融合多尺度上下文信息的实例分割
2023-02-21万新军周逸云沈鸣飞周涛胡伏原
万新军,周逸云,沈鸣飞,周涛,胡伏原*
1. 苏州科技大学电子与信息工程学院,苏州 215009; 2. 苏州市虚拟现实智能交互及应用技术重点实验室,苏州 215009; 3. 北方民族大学计算机科学与工程学院,银川 750021
0 引 言
实例分割(王子愉 等,2019)是图像及视频场景理解的基础任务,精确的实例分割在自动驾驶(Zhou等,2020)、医学影像分割(林成创 等,2020)和视频监控(黄泽涛 等,2021)等实际场景中具有广泛应用。随着深度卷积神经网络的快速发展,实例分割技术取得显著进展,主要包括单阶段实例分割方法和两阶段实例分割方法。
单阶段实例分割方法形式多样。YOLACT(you only look at coefficients)(Bolya等,2019)为每个实例预测一组原型掩膜和掩膜系数,并通过矩阵乘法组合;PolarMask(Xie等,2020)利用实例中心点分类和密集距离回归,基于极坐标系对实例掩膜进行建模;SOLO(segmenting objects by locations)(Wang等,2020)将实例类别定义为目标的位置和尺寸,将实例分割任务分为类别预测和生成实例掩膜两个子任务。单阶段方法需要同时定位、分类和分割对象,特别是不同尺度目标,难度更大,虽然速度较快,但分割精度提升受限,在解决目标多尺度问题上不具有优势。
两阶段实例分割方法首先使用检测器生成候选区域,然后针对候选区域进行分割,并为每个实例生成像素级掩膜。Mask R-CNN(mask region-based convolutional neural network)(He等,2017)通过扩展Faster R-CNN(Ren等,2017),增加掩膜预测分支来分割候选框中的目标,该算法对于检测和分割两个阶段的高效利用,极大提高了分割精度。以下算法都是在Mask R-CNN框架基础上的改进。PANet(path aggregation network)(Liu等,2018)通过添加一条自底向上的路径,增强了特征金字塔网络(feature pyramid network,FPN)(Lin等,2017)的多层次特征表示;MaskLab(Chen等,2018)产生边界框检测、语义分割和方向预测3个输出,通过组合语义和方向预测来执行前景和背景分割;MS RCNN(mask scoring region-based convolutional neural network)(Huang等,2019a)缓解了掩膜质量和评分之间的偏差;Wen等人(2020)提出联合多任务级联结构,并在全卷积网络分支中引入特征融合,有效联合了高低层特征;BMask R-CNN(boundary-preserving mask region-based convolutional neural network)(Cheng等,2020)利用额外的分支直接估计边界来增强掩膜特征的边界感知。DCT-Mask(discrete cosine transform mask)(Shen等,2021)使用离散余弦变换将高分辨率二进制掩膜编码成紧凑的向量。两阶段方法经过不断改进,有效提高了分割精度。但上述方法未从多尺度目标变化角度提出解决方案,因此分割精度仍有提升空间。
多尺度上下文信息通过增强特征表示,可以有效提高分割性能。在图像分割领域已有一些工作致力于提取和融合多尺度上下文信息。PSPNet(pyramid scene parsing network)(Zhao等,2017)通过金字塔池模块和金字塔场景解析网络,利用不同尺度的上下文信息聚合来实现高质量的场景分割;CCNet(criss-cross network)(Huang等,2019b)通过循环交叉注意模块获取密集的上下文信息进行语义分割;HTC(hybrid task cascade)(Chen等,2019a)增加了语义分割分支来整合FPN各层特征的上下文信息,以增强目标前景和背景的判别性特征用于实例分割;Zhang等人(2022)设计了语义注意模块和尺度互补掩膜分支,以充分利用多尺度上下文信息解决遥感图像实例分割问题;吉淑滢和肖志勇(2021)使用金字塔卷积和密集连接的集成提取多尺度信息,并充分融合上下文和多尺度特征进行胸部多器官分割;丁宗元等人(2021)提出融合不同尺度交互映射的双路网络结构用于提取目标的多尺度特征,显著提升交互式图像分割性能;RefineMask(Zhang等,2021)使用空洞卷积设计了语义融合模块,将捕获的多尺度上下文信息用于实例分割。
但是,目标多尺度变化导致实例分割精度提升受限。对此,本文在两阶段实例分割模型Mask R-CNN的基础上,提出了融合多尺度上下文信息的实例分割算法。首先,提出注意力引导的特征金字塔网络(attention-guided feature pyramid network,AgFPN),通过邻层特征自适应融合模块(adjacent-layer feature adaptive fusion module,AFAFM)对FPN邻层特征融合方式进行优化,使用内容感知重组(Wang等,2019)对特征上采样,并在邻层特征融合前使用通道注意力机制(Hu等,2020)对通道加权,增强语义一致性。其次,引入多尺度通道注意力(multi-scale channel attention, MSCA)(Dai等,2021)构造了注意力特征融合模块(attentional feature fusion module, AFFM)和全局上下文模块(global context module,GCM)来整合多尺度特征,并将感兴趣区域(region of interest,RoI)特征与目标多尺度上下文信息(multi-scale contextual information,MSCI)进行融合,增强了分类回归和掩膜预测两个分支的多尺度特征表示。通过在MS COCO 2017(Microsoft common objects in context 2017)(Lin等,2014)和Cityscapes(Cordts等,2016)两个数据集上进行训练和评估,所提方法有效提高了实例分割的精度,显著提升了不同尺度目标在相互遮挡和分界处的定位、识别和分割性能。
1 本文算法
为解决目标多尺度变化问题,本文提出了融合多尺度上下文信息的实例分割算法。如图1所示,所提算法网络结构以Mask R-CNN框架为基础,首先,使用注意力引导的特征金字塔网络AgFPN提取图像多尺度特征,主干网络的特征层次表示为{f2,f3,f4,f5},邻层特征自适应融合后得到的自顶向下的特征表示为{p2,p3,p4,p5}。接着,进行多尺度上下文信息提取与融合。其中,区域建议网络(region proposal network,RPN)对目标区域建议边界框,进行前景和背景的分类和边界框的回归,并筛选感兴趣区域RoI;同时,多尺度上下文信息通过注意力特征融合模块和全局上下文模块从AgFPN中获得。然后,使用RoIAlign算法根据目标检测框的位置,将RoI映射到特征图中获得固定尺寸的特征图,进而与多尺度上下文信息进行融合。最后,利用融合特征进行边界框回归和掩膜预测。
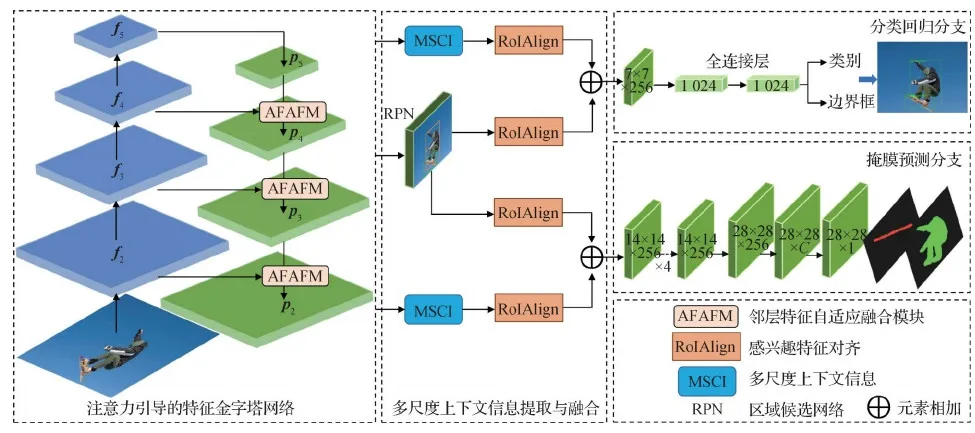
图1 融合多尺度上下文信息的实例分割模型
通过更高效的AgFPN进行特征提取以及多尺度上下文信息聚合,可以有效提高不同尺度目标的实例分割性能。
1.1 注意力引导的特征金字塔网络
多尺度特征表示是检测和分割不同尺度目标的有效方法,为了充分利用高层语义特征和底层细粒度特征,FPN成为实例分割算法的通用网络。
但是,在FPN自顶向下的特征融合路径中,不同层的特征融合采用最近邻插值和元素相加的方法,插值只依赖特征的相对位置而无法利用丰富的语义信息,直接元素相加忽略了相邻特征之间的语义差距而产生混叠效应。FPN邻层特征的融合方式不能充分利用不同尺度的特征,因此,本文提出AgFPN,通过邻层特征自适应融合模块AFAFM对FPN邻层特征融合方式进行优化。
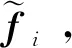
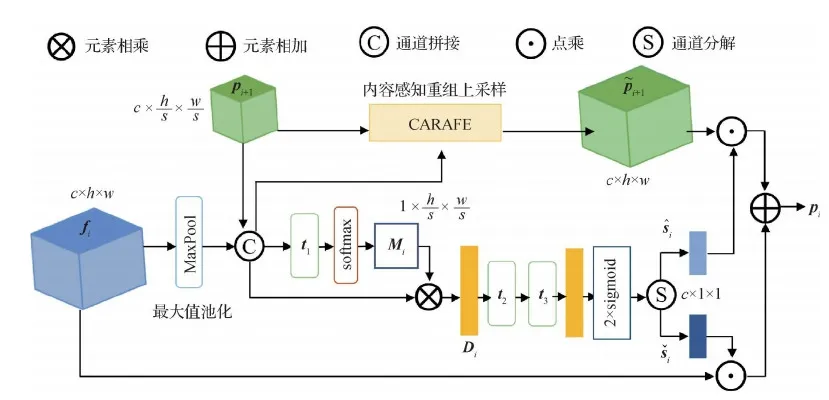
图2 邻层特征自适应融合模块结构图
上述过程可具体描述为
(1)
(2)
(3)
(4)
式中,t1∈R1×2c×1×1,t2∈R(c/s)×2c×1×1,t3∈R2c×(c/s)×1×1,s=2为尺度因子;LN代表层归一化,δ表示激活函数ReLU(rectified linear unit);2σ表示激活函数2 × sigmoid,该函数可使通道权值连续相乘后的均值为1,并可选择性地激发或抑制特征,⊙表示点乘。
1.2 多尺度上下文信息提取与融合
Mask R-CNN算法在检测和掩膜分支中仅利用到RoI特征,由于缺乏多尺度上下文信息,掩膜预测质量提高受限。
因此,本文通过引入多尺度通道注意力,设计了AFFM模块来整合多尺度特征,以及GCM模块来挖掘融合特征中的多尺度上下文信息,并将上下文信息与RoI特征融合,从而使模型能够更好地预测实例分割结果。
具体来说,给定RoI,使用RoIAlign算法从相应层次的FPN输出中提取小的特征块(例如7 × 7或14 × 14)。同时,对多尺度上下文信息特征应用RoIAlign,得到相同尺寸的特征块,然后将两个分支的特征按元素求和进行组合。MSCI的结构设计如图3所示。首先,利用AFFM聚合相邻层特征;然后,GCM提取融合特征的上下文信息为新的特征层,并与下一层特征进行注意力特征融合,依次迭代;最后,得到来自不同层的多尺度上下文信息。
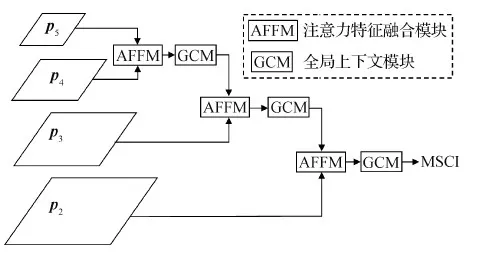
图3 多尺度上下文信息提取与融合
1.2.1 注意力特征融合模块
将不同层或分支的特征进行融合通常利用加法求和或通道拼接等简单操作,无法有效利用上下文信息。因此,本文提出注意力特征融合模块AFFM,通过引入多尺度通道注意力MSCA有效融合跨层特征,利用多尺度上下文信息缓解多尺度变化的影响。
MSCA对不同尺度目标具有较强的适应性,其结构如图4(a)所示。MSCA使用双分支并行结构,其中一个分支利用全局平均池化提取和增强特征图的全局上下文信息,另一个分支保持原始特征分辨率以获取局部上下文信息,避免忽略较小尺度目标。MSCA利用两个分支的逐点卷积沿通道维度压缩和恢复特征,从而聚合多尺度通道上下文信息,便于网络识别和检测极端尺度变化下的目标。
AFFM结构如图4(b)所示,表示为

(5)
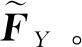
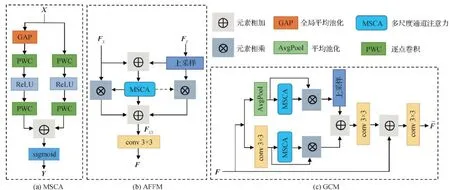
图4 3种网络结构图
AFFM引入了多尺度通道注意力,通过挖掘通道之间的相互依赖关系,对不同层次的多尺度特征进行融合,获得了注意力信息引导的融合特征。
1.2.2 全局上下文模块
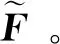
FC=conv(F),FCA=FC⊗A(FC)
(6)
FP=conv(Pool(F)),FPA=FP⊗A(FP)
(7)
(8)
式中,conv,Pool,A和upsample分别代表卷积、平均池化、MSCA和上采样操作。
GCM用于在特定级别自适应地提取多尺度上下文信息,改进不同尺度和特定语义的特征表示,自适应地整合全局和局部特征,可以有效提高多尺度目标的分割精度。
2 实验与结果分析
为了验证本文算法的性能,在MS COCO 2017和Cityscapes数据集上进行实验,与相关方法进行视觉效果和定量结果对比,使用平均精度(average precision,AP)作为评价指标,并在MS COCO 2017数据集上进行消融实验。
2.1 实验数据集与评价指标
MS COCO 2017数据集包含80个实例级标签类别,模型使用训练集的115 000幅图像进行训练,对5 000幅验证集图像进行测试,最终展示了20 000幅测试数据集图像上的定量结果。
Cityscapes数据集包含大量城市街道场景图像,提供了语义、实例特定和像素特定的注释,分别有2 975、500和1 525幅图像用于训练、验证和测试。对于实例分割任务,有8个实例类别。

2.2 实验环境与参数
利用深度学习框架PyTorch实现所提算法,实验环境为Ubuntu 16.04操作系统,使用4块NVIDIA 1080Ti图形处理器(graphics processing unit,GPU)加速运算。
在MS COCO 2017数据集上,本文方法分别使用ResNet-50和ResNet-101作为主干网络,并利用ImageNet上预训练的权重来初始化网络参数。实验采用随机梯度下降法(stochastic gradient descent,SGD)进行16万次迭代训练优化,初始学习率为0.002,batch size设为4,当迭代次数为13万次和15万次时,学习率分别降低10倍。设置权重衰减(weight decay)系数为0.000 5,动量(momentum)系数设为0.9。损失函数和其他超参数均按照mmdetection(Chen等,2019b)中描述的策略进行设置和初始化。
在Cityscapes数据集上,使用ResNet-50作为主干网络,batch size设为4,迭代次数为48 000次,初始学习率为0.005,当迭代到36 000次时,学习速率降至0.000 5。其他设置与在MS COCO 2017数据集上的实验相同。
2.3 定量结果分析
在MS COCO 2017测试集上,将所提方法与经典的两阶段方法和其他单阶段方法进行分割精度的对比,结果如表1所示。其中,AP50和AP75分别表示IoU阈值为0.5和0.75时的平均精度,APS、APM和APL分别是小、中、大3种不同尺度目标的平均精度。可以看出,所提算法相较于基线Mask R-CNN在主干网络为ResNet50和ResNet101时分别提高了1.7%和2.5%;在多尺度目标分割精度上,以主干网络ResNet50为例,APS和APM分别提高了1.6%和2.6%,说明利用AgFPN进行特征提取,并在RoI特征中引入多尺度上下文信息,有效提高了中小目标的掩膜预测质量。
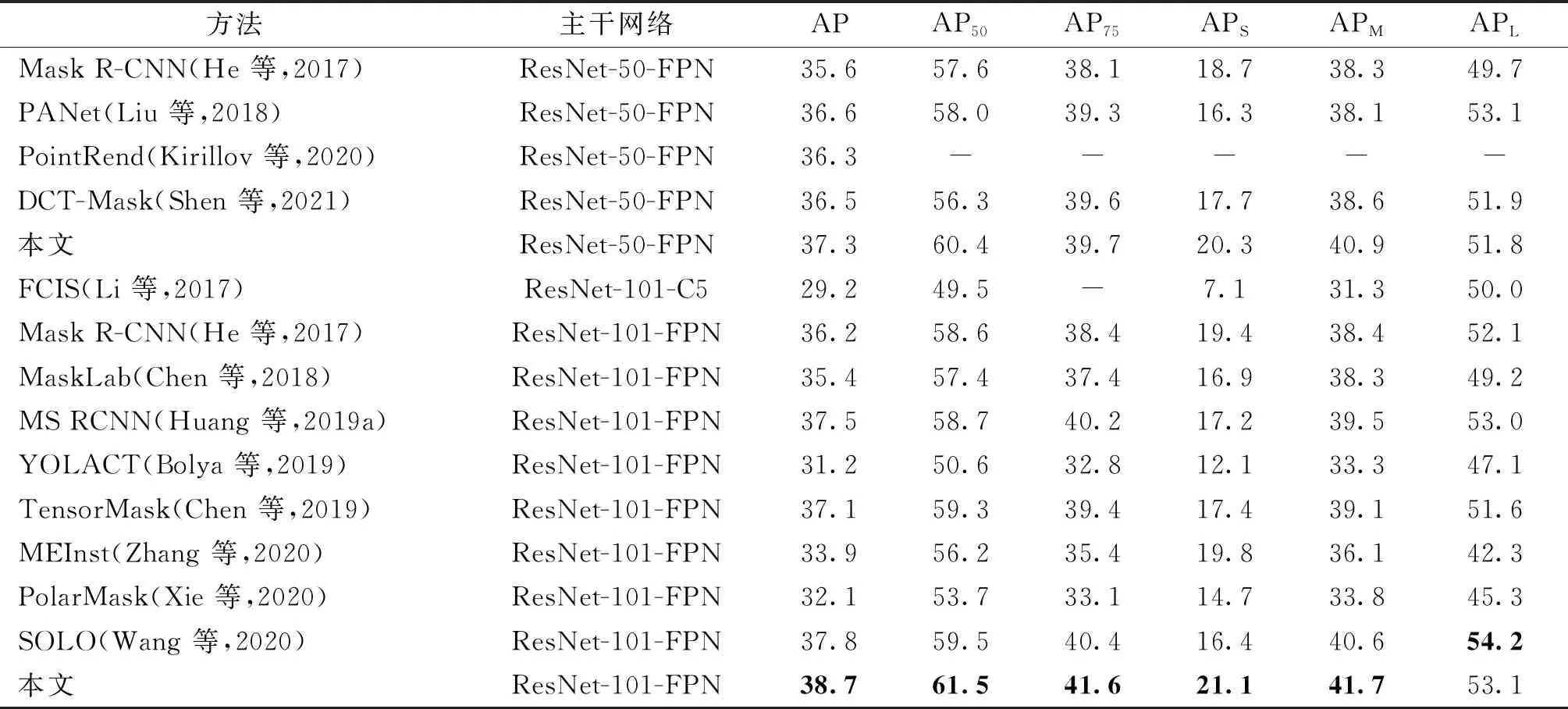
表1 实例分割模型在MS COCO 2017测试集上的平均精度对比
本文方法与其他两阶段方法如PANet和MS RCNN等相比具有一定的竞争优势,且分割精度高于流行的YOLACT(you only look at coefficients)、PolarMask和SOLO等单阶段方法。但是,本文方法在大尺度目标的分割精度APL上低于SOLO算法,表明所提方法在大型目标的边缘分割精度上还有提升空间。
在Cityscapes数据集上,对比了部分实例分割模型的平均精度,主干网络均采用ResNet-50。实验结果如表2所示。其中,AP[val]表示Cityscapes 验证子集的结果,AP和AP50表示Cityscapes测试子集的结果。fine表示只使用精细数据进行训练,coarse表示粗糙数据,fine + coco表示使用精细数据并在MS COCO 2017数据集上进行预训练。
从表2可以看出,所提方法使用fine + coco训练策略,在验证子集和测试子集上进行性能评估,比Mask R-CNN分别提高了2.1%和2.3%,有效提高了实例分割精度,同时优于PANet和BMask RCNN等实例分割方法。实验结果表明,所提方法具有较强的模型泛化性和对不同尺度目标的识别鲁棒性。
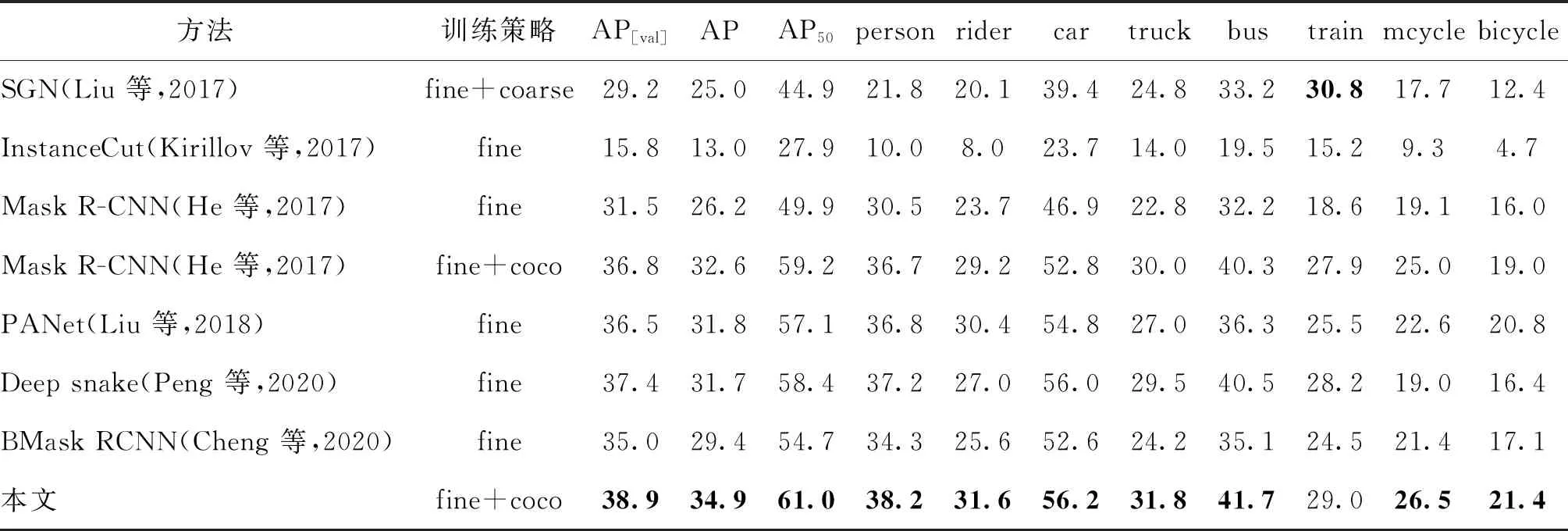
表2 Cityscapes数据集上实例分割模型的平均精度对比
2.4 可视化结果展示与对比分析
2.4.1 在MS COCO 2017数据集上多尺度目标下的可视化结果展示
MS COCO 2017数据集上多尺度目标实例分割的可视化结果如图5所示。可视化结果表明,本文方法对多尺度目标具有较好的定位、分类和分割效果。由于远、小目标信息较少,通过在分类回归和掩膜预测分支中弥补目标多尺度上下文信息可以有效提高小目标的识别精度,更有利于分割。同时,AgFPN可以有效缓解FPN邻层不同尺度目标的语义特征混叠,减少多尺度目标错检和漏检概率,显著提高多尺度目标的分割精度。

图5 在MS COCO 2017数据集上多尺度目标实例分割的可视化结果
此外,本文方法在不同目标边界位置以及存在遮挡的情况下有较好的预测结果。如图6第1、2行所示,本文方法可以识别到被“足球”遮挡的“手”属于“运动员”,能准确识别出被“轿车”遮挡的目标是“马”,而其他算法或漏检或错检。如图6第3、4行所示,在不同实例的边界处,本文方法处理的边界更为精准,分割质量更高。可视化对比表明,所提算法取得了良好的性能。

图6 在MS COCO 2017数据集上在目标边界处和遮挡情况下的可视化结果对比
2.4.2 在Cityscapes数据集上的可视化结果展示与分析
为了验证本文方法的有效性和泛化性,在Cityscapes数据集上进行多尺度目标实例分割,可视化结果如图7所示。Cityscapes数据集注释质量较高,且城市街景中更容易造成视觉形变,产生多尺度目标,对于实例分割任务具有更多挑战性。从图7可以看出,本文方法有效解决了不同尺度和不同类别的实例分割任务,多尺度目标得到了准确的识别、分类和像素级掩膜生成,甚至有效缓解了目标遮挡问题,表现了较好的分割性能,证明了所提方法的有效性和泛化性。

图7 在Cityscapes数据集上多尺度目标实例分割的可视化结果
为进一步验证本文方法的性能,在Cityscapes数据集上与基线Mask R-CNN进行对比,结果如图8所示。从图8第1、2行可以看出,本文方法在不同尺度目标存在遮挡和目标边界处分割效果较好;从图8第3、4行可以看出,所提方法有效改善了小尺度目标的漏检和错检。可视化结果显示,所提方法在具有挑战性的Cityscapes数据集上也有较好的效果。

图8 本文方法与Mask R-CNN在Cityscapes数据集上的可视化结果对比
2.4.3 本文训练模型在不同场景图像上的测试结果
图9为在MS COCO 2017和Cityscapes数据集上训练的本文方法模型在不同场景图像上的测试结果,测试图像来源网络和实地拍摄。在Cityscapes数据集上训练的模型,主要测试具有不同尺度目标的城市街景图,如图9(a)所示,不同尺度目标得到了准确的识别和分割。在MS COCO 2017数据集上测试了室内场景、城市街景和河景,以及白天、黑夜和雨天等特殊场景,如图9(b)所示。测试结果表明,所提方法具有一定的泛化性和实用价值。

图9 训练模型在不同场景图像上的测试结果
2.5 消融实验
为验证所提模型设计的注意力引导的特征金字塔网络AgFPN、注意力特征融合模块AFFM和全局上下文模块GCM的有效性,进行消融实验。
2.5.1 AgFPN的作用
本文提出的AgFPN易于集成到当前流行的两阶段实例分割网络,只需要将AgFPN直接替换基线模型中的FPN即可。表3为AgFPN对实验结果的影响对比。其中,*表示重新实现的结果,APb表示检测框的精度,R代表ResNet。可以看出,使用不同的实例分割框架和骨干网络,与基线模型相比,AgFPN带来了更好的性能提升,表明AgFPN在提高分割和检测精度上具有一定效果。
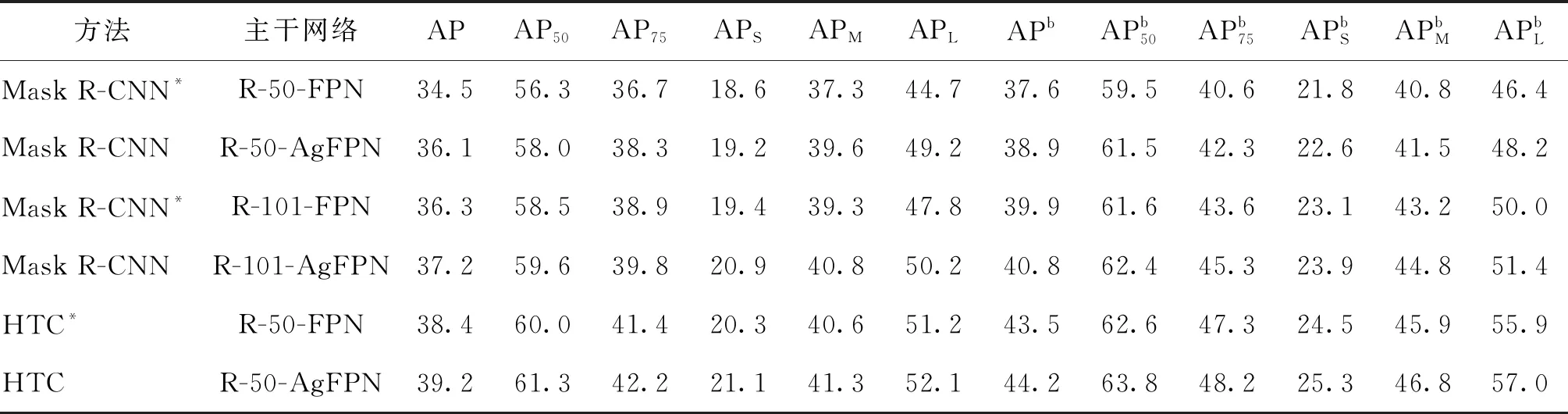
表3 AgFPN对实验结果的影响对比
2.5.2 AFFM和GCM的作用
注意力特征融合模块AFFM和全局上下文模块GCM都是即插即用的特征关系增强模块。为评估AFFM和GCM模块的作用,以ResNet-50 + FPN为主干网络,在MS COCO 2017验证集上进行消融实验。表4为AFFM和GCM模块对实验结果的影响对比。可以看出,每个模块都有效提高了基线的性能。具体来说,AFFM和GCM模块将平均精度分别提高了0.6%和0.7%,当组合两个模块时,基线的性能进一步提高了1.7%。实验结果表明,两个模块有助于整合多尺度特征并充分挖掘多尺度上下文信息,提高了实例分割的准确度。

表4 AFFM和GCM模块对实验结果的影响对比
2.5.3 MSCI网络结构有效性分析
为了验证多尺度上下文信息MSCI结构的有效性,对利用不同层、不同融合顺序的结构进行测试,消融实验结果如表5所示。其中,原始结构记为“P5、P4、P3和P2”,则“P2、P3、P4和P5”表示从P2层和P3层开始进行融合迭代,“P2和P3”表示只利用P2层和P3层特征进行融合,“P4和P5”表示只利用P4层和P5层特征进行融合。可以看出,从高层开始进行特征融合比从低层开始更加有效,高层特征具有较强的语义信息,将高级的语义特征从顶至下传播到底层,有助于多尺度特征融合与表达。此外,只融合P2层和P3层特征比只融合P4层和P5层特征更有利于精度提高,由于低层特征包含的是颜色、边缘、轮廓和纹理等信息,能使分割预测结果更加细致、精准。
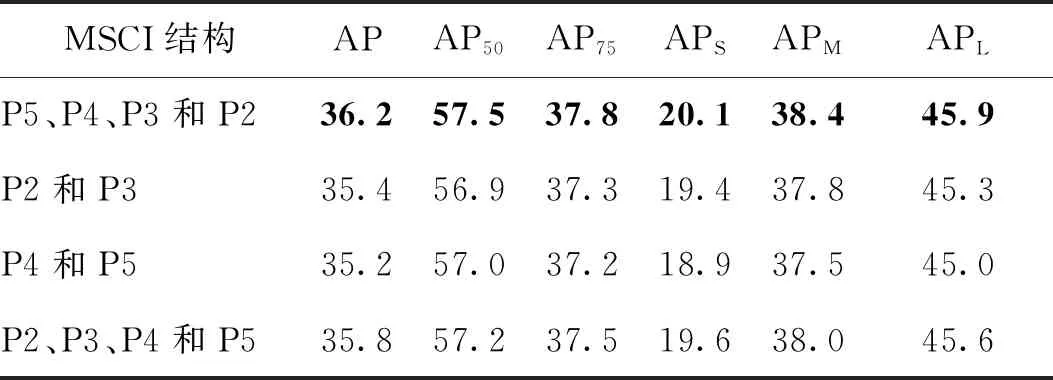
表5 多尺度融合策略对实验结果的影响对比
为了验证MSCI的网络结构对目标定位和多尺度目标识别的作用,使用Grad-CAM(gradient-weighted class activation mapping)(Selvaraju 等,2017)对MS COCO 2017数据集图像进行热力图可视化。图10为ResNet-50和ResNet-50 + MSCI网络热力图可视化结果对比。
可以看出,更强的可视化类激活映射(CAM)区域被更亮的颜色覆盖。与ResNet-50相比,ResNet-50 + MSCI网络的激活区域更集中,与目标重叠度更高,如图10第1行中的飞机和第2行中的人等,表明它能更好地定位目标、利用目标区域特征。而ResNet-50的定位能力相对较差,只覆盖部分对象或受背景干扰。此外,ResNet-50 + MSCI也可以准确预测小尺度的目标,如图10第3行和第5行中远处的人,图10第4行中远处的动物等,这体现了MSCI网络具有充分表达多尺度特征的能力。

图10 在MS COCO 2017数据集上ResNet-50和ResNet-50 + MSCI网络热力图可视化结果对比
2.5.4 本文算法推理速度的讨论分析
为了测试所提模型在推理速度上的性能,以ResNet-50 + FPN为主干网络(本文方法替换为AgFPN),使用单个V100 GPU,利用预先训练的模型在同一台本地机器上测试每个模型的推理时间。
表6为本文方法与其他方法推理速度的对比。可以看出,本文方法在分割精度上略低于RefineMask和HTC,但推理速度明显高于这两种方法。RefineMask和HTC均利用多尺度上下文信息,并且RefineMask采用掩膜多阶段细化策略,HTC使用级联架构,二者都显著增加了计算量,分割精度得到大幅提升的同时,推理速度受限。SOLO算法是单阶段实例分割方法,采用轻量化模型,有效提高了推理速度,但分割精度不足。本文方法在Mask R-CNN的基础上增加了一定的计算复杂度,提高了分割精度,也影响了一定的推理速度,但在精度与速度的权衡上具有一定优势。
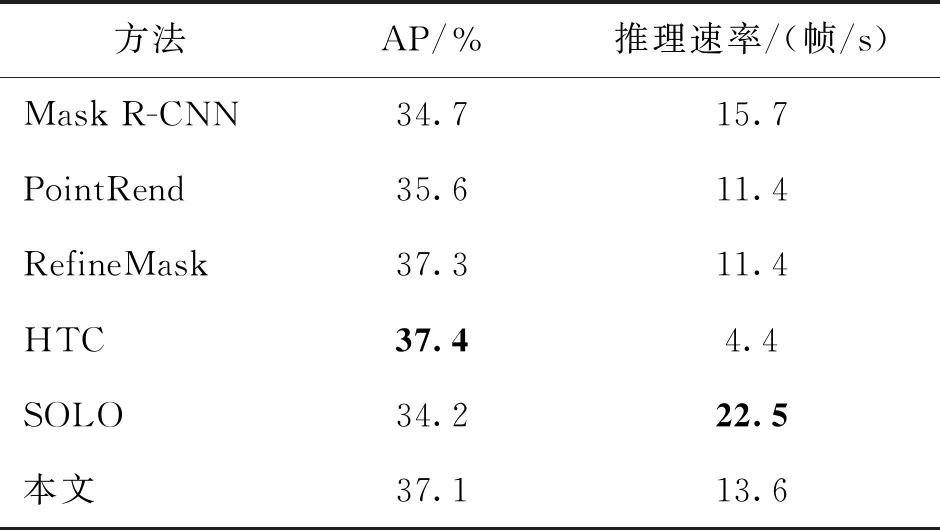
表6 本文方法与其他方法推理速度的对比
3 结 论
为解决目标多尺度变化问题,本文充分考虑FPN在邻层特征融合时信息损失和语义特征混叠,以及RoI特征多尺度上下文信息不足问题,提出一种融合多尺度上下文信息的实例分割方法。通过邻层特征自适应融合模块优化FPN邻层特征的融合方式,减少了信息衰减并增加了语义一致性,有利于多尺度特征的表达;同时,通过引入多尺度通道注意力设计了注意特征融合模块和全局上下文模块,增强了RoI特征的目标多尺度上下文信息。实验结果表明,所提方法有效提高了多尺度目标的实例分割精度。
但是,由于分割网络中存在多次卷积和下采样操作,且边界像素比例较低,本文方法在较大尺度目标边界分割精度上提升有限。此外,本文方法在Mask R-CNN的基础上增加了一定的计算开销,影响了推理速度,使得将本文算法应用于实时应用程序或部署在边缘设备上具有一定挑战性。因此,改善较大尺度实例边界分割准确度和模型轻量化设计是今后需要继续研究的问题。
