用于检测硬件木马延时的线性判别分析算法
2023-02-18黄正峰
宋 钛 黄正峰 徐 辉
①(安徽大学集成电路学院 合肥 230601)
②(合肥工业大学微电子学院 合肥 230009)
③(安徽理工大学计算机科学与工程学院 淮南 232001)
1 引言
近年来,以集成电路为代表的新一代信息技术产业,已逐渐成为经济发展的首位性、支柱性产业。为贯彻落实发展新一代信息技术的战略部署,紧抓全球产业分工变革、经济结构调整重大机遇,努力推动新一代信息技术发展取得新突破,积极抢抓国家战略机遇,大量代工厂脱颖而出,使集成电路(Integrated Circuit, IC)的设计、制造、封装和测试相互分离,产业链加长,不可控因素增多,导致芯片在生产过程中面临越来越多的安全隐患[1]。
其中威胁最大的就是硬件木马,它是指在原始电路中通过篡改数据、泄密或破坏电路功能等植入的具有恶意功能的冗余电路[2];具有破坏性、寄生性、隐蔽性、可变异性和潜伏性等特点[3]。其危害性表现在以下3个方面:
(1) 硬件木马不能像软件木马那样直接被查杀,危害性更大[4]。
(2) 硬件木马能够在IC生命周期的任何阶段植入,特别是在版图设计阶段修改一些填充电路。
(3) 引入大量第3方电子设计自动化(Electronic Design Automation, EDA)工具和知识产权(Intellectual Property, IP)核,进一步加剧了安全隐患,给芯片的可靠性和安全性带来灾难性后果[5]。
近年来,针对木马特征,Chakraborty等人[6]提出使用逻辑测试方法进行检测。该方法基于故障测试的自动化测试模式生成(Automatic Test Pattern Generation, ATPG)技术,通过测试激励,在输出端口观察输出响应,以达到检测硬件木马的目的。Sabri等人[7]提出一种基于统计的方法生成测试向量,首先检测出电路节点中的稀有事件,根据每个稀有事件的激活条件生成一个最佳测试向量集,该向量集都能将其激活N次(N值由检测者定义),从而得到木马激活的概率。许强等人[8]提出基于路径延迟检测硬件木马,该方法测量几条指定路径的延迟并考虑工艺噪声,在工艺噪声范围内能检测出占总电路大小0.36%的木马。尹勇生等人[9]提出的基于延迟的方法将2个寄存器之间的路径延迟定义为影子寄存器,通过比对设计与测试时影子寄存器的频率识别硬件木马。
以上研究表明,电路中延时信号可以有效地检测硬件木马。因此,本文针对延时信号进行分析,选择低转换概率的节点植入硬件木马,通过机器学习(Machine Learning, ML)中的线性判别分析(LDA)分类算法对木马电路进行分类[10];并且,通过多项式回归(Polynomial Regression, PR)把硬件木马检测问题转化为数学问题[11],揭示了木马特征及其规律,为识别木马提供了依据,突显了该方法的泛化能力;另外,面对木马检测中亟待解决的检测时间[12]、检测难度[13]、可靠性[14]、准确率等关键性问题,从特征提取、木马数据库建立、预测等方面开展研究,达到准确识别硬件木马的目的。随着ML研究的深入,海量的延时数据更有利于进行数据分析与预测,为本文提出的ML分类算法提供了契机。
本文提出的ML分类算法通过区分延时信号来识别硬件木马;通过线性回归算法对木马数据进行拟合[15],将木马数据库建立问题转化为数学问题,使其具有更广泛的适用性与通用性。并且该分类算法可以选择合适的温度和电压,达到最高的预测准确率。
2 背景知识
2.1 硬件木马简介
在电路中植入具有特定目的、使之具有改变逻辑功能的恶意电路,称为硬件木马。例如,通过在原始电路中加入额外的门电路,在特定条件下改变其输出逻辑。
如图1所示为“1”触发逻辑的硬件木马结构,其中,硬件木马的输入端A,B,C,D连接逻辑功能电路,触发逻辑部分输出全为1时,会把原始电路节点的逻辑值M修改为~M,硬件木马通过改变原始电路节点的逻辑值,达到改变初始逻辑功能的目的。
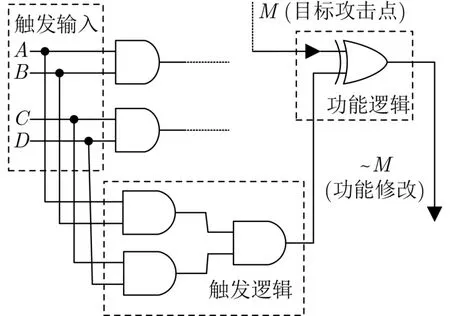
图1 硬件木马结构
2.2 基于延时分析的检测技术
基于延时的HT检测方法是根据在相同激励且没有工艺偏差的情况下,检测木马的路径延时。由于栅电容增加,路径延时一定会大于干净电路中的路径延时。所以在特定的延时路径上,对待检测电路的路径延时进行检测,并与干净电路中相应的路径延时进行对比,即可检测出是否含有HT。
如图2所示,黄金芯片为干净芯片,它所对应的延时被提取生成黄金指纹,当待测芯片的延时与之相同则认为是干净芯片,反之,则为可疑芯片。

图2 延时信号分析
3 文本方法
3.1 LDA分类方法
本文利用芯片工作时的旁路信息(电路延时信息)来对木马进行检测。其原理是电路中植入的硬件木马会对芯片的路径延时产生影响,因此通过观察芯片的旁路信号并与原始芯片的旁路信息作比较,进而检测出芯片中是否有硬件木马的存在。对电路进行基于旁路分析的硬件木马检测的最大优点是可以使硬件木马在不被触发的情形下被检测出来。
为了区分木马电路与干净电路的延时,本文使用LDA进行分类。LDA是一种处理高维数据的模式识别降维算法。LDA的目标是通过最大化类间散布矩阵,同时最小化类内散布矩阵来找到原始数据集的最佳低维表示,将高维空间嵌入到低维空间中,同时保留大部分所需的特征信息。此类技术主要可用于降低高维数据的维数。LDA的中心思想是找到最能将数据从两个或多个类别中分离出来的特征的线性组合。凭借特征分解,得到的组合给出了更简洁的数据表示,并保留了判别信息以供以后分类。
为简单起见,LDA分类方法如图3所示。
图3描述了LDA分类算法,分别以失败的分类(a)与成功的分类(b)进行对比予以说明。其中,蓝点和红点分别代表干净电路的延时与木马电路的延时。由图(a)可以看出,当两类点映射到子空间“a”中时,蓝点与红点没有分开,但当它们在图(b)中映射到子空间“b”后,蓝点与红点成功地进行了分离。此类技术主要可用于降低高维数据的维数,本质上是学习一组参数(特征值),这些参数用于将给定数据投影到可以将它们分开的最佳维度。该算法流程如算法1所示。

图3 LDA分类算法

算法1 LDA 算法
3.2 线性回归算法
为了更好地预测木马电路,找出木马电路特征与规律,对已经认定是木马的电路进行分析,从而建立木马特征库。本文使用线性回归拟合木马数据,通俗来讲,即总有一条曲线,它能拟合所有样本点,使均方误差值最小,从而达到拟合数据的目的。线性回归是利用线性回归方程对一个或多个自变量和因变量之间关系进行建模的一种回归分析。线性回归算法是由线性叠加函数表示决策函数,之后利用最小化损失函数通过监督学习的方法得到对训练集样本而言最好的模型,最后利用该模型对新样本数据的标签值进行分析预测。
图4为不同电压下(x轴0.3~1.2V)测得的19个电路延时(y轴单位为ps),为了确定两个变量电压和延时的关系,希望寻求一定的规则和方法,使得所估计的样本回归方程是总体回归方程的最理想代表,最理想的回归直线应该尽可能从整体来看最接近各实际观察点,即散点图中各点到回归直线的垂直距离(d1~d19),即因变量的实际值与相应的回归估计值的离差整体来说为最小。由于离差有正有负,正负会相互抵消,通常采用观测值与对应估计值之间的离差平方总和来衡量全部数据总的离差大小。因此,回归直线应满足的条件是:全部观测值与对应的回归估计值的离差平方的总和为最小,线性回归算法的模型为
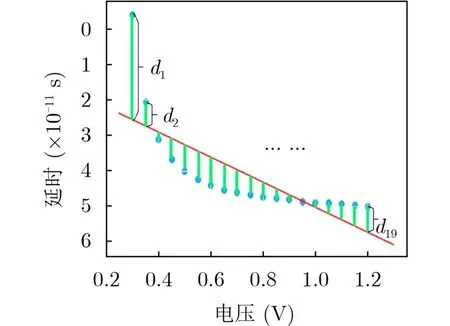
图4 线性回归方程

其中,x是输入的特征向量,y是输出的标签,w和b是模型参数。
线性回归模型包含参数w和b,求出最优参数w,b。本文选用的参数估计方法为均方误差最小化,其包括构建损失函数和梯度下降法两部分,线性回归算法流程如算法2所示。

算法2 线性回归算法
从算法中可以看出,根据正态分布初始化模型参数,然后执行前向传播。根据定义的损失函数L(例如交叉熵),计算损失函数L相对于权重w的梯度G1。首先通过随机梯度下降更新模型参数,然后使用惩罚项J以确保所有权重将逐渐接近+1,-1或0。通过定义的惩罚项更新所有参数后,将执行下一次迭代。迭代过程一直进行到满足训练精度要求。
4 实验结果
4.1 木马设计与注入
本文采用Synopsys公司的Design Compiler综合工具在45nm工艺下对RTL级电路进行综合,将综合后的电路转化为SPICE格式的电路网表,并采用蒙特卡罗模拟不同芯片间的工艺噪声,具体仿真过程如图5(a)所示。

图5 实验设置
基准电路来自NXP半导体提供的工业设计,在关键路径中转换概率较小的结点中值入如图5(b)所示的计数器型硬件木马,当计数达到预设值时,硬件木马被触发,电路的输出值发生改变,导致电路功能紊乱。本文设计了不同功耗的木马模块。尽管有木马类型、顺序或组合,但本地木马功率密度(Local Trojan Power Density, LTPD)是影响检测结果的唯一因素。将IC区域划分为10×10个块,并在这些块内的空白处插入一个木马。木马电路使用与IC相同的标准单元实现,LTPD从0.004变化到0.448 μW/μm2,而平均芯片功率密度为1.2 6 μW/μm2。假设木马是在制造阶段通过更改掩码插入的,由于路由空间有限,攻击者倾向于将木马放置在一个块内,而不是分布式地对于不同PV级别的每个基准测试,会生成10000个插入不同位置的不同大小木马的芯片。
本文模拟了一个真实的工艺偏差(Process Variation, PV)实验设置,并将其添加到门级参数中。测试了4种不同的基准电路(AES, MIPS, RS Decoder, JPEG Encoder),并在电路上改变木马的大小和位置。
IC基准电路:(1)128位AES加密电路;(2)32位MIPS电路;(3)Reed-Solomon (RS)电路;(4)JPEG电路。表1给出了基准测试的基本信息,包括门数、内核尺寸和总功耗,标准电压为1.1V,频率为1 GHz。使用synopsys的设计编译器综合工具将基准映射到Nangate 45nm库,并使用Synopsys的Primetime-PX估算特定时期内随机的平均功耗。

表1 测试台数据
对于每个注入木马的电路,提取相应的电路延时,并将电路响应数字化并收集。所有设计均使用45nm开放单元库进行综合。在这个过程中,所有状态元素都被去除,只留下了组合电路结构。为了评估每个基准电路,使用商业ATPG工具。被测电路包含每个电路的名称、大小和逻辑深度的信息。在测试模式下,干净电路在测试向量激励下的延时为“黄金模型”,通过与黄金模型比较,判断电路是否有木马。
使用HSPICE对电路延时进行仿真,如图6所示,准备2000组无木马电路,向1000组电路注入木马(改变输出逻辑功能),即定义为木马电路,提取1000组无木马电路的延时和木马电路的延时,组成2000组原始数据单元,并进行标记(label),将原始数据导入ML工具Python,取1639个单元的数据(82%)为训练集,361个单元(18%)作为测试集,建立KNN预测模型,以准确率作为评价分类性能的指标,准确率公式为

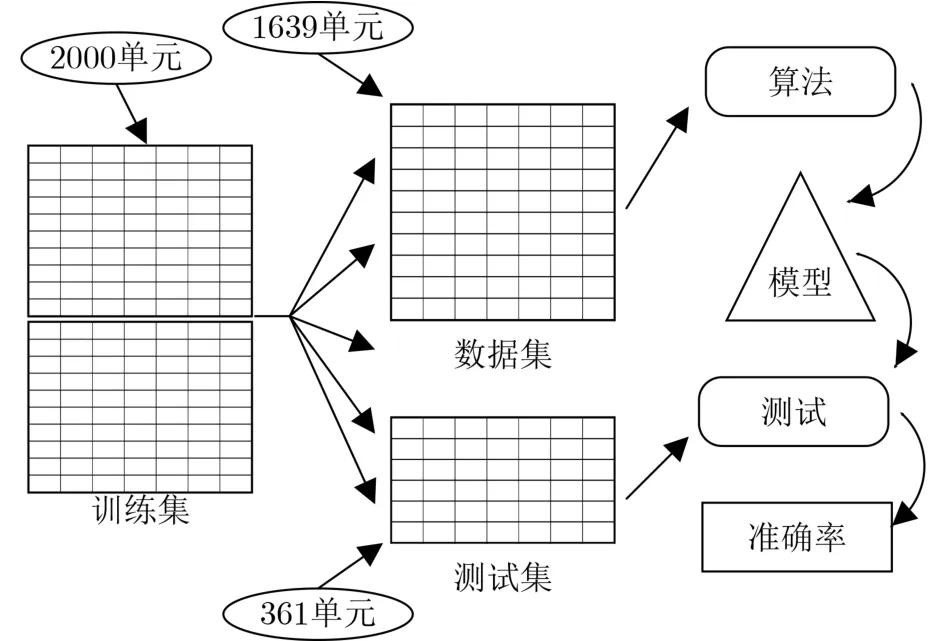
图6 实验流程
4.2 延时数据分析
为了找出HT的特征与规律,有必要对木马的延时特征函数化,以形成木马特征数据库,为判定木马提供依据。因此,本文通过改变电压的方式,采集不同电压下的延时数据,分别在0.3~1.2V共19个电压下,对木马电路与干净电路进行了1000次延时数据的采集,其延时分布如图7所示,红色区域为木马电路的延时分布,蓝色区域为干净电路的延时分布。
从图7的延时分布可以看出,干净电路与木马电路的延时高度重合,但蓝色区域并未完全被红色区域所覆盖,意味着它们有细微的差异。因此,实验分别对干净电路与木马电路的延时数据进行了特征提取,通过线性回归对延时数据进行线性拟合,实验结果如图8所示。

图7 不同电压下木马电路与干净电路延时对比
图8为干净电路与木马电路的线性拟合结果,它们分别由1000条延时数据拟合而成。为了形成木马特征数据库,本文只讨论木马电路的线性拟合结果,并生成其中一条拟合直线的线性回归方程,如式(2)所示。
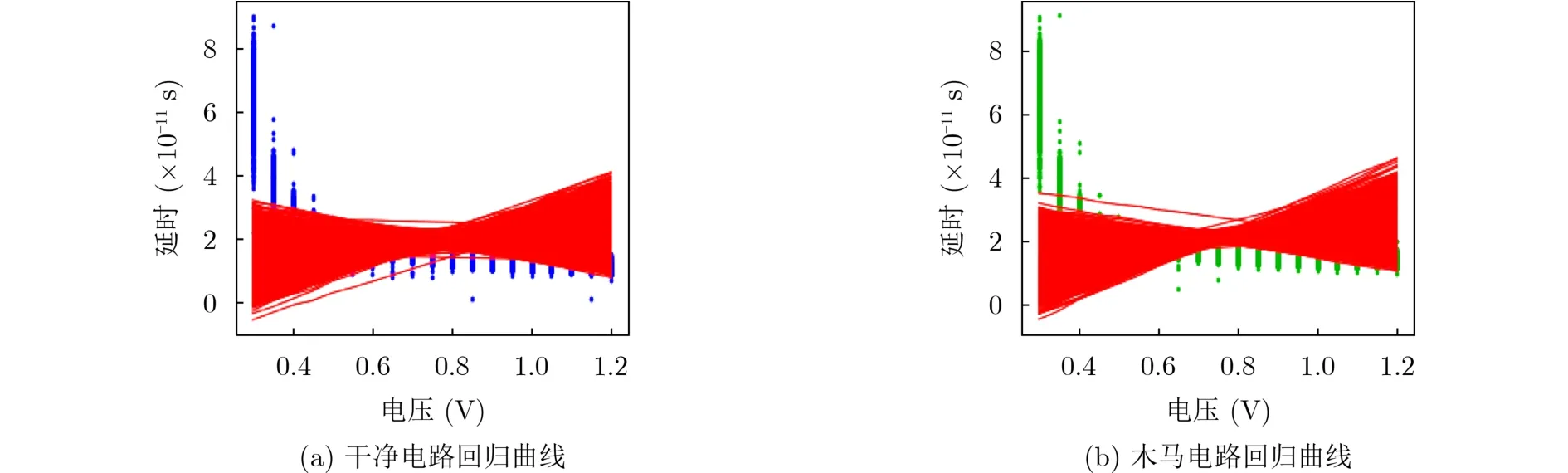
图8 干净电路与木马电路线性拟合对比

此函数为其中一条拟合直线的线性回归方程,其中,x为加载电压,y(x)为所对应的延时。当待测电路在指定电压下的延时满足此公式时,即可判定待测电路为木马电路。同理,根据1000条木马电路的拟合直线,即可生成1000组类似方程,生成木马特征数据库,此特征库可为判定木马电路提供依据。
4.3 实验结果与分析
本文使用识别率指标(Detection Rate)来表明所提出的木马检测方法的优越性,如表2所示分别比较了4种不同木马检测方法的识别率,4种方法分别为GNJ[16],BSC[17],LPA[18]和ML[19]。
实验结果分析:在这个实验中,我们比较了不同木马检测方法在各种基准电路下的结果,从表2中4种不同基准电路AES, MIPS, RS和JPEG的比较结果可以看到,木马检测率随着LTPD的增加而增加,本文方法优于其他方法,其检测率最高。IC芯片工作时产生的旁路信号是一种模拟高频信号,这种信号十分微弱,而且信号在传递过程中会受到噪声等多种因素的影响,很难准确地对其进行检测。不仅如此,对旁路信号进行去噪处理也会削弱原始信号,对后期的分析检测造成一定影响。另一方面,由于旁路信号具有成分复杂、高维等特点,直接对原始信号进行处理很容易造成“维数”灾难,检测效果往往不是很理想。以“金片”旁路信号作为参考模板,对待测芯片的旁路信号进行识别,本质上属于分类决策问题, 由于工艺噪声等因素影响,对于不同芯片或者同一芯片的不同批次,采集到的旁路信号不尽相同,这给硬件木马的潜伏提供了便利条件,同时也给模式的匹配带来困难,不利于进一步的分类决策。线性判别分析(LDA)使木马分类变得非常容易。因为LDA本身是一种处理高维数据的模式识别降维算法,它将高维空间嵌入到低维空间中,同时保留大部分所需的特征信息,因此面对高维数据时其分类效果最好。

表2 本文识别率与以往技术的比较(%)
4.4 温度与电压分析
集成电路会受到环境温度变化的影响,改变电子和空穴的迁移率,同时改变了器件的阈值电压,从而可能导致异常的电路电气行为或更细微的电气退化。为了解决这个问题,图9显示了VT灵敏度分析对电路的影响。在这项工作中,我们使用如图9(a)所示的温度传感器,它是一个开环运算跨导放大器,具有由双极晶体管Q1和Q2形成的差分对。回想一下,双极晶体管的集电极电流对温度具有指数依赖性,Q1和Q2位置之间的温差ΔT将反映在输出电压Vout上。因此,如果我们将Q1放置在靠近CUT而Q2远离CUT和任何其他热源,使得Q1感应到靠近CUT的温度而Q2感应到参考温度,那么Vout将响应温度的变化Q1的位置是由CUT的功耗变化引起的。
图9(b)中的虚线曲线显示了一个可能的初始传递函数。原因是传感器以开环配置工作,其输出电阻非常高,以实现所需的高灵敏度,这使得Vout对过程变化非常敏感。因此,在将传感器用于测试方案之前,需要精确控制其传递函数,并将Vout调整到期望值Vref,该值选择在接近Vdd的线性区域内。为此,我们采用晶体管MCALN和MCALP,它们作为电压控制的电流源工作,并在双极晶体管Q1和Q2处引入可控的不平衡。改变校准电压CALP和CALN以改变传递函数并校准传感器,使得ΔT=0时Vout=Vref,如图9(b)的连续曲线所示。
考虑CUT和温度传感器均无木马的情况。如果我们只打开温度传感器的电源,那么将能够通过改变CALP或CALN来校准它,使得Vout=Vref,如图9(c)所示,假设任何无木马的CUT都会在区间[Vmin, Vmax]内产生Vref2。所有上述区间都可以通过对分割矩阵批次中的一组无木马芯片进行表征来提取,以便考虑所有制造变化。
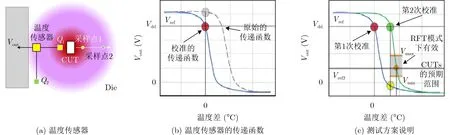
图9 温度和电压校准设置
图10描绘了木马检测数量在VT空间上的变化,电压范围(0.8~1.2V),温度范围(-20°C~120°C)。实验结果表明,当电压在1V左右,温度在36°C左右时,检测到的木马数量最多。可以注意到,VT对可木马检测数量存在很大差异,即在较低的电源电压、较低的温度往往会增加缺陷检测的难度,原因在于木马在特定VT下才被激活。因此,合理选择VT可以大大提高木马检测性能。

图10 不同温度和电压下检测到的木马数量
4.5 挑战
本文方法的局限性:旁路分析检测方法都需要“金片”(不含木马的IC)作为参考模板,该检测形式虽然有效但仍存在一定的局限性。一方面,由于工艺噪声的存在,检测效果往往不是很理想,尤其是基于延迟信息的旁路检测;另一方面,对于某些类型的木马,如通过改变电路板上的电路厚度来植入的木马,就很难得到真正的“金片”。因此,如何获取高质量的有效旁路信号是木马检测的重要前提,对旁路信号进行物理建模,描述其统计分布特性,找出由木马造成的旁路信号差异,建立最优匹配测度,达到与参考模板的最佳匹配。
5 结束语
芯片在生产过程中可靠性问题日益严俊。本文提出一种基于旁路信号的硬件木马检测方法,探索了机器学习分类算法在硬件木马检测方面的应用,初步凝练了硬件木马的科学问题与关键挑战,从分类、回归等角度提出了创新性的研究方向,提示了木马的特征与规律。在温度和电压影响方面,分析了机器学习预测模型对识别木马的重要性,对促进芯片可靠性研究起到了积极推动作用。
