基于双向语义的中文实体关系联合抽取方法
2023-01-27禹克强黄芳吴琪欧阳洋
禹克强,黄芳,吴琪,欧阳洋
(中南大学 计算机学院,长沙 410083)
0 概述
实体关系抽取任务的目的是从自然语言文本中提取实体及实体间关系,其为自然语言处理领域的一项重要研究内容,通过对文本进行语义关系分析,从而将非结构化文本转化为包含实体间关系信息的结构化数据,能够为知识图谱、信息检索、推荐系统等一系列下游任务提供有效支撑[1]。关系三元组是语义关系的基本单元之一,由主体、客体及它们之间的关系所组成的关系三元组(形如<主体,关系,客体>)代表了句子中实体之间的语义关系,这样的实体关系信息可以有效运用于文本语义建模[2]。
现有的关系抽取方法主要分为流水线(Pipeline)关系抽取方法和联合(Joint)关系抽取方法两大类[3],其中:流水线关系抽取方法将关系抽取任务划分为两个独立的子任务,先从给定的句子中识别其中的实体,再对实体间关系进行分类;联合抽取方法通过一个联合模型同时对句子中的实体和关系进行识别,根据其实现形式可以划分为参数共享和序列标注两类,参数共享方法通过在实体识别和关系抽取两个子任务中共享输入特征或内部隐层状态来实现模型联合,序列标注方法将关系抽取任务转化为序列标注任务,通过设计实体关系的联合标注策略来对任务进行建模。
尽管上述方法在关系抽取领域已经取得了较好的效果,但是它们大多存在仅从单一语义方向进行关系抽取的问题,例如,在句子“黑猫警长是上海电影美术制片厂制作的动画电影,由戴铁郎执导。”中,在关系“导演”的基础上,可以得到关系三元组<黑猫警长,导演,戴铁郎>,其中,“黑猫警长”是关系中的主体,“戴铁郎”是关系中的客体,如果将该关系三元组的主体和客体进行置换,则此时的关系三元组应为<戴铁郎,执导,黑猫警长>,主体与客体一旦交换了次序,它们的关系类型也随之发生改变,即主体到客体的关系信息与客体到主体的关系信息并不相同。现有的关系抽取方法大多仅利用单向的关系信息,然而,在大量的非结构化文本中,可能存在着一侧关系下语义特征不明显而另一侧语义特征较鲜明的情况。在上例中,关系类型“执导”的语义特征较关系类型“导演”的语义特征更为鲜明,在这种情况下,如果能有效利用双向关系的语义特征,就能够更深入地挖掘文本中所包含的关系三元组,并利用双向语义信息对关系三元组进行判别,从而提高关系抽取的准确率。
本文建立一种基于双向语义的实体与关系联合抽取模型BSCRE(Bidirectional Semantics Chinese Relation Extraction),其利用双向关系的语义信息,并结合正负关系下所得关系三元组的概率分布进行判别,以提高联合抽取的效果。为了避免句子单向语义特征不明显所导致的抽取错误,本文利用正负关系来捕获文本中的双向关系语义,设计一种基于正负关系映射的关系抽取模型,实现面向中文文本的端到端实体关系联合抽取,提高中文关系抽取的准确率与召回率。为了同时利用文本中的正关系和负关系语义,通过两组全连接神经网络分别构建正负关系映射器,同时从正关系与负关系的角度完成候选关系三元组构建。为了从候选三元组中识别正确的实体关系,基于候选关系三元组的正负关系概率分布序列和实体位置信息对候选关系三元组进行判别,利用全连接神经网络判别器,同时通过正关系与负关系的语义信息来确定最终的关系三元组。
1 相关工作
从自然语言文本中提取关系三元组是信息抽取中的一个热点研究问题,也是构建如DBpedia[4]、Freebase[5]等大规模知识图谱的重要步骤,能够有效地为搜索引擎、智能问答等下游任务提供支持。
基于传统机器学习的关系抽取模型通常利用特征向量完成关系抽取,如MIVA 等[6]利用词袋、词性等文本特征构建特征向量,KAMBHATLA 等[7]通过最大熵模型,利用文本的词法及语义特征进行关系抽取。由于特征向量的构建需要研究人员有着大量语言学的相关知识,并且可能导致误差的传递,而深度学习能够自动学习文本中的特征,通过学习每个词的表征来表示不同粒度的语义单元[8],同时具有较高的精确度,因此深度学习逐渐成为近年来学术界的研究重点[2]。
目前,主流的基于深度学习的关系抽取方法大致可以分为流水线关系抽取方法和联合关系抽取方法两种。
流水线关系抽取方法将关系抽取任务拆解为两个独立的步骤。NAYAK 等[9]在获取文本中所存在的所有实体后,通过分类网络对实体对间的关系进行分类。ZENG 等[10]采用卷积神经网络提取文本中的词汇及句子级特征进行实体对间的关系分类。ZHANG 等[11]通过将句子表征与实体表征相结合,并引入注意力机制来完成关系分类。SHIKHAR等[12]在图卷积神经网络的基础上添加实体类型和关系别名信息,以提高抽取效果。
虽然流水线方法实现简便,灵活性强,但是在实体识别过程中的误差有可能传递到关系分类中,从而造成误差的传递,因此,近年来学者们逐渐聚焦于联合关系抽取方法的研究。MIWA 等[13]基于LSTM最早实现了基于参数共享的实体关系联合抽取方法,参数共享是指关系抽取任务中的实体识别与关系分类两个子任务共用相同的底层参数,以学习语义信息更为丰富的隐层表示向量。KATIYAR 等[14]在此基础上,利用多层Bi-LSTM 和Attention 机制摒弃了以往方法过于依赖解析器性能的弊端。为了解决共享参数方法可能生成大量冗余信息的问题,ZHENG 等[15]通过序列标注的形式实现了实体关系的联合抽取,但是由于在标注过程中一个词只能被标注一次,从而导致该方案无法应对关系抽取中的关系重叠问题,尽管ZHENG 等[15]所提方法无法解决关系重叠问题,但为之后的研究提供了很好的理论基础。ZENG 等[16]使用带有复制机制的Seq2seq模型解决重叠问题,YU 等[17]和WEI 等[3]通过设计一种新颖的标记方案,将关系视为主体到客体的映射函数,即首先识别句子中的主体,然后根据传入的主体来识别对应的关系及客体,通过这样的设置,能够考虑到一个主体和多个客体之间存在关系的重叠情况,因此,能够有效解决实体间的关系重叠问题。
WEI 等[3]所提方法尽管很好地解决了关系重叠的问题,但是该方法仅利用了主体到客体的单向关系,关系三元组的正确抽取也依赖于主体的正确识别。客体到主体同样有着丰富的语义特征,因此,本文利用双向语义特征设计一种新的联合关系抽取模型BSCRE,其能够结合正关系与负关系完成关系抽取,从而有效避免由非结构化文本单侧语义特征不明显而导致的准确率下降问题。
2 相关定义
本文中的相关定义具体如下:
1)关系三元组。中文信息提取数据集定义为D={d1,d2,…,dn}(n>1),di(1 ≤i≤n)为数据集中一 个包含关系三元组的句子,关系三元组表示为<ei,rm,ej>(ei,ej∈E,i≠j,rm∈R),其中,ei和ej分别为关系三元组中的主体和客体,rm为主体ei与客体ej之间的关系,E和R分别为实体集和关系集,关系抽取任务的目的是从句子di中抽取出句子中所包含的所有关系三元组<ei,rm,ej>。
2)非互易性。在关系三元组中,大部分关系类型的主体和客体存在非互易性,即关系三元组<ei,rm,ej>与<ej,rm,ei>并不等价。例如,对于句子“老李是小李的父亲”而言,关系三元组<小李,父亲,老李>具有正确的语义,而<老李,父亲,小李>的语义是错误的。如果将关系三元组中的主体和客体位置交换,则三元组的语义随之改变,表示了不同的语义信息,即关系(ei→ej)与关系(ej→ei)并不等价,ei和ej存在非互易性。
3)正负关系。在一个关系三元组中,当且仅当实体ei和ej具备非互易性时,实体ei和ej间存在正负关系。对于预定义关系集合R中的关系类型ri,其对应的负关系为rTi。由于在双向关系语义中,负关系并不一定都有明确的关系词能与之对应,因此负关系rTi仅用于辅助完成关系三元组抽取,不指定明确的负关系词。对于正关系三元组<ei,rm,ej>而言,其对应的负关系三元组为<ej,rTm,ei>。本文设预定义关系集合为正关系集合R,表示原关系三元组中主体到客体的关系语义,对应的负关系集合为RT,表示原关系三元组中客体到主体的关系语义。
3 基于双向语义的中文实体关系联合抽取
关系抽取中传统方法对实体间关系进行划分,即f(ei,ej)→r,本文将关系视为主体到客体的映射函数,即fr(ei)→ej。与以往方法仅使用单向关系语义不同,本文方法将客体到主体的关系语义纳入模型中,将负关系视为客体到主体的映射函数,即frT(ej)→ei。如图1 所示,首先利用实体表征抽取模块对文本中的实体进行识别并抽取其实体表征,然后分别识别输入实体在正关系类型与负关系类型下的客体以得到候选关系三元组,最后由候选三元组判别部分,根据候选关系三元组在正负关系下的概率分布序列输出该候选关系三元组的最终置信度,若置信度大于阈值,则将其采纳。

图1 基于双向语义的实体关系联合抽取流程Fig.1 Joint extraction procedure for entity relationship based on bidirectional semantics
4 BSCRE 模型
基于双向语义的实体关系联合抽取模型总体架构是在文献[3]模型的基础上所提出的,BSCRE 模型首先对句子中可能存在关系的实体进行定位并获取其实体表征,然后同时利用正关系及负关系完成关系三元组抽取。如图2 所示,BSCRE 模型包括文本表示层、实体表征抽取模块、正负关系映射模块、候选三元组判别模块4 个部分。

图2 BSCRE 模型架构Fig.2 BSCRE model architecture
4.1 文本表示层
文本表示层采用RoBERTa 预训练语言模型[18]来获取句子的语义表征,从而使得到的语义表征X=[x1,x2,…,xn]包含RoBERTa 在预训练阶段所获得的先验语义知识。
首先,将输入的文本序列表示成向量形式,处理后字符序列中第i个字符的向量表示如式(1)所示:
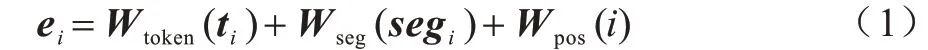
其中:Wtoken(ti)、Wseg(segi)、Wpos(i)分别为token 嵌入、分句嵌入、位置嵌入。
然后,将向量表示输入RoBERTa 中进行编码。RoBERTa 由12 个Transformer 模块[19]堆叠组成,取最后一个Transformer 的输出作为输入句子经过文本编码后的结果,如式(2)所示:

通过RoBERTa 预训练语言模型从输入文本Tj中获取具有上下文信息的字符表征序列H,用于后续抽取任务。
4.2 实体表征抽取模块
实体表征抽取模块根据输入的字符表征序列,利用首尾指针识别句子中所有可能存在关系的实体位置,并根据实体位置抽取实体表征。
4.2.1 实体首尾标注
本文模型利用两个全连接神经网络分别对句子中所有实体的首字符和尾字符进行标注,从而完成实体定位。其中:一个标注序列表示该位置字符是否为实体的首位置,如果是,则将其标注为1,否则标注为0;另一个同理,用于标注实体的尾位置。首尾标注如式(3)、式(4)所示:
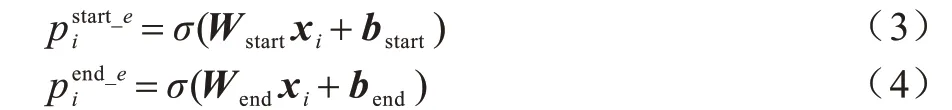
4.2.2 损失函数
本文模型采用二元交叉熵作为实体首尾标注的损失函数。实体表征抽取模块损失函数定义如式(5)~式(7)所示。因为文本中标签“0”的数量远比标签“1”多,所以将被标注为1 的概率乘以n次方,使初始状态更符合原始分布,加速模型收敛。
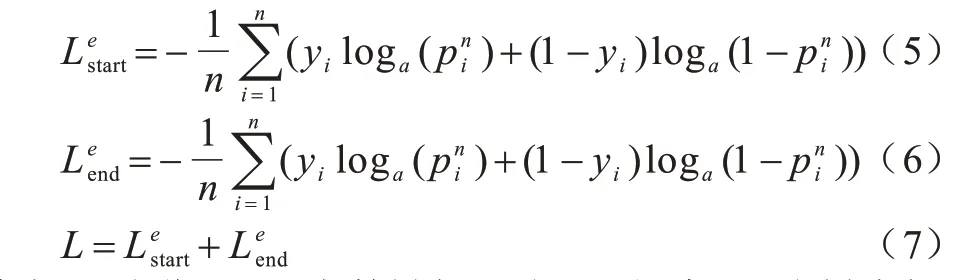
其中:pi为位置i处字符被标注为1的概率;yi为样本标签,如果i处字符被标注为1,则yi等于1,反之等于0。
4.2.3 实体首尾位置匹配
在获得实体的首尾位置标注序列后,采用就近匹配原则对两个标注序列进行匹配,如图3 所示,为同时完成对句子中多个实体的识别,本文对首指针标注序列中所有被标注为1 的字符,均与尾指针序列中位置在该字符之后的最近被标注为1 的字符进行匹配,图中箭头指向位置即为实体首字符所对应的尾字符,由此得到文本中的全部实体,包括“李白”“太白”“青莲居士”“唐朝”。

图3 实体首尾位置匹配Fig.3 Entity head and tail position match
在完成对实体位置的定位后,取字符表征序列中实体首尾位置及其中间字符表征取平均后的结果作为该实体的表征,用于后续任务,如式(8)所示:

其中:i和j分别为实体e的首位置和尾位置;He为实体的向量表示。
4.3 正负关系映射模块
如图2 所示,正负关系映射模块分别从正关系及负关系的角度,利用两组全连接神经网络根据输入实体获取候选关系三元组及其概率分布序列,并将未在实体表征抽取模块中被识别的客体重输入关系映射器,以保证每个候选关系三元组都具备正负关系下的概率分布序列。
4.3.1 基于正负关系映射的客体识别
正负关系映射模块如图4 所示,将每个实体的实体表征逐个与字符表征序列相拼接作为输入,并以该输入实体作为主体,分别在正关系和负关系下识别其客体。正负关系映射模块分为正关系映射器与负关系映射器,其中,正关系映射器用于识别输入实体在每一种正关系类型下的客体,而负关系映射器用于识别输入实体在每一种负关系类型下的客体。
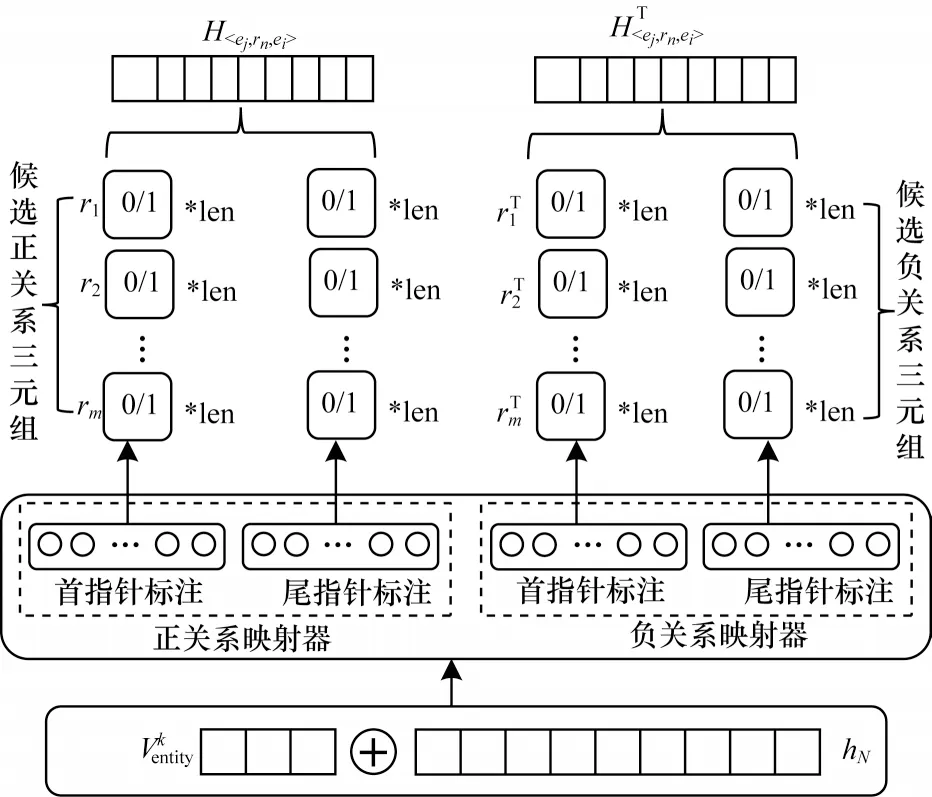
图4 正负关系映射模块Fig.4 Positive and negative relationship mapping module
正负关系映射器利用多层指针来进行客体位置标注,如图4 所示,假设文本中包含m种预定义关系类型,则经过正负关系的扩展后,总关系类型数为2m,为每一种关系类型建立两个指针标注器来对该关系下的客体进行标注。对于每一个输入实体,都在2m种关系下生成与字符序列等长的首尾标注序列,并利用如前文所述的就近匹配原则对客体进行定位。若在某关系类型的首尾标注序列中能够成功匹配到客体,则将此时的输入实体匹配到的客体及该关系作为一组候选关系三元组。在获取候选关系三元组后,根据关系映射器的输出构建其概率分布序列,具体过程如下:
1)训练样本构建。
在训练过程中,本文模型通过在句中关系三元组的所有主体和客体中随机选择实体的方式构建训练数据,如果选择的是原关系三元组中的主体,则此条训练数据是正关系映射器的正样本,同时是负关系映射器的负样本,如果选择的是原关系三元组中的客体,则此条训练数据是正关系映射器的负样本,同时是负关系映射器的正样本,通过这样的设计,可以保证训练过程中所构建的正样本与负样本大体均衡。
2)客体位置标注。
正负关系下的客体位置标注采用两组全连接神经网络对正负关系下的每一种关系类型进行遍历,从而定位输入实体在对应关系下的客体,如果定位成功,则将其作为一组候选关系三元组,如果不能定位到客体,则表示输入实体在该关系类型下不存在客体。对于每一个输入实体,均在正关系与负关系下对客体的首尾位置进行标注,其中,首指针用于预测句子中字符是客体起始位置的概率,尾指针用于预测句子中字符是客体终止位置的概率。客体位置标注如式(9)~式(12)所示:
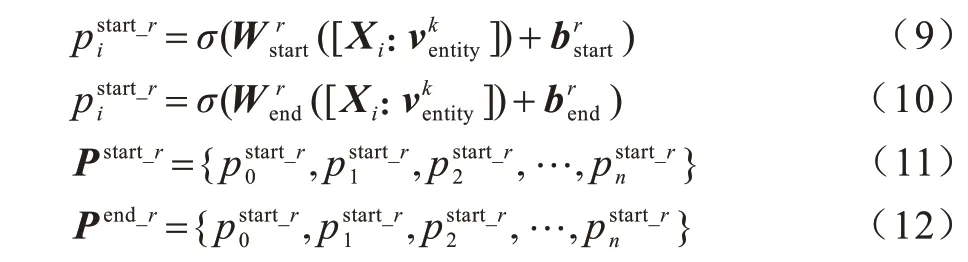
3)候选关系三元组概率分布序列。
本文模型分别为候选关系三元组构建在正关系与负关系下的概率分布序列,并对其进行判别,如图3 所示,当输入实体ei时,通过正关系映射器中的首尾指针定位到关系类型rn下的客体ej,则将<ei,rn,ej>作为一组候选关系三元组,并将此时它在关系rn处的首指针概率分布序列与尾指针概率分布序列相加,作为此候选关系三元组在正关系下的概率分布序列。将实体ej输入负关系映射器所得负关系类型下的首尾指针概率分布序列相加,作为候选关系三元组<ei,rn,ej>在负关系下的概率分布序列。候选关系三元组概率分布序列如式(13)、式(14)所示:

4.3.2 未登录客体重载
由于所得候选三元组中的客体可能未在实体表征抽取模块中被正确识别,从而导致候选关系三元组仅具备单向关系下的概率信息,为保证候选三元组具备正负关系下的概率信息,本文模型将检索关系映射器所得客体是否在实体表征抽取模块中被正确识别,如果没有被正确识别,则将这样的客体称为未登录客体,并将其重新输入到正负关系映射器中,以确保正负关系映射模块所得每个客体都被输入正负关系映射器。
将未登录客体重输入关系映射器,主要起到以下两个作用:1)当一个实体作为客体出现却未在实体表征抽取模块中被正确识别时,它有可能是未被实体表征抽取模块识别出的正确样本,同时它也有可能与另外的实体存在关系,因此,在关系映射器中识别出来的未登录客体同样应当为可能存在关系的实体,将其重新输入正负关系映射器,有助于挖掘包含此实体的关系三元组,降低因实体表征抽取模块识别不全所造成的误差;2)如果一个关系三元组中的两个实体仅有一个实体被实体表征抽取模块所识别,那么此时这两个实体所构成的候选三元组仅具备单向关系下的概率分布序列,无法通过双向关系对其进行验证,从而导致判别不准确。
4.4 候选三元组判别模块
为有效结合候选三元组在正负关系下的概率分布序列,本文采用全连接神经网络整合候选关系三元组在正关系与负关系下的概率信息,对候选关系三元组进行判别,得出最终的关系三元组。
4.4.1 候选三元组特征向量构建
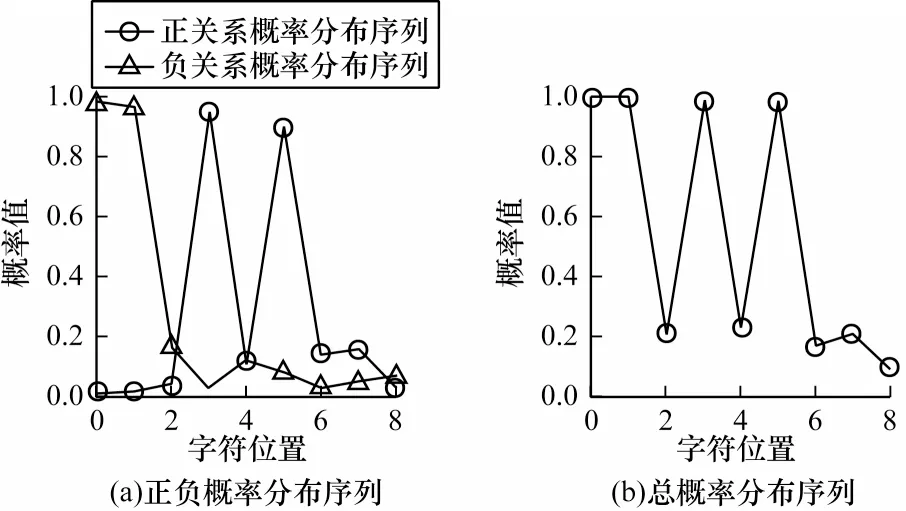
图5 概率分布序列Fig.5 Probability distribution sequence
4.4.2 候选三元组判别
如图6 所示,候选三元组判别模块将候选关系三元组的概率分布序列与首尾位置分布序列拼接并作为输入,通过隐藏层学习候选三元组的概率信息,并利用Sigmoid 函数输出该候选三元组的最终置信度Pspo。
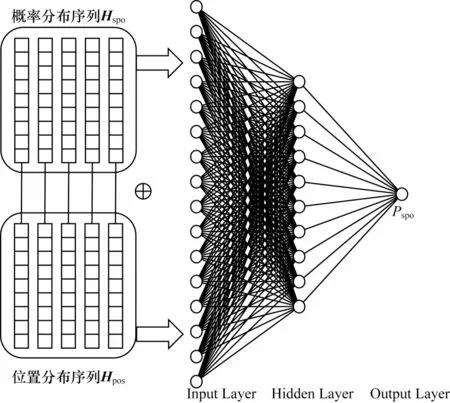
图6 判别器结构Fig.6 Discriminator structure
在本部分所利用的主要特征为候选关系三元组中实体首尾位置处的概率值及其在概率分布序列中是否具有显著性。当总概率分布序列中对应位置处的概率值均具有较高水平,即该候选关系三元组在正负关系下概率均高,则采纳该候选关系三元组,如果候选关系三元组单侧关系概率较低,即存在三元组中某个实体首尾位置处概率值较低的情况,则由判别器根据训练结果进行判别,如果候选三元组在正负关系下的概率均较低,则进行舍弃。

其中:W(·)为可训练权值;b为偏置项。采用二元交叉熵作为损失函数。
5 实验分析
为了验证本文所提关系抽取方法的有效性,从3个方面对关系抽取模型进行评估:首先,对利用单向关系完成关系三元组抽取与利用正负关系协同完成关系三元组抽取的准确性进行对比;然后,将本文模型与几个基线模型进行比较;最后,将本文模型在不同候选三元组判别器阈值下的抽取效果进行对比。
5.1 数据集与评价指标
本文采用百度DuIE 数据集[20]进行实验评估,该数据集是中文领域的大规模信息提取数据集,包含超过21 万条现实世界中的汉语语句及语句中的关系三元组,除此以外,数据集还预定义了50 种关系类型,该数据集中的所有数据均摘自百度百科及百度新闻提要。DuIE 数据集规模如表1 所示。

表1 数据集规模Table 1 Dataset size
本文实验采取的主要评价指标为精确率(Precision)、召回率(Recall)、F1 值(F1 Score),用于评估模型在实体关系联合抽取中的整体性能及预测结果。评价指标的计算公式如下:

其中:Nout_right、Nout_all、Ntest_all分别为预测正确的三元组数量、预测的三元组总数、测试集中的三元组总数。
5.2 实验设置
本文模型利用训练集进行模型训练,通过验证集进行最终评估。利用Keras 框架实现本文所提模型,实验在Windows10 系统的计算机上进行,机器配置为6 核i5 处理器,16 GB 内存,主要参数设置如表2所示。

表2 参数设置Table 2 Parameters setting
5.3 正负关系有效性分析
为了评估正负关系的设置对模型性能的影响,本文分别测试仅使用正关系映射器进行关系抽取、仅使用负关系映射器进行关系抽取以及通过正负关系映射器相结合进行关系抽取的性能,实验结果如表3 所示,最优结果加粗标注。从中可以发现,同时使用正负关系时模型的精确率、召回率及F1 值均高于仅使用单向关系的情况,在精确率上平均取得了1.6%的提升,这是因为正关系与负关系所包含的语义信息不同,利用负关系映射器的结果能够与正关系所得结果进行相互验证,进而提升精确率,同时,负关系的加入也有助于缓解文本在正关系下语义特征不鲜明的情况,从而提升模型的精确率。
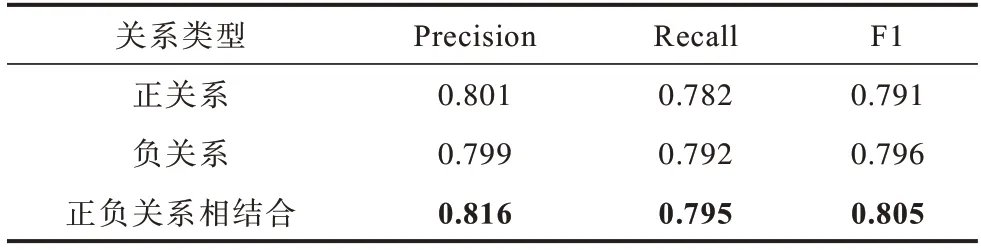
表3 正负关系有效性分析实验结果Table 3 Experimental results of positive and negative relationship validity analysis
5.4 对比实验
将本文所提模型与近年来前沿的关系抽取模型进行比较,用于比较的基线模型如下:
1)MultiR[21]是一种多实例联合学习关系抽取模型,能够应用于重叠关系抽取任务。
2)CoType[22]是基于序列标注的联合关系抽取模型,其将实体识别和关系抽取问题统一为全局序列标注问题。
3)指针标注模型[23]利用指针标注的方式完成关系三元组抽取,并引入共现实体特征和注意力机制来提升模型性能。
4)FETI[24]融合头尾实体类别信息来完成关系三元组预测,并增加对实体类别信息的约束。
5)Casrel[3]利用首尾指针 同时预测客体及它们之间的关系,能够有效解决关系三元组的重叠问题。
6)字词混合模型[25]通过引入字词混合嵌入来降低中文文本分词时由边界切分错误所导致的误差,并利用分层标记方法来解决关系重叠问题。
表4 列出了本文模型与6 个基线模型的性能比较结果,数据显示,本文所提模型的精确率、召回率和F1 值分别为0.816、0.795 和0.805,各项指标均高于基线模型,相较其他基线模型,在精确率、召回率及F1 值上平均分别提高了10.4%、14.4%和12.8%,这个提升来源于关系映射模块学习到了双向关系的语义信息,同时结合双向的语义信息对所得候选关系三元组进行判别,只有在双向语义中均满足一定条件的候选关系三元组才会被采纳,因此具有更高的准确率。此外,不论是正关系映射器还是负关系映射器所得到的客体,均有可能未在实体抽取模块中被正确识别,本文模型通过将未登录客体重输入关系映射器的方式,进一步提升模型的召回率。

表4 模型性能比较结果Table 4 Model performance comparison results
5.5 候选三元组判别模块阈值分析
为了验证候选三元组判别模块阈值对模型性能的影响,本文在不同阈值下进行对比实验,结果如图7 所示。从中可以看出,当阈值设置为0 时,模型输出的关系三元组为正负关系下的所有候选关系三元组,因此具有较低的精确率与较高的召回率,随着阈值的提高,精确率上升而召回率下降,这是由于阈值提高时置信度较低的候选三元组被舍弃,过滤掉了较多低置信度的负例,从而导致精确率上升,但同时也有部分拥有低置信度的正例被舍弃,使得召回率下降。F1 值随着阈值的提高先呈上升趋势后呈下降趋势,当阈值为0.41 时,F1 值为0.805,曲线达到拐点,此时模型效果最佳。
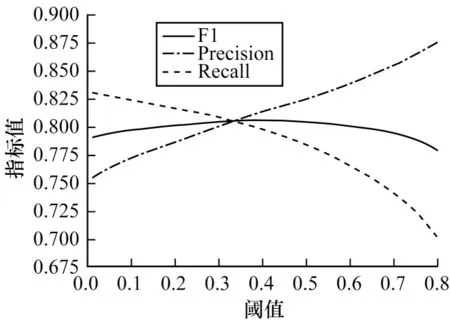
图7 阈值影响分析结果Fig.7 Threshold impact analysis results
6 结束语
本文在分析现有关系抽取方法的基础上,提出一种基于双向语义的实体与关系联合抽取模型BSCRE。首先使用预训练语言模型将句子转化为字符表征序列,然后对句子中所包含的有可能存在关系的实体进行定位并获取其实体表征,分别从正关系与负关系的角度获取候选关系三元组及其概率分布序列,同时,对于在预测过程中出现的未登录客体,将其重输入关系映射器,以确保每个候选三元组都有其正负关系下的概率分布,最后根据正负关系下的概率分布序列对候选关系三元组进行判别,以完成关系抽取。DuIE 数据集上的实验结果表明,该模型的精确率、召回率优于MultiR、CoType 等基线模型。但是,在本文模型中,候选关系三元组的抽取效果仍然依赖于指针标注的准确性,下一步将对指针标注方案进行改进,如采用语义信息更为丰富的预训练语言模型等,从而提高关系抽取效果。
