一种加速访存地址计算的编译优化
2023-01-27高秀武姜军白书敬黄亮明
高秀武,姜军,白书敬,黄亮明
(江南计算技术研究所,江苏 无锡 214083)
0 概述
随着大数据、云计算、物联网等新兴技术的快速发展,许多应用软件的计算量呈指数级增长,人们对高性能处理器需求也逐渐增加[1]。基于国产异构众核处理器研制的“神威-太湖之光”超级计算机连续多年在高性能计算机排行榜TOP500[2-3]中位于第一梯队。由此可见,国产高性能处理器已经达到世界领先水平,但由于国产处理器软件生态不成熟,应用程序实际性能与处理器峰值性能还存在较大差距[4]。另外,用户不熟悉国产处理器微结构,且手工优化代价高,难以发挥国产处理器高性能的内部操作能力,容易导致应用程序性能低下。编译优化是在一定处理器资源的前提下,通过对程序代码进行重组、对指令的执行顺序进行调度等手段,充分发挥处理器的内部操作能力,达到提高应用程序运行性能的目的。因此,针对国产处理器指令集架构与微结构特征,进行深层次的编译优化,进一步挖掘国产处理器的计算能力是十分必要的。
现代处理器普遍采用冯·诺依曼体系结构,代码与数据存储在内存中,与处理器计算控制单元相隔离。处理器的任何操作都要首先从内存中取得指令与数据,然后进行相应操作,最后将运算结果写回内存。然而,由于制造工艺的不同,存储器与处理器性能发展呈现不均衡增长,由此引发的“存储墙”[5-6]问题成为阻碍处理器性能发挥的主要因素之一。因此,如何设计高性能的存储器系统以及提升片上存储系统利用率与访问效率,成为处理器系统性能优化长期以来研究和关注的热点。本文针对应用程序中频繁出现的内存地址计算低效问题,基于国产多核申威(SW)处理器提供的带扩展因子的运算指令,提出一种加速访存地址计算的编译优化方法,充分发挥国产高性能处理器计算能力来快速计算内存地址,进而加快访存指令的发射与执行,以此达到提高存储器系统访问效率的目的。
1 相关研究
为解决处理器与存储器之间的速度差异,SMITH 等[7]提出了Cache 概念,并在Intel Pentium 处理器中实现了Cache。Cache 是存储器与处理器之间的过渡桥梁,容量小但访问速度快,几乎接近处理器的处理速度。Cache 利用程序的局部性原理[8-9],将处理器所需要的指令与数据存放在Cache 中,减少了对片外主存的直接访问次数,从而提高处理器对数据和指令的访问速度。采用Cache 这种方式能够有效缓解处理器与存储器之间速度不匹配的“存储墙”问题,但随着片上多核处理器的出现与单芯片执行核数的增加,单位时间内整个芯片执行的指令与数据也随核数增加呈线性增长,“存储墙”问题也越来越严重。应用程序的执行时间也越来越受限于数据的访问延迟,对存储器与处理器之间访存带宽与访问速率都有更高的需求。为满足片上多核更高的访存带宽与更快的访问速率,现代处理器在Cache的基础上引入了层次化存储结构[10],并且随着多核处理器的不断发展,层次化的存储结构也变得十分复杂。至此,学术界与工业界都开始着重研究如何利用多核处理器片上丰富的Cache 资源来优化应用程序的执行性能,主要包括Cache 管理策略优化、内存管理以及编译优化等。
Cache 管理策略优化主要涉及Cache 淘汰算法优化、Cache 划分与调度机制以及Cache 一致性维护协议开销优化。现代处理器普遍采用最近最少使用(Least Recently Used,LRU)淘汰策略[11],这种策略的优点是实现简单且对局部性较好的程序效果较好,但对于抖动访问模式与混合访问模式[12]的程序不友好,会降低Cache 的利用率。针对数据抖动访存,QURESHI 等[13]提出一种通过保护局部性较强的数据来防止数据的动态插入策略(Dynamic Insertion Policy,DIP)。JALEEL 等[12]在替换算法中加入重引用距离预测(Re-Reference Interval Prediction,RRIP)机制,并提出基于RRIP 的缓存块替换算法,进一步提高Cache 命中率。文献[14-15]研究Cache 划分机制,根据程序运行时的行为将运行程序的数据固定在某一Cache 区间,防止不同特征程序相互干扰,从而提升系统的整体性能。文献[16]提出数据局部性感知的Cache 数据一致性维护协议,高效地管理片上多核处理器中的分布式和私有Cache。
在内存管理方面,现代处理器都会采用TLB 来加速虚拟地址到物理地址的映射。但由于TLB 容量有限,无法同时存储所有工作负载的虚实映射关系,当工作负载的数据量超过一定的范围时,会导致程序在查询TLB 时频繁发生TLB 缺页,这将极大影响程序的访存性能。因此,研究人员普遍采用大页技术[17]、预取技术[18]、分级分区的转换缓存[19-20]等方法来提高TLB 的命中率。
编译优化是在一定处理器资源的前提下,通过对程序代码进行重组、对指令执行顺序进行调度等手段,充分发挥处理器的内部操作能力,达到提高应用程序运行性能的目的。文献[21]提出使用静态单赋值图作为程序中间表示,并采用分区布尔二次型问题来寻找最优指令选择。文献[22]介绍了一种针对寄存器分配与指令调度的组合优化方法,通过牺牲编译时间获取更多的优化机会。文献[23]针对嵌入CPU C-SKY 的地址立即数管理问题,通过编译优化来减少内存访问指令的生成,从而提高应用程序的性能。文献[24]介绍了GCC 编译器预取技术的实现与分析,通过编译器为应用程序生成预取指令,通过预取技术来提高应用程序的Cache 命中率。所以,通过编译优化可以进一步挖掘处理器系统的潜能。本文针对给定的处理器系统,基于其指令集特征,提出一种加快访存地址计算的编译优化,加速访存指令的执行与发射,从而提高存储系统的访存效率。
2 国产SW 处理器架构特征
国产SW 处理器基于具有自主知识产权的“SW指令集系统”自主设计研制完成,是一种RISC 架构的高性能处理器,采用多核架构和片上系统技术。其核心采用乱序发射、乱序执行以及推测执行等技术实现4 译码7 发射的超标量结构,支持256 位整数/浮点向量运算。核心微结构如图1 所示。
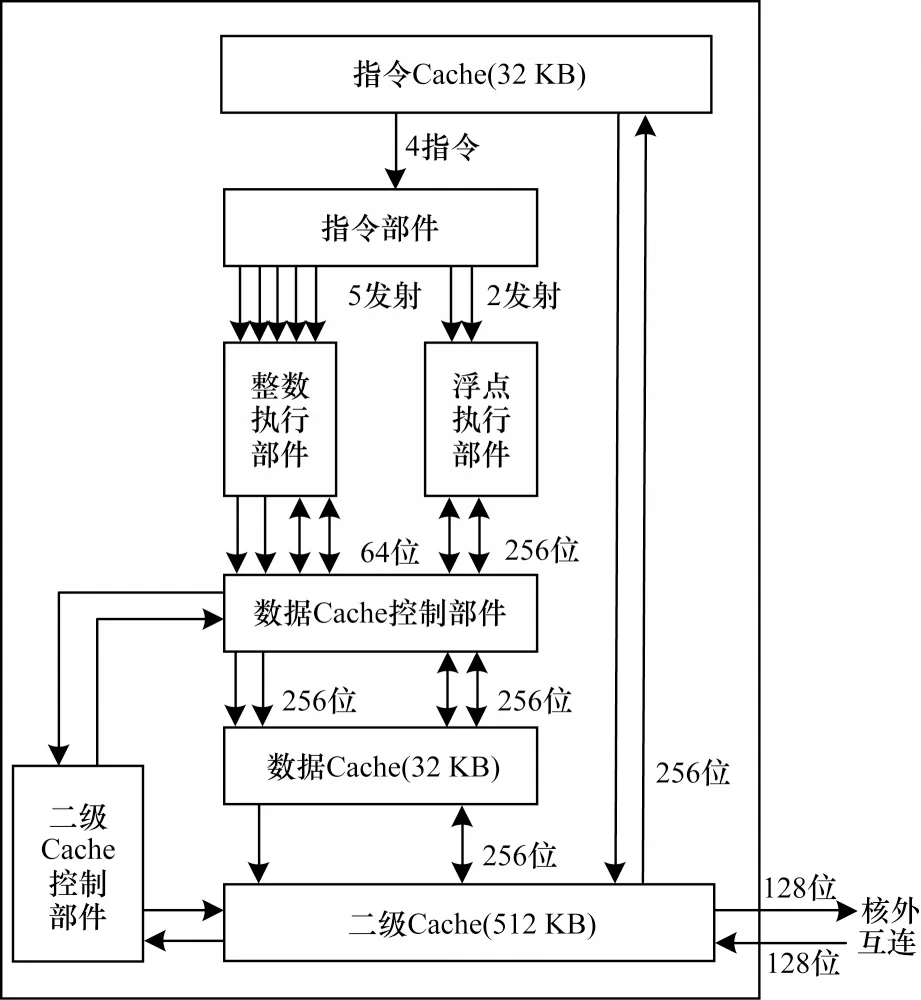
图1 SW 处理器核心微结构Fig.1 Core microstructure of SW processor
2.1 寻址方式
国产SW 处理器为64 位字长的Load/Store 型多核处理器,存储管理机制支持小端地址格式的字节寻址,寻址方式包括寄存器寻址、立即寻址、偏移寻址以及相对PC 寻址4 种模式。寄存器寻址与立即寻址用于运算类、比较类指令,PC 寻址用于跳转类指令,偏移寻址用于存储器访问指令。因此,国产SW 处理器的内存访问使用偏移寻址方式,即内存的有效地址由指令中的寄存器内容与包含在指令中的偏移量求和形成。如存储装入指令LDx Ra.wl disp.ab(Rb.ab),其指令格式如图2 所示。该指令低16 位立即数为偏移量(disp),寄存器Rb 存储基址的值,寄存器Ra 为目标寄存器。内存的有效地址(Vaddr)即是16 位偏移量(disp)经符号扩展到64 位后加上寄存器Rb 的值。

图2 SW 处理器的内存指令格式Fig.2 Memory instruction format of SW processor
2.2 访存指令执行流程
国产SW 处理器核心采用超标量流水线结构,支持乱序发射、乱序执行、推测执行和顺序退出。因此,一条访存指令执行过程包括取指、译码、发射、地址计算、读数据、数据选择、指令完成以及指令提交等步骤,其中地址计算由地址生成单元AGU 完成。往往访存指令中的基址寄存器的值依赖于访存指令之前的运算指令,且只有当运算指令完成指令提交时才能发射执行。只有及时获得基址寄存器的值,才能加快访存指令的发射与执行,从而提高处理器计算部件与访存部件的并行性。
2.3 带扩展因子的运算指令
国产SW 处理器提供了带扩展因子的运算指令,即一条指令可以完成扩展因子乘法与加法或减法的组合操作。带扩展因子的运算指令包括带扩展因子的字加、带扩展因子的字减、带扩展因子的长字加、带扩展因子的长字减等4 类指令,其指令功能如表1 所示。

表1 SW 处理器带扩展因子运算指令功能描述Table 1 Function description of SW processor with extension factor operation instruction
通过分析带扩展因子的运算指令功能可知,该类指令主要进行乘4 的加减法运算与乘8 的加减法运算。应用程序中存在大量以字或双字为地址单元的数据结构,其成员的内存地址计算涉及乘4 加减或者乘8 加减的运算。合理使用带扩展因子的运算指令可以加速这些数据结构成员地址的计算,从而提升访存速度。
3 GCC 编译器访存地址代码生成
3.1 GCC 编译器代码生成
GCC 编译器代码生成在其后端实现,完成中间表示向汇编指令代码的转换,同时进行一系列与架构相关的优化。GCC 编译器代码生成过程可以分为GIMPLE 中间形式转化为IR-RTL(Intermediate Representation RTL)与IR-RTL 匹配指令模板生成汇编代码两个阶段[25]。具体流程如图3 所示,每一条GIMPLE 语句首先根据具有标准模板名称(Standard Pattern Name,SPN)的指令模板构造IR-RTL,然后对IR-RTL 序列进行进一步的处理,包括循环优化、指令调度、寄存器分配、窥孔优化等过程,最后根据包含目标机器信息的指令模板与RTL 进行匹配生成目标机器的汇编代码。
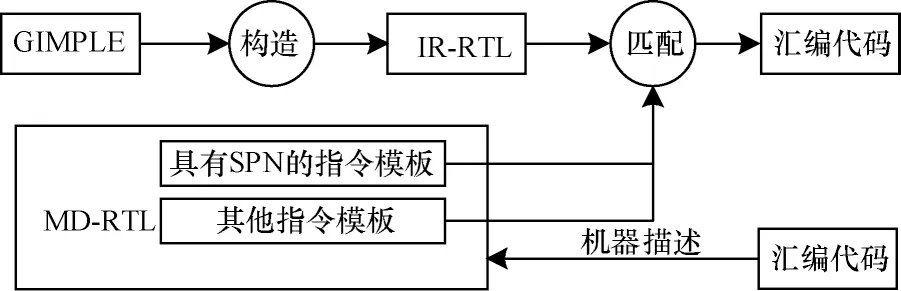
图3 GCC 编译器代码生成流程Fig.3 Generation procedure of GCC compiler code
3.2 GCC 编译器访存地址代码生成算法
数组是在内存中连续存储的具有相同类型的一组数据的集合,广泛地应用于高级程序语言中。在高级程序语言中,数组元素按照“数组名[下标]”的形式进行访问,形如a[i](a 为数组名,i 为下标)表示数组a 中的第i+1 个元素。为简化描述,本文以C 语言中对数组(数据类型为long int)循环赋值为示例来分析GCC 编译器访存地址代码生成过程。
C 语言源代码如下:

C 语言数组赋值会被转换成一条GIMPLE 赋值语句,其中数组元素a[i*i]也转化为ARRAY_REF 类型的表达式a[_1]。GCC 编译器数组访问代码生成主要完成GIMPLE 赋值语句中表达式a[_1]的展开,其算法步骤如下:
步骤1通过TREE_OPERAND 接口获取数组索引,构建形如_1*8 的数组元素地址偏移量表达式,并将其展开为一个乘法RTX 表达式。
步骤2将数组变量基址的RTX 表达式与数组元素地址偏移量表达式合并,生成完整的数组元素地址计算表达式,即一个先乘后加的RTX 表达式。
步骤3对步骤2 产生的地址计算表达式进行合法性检查,判断是否能对应目标机器的一条指令。合法性检查是内存地址计算代码生成十分关键的一步,决定地址计算生成的代码是否高效。SW 编译器支持常量、寄存器以及常量加寄存器等三类地址生成方式。符合以上方式则发射对应指令,否则对地址计算RTX 表达式进行递归拆分,直至拆分的RTX满足上述三类方式,合法性检查流程如图4 所示。内存地址计算RTX 表达式经过合法性检验后,生成相应的地址计算INSN 序列,并返回最终的内存引用RTX 表达式。
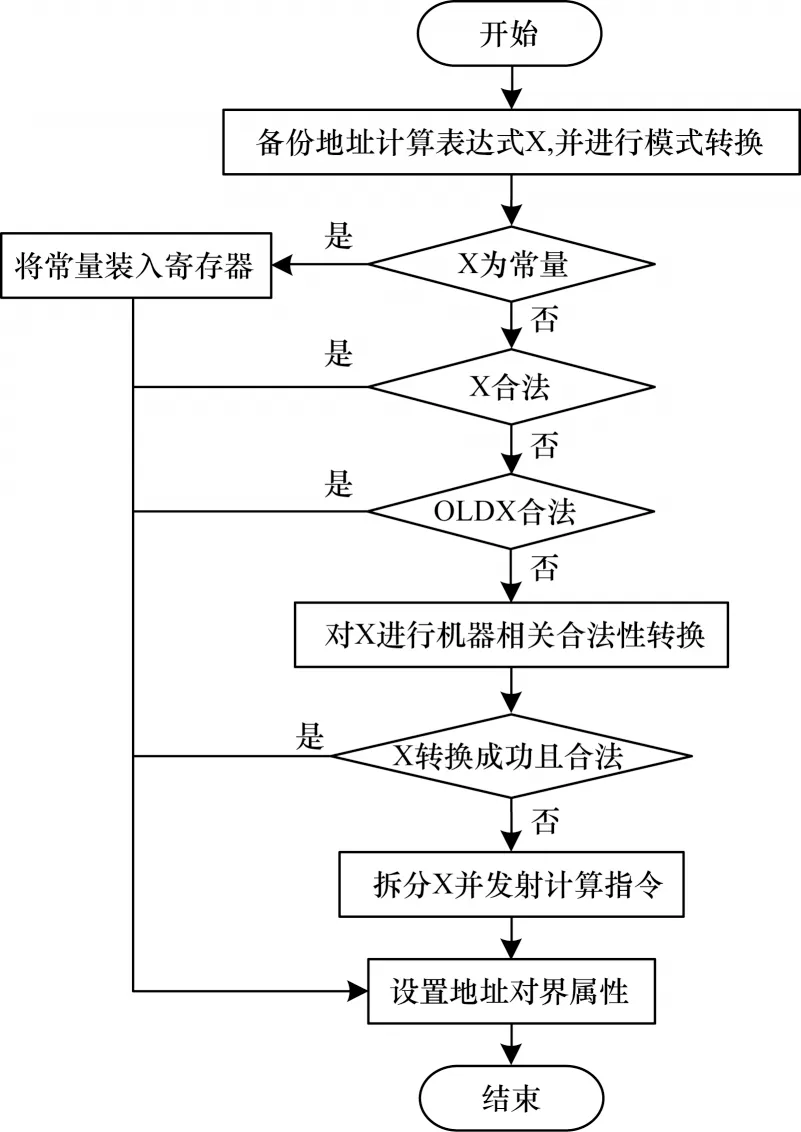
图4 GCC 编译器内存地址合法性检查流程Fig.4 Procedure of memory address validity inspection in GCC compiler
步骤4根据步骤3 返回的内存引用RTX 完成最后访存指令的生成,数组访问完整INSN 序列如下所示。数组元素a[_1]的访问共产生左移(ashift)、加法(plus)以及存储(mem)三条INSN 指令,地址表达式a+_1*8 被转化为R78=R65+R76<<3。

步骤5匹配机器指令模板,将INSN 指令序列转化成汇编代码,如把C 语言循环语句转换为汇编代码。
C 语言循坏语句如下:

通过分析汇编代码可知,数组内存地址计算总共包括装入立即数(ldi)、逻辑左移(sll)与长字加(addl)三条指令,装入立即数指令用于获得数组基址,逻辑左移指令计算地址偏移,加法指令计算完整的数组地址。其中加法指令数据依赖于装入立即数与逻辑左移指令,会阻断处理器流水。若能合并以上指令,消除指令间的相关性,则能快速计算数组地址,加快访存指令的发射与执行。
4 基于带扩展因子运算指令的访存地址生成算法
通过分析GCC 编译器数组访问代码生成算法可知,其核心步骤在于地址表达式合法性的检验及INSN 指令的生成,即表示地址计算的RTX 表达式能否对应目标机器后端指令模板中的一条指令。若能则生成相应INSN 指令,否则递归拆分表达式生成INSN 指令序列。
针对申威处理器的访存地址计算编译优化方法就是在满足合法性检验的基础上,采用申威处理器自主指令集支持的带扩展因子的运算指令,替代原本要生成的多条指令来完成地址计算过程中的乘加操作,从而解决指令间存在强相关性带来的处理器断流水问题,并减少指令数量。该优化方法主要在编译器后端进行实现,包括地址合法性检验算法设计与后端代码生成两个部分。
4.1 地址合法性检查算法设计
地址合法性检查算法设计主要针对国产处理器SW3231 支持的带扩展因子的运算指令新增一个合法的乘加地址模式,并基于该地址模式去识别或者检查内存地址计算过程中的乘加表达式,最后指导后端生成带扩展因子的加减法指令,其具体流程如图5 所示。
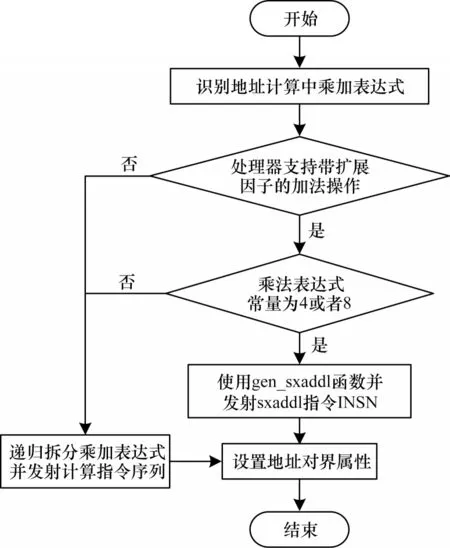
图5 地址合法性检查算法流程Fig.5 Procedure of address validity inspection algorithm
首先,识别数组元素访问地址计算中的乘加RTX 表达式,判断依据为RTX 表达式类型为加法操作,且该加法操作的第一个操作数类型为乘法操作,即进行一次先乘后加运算。然后,判断目标处理器是否支持带扩展因子的加法操作,如不支持则递归拆分该乘加表达式。最后,判断RTX 表达式乘法操作常量操作数是否为4 或者8,满足则调用gen_sxaddl 函数并发射sxaddl 指令,否则退出递归拆分乘加表达式。其中gen_sxaddl 函数实现依赖于后端代码生成,将在4.2 节进行描述。合法性检查算法修改后数组地址计算的乘加RTX 表达式不再拆分为左移与加法两条INSN 指令,而只发射一条匹配sxaddl 指令模板的乘加IR-RTL 形式的INSN,如图6所示。

图6 乘加表达式展开示意图Fig.6 Schematic diagram of multiply and add expression expansion
4.2 后端代码生成
编译器后端主要进行与目标机器紧密相关的处理与优化,最后输出目标机器的汇编指令。现代编译器为了提高灵活性和可移植性,通常将机器相关信息相对集中地组织到一个模块,称作机器描述(Machine Descriptions,MD)。MD 主要包括编译环境、机器基本属性、指令模板、应用二进制编程接口(ABI)等内容。
为简化编译优化方法的代码生成过程,带扩展因子的加法指令定义为具有SPN 的指令模板,并采用适合生成单条或少数条指令的define_insn 类型用于指令生成。模板中的match_operand 是第n个操作数的占位符,用来进行操作数属性匹配,比如第1 个match_opreand 中的DI 表示数据模式为双字整数,0是match_opreand 的第1 个参数,表示第1 个操作数,register_opreand 是第2 个参数,表示该操作数的类型为寄存器。模板中的(INTVAL(operands[2])==4 ||INTVAL(operands[2])==8)表示指令模板的前置条件,即第2 个操作数值为4 或者8,该模板才起作用。大括号包括的内容为模板的执行语句,即根据第2 个操作数的值输出对应的汇编代码。
sxaddl 指令模板如下:

定义了sxaddl 指令模板后,编译器自身生成过程中会创建gen_sxaddl 函数,该函数会构造sxaddl 指令对应的IR-RTL 语句,最后在Final 过程中匹配指令模板输出汇编代码。示例程序经过地址优化后,逻辑左移指令(sll)和加法指令(addl)被带扩展因子的加法指令替换,缓解了地址计算指令断流水情况,从而加快数组地址计算。
优化前汇编代码如下:


5 实验与结果分析
5.1 实验配置
本文基于开源编译器GCC(版本GCC8.3.0)实现了地址快速运算编译优化方法,并在一台多核服务器上进行了优化效果评测。服务器采用国产多核处理器SW3231,具有运算性能强、访存带宽高、可靠性好等特点,同时安装配套的Linux 操作系统(内核版本4.19)。评测程序采用CPU 标准性能评估测试集SPEC2006(版本v1.2),包括SPECint 和SPECfp 两套基准测试程序。CINT2006 用于评测整数性能,包含12 道测试课题,如表2 所示。CFP2006 用于评测浮点性能,包含17 道测试课题,如表3 所示。
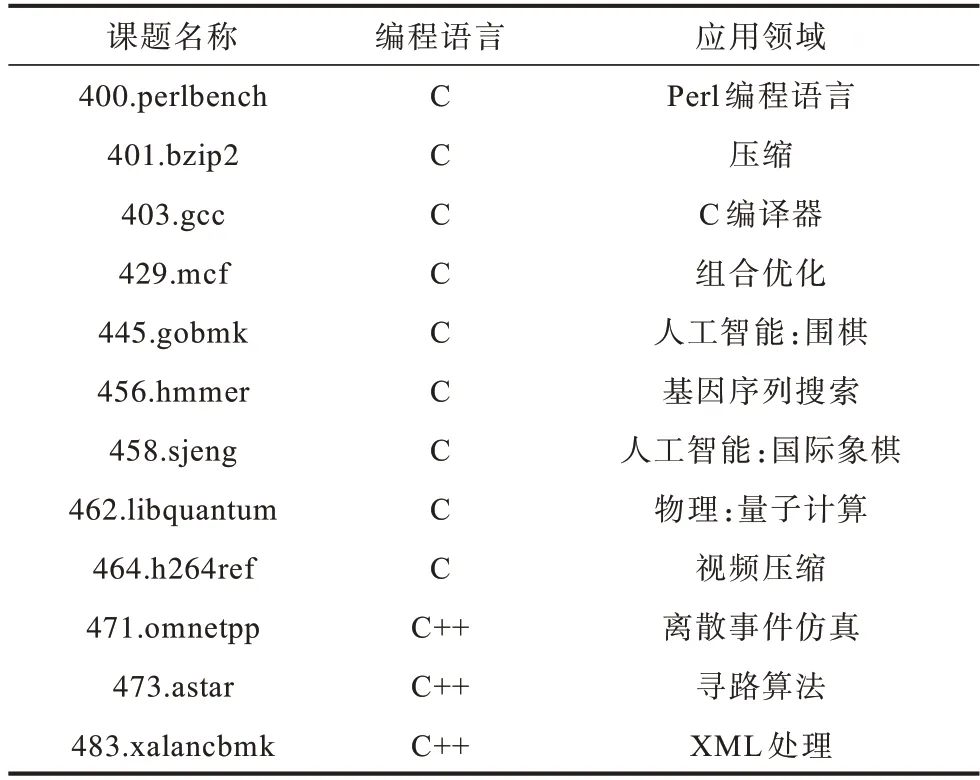
表2 SPECint 2006 课题说明Table 2 SPECint 2006 project instructions
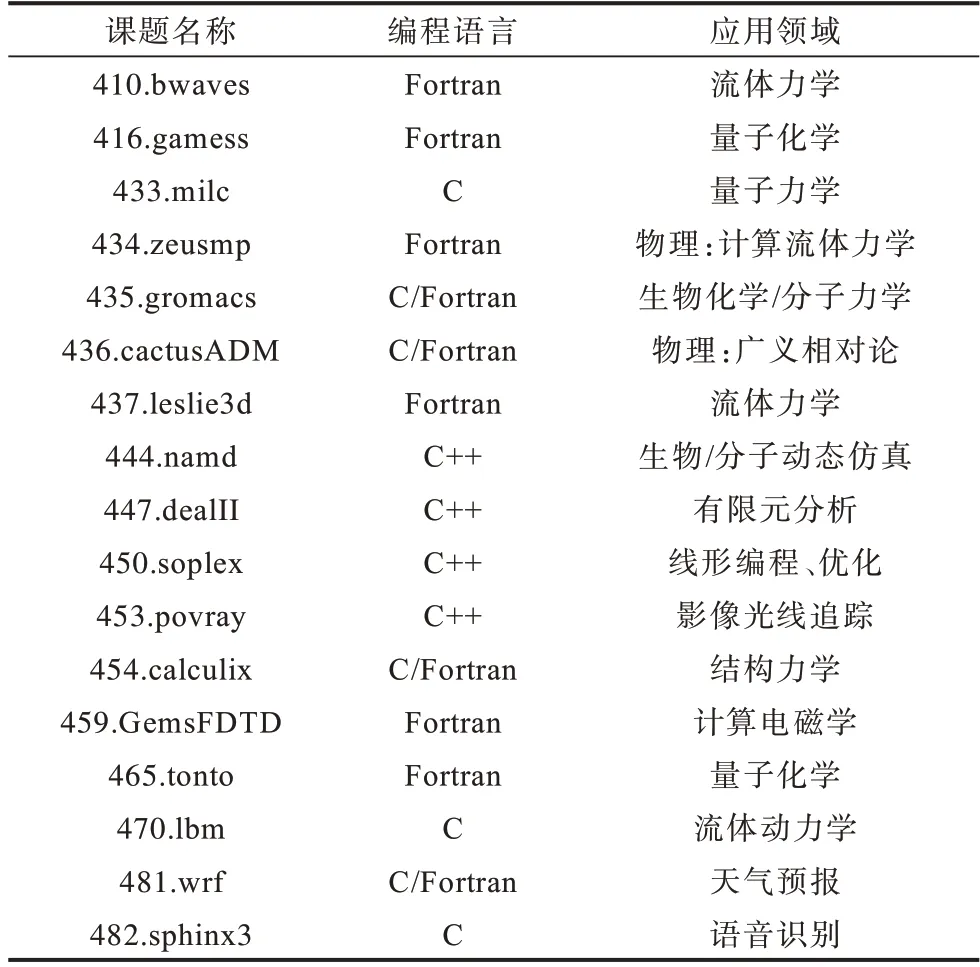
表3 SPECfp 2006 课题说明Table 3 SPECfp 2006 project instructions
5.2 实验数据与分析
针对本文实现的编译优化,采用SPEC2006 speed 模式进行优化效果评测。对程序进行编译时,基准测试采用-O2 选项编译,优化选项只额外打开地址运算编译优化选项,课题执行均使用标准的ref规模。
图7 所示为SPECint 2006 课题的性能提升情况,12 道课题几何平均性能提升2.53%。其中9 个课题有不同幅度的性能提升,401、429 课题性能提升超过7%。403、462、483 等课题性能略有下降,但下降幅度均小于1%。图8 所示为SPECfp 2006 课题的性能提升情况,17 道课题几何平均性能提升1.50%。其中9 个课题有不同幅度的性能提升,433、450 课题性能提升超过6%。435、453、459 等课题性能略有下降,但下降幅度均小于1%。
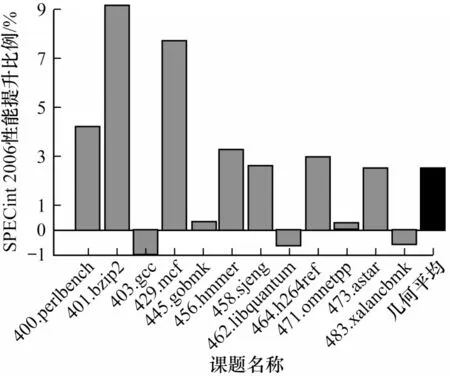
图7 SPECint 2006 课题性能提升比例Fig.7 SPECint 2006 project performance improvement ratio
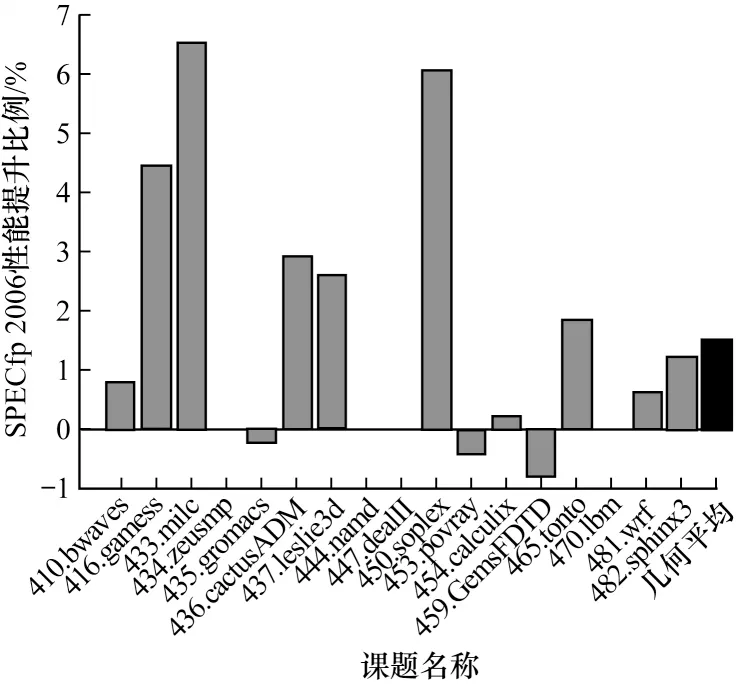
图8 SPECfp 2006 课题性能提升比例Fig.8 SPECfp 2006 project performance improvement ratio
性能提升最大的课题为整数课题401.bzip2,幅度为9.16%。该课题为解压缩程序,基于Julian Seward 的bzip2 v1.03 改写。负载包括JPEG 图片、可执行程序、源程序tar 包、HTML 文件以及混合文件等部分,覆盖了高可压缩文件与低可压缩文件,测试分别使用了三个不同压缩等级进行解压缩[26]。在本文使用的实验平台上,通过gprof 性能工具对课题函数运行时间进行统计,时间占比前二的函数依次为fallbacksort、mainSort,总共占据了整个课题的60%。进一步对两个函数源码进行分析发现,两个函数核心段均是对数组进行频繁操作且为间接访问,如fallbacksort 函数中的fmap 与eclass 数组访问和mainSort 函数中的quadrants 数组访问。因此,通过地址编译优化可以大幅提升该课题性能。
401.bzip2 课题热点函数fallbacksort 核心代码如下:

虽然多数课题都能通过地址优化获得正加速效果,但也有少数课题出现负加速效果,比如403.gcc 课题性能下降幅度最大为0.99%。通过分析该课题程序核心段汇编代码,发现使用地址优化后指令数量变化引起了指令排布不合理,从而出现负加速的情况。
6 结束语
本文针对编译器生成的访存地址计算代码效率低的问题,基于国产SW 处理器支持的带扩展因子运算指令,提出一种加速访存地址计算的编译优化方法。通过在编译器内存地址表达式合法性检查算法中识别乘加模式,并在代码生成阶段匹配生成带扩展因子的运算指令来计算访存地址,加快访存指令的发射与执行,从而提高国产SW 处理器访存效率。实验结果表明,该优化方法能够有效解决内存地址计算低效问题,提高国产SW 处理器系统的计算能力。下一步将分析SPEC CPU2006 部分程序倒加速原因,总结内存地址计算不同情形下的最优代码生成方案,完善GCC 编译器内存地址计算代码生成优化。
