最后期限动态分配的三步云工作流调度算法
2023-02-17王子健卢政昊潘纪奎孙福权
王子健,卢政昊,2,潘纪奎,2,孙福权
1(东北大学秦皇岛分校 数学与统计学院,河北 秦皇岛 066000)2(东北大学 信息科学与工程学院,沈阳 110000)
1 引 言
工作流经常被用于生物信息学、天文学和物理学等大规模建模科学问题[1].一个工作流中通常包含成百上千个具有依赖关系的计算任务,一般被描述成有向无环图(DAG).工作流调度的目的是找到最合适的资源来执行工作流中的每一个任务,同时满足服务质量(QoS)约束[2].随着云计算的兴起,云环境成为了执行工作流的新平台.云工作流调度变得越来越流行,越来越有前景[3].云环境可以被当成一个“无限的”资源池,其中包含各种类型的资源.为了执行工作流,用户通常基于按次付费的模式租用云资源[4].一般来说,资源性能越高,执行任务的速度越快,同时价格也越昂贵.因此云工作流调度需要同时考虑执行成本和完工时间.一种常见的形式是在满足最后期限约束的前提下最小化执行成本,这是一个已知的NP难问题[5].这一问题多年来一直是分布式计算社区的热点[6].
列表调度算法被广泛用来解决工作流调度问题.它通常包含两个步骤:根据预先定义的启发式信息设置任务的优先级并依据优先级构建一个调度列表;依次为调度列表中的任务分配合适的资源.为解决云工作流调度问题,有些研究[7]在两步列表调度之前先进行了最后期限的分配,从而形成三步列表调度.整个工作流的最后期限被分配到每个子任务上,形成每个任务的子期限.之后按照两步列表调度算法的方式进行资源的分配,确保每个任务在不超过其子期限的前提下配置上最廉价的资源.实验数据表明,这种三步列表调度算法的效果要优于两步列表调度算法.
然而现有的最后期限分配策略均只能形成静态的子期限,因此还可以进行进一步的优化.本文采用三步列表调度算法进行云工作流调度,并提出一种基于粒子群的动态最后期限分配方法(DY-DD).实验结果表明,相比于其它经典调度算法,本文提出的算法在成功率和执行成本上均具有优势.
2 相关研究
工作流调度问题最初聚焦于多处理器系统[8]和阵列系统[9].由于这类系统通常提供数量有限且容量确定的资源,同时资源可免费使用,因此传统工作流调度的主要目标是最小化工作流执行时间,从而以尽力而为的方式为用户提供服务.列表调度算法被广泛用于解决此类问题,例如EFT[10]、HEFT[11]、CPOP[11]、PEFT[12].它们通常为每个任务计算启发式信息,并根据启发式信息构建一个调度列表.之后为列表中的每一个任务分配合适资源使得任务可以尽早开始执行.
云计算的兴起使得云环境成为执行工作流的新平台,也使得云工作流调度成为新的研究课题.云工作流调度通常需要同时进行多个目标的优化,例如同时优化工作流的完工时间和执行成本.通常的做法是将其中一个目标作为主要优化对象,同时满足其它目标的约束.例如在满足最后期限约束的前提下最小化执行成本.这一问题是已知的NP难问题且求解过程很容易陷入局部最优,因此大量元启发式算法被用来解决这一问题.文献[13]利用了遗传算法、文献[14,15]基于粒子群算法、文献[16]基于蚁群算法.文献[17]则在传统粒子群算法的基础上进行了改进,提出了免疫粒子群算法.该算法改善了粒子群算法的收敛速度,从而提高了算法的质量.文献[18]在使用粒子群算法的同时考虑了同一个资源实例下顺序执行的任务间存在的空闲时隙,并加以利用.然而以上这些元启发式算法都只着重解决任务与资源间的映射,忽视了工作流执行时各任务需要满足的子期限.
列表调度算法同样用于解决云工作流调度问题.有些文献在传统列表调度算法的基础上新增了最后期限分配这一步骤.最后期限首先被分配给工作流中的每个任务,从而形成子期限.之后利用列表调度算法为每个子任务分配合适的资源.分配资源时确保每个任务满足子期限且执行成本最优.例如文献[7]提出的ProLis、文献[19]提出的DCO/DUCO和文献[20]的HAS都根据自定义的启发式信息进行最后期限的分配.文献[21]提出的LBWS则根据任务节点在工作流图中所处的层级进行最后期限的分配.尽管上述文献均可以获得不错的调度结果,但是这些算法都只针对每个任务生成了静态子期限,因此还可以进行进一步的优化.
除此之外还有一些文献利用了分治的思想进行工作流调度.他们的目的也同本文一致,即满足最后期限约束最小化执行成本.例如文献[22]提出的PCP算法利用了关键路径的概念.算法首先找到工作流图中的关键路径,并将最后期限分配给每一个关键任务(位于关键路径上的任务).之后再以每个关键任务为终点继续反向查找关键路径并分配最后期限.文献[23]在此基础上提出了IC-PCP算法.该算法与PCP具有类似的关键路径查找方案,但不进行最后期限的分配,取而代之的是直接进行服务资源的配置.文献[24]则进一步利用了这种分治的思想,文献中提出的DQWS算法在找到关键路径后会直接将其从工作流图中删除,从而将原工作流一分为二.之后递归执行此过程,直至每个子图均只包含一条单任务链.以上算法有些虽然也使用了最后期限分配策略,但也均只形成了静态子期限,没有对分配的子期限进行局部调优.
3 问题描述
3.1 工作流模型
一个工作流可以用有向无环图DAG=(V,E)来表示.V={t1,t2,…,tn}是有向无环图中节点的集合,每一个节点都代表一个任务,一个任务也可以被理解成一段独立的且不能被并行执行程序.对于一个给定的任务ti,可以用wi代表该任务的计算量.E是有向无环图中边的集合.E中的一条边eij={ti,tj}代表了任务ti和tj之间的一种依赖关系,即任务tj只能在任务ti执行结束后才能开始执行.此时ti和tj被分别被称为父任务和子任务.若一个任务没有父任务,则称之为起始任务,若一个任务没有子任务则称之为终止任务.如果任务之间存在数据传输,则需要为eij添加一个属性dataij来代表由ti到tj的数据传输量.此时任务tj只能在ti执行结束且完成数据传输后才开始执行.有些工作流可能同时拥有多个起始节点或终止节点,大多数调度算法并不适用于这种情况.为了一般化工作流模型,可以在工作流的开始处和结束处分别添加了两个负载为零且不传输任何数据的虚拟任务tentry和texit.图1展示了一个工作流示例.
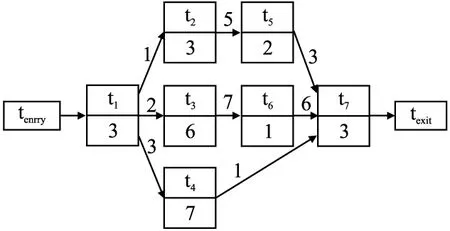
图1 工作流示例图Fig.1 Example of workflow
3.2 云资源模型
云平台中的各类资源被虚拟化为资源池以便进行统一的管理并以租赁的方式为云使用者提供服务.用R={r1,r2,…,rn} 代表云使用者可租用的资源类型的集合.不同类型的资源拥有不同的处理能力和租赁费用.通常处理能力越强的资源,其租赁费用也越昂贵.vmk代表云使用者租用的一个具体的资源实例或虚拟机.虚拟机是工作流中任务的执行平台.工作流中的一个任务只能被调度到唯一的一个虚拟机上执行,而一个虚拟机可以顺序的执行一组任务.Tp(vmk)代表vmk的资源类型,因此Tp(vmk)∈R.P(rl)代表l类资源的处理能力,因此vmk的处理能力为P(Tp(vmk)).本文采用的定价方式为即付即用模式,即根据虚拟机被租用的单元时间数量来进行收费.当租用的虚拟机没有使用完一个完整的单元时间时,也会按照一个单元时长的费用对其进行收费.如图2所示,虚拟机的单元时长设置为T,虚拟机在0时刻被租赁,3.2T时刻被释放,那么用户需支付4个单元时间的开销.UC(rl)代表l类资源单位时长所需要的租用费用,因此租用vmk一个单位时长所需要承担的租赁费用为UC(Tp(vmk)).
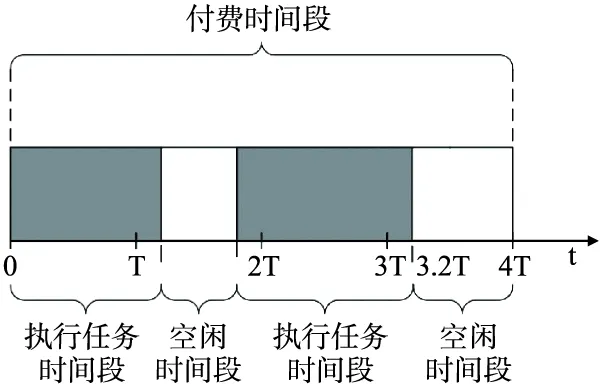
图2 付费时间段示例图Fig.2 Example of a paid time period
假设任务ti被安排到虚拟机vmk上执行,则ti在vmk上的执行时长为:
(1)
本文假设所有虚拟机都位于相同的物理区域且虚拟机之间的平均带宽(bw)大致相等,同时虚拟机间数据传输是免费的.用TTi,j代表ti到tj的数据传输时长,则:
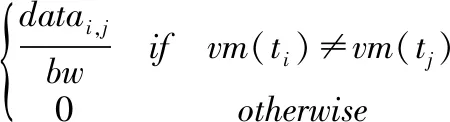
(2)
其中vm(ti)代表执行ti的虚拟机.当两个任务由同一个虚拟机执行时,它们之间的数据传输时长为0.
用STi,k代表任务ti在虚拟机vmk上的开始执行时刻,FTi,k代表任务ti在虚拟机vmk上的完成时刻,则:
(3)
FTi,k=STi,k+ETi,k
(4)
其中RTk代表vmk的空闲时刻,即vmk上排列在ti之前的任务的完成时刻.也可以理解为vmk可执行ti的最早时刻.若ti是vmk上的第一个任务,则为的启动完成时刻.
分别用LSTk和LFTk代表虚拟机vmk的开始租用时刻和租用结束时刻.LSTk为虚拟机vmk上的第一个任务开始接收数据的时刻,LFTk为vmk上最后一个任务完成数据传输的时刻.公式(5)给出了vmk的租用费用.
ECk=「(LFTk-LSTk/TI)⎤×UC(T(vmk))
(5)
3.3 调度模型
调度的目的是将工作流中的任务分配到具体的虚拟机中并按照既定的顺序执行.一次调度的结果可以被描述为
(6)
(7)
若一个已知工作流给出的最后期限为D,则工作流调度问题可描述为:
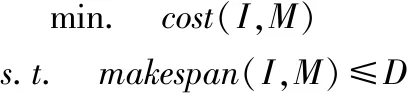
(8)
4 算法设计
本文所解决的调度问题中,一个关键点在于如何确定每个任务的子期限.这个问题的求解空间维度高、范围广且连续.粒子群算法是一种随机优化技术,每个粒子的本质是一个多维向量,整个算法通过渐进式的计算进行求解,从而得到最优的粒子.这种算法自问世来一直被广泛的研究和应用.粒子群算法的特点非常适用于解决本文所面对的问题.这一部分提出了基于粒子群的动态最后期限分配方法及相应的列表调度算法.
4.1 t-level,b-level,alap
在应用列表调度算法时,一个任务的t-level、b-level、alap经常被计算[8].使用tli、bli和alapi分别代表任务ti的t-level、b-level、alap值,计算方式如公式(9)~公式(11)所示:
(9)
(10)
(11)
一个任务ti的t-level值等于从入口节点tentry到ti的最长距离,它关系到任务ti最早何时可以开始执行.b-level值等于从ti到tentry的最长距离.alap值代表了在不影响整个工作流关键路径长度的前提下,任务ti的开始执行时间可拖延到何时.在计算这些值时,每个任务的执行时长ETi必须已知.然而在实际情况中,任务的执行时长与分配得到的虚拟机类型有关,因此只能在调度结束后才能精确计算.本文采用了一种近似计算的方法来计算一个任务的执行时长,如公式(12)所示:
(12)
其中,r*代表云平台能够提供的处理速度最快的虚拟机类型.通过此种方法可以在工作流开始调度之前计算出每个任务的t-level值,b-level值和alap值.
4.2 粒子群算法
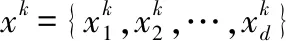
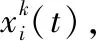
(13)
(14)
(15)
(16)
参数w为惯性系数,取随机数.c1和c2为加速系数.r1和r2为随机数.
4.3 基于粒子群算法的DY-DD
三步列表调度是非常有效的云工作流的调度算法.这种调度算法通常先进行最后期限的分配,即将整个工作流的最后期限D分配给每一个任务.通过分配,任务ti会得到一个子期限sdi.之后需要对所有任务进行拓扑排序,从而得到一个任务队列L.最后依次为队列中的每一个任务配置虚拟机.配置的虚拟机尽量保证任务在子期限前执行完成且执行成本最小.本文提出的动态最后期限分配方法(DY-DD)将粒子群算法应用于最后期限分配阶段.为了能够使用粒子群算法,本文所提出的算法对三步列表调度的执行步骤进行了改变.首先对任务进行拓扑排序生成队列L,之后利用粒子群算法找到近似最优的最后期限分配结果,最后进行虚拟机的配置.
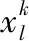
(17)
其中fi代表对粒子xi进行虚拟机配置后的最终调度结果,fj代表对粒子xj进行虚拟机配置后的最终调度结果.若两种调度方案的完工时间均满足最后期限则执行费用小的方案较优,否则完工时间小的方案较优.
为了将粒子的移动控制在合理的空间范围内,需要对粒子各分量的最大值和最小值进行设置.一个简单的思路是将所有分量的最大值设置为D,最小值设置为0.这是因为所有任务的子期限最晚也不会超过整个工作流的最后期限,最早也不会早于0.然而由于搜索空间过大,这种设置方式会影响粒子群算法的性能.根据4.1节的介绍可知,任务ti开始执行的时间不会早于tli,最晚开始时间也不应当晚于alapi,因此将粒子的最大值和最小值设置为:
(18)
(19)
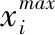
(20)
(21)
为了加速粒子群收敛,本文设置了t=0时刻的全局最优解,设置方式如公式(22)所示:
(22)
算法1给出了动态最后期限分配方法的详细描述.算法的输入是一个代表工作流的DAG,输出是调度的结果.算法首先按照b_level降序顺序对所有任务进行拓扑排序(第1行).之后初始化粒子群算法的相关参数和粒子并设置局部最优位置及全局最优位置(第2-3行).接下来启动粒子群算法(第4-12行).每一个粒子都需要利用虚拟机选择算法(算法2)进行解码,生成最终解决方案(第8行).利用公式(17)可以对生成的解决方案进行比较,从而更新局部最优位置和全局最位置(第9和11行).粒子群迭代结束后,算法返回由全局最优位置解码得到的解决方案,这也是整个算法计算出的最终调度方案(第13-14行).
算法 1.动态最后期限分配方法(DY-DD)
输入:TheDAGofaworkflowG=
输出:TheschedulingsolutionS=
1.L←listedtasksofworkflowindescendingorderbyb_level
2.Setparametersofpsoand set global best position gb
3.Initialize the population and set local best position lb of each particle
4.Whileitdoesn′tmeetiterationconditiondo
5.Foreach particlexk,k∈{1,2,…,size}do
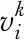
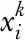
8.DecodexktoasolutionSkbyAlgorithm 2accordingtotheorderofL
9.Updatethelocalbestpositionlbkofxk
10.Endfor
11.Updatetheglobalbestpositiongb
12.Endwhile
13.DecodegbtoasolutionSbyAlgorithm2accordingtotheorderofL
14.ReturnthesolutionS
粒子通过虚拟机选择算法进行解码.算法的详细描述如算法2所示,此算法参考了ProLis的服务选择算法.算法2的输入包括一个任务列表L和一个具体的粒子x,输出是由x解码得到的一个调度方案.L是拓扑排序后的任务列表,x代表L中每个任务的子期限.算法需要为L中的每一个任务选择虚拟机,原则是满足任务的子期限且执行成本的增量最小(第3行).候选的虚拟就包括所有已选择的虚拟机(集合I)以及尚未被选择但是可以随时被添加到I中的虚拟机.如果所有虚拟机均不能满足一个任务的子期限,则将该任务配置到能使其最早完成的虚拟机中,并将此虚拟机升级为执行速度最快的类型(第4-10行).至此虚拟机选择完毕,计算任务的开始执行时刻和执行完成时刻并生成分配方案(11-15行).直到所有的任务均配置好虚拟机后返回最终的调度结果(第17行).
算法 2.虚拟机选择算法
输入:AtasklistL
Aparticlex
输出:TheschedulingsolutionS=
1.I←φ,M←φ
2.ForeachtasktiinLdo
3.vmk←selectavmthatmeetsxiandminimizesthecostincrementofaddingti
4.Ifvmkisnullthen
5.vmk←selectavmwhichallowsearliestfinishtime
6.Whilexiisnotmet&&vmkisnotofthefastesttypedo
7.upgradethetypeofvmktoafasterlevel
8.updatefinishtimeoftasksonvmk
9.Endwhile
10.Endif
11.CalculateSTi,k,FTi,kby(3)and(4),respectively
12.M←M∪ {
13.Ifvmk∉Ithen
14.I←I∪{vmk}
15.Endif
16.Endfor
17.Return
5 仿真实验
5.1 实验设置
这一部分将对实验的设置进行介绍.本文通过仿真的方式对提出的算法进行了验证.仿真程序利用了文献[7]所提供的开源程序,并在此基础上嵌入了本文所提出的算法的源代码.
本文选取了4种不同特点的工作流模型,它们分别是:CyberShake、Epigenomics、LIGO、Montage.这些工作流各具特色,图3展示了这些工作流的结构特点,更具体的描述可以参看文献[25].一般来说CyberShake用于刻画地震灾害,属于数据密集型工作流,且需要大量的CPU资源; Epigenomics被应用于信息生物学,本质上是一个数据处理管道,用来自动执行各种各样的基因组排序操作;LIGO主要应用于引力物理学,属于CPU密集型工作流;Montage被应用于天文学,任务间存在大量的I/O,CPU资源需求不高.工作流由Bharathi等人提供的工作流生成器生成.每个工作流模型下分别选择了50个任务、100个任务、200个任务、…、900个任务、1000个任务等不同规模的工作流进行实验.为了减小随机性对实验结果造成的影响,每类模型相同规模的工作流使用了20中不同的实例.

图3 4种工作流的结构特征Fig.3 Structural characteristics of the four workflows
在实验中,假设云平台中包含9种不同类型的虚拟机,它们都拥有各自的处理能力和租用费用,详见表1.由于工作流数据集中任务工作量被刻画成了在标准计算资源上的运行时间而不是工作负载,因此这些虚拟机的处理能力被刻画为标准计算资源处理速度的倍数.虚拟机之间的带宽被设置为20MBps,虚拟机租用付费的单元时长设置为1小时,这些设置都参考了Amazon EC2.
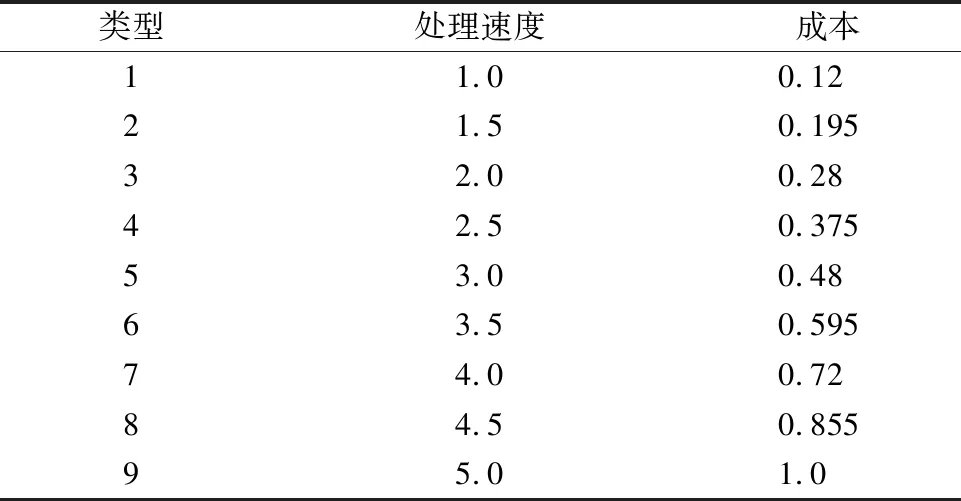
表1 可用服务类型的处理速度和成本Table 1 Processing speed and cost of available service types
为了对本文所提出的算法做出评估,选择了IC-PCP[26]和ProLis[7]作为了对比算法.IC-PCP是经典的满足最后期限约束的工作流调度算法.ProLis是典型的三步列表调度算法,此算法在列表调度的基础上应用了最后期限的分配.
本文使用调度成功率和执行成本两个指标对算法进行评价.成功率越高且执行成本越低的算法效果越好.调度算法的结果经常受到最后期限设置的影响.过于紧张的最后期限会使得调度成功率降低且执行成本增高,宽松的最后期限则与之相反.为了对算法做出更为全面的评价,需要在不同的最后期限设置下对算法进行验证,为此引入了两个基准:
1)廉价调度:仅在一台最廉价的虚拟机上使用HEFT[11]算法进行工作流调度.Mc和Cc分别代表廉价调度的完工时间和执行成本.
2)快速调度:仅选择最昂贵的虚拟机进行工作流调度,调度算法为HEFT[11].Mf和Cf分别代表快速调度的完工时间和执行成本.
另外引入λ(λ∈ [0,1])作为最后期限的宽松程度,并将最后期限表示为:
D=MF+(MC-MF)×λ
(23)
由于最后期限由λ确定,因此可以通过设置不同的λ值来观察不同宽松程度下各工作流调度算法的表现.
参与实验的工作流均具有不同的属性,如任务数、任务负载值、数据传输量等,这必然导致调度结果的执行成本值千差万别.对于一个工作流,使用执行成本除以Cc的方式对结果进行标准化处理.
由于计算量很大,整个实验过程使用了56台PC机共同完成.不同的PC机负责计算不同工作流模型和最后期限设置.最后汇总各PC机的计算结果并生成相应的图表.表2给出了算法相关参数的设置方式.

表2 参数设置Table 2 Parameter settings
5.2 实验结果
在进行实验时先另λ从0.005变化至0.05,步长为0.005;又另λ从0.1变化至0.5,步长为0.05.前者用以观察在相对紧张的最后期限设置下各算法表现,后者则用以观察在相对宽松的最后期限设置下各算法表现.图4给出了λ从0.005变化至0.05时各算法平均成功率.
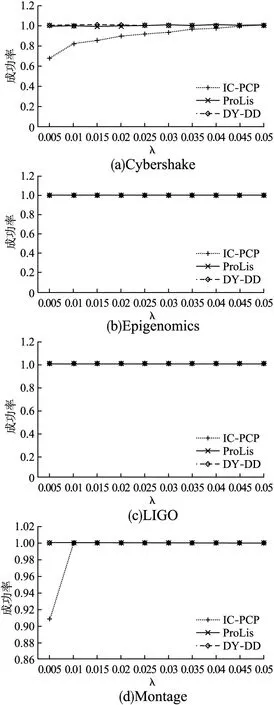
图4 不同λ时每种方法的成功率Fig.4 Success rate of each method at different λ
由实验结果可知,算法的平均成功率均会随着λ的增大而增加.设置相对较宽松的最后期限显然可以使算法更容易找到满足约束条件的解决方案.ProLis和DY-DD几乎在所有情况下都能成功的找到解决方案.IC-PCP在Epigenomics和LIGO两个模型下表现的十分出色;在Montage模型下,当λ为0.005时其成功率约为91%;在CyberShake下表现的最差,当λ为0.005时其成功率仅有68%.不过随着λ的增加,IC-PCP的成功率会逐渐提升,直到λ等于0.045时,其成功率会趋近100%.
图5给出了λ从0.005变化至0.05时各算法的标准化执行成本.由于在不满足截止时间约束的情况下比较成本是没有意义的,因此图5只给出了成功率近似100%的情形下个算法的执行成本情况.
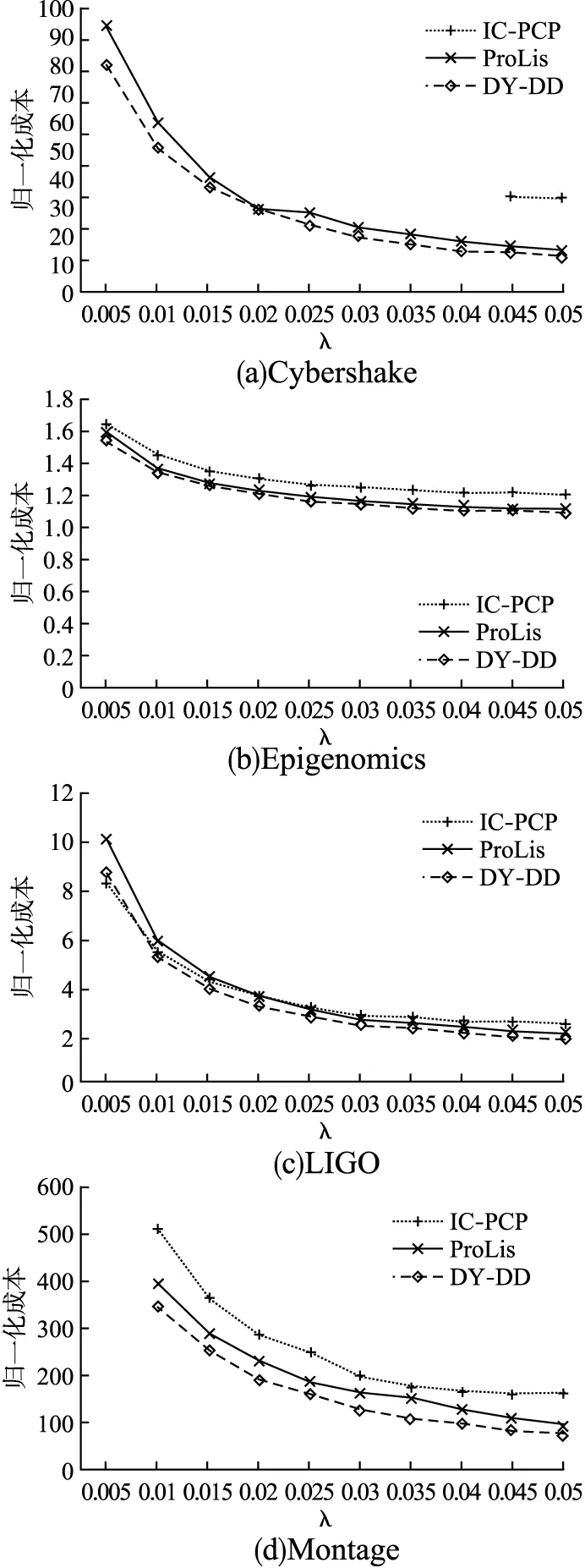
图5 不同λ时每种方法的成本(0.005< λ< 0.05)Fig.5 Cost of each method when 0.005< λ< 0.05
由实验结果可知,IC-PCP在LIGO模型下λ为0.005时表现的最为出色,除此之外的其它情形下表现最好的均为DY-DD.ProLis在大多数情况下都优于IC-PCP,但是相比于DY-DD一直存在劣势.
图6给出了λ从0.1变化至0.5时各算法的标准化执行成本.由实验结果可知,在相对宽松的最后期限设置下,ProLis和DY-DD具有明显的优势.在大多数情况下DY-DD均优于ProLis,仅在Montage下且λ大于0.4时两者的结果才相差无几.
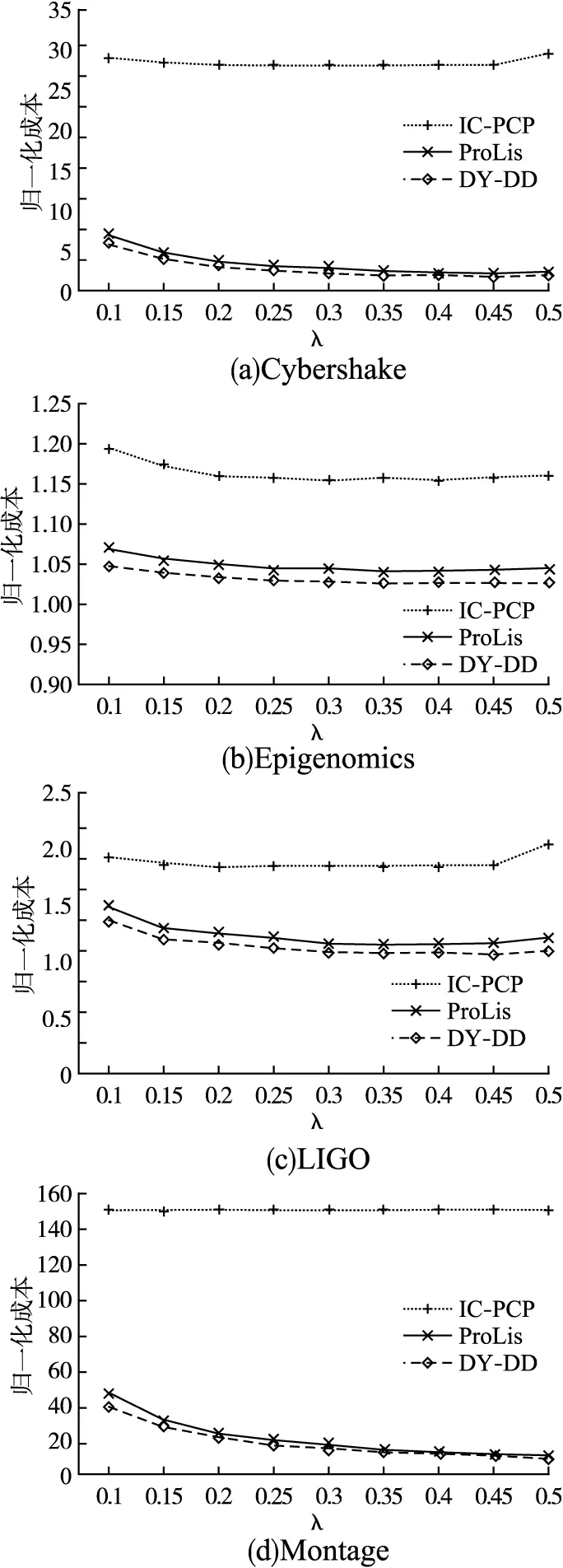
图6 不同λ时每种方法的成本(0.1< λ< 0.5)Fig.6 Cost of each method when 0.1< λ< 0.5
5.3 算法时间复杂度分析
DY-DD算法首先需要生成调度列表(算法1第1行).其中为每个任务计算b-level的过程需要遍历所有任务和任务间的依赖.对于一个包含n个任务的工作流,其依赖最多为n×(n+1)/2.因此整个计算过程的时间复杂度为O(n2).排序过程的时间复杂度为O(n×logn).之后需要初始化粒子群(算法1第2-3行),这一过程需要设置初始的最优粒子和设置粒子的速度上下限.设置速度上下限时需要利用t-level和alap,它们的计算方式与b-level类似,因此需要O(n2)的时间复杂度.设置最优粒子需要遍历粒子的每一个维度,即遍历每一个任务,因此时间复杂度为O(n).初始化粒子也需要遍历粒子的每一个维度,若粒子群的粒子数量为SIZE,则这一过程的时间复杂度为O(SIZE×n),其中SIZE为常数.对于某一次迭代,更新某一个粒子的速度、位置和局部最优解(算法1第6-7行、算法1第9行)的时间复杂度为O(n).对粒子进行解码(算法1第8行)需要利用算法2,算法2需要遍历每个粒子维度,即每一个任务,并为每一个任务选择一个合适的虚拟机.若云平台提供的虚拟机类型数量N,则每次选择所需要遍历的虚拟机数量为n+N,因此算法2的时间复杂度为O(n×(n+N)),其中N为常数.若粒子群的迭代次数上限为T,则整个迭代阶段(算法1第4-12行)的时间复杂度为O(T×SIZE×(n+n×(n+N))),其时间复杂度约为O(n2).由此得出整个算法的时间复杂度为O(n2).
6 结束语
本文提出了DY-DD算法.该算法主要解决云工作流的调度问题.对于一个给定的工作流、最后期限约束和云模型,使用该算法可以找到满足最后期限约束的调度方案且优化了执行成本.使用现实的数据进行了实验仿真,并与经典的调度算法进行了对比.实验结果表明,DY-DD算法在成功率和执行成本上很有竞争力.
接下来一方面试图改进本文提出的算法,降低算法的复杂度;另一方面也尝试使用其它方式解决本文所研究的问题.除此之外,还将聚焦于多目标的工作流调度.
