Lite-YOLOv3轻量级行人与车辆检测网络
2023-01-31涂媛雅汤国放张建勋
涂媛雅,汤国放,张建勋
(重庆理工大学 计算机科学与工程学院,重庆 400054)
1 引 言
近年来随着社会的发展、图形计算硬件算力的提升、科研队伍的壮大,深度学习方法已经在各个领域发挥重要作用.2021年,《中华人民共和国国民经济和社会发展第14个5年规划和2035年远景目标纲要》在数字化应用场景中阐述智能交通的重要性.在智能交通领域,有效的行人与车辆检测是最基础的保障.
许多研究者使用机器学习和图像处理技术实现了行人和车辆的检测.杨婉香[1]等人提出一种多尺度融合的行人检测算法,采用方向梯度直方图(HOG)[2]提取行人特征,再结合支持向量机(SVM)实现分类检测.王周春[3]以HOG+SVM分类模型为基础,通过加入GLCM[4]算法提取目标纹理特征,解决穿着不同服饰的红外面目标识别问题.穆柯楠[5]等人提出一种基于多尺度边缘融合和SURF[6]特征匹配的车辆检测算法,克服了传统基于边缘特征的车辆检测方法易受噪声、背景干扰的问题.施培蓓[7]等人基于RealAdaboost[8]框架提出一种基于快速增量学习的行人检测方法,能够有效解决行人检测器的场景自适应问题.这些算法利用行人和车辆特点手工设计特征并配合图像处理和机器学习实现了行人和车辆检测,取得了一定的检测效果,但实际城市交通环境存在复杂背景、复杂干扰等问题,基于传统特征提取算法的行人和车辆检测可能存在稳定性差和泛化能力不足等问题,导致行人和车辆检测不准确或出现漏检.也有研究者采用基于卷积神经网络(CNN)[9]的目标检测算法,对比传统特征提取的目标检测算法,基于CNN的目标检测算法不仅可以提取更高层次和更好的表达特征,而且可以在同一模型中完成特征的提取,选择和分类,具有检测准确率高和泛化能力强的特点.
基于CNN的目标检测算法主要包含两种主流算法:1.区域提议模型,例如R-CNN[10],SPP-Net[11],Fast R-CNN[12],Faster R-CNN[13],R-FCN[14];2.端到端(无区域建议)模型,例如YOLO[15],YOLO9000[16],YOLOv3[17],SSD(单发多盒检测器)[18].前者基于分类的算法核心是区域提议,通常是通过使用选择性搜索(Selective Search)[19]算法或区域提议网络(Region Proposal Network)获得感兴趣的区域(Region of Interest),然后使用CNN模型对每个区域进行分类以获得类别和置信度.目前,此类方法因其检测精度高仍然流行,2020年,陈康[20]等人基于Faster R-CNN算法解决布匹瑕疵点检测问题,主要通过引入深度残差网络和增加预测锚点框的方式提升多尺度瑕疵点检测和小目标瑕疵点的检测性能.同年,吉训生[21]等人也使用FasterR-CNN作为基础网络对电路板字符进行检测.但是由于此类方法需要先定位目标候选框然后利用分类算法进行目标分类,存在效率低的弊端.后者将目标检测问题转化为单步的回归问题,将目标框与目标分类合起来,一次输出目标类别和目标位置信息,大大提高了检测的效率,但检测准确率稍弱.2020年,徐守坤[22]等人提出一种安全帽佩戴检测算法,该算法基于YOLOv3网络,主要通过改进网络多尺度预测结构和初始锚框参数提升检测性能.由于卷积神经网络的深度深、复杂性高,对数据集的训练将消耗许多计算资源,并且要达到实时检测的目的对计算机硬件配置要求很高,许多研究者们开始探索小型微型目标检测算法.
2018年,Joseph Redmon提出了YOLOv3网络,引入特征提取网络Darknet-53和多尺度预测网络.与之前提出的版本(YOLO,YOLO9000)比较而言,YOLOv3网络体积较大,但预测准确率更高.同时,作者提出了其小型网络Tiny-YOLOv3来满足对速度要求比较高的项目.Tiny-YOLOv3大小为33.4MB,接近于YOLOv3的1/8倍.其在YOLOv3的基础上删减了一些特征提取层,只保留了两个预测分支,因此检测速度有很大程度的提升,满足实时性任务的要求.但同时因其网络的删减导致整体检测准确率有所下降,预测分支的减少也导致对小目标物体的检测能力不足.因此如何在检测速度和检测精准度上找到一个平衡点成为近些年目标检测任务的重点与难点.
基于此,本文提出一种轻量级行人与车辆检测网络Lite-YOLOv3,网络模型在检测速度与检测精度方面均有较大幅度提升.
2 Tiny-YOLOv3网络
本文采用轻量级网络Tiny-YOLOv3作为基础网络,Tiny-YOLOv3是YOLOv3网络的简化网络,其参数量小的特性使得网络检测速度较快,能够满足低性能计算机对检测实时性的需求.
Tiny-YOLOv3网络结构如图1所示,Tiny-YOLOv3的主干网络(BackBone)由6层卷积层和池化层组成,卷积层主要用于提取特征,池化层主要用于降低特征图尺寸,相较于YOLOv3网络的主干网络,Tiny-YOLOv3采用更少的卷积层提取特征,并且YOLOv3主干网络通过卷积的方式下采样,由此可知Tiny-YOLOv3的参数量大幅下降,其模型运算速度得到大幅提升,但是由于网络深度变浅,其提取特征的能力则有所下降.Tiny-YOLOv3的预测网络(Head)由卷积层、上采样层和连接层组成,其卷积层主要用于提取抽象特征,使得网络能够学习到图像的深层语义信息.上采样层将13×13像素的特征图放大到26×26像素,连接层将低维度的特征图与高维度特征图进行通道拼接融合,使得网络能够学习到不同深度的语义特征,加强了网络的特征学习能力.Tiny-YOLOv3网络有2个预测尺度,分别为13×13和26×26,相较于YOLOv3网络,其预测尺度减少1个,从而参数计算量减少了一部分,但是其预测精度也有一定程度的下降.

图1 Tiny-YOLOv3网络结构图Fig.1 Structure of Tiny-YOLOv3
YOLOv3网络与Tiny-YOLOv3网络参数对比如表1所示,Tiny-YOLOv3作为YOLOv3的轻量版,网络删减大量卷积层并且使用两个尺度预测结果,其网络层数和参数量均得到大幅下降,分别为YOLOv3网络参数量的1/6倍和1/7倍,因此Tiny-YOLOv3网络运算速率得到大幅提升.
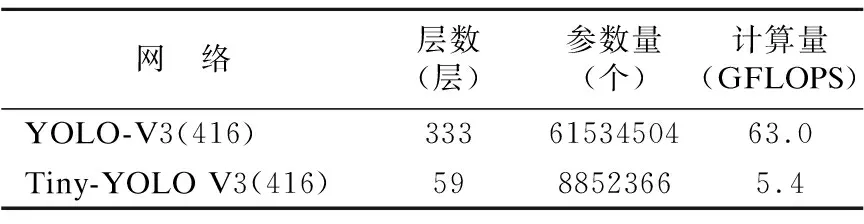
表1 YOLOv3网络与Tiny-YOLOv3网络参数对比Table 1 Comparison of YOLOv3 network and Tiny-YOLOv3 network parameters
3 相关工作
3.1 BottleNeckLayer
BottleNeck Layer亦称瓶颈层,其含义是卷积过程中生成的特征图的大小如同花瓶的瓶颈.BottleNeck Layer网络结构如图2所示,BottleNeck层由两层卷积层组成,第1层卷积核大小为1×1,第2层卷积核大小为3×3.每层卷积核的个数不固定,往往第1层卷积核的数量较小,第2层卷积核的数量较大,前者用于降低特征图维度,后者用于提取特征.BottleNeck层在不增加冗余计算量的同时,使得网络能够提取到更深层的语义信息.
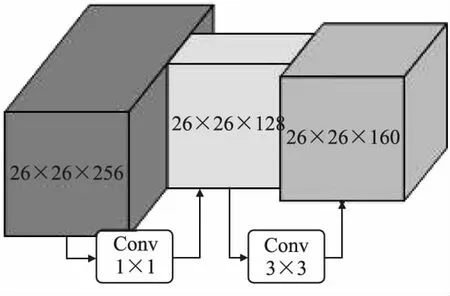
图2 瓶颈层网络结构图Fig.2 Structure of BottleNeck
假设输入特征图的大小为hinput×winput×cinput,分别代表输入特征图的宽、高、通道数,直接使用3×3卷积,输出特征图的大小为hout×wout×cout,根据参数量计算公式(1)可知两种情况的参数量:
Params=hinput×winput×cinput×k2×cout
(1)
Pconv=cinput×3×3×cout
(2)
当使用BottleNeck层时,先用1×1卷积下降到C1个通道,再用3×3卷积升维到C1个通道,参数计算量为:
Pbottlenck=1×1×cinput×cmid+3×3×cmid×cout
(3)
两者之比为:
(4)
其中,Params表示卷积过程中的参数量,k表示卷积核大小,cout表示输出特征图通道数.cmid表示BottleNeck中第1次卷积输出的特征图维度.
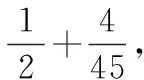
3.2 深度可分离卷积
深度可分离卷积(Depthwise Separable Convolution,DSC)将标准卷积结构进行拆分,主要分为两个过程,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution).深度可分离卷积首先使用逐通道卷积在二维平面内对输入层的每个通道独立进行卷积,卷积后生成的特征图数量与输入层的通道数相同,但是没有有效利用不同通道在相同空间位置上的特征信息.因此需要使用逐点卷积在上述步骤生成的特征图深度方向上进行加权组合,由此生成新的特征图.逐通道卷积和逐点卷积的过程如图3所示.
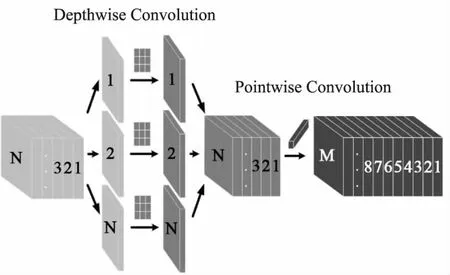
图3 逐通道卷积和逐点卷积Fig.3 Depthwise convolution and pointwise convolution
假设输入特征图大小为Wi×Hi×C,Wi代表输入特征图的宽,Hi代表输入特征图的高,C代表输入特征图的通道数,标准卷积大小为Wc×Hc×C×N,分别代表标准卷积的宽、高、通道数和卷积核个数,经过标准卷积后,输出特征图大小为Wo×Ho×N.则标准卷积的参数计算量为:
Params(Sd)=Wo×Ho×N×Wc×Hc×C
(5)
深度可分离卷积首先使用Wc×Hc×1×C的卷积进行逐通道卷积,然后使用1×1×C×N的卷积进行逐点卷积,则深度可分离卷积的参数计算量为:
Params(DSC)=Wo×Ho×1×Wc×Hc×C+
Wo×Ho×N×1×1×C
(6)
两者之比为:
(7)
3.3 卷积代替池化
原Tiny-YOLOv3的骨干网络由一系列卷积层和池化层组成,其中卷积层为常见的3×3卷积,用于提取图像特征,池化层采用2×2的最大池化策略,其作用机理为:在每4个权重值中取最大值作为新特征图的权重.虽然池化层在降低特征图的大小的同时保证了图像语义信息平移不变性,但是在2×2特征图中选择1个特征作为新权重的方式会导致新的特征图不包含其他3个权重的信息,整体上会丢失部分语义信息,导致训练结果不理想.故本文提出了使用卷积代替池化的骨干网络,使用尺寸大小为3×3,步长为2的卷积层代替2×2的最大池化层,在不影响输出结果尺寸的同时,能够保证新特征图的权重值间接包含前面特征图的所有权重值,一定程度上能够丰富深层特征图的语义信息.
4 Lite-YOLOv3
基于BottleNeck、深度可分离卷积与卷积代替池化等方案,本文提出了Lite-YOLOv3网络,其具体网络结构如图4所示.Lite-YOLOv3网络共包含20层,其中所有的下采样池化层均被尺度为3×3步长为2的卷积层替代.Lite-YOLOv3网络在第9层加入本文改进的BottleNeck网络块,第11、12、14和18层加入本文提出的DPRConv网络块.

图4 Lite-YOLOv3网络结构Fig.4 Structure of Lite-YOLOv3
本文基于组卷积方法改进BottleNeck,其具体结构如图5(a)所示,由1×1和3×3的卷积组成,其中第1层1×1的卷积核个数为输入特征图通道数的一半,卷积核个数的降低可以减少网络参数量.如图4中网络第9层所示,BottleNeck块的输入特征图的大小为26×26×256,经过1×1×128卷积输出尺寸为26×26×128的特征图,1×1的卷积在加深网络提取深层语义信息的同时降低网络一半的参数量,使得后续的卷积计算量大幅降低.BottleNeck块第2层为3×3卷积为组卷积层,组卷积的卷积核个数为输入特征图的通道数,将26×26×128的特征图按通道分为128个26×26×1的特征图,并使用128个3×3的卷积核提取特征,将输入和输出特征图对位相加得到最终特征图,对位相加方法在一定程度上可以解决网络退化问题.

表2 BottleNeck改进前后参数量对比
根据公式(1)可计算出BottleNeck改进前后参数量.具体如表2所示,可以发现改进后的BottleNeck块相较于原BottleNeck块参数量有大幅下降,比率接近1/10.因此可以说明加入组卷积模块的BottleNeck块具有更少的参数量和更快的运算速度,为网络模型的实时性奠定良好基础.
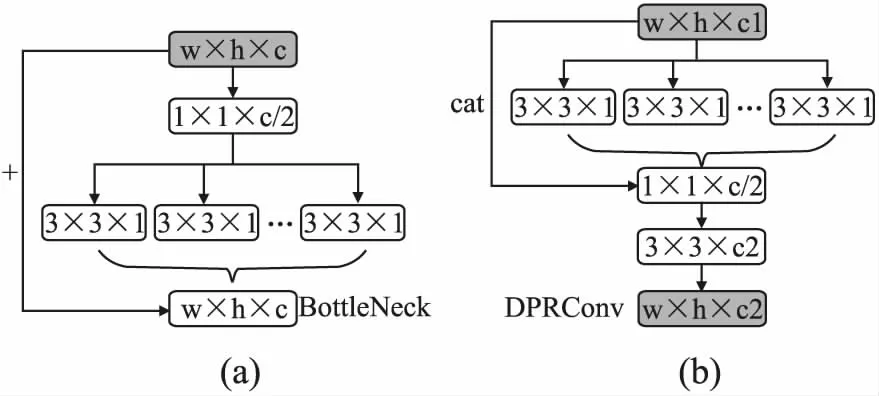
图5 BottleNeck和DPRConv结构Fig.5 Structure of BottleNeck and DPRConv
卷积可分离残差网络DPRConv是本文基于Depth Point网络和Resnet网络提出的网络模块,其具体结构如图5(b)所示.DPRConv由一个组卷积和两个3×3卷积组成,其中组卷积由c1个3×3的卷积核组成,分离输入图像的每一个通道再卷积.其后第1个卷积层尺寸为1×1×c2,并且包含一个在通道上拼接的concat操作,目的是整合输入与输出的特征图,得到通道数为c1+c2特征图.第2个卷积层的尺寸为3×3×c2,其作用是将输出特征图通道数由c1+c2降低为c2,目的是降低最终输出特征图的参数量.
本文在Lite-YOLOv3网络结构中的改进点中增加了concat操作和卷积降维层,虽然在一定程度上导致网络参数量增多,但是对输入数据进行信息叠加,使得输出特征的语义信息更丰富,从而能够提升模型预测精准度,并且降维层使得后续的网络结构的输入参数减少,从而提升模型运算速度.
5 实验结果与分析
5.1 实验环境
本文的实验硬件环境为: Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz,8G DDR4内存,NVIIA GeForce GTX3060 8G独立显卡.软件环境为:ubuntu18.04操作系统,使用Pytorch[23]深度学习框架,python3.8.5,A9.2,torch1.6.0,opencv-python4.4.0等相关工具包.
5.2 数据集
本文实验数据集是KITTI,它是目前世界上最大的自动驾驶场景中的计算机视觉算法评估数据集.包含从市区,村庄和高速公路等场景收集的真实图像数据.图像最多包含的检测目标可达15辆汽车和30位行人,并且图像具有不同程度的遮挡和截断.目标检测包括7481张训练图像和7518张测试图像,包括总共80256个带标签的物体,并且标签分为小汽车、货车、卡车、行人、人(坐)、骑自行车的人、有轨电车和其他杂项.本文主要对行人和车辆进行检测,所以对数据集类别进行合并为3种,分别是Pedestrains、Car和Cyclists.具体是将小汽车、货车、卡车、有轨电车合并为Car,行人、人(坐)合并为Pedestrians,骑自行车的人为Cyclists.
5.3 评估指标
为了验证改进后的网络模型Lite-YOLOv3的性能,本文采用平均精准度(mean Average Precision,mAP)、精确率(Precision,P)、召回率(Recall,R)和每秒检测帧数(FPS)4个指标对算法进行评估.其中,mAP是对所有类别的平均精度(Average Precision,AP)求取均值后获得,采用mAP_0.5∶0.95,表示在不同IOU阈值(从0.5-0.95,步长0.05)上的平均mAP.精确率如公式(8)所示,召回率如公式(9)所示,平均精度如公式(11)所示.本文统计了FPS参数,以验证模型的检测速率.
(8)
(9)
其中,TP表示检测结果为正的正样本,FP表示检测结果为正的负样本,TP+FP表示检测结果为正的样本总数,FN表示检测结果为负的正样本,TP+FN表示正样本的总数.P表示检测结果为正的样本中真正正样本占的比例,R表示所有正样本中有多少正样本被预测正确.
(10)
(11)
其中,Sum表示测试集中图片总数,Class表示检测类别数.
(12)
其中,fn表示模型处理图像的总数,T表示所用时间.
5.4 模型训练
本文训练模型初始学习率为0.01,OneCycle学习率为0.10,动量为0.937,weight_decay为0.0005,warmup_epochs为20,warmup_momentum为0.8,warmup_bias_lr为0.1,训练epoch为600次.
本文采用消融实验对比不同模型的参数量,模型如表3所示.Tiny YOLOv3 ConvSample、Tiny YOLOv3 BottleNeck、Tiny YOLOv3 DPR、Tiny YOLOv3和 Lite-YOLOv3.Tiny YOLOv3 ConvSample网络使用大小为3×3、步长为2的卷积层代替原Tiny YOLOv3网络中的下采样层.Tiny YOLOv3 BottleNeck网络使用改进后的BottleNeck层替换原Tiny YOLOv3网络的第9层.Tiny YOLOv3 DPR使用改进后的可分离卷积层替换11、12、14和18层.Lite-YOLOv3即本文提出的基于ConvSample、BottleNeck和DPR模型的轻量级网络,其具体包含模型、模型参数量与GFLOPS如表3所示.
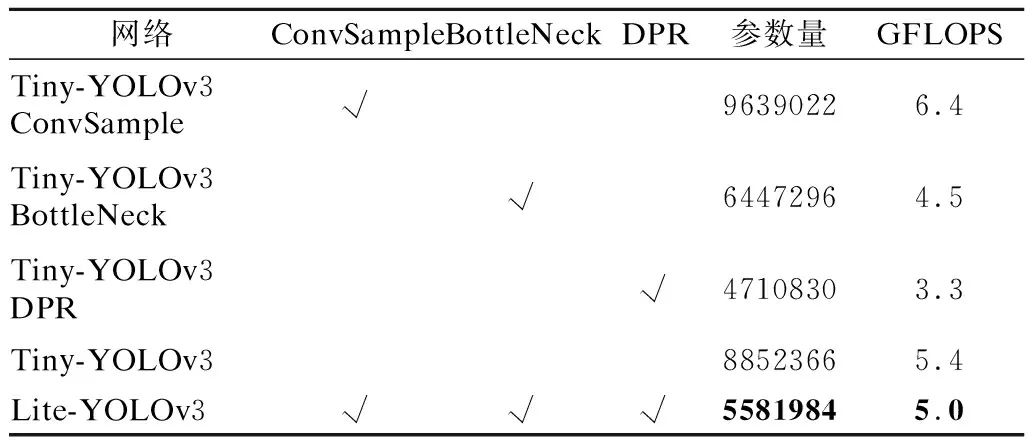
表3 多种模型参数对比表
ConvSample卷积替代池化参数量虽然增多,但是随着卷积的加入有两个作用:1)使得网络层数增加,激活函数的增多可以使得学习特征更具非线性特征;2)相较于舍弃权重的下采样卷积方式,卷积过程能够提取上一层输入特征图的所有权重值.在引入改进后的基于组卷积BottleNeck、DPR等模块后,网络的参数量得到有效降低,证明以上二者具有降低参数量的效果,并且二者均由多层网络组成,同样可以提取深度语义信息.
5.5 消融实验
消融实验平均精准度对比如图6所示,4种网络模型在平均准确率mAP方面由高到低的排序是:Lite-YOLOv3,Tiny-YOLOv3 ConvSample,Tiny-YOLOv3 DPR,Tiny- YOLOv3 BottleNeck和Tiny-YOLOv3,具体准确率如表4所示,其中Lite-YOLOv3的mAP0.5:0.95与mAP0.5平均准确率值分别为42.51%和76.64%,相较于Tiny-YOLOv3网络,Lite-YOLOv3网络具有6.26%和9.07%的平均准确率的提升,证明卷积替代池化方案可以提取到更多输入信息,识别更多目标行人与车辆,并且多层网络可以将输出特征向量非线性化,使得网络学习到的特征更拟合输入数据.
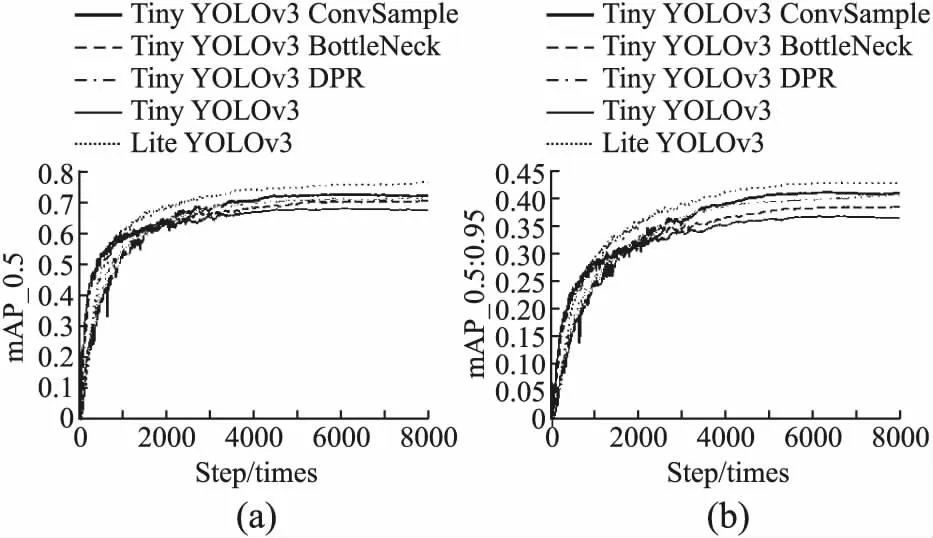
图6 消融实验平均检测精准度对比图Fig.6 Comparison chart of mAP of ablation experiment
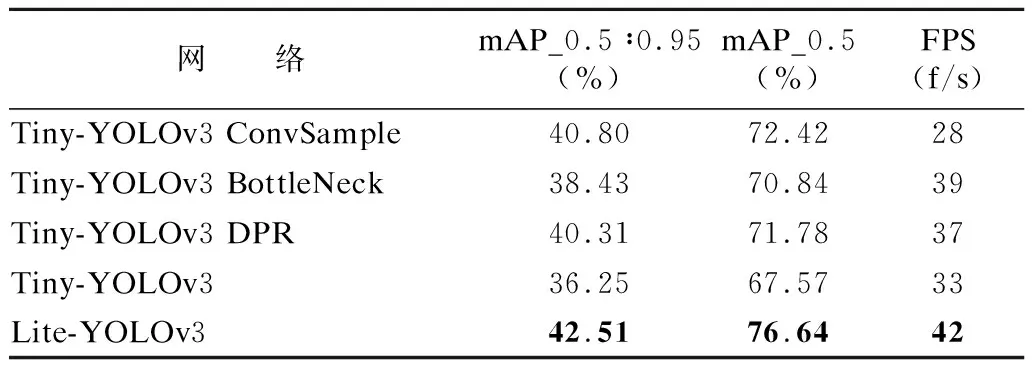
表4 消融实验性能对比Table 4 Comparison of ablation performance
由表4数据可知,ConvSample网络的精准度相较于Tiny-YOLOv3网络有一定的提升,同时其网络运算速度有一定损失,证明卷积代替池化能够提升网络识别精准度,但在一定程度上增加模型的参数量,降低网络运算速度.BottleNeck和DPR模型的运算速度相较于原网络有一定提升,证明组卷积的加入能够有效降低网络参数量,提升模型运算速度,并且BottleNeck和DPR模型的平均准确率均有一定提升,证明两个模块的多层卷积网络可以有效增强特征拟合能力,提升网络检测精准度.
5.6 主流算法对比实验
本文与两种目标检测领域流行的轻量级网络框架进行对比实验,分别是NanoDet和Tiny-YOLOv4[24].主要对比3个网络模型的mAP和FPS两个指标,如表5所示.Lite-YOLOv3网络的平均检测精准度最高,相较于NanoDet和Tiny-YOLOv4分别提升了4.5%和5.73%.在网络运行速度方面,NanoDet具有较大优势,但是Lite-YOLOv3其42f/s的运行速度完全满足实时检测的要求.所以三者在网络满足实时输出检测目标的情况下,Lite-YOLOv3具有更高的检测精准度,能够检测到更多的有效车辆和行人.证明Lite-YOLOv3的3个改进模块在一定程度降低了模型的参数量,使得模型的运算速度加快,且能够提取到更丰富的图像特征.
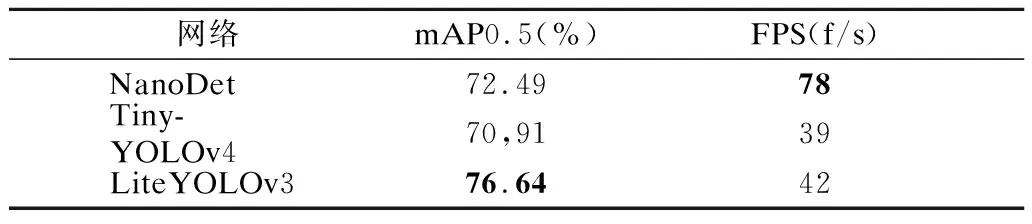
表5 主流目标检测网络对比
5.7 检测结果
5种网络的实验结果如图7所示,由上到下依次是Tiny-YOLOv3,Tiny-YOLOv3 BottleNeck,Tiny-YOLOv3 DPR,Tiny-YOLOv3 ConvSample和Lite-YOLOv3,下文使用abcde代替.第1列结果中(d)、(e)网络输出图中的检测框数量明显多于(a)、(b)和(c),说明卷积替代池化模块可以提取到更多的信息,从而识别出更多的目标车辆.(e)相较于(d)网络,其输出特征图的类别置信度均高于(d),说明BottleNeck和DPR结构中的cat和add操作可以有效防止网络退化,从而不丢失前部网络学习的特征信息.第2列结果图中只有(e)网络具有多个检测框,且检测目标均为小目标.第3列输出图与第2列输出图相似,(e)网络能够识别到远处的行人与车辆,说明卷积替代池化操作能够提升浅层网络的深度,BottleNeck和DPR结构包含多个卷积层再次加深网络模型,进而提升网络拟合数据能力,提高针对小目标行人和车辆的检测能力.

图7 结果对比图Fig.7 Results comparison chart
6 总 结
本文基于改进的BottleNeck,DPR模块和卷积代替下采样方案在Tiny-YOLOv3基础提Lite-YOLOv3.Lite- YOLOv3在平均检测精准度和网络运算速度方面较Tiny- YOLOv3 均有一定提升,分别提升9.07%和9f/s.通过实验结果分析,所提出的Lite-YOLOv3网络模型能够在提升网络检测速度的情况下同时有效实现小目标的检测,为嵌入式移动终端提供了可行性.通过整体实验效果来看,DPR和BottleNeck中的组卷积部分虽然可以降低网络运算速度,但是可能导致一定的特征损失,降低网络学习能力.后续考虑使用空洞卷积代替组卷积进行实验,同时考虑知识蒸馏再次压缩网络模型.
