图神经网络在招投标文件分类中的应用
2023-02-17强成宇李晓戈马鲜艳田俊鹏
强成宇,李晓戈,2,马鲜艳,李 涛,田俊鹏
1(西安邮电大学 计算机学院,西安 710000)2(西安邮电大学 陕西省网络数据分析与智能处理重点实验室,西安 710000)
1 引 言
招投标是目前社会上兴建工程或者进行大宗商品交易时广泛采用的一种公开竞争方式.根据相关规定,采购网站与行业招投标平台会在招标结束后公开招投标详情,而这些公开的招投标信息往往具有很高的商业价值,对于很多企业而言,从中挖掘潜在的商业机会,能起到事半功倍的效果.
关于招投标文件数据挖掘、分析、评测的研究有很多.黄晓辉[1]根据对招投标文件的分析研究,结合数据挖掘技术与决策模型,提出了一种基于数据挖掘的投标决策辅助系统.孔维健[2]提出了一种基于图聚类的招投标数据挖掘方法,该方法通过在招投标数据挖掘中应用二分图聚类分析方法,发现存在一些具有行业背景聚类特征的群体簇,并分析招投标关系网络中社团形成所需要的条件.王佩光等人[3]提出了一种基于人工智能的智能评标辅助系统.该系统通过对招投标数据的分析,并采用主成分分析方法获取影响企业信用等级的主要影响指标.将指标及对应的企业信用等级作为样本集,从原始样本集有放回的生成随机树训练集,建立企业信用评估的随机森林模型,并通过投票方式获得企业信用等级.
招投标文件较普通的文本相比有一定的特殊性和不同性,网络上的招投标信息存在缺乏标注、结构混乱不规则、数据来源多样等特点.并且同一网站公布的招投标文件都拥有相同的格式和文件模板,例如,对于同一采购单位的招投标文件,除了项目名称、采购需求和成交金额不同外,其余文本内容几乎相同,导致用于文本挖掘的特征字段十分有限.由于缺乏足够的文本和上下文信息,使得许多神经网络模型无法自动获取到丰富的类别特征,并且模型训练时依赖大量的标记样本,专业标记成本较高.因此如何有效补充招投标文件的文本特征,同时低成本的充分利用少量标记样本和其他大量未标记样本进行分类,成为其价值挖掘的关键.
本文针对招投标文件主流的分类方法进行了探究,并提出一种基于图卷积神经网络的半监督招投标文件分类模型.首先将网络上爬取的招投标文件信息进行结构化清洗,并利用基于规则的信息抽取技术构建知识图谱,再融合外部文本信息对知识图谱进行特征补充,最后利用少量标记样本通过卷积神经网络进行半监督分类.
2 相关工作
招投标文件分类的本质就是文本分类,目前主流的文本分类方法有:基于预定义规则的方法、基于传统机器学习的方法以及基于深度学习的方法.
基于预定义规则的方法是使用一系列预先定义好的规则将文本分类为不同的类别,该方法虽然在足够准确的规则下效果会很好,但需要对分类的所在领域有足够深入的了解,使用门槛较高.
近年来传统机器学习模型备受关注,大多数机器学习文本分类模型都分为以下两个步骤:特征工程与模型分类.第1步特征工程主要是从文本文档中手工提取一些特征;第2步则是将提取的特征利用传统机器学习的分类算法进行预测.常见的机器学习分类算法包括朴素贝叶斯、支持向量机(SVM)、K近邻(KNN)、决策树和随机森林等.同样,传统机器学习的分类方法也具有一定的局限性,例如,十分依赖前期的特征工程,对特定领域知识提取的文本特征所训练的分类器难以将其推广到新的任务中[4].
相较于传统的机器学习分类算法,基于深度学习的分类方法在特征提取方面有足够的优势,但也存在一定的局限性.具有代表性的深度学习算法主要有RNN、CNN、Transformer等[5].其中以LSTM/GRU及其变形为代表的RNN不仅可以有效的捕获文本的长距离特征,而且还可以有效的处理不定长的线性序列文本数据,但是由于RNN本身要求在计算当前时刻的输出结果时要考虑上一时刻的隐藏状态,从而导致RNN难以实现并行运算,运算速度较慢,因此限制了RNN在文本特征提取中的发展和应用.而CNN利用堆积一个或多个卷积层、非线性和池化层来自动提取特征,在CNN网络结构的设计中,通常可以利用跨层连接机制来增加网络深度,从而提取更为有效的特征,但CNN在长距离特征提取上性能低于RNN[6].后来Tai[7]等人改进了传统的链式LSTM并提出Tree-LSTM模型,使其学习到更加丰富的语义表示.Bieng[8]提出了Topic RNN模型,该模型将主题模型与循环神经网络相结合,使RNN获取局部联系的同时通过主题模型获取全局联系.Prusa[9]利用卷积神经网络对文本特征进行提取,该方法减少字符级文本训练耗时,并保留了更多原始文本信息.Conneau[10]等人研究发现,随着CNN(VDCNN)网络层数的不断增加,模型提取特征的能力会更强,分类的准确率会更高.与VDCNN模型类似,目前很多深度学习模型大多都通过增加复杂度来提高性能[11].
知识图谱(Knowledge Graph)作为人工智能在知识组织和表示方面发展的最新技术,不仅能在不同实体之间建立语义联系,而且还能为子图分类和节点分类等工作提供良好的数据支持.对于知识图谱这种图结构数据,普通的卷积操作难以提取图结构的特征,针对这样的问题,以Gori等人[12]为代表的学者们逐步提出了一系列应用于图结构数据的深度学习模型,使得学习过程可直接架构于图数据之上.Scarselli等人[13]提出了一种基于信息传播机制,且有监督学习的图神经网络方法,其中节点之间通过互换信息,来更新自己的节点特征表示.Defferrard等人[14]开始从频谱上研究论证了积分在文本分类上的可行性.Kipf等人[15]提出图卷积神经网络模型(GCN),该方法把频谱图卷积的定义进行简化,提高计算效率,并且该方法还可以进行半监督分类.Yao[16]提出了将单词和文档作为图节点构建异构图网络,但未使用Attention计算节点间的权重,因此模型在评价类文本中准确率略低于传统神经网络模型.范敏[17]等人提出了一种基于混合图卷积网络模型,该方法结合了图中节点的相邻相似性、结构相似性以及特征多样性.本文采用GCN模型在构建的知识图谱上进行半监督节点分类.
3 模 型
本文提出的基于图卷积神经网络的半监督招投标文件分类模型(BD-GCN),流程如图1所示.
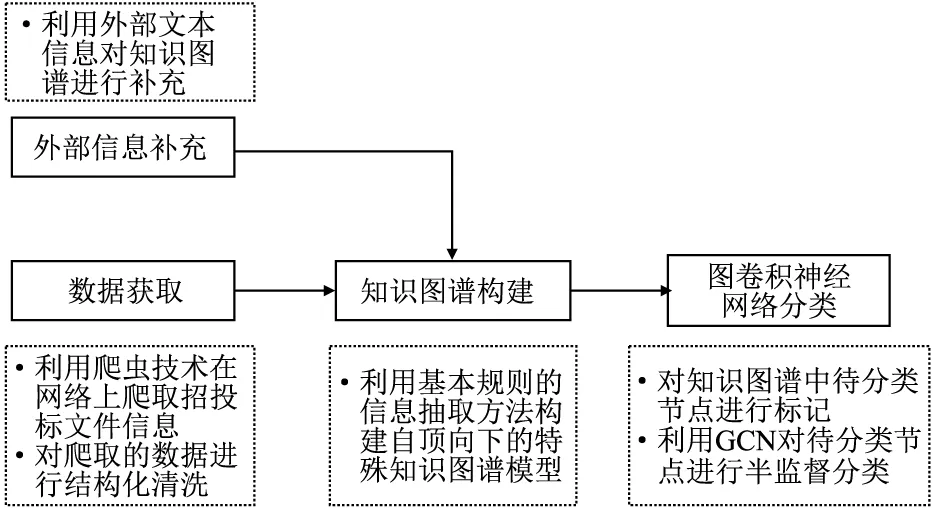
图1 BD-GCN模型流程图Fig.1 BD-GCN model flow chart
BD-GCN模型分为数据获取与知识图谱构建——外部信息补充——图卷积神经网络分类.数据获取与知识图谱构建是将网络上爬取的招投标文件信息经结构化清洗后,利用信息抽取技术构建成知识图谱;外部信息补充是利用外部的文本信息对知识图谱的每一个待分类节点进行特征补充,融合后形成多源异构图;图卷积神经网络分类是采用GCN对图谱中的待分类节点进行半监督分类,网络模型介绍见下文.
3.1 数据获取与知识图谱构建
首先,利用爬虫技术从全国政府采集网站上爬取招投标文件信息,其中各个领域、省份之间的内容、结构、格式都差异巨大.因此第一步需要对这些非结构化文本进行结构化数据清洗,这样既可以从中提取特征字段,又可以让不同来源的招投标文件结构统一化.
具体提取的内容包括:项目(项目名称)、发布时间、成交金额、标的信息、评审委员会名单、采购单位名称、采购单位地址、采购单位联系人与电话、代理单位名称、代理单位地址、代理单位联系人与电话、中标供应商名称、供应商地址.
上述提取内容中,招投标文件的类别主要由项目(项目名称)、标的信息、中标供应商名称、供应商地址决定,所以本文利用基于规则的信息抽取方法自顶向下构建一个特殊的知识图谱模型,构建时预定义实体和关系,将实体对应的具体文本内容作为实体属性,如表1、表2所示.

表1 实体预定义表Table 1 Entity predefined table

表2 关系预定义表Table 2 Relationonship predefined table
将项目(项目名称)实体作为待分类的中心节点,将单位、地址和标的信息实体作为邻居节点,如图2所示.
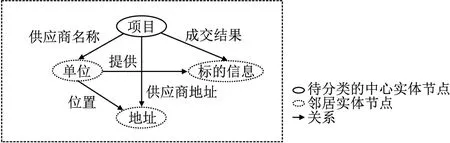
图2 招投标文件知识图谱模型示意图Fig.2 Schematic diagram of knowledge graph model of bidding documents
3.2 外部信息补充
与段落或文档分类相比,清洗后的招投标文件属于短文本,分类更加困难,即使经过数据清洗、特征筛选以及知识图谱构建等工作,但依然没有足够的上下文信息,特征较为稀疏,使得基于知识图谱做节点分类时效果不佳.为了解决这个问题,本文利用外部文本来增强知识图谱语义表示.
对于招投标文件而言,中标供应商为采购单位提供货物、工程和服务,一定程度上决定了它的类别,因此本文采用爬虫技术在天眼查网站上抓取每条招投标文件中中标公司的经营范围,爬取的内容示例如表3所示.

表3 供应商与其对应的经营范围示例表Table 3 Example list of scope of business
将爬取的文本同知识图谱中该条招投标文件的项目(项目名称)节点和单位节点建立关系,对知识图谱模型进行特征补充,新增预定义关系如表4所示.

表4 新增预定义关系表Table 4 Add a predefined relations table
图谱中单位与其经营范围会重复,即一个中标公司可能参与多个标,多个公司的经营范围的描述文本也可能相同,因此这样更加丰富了知识图谱模型中的关系,使其可以更好的利用图卷积神经网络进行半监督分类.经融合后构成多源异构图,如图3所示.
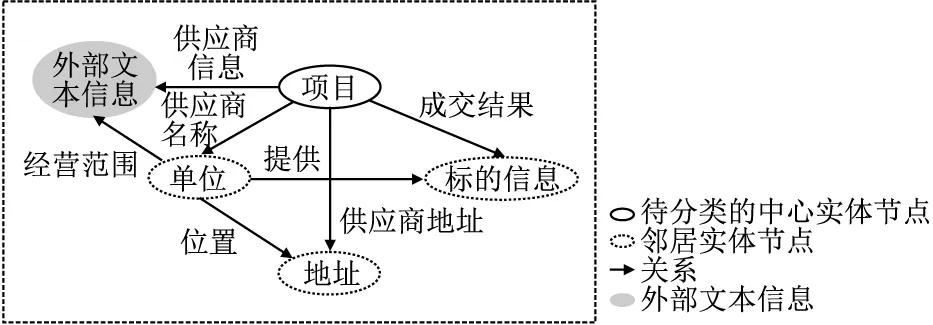
图3 经外部文本信息补充后的知识图谱模型示意图Fig.3 Schematic diagram of knowledge graph model supplemented by external text information
3.3 图卷积神经网络分类
本文采用文献[15]提出的图卷积神经网络(GCN)进行半监督分类,将少量有标签样本和大量无标签样本同时投入该模型,模型会将图结构和节点特征自然地结合起来,其中无标签节点特征会和附近有标签节点特征混合在一起,通过多层神经网络在图上进行传播,逐层递进更新节点的表示,以预测未标记节点的标签,实验表明该模型在一系列基准数据集上取得了很好的分类结果.因此本文利用该模型在构建的多源异构知识图谱上对待分类节点进行半监督分类.
3.3.1 图卷积神经网络模型结构
模型中的图卷积神经网络由输入层、特征提取层、图卷积层、输出层组成.图4展示了该模块的整体架构,各层具体描述如图所示.
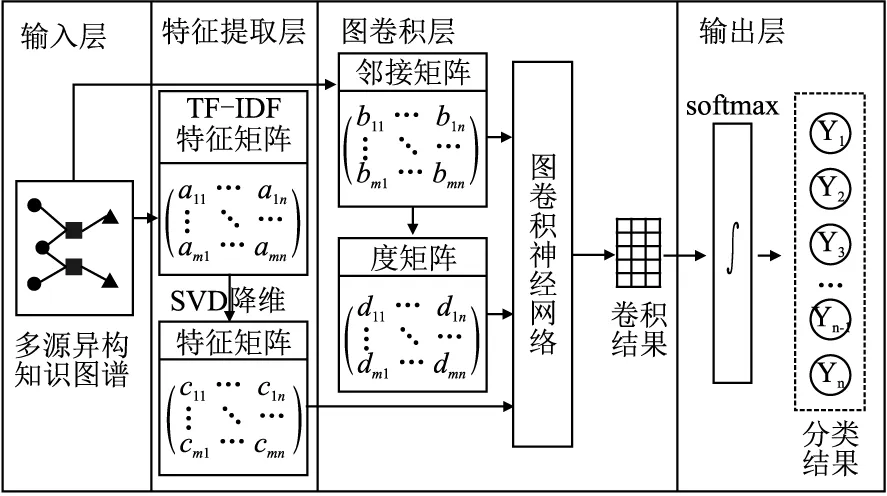
图4 图卷积神经网络分类结构图Fig.4 Figure classification structure of graph convolutional networks
3.3.2 输入层
输入层一方面将上一模块得到的多源异构知识图谱输入到图卷积层;另一方面,直接从知识图谱中抽取所有节点文本信息,输入到特征提取层,用于提取图谱节点的短文本语义信息.
3.3.3 特征提取层
特征提取层具体由两部分构成.第1部分利用TF-IDF[18]对知识图谱中每个节点进行文本向量化.IDF公式如式(1)所示:
(1)
在得到每个词的词频与值后,利用公式(2)计算出每个词的TF-IDF值.由此可将原始的图谱节点文本转换为TF-IDF的稀疏矩阵,来表示节点的特征.
TF-IDF(x)=TF(x)×IDF(x)
(2)
因为得到的特征矩阵为稀疏矩阵,并且当TF-IDF词表过长时,每个节点的特征维数会很高,会影响下游分类效果,所以本文利用SVD对特征稀疏矩阵进行降维,将原数据十万维的特征压缩至5000维,在保留大部分数据信息量的同时,使用维数小得多的特征来表示原始特征,去除噪声和冗余信息,优化数据,并提高分类效果.SVD的公式如式(3)所示:
(3)
式(3)中,降维后的矩阵维数k远小于降维前的矩阵维数n.
3.3.4 图卷积层
图卷积层是首先从输入层的多源异构知识图谱与特征提取层获得邻接矩阵、度矩阵和特征矩阵,然后将其输入到两层图卷积神经网络中进行半监督分类模型训练.该层输入的是知识图谱和特征矩阵,输出的是向量矩阵形式的卷积结果.
输入层的多源异构图由n个节点V={v1,v2,…,vn}和m条边E={e1,e2,…,em}的集合组成.要对图中节点利用图卷积神经网络进行分类,需首先从多源异构图中得到邻接矩阵、度矩阵和正则化的拉普拉斯矩阵,计算公式分别为:
A=(aij)
(4)
D=diag(∑i≠jaij)
(5)
(6)
在谱图卷积中,图上的卷积操作需要将拉普拉斯矩阵进行特征分解为特征值和特征向量,定义如式(7)所示:
gθ×x=Ug(ψ)UT×x
(7)
上式中,表示每个节点的标量,U表示表示拉普拉斯矩阵分解后的特征向量,ψ表示特征值.特征分解计算复杂度高,属于计算密集型,这就导致了矩阵分解在实际应用中无法计算.此外,该卷积核是全局的卷积核,参数量随着图中节点数增加而增加,因此需要放松约束条件,利用空间采样或者谱采样的方式来近似拉普拉斯矩阵.例如Donnat[19]等人提出的GraphWave模型,利用Heat Kenel来近似g(ψ).
而本文所采用的GCN模型通过引入切比雪夫多项式来近似g(ψ),避免了复杂的矩阵分解,同时利用一阶近似也就是局部卷积核来避免卷积核参数过大的问题.切比雪夫多项式定义见公式(8),式中,T1(x)=x,T0(x)=1.
Tk(x)=2xTk-1(x)-Tk-2(x)
(8)
GCN模型采用一阶切比雪夫多项式来近似g(ψ),从文献[15]推导得出近似函数,如式(9)所示:
(9)
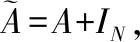
(10)
两层的图卷积网络为:
(11)
(12)
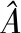
(13)
将除softmax外的操作进行可视化分解,以便于理解,其模型示意图如图5所示,其中H(1)表示神经网络隐藏层向量,H(2)为输出结果.
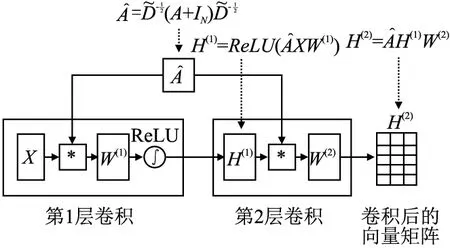
图5 GCN模块示意图Fig.5 GCN model schematic diagram
通过引入一阶切比雪夫多项式近似,使原先的全局卷积变成局部卷积,即将距离中心节点1跳的节点作为邻居节点.
正是因为GCN拥有这样的特性,本文将构建的特殊知识图谱模型中项目(项目名称)节点作为中心节点,将标的信息、中标单位名称、中标单位地址节点以及经营范围文本作为邻居节点.然后通过每一次迭代,GCN模型都会聚合邻居节点的特征信息到中心节点,这样即可以丰富中心节点的语义信息,又避免了每次迭代都需要重新计算并更新整个图的卷积核参数,降低了计算复杂度.
通过将特征矩阵经过两层图卷积操作,最终将得到的向量矩阵形式的卷积结果输出到输出层.
3.3.5 输出层
将上一层的结果通过softmax函数输出为n个节点的类别标签,Yi表示节点i(i =1,2,3,…,n)的类别标签,该层输入是图卷积层的卷积结果,输出的是待分类节点的类别标签,如式(14)所示:
Z=softmax(H(2))
(14)
如图6所示,H(2)是输出层的输入,Z是分类结果.
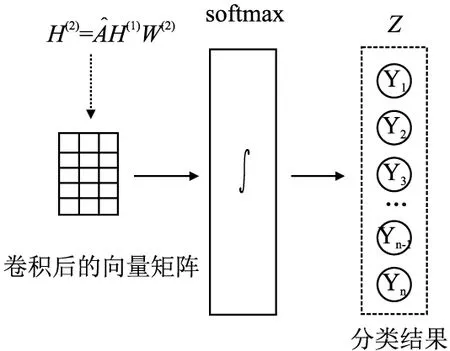
图6 输出层示意图Fig.6 Output output layer
对于本文的半监督节点分类,模型利用已标记样本来评估交叉熵损失函数:
(15)
其中YL是具有标签节点的索引集合,并采用Adam优化器,通过梯度下降来训练神经网络的权值W(1)与W(2).最终经过多次迭代后,利用softmax函数对卷积结果进行分类,最终得到所有待分类节点的类别标签.
通过图卷积分类,本文实现了对多源异构知识图谱中项目中心节点的半监督分类.
4 实 验
4.1 数据集
实验部分本文选择了两种数据集,Cora[20]数据集以及招投标文件数据集.
Cora数据集是一个由机器学习相关的论文组成[21]的引用网络.每篇论文都被划分到一个特定的类,其中存在的类有:基于案例、遗传算法、神经网络、概率方法、强化学习、规则学习和理论.
招投标文件数据集是从中国政府采购网等30个政府采购网站上爬取的招投标文件信息,手工构造分类数据集.在对原数据进行清洗筛选后,选取其中36123条结构完整的招投标文件数据进行实验.分类标准选取广东省政府采购网的品名类别标准,将招投标文件分为40类.
4.2 评测标准
实验采用准确率(Accuracy)来评估分类的结果,准确率定义如公式(16)所示:
(16)
其中,numcor表示样本分类结果中正确预测的文本总数,numall表示数据集总共的样本总数.评估指标acc表示了模型在数据集中预测正确样本类别的百分比,准确率acc越高的模型,性能越好.
4.3 对比实验设置
本文设置以下3部分对比试验,第1部分分别对Cora基准数据集进行传统机器学习的有监督分类实验,和基于图卷积神经网络的半监督分类实验.
第2部分对招投标文件数据集进行实验,将数据不构建知识图谱而是将每条数据的各部分文本进行字符串的拼接,然后分别采用传统机器学习、深度学习和基于Bert的分类方法对招投标文本进行分类.机器学习采用逻辑回归、支持向量机、K近邻和随机森林的分类方法,深度学习采用卷积神经网络,基于Bert的分类方法采用Bert预训练模型对拼接文本进行特征表示,再通过全连接层Softmax函数进行分类.并且为了保证实验的可对比性,在机器学习的分类方法中,采取和本文提出模型一样的特征工程方法,即TF-IDF+SVD.
第3部分是在构建知识图谱后,不对其进行外部文本信息的特征补充,直接利用GCN进行半监督分类.
第2、第3部分的对比实验与本文提出的BD-GCN模型实验采用相同标记样本数据做模型的训练.
4.4 实验结果与分析
在Cora数据集实验中,有监督实验模块,用1900条做训练集,其余做测试集;在GCN半监督实验模块,140条数据做训练集,400条做验证集,1000条做测试集.
在招投标文件数据集实验中,手工标记1000条样本,其中每类招投标文件至少标记了10条,其中训练集700条,测试集300条,实际进入模型训练的样本数为36123.利用GCN进行半监督分类时,学习率设为0.05,权重衰减设为5e-4,迭代次数设置为300次.
实验结果如表5、表6所示.

表5 Cora数据集实验结果Table 5 Cora dataset experimental results
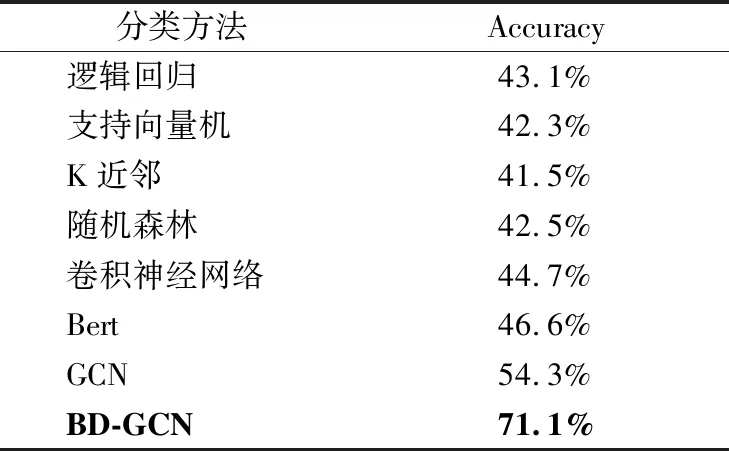
表6 招投标文件数据集分类实验结果Table 6 Experimental results of dataset of bidding documents
表5结果表明,GCN模型在有些分类任务上优于传统机器学习方法,因为模型利用了图结构和节点间的关系,通过在网络中逐层学习,更好的表示了节点特征,同时仅利用少量标记数据,就能实现很好的分类效果,实验结果验证了GCN在半监督分类任务上的可行性和有效性.
表6中显示了8组模型对比结果.从评价指标Accuracy上来看,本文提出的BD-GCN模型优于其他,准确率达到了71.1%.传统机器学习对于特征工程的要求较高;卷积神经网络则需要大量高质量的标记样本;Bert预训练模型训练预料来源于公共领域,对招投标领域内文本表征效果欠佳;而未经过外部文本信息补充的知识图谱在利用GCN进行半监督分类时会因语义特征不足而影响分类结果.因此本文提出的模型能有效提高招投标文件的分类准确率.
5 结 论
本文提出的基于图卷积神经网络的半监督招投标文件分类方法(BD-GCN),通过将数据构建成知识图谱,让多条数据之间产生联系,使非结构文本结构化清晰化,并且利用外部信息对待分类节点进行特征补充,从而弥补短文本构建的知识图谱语义信息不足的缺点.另外模型对节点的特征提取要求不高,可利用图卷积神经网络对中心节点聚合邻居节点信息,使待分类节点更好的得到表征,拥有更加丰富的特征信息.同时只需要少量的标记样本就能使大量的数据进入模型进行训练.实验结果表明,模型有效提高了分类准确率.在未来的工作中,本文将进一步研究图神经网络,并引入注意力机制与关系权重来提高模型分类的准确率.
