面向深度学习图像分类的GPU 并行方法研究
2023-01-27韩彦岭沈思扬徐利军王静张云周汝雁
韩彦岭,沈思扬,徐利军,王静,张云,周汝雁
(上海海洋大学 信息学院,上海 201306)
0 概述
深度学习在图像分析[1]、目标检测[2-3]、语义分割[4]、自动驾驶[5-6]等诸多领域具有广泛应用,其主要通过增加网络的深度使计算机提取到更多的数据特征,目前深度学习网络普遍达到几百甚至上千层。庞大的数据量及复杂的网络结构对训练效率带来很大挑战。为了缩短训练时间,基于各种计算平台设计的并行训练方法逐渐成为研究热点。目前,对深度神经网络的并行化主要有数据并行和模型并行[7]两种方法。
数据并行是最简单的并行策略[8-9],模型副本在每台参与并行的设备上使用独立的数据子集,目前主流框架如TensorFlow[10]、PyTorch 都使用直观的方式支持数据并行[11]。但是随着并行设备数量的增加,批大小(Batch Size)通常也会增加,这使得数据并行可扩展性变差,因为对于任何给定的深度学习网络,当超过相应Batch Size 临界值后达到相同收敛精度所需要的迭代次数大幅提高,导致训练过程的统计效率降低[12]。此外,由于使用的并行设备数量增加而带来的通信开销增长,进一步限制了整体训练速度。
模型并行是一种与数据并行类似的并行方法,将模型图分割部署在多个设备上,同时并行处理同一个mini Batch[13],通常用于拆分大型模型(单个GPU 无法承载一个模型),因此也可通过此方法加速训练。但目前来看,通过改进模型并行算法所获得的加速效果非常有限[14-15]。因此,仅使用该方法也会带来扩展性较差的问题。另一方面,为了得到最大化加速,需反复调整模型切分方式以达到正反向传播过程中的通信效益最高[16-17]。在多数情况下,模型并行带来的通信开销和同步开销超过数据并行,因此加速比也低于数据并行。
谷歌开发的DistBelief 采用数据并行及模型并行的方法训练大规模模型,COATES[18]等使用GPU集群构建了模型并行训练方法,LI[19]等则提出了改进的参数服务器异步交互数据并行方案。但上述对于深度学习并行化的研究多基于大规模商用GPU平台,与具体图像分类中小规模GPU 实验环境存在较大差别。
本文通过研究图像分类场景中的并行问题,提出一种混合并行优化算法。该算法将数据并行和模型并行相结合提高并行性能,并提出一种改进的Ring All Reduce 算法[20],通过数据通信时的并行策略优化提高梯度交换效率。针对数据并行随设备数量增至一定规模后出现加速效果变差的问题,提出融合数据并行和模型并行的混合并行方法提高训练速度。在此基础上,利用feature map 数据量远小于权重参数数据量的特点,将全连接层及Softmax 运算进行模型并行,避免数据并行在通信过程中损耗引起的性能下降。最终在Cifar10 及mini ImageNet 两个数据集上分别对比了不同节点下数据并行与混合并行的时间、精度表现。
1 面向深度学习图像分类并行化的数据通信算法
多GPU 之间的数据通信是各深度学习模型实现并行化的基础,目前常用的传输方法包括参数服务器(Parameter Server,PS)和Ring All Reduce。集群包括用于运算及训练网络的工作节点worker 和整合所有worker 传回的梯度后更新参数的中心节点PS,该算法的缺点在于节点间通信时间和GPU 个数成正比。Ring All Reduce 在摒弃中心节点的基础上完成Map Reduce 操作,提高了传输效率,但时间复杂度仍较高。本文通过分节点间隔配对原则实现数据传输流程的优化,在不影响算法精度的基础上进行改进,以降低时间复杂度,提高传统深度学习各在个网络并行后的数据传输效率,达到加速优化的效果。
1.1 Ring All Reduce 算法
PS 的最大问题在于耗时与节点数量n线性相关,Ring All Reduce 算法在不使用中心节点的前提下完成Map Reduce 操作,分为Reduce Scatter 及All Gather 两个阶段:整个计算单元构成一个环形,仅与左右节点通信,数据按照节点数量切分为n,n为节点数。在Reduce Scatter 阶段,各节点每次传输,并将接收到的数据归约操作,在n-1 次后,各节点得到一份完整的数据;在All Gather 阶段,重复n-1 次,各节点将存有完整归约后的n份数据。在Ring All Reduce 算法中,各分节点在同一时刻既是发送节点也是接收节点,因此没有空闲机器的存在,且通信成本恒定,相较于参数服务器算法并不会随着分节点数量增加而线性增加,但该算法时间复杂度为O(n),仍具有改进空间。
Reduce Scatter 及All Gather 流程如图1 和图2所示。
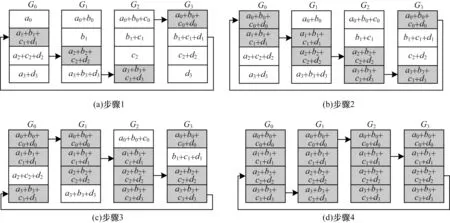
图2 All Gather 流程Fig.2 Procedure of All Gather
1.2 优化时间复杂度的Ring All Reduce 算法
Ring All Reduce算法在Reduce Scatter及All Gather阶段均需要n-1 步完成,使其时间复杂度为O(n),在Reduce Scatter 及All Gather 阶段通过分节点间隔配对原则实现数据传输流程的优化,在不影响算法精度的基础上使其时间复杂度降低为O(lbn)。
在算法实现中,规定总节点数Na为2 的指数幂,具体算法步骤如下:
算法1优化时间复杂度Ring All Reduce 算法


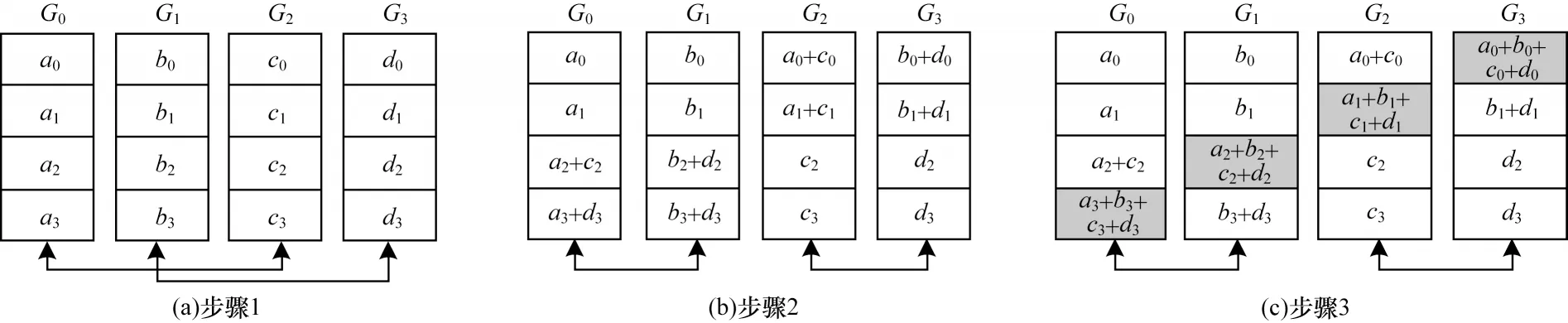
图3 Ring All Reduce 改进算法的Reduce Scatter 操作流程Fig.3 Reduce Scatter operation Procedure of Ring All Reduce improved algorithm


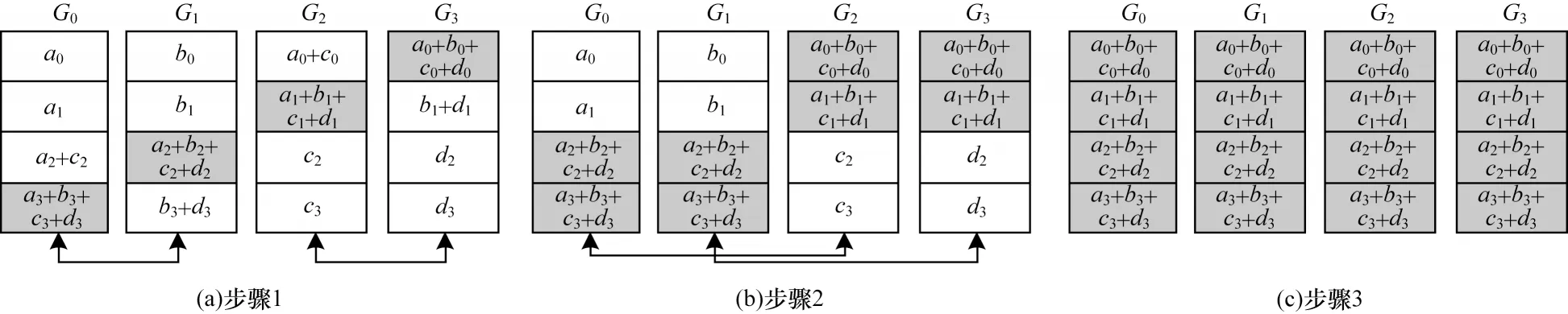
图4 Ring All Reduce 改进算法的All Gather 操作流程Fig.4 All Gather operation procedure of Ring All Reduce improved algorithm

2 面向深度学习图像分类的GPU 混合并行算法
数据并行是目前应用于各个深度学习模型最为广泛的并行策略,但在实际训练过程中,数据并行每个训练步中批大小规模及设备数量增长到一定程度时,数据并行的加速效果出现下降,影响整体训练时间。针对大型分类网络中feature map 数据量远小于参数数据量这一特点,本文提出针对图像分类任务的面向各深度学习模型混合并行优化方法,结合数据并行与模型并行思想,在权重参数较小的主干网络阶段采用数据并行,将传统数据并行节点上完整模型的全连接层采用模型并行,减少参数传输量,提高训练速度。另外,在数据并行中,多节点间的数据交换采用1.2 节提出的Ring All Reduce 改进算法,将两者结合的优势在于:一方面提升并行后多设备间传输效率,缓解带宽损耗问题;另一方面进一步加快训练速度,解决数据并行加速延缓的问题。
2.1 数据并行与模型并行
数据并行和模型并行均包含张量切分、张量传输(复制)及Reduce 等操作。张量切分表示物理上的张量是逻辑张量按照某一维度切分后得到的,axis代表切分的维度。张量传输(复制)是指物理上的张量和逻辑上的张量完全相同。Reduce 是一种逻辑张量与物理上多个张量映射关系的操作。如图5 所示,分别展示了张量切分的“行切分(axis=0)”、“列切分(axis=1)”以及张量传输与Reduce 映射操作。
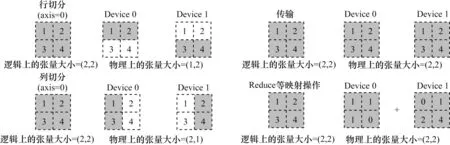
图5 深度学习中的并行化张量运算Fig.5 Parallelization of tensor operation in deep learning
从张量角度来看数据并行和模型并行,假定在模型训练中,存在一个输入矩阵Ι,通过矩阵Ι与矩阵W做矩阵乘法,得到输出矩阵Ο:
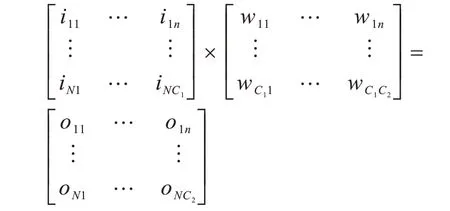
其中:Ι的大小为(N,C1);W的大小为(C1,C2);Ο的大小为(N,C2)。
结合深度学习模型结构,上述矩阵代表的含义如下:
1)矩阵Ι作为输入矩阵,每一行都代表数据集的一个样本,每行中的各列代表样本的特征。
2)矩阵W代表了模型参数。
3)矩阵Ο是预测结果或者数据集标签,如果需要执行预测任务,那么就是矩阵Ι、W求解矩阵Ο,得到分类结果;如果需执行训练任务,那么就是矩阵Ι、Ο求解矩阵W。
如果以上矩阵Ι的行N很大,则代表数据集庞大;如果矩阵W的列C2很大,则说明模型复杂程度高;当这两者量级都达到一定程度时,目前传统的单机单卡训练模式已无法承载,需要考虑并行的方式训练。因此,可以选择本文的数据并行和模型并行,矩阵相乘关系如图6 所示。

图6 深度学习中张量运算示意图Fig.6 Schematic diagram of tensor operation in deep learning
在图6 中,左边第一个矩阵Ι代表输入样本张量,每一行是一个样本;左边第二个矩阵W代表模型张量。下文分别说明数据并行与模型并行所对应的不同“切分”方式。
在数据并行中,将样本的数据张量进行切分,如图7 所示。切分后的数据被送至各个训练分节点,与完整的模型进行运算,最后将所有节点的梯度通过Ring All Reduce 改进算法进行交换。
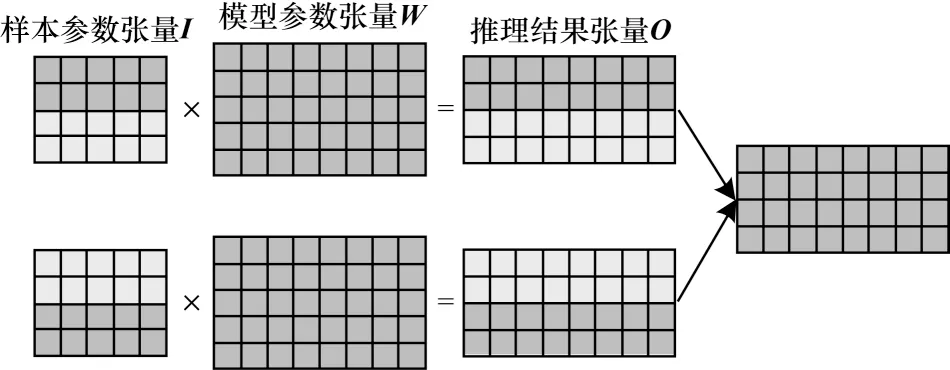
图7 数据并行张量运算示意图Fig.7 Schematic diagram of data parallel tensor operation
模型并行则是将模型张量进行划分,完整的数据被送至各个训练分节点,与切分后的模型进行运算,最后将多个节点的feature map 合并,如图8所示。
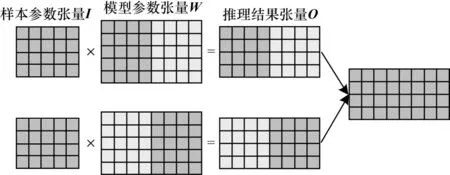
图8 模型并行张量运算示意图Fig.8 Schematic diagram of model parallel tensor operation
2.2 混合并行方法结构
本文并行结构是将数据并行和模型并行的思想相结合,并利用1.2 节改进的Ring All Reduce 算法实现各节点之间的并行后数据通信,实现一种更加优化的GPU 并行算法。从张量的角度来描述,存在一个矩阵运算Y=MatMul(A,B),A、B、Y都是张量,为简化起见,表示为Y=AB,那么存在以下2 种策略:
1)Y行切分(axis=0),A行切分(axis=0),B直接传输复制。
2)Y列切分(axis=1),A直接传输复制,B列切分(axis=1)。
假设逻辑上的Y运算为:
A(128,40)×B(40,50)→Y(128,50)
两种策略方式如图9 所示。
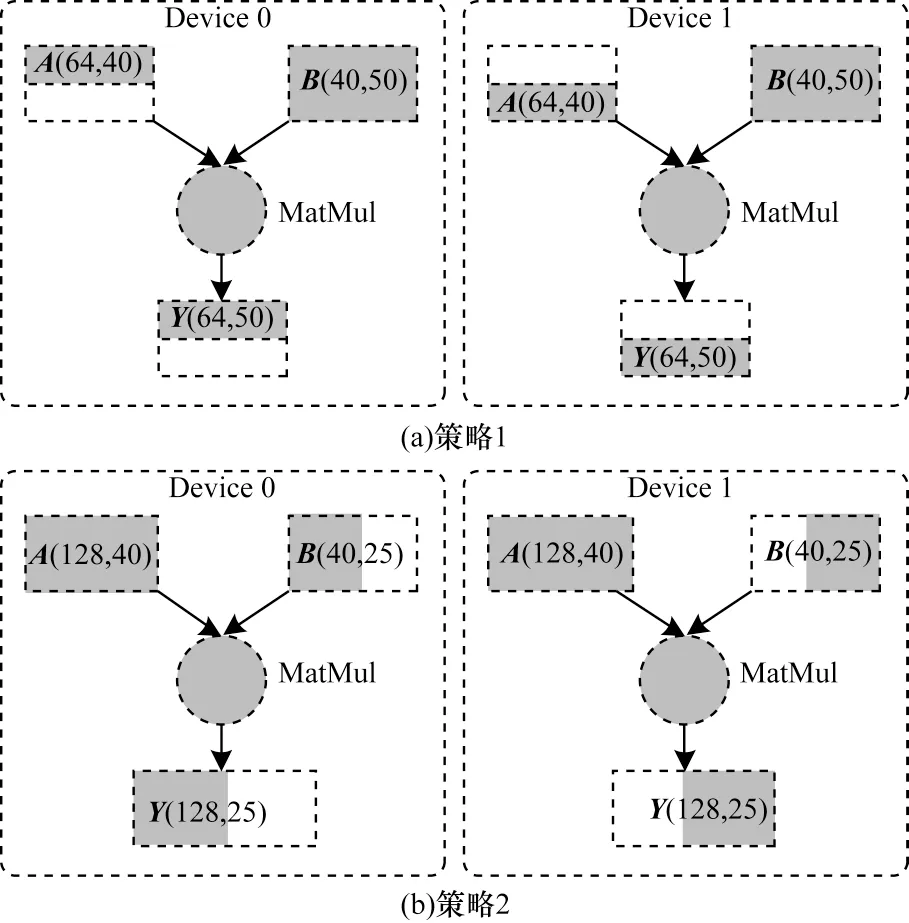
图9 两种并行化训练张量的分布策略Fig.9 Distribution strategies of two parallel training tensor
从图9 可以看出,当张量A是样本数据,张量B是模型时,图9(a)为数据并行,图9(b)为模型并行。图9 中采用了两个节点进行并行训练,最后组合各个节点上的张量通过Ring All Reduce 改进算法得到完整的输出。如果通过两个相邻的张量矩阵乘法计算,前一个使用策略1,后一个使用策略2,完整的并行结构如图10 所示。
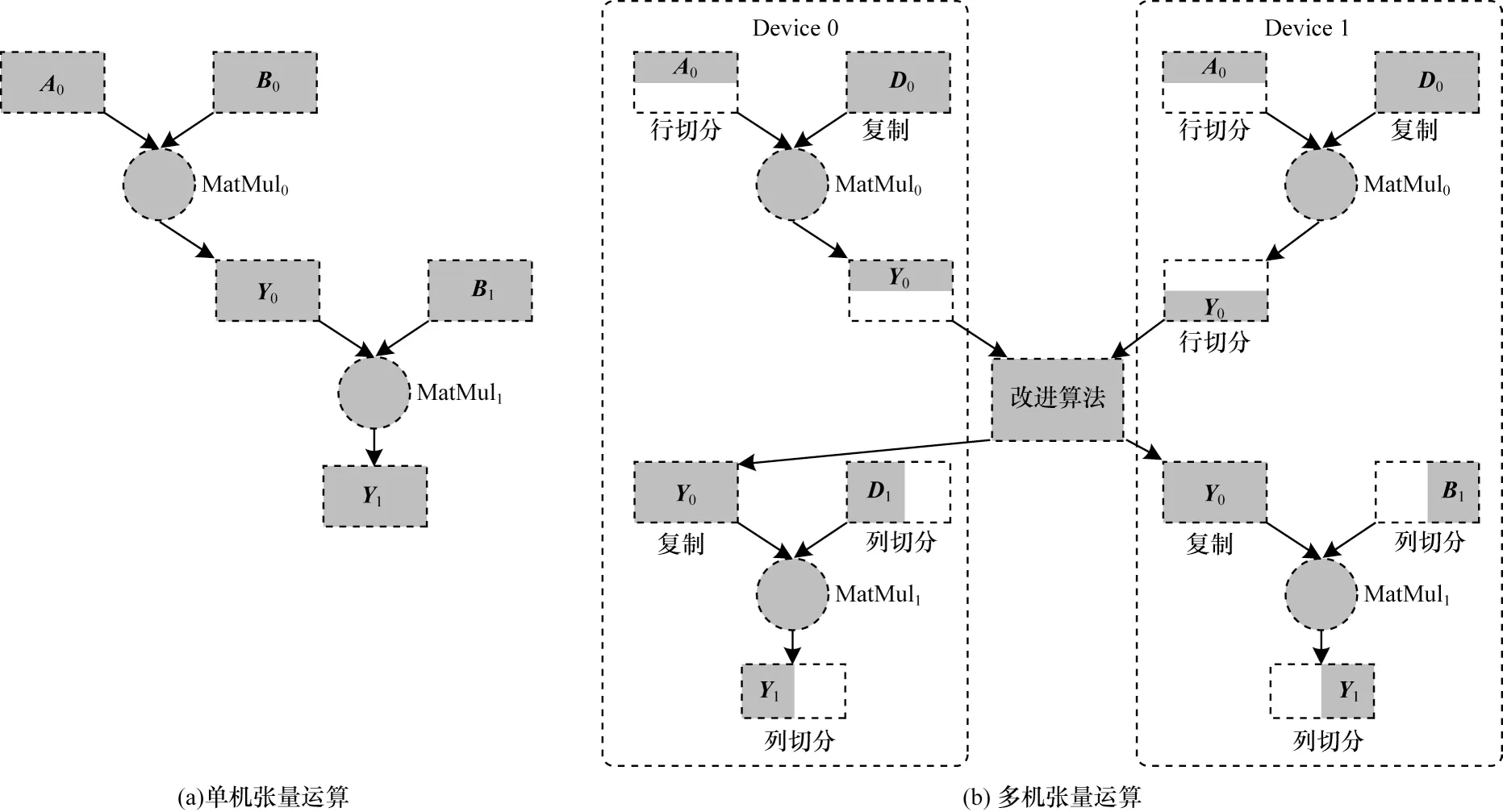
图10 混合并行结构Fig.10 Structure of hybrid parallel
从图10 可以看出,MatMul0得到的Y0被MatMul1用于进一步运算,但两者对同一个张量有所区别,MatMul0认为Y0是行切分(axis=0),由于模型并行需要部分的模型与完整的数据,即MatMul1需要一个完整的Y0输入,这意味着前一层的输出并不能作为后一层的直接输入,为了解决这个问题,需要在Ring All Reduce 改进算法做数据交换时进行必要的数据裁剪、拼接、搬运和求和等操作,使得所有的策略都可以在并行环境下高效地得到自己想要的数据进行下一步的运算。
2.3 混合并行方法实现
在深度学习分类任务中,针对模型不同部分采用不同的并行策略,从而提升效率。
在深度学习的图像分类问题中,其主干网络所包含的权重小于全连接层,同步开销小,所以对主干网络进行数据并行处理;而全连接层通常权重较大,使得多节点间梯度传输开销过高。为避免数据并行在通信过程中损耗引起训练性能下降,将全连接层的模型按列划分,使用多个节点存储分片,针对全连接层运算进行模型并行。
假设存在Gk,k∈[0,Nb-1],Nb为2 的指数幂个节点参与并行训练,整个分类网络由主干网络(ResNet50)、全连接层(Fully Connected Layer,FC)和Softmax 组成,其中k∈[0,Nb-3]节点负责主干网络数据并行,负责模型并行,下文分别阐述具体方法。
2.3.1 主干网络数据并行
主干网络数据并行过程如下:

2.3.2 全连接层模型并行
单节点的全连接层正向传播参数包括主干网络输出、网络权重、偏差、偏差权重,全连接层输入可描述为网络输出与网络权重的乘积加上偏差与偏差权重的乘积。本文模型并行对全连接层按照主干网络输出纬度进行分割,使用两个节点,考虑到每个节点的均衡性,采用等量的方式切分,具体模型的并行正向传播过程描述如下:
输入主干网络输出网络权重

传统全连接层反向传播梯度与特征相乘得权重梯度,偏差与梯度相乘得偏差梯度,梯度与权重相乘得输入梯度。同正向传播过程,模型并行先将网络参数切分后进行反向传播,具体流程如下:

3 实验与结果分析
3.1 实验数据描述及实验设置
实验数据采用在图像分类领域常用的两个公共数据集,分别是Cifar10 与mini ImageNet。Cifar10 是一个用于识别普适物体的小型数据集,共包含飞机、汽车、鸟类、猫、鹿、狗、蛙类、马、船和卡车10 个类别的RGB 彩色图片。图片的尺寸为32×32 像素,数据集中一共有50 000 张训练图像和10 000 张测试图像。ImageNet 共包含1 500 万幅图像,分为2 万多个类 别。本 文mini ImageNet为从ImageNet[21]中选取的前100 类,总共包含129 395 张训练图片及50 000 张验证图像组成的数据集。
本文所有实验都采用2080Ti,分别在单机和2GPUs、4GPUs、8GPUs 环境下进行。每组实验结果在随机选择训练样本的前提下均重复两次取平均值。
3.2 Ring All Reduce 算法及其改进算法对比
加速比是作为衡量并行计算性能的常用指标,其主要意义在于:对于相同业务流程,在单节点消耗的时间T1与并行计算后多节点消耗时间Tn的比值,比值的变化对应性能的好坏,在理想状态下,当节点增长与加速比成正比时为最优情况。
使用Cifar10 数据集在拥有两个节点的主机上进行100 次单机多卡数据并行训练,在Vgg16 及Resnet50 这两个网络下,比较不同Batch Size 时Ring All Reduce 算法和改进后算法较参数服务器算法的加速比,以此衡量算法在传输性能上的表现。
图11 为使用两种算法进行数据并行时的加速比对比,可以看到,无论Vgg16 还是Resnet50,随着Batch Size 的增大,两种算法的加速比存在一定程度的下降,这主要是由于数据量的增大使得传输耗时增加导致。Vgg16 网络在Batch Size 为4 时两种算法的差距最大,同样当Batch Size 为16 时,两种算法在Resnet50 也达到了最高25%左右的性能差距,因此可以得出,对于不同网络,均存在一个最优Batch Size 使得改进算法性能达到最优。总体而言,改进算法均能获得较Ring All Reduce 算法更好的性能,且加速比始终大于1。
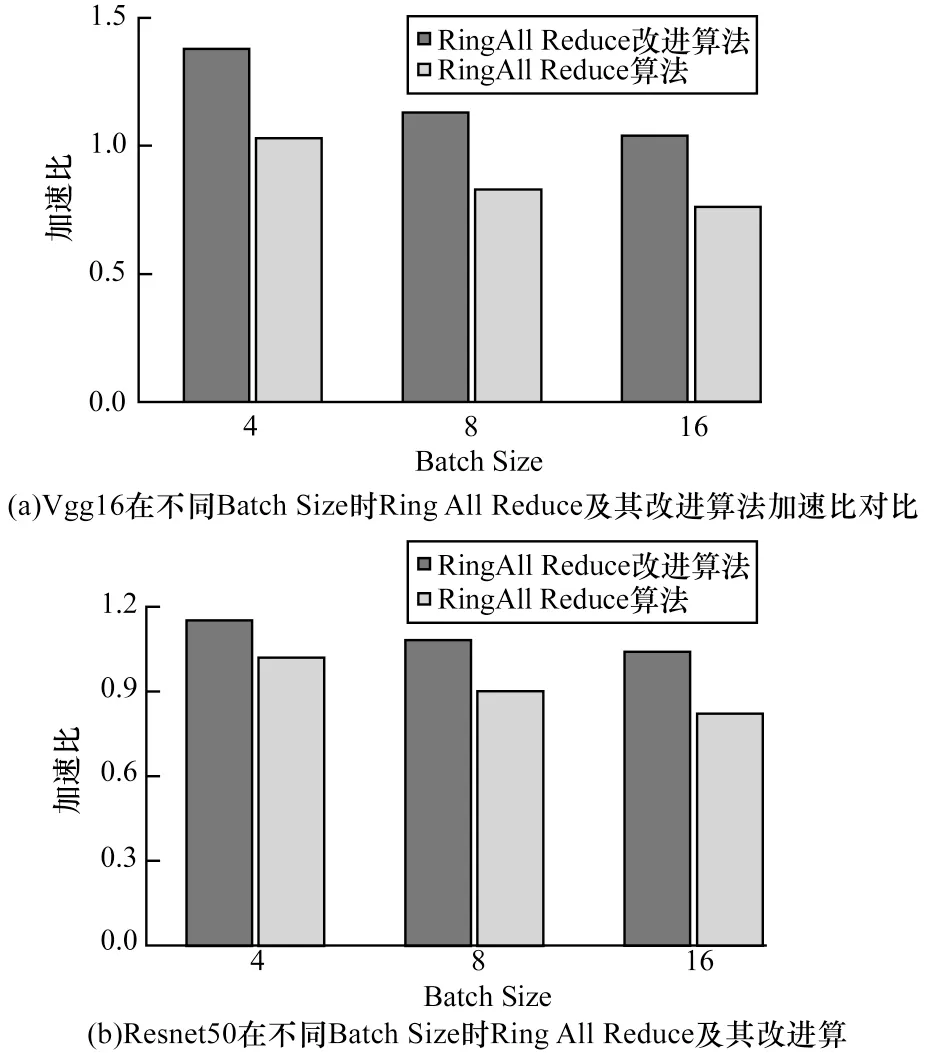
图11 Ring All Reduce 及其改进算法性能对比Fig.11 Performance comparison of Ring All Reduce and its improved algorithms
3.3 Cifar10 数据并行与改进并行算法对比
首先验证数据并行在不同节点数量下的性能表现,使用Cifar10 数据集,通过训练收敛性、时间等指标观察其性能。
实验在Resnet50 网络上进行图片分类,采用本文Ring All Reduce 改进算法实现数据传输。训练与测试Batch Size 均设置为64,训练集进行6 000 次,测试集进行1 000 次,初始学习率设为0.001,分别在3 000 及5 000 次后减小10 倍。
分别在节点数为2、4、8 的集群上进行数据并行训练,实验结果如表1 和图12 所示。
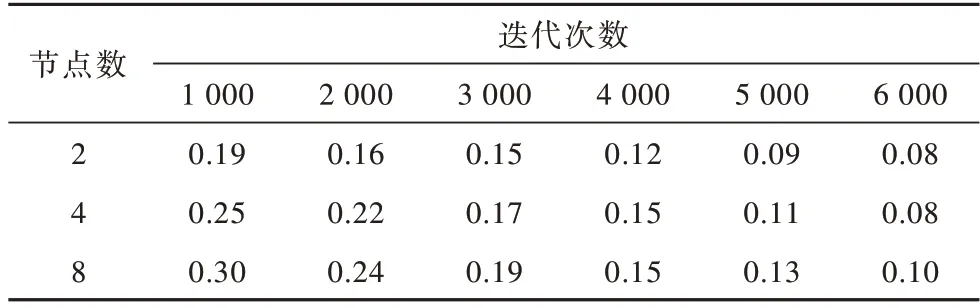
表1 多节点Cifar10 数据并行训练不同迭代次数损失率对比Table 1 Comparison of loss rate of different iterations in parallel training of multi node Cifar10 data
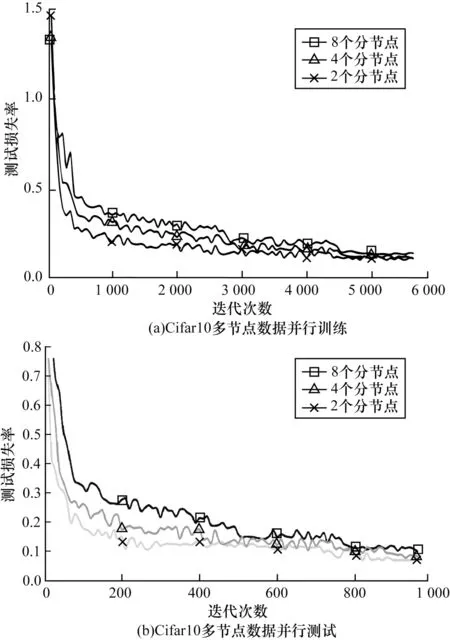
图12 Cifar10 多节点数据并行训练及测试损失率曲线Fig.12 Cure of parallel training and test loss rate of Cifar10 multi node data
表1 所示为在不同节点数上进行数据并行训练损失率随迭代次数的变化情况,对比8 个节点与2 个节点数据可以发现,并行节点数的增加会导致一定程度的损失率增加,在迭代次数为1 000 时,两者差距达到11%,但最终差距不大,6 000 次迭代后差距仅为2%,这说明数据并行对于训练最终精度影响较小。
从图12 可以得出以下3 点:
1)数据并行后训练及测试损失率会随着并行节点数的增多而有所增长。
2)参照表1 中训练损失率及图12(a)曲线,8 个节点数据并行在开始训练时收敛趋势较2 个节点更为缓慢,存在一定差距,迭代3 000 次后差距减小且保持在3%范围内,最终收敛点不超过2%,这主要是由于节点增加所带来的数据交换消耗降低了一定效率。
3)从图12(b)可以看出,在数据并行测试集测试过程中,同样迭代次数下,4 节点相较8 节点的曲线虽也然同样存在收敛放缓现象,但最终收敛点却更优,这说明节点数量与效率存在非线性关系。
将训练后权重在单卡上测试,并以此时间作为参照,绘制节点数与测试集上测试时间关系,如图13所示。
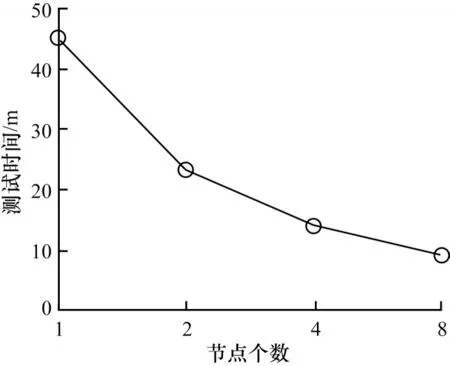
图13 Cifar10 多节点数据并行节点数与测试时间关系Fig.13 Relationship between the number of parallel nodes and test time of Cifar10 multi node data
从图13 可以看出,增加并行节点数量可以加速训练,这也体现了数据并行后的优势[22],但也可以看到,随着节点数量的增加,曲线斜率变大,加速效果变缓,当节点数量不断增加时使得数据交换次数更多,耗时更长[23-25],最终导致不能达到理想状态下的线性加速。
从以上实验结果可知,多节点的数据并行训练对于最终分类精度影响较小,但加速效果受到一定限制,当使用8 节点数据并行训练时速度下降最为明显,因此在保证其余实验环境一致的前提下,同样使用8 节点并行可以最大化反映提升效果,在测试集上经1 000 次迭代测试后损失率曲线如图14(a)所示,时间对比如图14(b)所示。由图14(a)可以看出,本文提出的并行方法相较于数据并行策略最终收敛效果基本相同,可见该方法对于网络精度影响较小。从图14(b)可知,相较于数据并行,加速效果有小幅改善,并将测试时间从9 min 缩短至7.8 min,这主要是由于模型并行通信内容为feature map,数据并行通信内容为参数,本文的策略是将全连接层使用模型并行,其余部分使用数据并行,这对于类别较少的Cifar10,全连接层总参数量与feature map 差距较小,因此提升有限,当网络feature map 远小于参数量时,在通信上性能更优。
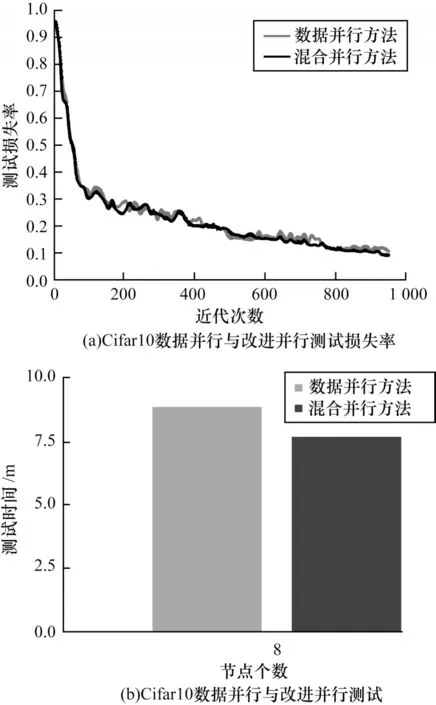
图14 Cifar10 数据并行与改进并行测试对比Fig.14 Comparison of Cifar10 data parallel and improve parallel test
3.4 mini ImageNet 数据并行与改进方法对比
本节采用数据集mini ImageNet 进一步验证提出的并行策略性能。使用Resnet50 作为训练网络,实验环境为单机多卡GPU 集群,最大程度地排除带宽对于数据传输的影响,采用本文提出的Ring All Reduce 改进算法作为集群通信方式,在节点为1、2、4、8 上对比数据并行与改进后并行方法的训练时间,验证该方法对于进一步提升加速的有效性。
实验Batch Size 设置为64,迭代90 次后实验结果如表2 所示,其中Acc 代表训练的准确率,T表示训练完成时间。
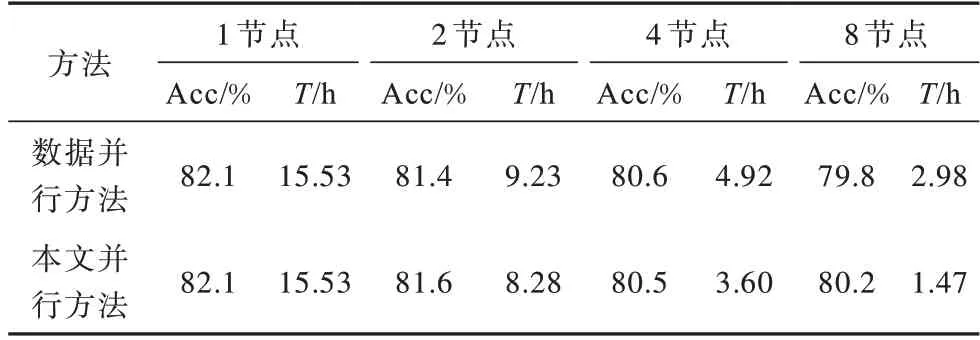
表2 mini ImageNet 数据集多节点数据并行与本文并行方法对比Table 2 Comparison of multi node data parallel and Proposed parallel method in mini ImageNet dataset
分析表2 可知,在mini ImageNet 数据集上,无论采用数据并行还是本文并行方法,随着节点数量的增加,训练时间逐渐缩短,但都会带来一定程度的准确率下降,对比单卡训练,存在2%左右的下降,这与在Cifar10 数据集上得到的结论相同,结合表2 和图15(a),本文提出的方法在加速效果上相比数据并行方法有所提升。对比图15(a)可以看出,本文方法在多节点并行下优势更为明显。图15(b)展示了在同样节点数情况下Cifar10 与mini ImageNet 数据集采用该方法并行训练的加速比情况,在使用2 个节点并行时,Cifar10 数据集进行训练所得到的加速比稍好于同样节点数的mini ImageNet 数据集,随着节点数的增长,加速比不断提升,但mini ImageNet 数据集所得到的加速比幅度更大,两者差距也越明显,这主要是因为此时feature map 量远小于大量数据的参数量,使得加入模型并行后在通信量上反而相对更少,速度更快,由此可进一步说明,当进行海量数据分类时,本文提出的方法能有效提高效率。
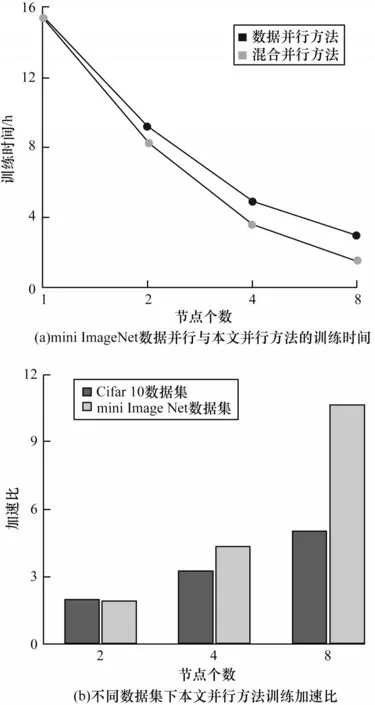
图15 数据并行与本文并行方法对比Fig.15 Comparison between data parallelism and the parallel method in this paper
4 结束语
针对图像分类场景大规模数据及模型训练效率低等问题,本文通过分节点间隔配对原则优化数据传输流程,提出一种改进时间复杂度的Ring All Reduce 数据通信算法,用于提升数据并行多设备间传输效率,并提出混合并行算法,将主干网络进行数据并行处理,全连接层采用模型并行处理,解决数据并行模式难以支撑大规模网络参数及加速延缓的问题。实验结果表明,本文提出的混合并行算法相比并行方法,最终测试与训练精度差异不大,但在加速效果上衰减幅度更小,效果更好,相比Cifar10 等类别较少的数据集,在mini ImageNet 上具有较大的加速优势,更适用于海量图像分类数据并行训练。后续将针对推荐网络等结构复杂模型进行优化及应用,以进一步提高传输效率。
