基于Fork/Join的事务日志伴随模式挖掘方法
2023-02-17冉义兵毕国鹏
孔 明,魏 东,2,冉义兵,毕国鹏
1(北京建筑大学 电气与信息工程学院,北京 100044)2(北京市科学技术委员会 建筑大数据智能处理方法研究北京市重点实验室,北京 100044)3(北京声讯电子股份有限公司,北京 100094)
1 引 言
随着信息网络的快速发展和信息技术的广泛应用,客户关系管理系统、电子商务系统、监控系统等各类信息系统得以部署,从这些系统中可以获取大量的事务日志.事务日志一般包括活动内容、执行时间、参与者等信息[1].通过对日志信息进行挖掘,可以发现在给定时间段内经常共同出现在同一地点的对象(用户、车辆、人群等),而这些在时空上频繁共现的对象,即为伴随模式.伴随模式通常蕴含着事物间潜在的关系,因此伴随模式的挖掘被广泛应用于各类信息系统中.例如,利用学生卡管理系统的刷卡数据推断学生的时空共现,有利于构建和分析真实社会网络[1];在车辆智能监测记录系统的过车数据中挖掘伴随车辆,有利于公安部门搜寻有结伴作案的嫌疑车辆[2];基于移动通信基站IP数据的伴随人员推荐,有利于移动运营商向潜在的用户推荐服务;基于用户位置签到数据的伴随人群发现,有利于解决所在签到地点的资源配置和规划决策问题[3].
现有伴随模式可分为轨迹伴随模式和频繁伴随模式,轨迹伴随模式是指在设定的时间长度阈值上,具有相同或相似运动轨迹的移动对象群体;频繁伴随模式是指在设定时间内频繁出现在多个不同数据流上的一组对象[4].伴随模式挖掘方法可分为轨迹相似度算法和关联规则算法.
轨迹相似性算法一般用于挖掘轨迹伴随模式,该算法通过构建对象的移动序列,求得对象之间移动轨迹的最长公共子序列,当最长公共子序列的长度达到设定阈值,则判定这些对象存在伴随关系.赵新勇等[5]提出了基于车牌自动识别数据的最长公共子序列算法,以实现伴随车辆的检测和识别;Zheng等[6]提出了一种基于密度聚类的伴随模式挖掘算法,用于发现蕴含在轨迹数据中的伴随模式;SHEIN等[7]提出了一种微聚类算法用于发现轨迹数据流中的松散伴随模式.然而,轨迹相似度算法需要事先指定待比对的对象,才能通过其轨迹数据找出与其存在伴随关系的其他对象.若挖掘数据中所有的伴随模式,轨迹相似度算法会耗费大量的时间.
关联规则算法一般用于挖掘频繁伴随模式,相比轨迹相似度算法,关联规则算法能够高效地挖掘出数据中所有的伴随模式[8],它将一定时间范围内一起出现的对象集作为事务集(伴随数据集),通过所设定的支持度阈值,挖掘出存在伴随关系的频繁项集.常用的频繁伴随模式挖掘方法主要是利用滑动窗口或时间切片方法,来划定伴随数据集,再运用关联规则算法挖掘出伴随模式.王齐童等[9]提出了基于时空数据的滑动窗口方法用于划定伴随数据集,并将剪枝算法、贪心算法与Apriori 技术相结合,对移动对象的伴随模式进行挖掘;朱美玲等[10]提出了基于车牌识别流数据的PlatoonFinder算法来挖掘伴随车辆,其中利用了滑动窗口划定伴随数据集;Liu等[11]采用滑动窗口划定伴随数据集,并利用改进SeqStream算法挖掘伴随车辆;陈瑶等[12]通过时间切片划定伴随数据集,并基于Spark计算框架的矩阵剪枝频繁项集挖掘算法发现伴随车辆;刘惠惠等[8]通过时间切片划定伴随数据集,基于Spark计算框架的FP-Growth算法挖掘伴随车辆.此外,还有学者采用聚类算法划定伴随数据集.YAO等[13]采用DBSCAN算法对轨迹数据进行聚类,然后利用FP-Growth算法挖掘蕴含在轨迹数据的伴随模式;YAO等[14]采用HDBSCAN算法,解决了传统DBSCAN算法在处理密度不同的聚类问题时遇到的困难,再利用FP-Growth算法挖掘伴随模式.虽然上述学者在伴随模式挖掘方面取得了一些成果,但是现有划定伴随数据集的方法主要应用于轨迹数据,并非事务日志数据;而且上述成果尚未利用伴随模式挖掘结果生成关联规则,无法进一步获得和分析对象间潜在的关联关系.
事务日志是一种大规模的历史静态数据,由于传统串行的滑动窗口算法和FP-Growth算法只能调用单一线程进行计算,无法充分利用多核配置的加速性能,随着数据规模的扩张,会导致挖掘伴随模式的时间急剧增加.目前计算机技术的快速发展促进了多核处理器与并行计算框架的发展与应用,然而现有的Hadoop和Spark并行计算框架不够轻量,难以对串行的算法进行并行化改造,不利于应用的迁移和扩展[15],并且通信成本、负载平衡和I/O操作会导致运维费用较高[16].为此,本文在共享内存的多核平台上,提出一种基于事务日志的伴随模式挖掘框架,该框架以Java的并发性和Fork/Join并行计算技术为基础,包括划定伴随数据集、频繁项集挖掘和关联规则挖掘3部分.在划定伴随数据集部分,本文提出一种多核并行滑动窗口(parallel sliding window,PSW)算法,通过对事务日志数据库进行划分,能够并行地在各个子数据库上划定子伴随数据集.在频繁项集挖掘部分,本文提出一种多核并行FP-Growth(parallel FP-Growth,PFP-Growth)算法,能够并行地在各个子伴随数据集上构造FP树,从而缩短挖掘频繁项集的时间;在关联规则挖掘部分,本文利用支持度、置信度和提升度3个参数来挖掘伴随模式中的关联规则,目的是通过这些关联规则分析出对象间的关联关系和规律性.基于门禁刷卡数据的实验结果表明,相比传统算法,本文所提出的框架能够挖掘出更多的伴随模式,同时挖掘效率较高.
2 伴随模式挖掘框架
2.1 框架结构及问题描述
伴随模式挖掘框架结构如图1所示,由划定伴随数据集、频繁项集挖掘、关联规则挖掘3部分组成.
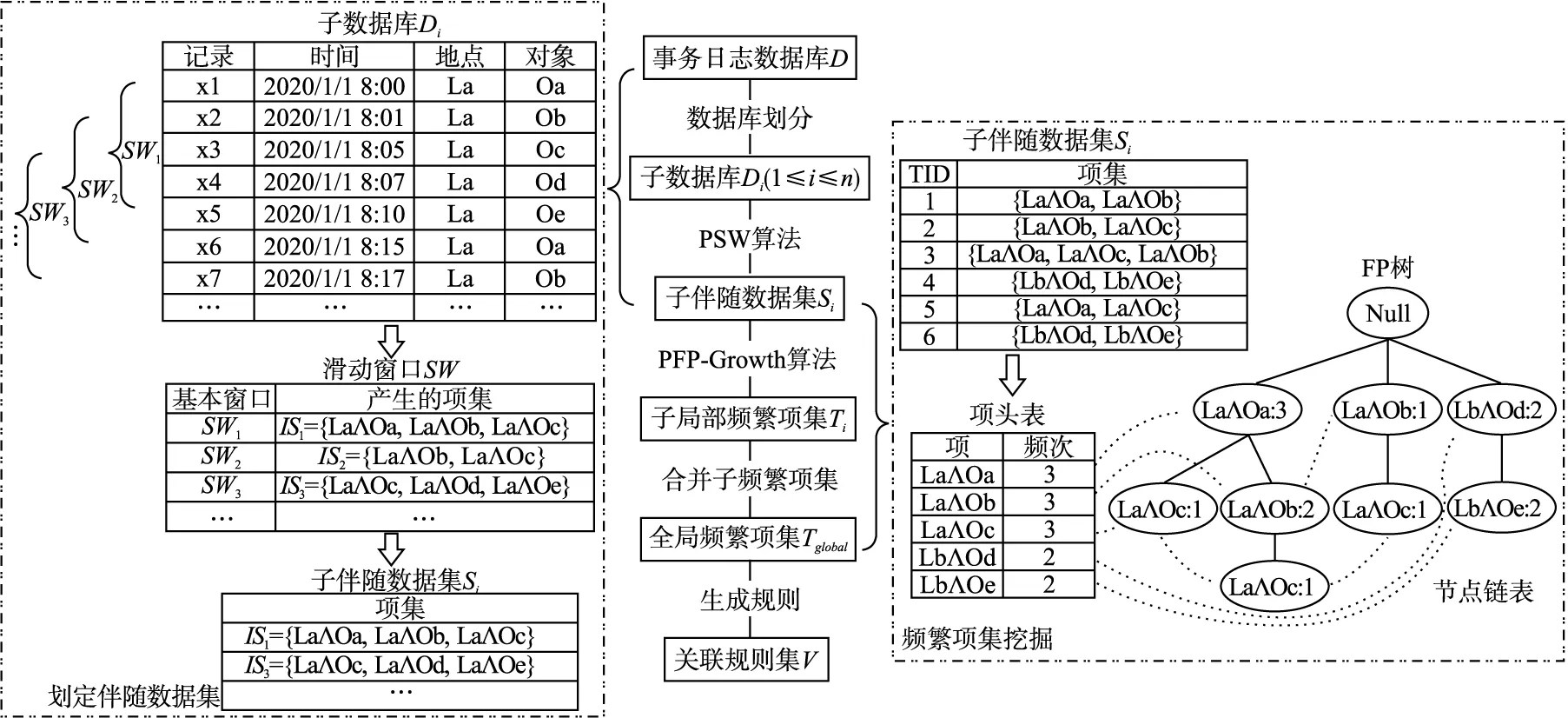
图1 伴随模式挖掘框架图Fig.1 Schematic illustration of the proposed co-occurrence pattern mining frame
在划定伴随数据集部分,本文首先将事务日志数据库D划分为n个子数据库D1,D2,…,Di,…,Dn(1≤i≤n).D中共包含h条事务日志记录,其中第j条事务日志记录可表示为:
xj={oj,lj,tj}(1≤j≤h)
(1)
式中,oj表示xj所记录的对象;lj表示oj所经过的监测点;tj表示oj经过lj的时间.
给定最大时间阈值λ,∀xu,xv∈Di,1≤u≤h,1≤v≤h,u≠v,若xu={ou,lu,tu},xv={ov,lv,tv}同时满足ou≠ov、lu=lv、|tu-tv|≤λ这3个条件,则称xu与xv在最大时间阈值内共同出现一次,即两者可能存在共现关系.
在此基础上,本文采用将Fork/Join并行技术与滑动窗口相结合的PSW算法,以高效地从D中划定出伴随数据集S:
S={S1,S2,…,Si,…,Sn}
(2)
式中,Si表示从Di中划定出的子伴随数据集,它由若干个存在共现关系的项集(item set)组成,项集IS可表示为:
IS={item1,item2,itemp,…,itemr} (2≤p≤r)
(3)
式中,itemp表示由地点lp与对象op组成的项(item),该项在Di中有唯一的事务日志记录xp={op,lp,tp}与之对应;r表示IS共包含项的个数.IS可重新表示为:
IS={l1∧o1,l2∧o2,lp∧op,…,lr∧or}
(l1=l2=lp=…=lr,o1≠o2≠op≠…≠or)
(4)
其中,∀itemp∈IS(p≠1),itemp={lp∧op}需满足|t1-tp|≤λ的条件.
在频繁项集挖掘部分,本文提出基于Fork/Join并行框架的PFP-Growth算法,该算法能够并行地从S中挖掘出局部频繁项集T:
T={T1,T2,…,Ti,…,Tn}
(5)
式中,Ti表示从Si中挖掘出的子局部频繁项集,它由若干个频繁项集(frequent itemset)组成.频繁项集是指Si中频繁出现的项集,其结构与IS的结构类似.若IS⊆Si,IS≠Ø并且IS满足式(6)的条件时,则将IS称为频繁项集.
support(IS)≥minSup
(6)
式中,support(IS)表示IS的支持度,即IS在Si中出现的频次,minSup表示绝对最小支持度阈值.
然后,本文通过合并Ti,得到全局频繁项集Tglobal,即所有的频繁k-项集.这些频繁k-项集,既满足伴随模式对两者以上的对象,在最大时间阈值内一起出现在同一地点的要求,又满足出现在伴随数据集S中的支持度不小于绝对最小支持度的条件,因此本文认为这些项集是伴随模式.
在关联规则挖掘部分,本文采用支持度、置信度和提升度3个参数,描述从Tglobal中挖掘的关联规则的有效性.关联规则集V由若干关联规则R组成,R可表示为:
R:A⟹B
(7)
式中,A表示规则的前件,B表示规则的后件,且A⊆IS,B⊆IS,A∩B=Ø,规则R表示当A中的对象出现时,B中的对象也将随之出现,有助于用户发现和分析蕴含在伴随模式中对象间潜在的关联关系.
2.2 Fork/Join并行技术
Fork/Join框架是Java提供的一个用于并行执行任务的轻量级框架,能够充分利用多核CPU性能,提高程序的运行效率.该框架便于学习和实现,可以简化开发人员编写并行程序的工作[17].
Fork/Join采用分治思想[18],通过递归分割大规模复杂的父任务,形成多个小规模简单的子任务;然后把各个子任务分配到不同的CPU线程中开始并行计算;最后合并所有子任务的执行结果,得到最终的任务结果.Fork/Join可以根据问题规模的阈值来控制子任务的计算规模,采用线程池对工作线程进行统一管理,避免因线程的多次创建和关闭造成资源被不断消耗的问题.图2为Fork/Join 框架并行计算原理.

图2 Fork/Join 框架并行计算原理Fig.2 Principles of Fork/Join parallel computing
工作窃取算法是Fork/Join框架中一种用来实现负载均衡、提高运算性能的方法,其实际上是一种工作任务的调度方法.它的基本思想是当一个线程把自身任务队列中全部任务执行完毕后,该线程会从其他未执行完毕的线程任务队列中窃取任务执行,避免线程处于闲置状态,从而能够保证负载均衡,提高CPU的利用率,减少程序的处理时间.
本文基于Fork/Join并行技术,采用Java语言编程实现了PSW和PFP-Growth算法,伪代码如下:
1.public class ParallelTask extends RecursiveAction{ //继承RecursiveAction类
2. @Override
3. protected void compute(){
4. if(end-start<=Threshold){//如果问题规模小于阈值
5. ComputePswPfp(start,end);}//执行子任务
6. else{
7. int pivot =(start + end)/2;//对半分解父任务
8. ParallelTask task1 = new ParallelTask(start,pivot,Threshold);
9. ParallelTask task2 = new ParallelTask(pivot,end,Threshold);
10. invokeAll(task1,task2);}}//子任务递归
11. public void ComputePswPfp(start,end){
12. for(int i = start;i <= end;i++){//i表示第i个子数据库
13. PSW(i);//从Di中划定子伴随数据集
14. PFP_Growth(i);}}//从Si中挖掘子频繁项集
15. public static void main(){
16. int n = 子数据库的总数;
17. ParallelTask task = new ParallelTask(1,n,Threshold);
18. int thread = Runtime.getRuntime().availableProcessors();
19. ForkJoinPool pool = new ForkJoinPool(thread);//创建ForkJoin线程池
20. pool.invoke(task);//并行执行问题
21. 汇总各子任务的计算结果;}}
为实现上述算法的并行,需要对Fork/Join框架进行重构,建立可以被Fork/Join框架执行的任务类ParallelTask,该类通过继承Fork/Join应用接口类java.util.concurrent.RecursiveAction得到.在ParallelTask类中,通过重写compute()方法,可实现对各个子任务的计算.main()方法表示程序的主函数,用于运行PSW算法和PFP-Growth算法.
在compute()方法中,首先需要判断事务数据库的规模是否小于阈值,本文用start与end的差值(1≤start≤n,1≤end≤n,start≠end)来表示事务日志数据库的规模,用Threshold来表示阈值.Threshold的设定是决定Fork/Join框架执行时间的关键因素,其大小需要根据经验或实验分析来设定[19],本文将Threshold设定为1.如果差值小于等于阈值,则执行子任务,即执行ComputePswPfp方法;如果差值大于阈值,则对任务进行第一次分解.第一次分解完成后,程序会再次进行判定,如果start与end的差值仍大于阈值,则利用invokeAll()方法对分解后的任务进行递归分解,直到满足条件为止.
2.3 划定伴随数据集
本文采用滑动窗口扫描事务日志数据库以划定出伴随数据集,其中伴随数据集由满足共现关系的项集组成.
2.3.1 滑动窗口
由于事务日志并非实质上的事务数据,本文不能直接将其作为关联规则挖掘算法的输入,需要将事务日志数据转换为伴随数据集.考虑到事务日志是按照时间顺序对数据进行记录,此处适合采用滑动窗口[20](sliding window,SW)找出所有可能存在共现关系的项集,实现伴随数据集的划定.
滑动窗口SW可由m个连续的基本窗口组成,SW可表示为:
SW={SW1,…,SWd,…,SWm}(1≤d≤m)
(8)
式中,SWd可表示为:
SWd={x1,…,xs,…,xw}(1≤s≤w)
(9)
式中,w表示滑动窗口的宽度.
本文将SWd作为一个包含了w条事务日志记录的队列,队列的长度固定为w.通过将SWd向前滑动一条事务日志记录,同时将这条新记录放入队尾,并扔掉原来位于队首的记录,可得到SWd+1(d+1≤m).
SW算法的计算对象不再是当前的整个事务日志数据库,而是事务日志数据库的子集,因此可以在每个SWd内判断事务日志记录之间是否存在共现关系,以提高划定伴随数据集的效率,并减少所需的内存.
2.3.2 PSW算法
本文对串行SW算法进行了改进,所提出的PSW算法采用基于分治策略的Fork/Join并行技术,能够并行地划定Di上的子伴随数据集Si,以解决串行SW算法对事务日志这种大规模的历史静态数据处理效率低的问题.
在执行PSW算法前,本文需要先对事务日志数据库进行划分,得到n个具有一定规模的子数据库Di.然而,将事务日志数据库划分为若干个不相交的子数据库,可能会造成各子数据库失去与其相邻子数据库的联系,从而使计算结果与不采用数据库划分的串行SW算法不同.因此,本文在子数据库最后一条事务日志记录的时间上,额外增加时间长度为最大时间阈值的数据,从而为每个子数据库增加了冗余数据空间,以保留不同子数据库之间的关联性[21].
PSW算法具体流程如下:
1)首先遍历D中的Di,利用哈希映射(HashMap)中键的唯一性,将出现在相同地点的事务日志记录分为一组,从而减少程序的冗余计算.本文将Di的分组数据称为dMap,其键值对(key-value)中的key存储地点,value存储所有出现在该地点的事务日志记录.
2)然后,本文采用滑动窗口处理dMap,在每个基本窗口SWd中,判断位于队首的事务日志记录与队列中其他记录是否满足时间差TD小于等于λ的条件,同时判断两者的对象是否相同.若TD=|t1-ts|≤λ且o1≠os,则根据式(4)将这些事务日志记录转换为一个项集ISd;若TD=|t1-ts|>λ且o1≠os,则中断后续判断,因为队列中的记录是按照时间顺序排列的,显然队列中剩余的记录均不满足TD≤λ的条件.
3)最后,为避免当前窗口SWd产生的ISd是上一个窗口SWd -1产生的ISd-1的子集,算法需要判断ISd-1是否包含ISd,以及ISd包含项的个数r是否大于1.若ISd⊄ISd-1且r>1,则将ISd存入子伴随数据集Si中.
基于Java编程语言实现的 PSW算法流程如算法1所示.
算法1.PSW算法
输入:数据数据库D,滑动窗口宽度w,最大时间阈值λ
输出:伴随数据集S
1.for eachDiinD//开启多线程并行计算
2. 初始化Si
3.dMap=groupByPlace(Di)//根据地点对Di中的数据进行分组
4. for eachdListindMap.values()
5.start=0,end=dList.size(),初始tempSWList//tempSWList存储项集ISd-1
6. while(start!=end)
7. 初始化SWList//SWList存储项集ISd
8.SWList.add(dList.get(start).getPlace()+dList.get(start).getObject())
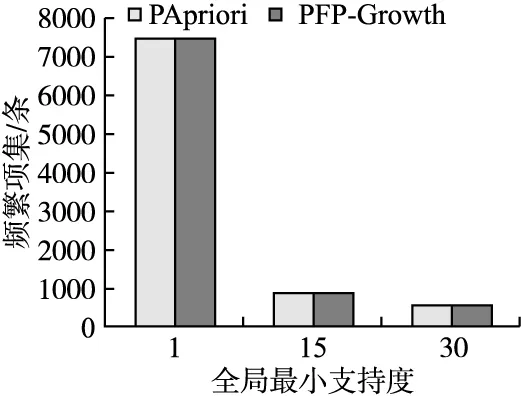
9. for(right=start+1;right 10.TD=dList.get(right).getTD(dList.get(start))//TD表示两条记录间的时间差 11. if(TD≤λ) 12.SWList.add(dList.get(right).getPlace()+dList.get(right).getObject()) 13. else 14. break 15. if(SWList.size()>1&&tempSWList.containsAll(SWList)) 16.Si.add(SWList) 17.tempSWList=SWList 18.start++,w++ 19.S.add(Si) 20.returnS 在算法1中,第1行开启基于Fork/Join框架的多线程并行计算,并行地对每个Di划定伴随数据集;groupByPlace()函数用于根据地点对Di进行分组,并将分组数据存入dMap中;getPlace()和getObject()方法用于获取当前记录的地点和对象. 对于参数w的确定,可采用简单的搜索法,先从一个较小的w(例如w=2)开始执行PSW算法,然后逐渐增大w,记录S的变化,直到S的大小不再改变,此时的w为最佳的w.因为这个w能够使滑动窗口包含较少数量的事务日志记录,同时使滑动窗口划定出的S尽可能大.至于参数λ,需要用户根据业务需求自行确定,一般在1~5min的范围内. 为了更好地描述PSW算法,本文以图1中划定伴随数据集部分为实例来说明该算法.在该实例中,w=5,λ=5min.由于Di中所有记录的地点均为La,本文省略了PSW算法中分组的步骤.已知SW1={x1,x2,x3,x4,x5},虽然x1,x2,x3,x4,x5所记录的对象各不相同,但只有x1与x2、x1与x3满足TD≤5min的条件.因此,根据式(4)得到SW1产生的项集IS1={LaΛOa,LaΛOb,LaΛOc}.同理,可得到SW2产生的IS2={LaΛOb,LaΛOc},SW3产生的IS3={LaΛOc,LaΛOd,LaΛOe}.最后,由于IS2⊄IS3而IS2⊂IS1,Si只存储了IS1和IS3. 频繁项集挖掘是指在伴随数据集中寻找满足最小支持度阈值的所有项集,目的是发现在给定时间段内频繁的共同出现在同一地点的对象. 2.4.1 传统FP-Growth算法 目前常用的关联规则算法有Apriori[22]和FP-Growth[23]算法.Apriori算法需要多次扫描事务集,利用候选频繁项集来产生频繁项集,具有I/O负载较高和算法效率较低的缺点.FP-Growth算法只需要扫描事务集两次,通过树形结构产生频繁项集,与Apriori算法相比,能够提高挖掘频繁项集的效率. 传统FP-Growth算法挖掘频繁项集的方法为扫描伴随数据集,获得每个项的频次,去除不满足最小支持度的项,将剩余项存入项头表,并按照支持度的大小将各项按照降序排列(次序记为Seq);然后再次扫描伴随数据集,按次序Seq组成相应的项集以将其插入到FP树中,并构建节点链表以连接项头表与FP树;最后,对每一个频繁项目对应的条件模式基进行挖掘,从而得到所有能够满足最小支持度约束的频繁k-项集[24].其流程如图1中频繁项集挖掘部分所示. 然而,当对大型的伴随数据集进行挖掘时,FP-Growth算法会显著增加时间和空间的消耗,甚至还有可能使内存无法完全容纳一个完整的FP树.另外,当设定较小的支持度阈值时,即使数据库规模不大,FP-Growth算法仍需要递归地产生大量的条件FP树,使得算法运行速度较慢,占用内存较大. 2.4.2 PFP-Growth算法 文献[25]从理论上证明,对每个子事务数据库构造FP树,再通过合并局部频繁项集,能够得到全局频繁项集.基于此,本文采用基于Fork/Join框架的PFP-Growth算法,以解决当事务数据库规模较大或支持度阈值较小时,传统的串行FP-Growth算法时空效率不高的问题. PFP-Growth算法具体流程如下: 1)首先通过式(10)计算出子伴随数据集Si上的局部的绝对最小支持度minSupi. (10) 式中,minSup表示伴随数据集S上的全局的绝对最小支持度;符号‖·‖用于获取相应数据集中含有的项集总数. 2)在求取minSupi后,PFP-Growth算法开始在各个Si上构造FP树,以挖掘出子局部频繁项集Ti.然后,算法开始遍历Ti中的频繁项集IS,并判断全局频繁项集Tglobal中是否已经存在与IS相同的频繁项集ISexist,若存在,则更新ISexist的支持度(ISexist在S中出现的频次),ISexist更新后的支持度等于ISexist未更新前的支持度与IS的支持度(IS在Si中出现的频次)相加;若不存在,则将IS存入Tglobal中,同时记录IS的支持度. 3)当并行计算完成后,PFP-Growth算法需要遍历Tglobal中的项集ISglobal,若ISglobal的支持度低于全局的绝对最小支持度,即support(ISglobal) 基于 Java编程语言实现的PFP-Growth算法流程如算法2所示. 算法2.PFP-Growth算法 输入:伴随数据集S,最小支持度minSup 输出:全局频繁项集Tglobal 1.for eachSiinS//开启多线程并行计算 2. 根据式(10)计算出minSupi 3.Ti=FP_Growth(Si,minSupi) 4. for eachISinTi 5.countIS=Ti.get(IS)//countIS表示IS的支持度 6. if(Tglobal.hasExist(IS)==false) 7.Tglobal.put(IS,countIS)//将IS与countIS存入Tglobal的键值对中 8. else 9.countIS=countIS+Tglobal.get(IS) 10.Tglobal.put(IS,countIS) 11.for eachISglobalinTglobal 12. if(Tglobal.get(ISglobal) 13.Tglobal.remove(ISglobal) 14.returnTglobal 算法从第1行到第10行利用Fork/Join技术并行地对每个Si进行频繁项集挖掘.其中FP_Growth(Si,minSupi)函数表示根据minSupi,对Si调用FP-Growth算法;Ti和Tglobal采用Hash结构存储,两者的键值对相同,key用于存储频繁项集,value用于存储频繁项集的支持度;Tglobal.hasExist(IS)用于判断Tglobal中是否已经存在与IS相同的项集. 关联规则是一个非监督的学习过程,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构.对于关联规则而言,判断其产生的规则是否有效,一般看它的支持度、置信度是否满足最小支持度、最小置信度阈值,如果大于阈值则为有用的、正确的规则,否则为无用的规则.除支持度和置信度指标之外,为去除具有误导性的冗余规则,本文引入提升度来描述规则的相关性,以有效发现伴随式所蕴含的内在规律,提炼对象之间的内在联系. 2.5.1 支持度指标 支持度表示项集在伴随数据集中的频繁程度,关联规则A⟹B的支持度定义为: (11) 式中,count(A∪B)表示由A与B组成的项集在伴随数据集中出现的频次.值得一提的是,关联规则中的支持度是指相对支持度而非绝对支持度,相对支持度表示绝对支持度与伴随数据集中项集总数的比值,绝对支持度表示项集在伴随数据集中出现的频次. 2.5.2 置信度指标 置信度表示出现规则前件后再出现规则后件的条件概率,关联规则A⟹B的置信度定义为: (12) 式中,count(A)表示A在伴随数据集中出现的频次.置信度越大说明出现A后再出现B的可能性越大. 2.5.3 提升度指标 提升度表示先出现规则前件对出现规则后件的概率的提升作用,关联规则A⟹B的提升度定义为: (13) 其中,如果lift>1,表示A和B为正相关性;如果lift=1,表示A与B无相关性;如果lift<1,表示A和B为负相关性. 2.5.4 产生规则 本文将Tglobal中所有的频繁k-项集(k=2,3,…)分解成由子项集组成的前件和后件.然后根据式(11)、式(12)、式(13)计算由前件和后件组成的规则的支持度、置信度、提升度.若规则满足支持度阈值、置信度阈值、提升度阈值,则按文献[26]提出的用于关联规则可视化的数据结构,将规则存入关联规则集V中,V可表示为: V={{A1,B1,θ1},{A2,B2,θ2},…,{Az,Bz,θz}} (14) 式中θ表示规则的度量(例如规则的支持度、置信度、提升度),z表示规则的总数. 基于Java编程语言实现的产生规则的算法流程如算法3所示. 算法3.产生规则的算法 输入:支持度阈值minSupport,置信度阈值minConfidence,提升度阈值minLift,全局频繁项集Tglobal 输出:关联规则集V 1.for eachISinTglobal 2. if(IS.size()>1)//如果IS的项数大于1 3.countA∪B=Tglobal.get(IS) 4. for(i=1;i 5.combination=getCombi(IS,i) 6. for eachAincombination 7.B=getleft(IS,A) 8.countA=Tglobal.get(A) 9. 根据式(11)计算规则的支持度 10. 根据式(12)计算规则的置信度 11. 根据式(13)计算规则的提升度 12. if(support>=minSupport&& confidence>=minConfiedence&& lift>=minLift) 13.V.add(A,B,support,confidence,lift) 14.returnV 算法中getCombi(IS,i)函数用于从IS中获取所有项数为i的子项集组合;getleft(IS,A)函数表示排除IS中的A后,所留下的子项集.关于生成规则的参数一般可以通过经验与用户的业务需求来确定,还可通过关联规则的可视化结果来确定. 本文基于某城市某社区门禁刷卡数据进行实验,以2020年4月-9月全天采集到的门禁刷卡数据作为数据集,数据集共包含12万余条事务日志记录,涉及930位对象,14个地点,实验前已对数据进行了清洗和隐私处理.实验在单台计算机上进行,处理器为Intel Core i7-6700 3.40GHz(4核8线程),内存大小为8GB,操作系统为64位Windows10,JDK版本为1.8,采用MySQL数据库存储事务日志记录. 3.2.1 数据规模和并行度对算法性能的影响 本文利用Fork/Join技术对基于密度的DBSCAN算法[27]、时间切片[12]、Apriori进行了并行化改造,并将改进算法分别命名为PDBSCAN(parallel DBSCAN)、PTS(parallel time slice)和PApriori(parallel Apriori). 为了验证本文所提出算法的时间复杂度,本文在不同数据规模下,使用PDBSCAN、PTS、PSW算法对事务日志数据进行划定伴随数据集实验,以及采用PApriori算法、PFP-Growth算法对伴随数据集进行频繁项集挖掘实验,实验结果如图3所示.在未标明参数的情况下,默认各算法的参数如表1所示.本文使用时间差来度量PDBSCAN算法中两个对象之间的距离(相似性),因此表中PDBSCAN算法的邻域半径单位为分钟. 表1 各算法的参数设置Table 1 Parameter setting of each algorithm 从图3可知,PDBSCAN算法的运行时间高于其他算法,这是因为PDBSCAN算法在聚类过程中需要访问原始数据中的所有对象,并且有些对象可能需要重复访问多次,导致算法的计算量较大.其中当事务日志记录数为107186条时,PSW算法比PDBSCAN算法节省了35.5%的时间,与PTS算法相比两者运算时间较为接近.因此PSW算法适合处理海量的事务日志数据. 从图3还可发现,PApriori算法的运行时间远高于PFP-Growth算法,这是因为在频繁k-1-项集生成候选频繁k-项集时,需要进行连接与剪枝操作,以及在验证候选频繁k-项集时,需要对整个事务数据库进行扫描,增加了算法的计算量和运行时间.其中当事务日志记录数为107186条时,PFP-Growth算法比PApriori算法节省了98.9%的时间. 图3 不同数据集下的算法运行时间Fig.3 Algorithm executing time under different data sizes 综上所述,相较于传统算法,本文所提出的融合了数据库划分和Fork/Join并行计算技术的伴随模式挖掘框架能够有效减少算法的计算量,提高挖掘伴随模式的运行效率. 为了探究并行度对本文所提出算法的影响,本文对算法在同一台计算机上的CPU可运行线程数进行了限制,以测试在同一记录数(记录数为107186条)、不同并行度下算法运行时间,实验结果如图4所示.由图4可知,随着线程数的增加,PSW算法、PFP-Growth算法的运行时间均不断降低.因此对于计算规模较大的任务,较多的可运行线程数将可以更加显著地提高本文所提出的改进算法的效率. 图4 不同并行度下的算法运行时间Fig.4 Algorithm executing time under different parallelism degrees 3.2.2 最大时间阈值和支持度对算法性能的影响 本文通过调整最大时间阈值和全局最小支持度这两个参数,使算法能够发现不同时间段内共同出现在同一地点的对象,以及不同频繁程度的伴随模式,从而提高伴随模式挖掘的灵活性. 如表2和图5所示,本文统计了不同最大时间阈值对PDBSCAN、PTS、PSW算法运行时间,以及伴随数据集划定结果的影响,其中实验的事务日志记录数为107186条.由表2和图5可知,随着最大时间阈值的增加,所有算法生成伴随数据集的数量均不断增加,这是因为在较大的时间段内可能会有更多的对象出现在同一地点,增加了算法所挖掘出伴随数据集的数量.此外,在PDBSCAN算法中可能会存在类内第一个对象与最后一个对象间时间差大于最大时间阈值λ的情况,使得PDBSCAN算法产生的伴随数据集的数量较小,这是因为第一个对象和最后一个对象不满足直接密度可达的条件.虽然PTS算法均满足切片内第一个对象与最后一个对象间时间差不大于λ,但是出现在某时某地的对象只能属于一个切片,无法同PSW算法一样,可以属于不同的滑动窗口,因此时间切片产生的伴随数据集的数量不及PSW算法.可见PSW算法能够更加充分地挖掘出伴随数据集,并缩短所需的挖掘时间. 表2 不同最大时间阈值对算法运行时间的影响Table 2 Effects of different time thresholds on the algorithm executing time 图5 不同最大时间阈值对伴随数据集的影响Fig.5 Effects of different time thresholds on the CP dataset 如表3和图6所示,本文统计了不同全局最小支持度对PApriori算法、PFP-Growth算法的运行时间和频繁项集挖掘结果的影响,其中输入数据为图5中PSW算法在最大时间阈值为5min时生成的伴随数据集.由表3和图6可知,当全局最小支持度不断增加时,各算法的运行时间和频繁项集的大小不断减少,这是因为频繁程度高的伴随模式比频繁程度低的伴随模式更少,造成运行时间和频繁项集大小减少.此外,在相同的全局最小支持度下,PFP-Growth算法生成频繁项集的大小不仅与PApriori算法相同,而且运行时间更少. 图6 不同全局最小支持度对频繁项集的影响Fig.6 Effects of different global support on the frequent itemsets 表3 不同全局最小支持度对算法运行时间的影响Table 3 Effects of different global support on the algorithm executing time 为了帮助用户直观地从大量规则中筛选出有效的强关联规则,并分析出项与项之间的关联关系,本文利用SpringBoot技术设计了一个基于HTML与Echarts的动态数据显示前端,使其成为关联规则挖掘结果可视化的承载体,关联规则的散点图和网图如图7和图8所示.实验中规则的支持度阈值设置为0.0001,置信度阈值设置为30%,提升度阈值设置为10,共生成502条规则.支持度阈值很小的原因是本文频繁项集在伴随数据集中出现的频次一般很小. 在图7中,x轴表示置信度,y轴表示支持度,点的明暗表示规则的支持度计数,点的大小表示提升度.由图7可以看出所有规则在散点图中的分布,其中支持度和置信度较低,而提升度较高的规则集中于散点图的底部,这有助于用户调整支持度阈值、置信度阈值和提升度阈值,以筛选出相关性更高的规则. 图7 关联规则的散点图Fig.7 Scatterplot of association rules 图8只截取了关联规则可视化网图的一部分,没有包含所有的关联规则.图中圆点表示项,较大的圆形表示规则,圆形的大小表示规则的支持度计数,箭头表示规则内部项与项的关系.从图8可以看出不同规则之间如何共享一个前件,并可发现哪个前件是网图的中心,这有利于用户直观地发现规则中项与项之间一对一、一对多、多对多的关系. 图8 关联规则的网图Fig.8 Network diagram of association rules 随着事务日志的数据规模不断扩大,传统基于滑动窗口的伴随数据集划定方法,以及传统FP-Growth算法,无法充分利用计算机的多核性能,导致挖掘伴随模式的时间急剧增加,为此本文提出基于Fork/Join并行技术的伴随模式挖掘框架.该框架包括划定伴随数据集、频繁项集挖掘和关联规则挖掘3部分.首先,本文提出了基于Fork/Join的PSW算法,以并行地从事务日志数据库中划定伴随数据集;然后,本文提出了PFP-Growth算法,以并行地在伴随数据集上构造FP树,缩短挖掘频繁项集的时间;最后,本文利用支持度、置信度和提升度来挖掘伴随模式中的关联规则,以进一步分析对象间的关联关系和规律性.基于门禁刷卡数据的实验结果表明,相比传统算法,本文所提出的框架能够挖掘出更多的伴随模式,同时挖掘效率较高. 本文所提出的伴随模式挖掘框架目前仅适用于静态历史的事务日志数据.下一步本文将研究如何实时地从事务日志数据流中挖掘伴随模式,拟利用分布式计算框架对数据流进行切片,并改进滑动窗口和关联规则算法,以满足实时挖掘伴随模式的需求.2.4 频繁项集挖掘
2.5 关联规则挖掘
3 实验研究
3.1 实验配置
3.2 实验内容和结果分析

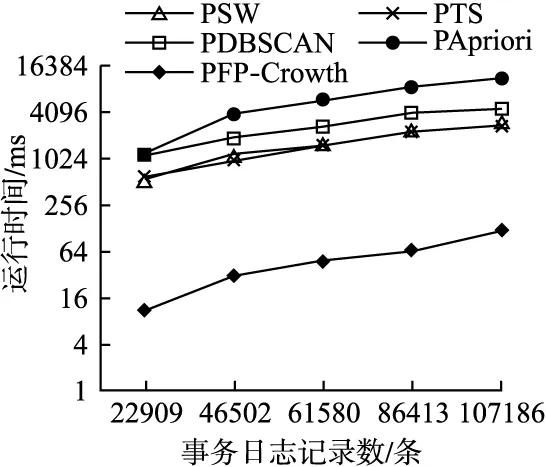
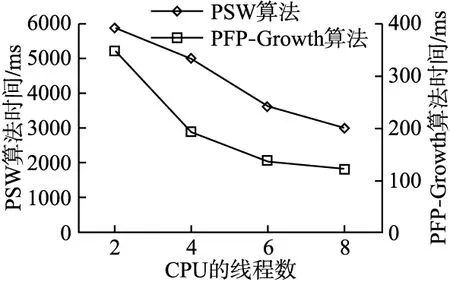

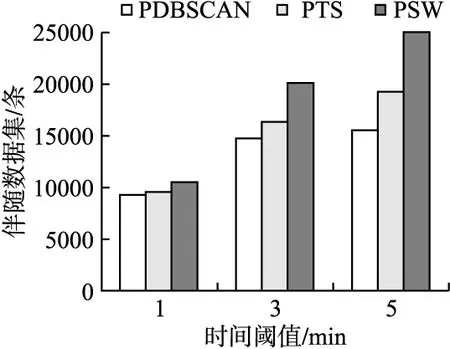

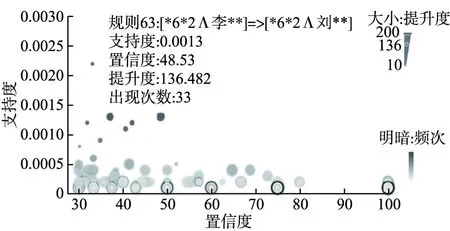
3.3 关联规则可视化展示
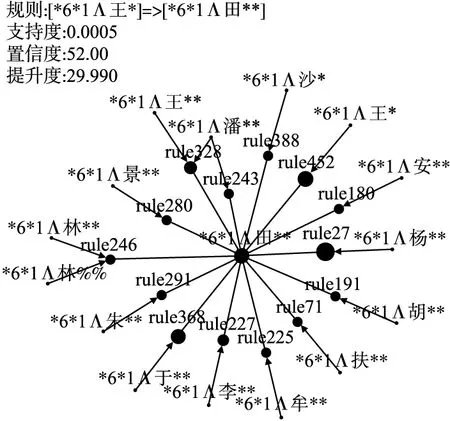
4 总 结
