基于忆阻器的图卷积神经网络加速器设计
2023-02-18午康俊张伟功倪天明
李 冰 午康俊 王 晶 李 森 高 岚 张伟功 倪天明
①(首都师范大学交叉科学研究院 北京 100048)
②(首都师范大学信息工程院 北京 100048)
③(人民大学信息学院 北京 100048)
④(中国运载火箭技术研究院 北京 100076)
⑤(安徽工程大学集成电路与系统研究所 芜湖 241000)
1 引言
为了应对图结构数据规模不断扩大带来的挑战,随着人工智能的发展研究人员结合卷积特征提取方案针对图结构数据提出了图卷积网络(Graph Convolutional Network, GCN)[1]并应用到社交网络[2]、分子结构预测[3]等多个领域中。目前已有多个针对图卷积神经网络的专用加速器设计,例如混合架构图卷积网络加速器(a GCN accelerator with Hybrid architecture, HyGCN)[4]分析节点聚合和特征提取阶段计算差异,对每个阶段采用不同的架构和数据流;运行时工作负载再平衡图卷积网络加速器(a Graph Convolutional Network Accelerator with runtime Workload reBalancing, AWBGCN)[5]提出了一些数据重映射方案自动调整工作负载,缓解GCN计算时邻接矩阵不规则的数据分布导致的处理单元(Processing Element, PE)空转问题。高吞吐量高能效图神经网络加速器(a highthroughput and Energy-efficient accelerator for Large Graph Neural networks, EnGN)[6]则集成了神经图处理单元(Neural Graph Processing Unit,NGPU)以在统一的架构下执行图神经网络特征提取、聚合和更新操作,并利用图分块(graph tiling)、环边归约(ring-edge-reduce)、节点度感知缓存(degree aware vertex cache)等技术解决图规模庞大、稀疏连接不规则内存访问以及图节点幂律分布导致的数据局部性低,处理单元利用率不足,内存冗余等问题。然而上述基于传统冯诺依曼架构的加速器都存在大量数据移动和频繁访存,能耗延迟过高。忆阻器(Resistive Random Access Memory, ReRAM)[7]作为一种新兴的非易失性存储器件,具有高密度、读取访问速度快和低功耗等特性,由忆阻器组成的交叉阵列可以实现存内计算,有效减少数据移动。目前已经有多个基于忆阻器的神经网络加速器[8-11]以及图处理加速器[12-14],但是由于图卷积神经网络庞大的计算规模,极其稀疏的连接关系以及相对稳定的邻居节点使其不适宜直接部署在上述加速器中。图神经网络存内处理架构(a Processing-In-Memory architecture for Graph Neural Networks, GNN-PIM)[15]是第1个基于存内处理的图神经网络加速器,它提出一种数据流让图神经网络中多个子图并行运算,但是其静态的数据选择模式无法解决不规则图数据分布的影响并且节点数据仍旧需要大量传输过程。忆阻器交叉阵列虽然可以解决数据移动问题,但是真实大规模图数据中节点有限的邻居关系致使邻接矩阵极其稀疏,同时输入特征向量的稀疏性也很大,如果直接映射计算,会在无效零值上浪费大量资源。图学习任务自适应忆阻器计算 (Task-Adaptive in-situ ReRAM computing for graph learning, TARe)[16]提出了一种基于ReRAM的原位图学习加速器架构,支持混合原位加载,选择性地将稀疏的输入数据存储在忆阻器阵列上做计算,并提出一种稀疏数据映射机制来优化映射过程,但是此方案未充分复用邻接矩阵和权值,并且在映射时未考虑划分方案对结果的影响。综上,结合忆阻器和图卷积神经网络特性,本文将设计一个利用图卷积神经网络数据稀疏差异性的ReRAM图卷积神经网络加速器。本文的主要贡献为:
(1) 本文分析了GCN中各操作数的计算访存特征并提出权重和邻接矩阵到忆阻器的映射过程,充分利用这两种操作数的计算密集特征同时避免访存密集的特征向量产生过高开销。
(2) 针对邻接矩阵稀疏性,本文提出子矩阵划分算法以及邻接矩阵的压缩映射方案,最大限度降低GCN忆阻器资源需求,并且加速器提供对稀疏计算支持,支持压缩格式为坐标表的特征向量输入,保证计算过程规则且高效地执行。
(3) 根据本文的实验结果,加速器相比CPU和GPU分别有483倍和28倍的速度提升以及1569倍和168倍的能耗节省。
本文的余下部分按以下形式组织,第2节将介绍图卷积神经网络和忆阻器的相关背景知识。第3节将详细讨论加速器设计方案,包括加速器整体架构以及针对不同稀疏数据的具体优化措施。第4节展示本文实验相关设置和结果分析。最后第5节工作总结。
2 背景
2.1 图卷积神经网络
图卷积神经网络因其对关系数据的强大建模能力已被应用于包括推荐系统、生物化学、网络分析、计算机视觉以及自然语言处理等多个领域中[17]。图1为图卷积神经网络计算步骤,公式为
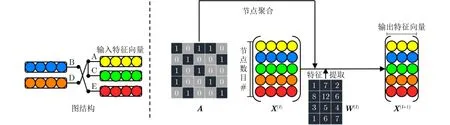
图1 图卷积神经网络计算
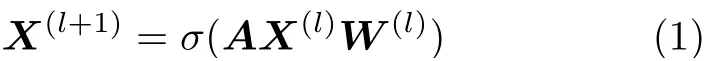
其中,A是图的邻接矩阵,每行数据表示当前节点与其他所有节点的连接关系,考虑到节点邻居分布的不规则性通常需要对邻接矩阵A进行归一化处理并且其在整个图卷积神经网络计算过程中保持不变。X(l)是 第l层的输入特征矩阵,每个行向量表示节点的特征向量。W(l)是 第l层的权重矩阵,同一层中所有节点共用一套权值参数。σ(.)为非线性激活函数,例如线性整流单元(REctified Linear Units, RELU)函数。图卷积神经网络矩阵乘积虽然存在大量无效0值参与运算,但是其规则的数据运算过程可以被忆阻器交叉阵列高效处理。
2.2 忆阻器交叉阵列
忆阻器是一种非易失性存储器,由上下电极和金属氧化物组成,通过改变金属氧化物的电阻来存储数据并且断电后保持不变。以交叉阵列(crossbar)形式组织的忆阻器能够模拟向量矩阵乘法,图2(a)展示了具体计算过程,对每个字线施加不同电压作为向量输入值,矩阵数据用忆阻器中的电导表示,根据基尔霍夫定律从位线中测得电流值即为向量矩阵乘积结果。如式(2)所示:V为输入电压,G为电导率,I为输出电流值,i,j分别表示对应字线和位线。交叉阵列内存储的矩阵数据可以长期保持且不受断电影响,因此可以实现存算一体化,非常适合用于运算存储密集型计算的加速。本文将基于忆阻器交叉阵列设计一种对稀疏进行特别优化的图卷积神经网络加速器

图2 Crossbar乘加运算和Crossbar上GCN映射方案

3 加速器设计
3.1 架构组织
加速器架构采用类似ISAAC[8]的层级设计,由多个片(Tile)组成(图3)。每个Tile包括以下几部分:多个原位乘加模块(In-situ Multiplication Adder, IMA)用于执行向量矩阵运算;Tile缓冲区存储输入向量值以及计算结果;控制单元调度缓冲区和IMA之间的数据交互;IO接口则加载图数据和相关指令到缓冲区和控制单元上,其中IMA通过低开销的H树结构互连。IMA内部又包含多个忆阻器阵列及相关外围电路:寻址单元将压缩格式存储的数据映射到交叉阵列正确的位置上,同时它还负责控制行列地址选通信号来激活参与计算的行列;输入输出寄存器缓存输入特征和中间结果;数模转换器(Digital Analog Converter, DAC)和模数转换器(Analog Digital Converter, ADC)用于数模转换和模数转换,由于ADC的面积和功耗开销相对更大,因此每个交叉阵列的多个位线共享一个ADC;采样保持器对模拟值进行采样并在转换为数字形式之前将其存留;为了支持高精度数据,数据高位和低位存储在相邻的忆阻器阵列上进行计算,所得各部分结果利用移位加单元合成完整的计算结果;最后经ReLU单元激活后即可得到本层输出结果。

图3 加速器整体架构


3.2 稀疏特征映射
输入特征X1的体量和稀疏度随图卷积任务的不同而有所变化,一般特征值维度越大其体量和稀疏度也就越大,某些任务中X1的稀疏度高达99.9%的同时数据量占比近1/2,因此有必要对其进行稀疏优化。在X×W计算时稀疏特征向量通常以行列坐标值( row,col,value )压缩格式存储在缓冲区中,r ow为 特征所属节点,c ol表 示此节点的第col个特征,v alue为特征值。Tile上的控制单元依据行坐标值r ow 和 列坐标值c ol将数据传输至对应IMA相应阵列字线上,对应IMA记为 I MAcount,相应交叉阵列和字线分别记为 XBarcount和W ordlinecount。由于不同任务节点特征数目不同,所需的I MA数目也不同,用 N odeIMA表示完成一个节点特征提取所需的IMA数目,为了计算N odeIMA我们首先需要知道一个IMA最多可以处理的特征值数目,用IMAFeature表示,X Barnum是 IMA上的交叉阵列数目,XBarsize为交叉阵列大小
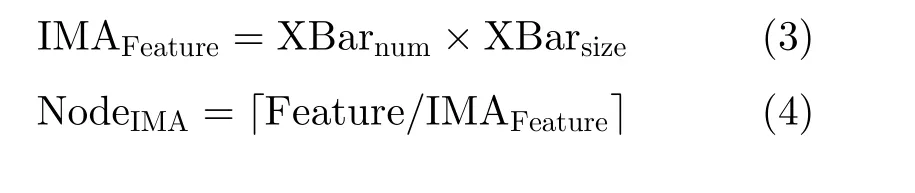

为了提高运算并行度,本文将权重矩阵复制多份,同时提取多个节点特征,用S imultnode表示同时运算的节点数目。则总体IMA计数 I MAcount计算如式(6)所示

接着IMA内寻址单元通过列坐标 col 将其分发至对应交叉阵列的对应字线上。分发规则为式(7)和式(8)。需要注意的是存在部分任务其特征向量维度过大,计算需要多个Tile共同完成,此时 col应为减去对应偏置后的值,偏置为Tile乘以每个Tile能够处理的特征值数目
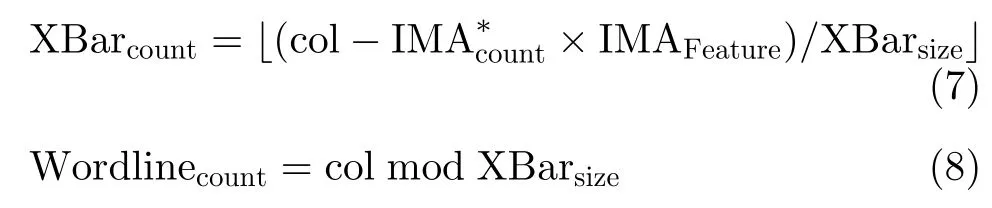


3.3 邻接矩阵子矩阵划分
具有全局不变性的邻接矩阵应用于GCN各层计算,其在初始化时被写入忆阻器单元,但是邻接矩阵稀疏性极大,在各个数据集中稀疏度均超过99%。因为邻接矩阵上所有有效数据均需频繁参与运算,出于对ReRAM计算并行性以及特征数据映射和乘加操作复杂度的考虑,本文采用先划分后压缩的稀疏处理方案。如图5所示,首先将稀疏邻接矩阵划分为子矩阵,图5中每个小方块代表一个子矩阵,全0子矩阵用空白方块表示,接着将非0子矩阵按照IMA中交叉阵列排布按列压缩,最后把压缩后的数据映射到各个Tile上。
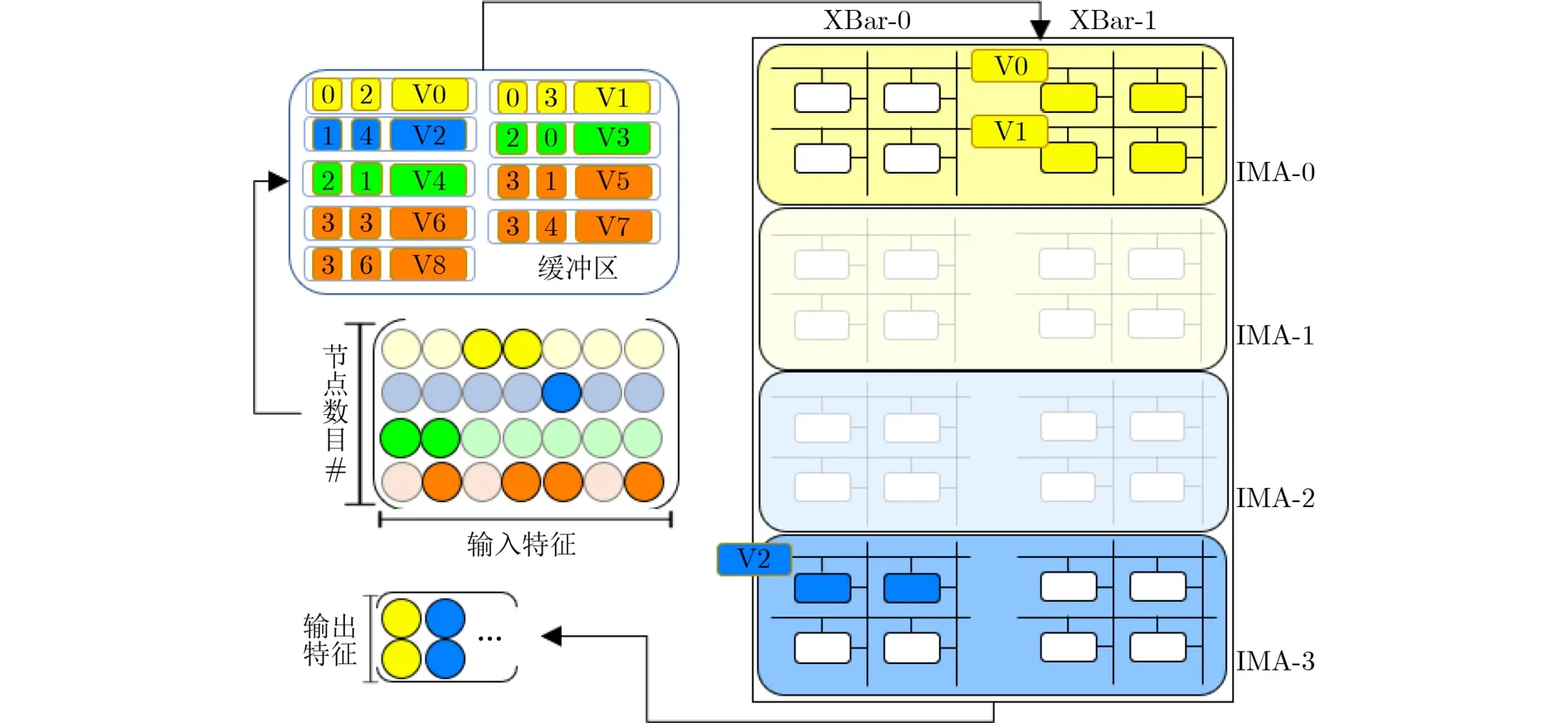
图4 稀疏特征映射
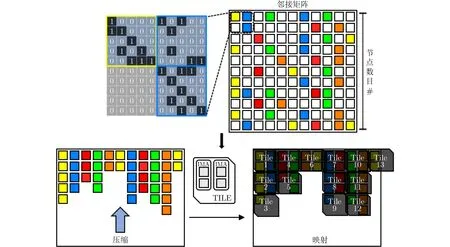
图5 稀疏邻接矩阵子矩阵划分、压缩和映射
通过划分子矩阵并压缩映射的方案能有效缓解稀疏性对邻接矩阵计算的影响,但是不同大小的子矩阵划分粒度会导致不同的Tile映射数目需求,进而影响加速器能效。不同子矩阵划分粒度下的Tile消耗如图6(a)所示,横轴表示子矩阵划分粒度,纵轴为Tile占用数目,Cora和Citeseer数据对应左侧坐标轴,Pubmed和Nell数据对应右侧坐标轴,可以发现不同划分方案结果并非线性关系。接着观察不同子矩阵划分下的Tile分布情况,图6(b)为Cora数据集在子矩阵划分大小分别为32和16时的Tile分布情况,横轴为不同划分下所需的Tile列数,纵轴为每列Tile数目,本文观察到子矩阵划分粒度为16时相比32时占用更多Tile列,但同时稀疏利用率也越高使得每列Tile数目相对更少,反之亦然。为了得到最优划分,本文希望每个Tile列上数据尽可能利用稀疏的同时占用更少Tile列。由于子矩阵划分粒度在交叉阵列大小范围内,是离散且有限的,并且其在Tile上规则排布,模拟开销小,所以本文通过遍历模拟子矩阵压缩后的Tile映射选择Tile资源数目最少的划分方案即为最优划分。
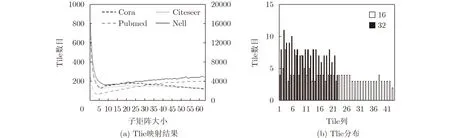
图6 邻接矩阵不同子矩阵划分下Tile数目
4 实验
4.1 实验设计
本文参考交叉阵列卷积网络加速器(a convolutional neural network accelerator with In-Situ Analog Arithmetic in Crossbars, ISAAC)等[8,20]以往工作基于忆阻器神经形态计算系统建模工具(a behavior-level modeling tool for Memristor-based Neuromorphic Computing Systems, MNSIM)[21]构建了一款模拟器对加速器进行评估,MNSIM是一款专为基于忆阻器的存内计算架构设计的模拟器,它提供对CNN计算精度和硬件性能(即面积、功率、能量和延迟等)的建模仿真。本文加速器采用32 nm工艺, ReRAM单元为1T1R结构,HRS /LRS分别为150 kΩ/ 30 kΩ,读/写电压为0.5 V/3 V,系统时钟频率为500 MHz。加速器总体大小约为4.3 GB,共65536个Tile,但是由于功耗限制同时运行的Tile数目不超过120,每个Tile约70 kB,包含16个IMA 和 4 kB Output buffer,每个IMA包含8个64×64的交叉阵列和1 kB Input buffer。每个交叉阵列有64个1 bit DAC和2个8 bit ADC。每个ReRAM单元存储1 bit数据。
用于评估GCN的数据集为Cora, Citeseer,Pubmed和Nell。Cora, Citeseer, Pubmed是3个引文网络数据集[18],包含每篇论文的稀疏词袋特征向量和论文之间的引文链接列表;Nell是从[19]所述知识图谱中得到的数据集。实验对比了GCN及上述数据集在4个平台的实验结果,采用稀疏特征映射,邻接矩阵子矩阵划分优化方案的OPT,未采用优化方案的BASE,基于PyG[22,5]框架的Intel至强E5-2680-V3 CPU平台和基于PyG框架的NVIDIA RTX 8000 GPU平台。
为了获得GCN在加速器平台运行的延迟及能耗结果,本文首先将数据集特征向量和邻接矩阵分别预处理映射,得到各数据特征向量和邻接矩阵在加速器上的映射参数,例如Tile数目、各Tile上交叉阵列激活行列数等。接着我们将其映射到加速器上进行仿真运算,最终得到GCN计算的延迟、能耗结果。
4.2 结果分析
本文首先评估不同子矩阵划分方案的Tile资源占用量,并选择最小占用的子矩阵划分方案,结果如表2所示。

表2 各数据集子矩阵划分粒度
对于Cora,Citeseer这种体量相对较小(节点数目3k左右)的图数据,使用较大的子矩阵划分粒度(62×62, 64×64)消耗更少的Tile资源;而对于节点数目数10k的大体量数据集,较小的划分粒度(5×5,10×10)Tile资源占用更少。但是二者并非完全线性关系,不是数据体量越大就应该使用越小的划分方案,Nell数据集节点数为65755,远大于Pubmed数据集19717,但是Nell邻接矩阵划分粒度却大于Pubmed,具体的划分方案需要依据不同数据集邻接矩阵稀疏分布的不同而定。对于Nell数据集根据幂律分布[23]存在一些节点度很大,导致邻接矩阵中包含密集度较大的列,此时若选择很小的子矩阵划分方案会增加Tile占用且由于这些密集的列使得小划分方案不能充分利用稀疏性;而对于Pubmed数据集,因为其度大的节点数据相对更少,更加均匀的稀疏分布使Pubmed更适合小的子矩阵划分粒度进而消耗更少的Tile资源。实验结果表明通过合适的子矩阵划分平均可以节省7倍Tile资源。
接着本文对比采用稀疏特征映射,邻接矩阵子矩阵划分优化方案的OPT和未采用优化方案的BASE,延迟和能耗结果分别在图7、图8展示。在延迟方面,对X×W计算(图7和图8中XW)应用稀疏特征映射方案与否对这部分延迟影响不大,虽然仅需激活有效数据对应阵列字线,但是只要存在字线被激活即会产生相应延迟开销;而对于A×(XW)(图8中A*)计算应用子矩阵划分可以有效降低延迟开销,平均可以达到38.8倍速度提升。Pubmed和Nell数据集的延迟降低相比Cora和Citeseer数据集更加明显,因为应用子矩阵划分方案后Pubmed和Nell数据集的Tile节省要远大于Cora和Citeseer数据集。在能耗方面,不论是X×W阶段稀疏特征映射还是A×(XW)阶段邻接矩阵子矩阵划分方案都能带来显著的能耗降低,平均分别为3.69倍和181.99倍。并且本文还发现对于小体量数据集来说X×W阶段计算是限制延迟和能耗的主要因素,而对于大体量数据集来说A×(XW)阶段计算对延迟和能耗的影响更大。

图7 各数据集在加速器优化方法(OPT)和基础方法(BASE)下两步计算正则化延迟结果

图8 各数据集在加速器优化方法(OPT)和基础方法(BASE)下两步计算正则化能耗结果
最后本文将采用稀疏特征映射,邻接矩阵子矩阵划分优化方案的OPT,未采用优化方案的BASE,与基于PyG框架在Intel至强E5-2680-V3 CPU(CPU)和NVIDIA RTX 8000 GPU(GPU)的方案进行对比,对比结果如图9、图10所示。在延迟方面,OPT与未优化的BASE在Cora和Citeseer数据集上表现相近。因为Cora和Citeseer数据集体量较小,延迟开销主要在X×W计算阶段产生,而稀疏特征映射方案对延迟性能影响有限,因此表现相近。加速器相较于CPU可以获得平均72.32倍(BASE)和78.16倍(OPT)的速度提升,相较于GPU可以获得平均17.48倍(BASE)和18.93倍(OPT)的速度提升。由于Cora数据集的特征数目远低于Citeseer(表1),故Cora数据集在加速器上能够获得更好的延迟优化效果。对于Pubmed和Nell数据集来说,延迟开销主要产生在A×(XW)计算阶段,其过于稀疏的数据运算中包含太多无效值,极大降低了运算效率,在应用邻接矩阵子矩阵划分后Pubmed和Nell可以得到更小的子矩阵粒度(5×5, 10×10)同时Tile资源占用也更低,故而延迟优化效果显著,OPT相比BASE在Pubmed和Nell数据集上分别有5.61倍和26.96倍的速度提升,并且OPT相较于CPU在这两个数据集上平均可以获得887.74倍速度提升,相较于GPU平均可以获得36.5倍速度提升。综合来说,OPT相较于CPU和GPU分别有平均483倍和28倍(最大60倍)的速度提升。
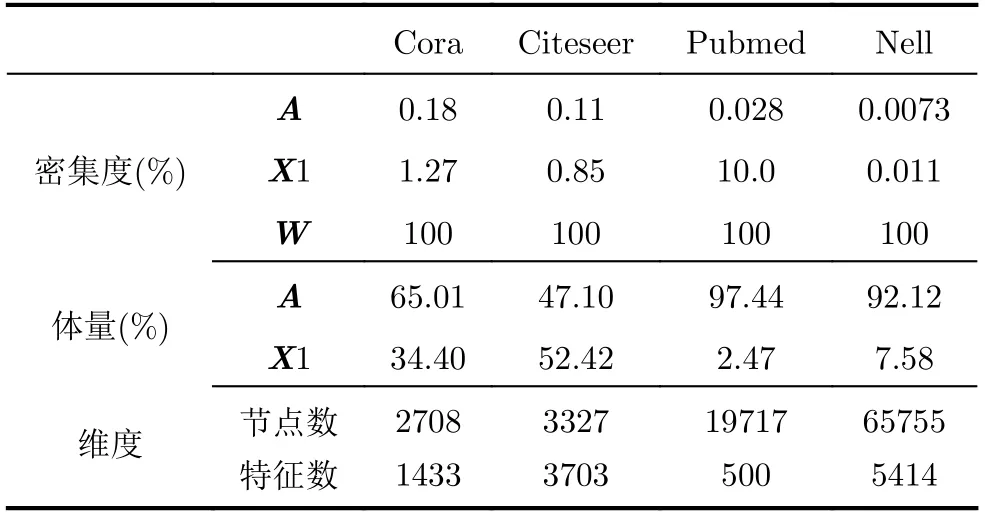
表1 不同数据集密集度、体量和维度

图9 不同数据集下优化方案OPT相比CPU, GPU和BASE的速度提升

图10 不同数据集下优化方案OPT相比CPU, GPU和BASE的能耗降低
在能耗方面, OPT在各数据集上的表现均远好于BASE,平均可以得到32.41倍能量节省,并且数据集体量越大优化效果越明显,这是因为图数据节点大多仅存在有限邻居,数据集体量越大意味着稀疏性越强,经稀疏优化后的能量节省效果也就越明显。即便不经稀疏优化,利用低功耗忆阻器存内运算,BASE相较于CPU和GPU仍旧可以得到平均57倍和19倍能量节省。OPT相较于CPU和GPU则有1569倍和168倍能量节省。
5 结论
本文提出一种基于忆阻器交叉阵列的图卷积神经网络加速器,并针对输入特征和邻接矩阵在加速器上的不同加载方式分别应用不同的稀疏优化方案,结果表明,本文的加速器相比CPU有平均483倍的速度提升和1569倍的能耗节省;相比GPU可以得到平均28倍的速度提升和168倍的能耗节省。
