一种基于词频-逆文档频率和混合损失的表情识别算法
2023-01-27蓝峥杰王烈聂雄
蓝峥杰,王烈,聂雄,2
(1.广西大学 计算机与电子信息学院,南宁 530004;2.广西多媒体通信与网络技术重点实验室,南宁 530004)
0 概述
人脸表情包含丰富的语义信息,能够影响人们的沟通过程。近年来,人脸表情识别(Facial Expression Recognition,FER)在个性化推荐、社交应用、医疗健康、自动驾驶等诸多新兴交互系统中逐渐展现出应用价值,成为计算机视觉领域的一个研究热点。
在FER 任务中,受到人种不同、年龄差异以及侧脸、光照不均等外界因素的影响,其识别准确率普遍较低。随着深度学习技术在图像处理领域取得成功,基于深度学习的FER 算法已成为人脸表情识别领域的主流方法。当前较多的研究人员在数据处理、损失函数设计、特征提取等方面对FER 网络进行优化。
在数据处理方面,常规做法包括对图像进行几何变换、色调变换、局部遮挡处理等操作,以增加训练样本数量。在数据驱动的深度学习技术中,通过数据集来提高训练效果的方法已经被广泛使用。文献[1]提出一种针对FER 中嘈杂数据集的数据处理方法,通过对每个Batch 中的数据样本按照确定性进行权重排序和分组,在训练时加强确定性高质量样本的权重,抑制低质量数据对网络的影响。通过实验表明,该方法在数据嘈杂的FER 数据集中取得了较高的识别准确率。
在特征提取方面,有一些研究使用多CNN 支路并行的方式提取特征,如XU 等[2]为了提取更多细微的人脸表情,设计一个具有2 路并行的网络来分别提取不同尺度的图像特征,最后将特征进行融合并用Softmax 输出分类结果。有部分研究则侧重于对表情产生关键区域的特征进行提取,如VERMA 等[3]提出一个具有视觉和面部标识分支的网络,其视觉分支负责图像序列的输入,并引入从低层到高层的跳转连接,关注因面部区域(如眼睛、鼻子、嘴唇等)的变化而引起的面部表情信息,该方法在CK+数据集上取得了较高的识别率。CHEN 等[4]对VGG16 网络进行改进,提出一种20 层并基于VGG 和残差网络结构的CNN 网络,其采用混合特征策略将Gabor 滤波器CNN 并行化以实现表情识别,在部分遮挡的面部表情数据库中,该网络取得了较好的识别效果,具有良好的应用价值。文献[5]将表情图像划分成43 个子区域,将肌肉运动区与面部器官所覆盖的8 个候选区域输入8 个并行的特征提取分支以提取特征,每个分支使用不同维的全连接层,最后经Softmax 函数输出分类结果。
在损失函数方面,由于表情类间差异小,分类边界模糊,因此诸多研究通过改进损失函数来提高分类准确率。文献[6]为了加大不同类别中心之间的分类距离,提出岛屿损失函数(Island Loss),通过在特征提取层的Island Loss 和输出层的Softmax 损失监督CNN 训练过程。文献[7]在使用分组卷积操作对通道注意力模块进行改进后,引入孤岛损失函数,将其与Softmax 分类损失函数相结合,构建新的损失函数,并获得了较好的表情识别效果。文献[8]提出一种locality-preserving 损失函数,其使得同一类别的样本特征聚拢,每个表达式的类内局部簇更接近,最后将所提损失与Softmax 联合训练,增强了对表情特征的鉴别能力。
本文从特征提取和损失函数2个方面入手,对人脸表情进行识别。提出一种基于词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)的空间金字塔注意力机制,以增强表情关键区域的特征关注度,使用词频-逆文档频率算法强化表情关键区域内细微特征的权重值,增强表情特征的提取能力。同时,改进针对FER 任务的损失函数,在交叉熵损失和Arcface 损失函数的基础上提出一种混合加权损失函数(Weighted Hybird Loss function),从而缓解数据集中样本数量分布不均的问题,加强类内聚拢,增大类间边界。
1 注意力机制
1.1 空间金字塔注意力
近年来,注意力机制在计算机视觉任务中得到广泛使用[9]。注意力机制模拟了人类视觉辨析机制,人类的视觉系统会选择性地关注图像中的关键区域信息,同时忽略掉不重要的信息[10]。
空间金字塔注意力网络(SPANet)[11]是一种新颖的注意力结构,获得了ICME2020 最佳学生论文奖。SPANet 提出空间金字塔注意力结构(Spatial Pyramid Attention,SPA),利用3 个自适应平均池化构成金字塔结构,改进了SE-Net 注意力网络中由于在大尺寸、高分辨率特征图中应用全局平均池化(Global Average Pooling,GAP)所导致的细节信息丢失问题。SPANet 注意力结构如图1 所示[11]。
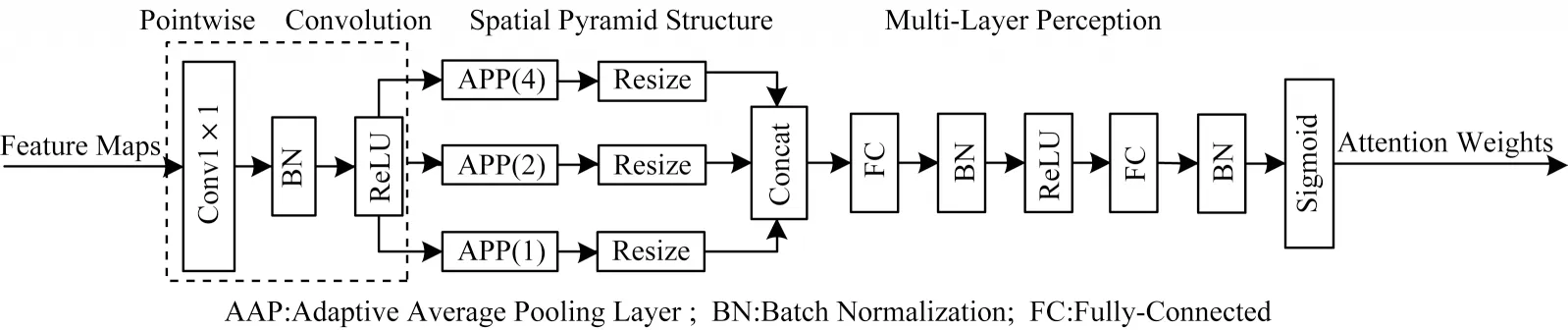
图1 SPANet 注意力结构Fig.1 SPANet attention structure
在图1 中,在对输入特征图进行逐点卷积后,使用3 个自适应平均池化改进传统的全局平均池化以统计空间上下文信息,使得提取到的特征图中保留更丰富的细节信息,有助于提升细粒度表情分类效果。本文所设计的注意力机制是在SPANet 基础上进行的改进。
1.2 词频-逆文档频率原理
TF-IDF 常被应用于自然语言处理(Natural Language Processing,NLP)及搜寻引擎中,用于评估某一个词组对于某文档集的重要程度,是某个词语普遍重要性程度的度量。在NLP 任务中,字词的重要性随着其在文档中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF 可保留文档中较为特别的关键词,过滤掉语义信息不明显的常用词,如the、is 等。受此启发,本文引入TF-IDF 改进注意力机制,增强网络对表情产生关键区域重要特征通道的提取能力。
在FER 数据集中,通道特征图中非零像素(白色区域少)占比小,灰度值像素区域占比大。在表情表达的过程中,嘴角、眉间、眼角等非零像素区域具有关键的特征,为了降低这些重要特征在多轮池化中丢失的可能,提高这些非零像素细微特征在人脸表情判断中的重要程度,本文使用TF-IDF 引导金字塔池化注意力网络关注语义信息更明显的表情产生区域,增强嘴角、眼角等关键区域的细微特征表达。
1.3 词频-逆文档频率空间金字塔注意力
在细粒度表情识别中,当图像特征细微且出现次数有限时,特征提取网络容易忽略掉该区域的细节特征,造成细节信息丢失,从而影响最终的分类结果[12]。使用TF-IDF 构建注意力机制捕捉重要特征并学习其与表情类别之间的关联,能够使网络形成更准确的注意力热图,从而提高网络的分类性能。
将TF-IDF 算法思想结合到金字塔池化注意力机制中,得到逆向文档频率空间金字塔注意力(TFIDF SPA),其结构如图2 所示。

图2 TF-IDF SPA 注意力机制结构Fig.2 TF-IDF SPA attention mechanism structure
TF-IDF SPA 注意力机制由两部分结构组成,上半支路为词频-逆文档频率模块,下半支路使用SPA注意力机制实现,TF-IDF 模块和SPA 注意力模块进行Concat 拼接后形成新的注意力输出,用以对输入特征图进行注意力处理。
在上支路的IDF 模块中,从左到右包含3 个主要的功能结构。上支路的实现过程为:
1)计算非零区域词频,该部分的处理过程如图2上半部分所示,在经过批归一化(Batch Normalization,BN)后进入通道处理过程,通过计算通道特征中非零像素的个数和通道像素的总数,将两者相除获得通道特征中非零区域的占比。用Ni表示每一个通道特征图中非零像素的个数,每个通道特征图大小为W×H,统计出某一个非零区域在一个给定区域中出现的频率Di,计算过程如式(1)所示:
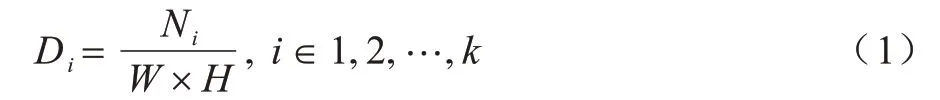
2)求出该区域中非零像素的普遍重要性。本步骤求取逆文档频率IDF,其数值能衡量某一特征的普遍重要性程度,通过特征图中所有特征通道数量除以包含该特征的通道数量然后取对数得到,计算方法如式(2)所示:

3)对式(2)中的结果用Sigmoid 函数激活,如式(3)所示:
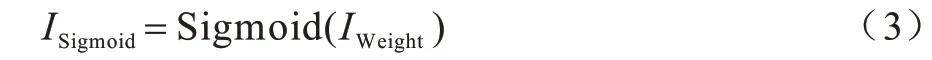
4)最后求出词频注意力权重,将词频与逆文档频率相结合获得输出权值,如式(4)所示:
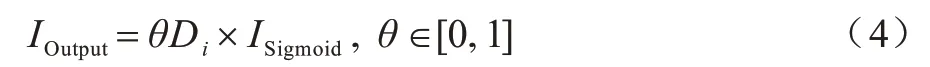
式(4)为TF-IDF 部分的输出结果,其中,θ为调整词频对最终结果的影响,取值范围为0~1,本文经实验测试,取θ值为0.15。
下支路SPA 注意力模块由3 个部分构成,如图2 中下半部分所示,从左到右第一部分结构为1×1 卷积、BN和Sigmoid 激活函数,主要用于匹配输入特征图的通道数并提取特征;第二部分为自适应空间金字塔池化结构(Adaptivce Average Pooling,AAP),图2 中AAP(4)和AAP(2)分别代表不同下采样尺度的池化操作,通过并行加入3 个不同尺度的池化层,保证特征图的多样性,减少传统全局平均池化聚合到一个平均值而导致的信息丢失;第三部分为多层感知模块,由全连接层(Fully-Connected)、BN 和激活函数组成。
1.4 基于TF-IDF SPA 的残差模块
在词频-逆文档频率注意力机制中,下支路SPA注意力机制所得的权重与上支路TF-IDF 模块输出的Ifinal系数进行叠加形成TF-IDF SPA 注意力权重,从而提取表情产生区域词频重要性高的关键细节特征。在本文中,将TF-IDF SPA 组成带有残差结构的模块嵌入网络中使用,模块结构如图3 所示。

图3 由TF-IDF SPA 组成的残差模块Fig.3 Residual module composed of TF-IDF SPA
TF-IDF SPA 注意力模块使用金字塔池化避免全局平均池化所导致的表情特征丢失,丰富表情特征图的细节表示,并使用词频-逆文档频率引导注意力网络突出关键区域的重要细节特征。
2 损失函数改进
在图像分类任务中,常用Softmax 作为损失函数监督网络训练,该损失函数结构简单,在多数情况下能取得良好的分类效果,但在人脸表情识别任务中,表情样本存在数据类别分布不均、样本类间差异小、类内差异大、某些表情之间分类边界模糊的问题。因此,对损失函数进行改进成为提高表情识别准确率的关键步骤。本文主要的改进思路是:加强同一类表情的类内聚拢性,加大不同类别模糊表情间的分类边界,同时调节权重使得网络关注小数据量样本类别的学习。
2.1 同类样本类内聚拢
WEN 等[13]在传统Softmax 函数的基础上进行改进,提出Center Loss 函数,其为每个类别的数据定义一个样本中心,各类别的样本均向本类别的样本中心聚拢,聚拢方法为:

其中:xi为第i个样本对应的特征向量(全连接层之后、决策层之前提取到的特征)是第i个类别样本的中心点处。通过最小化Lcenter使得每个批次中的每个样本与聚类中心的距离缩小,从而把相同类的样本都聚拢到类别中心,使得类内簇更加紧密。
2.2 类间边界增大
类间边界增大通常有如下两种方法:
1)岛屿型损失。
在类内聚拢的基础上扩大类间距离,能使决策边界更为清晰,有助于模型分类。CAI 等[5]提出一种孤岛化分离不同类别样本的方法,使得类间差异显著增大,其表达定义为:
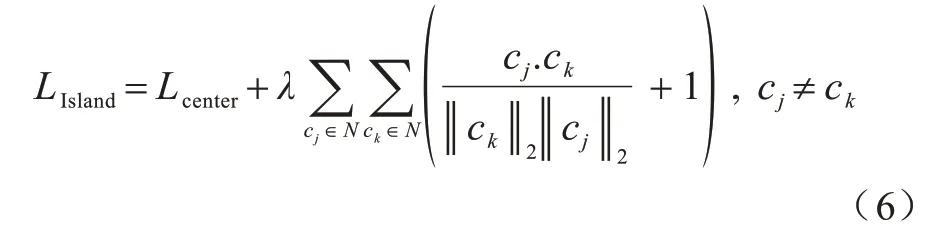
式(6)由2 个部分组成,Lcenter使得类内簇聚拢,后一部分为求每个类别中心的余弦间距,式中+1 操作使得变化范围为0~2,越接近0 即代表类别之间差异越大,从而训练Loss 收敛后实现类间距离变大的效果。经式(6)的损失函数处理,7 个表情类别各自分离为7 个岛屿化分布,如图4 所示。
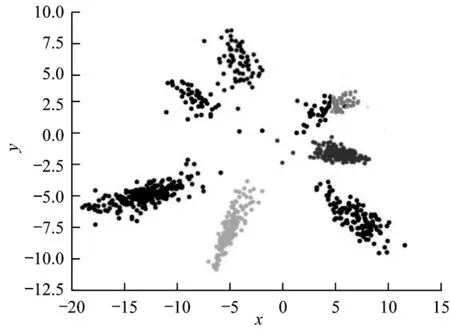
图4 岛屿型损失函数样本分布Fig.4 Sample distribution of Island Loss function
2)基于角度距离优化方法。
WANG 等[14]提出一种基于余弦距离(Cosine Margine)的损失函数,引入角度间距,使用cosθ减去某一标量m,设定不同的类间边界,如下:

式(7)为划定的分类边界,利用m的取值大小在不同的类别中形成不同大小的分类边界:
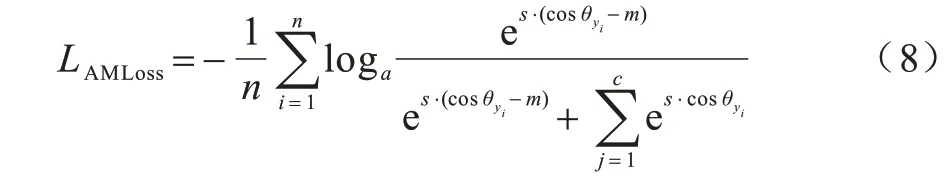
式(8)为其标准实现过程,在实现过程中,将输入特征做归一化处理,使得x=cosθ yi,因此,间距简化为:

使用式(9)替换式(8)的cosθ,该表达式最终写为:

在式(10)中,WANG 等[14]引入了超参数s,为了提高损失函数LAMLoss的收敛速度,s设为固定值30。
2.3 加权重的分类损失函数
2.3.1 交叉熵损失函数
交叉熵损失(Cross Entropy Loss,CE)函数应用广泛,其可以保证神经网络的基本分类能力,表达式为:

在FER 数据集中,每个类别的样本数量不平衡。在各类别数量差异大的数据集中,网络通常倾向于拟合数量较大的类别,由于训练损失下降到一定程度后,在碰到困难样本时,将分类结果“简单而盲目”地判定为大数据量对应的类别即可获得概率更大的准确率,而对于小数据量样本类别,网络则需要花费更多的训练代价才会取得训练损失值很小幅度的下降,这就导致了网络对小数据量类别及难例样本的训练“惰性”,从而影响特征提取效果。对分布不均匀的数据集进行权重调整,有利于难例样本和小数据量样本的特征提取。
2.3.2 权重调整方法
本文在损失函数设计中提出一种提高不平衡分类性能的方法,根据不平衡样本类分配比例调整加权值,其定义如下:

其中:N为总样本数;L为总类数;mk为某一类别k的样本数。通过式(12)操作调整不平衡样本的权值。
2.3.3 加权交叉熵损失函数
加权交叉熵损失函数定义为:

式(13)是权值分配方法与传统交叉熵损失函数相乘而得到的,通过此设计优化了损失函数中小数量、难分类样本的权重,使得模型在训练过程中更关注小数据量样本和难例样本。
2.4 混合加权余弦损失函数
本文最终基于角度距离的损失函数为:
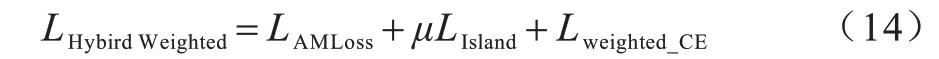
其中:μ为岛屿损失将样本孤岛化分布的系数,在实验中取0.01 可获得较快的收敛效果;LAMLoss作为辅助分类损失函数,目的在于拉开分类边界;Lweighted_CE监督分类输出。混合加权损失LHybirdWeighted获得了优于现有单一损失函数的分类效果,在实验中取得了更快的收敛速度和更高的分类准确率。
3 网络总体结构
本文使用CNN 特征提取网络结构,由多层3×3 小尺度核卷积层嵌入TF-IDF SPA 注意力模块堆叠组成,图5 所示为总体网络结构。图中R×R×C表示每层输出分辨率大小为R×R、通道数为C的特征图。每个卷积组合依次为批归一化BN、3×3 卷积、Mish 损失函数。第一个全连接层使用岛屿损失LIsland促使特征形成岛屿形分布。最后一层使用LAMLoss加大类间界限,同时利用加权重的分类损失函数LWeight_CE对高维特征进行分类输出。网络中的主要参数如表1 所示。

图5 网络总体结构Fig.5 Overall network structure

表1 模型主要参数Table 1 Main parameters of the model
4 实验分析
本文实验配置:处理器Intel Xeon Gold 6230,显卡NVIDIA Tesla T4,内存16 GB,操作系统Ubuntu 16.04,深度学习框架Pytorch,编程实验均在Python 3.7 环境下进行。
4.1 数据集
4.1.1 数据集类别
CK+数据集[15]是CK 数据集的扩展,包含593 个视频序列和7 种静态表情图像。静态图像是在实验室环境下拍摄的年龄从18 岁~30 岁的123 名受试者的表情图像,共计981 张。CK+实验数据包含高兴、厌恶、害怕、生气、伤心、惊讶、蔑视7 类。由于数据集样本数量少,为了提高测试的准确性,使用K 折交叉验证法[16]进行实验,在实验中随机将数据集划分为K个,其中K-1 个用于模型训练,剩余1 个用于测试,本实验中K取10。CK+数据分布如图6 所示。

图6 CK+数据集中的各类别样本分布Fig.6 Distribution of various samples in CK+dataset
FER2013 数据集[17]从互联网中收集而得,是Kaggle 人脸表情竞赛数据集,且为目前规模较大的表情识别数据集[18]。FER2013包含人脸图像35 887张,28 709 个训练图像、3 589 个验证图像和3 589 个测试图像,带有7 个标签,分别为愤怒、厌恶、恐惧、快乐、中性、悲伤和惊讶。数据集中的样本在年龄、人种、面部方向等方面都有很大的差异,存在侧脸表情及模糊卡通表情,是一个具有挑战性的表情识别数据集。FER2013 数据分布如图7 所示。

图7 FER2013 数据集中的各类别样本分布Fig.7 Distribution of various samples in FER2013 dataset
4.1.2 数据增强操作
数据增强是在不改变样本类别标签的情况下对数据进行几何变换、色调变换、像素扰动、添加噪声等操作,能简单有效地扩充训练集数量,提高网络在复杂背景下的泛化能力,对于CNN 训练过程意义重大。在本文实验中,对数据进行水平翻转、伽马变换和随机遮挡,将训练数据量扩充8 倍,操作如图8所示。

图8 在FER2013 数据集中的数据增强操作Fig.8 Data enhancement operation in FER2013 dataset
4.2 结果分析
为了验证本文所提方法的有效性,实验中将所提方法分别加入网络中进行对比。
实验1TF-IDF SPA 注意力机制有效性实验
本部分进行4 组对比实验,在FER2013 中使用交叉熵损失函数的情况下,验证未加入注意力机制、加入SE 注意力机制、加入SPA 注意力机制、加入TFIDF SPA 注意力机制在FER2013 数据集上的有效性,实验结果如表2 所示。

表2 注意力机制有效性实验结果Table 2 Experimental results of the effectiveness of attention mechanism
从表2 可以看出:采用不加注意力仅使用残差结构的特征提取网络进行特征提取,所得的识别准确率为68.79%,性能较差;采用SE 注意力机制改进特征提取网络,准确率得到3.24 个百分点的提升;用SPA 金字塔空间池化注意力取代SE 注意力,性能提升0.11 个百分点;加入TF-IDF 模块后,网络识别准确率持续提升,较SPA 注意力提升了0.32 个百分点,较不加注意力提升了3.67 个百分点,提升效果明显。实验结果表明,注意力机制对于特征提取效果具有积极的作用,同时改进型的TF-IDF SPA 注意力较SE、SPA 等注意力能获得更好的识别效果。
实验2改进损失函数有效性实验
本部分进行5组对比实验,在使用相同TF-IDF SPA注意力机制特征提取网络的情况下,分别测试Cross-Entropy、Weighted Cross-Entropy、Island Loss、AMLoss、混合加权损失函数的作用,结果如表3 所示。

表3 改进损失函数有效性实验结果Table 3 Experimental results of the effectiveness of the improved loss function
从表3 可以看出:使用加权的交叉熵损失函数(Weighted Cross-Entropy),较Cross-Entropy 有小幅度的性能提升,在CK+中准确率提升了0.12 个百分点,在FER2013 中提升了0.25 个百分点;Island Loss和AMLoss 在CK+、FER2013 中取得了类似的性能;混合加权损失函数作用于网络时,在CK+中准确率比AMLoss 提升了0.66 个百分点,在FER2013 中准确率较Island Loss 提高了1.1 个百分点。实验结果表明,本文所提混合加权余弦损失函数在识别准确率上有一定提升。
实验3本文所提算法与当前较新算法的对比实验
表4 对比了当前针对CK+和FER2013 且较新的算法识别准确率,最优结果加粗标注。在CK+中,文献[22]算法利用纹理、几何特征、语义特征等手工特征与改进后的自动编码器网络进行融合,再输入到Softmax 分类器中进行面部表情识别,达到了较好的性能,但是,相较全程使用CNN 自动提取特征的方式,其算法过程相对繁琐。本文算法识别准确率在CK+数据集中与文献[23]算法较为相似,本文算法比该算法高0.09 个百分点,在FER2013 数据集中,本文算法的准确率比该算法高1.41 个百分点,识别准确率提升明显。

表4 不同算法的对比实验结果Table 4 Comparative experimental results of different algorithms
图9(a)、图9(b)分别为CK+和FER2013 数据集上的混淆矩阵。由图9 混淆矩阵可见,“高兴”“惊讶”这2 个类别识别准确率均较高,这是由于数据集中这2 个类别与其他类别特征差异明显,经本文损失函数增强分类边界后,类间距离更加清晰,网络容易准确识别。图9(b)比图9(a)分类模糊数量多,这是由于FER2013数据集中嘈杂样本较多,且某些类别样本较为相似,如“悲伤”“中性”“恐惧”之间类间边界模糊,人类也难以准确区分,导致了分类混淆的现象。

图9 本文算法的混淆矩阵Fig.9 Confusion matrix of this algorithm
5 结束语
本文针对人脸表情识别任务,提出一种基于词频-逆文档频率的改进型注意力机制TF-IDF SPA,引导网络关注表情关键区域的重要细节特征。本文使用简单卷积层堆叠和带残差结构的TF-IDF SPA 模块提取表情特征,能够达到与诸多复杂模型相同的特征提取效果。在损失函数设计上,针对细粒度分类任务中类间差异小而类内间距大的问题,设计混合加权损失函数,根据数据集的分布调整加权值,从而引导网络挖掘样本数量少、识别难度大的训练样本特征信息。同时,在保持表情类别之间岛屿型分布的同时使用余弦距离调整类间间隔,增大类间距离。FER2013、CK+数据集上的实验结果验证了本文改进注意力机制和改进损失函数的有效性。
目前,网络特征提取过程还未加入多尺度卷积核以进行不同感受野下的特征提取,且本文还未针对局部遮挡、戴眼镜、侧面人脸等复杂条件进行针对性地研究。下一步将优化注意力机制,在更具挑战性的真实部署条件下进行算法设计,以实现更好的运行效率和识别效果。
