数据挖掘技术在电商客户粘性预测中的研究
2023-03-02黄维雅
黄维雅
数据挖掘技术在电商客户粘性预测中的研究
黄维雅
(厦门兴才职业技术学院 经贸学院,福建 厦门 361000)
为精准有效地预测电商客户粘性,提升经济效果,研究数据挖掘技术在电商客户粘性预测中的应用。利用可变网格的K-means聚类算法,聚类获取电商客户粘性预测相关数据;通过有效性指标优化可变网格K-means聚类算法的聚类数,确定最佳聚类数,提升数据聚类效果;采用技术接受模型,依据聚类获取的数据,建立电商客户粘性预测指标体系;通过模糊层次分析法,结合指标体系,建立电商客户粘性预测模型,获取预测分值。实验结果表明,该模型可有效确定最优聚类数,精准聚类电商客户粘性预测相关数据;所建立的预测指标体系的指标相关性较低,结构较稀疏、较全面。总体说明,该模型可有效预测电商客户粘性。
数据挖掘技术;电商客户;粘性预测;可变网格;K-means聚类;模糊层次分析
互联网的发展,促进了人与人间联系的紧密性,大量电商平台颇受大众喜欢[1],电商平台的经济效益也很可观。近年来,由于客户体验差,导致电商平台出现瓶颈,发展速度缓慢,电商平台的发展离不开客户,客户的满意度与电商平台发展密不可分[2],电商平台在吸引新客户的同时,还要与老客户保持着良好的关系。电商客户粘性代表客户使用电商平台的时间与电商平台留存客户能力,为此通过预测电商客户粘性,发现存在的不足之处,及时改进,提升电商客户粘性,便可提升电商平台的经济效益[3]。杨力[4]利用云计算方法划分电商客户流失量数据,通过线序列极限学习机,依据数据划分结果,建立流失量预测模型,融合多个数据集的预测结果,获取电商客户流失量的最终预测结果,该模型可有效预测电商客户流失量,预测模型训练时间较短,预测效率较快;葛绍林等[5]根据电商客户行为特征,建立用户行为特征模型,利用深度森林方法,结合行为特征模型,构造用户行为预测模型,该模型可有效预测用户行为,该模型在预测过程中既减少了开销时间,又提升了预测精度。但这两种方法的预测全面性较差,无法从各个角度预测电商客户的相关信息,对于提升电商平台经济效益的应用效果较差。数据挖掘技术是在不同类型数据内挖掘知识,加强已存在数据的内在价值,可在海量数据内精准提取有用信息,在检测与预测等领域均有应用,数据挖掘技术最常用的算法是聚类算法[6]。为全面预测电商客户粘性,研究基于数据挖掘技术的电商客户粘性预测模型。
1 电商客户粘性预测模型
1.1 基于数据挖掘技术的电商客户粘性预测数据提取
利用可变网格的K-means聚类算法,在海量电商客户数据中提取与电商客户粘性预测相关的数据。传统的K-means聚类算法初始中心点的选择方法为任意选择,这种选择方式无法呈现电商客户粘性预测相关数据集的实际情况,造成聚类结果波动性大。为此利用可变网格优化的K-means聚类算法,提取电商客户粘性预测相关数据,在高密度网格内选择存在代表性的初始中心点,避免孤立点对聚类结果的影响[7],增强聚类质量。
可变网格划分指对海量电商客户数据集的各维展开等深划分,分别求解邻近区间段的密度,合并超过密度阈值的邻近区间,获取可变的划分网格。按照电商客户数据分布特性,完成网格划分,大幅度降低网格数量,提升网格划分的灵活性[8],加快电商客户粘性预测相关数据聚类速度。

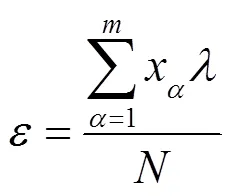
其中,是常数。

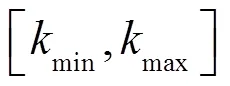
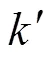
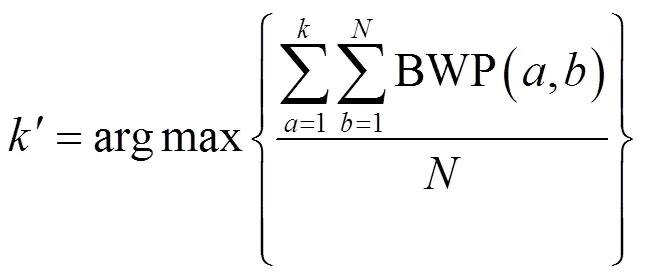
其中,电商客户数据样本编号是;聚类数编号是。
1.2 基于技术接受模型的电商客户粘性预测指标体系
通过技术接受模型,依据聚类获取的电商客户粘性预测相关数据,从感知有用性、感知易用性、感知服务性、感知安全性、感知趣味性与感知性价比六方面,建立电商客户粘性预测指标体系,电商客户粘性预测指标体系如表1所示。

表1 电商客户粘性预测指标体系
感知有用性代表客户认为使用电商平台对自我提升有帮助;感知易用性代表客户认为使用电商平台操作简单;感知服务性代表客户认为使用电商平台服务质量较高[13];感知安全性代表客户认为使用电商平台安全程度高;感知趣味性代表客户认为使用电商平台时具有一定的趣味性,会增加其使用该平台的兴趣;感知性价比代表客户认为使用电商平台购买商品的性价比较高。
1.3 基于模糊层次分析法的电商客户粘性预测模型
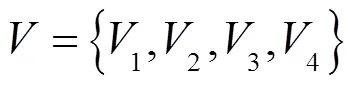

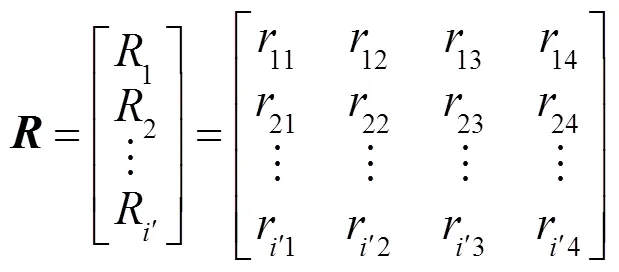
因此,获取电商客户粘性模糊综合预测模型,公式如下:

其中,电商客户粘性预测指标因素权重是;电商客户粘性预测分值是;电商客户粘性预测指标因素隶属度是。
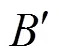
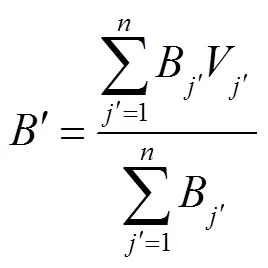
电商客户粘性预测等级的分值区间分别是优秀[100,85)、良好[85,70)、一般[70,55)、差[55,0]。
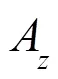

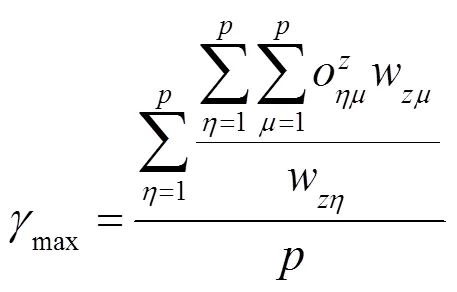
2 实验分析
以某电商平台为实验对象,该电商平台的公开数据集内共包含10万多条数据记录,该数据集内共包含三种维度的数据,分别是3维、4维、5维,按照数据维数将该数据集分成3个子数据集,记作子集1、子集2、子集3;利用本文模型预测该电商平台的电商客户粘性,为提升该电商平台的经济效益提供帮助。
利用本文模型在3个子数据集内,提取电商客户粘性预测相关数据,提取电商客户粘性预测相关数据前,需先确定本文模型中数据聚类的最佳聚类数,提升电商客户粘性预测相关数据聚类效果,即数据提取效果,利用BWP有效性指标确定本文模型的最佳聚类数,分析结果如图1所示。

图1 最佳聚类数确定结果
根据图1可知,本文模型可有效依据BWP有效性指标,确定电商客户粘性相关数据聚类的最佳聚类数,3个子集的聚类数均在3时,对应的BWP有效性指标值达到最高,说明3个子集的最佳聚类数均为3。
确定完最佳聚类数后,利用本文模型聚类这3个数据子集内电商客户粘性预测相关数据,以子集1为例,聚类结果如图2所示。根据图2可知,本文模型可有效按照最佳聚类数,聚类电商客户数据集,提取电商客户粘性预测相关数据。实验结果表明,本文模型可精准聚类电商客户数据集,精准提取电商客户粘性预测相关数据,为后续电商客户粘性预测打下坚实的基础。
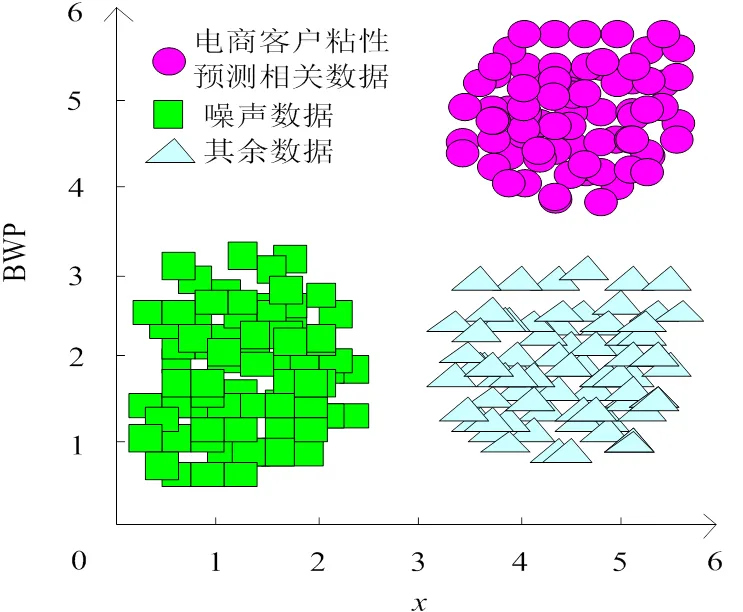
图2 电商客户粘性预测相关数据聚类结果
利用随机一致性检验指标CR,分析本文模型计算电商客户粘性预测指标权重时,建立的评判矩阵是否通过一致性检验,评判矩阵数量与准则层电商客户粘性预测指标数量一致,当全部评判矩阵均通过一致性检验,计算的电商客户粘性预测指标权重才是合理的,CR值小于0.1,说明评判矩阵通过一致性检验,CR值大于0.1,说明评判矩阵未通过一致性检验,本文模型计算电商客户粘性预测指标权重时,建立的评判矩阵一致性检验结果如表2所示。

表2 评判矩阵一致性检验结果
根据表2可知,本文模型计算电商客户粘性预测指标权重时,建立的评判矩阵CR值均低于0.1,说明各评判矩阵均通过一致性检验,即计算的各电商客户粘性预测指标权重均是合理的。
本文模型计算的电商客户粘性预测指标权重,以及依据该权重获取的电商客户粘性预测结果如表3所示。根据表3可知,本文模型可有效获取电商客户粘性预测指标权重与预测分值,对比分析各电商客户粘性预测指标的预测分值与预测等级的分值区间可知,该电商平台的电商客户粘性预测指标层内共有两个指标的预测等级为差,分别是感知服务性内的卖家发货及时性与物流送货效率;共有5个指标的预测等级为一般,分别是感知易用性内的检索工具效率与支付便捷,感知服务性的售后卖家沟通主动性,感知安全性内的交易信息安全性、快递安全性;该电商平台为提升其经济效益,需要对预测等级为一般与差的指标进行改进,对于准则层指标来说,仅有感知服务性与感知安全性的预测等级为一般,其余指标为优秀与良好,该电商平台需重点改进感知服务性与感知安全性两个指标,改善其电商客户粘性,提升该电商平台的经济效益。

表3 电商客户粘性预测指标权重及预测结果
利用相关性分析本文模型构建电商客户粘性预测指标体系的全面性,指标相关性越低,说明电商客户粘性预测指标体系结构越稀疏,信息越全面,指标相关性在[0.0,0.4)区间时,说明不相关,在[0.4,0.7)区间时,说明显著相关,在[0.7,1.0]区间时,说明高度相关,以电商客户粘性预测准则层指标为例,本文模型构建的指标体系内准则层内各指标相关性测试结果如图3所示。

图3 指标性相关性测试结果
根据图3可知,两个不同电商客户粘性预测指标间的相关性最高值为0.3,同一指标的相关性为1.0,本文模型构建的电商客户粘性预测指标间的相关性位于区间[0.0,0.4)中,说明各指标间不相关。实验结果表明,本文模型构建的电商客户粘性预测指标间不相关,即指标体系结构较稀疏,信息较全面。
3 结论
电商客户粘性直接决定了客户是否愿意继续使用某电商平台,与该电商平台的销售额具有正相关关系,为此研究基于数据挖掘技术的电商客户粘性预测模型。在提取电商客户粘性预测相关数据前,需先利用BWP有效性指标确定本文模型中数据聚类的最佳聚类数,三个子集的聚类数均在3时,对应的BWP有效性指标值达到最高,根据聚类结果说明该模型可有效确定最优聚类数,精准聚类电商客户粘性预测相关数据;利用相关性,分析本文模型构建电商客户粘性预测指标体系的全面性,该模型相关性位于区间[0.0,0.4)中,相关性较低,说明该模型指标体系结构较稀疏、较全面。总体说明,该模型可有效预测电商客户粘性。根据预测结果,及时发现降低电商客户粘性的影响因素,并加以改进,弥补不足之处,加强电商客户粘性,为提升经济效果提供帮助。
[1] 龚祯. 基于复杂网络理论的电商供应链风险预测方法研究[J]. 西南师范大学学报(自然科学版),2021, 46(03): 39-44.
[2] 吕泽宇,李纪旋,陈如剑,等. 电商平台用户再购物行为的预测研究[J]. 计算机科学,2020, 47(S1): 424-428.
[3] 何喜军,马珊,武玉英,等. 小样本下多维指标融合的电商产品销量预测[J]. 计算机工程与应用,2019, 55(15): 177-184.
[4] 杨力. 基于在线序列优化极限学习机的电子商务客户流失量预测模型[J]. 南京理工大学学报,2019, 43(01): 108-114.
[5] 葛绍林,叶剑,何明祥. 基于深度森林的用户购买行为预测模型[J]. 计算机科学,2019, 46(09): 190-194.
[6] 张振华,许柏鸣. 基于网络口碑数据挖掘的电子商务物流服务质量问题[J]. 中国流通经济,2019, 33(01): 43-55.
[7] 原慧琳,杜杰,李延柯. 基于数据挖掘的客户细分模型研究及应用[J]. 计算机工程与设计,2021, 42(01): 57-64.
[8] 顾永春,顾兴全,武娇,等. 面向不平衡网络评论数据挖掘的服务质量评价[J]. 小型微型计算机系统,2021, 42(02): 354-361.
[9] 耿德志,徐乾. 基于K-Means聚类算法的HDMA数据挖掘方法[J]. 计算机仿真,2021, 38(02): 308-312.
[10] 王秋萍,丁成,王晓峰. 一种基于改进KH与KHM聚类的混合数据聚类算法[J]. 控制与决策,2020, 35(10): 2449-2458.
[11] 梅婕,魏圆圆,许桃胜. 基于密度峰值多起始中心的融合聚类算法[J]. 计算机工程与应用,2021, 57(22): 78-85.
[12] 李海霞. 电商服务接触对消费者重购意愿的影响——以生鲜为例[J]. 商业经济研究,2019 (03): 75-78.
[13] 张朝辉,刘佳佳,冉惠. 基于贝叶斯与神经网混合算法的电商信用评价方法研究[J]. 情报科学,2020, 38(02): 81-87.
[14] 赵家胤. 基于模糊综合理论与随机森林的电子商务服务满意度评价方法研究[J]. 电子器件,2021, 44(06): 1520-1524.
[15] 翟小可,吴祈宗. 基于AHP-模糊综合评价的农村电商物流服务质量评价研究[J]. 数学的实践与认识,2019, 49(05): 121-127.
Research on data mining technology in e-commerce customer stickiness prediction
HUANG Wei-ya
(School of Economics and Trade, Xiamen Xingcai Vocational and Technical College, Fujian Xiamen 361000, China)
In order to accurately and effectively predict e-commerce customer stickiness and improve economic results, the application of data mining technology in e-commerce customer stickiness prediction is studied. The K-means clustering algorithm of variable grid was used to obtain the relevant data of e-commerce customer stickiness prediction. The clustering number of variable grid K-means clustering algorithm was optimized by the validity index to determine the optimal clustering number and improve the data clustering effect. The technology acceptance model is adopted to establish the prediction index system of e-commerce customer stickiness according to the data obtained by clustering. Through the fuzzy analytic hierarchy process, combined with the index system, the e-commerce customer viscosity prediction model is established to obtain the prediction score. The experimental results show that the model can effectively determine the optimal clustering number and accurately cluster the relevant data of e-commerce customer stickiness prediction. The index correlation of the established prediction index system is low, and the index system structure is sparse and comprehensive. Overall, the model can effectively predict e-commerce customer stickiness.
data mining technology;e-commerce customers;viscosity prediction; variable grid;K-means clustering;fuzzy hierarchy analysis
2022-08-17
2020年度福建省教育厅中青年教师教育科研项目“大数据分析在网络平台精准营销中的应用研究”(JAS20752)
黄维雅(1987-),女,福建厦门人,讲师,本科,主要从事跨境电商、大数据网络营销研究,hufenghuanyu109@sina.com。
TP181
A
1007-984X(2023)01-0081-06
