一种基于信任和不信任的矩阵分解推荐算法
2023-01-31魏国亮吴超异
乔 猛,魏国亮,吴超异
1(上海理工大学 理学院,上海 200093) 2(上海理工大学 外语学院,上海 200093)
1 引 言
随着互联网技术的快速发展,用户面临着信息过载问题,使得对推荐系统研究变的愈发重要[1].推荐系统利用多种信息推断顾客的喜好对用户进行推荐,使得用户快速找到感兴趣的内容.推荐系统可以大致分为3类,基于内容的推荐系统[2],协同过滤推荐系统[3-5],混合推荐系统[6].基于内容的推荐系统通过计算用户间的相似性,根据用户间的相似性推荐物品.协同过滤推荐系统通过对大量用户给出的评分协同处理给出推荐.而混合推荐系统是通过结合基于内容的推荐和协同过滤推荐进行推荐,其优点是结合两种推荐算法,避免使用单一推荐算法的局限性.这3类推荐系统算法中,协同过滤推荐是最流行的推荐算法.
协同过滤算法通过分析用户的近邻信息和和用户历史购买行为进行个性化推荐[7]..与基于内容的推荐算法相比,协同过滤推荐算法不需要对物品进行隐式的特征表示,而仅仅利用用户的评分和社交等信息进行推荐.协同过滤算法大致分为两类,基于近邻的协同过滤和基于模型的协同过滤[8].基于近邻的协同过滤算法关键在于计算用户或物品之间的相似性,通过对相似用户的评分或相似物品评分的进行加权来估计未知评分,从而进行推荐.当用户对较多的物品评分时基于近邻的协同过滤算法能够有效的进行推荐,但当用户只对少量物品评分时,基于近邻的推荐效果较差,因为此时采用加权预测时容易产生较大的误差.然而在真实场景中数据是极度稀疏的,这导致基于近邻的协同过滤不能应用于大规模场景推荐.
基于模型的协同过滤算法可以在一定程度上弥补基于近邻的协同过滤算法的缺陷.基于模型的协同过滤算法通过用户的历史评分对用户进行推荐.基于模型的协同过滤算法主要包括聚类方法[10].,贝叶斯方法[10],矩阵分解方法等[11,12]..其中矩阵分解算法是最流行的算法,矩阵分解算法将评分矩阵进行低秩矩阵分解,通过学习低秩的潜在因子矩阵来预测未知评分.常见的矩阵分解算法有奇异值分解算法(SVD++)[13],加权非负矩阵分解算法(WNMF)[14],概率矩阵分解算法(PMF)[15],最大边际矩阵分解算法(MMMF)[16].
尽管矩阵分解算法可以进行较高的推荐,但传统的矩阵分解算法易受矩阵稀疏问题的影响.在真实数据集中,因为用户只对极少数物品进行评分,使得用户评分矩阵极度稀疏,严重影响推荐质量.一种有效的解决方法是利用其它信息,作为对稀疏的评分信息的补充.最常用的方法是考虑用户间的社交信息[17,18].
用户间的社交信息包括信任信息,不信任信息等.研究表明,利用用户之间的社交信息可以有效的提高推荐准确性[19,20].Guo等人基于SVD++算法提出了TrustSVD,TrustSVD利用了用户之间的信任信息构建信任矩阵,同时分解评分矩阵和信任矩阵进行建模推荐[21].与传统的基于社交信息的矩阵分解算法不同,TrustSVD算法考虑了用户之间信任的隐式反馈.尽管TrustSVD算法考虑了用户之间的信任关系,却忽略了用户之间的不信任关系.事实上,研究表明用户之间的不信任关系对提高推荐性能也十分重要[22,23].
本文基于TrustSVD模型提出了一种基于信任信息和不信任信息的非负矩阵分解算法TDSVD,TDSVD算法利用评分信息,用户之间的信任信息和不信任信息进行个性化推荐.本文的主要贡献如下:
1)提出了一种新颖的非负矩阵分解算法TDSVD,与传统的基于信任信息的分解算法不同,TDSVD算法不仅利用了用户之间的信任信息,还利用了用户间的不信任信息,有效的解决了数据稀疏对推荐质量的影响.
2)因为评分矩阵和信任矩阵的非负性,所以对其潜在因子进行了非负约束.而不信任矩阵因其值均为负数,所以对其潜在因子做了负约束,使模型训练时更易收敛,并提高了推荐准确率.
3)在模型训练时,加入了一种新颖的信任正则化和不信任正则化方法.
4)在真实数据集Epinoins实验表明TDSVD算法优于其它的经典算法,显著的提高了预测准确性.
2 相关工作
基于社交的推荐系统已经被广泛的研究.Ma等人提出了一种基于社交的推荐推荐算法SoRec[24],SoRec考虑了社交关系的约束,同时对评分矩阵和信任矩阵进行分解,使评分矩阵和信任矩阵共享同一个潜在因子矩阵.Lyu等人提出了一种社交信任集成方RSTE,RSTE算法将评分矩阵和信任矩阵进行线性组合进行推荐[25].Guo等人基于SVD++算法,提出了TrustSVD算法,TrustSVD不仅考虑了用户之间存在的信任关系,还探究了用户信任的隐式反馈对推荐性能的影响.Yang等人提出了一种混合推荐算法TrustMF,TrustMF分别从信任者与被信任者两个角度考虑了用户之间的信任关系,信任用户和被信任都会都评分产生影响,最后TrustMF将两种信任关系进行组合进行推荐[24].尽管这些推荐算都利用了用户之间的信任信息,但却没有考虑用户之间存在的不信任信息.研究表明,不仅信任信息影响推荐质量,不信任信息也同样影响[26].因此,本文提出了一种新颖的推荐算法TDSVD,既考虑用户之间的信任信息,又考虑不信任信息.
2.1 SVD++算法
假设R=[ru,j]mxn表示评分矩阵,ru,j表示用户u给物品j的评分.u,v表示用户,i,j表示物品.Iu表示用户u评分的物品组成的集合.pu和qj表示用户u和物品j的潜在因子向量.P∈Rk×m表示用户特征矩阵,Q∈Rk×n表示物品特征矩阵.矩阵分解算法将评分矩阵分解成两个低秩矩阵的乘积,即R≈PTQ,这里PT表示矩阵P的转置.
与传统的矩阵分解算法不同,SVD++考虑了用户偏置,物品偏置及已评分的物品对评分的影响,用户u对物品j的预测评分定义为:
(1)
其中bu,bj分别表示用户偏置和物品偏置,μ是评分的平均值,yi表示被用户u评分的物品所产生的隐式影响.通过训练损失公式(2)得到各个参数:
(2)
2.2 TrustSVD算法
TrustSVD算法在SVD++算法的基础上考虑了用户间的信任关系对评分的影响.假设T=[tu,j]m×m表示信任矩阵,P∈Rk×m表示信任者特征矩阵,W∈Rk×m表示被信任者特征矩阵.利用低秩矩阵分解技术,通过T≈PTW来预测用户之间的信任值,且评分矩阵和信任矩阵共享一个相同的潜在因子矩阵P.用户u对物品的预测评分定义为:
(3)
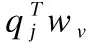
(4)

3 主要结果
3.1 TDSVD算法
用户之间不仅存在信任关系,也存在不信任关系,且用户间的信任与不信任都会对用户的评分产生影响,基于此种假设,本文提出了TDSVD模型.用户u对物品j的预测评分计算方法如公式(5)所示:
(5)

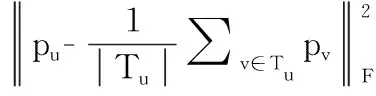
s.t∀u,v,i,j,puk≥0,qjk≥0,yik≥0,wvs≥0,vvs≤0
s∈(1,2,…,m)
(6)
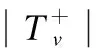
本文采用梯度下降法训练各个参数,具体如下:
(7)
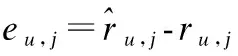
在冷启动问题中,用户可能只评分少量的物品,此时的评分矩阵很稀疏.在此情况下,通过分解信任矩阵T和不信任矩阵D,可以得到更准确的用户特征向量.在特殊情况下,若一些用户没有对物品评分,依然可以通过对信任矩阵和不信任矩阵的分解得到用户的特征向量.所以利用用户间的信任和不信任信息,对评分矩阵,信任矩阵和不信任矩阵同时分解可以在很大程度上解决冷启动问题.
3.2 算法设计和复杂度分析
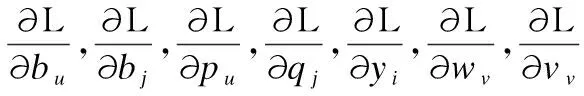
1www.Epinions.com
TDSVD算法步骤如表1所示.

表1 TDSVD算法步骤Table 1 Algorithm steps of TDSVD
4 实验结果与分析
在本节中,我们设计了实验将TDSVD模型与其它出色的推荐算法进行了对比.实验主要解决以下几个问题:
1)与其它出色的推荐算法相比,TDSVD算法的推荐效果如何?
2)超参数λt,λd,λ不同的取值对模型的预测准确性会产生怎样的影响?
3)不同的潜在因子维数对推荐效果有什么样的影响?
4)TDSVD算法的鲁棒性如何?
4.1 数据集
我们选择数据集Epinoins作为我们的实验数据集,因为Epinions是唯一包含不信任信息的公开数据集.Epinions.com1是1999年建立的知识分享的网站,用户可以对物品进行评分,评分区间是[1,5]内的整数.Epinoins数据集中的每个成员都维护着一个信任列表和不信任列表,根据用户的信任关系和不信任关系排序物品.所以Epinoins是进行社交推荐实验的理想数据集.
Epinoins数据集中包含120492个用户,755760个物品,755760个信任值,13668320个评分,123705个不信任值.由于数据的极度稀疏和机器内存的有限,我们根据Epinions构建了两个不相交的子数据集E1,E2.其中E1数据集包含2894个用户,6489个物品,262908个评分值,10887个信任值,15912个不信任值.评分矩阵密度为1.14%,信任矩阵密度为0.13%,不信任矩阵密度为0.19%;E2数据集包含9875个用户,42431个物品,2472130个评分值,12054个信任值,14870个不信任值.评分矩阵密度为0.59%,信任矩阵密度为0.012%,不信任矩阵密度为0.015%.
本文将数据集80%-20%分离,并采用5折交叉验证的方法,重复实验20次,取20次结果的平均值作为最终的结果.所有的实验是在3.5GHz CPU和 16GB内存的戴尔Precision Tower 7910 台式机工作站进行,编程语言是Python 3.7.
4.2 评估指标
本文实验采用MAE(Mean Absolute Error)和RMSE(Root Mean Squared Error)作为评价指标.MAE和RMSE通过计算预测值与真实值之间的误差来度量预测的准确性.MAE和RMSE公式表示为:
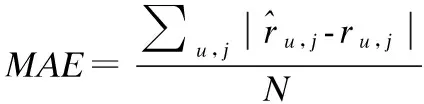
(8)
4.3 鲁棒性检验
为了验证TDSVD算法的鲁棒性,本文对训练集中的评分数据,信任数据,不信任数据加入了高斯白噪声,即
ru,j←ru,j+ε,ε~N(0,δ2)
(9)
tu,v←tu,v+ε,ε~N(0,δ2)
(10)
du,v←du,v+ε,ε~N(0,δ2)
(11)
其中ε服从均值为0,方差为δ2的高斯分布,(当ε=0时,此时没有噪声).
用含有噪声的训练集训练TDSVD模型,之后将训练的模型进行交叉验证.通过度量不同噪声强度下模型的MAE值或RMSE值来验证模型的鲁棒性.
4.4 对比实验和参数设置
本文选择了4个推荐算法作为对照算法,具体如下:
SVD++:是一种基于矩阵分解的推荐算法,在传统矩阵分解的基础上,考虑了用户的隐式反馈.
SoRec:是一种基于概率的矩阵分解算法,在分解评分矩阵的同时分解信任矩阵,可以在一定程度上解决冷启动问题,提高推荐准确率.
SocialMF:是一种基于模型的分解算法,在建立模型时考虑了用户之间的信任传播机制[27].
TrustSVD:是一种基于SVD++算法矩阵分解算法,考虑了用户之间存在的信任关系,并且考虑信任用户之间的显示反馈和隐式反馈.
本文的参数设置为:E1数据集:λ=0.2,λt=0.5,λd=0.5,学习率η=0.5;E2数据集:λ=0.1,λt=0.07,λd=0.2,学习率η=0.5.
4.5 实验结果
表2和表3给出了E1数据集上不同潜在因子维度下MAE和RMSE的取值,从表中可以看出,与其他算法相比,TDSVD算法可以得到最好的结果.当k=5时,TDSVD算法的MAE值为0.824,RMSE值为0.907; 当k=10时,MAE值为0.821,RMSE值为0.904;当k=20时,MAE值为0.819,RMSE为0.902.表4,表5给出了在E2数据集上不同潜在因子维度下MAE和RMSE的值.当k=5时,TDSVD算法的MAE值为0.907,RMSE值为1.104; 当k=10时,MAE值为0.904,RMSE值为1.102;当k=20时,MAE值为0.902,RMSE为1.097.随着潜在因子的维度增加,MAE和RMSE值变小,这是因为随着潜在因子维度增加,模型中变量个数变多,此时模型可以学习得到更准确的参数,所以模型的准确率更高.
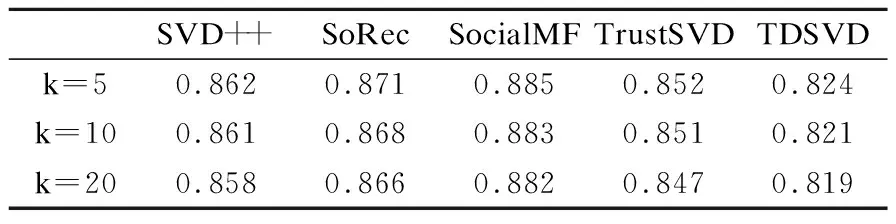
表2 TDSVD在E1数据集上的MAETable 2 MAE of TDSVD on E1 dataset
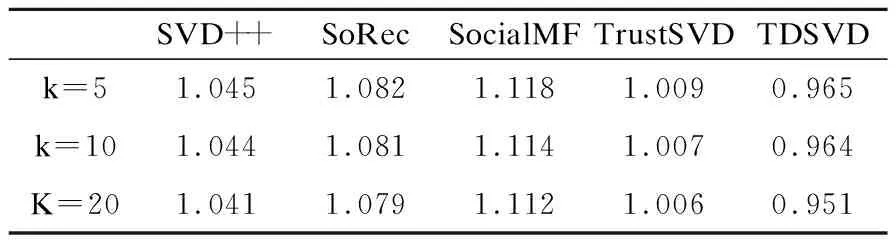
表3 TDSVD在E1数据集上的RMSETable 3 RMSE of TDSVD on E1 dataset

表4 TDSVD在E2数据集上的MAETable 4 MAE of TDSVD on E2 dataset
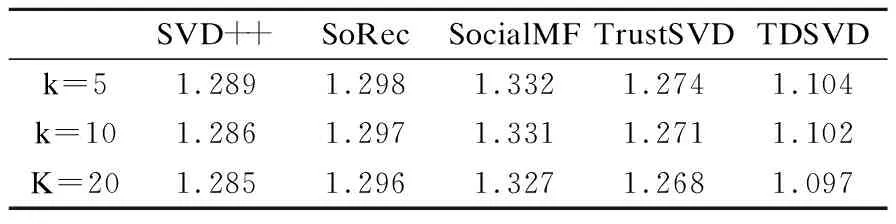
表5 TDSVD在E2数据集上的MAETable 5 MAE of TDSVD on E2 dataset
图1和图2分别描述E1和E2数据集上不同取值的λ,λt,λd对MAE值的影响,从表中可以发现,随着λ,λt,λd取值的增大,MAE的值先减小后增大.对于E1数据集,当λ=0.2,λt=0.5,λd=0.5时MAE取得最小值,此时的推荐效果最佳;对于E2数据集,当λ=0.1,λt=0.07,λd=0.2时MAE取得最小值,此时的推荐效果最佳.
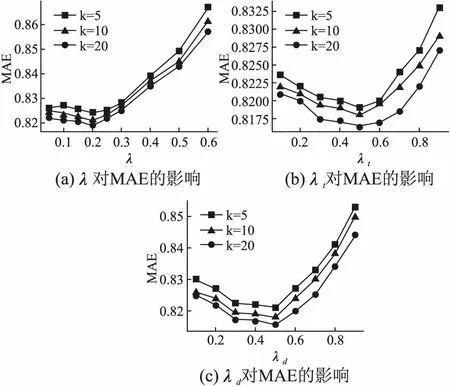
图1 E1数据集上不同对MAE值得影响Fig.1 Different values of on E1 data set affect the MAE value
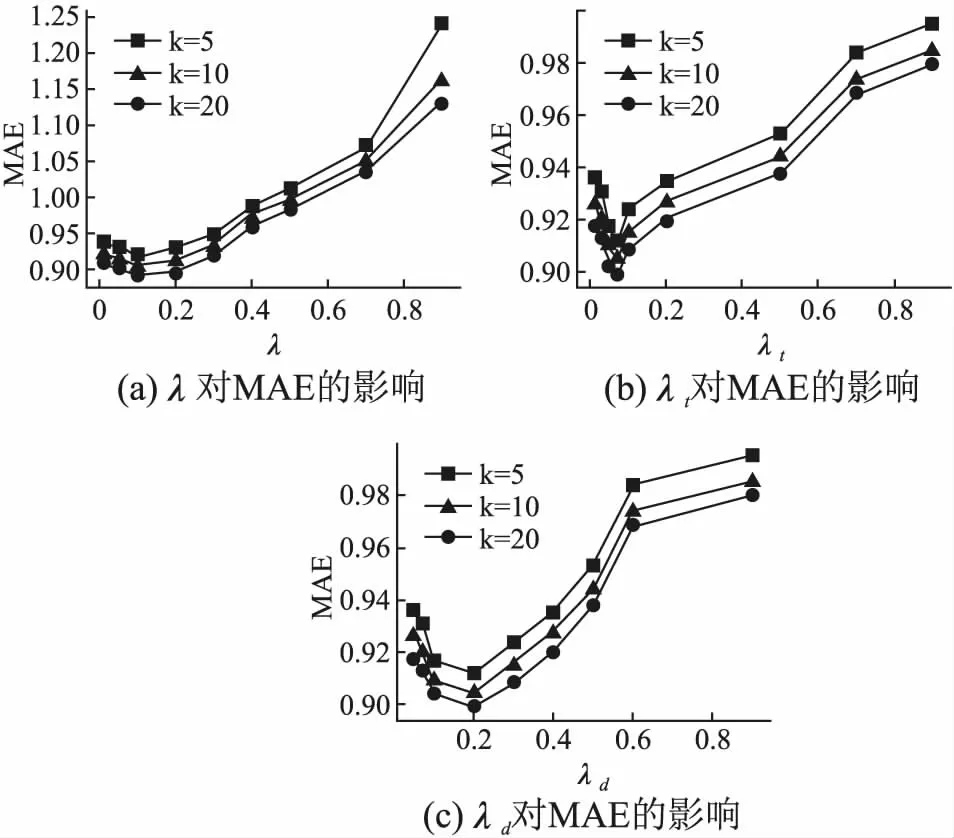
图2 E2数据集上不同对MAE值得影响Fig.2 Different values of on E2 data set affect the MAE value
图3和图4分别E1,E2数据集上不同潜在因子维度下,各个算法的MAE值随迭代次数的变化情况.从图3和图4中可以看出,随着迭代次数的增加,MAE值减小,直至趋于稳定状态.且SVD++算法总是最先达到收敛状态,而TDSVD模型收敛速度慢于其它算法.
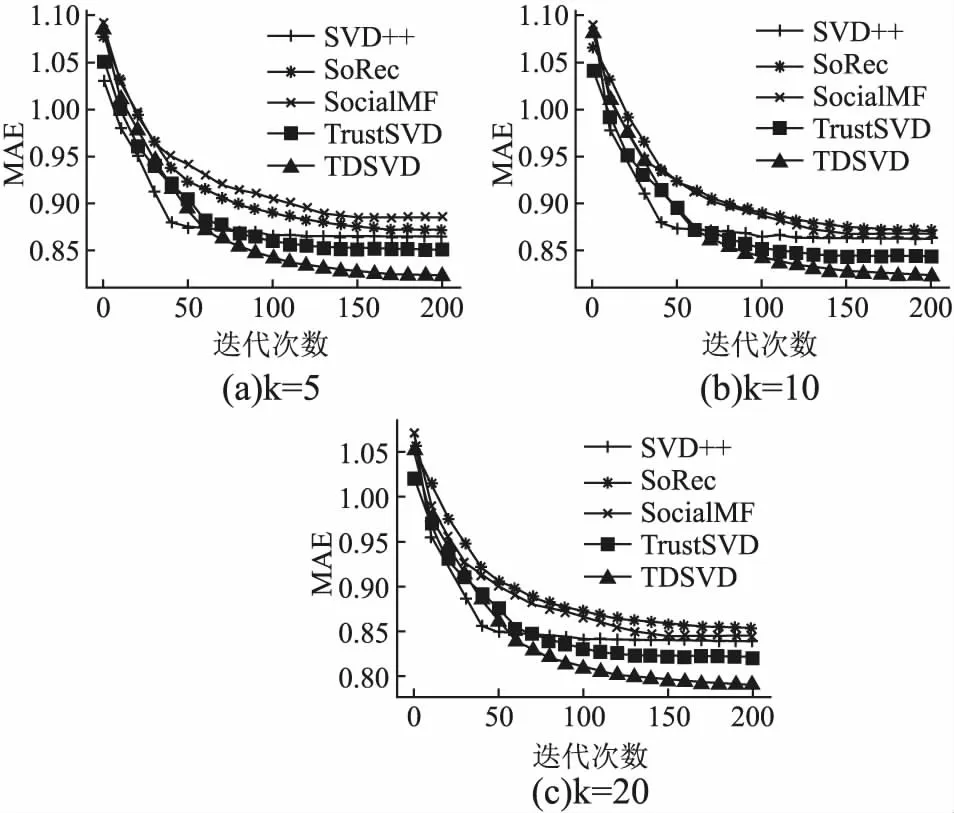
图3 E1数据集上不同潜在因子维数下各模型的迭代图Fig.3 Iterations of each model under different latent factor dimensions on E1 data set
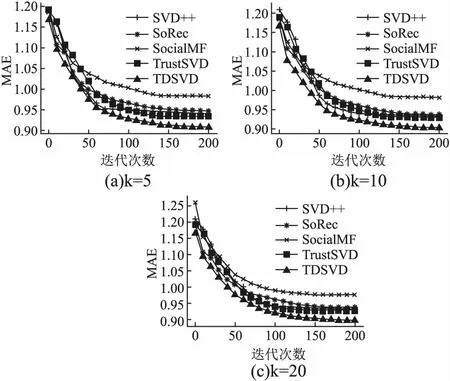
图4 E2不同潜在因子维数下各模型的迭代图Fig.4 Iterations of each model under different latent factor dimensions on E2 data set
图5和图6分别给出了E1,E2数据集在不同噪声强度下MAE值变化的情况,此时潜在因子维数为5,因为其它潜在因子维数情况类似.其中x轴表示噪声强度,y轴表示MAE值,MAE值越小表示模型预测的准确度越高.从图5和图6可以看出,随着噪声强度变化,MAE值也随之发生改变,但变化幅度都很小.在E1数据集上MAE的变化幅度为0.004,E2数据集上MAE的变化幅度为0.003,这说明模型具有较强的鲁棒性.

图5 E1数据集上不同噪声强度对模型预测准确度的影响Fig.5 Influence of noise intensity on prediction accuracy of model (E1 datasets)
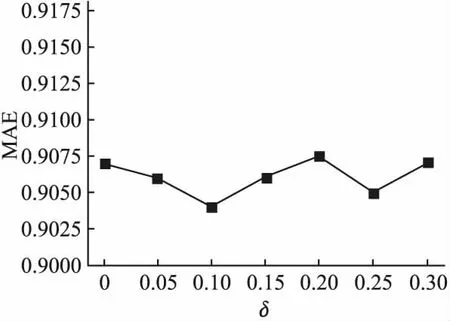
图6 E2数据集上不同噪声强度对模型预测准确度的影响Fig.6 Influence of noise intensity on prediction accuracy of model on E2 data set
表6和表7分别给出了各个模型在E1和E2数据集上的平均收敛时间.从表中可以看出,SVD++模型收敛时间最快,而TDSVD模型收敛时间最慢.这是因为在本文所选的对比模型中,SVD++模型是最简单的模型,其只对评分矩阵进行分解,而SoRec、SocialMF、TrustSVD算法考虑了信任信息,这些算法对评分矩阵和信任矩阵同时进行分解来进行推荐,所以这些算法的收敛速度慢于SVD++算法.而本文所提出的算法TDSVD因为考虑评分信息,信任信息,不信任信息,所以算法收敛时间较长.虽然与其它算法相比TDSVD需要耗费较长的时间进行训练,但TDSVD的推荐效果最好,所以在实际应用中应该根据具体情况进行合理的选择.

表6 E1数据集上算法的平均收敛时间(秒)Table 6 Average converge time of models on E1 data set(s)
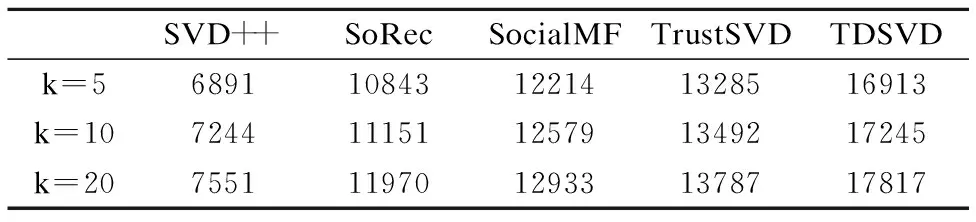
表7 E2数据集上算法的平均收敛时间(秒)Table 7 Average converge time of models on E2 data set(s)
5 结束语
推荐系统能够有效的解决互联网中的信息过载问题,为用户推荐感兴趣的项目.本文针对推荐系统算法易受数据稀疏的影响,提出了基于评分信息,信任信息和不信任信息的矩阵分解算法TDSVD.与传统的基于社交信息的分解算法不同,TDSVD考虑了用户间的不信任信息,能很大程度上解决数据稀疏性问题,提高推荐准确性.最后在真实稀疏数据集上的实验也说明了TDSVD算法优于其它算法.将来可以对TDSVD进行进一步拓展,如考虑时间因素.真实数据集包含不同时间的评分信息,所以可以通过考虑时间因素来提高TDSVD算法的鲁棒性.此外,可以通过研究用户间信任与不信任的传播机制,更加准确的度量用户间的信任与不信任关系.最后,可以通过尝试使用不同的损失函数和正则化项来优化模型也是未来的一个研究方向.
