一种面向自然语言交互接口语义分析的MNet方法研究
2023-02-17沈春山肖宗涛徐德强
沈春山,肖宗涛,徐德强
(安徽农业大学 信息与计算机学院,合肥 230036)
1 引 言
语义分析是自然语言处理的关键过程,是一个广泛的概念.面对不同的语言单位时,其任务不同,如词层面上的词义消歧、句子层面上的角色标注,以及篇章上的指代消歧层等.
近年来语义分析主要集中在规则类方法和统计类方法,前者基于一系列语言规则,以生成语言学为基础,后者以大规模语料库的分析为基础,采用概率和数据驱动的方法[1].规则的方法通常从建立“谓词论元之间的关系”入手,例如有一阶谓词演算、语义网络、概念依存图、基于框架的表示方法等.随着向深层语义分析方向的发展,逐渐演化出了语义依存分析树、依存分析图,抽象语义表示(abstract meaning representation,AMR)[2],组合范畴逻辑,知识图谱等概念和应用.这类方法通常按照组合型原则进行语义分析,倾向于词汇主义,认为词汇是描述语言的中心,如义素分析法、语义场、HowNet等[1].统计类方法认为,人类对语言的运用依赖于以往大量语言实践经验[3].这样产生了基于概率统计和数据驱动的方法,当前主要以分布式学习(又称词嵌入、词向量表示)为基础的深度网络为代表.包括词嵌入、句子嵌入这类语言单位的向量表示在一些浅层语义分析中获得了不错的效果,如命名实体识别、词关系抽取、文本分类、自动术语抽取等[4].基于理性规则和经验统计的方法在实践应用中也不断地进行融合,并取得不错的效果.例如,文献[5]采用卷积神经网络方法开展情感分析任务研究.文献[6]提出了一种情感语义分析中的深度学习融合算法.
从语义分析的时空过程看,语义分析处理与句法分析可以有先后,也可以同步进行,从而导致语义表示方法的不同.可以先句法分析再语义分析,又称为句法驱动的语义分析,相应的语义表示方法如带语义附着的剖析树;也可以句法分析与语义分析同步进行,又称句法语义一体化方法,如融入λ演算的组合范畴语法.从效率的角度看,句法与语义同步分析有一定的优势[1].
从实际的应用效果来看,在面向不同的自然语言理解任务时,语义分析的重点是将自然语言转化为某种目标系统的形式化描述逻辑.分布式SCADA(Supervisory Control And Data Acquisition,系统控制与数据采集)的自然语言操控接口设计,需要将用户表达的语音或者文本转换成可执行的计算机系统调用接口.核心是解决下列两个问题:1)自然操控语言的形式化语义功能描述,解析操控的意图及复杂操控序列之间的输入输出调用关系;2)操控序列与计算机系统调用接口之间的映射.就如软件建模方法一样,其中第1步是根本任务,打造由抽象语义实体构成的复杂自然语言概念结构.
如果说自然语言是对客观世界场景的描述性建模,那么自然语言处理领域的语义分析就是对自然语言的建模,但归根结底语义分析是对客观世界场景的建模.客观世界场景的本质上是描述静动态特征的组合,即组成及其相互关系.静态特征描述了各个组成部件之间的组成关系;动态特征描述了部件之间是如何协作交互的.语义分析模型通常融合了静动态的建模方法:语义实体的组成及其相互关系.模型的评价可以从可视化、并发性、可执行、复杂度、一致性和可变性等6个方面描述.
语义分析方法在复杂度、一致性、可变性和可视化等方面还需要进一步研究.如AMR在依存图的基础上,放松了对节点的限制,可以增补节点.节点可以是句子中的词,也可是PropBank Frameset等特殊的原句子单位中没有的词,但对于一些不符合组合原则的句子语义并不能很好地表达,需要添加一系列特殊规则,一致性不够好,这给应用带来了困难[2].语义网络也融入了很多自然语言本身中没有的概念节点,模型构造的一致性较差,不便于理解.统计类方面,基于大规模语料库,通过自然语言句子和对应的逻辑表达来训练得到语义解析器,可视化、可变性较差,且对段落和篇章以上的嵌入式表达比较困难.
本文在吸收语义网、深度网络、依存分析等现有概念基础上稍作综合和延伸,提出一种意元网络MNet的语义分析方法.MNet由意元、内关系、外关系及特征属性构成,并通过层次化递归的方式进行定义,面向从短语、句子到篇章的整体语义空间描述.后续的章节安排如下:第2节介绍对MNet方法做了总体的介绍;第3节给出了MNet的构建过程;第4节开展了第3节的实验研究,解决智能家居SCADA系统的自然语言交互接口语义分析问题;第5节是总结和展望.
本文以设计SCADA系统的自然语言操控接口为例来说明MNet方法.本质上来说,MNet不是新理论,是一种面向特定应用的语义分析综合架构,是在已有方法基础上的综合运用.
2 MNet方法
本节先给出语义分析模型MNet的抽象定义,然后对比相关方法的相同点和不同点,最后给出MNet的构建思路,并说明了MNet的构建过程也就是语义分析求解的过程.
2.1 抽象定义
定义1.意元网络MNet:是一个有序组,MNet=(n1,n2,…,nm;r,R,P),其中:
ni(i=1..m)也是一个意元网络,是N的子意元网络(这是一种递归的定义,这点尤为重要,也是区别其它语义网络重要特点),m≥1,例如在自然语言描述的框架下,ni可以是从词、词组、短语到句子和篇章的任何形式.
r是N的内关系集合,r={rij|i,j=1..m,且i≠j};
R是N的外关系集合,R={Rik|i=1..m,k=1..∞};
P属性的集合,P={pi|i=1..∞};
定义2.意元网络MNet的内关系:rij是一个四元组(ni,nj,relation,P),其中relation是ni指向nj的关系名称,其中ni∈MNet,nj∈MNet.
定义3.意元网络MNet的外关系:Rik是一个四元组(ni,nk,relation,P),relation是ni指向nk的关系名称,其中ni∈MNet,nk∉MNet.
定义4.属性集P:pi是二元组(AttriName,AttriValue),即由属性名和属性值组成.
定义5.元关系:若ni,nj为独立的词,则rij或Rik为元关系.
这里做几点说明:1)MNet认为最小的语义单位是词,词与词之间的关系被称作为元关系;2)MNet只定义了二元关系,实际语义单元之间是存在多元关系的,如4.3节的SCADA自然语言接口解析中的指令就是三元关系的,一般三元关系可以转化为二元关系,为了简化起见,不再详细展开;3)外关系可以理解为语义单元的上下文关系,或者一些常识性的关系,如句子“打开卧室的台灯”,“台灯”和“电器”的就是一种类属关系,但“电器”并不是该句子的组成.
图1展示了从用户自然语言“请先打开卧室的台灯再关闭窗户”中抽取出“关闭卧室窗户”的指令任务的MNet求解方法过程.将“卧室”与“Location”、“关闭”与“Action”、“窗户”与“Object”建立起对应的映射关系,可理解为外关系;“先”依存“打开”,依存名称属性是“时间”,这些是内关系.本文在随后的3.3节做详细解释.
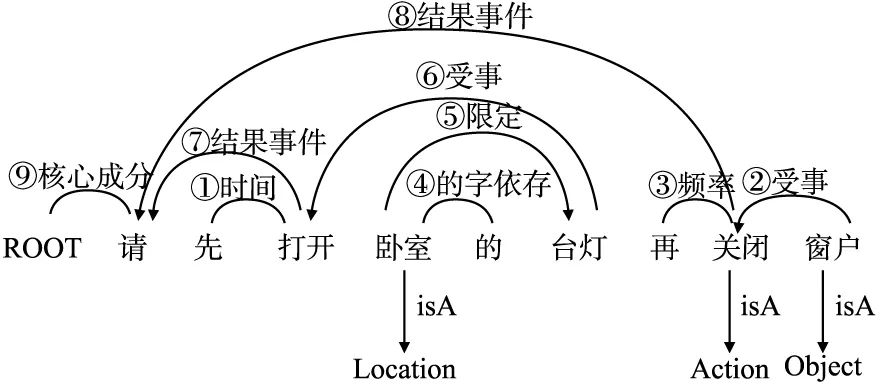
图1 MNet方法举例Fig.1 MNet method example
2.2 比较分析
MNet的目标对象是一个句子时,类似的方法主要集中在句子的依存分析,如依存分析树、依存分析图.语义依存分析旨在描述句子结构中词和词之间事实或逻辑上的语义关系.广义上来讲,这种关系也包含了句子成分上的句法功能关系,因此语义依存分析可包括句法依存分析.
从定义1看出,语义依存树是意元网络的一种特殊形式.当意元网络N满足如下限制时,即简化为自然语言语义依存关系树:
1)S=n1,n2,…,nm是由词构成的完整的自然语言句子;
2)r满足语义依存关系树相关的以下限定条件:
a)r为边与n1,n2,…,nm为节点构成的是一个单根节点的有向无环树;
b)ni(i=1…m)仅有一个父节点;
c)如果单词ni依赖nj,那么ni和nj之间的所有单词都从属于nj.也就是说依赖树中没有边交叉的.
3)R与P为空集合.
语义依存图突破了语义依存树在边交叉和多父节点上的限制,扩大了语义描述的功能[7].AMR同样突破了传统的句法树结构的限制,将一个句子语义抽象为一个单根有向无环图[2].从意元网络概念角度来看,语义依存树、语义依存图以及AMR侧重描述句子内部词与词之间的依存关系,即意元网络的内关系,缺少对所处语言背景下的外关系描述.以句子语义分析为目标的类似方法还包括语义网络等,其本质上都是以网络图形化的方式表达词之间的概念关系.
当讨论的目标对象是整个特定自然语言的所有以词为语言单位的集合时,意元网络MNet功能类似ConceptNet[8]、WordNet[9]、HowNet,以及知识图谱等知识库工具.一些互联网公司和组织也陆陆续续推出自己的知识库工具,如谷歌知识图谱(Google Knowledge Graph)、BabelNet、DBPedia、DBnary、微软概念图(Microsoft Concept Graph)等,但目前应用并不太广泛.这些知识库工具以描述词与词之间的概念关系为内容,可以作为更上层语言单位进行语义分析时的基础工具.意元网络MNet在描述词与词关系的时候所采用的方法和以上知识库工具具有类似性.
总之,MNet融合了WordNet等知识库工具、语义依存树(图)、语义网络等表达方法,试图以一种统一的模型来表示语义关系.重要的特点是引入了外关系和递归结构的定义.
2.3 构建思路
本节试图解释MNet产生的思考过程.以图2为例,从常识和直觉角度,加入假设性评价,说明阅读推理的自然语言处理任务过程.句子“某人微笑着走向放有苹果和水杯的桌子”是对“某自然生活场景”的概况描述.计算任务要求预测当事人下一步的状态.按照常识,该状态可能包括“吃苹果”或者“喝水”.从语义分析模型的静态特征看,场景中各层元素的内部和外部关系,对应着句子中的语义单位的内关系和外关系.这里的内外关系和语义分析模型的内外关系概念上一致.自然语言语义分析的过程就是要构建并推理出这些关系,也就是语义分析模型的构建.
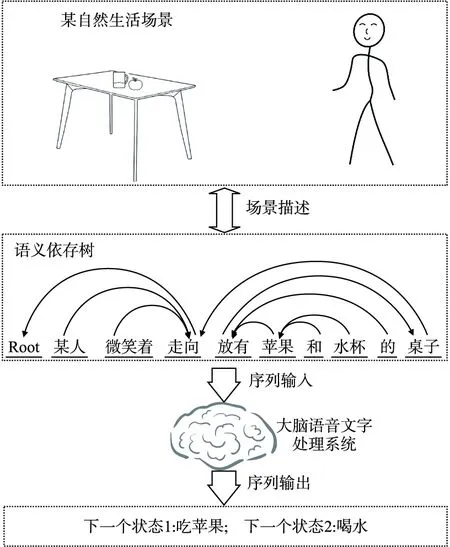
图2 自然语言理解任务Fig.2 Natural language understanding tasks
语义分析模型的构建其实是可以并行处理的.语音传输是时间序列,一般阅读也是从左至右,这样容易造成一个错觉,认为大脑处理语音文字总是依照输入顺序逐词逐句处理的.但是,语言文字中的语义单位之间的关系是由客观场景本质上决定的,每一个语义单位都是活生生的自然场景元素,彼此在时空上是独立的.因此,构建和推理这些关系可以由这些语义单位自行组织关联.也就是说关系的构建过程不必按照句子输入顺序逐词处理,可以类似处理视觉图像一样进行自底向上的并行处理.现代认知神经科学认为,语言可以被大脑转换为视觉信息,皮层处理来自耳朵的信号的方式与处理来自眼睛的信号的方式相同[10].通常在空间上相邻词之间依赖关系也越强烈,适合自底向上的并行分析处理.本文随后相应地在3.2节提出了自底向上规约式的MNet语义依存树构造算法.
在分析推理上可以充分利用外关系,这个外关系在语言文字中表现为上下文关系和背景知识.在自然语言处理中,我们可以用语义依存树来帮助标记场景元素的内外关系,以帮助逻辑推理,但显然这是不够完备的.由于句子本身的内部关系和上下文背景知识外部关系的共同作用,句子语义单位之间呈现出复杂的网状结构.在句子“某人微笑着走向放有苹果和水杯的桌子”中,当事人的内部关系有“走向桌子、苹果、水杯,微笑着”,结合外部关系“苹果、水杯可能是食物”、“人可以吃食物、喝水”等,对相应的关系网络进行搜索,演绎出下一个可能的状态是“吃苹果、喝水”.
基于上述分析,本文用MNet来探索标记客观场景的元素组成和关系.MNet的构建可以采用自底向上的自组织构建方式,以解决具体的自然语言处理实际问题为目标,采用以下步骤在构建MNet的过程中求解应用问题:
1)元关系构建.是指建立基本的词与词之间的语义关系库,为求解MNet的内关系做好基础.在3.1节采用基于双向GRU和注意力机制的深度学习方法构建了词和词之间的元关系库,对应地4.1节进行了实验研究.
2)树构建.主要指内关系的构建.根据元关系,采用并行的自底向上的自组织方式归纳构建一般意义上的语义依存树.本文随后在3.2节和4.2节分别提出一种自底向上规约式的MNet语义依存树构造算法和实验分析.
3)网构建.主要指外关系的构建.考虑到MNet不可能一次性构造完成,不可能也没有必要穷尽句子中语义单位的所有外关系.根据特定的自然语言计算任务,对前一步构建的语义树进行外关系扩展.以智能家居SCADA系统的自然语言操控接口为例,目的是将MNet语义依存树中的节点与目标指令进行关系映射.3.3节和4.3节分别介绍了算法和实验结果.
由于当前认知限制,我们没有严格从数学理论上对MNet方法做深入地探讨,主要是从解决自然语言操控接口的设计角度,提炼了语义分析的MNet思路.有待研究的空间还很大,包括引入第三方知识库来推理MNet外关系、MNet意元的嵌入式向量表达、属性集合的设计,以及逻辑语义学的引入等.
表1从语义表示模型评价的几个维度对MNet方法进行了说明.一定程度上MNet体现了较好的并发性、可变性、可视化、一致性,以及复杂性低等特点.
3 MNet构建
3.1 元关系构建
MNet元关系可以直接采用WordNet、HowNet知识库工具,但面对特定的领域问题时,还需要预先通过样本训练构建.采用双向GRU和字向量,结合子字符级别和句子级别注意力机制,从样本中训练词与词之间的关系[11,12].
输入的表达使用了字符嵌入和待预测关系的一对词的位置嵌入信息向量,加入字级别的注意力机制,结合双向GRU和字符注意力机制,形成句子的嵌入向量表达.
例如有涉及关系对(word1,word2)的n个句子,记为si(i=1…n),每个句子的嵌入表达向量信息中都包含了是否包含关系r的信息.为了利用所有句子的信息,当对关系对(word1,word2)预测关系r时,加入句子级别的注意力机制,用包含所有句子嵌入表达信息的特征向量来表达这n个句子集合,然后做整体训练.这样做的优点是可以降低错误标准数据的噪声影响.模型架构如图3所示.
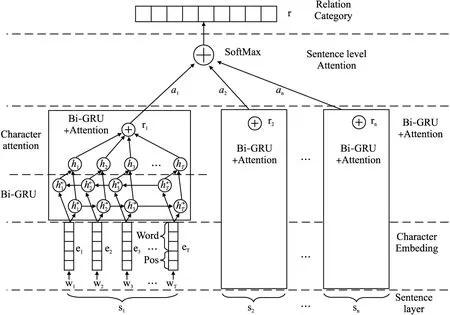
图3 Bi-GRU 结合字符及句子级别注意力机制原理Fig.3 Principle of Bi-GRU combining with character and sentence level attention mechanism
3.2 树构建
语义依存树分析方法主要包括基于转移和基于图的方法[7].为了更加符合人类语言思维习惯,考虑并发可执行性,综合了基于转移和图的方法,在获得句子中词与词之间的关系概率基础上,采用自底向上的相邻词竞争结合依赖方式,构建语义依存树.和传统的基于转移的方法不同在于:1)不再受限于句子的输入顺序,与左结合依赖优先还是右结合依赖优先无关;2)对于未确定所依存对象的词,不但从左右相邻词中检查依存关系,还包括相邻词所依存的词;3)对于构建过程中产生的多子树现象做了优化处理.具体算法如下所示.算法1.MNetSParser
输入:包含n个词语的句子S,从左至右第i个词标记为wordi,如S=“请先打开卧室的台灯再关闭窗户”
输出:句子S的语义依存关系D(是一棵树),D初始为空,数据形式如下:
{
′word′:[′请′,′先′,′打开′,′卧室′,′的′,′台灯′,′再′,′关闭′,′窗户′],#分词结果
′postag′:[′v′,′d′,′v′,′n′,′uj′,′n′,′d′,′v′,′n′],//词性
′head′:[-1,2,0,5,3,2,7,0,7],//word所对应依赖的词的序号,从0开始,如“台灯”依赖“打开”,关系是′受事′
′deprel′:[′核心成分′,′时间′,′结果事件′,′限定′,′“的”字依存′,′受事′,′频率′,′结果事件′,′受事′],#依赖类型
′prob′:[0.75,0.9,0.5,0.34,0.25,0.79,0.82,0.35,0.17] #依赖概率
}
处理:
BEGIN
初始化:
word=S的分词结果;word中的所有词标记为“未消解”;
n赋值为S中词的个数number=len(word);
word_undep= {1..n};//记录没有确定依赖的词的序号
head= array[n];//初值为-1
deprel= array[n];//初值为-1,-1表示依赖于ROOT
Step 1.根据意元网络N计算S中的所有还没有依赖项的wordi邻近依赖概率Pij(或Pji),i∈word_undep,wordj满足:
1)j属于{k|k=i-1,或者k=i+1,或者wordk是wordj的所有上层依赖(父节点)},且同时满足:
wordj与wordi之间未确定依赖关系.
wordj标记为′未消解′.
2)若j为空,令m、n分别为距离j左右两边最远的子孙节点,取:
j属于{k|k=m-1,或者k=n+1,或者wordk是wordj的所有上层依赖(父节点)};
Step 2.选择最大的Pij(或Pji),将对应的wordi与wordj为确定为依赖关系,记为DepWi,Wj(或DepWj,Wi),加入D.DepWi,Wj表示wordi依赖于wordj,反之表示wordj依赖于wordi.
Step 3.更新D://确定wordi依赖于wordj
word_undep = word_undep -{j};
head[i]=j;
deprel[i]=wordi依赖于wordj的关系类型名称;
将wordi与wordj之间的词(不包括wordi与wordj)标记为′已消解′
Step 4.去步骤1处理,直至len(word_undep)为1.
Step 5.将剩下唯一的未确定依赖项标记为根节点,标记依赖为Root.
Step 6.结束,输出D为依存分析结果.
END
以某个具体的句子“请先打开卧室的台灯再关闭窗户”为例,算法1“MNetSParser”的计算过程如图4所示.

图4 MNetSParser分析过程Fig.4 MNetSParser analysis process
例如第“⑧”步针对词“关闭”的依存概率计算相关词包括“台灯”、“打开”、“请”,从图5未标记关联折线中依据概率最大原则,选择“关闭”以′结果事件′的方式依存于“请”.
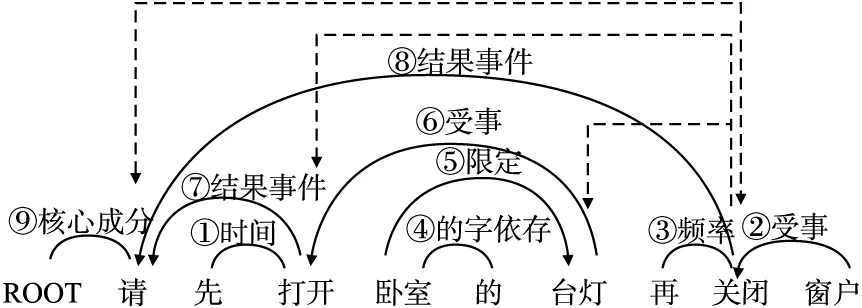
图5 依存关系计算选择过程Fig.5 Dependency calculation selection process
3.3 网构建
由于语义理解任务的不同,MNet网构建的内容是不同的.其本质是在树构建的基础上,根据下游自然语言处理的任务不同,对词及其相互关系进行再一次的标注.这里的二次标注既可以在语义依存树解析完成以后进行,也可以在语义依存树解析过程中进行.因此MNet对自然语言的解析是可以持续优化的,也就是可以对语义进行不断地加深理解,这一点比神经网络模式具有一定的优势.
以SCADA(System Control and Data Acquisition,系统控制与数据采集)系统的自然语言交互接口应用为例说明特定的MNet网构建的过程.SCADA系统操控模式主要包括查询指令和控制指令,前者获取现场过程或设备的状态数据,后者改变现场设备或者过程参数.SCADA系统操控指令一般包括3个部分:动作、对象和参数.最典型的参数就是位置,指示操控对象的具体地点.例如,自然语言指令“打开卧室的台灯”,利用自然语言处理程序将其转化为数据结构“{Object=台灯,Location = 卧室,Action = 打开}”的中间语言后,就可以通过形式化的规则生产SCADA系统的调用指令.SCADA系统自然语言操控指令解析原理如图6所示.
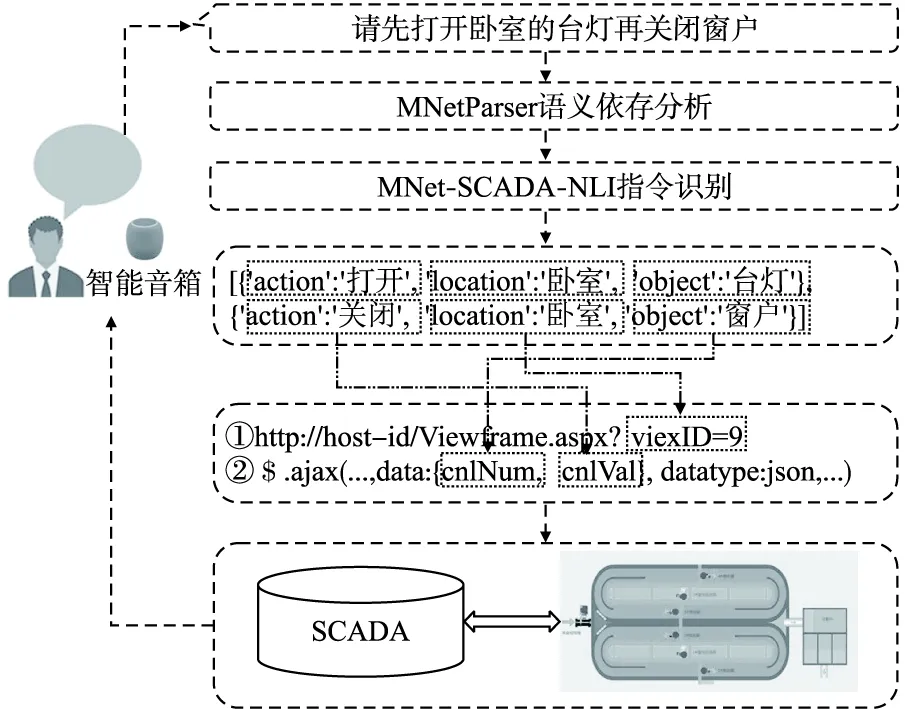
图6 MNet-SCADA-NLI解析原理Fig.6 MNet analytic principle
用算法1“MNetSParser”对句子“打开卧室的台灯”做语义依存解析,结果为:
{
′word′:[′打开′,′卧室′,′的′,′台灯′],
′postag′:[′ v ′,′n′,u′,′n′],
′head′:[0,4,2,1]
′deprel′:[′核心成分′,′限定′,′“的”字依存′,′受事′],
}
在依存分析结果上,结合特定环境下具体自然语言的语法和使用习惯,可以提炼出针对目标任务的规则集,从而能够比较容易地抽取结构 “{Object,Location,Action}”.例如,可以定义如下规则:
规则1.若wordi以′关系′受事′依存于wordj,则可抽取Action=wordj,Object=wordi;
规则2.若wordi以关系′限定′依存于wordj,且wordj已被抽取为Object,则可抽取Location=wordi.
规则3.如果与已经解析的Object存在连接依存关系且为名词,则也识别为Object,且两者的Action和Location一致.
因此,简单的SCADA系统自然语言操控接口可以用算法2 “MNet-SCADA-NLI”描述.当然,实际的自然语言操控系统可能多种多样,如“我想你打开卧室的台灯和空调”.针对更加复杂的自然语言操控序列,可以通过增加规则的方式解决,原理是一样的.
算法2.MNet-SCADA-NLI
输入:MNet语义依存分析树D,D的定义同算法1
输出:Command={Object,Location,Action}
处理:
BEGIN
command={};//产生的命令组
FOR 每个关系i IN D.deprel DO
IF D.deprel[i]==′受事′ D.postag[i]== ′n′
Objects.append(D.word[i]);
Action = D.word[D.head[i]];
//搜索Location
j=0;Location=′NULL′;
WHILE j<=D.head.length DO
IF j<>i and D.head[j] == i
IF D.deprel[j] == ′限定′
Location = D.word[j];
END IF
//处理Object的连接依存
IF D.deprel[j] == ′连接依存′ and D.postag[j]== ′n′
Objects.append(D.word[j]);
END IF
END IF
j++;
END WHILE
FOR 每个对象i IN Objects DO
IF Location== ′NULL′
Location赋值为前一组command的Location;
添加{Action,Location,Object[i] }到command;
END FOR
END IF
END FOR
END
为了更高效地完成目标任务,特定的MNet网构建的过程也可以融入到MNet树构建的过程中.这样,可对算法1“MNetSParser”的STEP3进行修改以满足应用要求.经过算法2 MNet-SCADA-NLI的处理,MNet网可示意如图7所示.
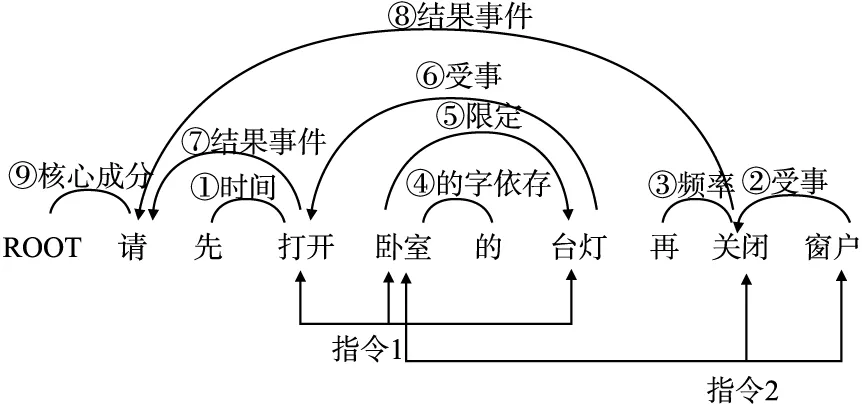
图7 MNet-SCADA-NLI添加的MNet网Fig.7 MNet network added by MNet-SCADA-NLI
4 实验与应用
4.1 MNet元关系的构建:词关系知识库
词与词之间的关系没有统一的定义,包括WordNet、HowNet、ConceptNet等都各自定义,但都不可能完备.本文从自然语言处理与中文计算会议(NLP&CC 2013)公开的中文语义依存关系分析评测数据包“evsam05.zip”中构建原始的词关系样本,采用3.1节的模型进行训练.
evsam05.zip的格式采用的是CoNLL格式的中文依存语料库,实验数据来源于其中的清华库.为了便于模型的训练,数据样本统一转换为如表2所示.

表2 部分样本数据展示Table 2 Some sample data display
清华语义依存树库中词之间的依存关系类型列出了69种,如表3所示.
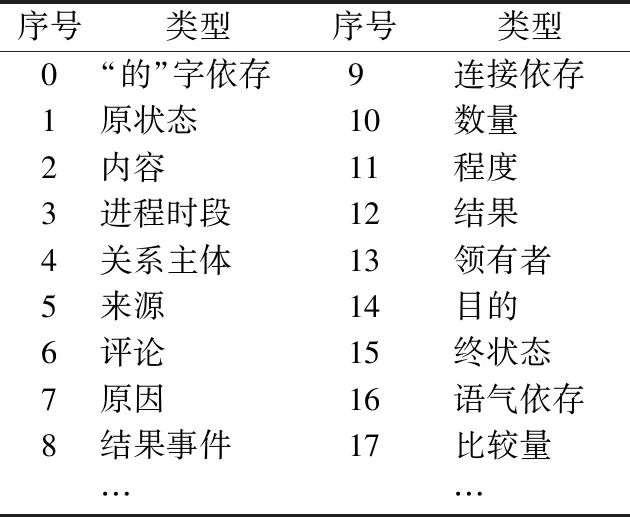
表3 部分词关系类型Table 3 Types of partial word relations
例如,在句子“世界第八大奇迹出现”中,“世界”依存于 “奇迹”的关系是“限定”.同时加入了负样本,关系类型为NULL,表示该组词之间并没有发生依存关系.数据分为训练集和测试集.分别测试了不含负样本和含负样本两种情况,其中含负样本的训练集中80%为负样本.负样本的加入,明显提高了训练的效率和准确性.图8和图9是利用tensorboardX工具展示了增加负样本的训练过程中损失函数和准确率的变化,最终选择了训练拟合准确率acc为0.98的模型作为使用模型.该模型在test测试集上关于词关系预测的准确率为89.9%.有关本模型使用的详细工作可参考文献[12].
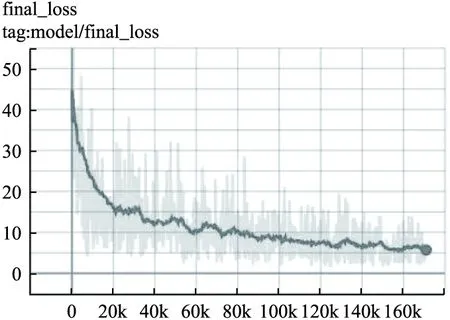
图8 训练过程误差的变化Fig.8 Error change of training process
图9 训练过程拟合准确率Fig.9 Accuracy of training process
4.2 MNet树构建:MNetSParser语义依存分析
4.2.1 数据来源和分析过程评价指标
测试集采用自然语言处理与中文计算会议(NLP&CC 2013)公开的中文语义依存关系分析评测数据包.
评测采用3个指标对被测试系统进行评测,分别为:
·依存标注准确率(Labeled Attachment Score,LAS)
·依存准确率(Unlabeled Attachment Score,UAS)
·标注准确率(Labeled Accuracy,LA)
假设整个测试语料包含的词个数总和为N,任意词语的依存用三元组
(1)
(2)
(3)
4.2.2 结果分析
1)计算复杂度分析角度.算法1“MNetSParser”可以在O(nlogn)时间内完成语义依存树的构建,和简单边优先类似.
2)从准确率角度.通过使用相同的词关系计算模型,与效果较好的基于转移的边优先算法进行对比[13,14],结果可以看出MNetSParser具有一定的优势,提高了约2~3个百分点,如表4所示.但总的来说都不算高,主要原因还在于样本偏少,且依存类别多达70种.如果降低依存类别,加大样本,准确率会提高.另外解析的过程中增加词性、依存类别优先级等因素也会改善准确率.

表4 MNetSParser测试结果比较Table 4 Comparison of test results of MNetSParser
4.3 MNet图构建:MNet-SCADA-NLI设计
针对智能家居领域的自然语言交互场景,采用小范围问卷调查的方式,构造了约100条常用语言操控指令,分别采用TF-IDF[15]、以及本文的MNet-SCADA-NLI进行指令的SCADA系统中间语言识别.
表5展示了部分常用自然语言指令以及相应的预期SCADA系统中间操控指令解析结果.表6是相应的实际指令解析结果.

表5 智能家居领域自然语言指令及SCADA系统中间操控指令解析示例Table 5 Analysis examples of natural language instruction and SCADA system intermediate control instruction in smart home field

表6 MNetParser的解析结果Table 6 Parsing results of MNetParser
采用精确率(P)、召回率(R)和F值来评价算法的效率,定义如式(4)~式(6)所示:
精确率:P反映了预测结果中间语言中正确解析参数所占的比率.
(4)
召回率:P反映了自然操控语言样本中正确解析参数所占的比率.
(5)
F值:
(6)
式中:
N:正确解析的参数指标数目;
TotalP:算法预测结果中参数指标数目;
TotalR:原始自然操控语言样本预期结果中参数指标数目.
用TF-IDF[15]方法和本文的MNet-SCADA-NLI算法进行指令的SCADA系统中间语言识别,对比结果如表7所示.

表7 SCADA系统自然语言操控指令解析比较Table 7 Comparison of instructions Analysis for SCADA
从实验结果看,对于小样本训练集下,MNet-SCADA-NLI具有较明显的优势.TF-IDF主要是通过提取关键词进行排序,并根据词性和类别进行判别.在简单的自然语言指令解析方面TF-IDF性能较好,但面对复杂的自然语言指令解析效果比较差,甚至完全不能解析另外.例如,对于“请先打开卧室的台灯再关闭窗户”,TF-IDF通常容易解析出一组命令.还尝试了Seq2Seq之类的方法,但由于样本少,效果不理想.Seq2Seq一般需要大量的优质训练数据集才有可能取得不错的效果.MNet-SCADA-NLI方法在针对复杂的自然语言指令,在依存分析的结果上,结合领域特定的规则,问句的设定也具有一定的局限性,开放性不足,因此能获得较高的准确率.特别是针对一些复杂的操控语言序列,还需要先提高语义依存分析准确率上着手改善.
5 结 论
本文提出一种意元网络MNet的语义表示方法.MNet由意元、内关系、外关系及特征属性构成,并通过层次化递归的方式进行定义,期待面向从短语、句子到篇章的整体语义空间描述.从元关系、树结构和网结构3个过程设计了MNet一般构造算法和面向特定语义分析问题的解析方法,重点提出了自底向上规约式的MNet语义依存树构造算法和面向自然语言接口解析的网构造算法.实验表明该算法在SCADA系统的自然语言控制接口指令解析上的有效性.将特定问题的语义分析过程转化成MNet的一般构造和特定解析过程,兼顾描述了语言单位自身结构的内语义和所处语言背景的外语义,为自然语言语义分析提供了一定的思路.
本文只是一个开始,未来还有很多重要的工作需要深入研究.例如,MNet元关系构建可提取词向量特征、位置、词性、其他如WordNet、HowNet等已知知识库中的上下位特征等;利用第三方知识库进行外关系的深入推理;可以把深度强化学习融入到MNetParser算法的依存关系选择过程中;针对复杂的自然语言操控语句,开发深层嵌套的基于MNet语义的指令解析算法等.
