基于改进型Yolov4的室内安全帽佩戴状态检测算法
2023-02-25黄志清张煜森张严心任柯燕
黄志清,张煜森,张严心,任柯燕
基于改进型Yolov4的室内安全帽佩戴状态检测算法
黄志清1,张煜森1,张严心2,任柯燕1
(1. 北京工业大学信息学部,北京 100124;2. 北京交通大学电子信息工程学院,北京 100044))
为实现智能检测室内作业人员是否佩戴安全帽,提出了一种改进的Yolov4算法.首先,针对目前室内安全帽佩戴状态检测实验数据较为匮乏的问题,自建了一个用于室内场景的安全帽佩戴状态检测数据集.随后,为提升室内监控图像中模糊、微小目标的安全帽佩戴状态检测准确率,设计了自校准多尺度特征融合模块并将其嵌入原Yolov4网络中.该模块首先通过深度超参数化卷积从上至下、从下至上融合不同尺度下的特征,加强待检测目标的特征纹理,使得模型能够检测出这两类目标.再通过特征自校准模块对融合后的特征进行过滤,加强或抑制特征图上的每一像素点,使得模型可以在融合后的特征图上进行精确的检测.此外为加速模型收敛,使用解耦合的检测头替换原Yolov4中的耦合检测头,使目标定位任务与安全帽佩戴状态的分类任务相互独立.最后为提升模型对于重叠目标的检测能力,提出了软性非极大值抑制后处理算法Soft-CIoU-NMS.实验结果表明,该改进的Yolov4模型能够准确地识别出室内作业人员是否佩戴安全帽,准确率达到了95.1%.相比于原Yolov4模型,该模型对位于监控摄像头远端的模糊、微小目标和监控图像中重叠目标的检测能力有明显提升,检测准确率提升了约4.7%,较好地满足了室内场景下作业人员安全帽佩戴状态智能检测的要求.
计算机视觉;视频监控;深度学习;安全帽佩戴状态检测;Yolov4
安全帽是保障工人室内工作安全的重要保护设备,能够有效减少或预防突发意外对工人头部的伤害.然而,在室内作业过程中,经常出现工人未按规定佩戴安全帽的现象.由于室内生产现场情况复杂,监管人员无法保证不间断地检查工人是否佩戴安全帽.单一的人工监督方式存在极高的安全隐患.实现室内场景下安全帽佩戴状态的智能检测十分必要.
目前,安全帽佩戴状态检测方法主要分为基于传感器的检测方法[1-5]和基于计算机视觉的检测方法[6-12].基于传感器的检测方法,主要是通过压力、加速度等传感器获取相关监测参数后,判断工人是否佩戴安全帽.但是嵌入传感器的安全帽造价较高,且传感器的数据通信传输受场地因素影响较大,相比之下基于计算机视觉的检测方法更适合室内场景下的安全帽佩戴检测任务.例如,Dahiya等[8]使用局部二值模式(local binary patterns,LBP)、梯度直方图特征(histogram of oriented gradients,HOG)、尺度不变特征转换(scale-invariant feature transform,SIFT)3种算子描述安全帽特征,然后通过支持向量机(support vector machine,SVM)分类器对目标的安全帽佩戴状态进行分类.实验结果表明使用HOG算子的检测方法准确率最高,但是HOG算子主要描述目标的边缘特征,当图像中出现与安全帽边缘特征相似的物体时,模型错检率较高.因此Silva等[9]使用HOG、LBP、霍夫圆变换(circle Hough transform,CHT)3种算子共同反映安全帽特征,实现了94.23%的检测准确率.同样地,Rubaiyat等[10]联合颜色特征与CHT特征,实现了81%的检测准确率.还有一部分研究人员对人脸检测方法进行改进,实现安全帽佩戴状态的检测.如Shrestha等[11]利用闭路电视系统实现安全帽佩戴状态检测.但是该模型需要工人脸部正对信息采集模块才能实现安全帽佩戴状态的检测.随着基于深度学习的目标检测技术的广泛应用[12-15],Fang等[16]使用Faster R-CNN模型检测建筑工地上未佩戴安全帽的工人,该方法对不同图像中安全帽的尺度变化问题具有较高的适应性.Shen等[17]则是先使用人脸检测网络DSFD[18]对目标头部区域进行定位,然后再使用DenseNet网络对待检测目标的安全帽佩戴状态进行分类.
总的来说,现有基于计算机视觉的安全帽佩戴状态检测方法在对应的数据集上均取得了较好的检测结果,但是在实际室内场景下,基于手工设计相关特征的安全帽佩戴状态检测方法[9-10]鲁棒性差、精度偏低;基于人脸检测的安全帽佩戴状态检测方法[11,17]无法检测背对或侧对监控设备的目标;基于目标检测的安全帽佩戴状态检测方法[16]对室内监控视频图像中的微小、模糊、重叠目标检测能力不足,漏检率较高.针对上述问题,笔者提出了一种基于改进型Yolov4[19]的室内安全帽佩戴状态检测算法.
本文的主要贡献如下:①针对目前室内安全帽佩戴状态检测实验数据不足的问题,本文建立了专用于室内安全帽佩戴状态检测的ISHWDD数据集,该数据集涵盖鱼眼、枪击、球形3种摄像头采集的室内监控图像.为增强模型的鲁棒性,本文还引入了一般场景下佩戴或未佩戴安全帽的样本作为补充.②本文设计了自校准多尺度特征融合模块(adaptive recalibration multiscale feature fusion module,ARMFFM)并将其嵌入Yolov4模型,有效提高了模型对监控摄像头远端模糊、微小目标的检测能力.③本文对Yolov4模型的检测头(detection head)进行了解耦,使待检测目标的定位任务与佩戴状态分类任务相互独立,加速了模型收敛.④本文提出了Soft-CIoU-NMS后处理方式,在不增加额外计算量的情况下,有效提升了模型对室内监控图像中重叠目标的检测性能.
1 数据准备
如图1所示,本文采集了球形(图1(a))、鱼眼(图1(b))、枪击(图1(c))3种摄像头所拍摄的室内监控视频,随后对视频进行有效帧抽取,最后使用Label-Image对图像进行标注.标注信息包括待检测目标的安全帽佩戴状态与相应的位置坐标,定义未佩戴安全帽目标的标签为0,佩戴安全帽目标的标签为1.此外,为提高模型的泛化能力,本文从SHWD数据集中引入了部分室内或一般场景下佩戴安全帽的样本(图1(d)、(e))作为数据集的补充,还引入了SCUT-HEAD教室监控图像数据集[20]作为未佩戴安全帽样本的补充(图1(f)).最终,本文自建的ISHWDD数据集共计10520张图像,其中7364张图像用于训练,3156张图像用于测试.并且,测试集中的图像大多为模糊、重叠、手持安全帽、佩戴普通帽子等检测难度较高的样本.

图1 ISHWDD数据集样本
ISHWDD数据集中图像的平均大小约为1920× 1080,不利于模型训练.本文将图像大小重调整为608×608.为提高训练数据的多样性,如图2所示,本文使用随机仿射变换(图2(a))、随机旋转(图2(b))、随机裁剪(图2(c))3种数据增强方法模拟自然场景下的可能噪声.最后通过Mix-up[21]的方法将数据增强后的图像进行融合(图2(d)),借以提升模型对待检测目标的定位能力.

图2 数据增强与Mix-up结果
2 安全帽佩戴状态检测模型
本节主要介绍基于改进型Yolov4的室内安全帽佩戴状态检测模型结构及其损失函数设计.如下图3所示,本文提出的安全帽佩戴状态检测模型主要分为特征提取模块(attention-CSP-darknet53)、自校准多尺度特征融合模块ARMFFM以及检测头模块.
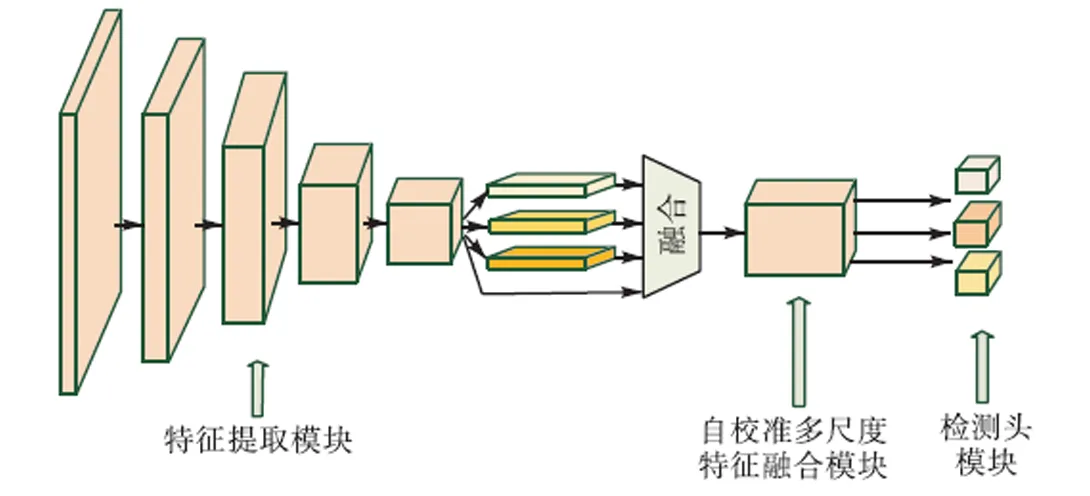
图3 基于改进型Yolov4的室内安全帽佩戴状态检测模型结构
2.1 特征提取
Yolov4使用CSP-darknet53作为特征提取网络.其由5个局部跨阶段(cross stage partial,CSP)网络组成.CSP网络[22]将输入特征图分为两个部分:一部分通过不同数量的残差卷积模块进行计算;一部分直接与残差模块输出进行融合.这样的设计在减少特征提取网络中重复梯度信息的同时,对梯度的反向传播路径进行了优化,进而提升模型的推理速度与特征提取能力.
室内监控摄像头采集的图像大多背景杂乱、质量偏低,安全帽有效特征的提取难度较大.注意力机制被广泛应用于计算机视觉领域,其有助于卷积神经网络关注重点特征,抑制无关特征.因此,笔者在特征提取网络中分别引入了SE通道注意力模块和CBAM通道空间混合注意力模块,借以加强特征提取网络的性能.
2.2 自校准多尺度特征融合
为使待检测目标获得足够大的感受野,在特征提取网络中对输入图像进行了5次下采样.然而,安全帽这类小目标在多次下采样后,相关特征极易丢失[23].因此,笔者提出了自校准多尺度特征融合模块ARMFFM.如图4所示,该模块首先使用深度超参数化卷积(depthwise over-parameterized convolutional,Do-Conv)[24]自顶向下传递语义等深层特征,自底向上传递浅层定位特征,将不同尺度下的安全帽特征进行融合,从而获得更为全面的特征.但是,不同尺度下的特征通常存在冲突,影响模型检测性能[25].所以,笔者设计了特征重校准模块FRM,对融合后的特征图进行逐像素点加强或抑制,使得模型可以在校准后的特征图上进行精确检测.
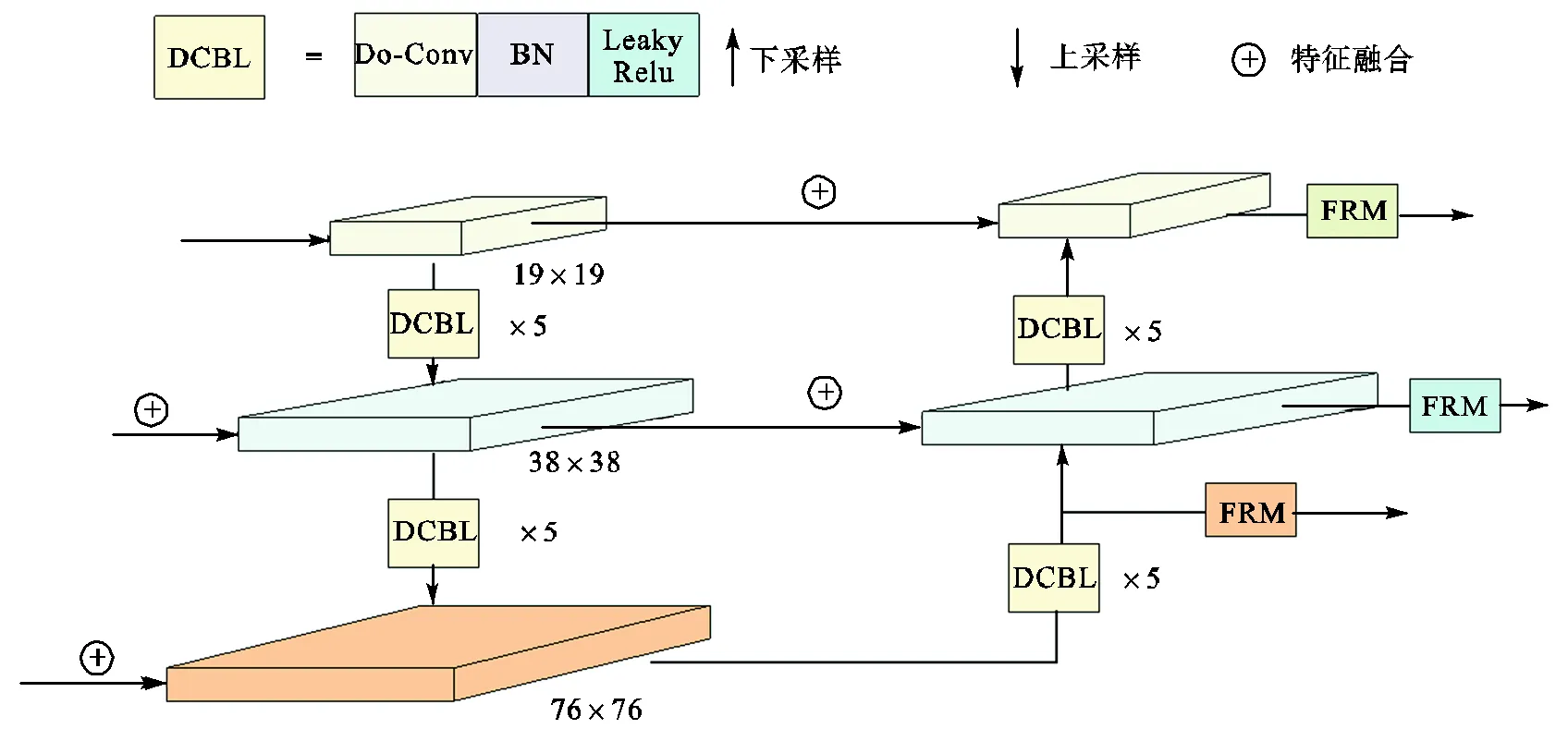
图4 自校准多尺度特征融合模块
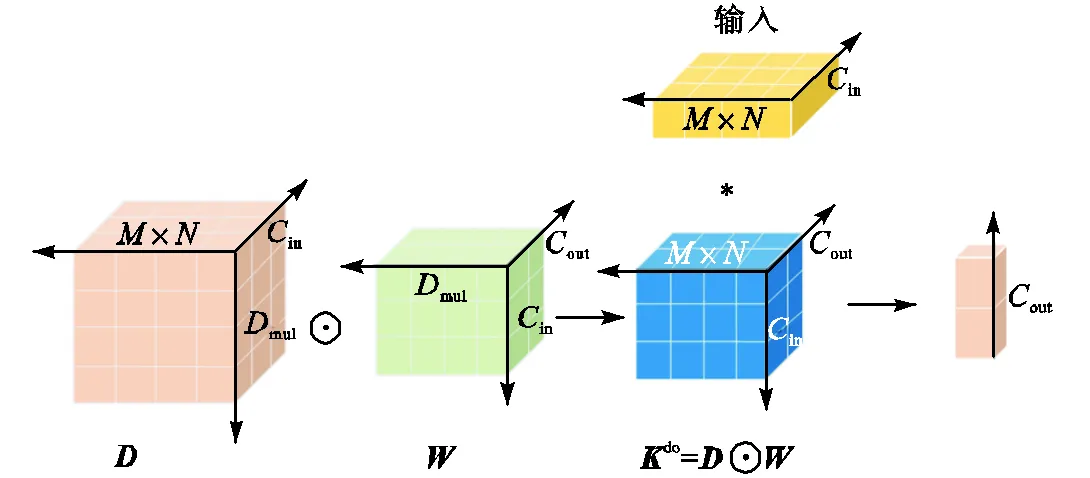
图5 Do-Conv卷积核结构
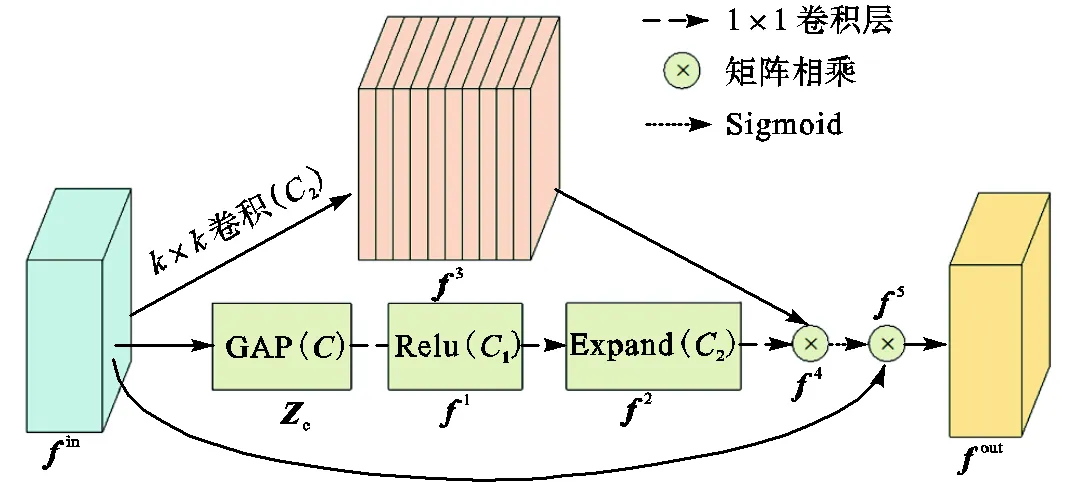
图6 特征重校准模块
2.3 安全帽佩戴检测
目标检测主要包括目标定位与目标分类两大任务,但是由于两种任务的性质与难度不统一,在耦合检测头(即同时预测目标类别、目标位置以及检测框置信度)中,二者常常相互冲突,导致模型收敛时间较长[26-27].因此本文对检测头进行解耦,如图7所示,笔者首先使用一个1×1卷积层将融合后的特征统一到256维,然后使用2个3×3卷积层分别独立且并行地处理安全帽佩戴状态分类任务与待检测目标的定位任务.其中,目标定位分支中还包含了预测框的置信度计算分支.最后使用3个1×1卷积分别输出检测目标类别向量、检测目标坐标向量及对应预测框的置信度向量.
此外,如表1所示,本文对训练集中的目标框进行K-means重聚类分析,得到了9种不同长宽比目标框.随后,将这9种长宽比作为目标定位的先验条件引导模型训练,加速模型学习.
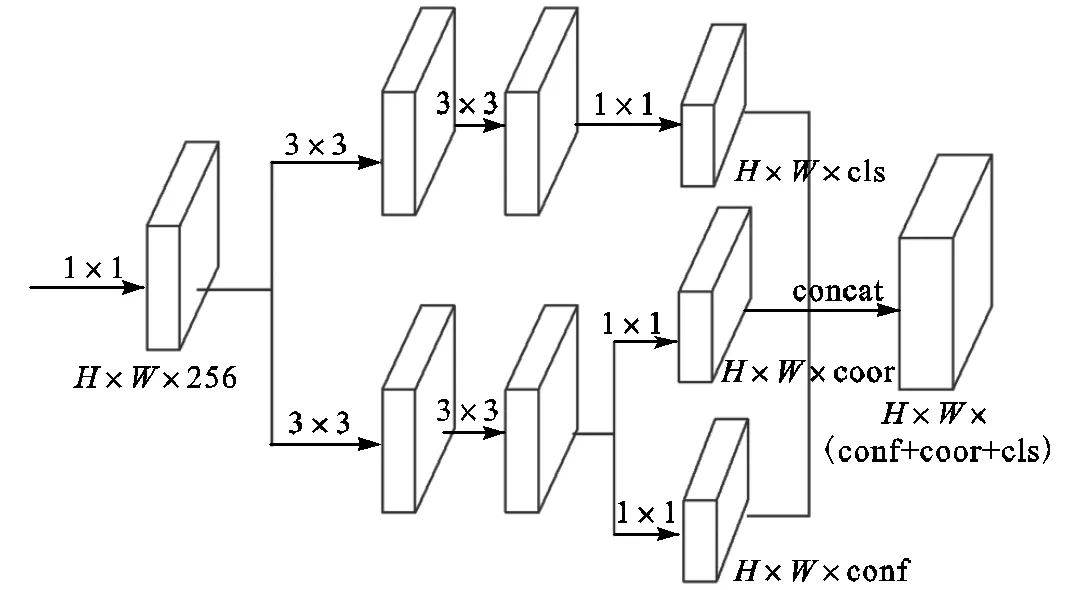
图7 解耦合检测头
表1 ISHWDD数据集尺度聚类结果

Tab.1 Scale clustering result of ISHWDD data set
因此,若t、t、t、t表示每个候选框的中心点坐标预测偏移量以及长宽偏移量,则根据该单元格距离左上角顶点的偏移量以及长宽的先验信息C、C、P、P,即可计算出候选框坐标预测结果b、b、b、b.计算方式为

式中表示Sigmoid激活函数.
预测框的置信度计算方法为
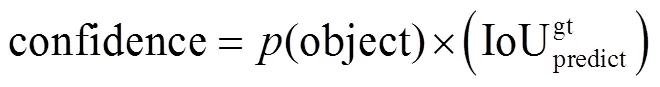
式中:(object)∈(0,1),当目标位于该候选框内时为1,否则为0;IoU表示预测框与实际框之间的重叠程度,即
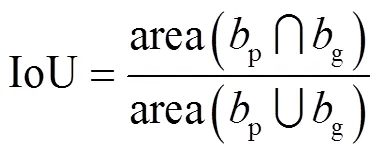
式中p与g分别表示模型预测边界框以及实际边界框.
2.4 损失函数
本文模型的损失函数包括预测框置信度损失Lossconf,预测框坐标损失Losscoor以及安全帽佩戴状态的分类损失Losscls3个部分,即

本文选择交叉熵损失函数作为安全帽佩戴状态分类损失函数与目标框置信度的损失函数.此外,为使得模型有效适应不同摄像头采集的安全帽样本的尺度变化,本文选择C-IoU-Loss[28](complete-IoU Loss)作为坐标回归损失函数,即
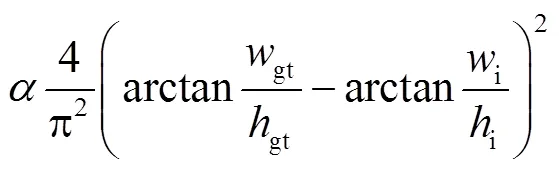
式中:i和gt分别代表预测框和真实框的坐标;和分别代表预测框与实际边界框的欧几里得距离和最小对角线距离;代表权重函数;i、i分别代表模型预测框长和宽;gt、gt是实际框长、宽.
2.5 Soft-CIoU-NMS后处理
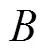
算法1 Soft-CIoU-NMS后处理算法
end
end
3 实验结果与分析
3.1 模型训练与评价指标
本实验平台基于Ubuntu16.04的64位操作系统、Tesla V-100 GPU以及Intel Xeon 4116搭建.使用PyTorch 1.2.0框架构建模型.在训练时,使用Yolov4模型在VOC2007数据集上的权重作为模型的训练初值,采用SGD方法优化模型,其初始化参数如表2所示,共计训练100轮(epoch).在最初的2个epoch内采用学习率热身的方式将学习率从0平缓增长至0.0001,然后采取余弦退火算法更新学习率.为使得模型能够更好地检测出不同尺度下的目标,本文采取多尺度训练方式,即每10次迭代就从{320,352,…,608}中随机选取一个值作为模型的输入大小.在测试阶段,模型输入大小均设置为608×608.
表2 模型训练参数

Tab.2 Training parameters of the proposed model
本文选取目标检测领域常用的平均准确率(mean average precision,MAP)作为本模型的评价指标,如式(6)所示,MAP值等于各类别精度()与召回率()平滑曲线在0~1上的积分值.


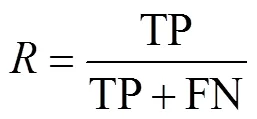
式中:TP表示预测框与真实框交并比(IoU)大于设定阈值,且二者类别相同;反之则认为是负样本,记为FP;若模型未预测出真实框则认为模型漏检,记为FN.本文模型IoU阈值设定为0.5.
3.2 实验结果与讨论
笔者每训练完一个epoch,就在测试集上对模型进行验证,测试日志的可视化结果如图8所示.从测试上的检测准确率曲线可以看出,本文所提模型(融合SE注意力模块)的收敛速度与检测性能明显优于原Yolov4模型.本文模型在第95个epoch中取得了最佳准确率,达到了95.1%.
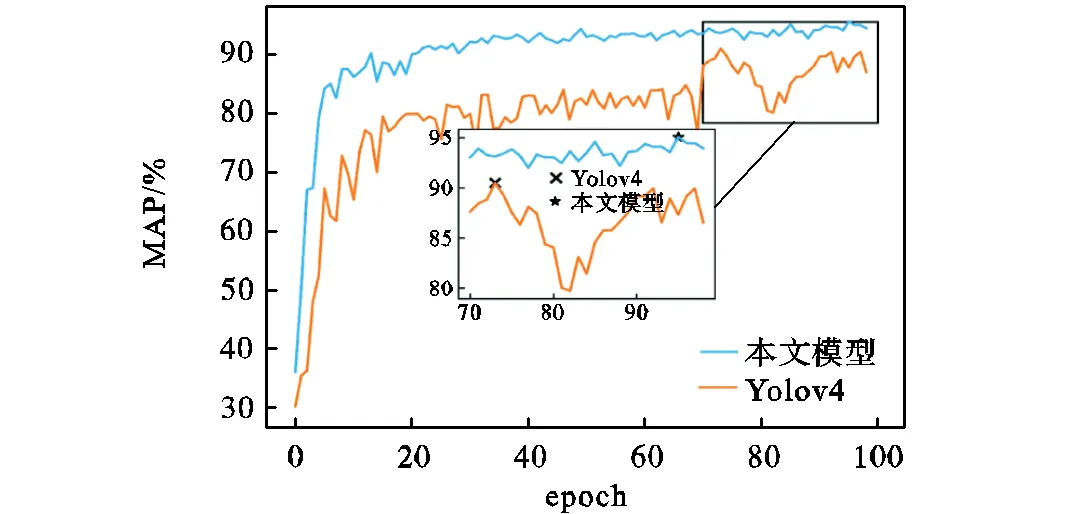
图8 测试日志可视化结果
本文模型(融合SE注意力模块)检测结果如图9所示,从检测结果可以看出,本文模型能够有效检测佩戴不同颜色安全帽的样本(图9(a)~(c))、佩戴其他帽子的样本(图9(d)、(e))、以及手持安全帽的样本(图9(f)).同时本文模型对于重叠目标样本(图9(g))和摄像头远端样本(图9(h)、(i))的检测能力也较为优秀.

图9 检测结果
为详细验证各模块对于模型性能的提升效果,使用相同平台进行消融实验,模型训练参数与第3.1节中的训练参数相同,实验结果如表3所示,表中模型参数量通过THOP库进行统计.
表3中第一行为原Yolov4模型的实验结果.从表3中第2~3行结果可以看出,引入SE注意力模块与CBAM注意力模块可在微量增加模型参数量的情况下,有效加强了模型对佩戴安全帽或未佩戴安全帽样本相关特征的提取.模型的准确率分别提升了0.8%与0.4%.但是由于CBAM注意力模块中存在额外的卷积计算,使得模型实时性有所降低,推理时间增加了约40ms.
表3 消融实验结果

Tab.3 Ablation experiment results
表3中第4行实验结果表明使用Soft-CIoU-NMS后处理算法可以在不增加模型参数量情况下,将模型检测准确率提升了约0.6%,并且如图10(a)、(b)所示,Soft-CIoU-NMS后处理算法对于重叠目标的检测更为友好,有效降低了模型漏检的可能性.

图10 重叠目标、远端模糊、微小目标检测结果
表3中第5行实验结果表明,相比于耦合检测头,使用解耦检测头可在模型参数量仅增加0.88×106的情况下,使模型准确率上升约0.5%,并且如图11所示,使用解耦检测头可加速模型收敛.
表3中6~8行的实验结果表明,使用3×3卷积层补充空间信息的ARMFFM模块性能最佳,如图12所示,由于缺乏预训练初值,模型在训练早期较为震荡,但是模型准确率最终提升了约3.4%.虽然引入ARMFFM模块(3×3)使得模型参数量增加了约4.91×106,但是如图10(c)~(f)所示,使用ARMFFM模块对融合多尺度信息的特征图进行自适应校准后,模型对远端模糊、微小目标的安全帽佩戴状态检测性能有明显提升.综上所述,本文对Yolov4模型的改进,对于真实场景下的安全帽佩戴检测任务具有一定的积极意义.
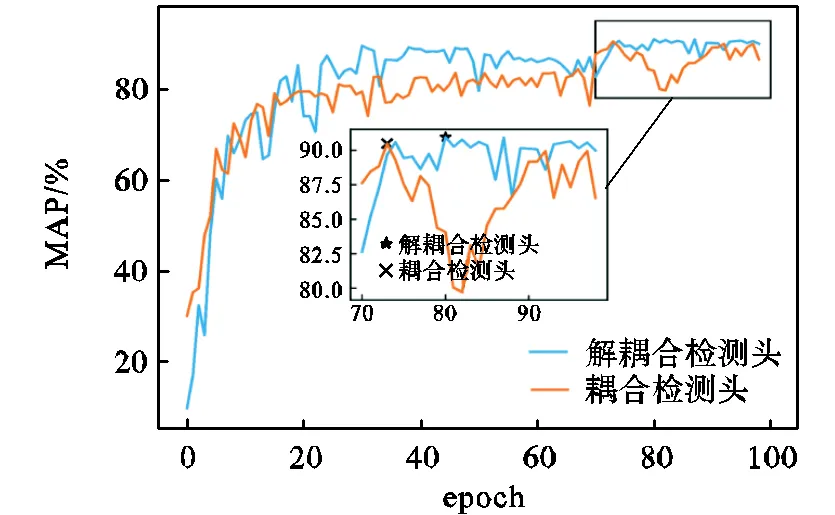
图11 解耦合检测头测试日志可视化
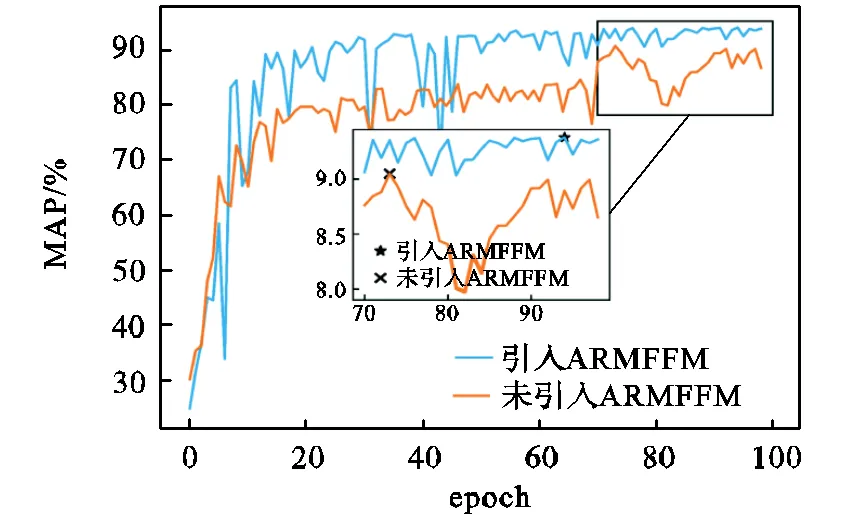
图12 自校准多尺度特征融合模块测试日志可视化
随后,笔者使用同一数据集在同一平台上训练常用目标检测模型,实验结果如表4所示.SSD、RetinaNet、Faster R-CNN、Yolov4以及本文模型采用Pytorch框架,DETR、PP-Yolov2采用PaddlePaddle框架.相比于SSD、RetinaNet、Faster R-CNN、DETR[30]目标检测模型,本文所提的检测模型在实时性、准确率方面均有明显提升,准确率分别上升16.9%、9.6%、6.2%、7%,推理时间分别下降3ms、24ms、157ms、128ms. 相比于Yolov4、PP-Yolov2[30]模型,本文模型准确率分别提高了4.7%、2.4%,推理时间分别增加了约19ms、30ms,虽然推理时间有所增加,但是模型的检测速度达到了21帧/s,依旧能够满足室内场景下安全帽佩戴状态检测任务的实时性要求.总的来说,相比于常用目标检测模型,本文模型在室内场景下的安全帽佩戴状态检测任务上具有一定的优越性.
表4 目标检测基线模型安全帽检测结果对比
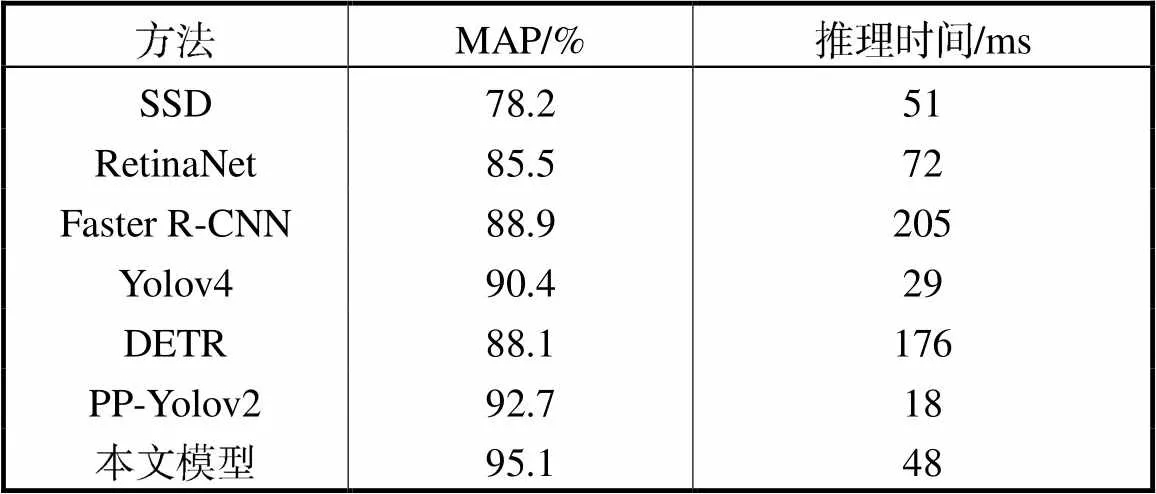
Tab.4 Comparison results with the baseline models
4 结 语
本文针对室内场景下的安全帽佩戴状态检测问题,提出了改进型Yolov4检测算法.首先,本文自建了室内场景下的安全帽佩戴状态检测数据集ISHWDD.随后,设计了自校准多尺度特征融合模块并将其嵌入Yolov4网络中,提高了模型对于摄像头远端的模糊、微小目标的检测能力.然后,使用解耦合检测头加速模型收敛.最后,使用软性非极大值抑制后处理算法降低模型对监控图像中重叠目标的漏检可能性.在自建数据集上,相比于原Yolov4模型,本文模型实现了更为优秀的检测性能,能够有效提高室内作业人员佩戴安全帽的监管效率.由于实际生产环境的复杂性,无可避免地存在一些错检,未来将研究提升特征提取网络模型性能,进一步提升模型准确率.
[1] Barro S,Fernández T M,Pérez H J,et al. Real-time personal protective equipment monitoring system[J]. Computer Communications,2012,36(1):42-50.
[2] Kim S H,Wang C,Min S D,et al. Safety helmet wearing management system for construction workers using three-axis accelerometer sensor[J]. Applied Sciences,2018,8(12):2400.
[3] Kelm A,Laubat L,Meins-Becker A,et al. Mobile passive radio frequency identification(RFID)portal for automated and rapid control of personal protective equipment(PPE)on construction sites[J]. Automation in Construction,2013,36:38-52.
[4] Zhang H,Yan X,Li H,et al. Real-time alarming,monitoring,and locating for non-hard-hat use in construction[J]. Journal of Construction Engineering and Management,2019,145(3):04019006.
[5] Dong S,He Q,Li H,et al. Automated PPE misuse identification and assessment for safety performance enhancement[C]//2015 International Conference on Construction and Real Estate Management. Lulea,Sweden,2015:204-214.
[6] Fang W,Ding L,Luo H,et al. Falls from heights:A computer vision-based approach for safety harness detection[J]. Automation in Construction,2018,91:53-61.
[7] Park M W,Elsafty N,Zhu Z. Hardhat-wearing detection for enhancing on-site safety of construction workers[J]. Journal of Construction Engineering and Management,2015,141(9):04015024.
[8] Dahiya K,Singh D,Mohan C K. Automatic detection of bike-riders without helmet using surveillance videos in real-time[C]//2016 International Joint Conference on Neural Networks(IJCNN). Vancouver,Canada,2016:3046-3051.
[9] Silva R,Aires K,Santos T,et al. Automatic detection of motorcyclists without helmet[C]//2013 ⅩⅩⅩⅨ Latin American Computing Conference(CLEI). Caracas,Venezuela,2013:1-7.
[10] Rubaiyat A H M,Toma T T,Kalantari-Khandani M,et al. Automatic detection of helmet uses for construction safety[C]//2016 International Conference on Web Intelligence Workshops(WIW). Omaha,USA,2016:135-142.
[11] Shrestha K,Shrestha P P,Bajracharya D,et al. Hard-hat detection for construction safety visualization[J]. Journal of Construction Engineering,2015,2015(1):1-8.
[12] 黄志清,贾 翔,郭一帆,等. 基于深度学习的端到端乐谱音符识别[J]. 天津大学学报(自然科学与工程技术版),2020,53(6):653-660.
Huang Zhiqing,Jia Xiang,Guo Yifan,et al. End-to-end music note recognition based on deep learning[J]. Journal of Tianjin University(Science and Technology),2020,53(6):653-660(in Chinese).
[13] 梁 煜,李佳豪,张为,等. 嵌入中心点预测模块的 Yolov3 遮挡人员检测网络[J]. 天津大学学报(自然科学与工程技术版),2021,54(5):517-525.
Liang Yu,Li Jiahao,Zhang Wei,et al. Embedded center prediction module of Yolov3 occlusion human detection network[J]. Journal of Tianjin University (Science and Technology),2021,54(5):517-525(in Chinese).
[14] 张 为,魏晶晶. 嵌入DenseNet 结构和空洞卷积模块的改进YOLOv3 火灾检测算法[J]. 天津大学学报(自然科学与工程技术版),2020,53(9):976-983.
Zhang Wei,Wei Jingjing. Improved YOLOv3 fire detection algorithm embedded in DenseNet structure and dilated convolution module[J]. Journal of Tianjin University(Science and Technology),2020,53(9):976-983(in Chinese).
[15] 高春艳,赵文辉,张明路,等. 一种基于YOLOv3 的汽车底部危险目标检测算法[J]. 天津大学学报(自然科学与工程技术版),2020,53(4):358-365.
Gao Chunyan,Zhao Wenhui,Zhang Minglu,et al. A vehicle bottom dangerous object detection algorithm based on YOLOv3[J]. Journal of Tianjin University (Science and Technology),2020,53(4):358-365(in Chinese).
[16] Fang Q,Li H,Luo X,et al. Detecting non-hardhat-use by a deep learning method from far-field surveillance videos[J]. Automation in Construction,2018,85:1-9.
[17] Shen J,Xiong X,Li Y,et al. Detecting safety helmet wearing on construction sites with bounding-box regression and deep transfer learning[J]. Computer-Aided Civil and Infrastructure Engineering,2021,36(2):180-196.
[18] Li J,Wang Y,Wang C,et al. DSFD:Dual shot face detector[C]//2019 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach,USA,2019:5060-5069.
[19] Bochkovskiy A,Wang C Y,Liao H Y M. Yolov4:Optimal speed and accuracy of object detection[EB/OL]. https://arxiv.org/abs/2004.10934,2020-04-23.
[20] Peng D,Sun Z,Chen Z,et al. Detecting heads using feature refine net and cascaded multi-scale architecture [C]//24th International Conference on Pattern Recogni-tion(ICPR). Beijing,China,2018:2528-2533.
[21] Zhang H,Cisse M,Dauphin Y,et al. Mixup:Beyond empirical risk minimization[EB/OL]. https://arxiv.org/ abs/1710. 09412,2017-10-25.
[22] Wang C Y,Liao H Y,Wu Y H,et al. CSPNet:A new backbone that can enhance learning capability of CNN[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020:390-391.
[23] Liu S,Qi L,Qin H,et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:8759-8768.
[24] Cao J,Li Y,Sun M,et al. DO-Conv:Depthwise over-parameterized convolutional layer[EB/OL]. https:// arxiv.org/abs/2006.12030,2020-06-22.
[25] Yu X,Wu S,Lu X,et al. Adaptive multiscale feature for object detection[J]. Neurocomputing,2021,449:146-158.
[26] Song G,Liu Y,Wang X. Revisiting the sibling head in object detector[C]//Proceedings of the IEEE/CVF Con-ference on Computer Vision and Pattern Recognition. 2020:11563-11572.
[27] Wu Y,Chen Y,Yuan L,et al. Rethinking classifica-tion and localization for object detection[C]//Proceed-ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020:10186-10195.
[28] Zheng Z,Wang P,Liu W,et al. Distance-IoU loss:Faster and better learning for bounding box regression [C]//Proceedings of the AAAI Conference on Artificial Intelligence. New York,USA,2020:12993-13000.
[29] Huang X,Wang X X,Lü W Y,et al. PP-YOLOv2:A practical object detector[EB/OL]. https://arxiv.org/abs/ 2104.10419,2021-04-21.
[30] Carion N,Massa F,Synnaeve G,etal. End-to-end object detection with transformers[C]//European Confer-ence on Computer Vision. 2020:213-229.
Indoor Safety Helmet-Wearing Detection Algorithm Based on Improved Yolov4
Huang Zhiqing1,Zhang Yusen1,Zhang Yanxin2,Ren Keyan1
(1. Faculty of Information Technology,Beijing University of Technology,Beijing 100124,China;2. School of Electronic and Information Engineering,Beijing Jiaotong University,Beijing 100044,China)
An improved Yolov4 algorithm was proposed to autodetect indoor safety helmet-wearing. First,a data set dedicated to the indoor safety helmet-wearing detection was self-built for testing and evaluating the algorithm due to a lack of safety helmet-wearing detection experimental data in indoor scenarios. Then,an adaptive recalibration multiscale feature fusion module(ARMFFM) was designed and embedded into the original Yolov4 network to improve the detection accuracy of fuzzy and tiny targets far away from the surveillance camera. In ARMFFM,the features were fused top-down and bottom-up at different scales through depthwise over-parameterized convolutional layers for the fuzzy and tiny objects to obtain the more obvious texture and feature at first. Afterwards,the feature recalibration module strengthened or suppressed each pixel in the fused feature map to make the model precisely detect it to avoid a conflict among the feature maps at different scales. Furthermore,a decoupled detection head replaced the detection head of the original Yolov4 for the individual performances of the location and classification tasks of the indoor safety helmet-wearing detection. Additionally,a Soft-CIoU-NMS post-process algorithm was developed for detecting overlapping targets. The experimental results demonstrated that the accuracy of the improved Yolov4 algorithm in the detection of safety helmet-wearing in indoor scenarios reached 95.1%,about 4.7% higher than that of the original Yolov4. Besides,the detection precision of fuzzy,tiny and overlapping targets was significantly enhanced,proving the superiority of the algorithm for indoor safety helmet-wearing detection.
computer vision;video surveillance;deep learning;safety helmet-wearing detection;Yolov4
TP391.4
A
0493-2137(2023)01-0064-09
10.11784/tdxbz202111026
2021-11-14;
2022-04-06.
黄志清(1970— ),男,博士,副教授.
黄志清,zqhuang@bjut.edu.cn.
国家自然科学基金青年基金资助项目(618002044).
Supported by the Youth Fund of the National Natural Science Foundation of China(No. 618002044).
(责任编辑:王晓燕)
