney disease (CKD) is one of the top 10 causes of death in the world. It is very common and difficult to detect. If we can detect the presence of CKD at an early stage, the number of deaths from CKD will be greatly reduced. In this paper, we first obtain physiological indicators of patients with early chronic kidney disease from the UCI (University of California Irvine) database, extract the key variables leading to chronic kidney disease, and then fit the data based on Logistic regression model. Finally, with 50% cross validation, the accuracy of the model in this paper is approximately 5.6% higher than that of the ordinary Logistic regression model, with 10.4% higher recall, 1.1% higher accuracy, 5.8% higher1 value, and 5.2% higher AUC. As can be seen, this can provide a reliable scientific basis for early screening for chronic kidney disease.
chronic kidney disease;Logistic regression;correlation analysis;variable selection
2022-09-27
黑龙江省教育厅基本科研业务费面上项目(145209125);齐齐哈尔大学研究生创新科研项目资助(YJSCX2021014)
韩瑜(1996-),女,陕西人,硕士,主要从事研究数据分析与挖掘研究,1299957889@qq.com。
王波(1980-),男,黑龙江人,博士,副教授,主要从事研究大数据分析与挖掘研究,bowangdr@qqhru.edu.cn。
TP183
A
1007-984X(2023)01-0013-07
