基于相似度评分与二级子系统的设计模式识别
2023-01-27王雷王文发宋慧娜张帅
王雷,王文发,宋慧娜,张帅
(1.延安大学数学与计算机科学学院,陕西延安 716000;2.陕西省能源大数据智能处理省市共建重点实验室,陕西延安 716000;3.延安大学 上海文思海辉联合实验室(大数据应用开发方向),陕西 延安 716000)
0 概述
设计模式[1-3]是解决某个特定面向对象软件问题的特定方法,使人们更加简单方便地复用成功的设计和体系结构。现代软件业广泛采用设计模式来重用最佳实践,以提高软件系统的质量。从源代码或系统设计(例如统一建模语言(Unified Modeling Language,UML)模型)中自动识别相应的设计模式,可以为面向设计模式的软件理解、维护和重构等活动提供自动化支持[4-5]。自软件设计模式提出以来,设计模式的识别成为逆向软件工程领域中非常重要的研究课题。
在GoF 设计模式提出后不久,少数研究人员对设计模式的识别进行研究。例如,KRAMER 等[6]提出一种自动搜索面向对象软件的结构设计模式方法。近年来,越来越多的研究人员致力于设计模式识别的研究。设计模式识别技术主要分为基于传统技术和基于机器学习的设计模式识别方法。基于传统技术的设计模式识别方法使用图论算法、可扩展标记语 言(XML)、抽象语法树(Abstract Syntax Tree,AST)等技术将系统和模板设计模式进行匹配,以寻找系统中的模式实例。而基于机器学习的设计模式识别方法通过从实际应用中实现的设计模式实例中学习规则,以预测未知系统中的模式识别。这些方法大多直接将原系统与设计模式进行匹配,限制了其召回率或精确率。
为此,在前期研究[7-8]的基础上,本文进一步探索基于相似度评分和二级子系统的设计模式识别(SSDPD)方法。提出一种系统和设计模式的有向图/矩阵表示方法。在此基础上,对待考查系统划分为若干个子系统,并将子系统进一步拆分和重组为二级子系统。利用相似度评分算法判断二级子系统是否为模式实例,并将判断结果进行合并做进一步处理,以获取最终的模式实例。
1 设计模式识别
1.1 基于传统技术的设计模式识别方法
研究人员提出 很多基于逻辑推理[6,9]、图论算法[10-12]、可扩展标记语言[13-15]、抽象语法树[16-17]、本体技 术[15,18]、抽象语义图[19]、形式化技术[20]、规 则[21-23]等传统技术的设计模式识别方法。
基于传统技术的设计模式识别方法的一般流程:首先,从源代码和模式中提取相关特征值,例如类、属性、操作以及类之间的不同关系;然后,将设计模式转换为某种具有严格语义的形式,根据提取到的源代码信息,将系统转换为相应的某种具有严格语义的形式;最后,将系统和设计模式转换为某种具有严格语义的形式后,通过执行模式匹配算法将子系统和模板设计模式进行匹配,若匹配成功,则认为子系统为模式(候选)实例,否则排除。
1.2 基于机器学习技术的设计模式检测
近年来,机器学习技术开始兴起,为设计模式的识别提供了一个新的途径。设计模式识别规则非常复杂和灵活,而机器学习算法可以从实际应用中实现的设计模式实例中学习规则。研究人员将决策树[24-25]、聚类[24-25]、支持向量机[26-27]、线性回归[27]、人工神经网络[28-30]、关联分析[31]、集成学习[32-34]等机器学习技术用于设计模式的识别。这些方法的一般流程:首先,从实际软件系统中构造正负样本;然后,在得到正负样本后,经过特征提取、特征选择及特征转换,使用机器学习算法对特征向量进行学习,以获取设计模式分类器模型;最后,使用决策模型对未知系统进行设计模式的检测。
上述两大类方法已经取得了一定的效果。然而,这些方法大多直接将原系统与设计模式进行匹配,以寻找系统中的模式实例。设计模式在实际的工程项目中通常会有各种各样的模式变体,这些变体难以与模板设计模式完全匹配。此外,设计模式还存在模式实例中的多个类关联同一个模式角色或一个子系统中包含同一种模式的多个实例的情况。因此,将原系统直接与模板设计模式相匹配会引入大量的假阴性或假阳性实例,使得召回率或精确率下降。
2 基本流程
本文对前期研究[7-8]中的基于相似度评分系统与二级子系统的设计模式识别方法的基本流程进行细化。本文方法的基本流程如图1 所示。
3 系统信息的提取与有向图/矩阵表示
3.1 系统信息的提取
从系统中设计模式的识别需要提取系统信息。本文对系统的UML 类图的XML 文件进行解析来获取关联、泛化、依赖、抽象类、子类对象创建、抽象方法调用等信息,并对这些信息进行存储。
对于缺乏UML 设计文档而只有源代码形式的系统,本文借助UML 建模工具的逆向工程功能将源代码转化为UML 类图模型,然后再对转化得到的UML 类图进行解析以获取相关信息。
3.2 系统与设计模式的有向图/矩阵表示
由于本文使用相似度评分算法计算系统和设计模式之间的相似度矩阵来寻找系统中存在的模式实例,因此提取到系统的关联、泛化、依赖、抽象类、子类对象创建、抽象方法调用等信息后,根据这些信息将系统表示为有向图/矩阵形式。此外,将设计模式也同样表示为有向图/矩阵形式并提前存储。
在前期研究中[7-8]考虑关联、泛化(包括接口与类之间的实现关系)、依赖、聚合、抽象类、对象创建、抽象方法调用、无子类8 个特征。本文去掉了无子类特征,其原因为无子类特征并不能用于区分模式角色和非模式角色。例如在状态模式的结构描述中,角色ConcreteState 无子类,但对应角色ConcreteState 的类SelectionTool 却有子类。去掉聚合特征的原因为聚合事实上是关联的特例,因此,本文不再专门考虑聚合特征。此外,由于创建某个类的子类对象比某个类的对象更能标识设计模式的存在,因此本文将文献[7-8]的“对象创建”特征修改为“子类对象创建”特征。
文献[7-8]提出一种系统和设计模式的有向图/矩阵表示,分别定义了系统或设计模式的关联关系有向图/矩阵、泛化关系有向图/矩阵、依赖关系有向图/矩阵、聚合关系有向图/矩阵、抽象类有向图/矩阵、对象创建有向图/矩阵、抽象方法调用有向图/矩阵以及无子类有向图/矩阵。本文所提的系统和设计模式的有向图/矩阵表示在此基础上去掉无子类有向图/矩阵,并将对象创建有向图/矩阵修改为子类对象创建有向图/矩阵。关联关系有向图/矩阵、依赖关系有向图/矩阵、聚合关系有向图/矩阵、抽象类有向图/矩阵、抽象方法调用有向图/矩阵的定义请参见文献[7-8]。本文给出子类对象创建有向图/矩阵的定义。
定义1系统或设计模式的子类对象创建有向图定义为有向图GSubClCre=(V,E)。其中:1)V中的每个顶点对应系统或模式中的一个类;2)E中的每条边对应一个子类创建关系,该条边由创建实例的类指向被实例化的子类对象。
该有向图的邻接矩阵称为子类对象创建矩阵,定义为:
本文以状态模式来说明设计模式的表示。对于设计模式结构的描述主要参考文献[3],并做了如下改进:
1)文献[3]中模式的结构是利用对象建模技术(Object Modeling Technique,OMT)进行描述,本文在此基础上用UML 进行描述。
2)删减特征完全相同的角色,以提升匹配的准确率及时间效率。例如,文献[3]中的角色ConcreteStateA、ConcreteStateB … 的特征完全相同,故只保留一个。
改进的状态模式结构描述如图2 所示。
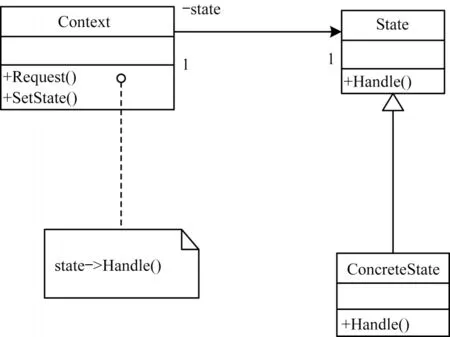
图2 改进的状态模式结构描述Fig.2 Description of improved state pattern structure
记Context、State 和ConcreteState 分别为c1、c2和c3。根据上述定义,可得状态模式的有向图/矩阵表示,如图3 所示。其他22 种设计模式的有向图/矩阵表示参见文献[7-8]。

图3 状态模式的有向图/矩阵表示Fig.3 Directed graph/matrix representation for the state pattern
4 子系统的划分与二级子系统的构建
4.1 子系统的划分
本文首先将待考查系统划分为若干子系统。子系统的划分方法请参见文献[7-8]。
本文给出JHotDraw 5.1 的一个针对不包含继承层或只包含一个继承层的设计模式子系统,记为s1。子系统s1的UML 类图如图4 所示。该子系统共包含38 个类(接口)和一个继承层。将图4 中各个类(接口)从左至右、从上至下分别记为C1,C2,…,C38,可得子系统s1的有向图/矩阵表示,图5 所示为泛化关系有向图/矩阵。

图4 开源项目JHotDraw 5.1 的子系统s1的UML 类图Fig.4 UML class diagram of subsystem s1 of open source project JHotDraw 5.1
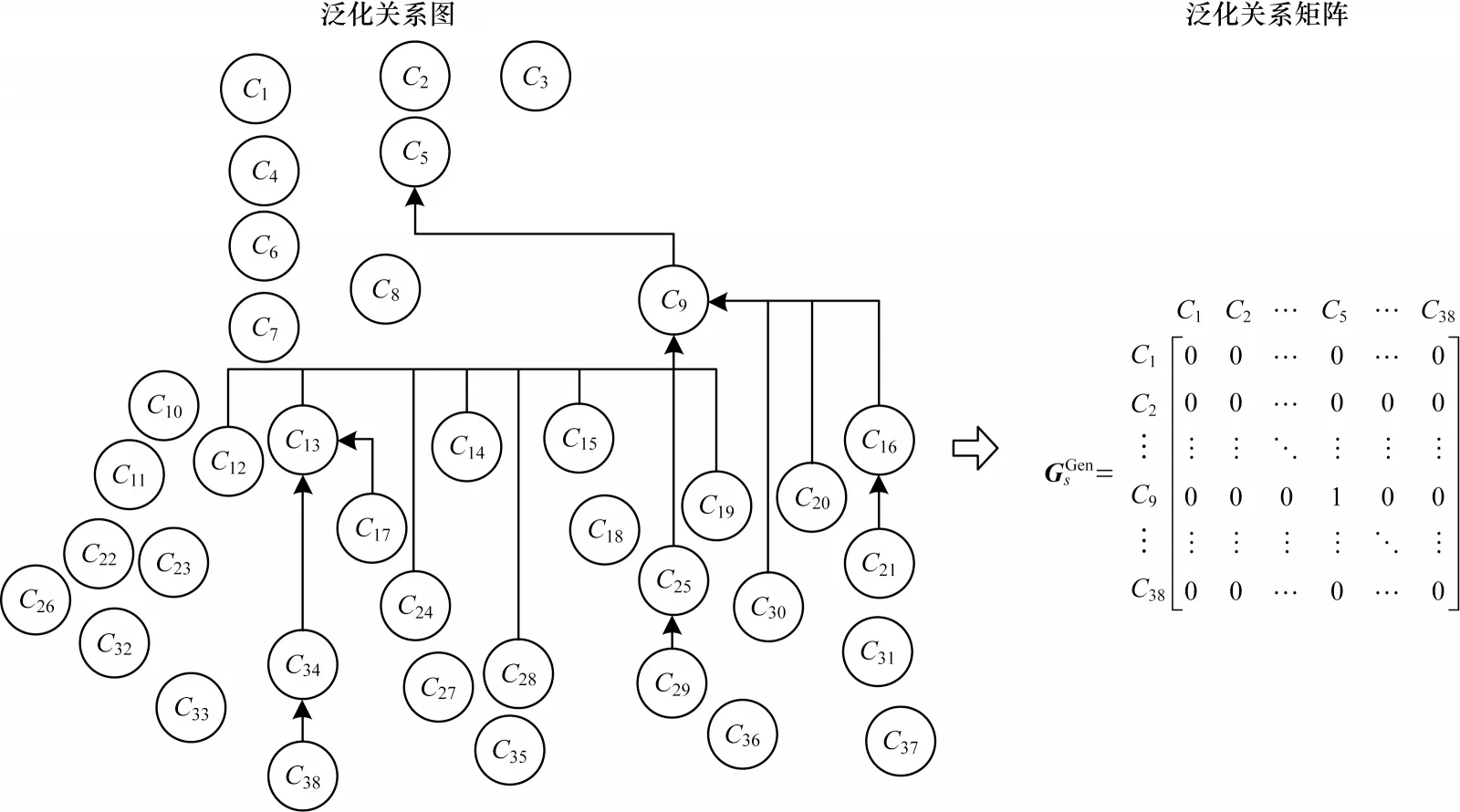
图5 子系统s1的泛化有向图/矩阵表示Fig.5 Generalization directed graph/matrix representation of subsystem s1
4.2 原系统直接匹配的问题
现有设计模式识别方法大多直接将原系统与模式进行匹配来识别模式实例。本文以文献[10]为例,说明将原系统直接与模式进行匹配存在的问题:
1)在通常情况下,子系统会包含一些不关联任何模式角色的类,这些类会干扰匹配的精度。设有子系统s2,其UML 类图如图6 所示。
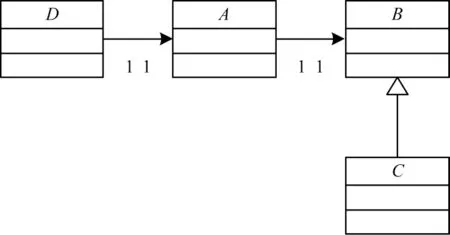
图6 子系统s2的UML 类图Fig.6 UML class diagram of subsystem s2
其中,类D不关联任何模式角色,经计算(详细算法请参见第5 节,为方便说明这里只考虑“泛化”特征和“关联”特征),子系统s2与状态模式之间的相似度矩阵为:

在子系统中类C和状态模式的角色c3(ConcreteState)的相似度分数为1.000 0,根据文献[10]所提的方法说明存在状态模式,且类C关联c3(ConcreteState)。本文分别考察c1(Context)列和c2列的最大值,c1(Context)列的最大值为0.500 0,对应类{A,D},c2(State)列的最大值为0.750 0,对应类B。组合可得两个状态模式实例:第1 个实例的类A、类B、类C分别关联状态模式的角色c1(Context)、c2(State)、c3(ConcreteState);第2 个实例的类D、类B、类C分别关联状态模式的角色c1(Context)、c2(State)、c3(ConcreteState)。显 然,第2 个实例是一个假阳性实例。
2)文献[10]所提的方法在根据相似度矩阵判断是否存在模式实例时,只要有一列的某个元素值超过阈值就认为存在模式实例,虽然某些类与角色关联,但是相似度评分却比较低。若一个模式角色关联子系统中的多个类,这些类的相似度分数通常比较低。设有子系统s3,其UML 类图如图7 所示。
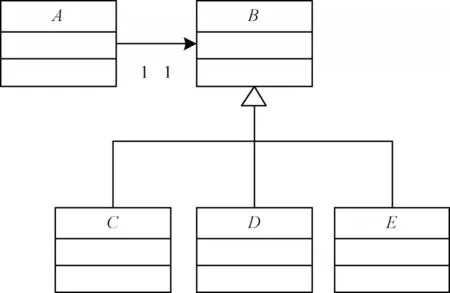
图7 子系统s3的UML 类图Fig.7 UML class diagram of subsystem s3
状态模式的角色c3(ConcreteState)和类C、c3(ConcreteState)和类D、c3(ConcreteState)和类E的相似度分数均仅为0.333 3,为方便说明,本文仅考虑泛化特征和关联特征。只要有一列的某个元素值超过阈值就认为存在模式实例,会引入大量的假阳性实例,导致精确率下降。
3)某个子系统可以包含某种模式的多个实例,文献[10]所提方法通过组合对应于各个角色的类来构建模式实例,这可能会引入假阳性实例。设有子系统s4,其UML 类图如图8 所示。根据文献[10]所提的方法,得到4 个状态模式实例(只考虑泛化特征和关联特征):(B,A,C,E)、(D,C,E)、(B,C,E)、(D,A,C,E)。显然,实例(B,C,E)和(D,A,C,E)为假阳性实例。
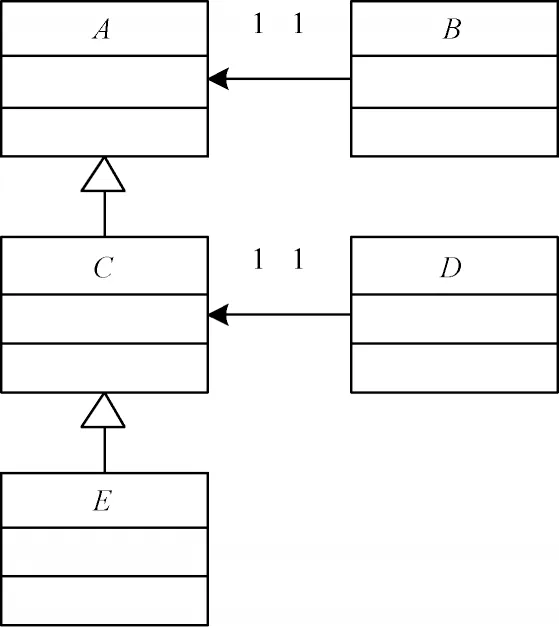
图8 子系统s4的UML 类图Fig.8 UML class diagram of subsystem s4
4.3 二级子系统的构建
本文通过对子系统中的类及其之间的关系进行删减和重组,将子系统进一步划分为若干个类个数与待识别模式中角色个数相等的二级子系统。本文对文献[7-8]中二级子系统的构建方法进行修正,除泛化关系以外的其他关系,即关联、依赖、抽象类、子类对象创建、抽象方法调用,将直接删减从被删减类出发的关系和指向被删减类的关系,而不再进行重组。修正后构建某个子系统s的针对模式p二级子系统的算法如下:
步骤1置集合Class={C1,C2,…,Cn}为子系统s的所有类构成的集合,其中n为子系统s中类的个数。
步骤2每次从集合Class中取出t个类构成一个新的集合,其中t为模式p中角色的个数,可构成个不同的子集合。
步骤3每个子集合对应一个二级子系统,该二级子系统中的类为该子集合中的类,二级子系统中类的关系为原子系统中类的关系删减与重组。对于某种关系(关联、泛化、依赖、抽象类、子类对象创建、抽象方法调用),删减与重组的规则如下:
1)对于关联、依赖、抽象类、子类对象创建、抽象方法调用关系,直接删减从被删减类出发的关系和指向被删减类的关系。
2)对于泛化关系,分以下3 种情况讨论:(1)若被删减类只存在指向该类的关系,则直接删减这些关系;(2)若被删减类只存在从该类出发的关系,则直接删减这些关系;(3)若被删减类既有从该类出发的关系,又有指向该类的关系,则删减从该类出发的关系,而将指向该类的关系重新指向从该类出发的关系指向的类。
步骤4去除不包含泛化关系的二级子系统,以及存在没有任何关系的两个类(也没有通过其他类产生关联)的二级子系统,例如,子系统s由类C25(ActionTool)、C29(BorderTool)和C30(PolygonTool)构成的二级子系统,其中,C29(BorderTool)和C30(PolygonTool)没有关联,其余二级子系统为最终的二级子系统。
单件模式只包含一个角色,则二级子系统只包含一个类。例如,子系统s2中类的个数为4,状态模式中角色的个数为3,则从4 个类中选择3 个类共有=20 种不同的选法。去除掉不包含泛化关系的1 种选法(二级子系统(D,A,B)和存在没有关联的两个类的2 种选法,即二级子系统(D,A,C)和(D,B,C)),最终得到1 个二级子系统。
本文考虑图4 所示的JHotDraw 5.1 的子系统s1的4 个二级子系统,分别记为其中二级子系统s′11由子系统s1中的类C1(AlignCommand)、C5(Tool)和C12(ConnectionTool)组 成,由类C8(DrawingView)、C5(Tool)和C12(ConnectionTool)组成,由类C5(Tool)、C16(SelectionTool)和C14(DragTracker)组 成,由类C5(Tool)、C16(SelectionTool)和C13(CreationTool)组成。二级子系统的有向图/矩阵表示分别如图9和图10 所示。和的有向图/矩阵表示类似。

图9 二级子系统 的有向图/矩阵表示Fig.9 Directed graph/matrix representation of secondary subsystem
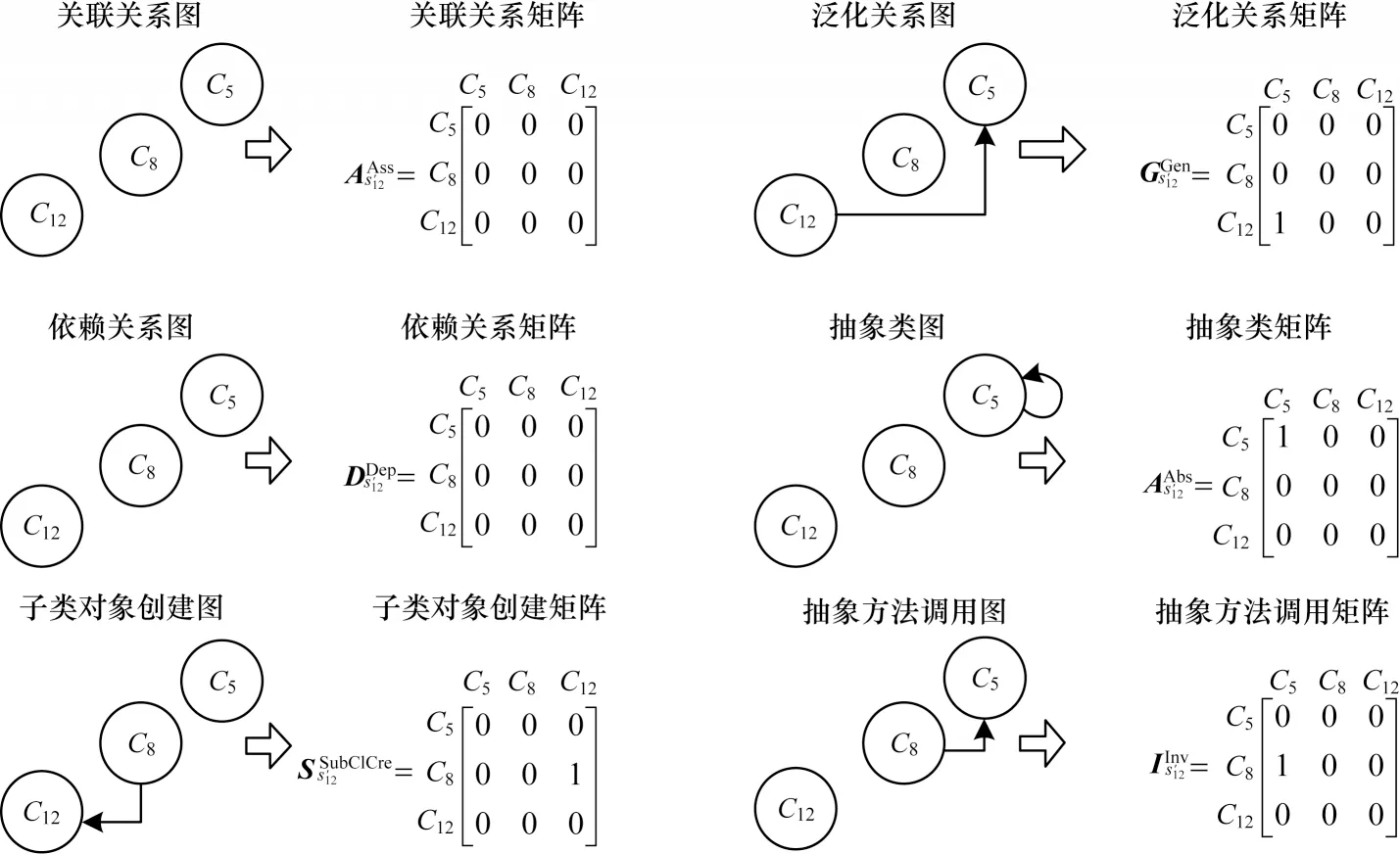
图10 二级子系统 的有向图/矩阵表示Fig.10 Directed graph/matrix representation of secondary subsystem
5 相似度矩阵的计算
本文将系统划分为二级子系统后,依次计算各二级子系统的有向图/矩阵和设计模式的有向图/矩阵之间的相似度矩阵。二级子系统s′和p 设计模式之间的关联相似度矩阵等6 个相似度矩阵和总相似度矩阵的计算公式以及总相似度矩阵的归一化公式请参见文献[7-8]。本文以状态模式和图4 所示的JHotDraw 5.1 子系 统s1的二级子系 统为例,说明相似度评分的计算过程。经计算可得状态模式和二级子系统之间的相似度矩阵为:


归一化总相似度矩阵为:


某个二级子系统s′和某种设计模式p之间的相似度矩阵Similatirys′,p的计算流程如图11 所示。

图11 相似度矩阵算法的计算流程Fig.11 Calculation procedure of similarity matrix algorithm
6 二级子系统的判断
相似度矩阵的元素表示二级子系统中的类和模式角色之间的相似度得分,因此可以根据相似度矩阵判断二级子系统是否为模式实例。二级子系统是否为模式实例的判断方法参考文献[7-8]。
状态模式中的角色c1(Context)、c2(State)和c3(ConcreteState)分别涉及3、4、2 个特征,取c1(Context)、c2(State)和c3(ConcreteState)的阈值分别为:=0.666 7,=0.750 0,=1.000 0。

并非所有列均有至少一个元素值大于等于该列对应角色的阈值,则说明二级子系统不是状态模式的实例。
对于:
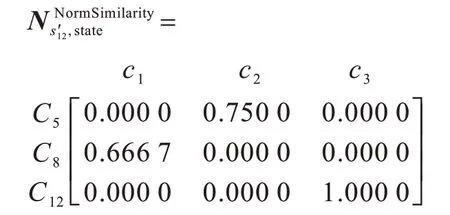
所有列均有至少一个元素的值大于等于该列对应角色的匹配临界值,则说明二级子系统为状态模式的实例。在c1(Context)对应的列中,值最大的元素对应C8(DrawingView)行,则说明二级子系统中的类C8(DrawingView)关联状态模式的角色c1(Context)。类似地,可以得到二级子系统中的类C5(Tool)、C12(ConnectionTool)分别关联状态模式的角色c2(State)、c3(ConcreteState)。
同理,二级子系统为状态模式的实例,且二级子系统中的类C16(SelectionTool)、C5(Tool)和C14(DragTracker)分别关联状态模式的角色c1(Context)、c2(State)、c3(ConcreteState),而二级子系统不是状态模式的实例。
类似地,可以判断JHotDraw 5.1 的子系统s的其他二级子系统是否为模式实例。
7 判断结果的进一步处理
对于系统中的一个模式实例,通常存在多个类关联同一个模式角色的情况。例如,在状态模式中,角色ConcreteState 关联多个代表具体状态的类。此外,还存在着一个子系统中包含同一种模式的多个实例的情况。因此,本文需要对某种模式p实例中某个子系统s的二级子系统进行进一步处理,对文献[7-8]中判断为模式实例的二级子系统的进一步处理算法进行修正和细化,修正和细化后算法的步骤如下:
步骤1若所有二级子系统只有一个被判断为模式p的实例,则说明子系统s只包含该设计模式的一个实例,且每个模式角色关联子系统中的一个类。否则转到步骤2。
步骤2若被判断为模式p的实例的l(l≥2)个二级子系统无公共类,则说明子系统s包含该设计模式的l(l≥2)个实例,且每个模式实例的每个类关联模式p的一个角色。否则转到步骤3。
步骤3设被判断为模式p的实例的l(l≥2)个二级子系统的集合为I={i1,i2,…,il},对于集合I中存在公共类的任 意两个二级子系统和,做如下处理:
1)若每个公共类分别关联同一个模式角色,而两个二级子系统中的非公共类共同关联同一个角色,则为以下两种情况:(1)非公共类共同关联的角色是子类,则将这两个实例合并为一个实例,然后将集合I中合并前的两个实例删除,将合并得到的新实例加入集合I中;(2)若非公共类共同关联的角色不是子类,则不需要进行合并。
2)若每个公共类分别关联同一个模式角色,而和中的某个非公 共类各自关联不同的角色,则不需进行合并。
3)若存在某个公共类在两个二级子系统中关联不同的模式角色,则不需进行合并。
重复以上过程直到集合I中不存在可以合并的两个实例,此时集合I中的实例为最终的实例。
本文以图4 所示的JHotDraw 5.1 的子系统s1和状态模式为例,说明如何对判断为模式实例的二级子系统进一步处理。子系统s1的二级子系统被判断为状态模式实例。将类C8(DrawingView)、C5(Tool)和C13(CreationTool)构成的二级子系统记为,经计算可知,也是状态模式实例。二级子系统和有公共类C5(Tool)和C8(DrawingView),分别关联角色c1(Context)和c2(State),非公共类C12(ConnectionTool)和C13(CreationTool)均关联模式角色c3(ConcreteState),且角色c3(ConcreteState)为子类,则将二级子系 统和合并为一个实 例。类 似地,可以继续与C8(DrawingView)、C5(Tool)、C14(DragTracker)等构成的14 个二级子系统合并,最终得到的实例如图12 所示,其中灰色填充的类为该实例的类,加粗边框的16 个类共同关联同一个模式角色c3(ConcreteState)。

图12 子系统s1的一个状态/策略模式实例Fig.12 A state/strategy pattern instance of subsystem s1
二级子系统也被判断为状态模式实例。二级子 系统和有公共 类C5(Tool),并关联角色c2(State),非公共类C8(DrawingView)和C16(SelectionTool)均关联角色c1(Context),但角色c1不是子类,因此不需要进行合并。而可以和与C16(SelectionTool)、C5(Tool)和C15(HandleTracker)等构成的2 个二级子系统合并,最终得到的实例如图13 所示,其中灰色填充的类为该实例的类,加粗边框的 3 个类共同关联模式角色c3(ConcreteState)。

图13 子系统s1的另一个状态/策略模式实例Fig.13 Another state/strategy pattern instance of subsystem s1
因为状态模式和策略模式的有向图/矩阵完全相同,所以上述两个实例也可以认为是策略模式的候选实例。
8 实验与结果分析
本文使用文献[12]所提的方法、文献[10]所提的方法、文献[34]所提的方法和本文方法SSDPD 在三个开源项目上进行实验,并从精确率、召回率和CPU 时间花费三个指标对实验结果进行分析和讨论。
8.1 实验环境与实验数据
本文使用JavaWeb 技术,以Eclipse 工具作为开发环境研发本文方法的支撑工具。该工具是本文在文献[7-8]中的所研发设计模式识别工具的更新和升级版本,命名为EasyDetector 2.0。
实验的运行环境:Windows 10 操作系统、Genuine Intel®CPU(核心数为4,线程数为8)、16 GB内存、2.40 GHz 主频、500 GB 硬盘。
开源项目JHotDraw、JRefactory 和JUnit 包含大量的设计模式实例,这些项目的文档较详细地记录了设计模式使用的信息,因此,被用于设计模式识别方法的验证。本文选用JHotDraw 5.1、JRefactory 2.6.24 和JUnit 3.7 作为实验数据。
8.2 评估指标与结果分析
本文的准确率评估指标与文献[7-8]相同,通过CPU 时间花费来评估时间效率。
表1~表3 分别所示为文献[10]方法、文献[12]方法、文献[34]方法和本文方法SSDPD 对三个开源项目进行设计模式识别的准确率对比。
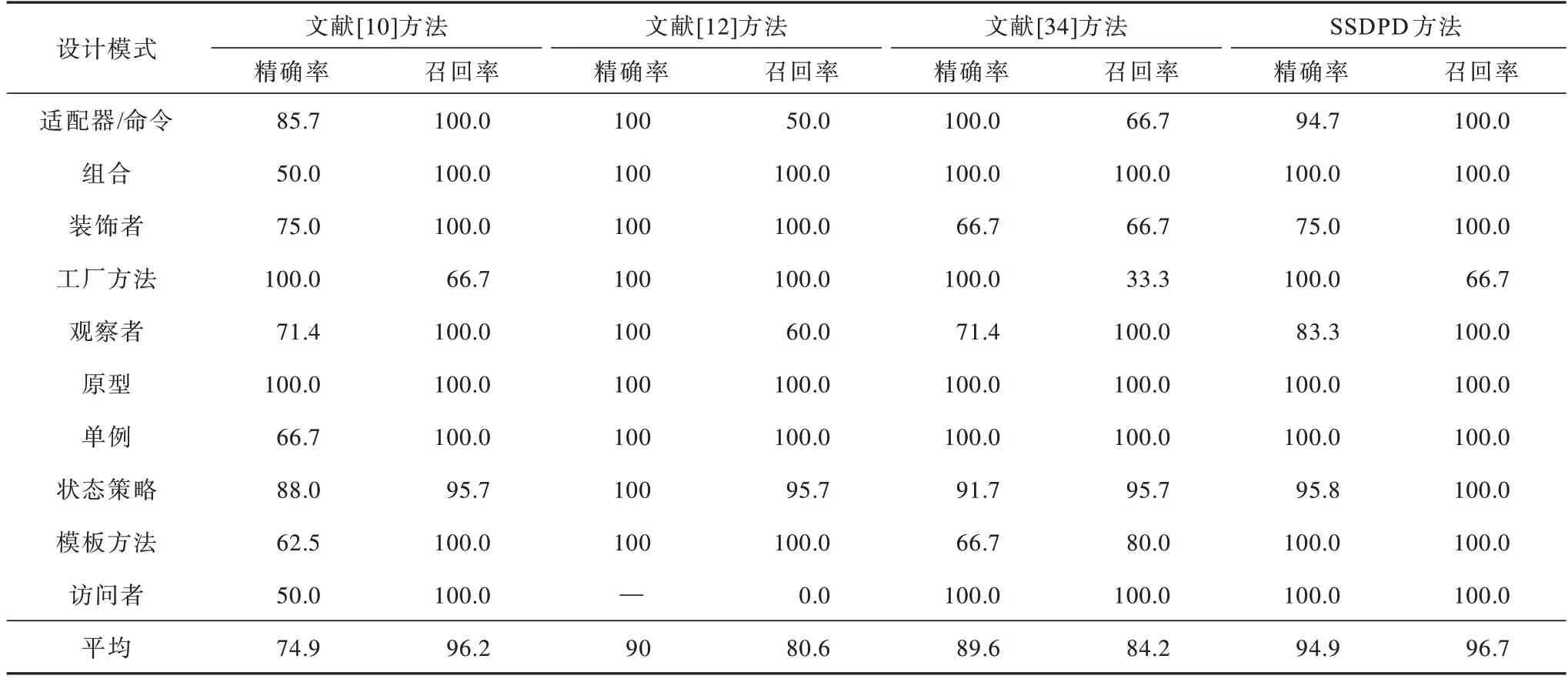
表1 不同方法对JHotDraw 5.1 的识别准确率对比Table 1 Recognition accuracy comparison among different methods for JHotDraw 5.1 %
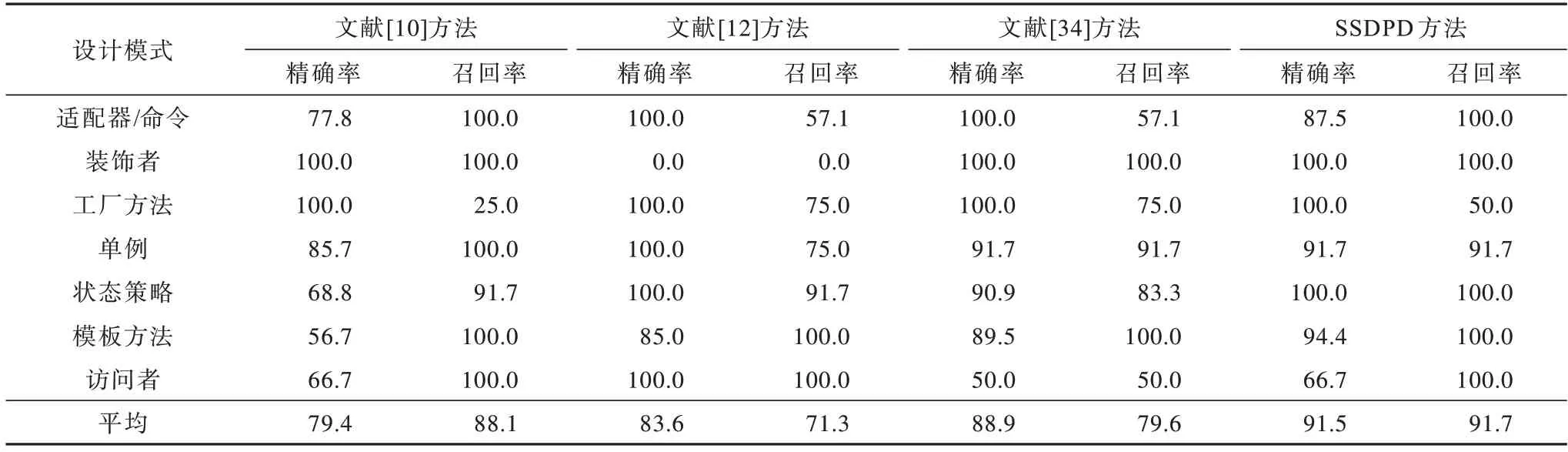
表2 不同方法对JRefactory 2.6.24 的识别准确率对比Table 2 Recognition accuracy comparison among different methods for JRefactory 2.6.24 %

表3 不同方法对JUnit 3.7 的识别准确率对比Table 3 Recognition accuracy comparison among different methods for JUnit 3.7 %
从表1~表3 可以看出:文献[12]方法、文献[10]方法、文献[34]方法的JHotDraw 5.1 平均精确率/召回率分别为90.0%/80.6%、74.9%/96.2% 和89.6%/84.2%;JRefactory 2.6.24 平均精确率/召回率分别为83.6%/71.3%、79.4%/88.1%、88.9%/79.6%;JUnit 3.7 平均精确率/召回率分别为100.0%/95.8%、60%/100%、95.8%/91.7%。文献[12]方法在三个项目上均取得了较高的精确率,但对JHotDraw 5.1 和JRefactory 2.6.24 识别的召回率较低。与文献[12]方法相比,文献[10]方法在三个项目上均取得了较高的召回率,但精确率都较低,尤其是JUnit 3.7 的精确率仅为60.0%。其原因为这两种方法都直接将原系统与设计模式进行匹配,引入大量的假阳性或假阴性实例。匹配标准的提高会在一定程度上提高精确率,但导致召回率下降,而降低匹配的标准会提升召回率,导致精确率较低。文献[34]方法保持了精确率和召回率的平衡,但除JUnit 3.7 以外,其他两个项目的精确率和召回率均未达到90%。本文方法使用二级子系统进行更精确地匹配,使得精确率和召回率较文献[12]方法、文献[10]方法和文献[34]方法均有所提升。
表4~表6 分别所示为文献[12]方法、文献[10]方法、文献[34]方法和本文方法SSDPD 对三个开源项目进行设计模式识别的CPU 时间花费。其中文献[34]方法的预处理主要是指分类模型的训练。

表4 不同方法的JHotDraw 5.1 CPU 时间花费Table 4 JHotDraw 5.1 CPU time cost among different methods 单位:ms

表5 不同方法的JRefactory 2.6.24 CPU 时间花费Table 5 JRefactory 2.6.24 CPU time cost among different methods 单位:ms

表6 不同方法的JUnit 3.7 CPU 时间花费Table 6 JUnit 3.7 CPU time cost among different methods 单位:ms
从表4~表6 可以看出,对于JHotDraw 5.1,文献[12]方法、文献[10]方法、文献[34]方法分别花费9 167 ms、7 494 ms 和5 648 012 ms,而本文方法仅用5 408 ms。对于JRefactory 2.6.24,文献[12]方法、文献[10]方法、文献[34]方法分别花费33 189 ms、29 777 ms 和5 649 046 ms,而本文方法仅用22 280 ms。对于JUnit 3.7,文献[12]方法、文献[10]方法、文献[34]方法分别花费4 865ms、4 799 ms 和5 647 797 ms,而本文方法仅用3 284 ms。由于划分二级子系统花费额外的时间,因此本文方法在预处理阶段的时间花费相较于文献[12]方法和文献[10]方法更多。然而,通过二级子系统的划分,大幅缩小了搜索空间,与文献[10,12]方法相比,本文的设计模式识别阶段节省了大量时间。本文方法将子系统进一步划分为若干个二级子系统,增加了矩阵运算的次数,在一定程度上会影响时间效率。同时,二级子系统的划分也使得参与运算的矩阵维数变小,但时间效率仍然优于直接将原系统与模式进行匹配的方法。文献[34]方法在JHotDraw 5.1、JRefactory 2.6.24 和JUnit 3.7 的识别阶段分别花费342 ms、1 376 ms 和127 ms,但模型训练阶段(预处理阶段)花费了5 647 670 ms(三个项目只需训练模型一次),总的时间花费远超于本文方法。
根据以上分析可知,本文方法在保持高召回率的基础上,通过将子系统进一步划分为二级子系统进行匹配,并将匹配结果进行组合,进一步提升了精确率。此外,二级子系统的划分使得部分肯定不属于模式实例的类在运算前就被剔除,且参与运算的矩阵维数变小,时间效率也有所提升。
9 结束语
本文在前期研究[7-8]的基础上,通过删减和修改所考虑的特征、修正二级子系统构建算法、修正和细化判断为模式实例的二级子系统等途径,探索了基于相似度评分与二级子系统的设计模式识别方法。将原系统划分为若干个子系统,并对子系统进一步拆解和重组为二级子系统,利用二级子系统进行匹配,将获取到的实例进行合并等进一步处理。实验结果表明,本文方法在保持较高召回率的基础上可有效提高精确率,此外,时间效率也优于直接将原系统和模式进行匹配的方法。
本文所考虑的6 个特征主要是结构特征,而行为型模式主要根据行为特征来相互区分。下一步将通过形式化技术(例如模型检测、有限自动机)研究,基于行为特征过滤掉行为型模式候选实例中的假阳性实例,并对具有相似结构的模式实例进行区分。此外,本文基于设计模式的理论描述将设计模式表示为有向图/矩阵的形式,并使用图论算法将二级子系统与设计模式进行匹配。使用深度学习从实际应用中实现的设计模式实例中学习规则构建设计模式预测模型,并在本文划分的子系统和二级子系统的基础上识别系统中的模式实例也是下一步研究的重点。
