双匹配焦点融合的开放域答案选择模型
2023-01-27何俊飞张会兵胡晓丽
何俊飞,张会兵,胡晓丽
(1.桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004;2.桂林电子科技大学 教学实践部,广西 桂林 541004)
0 概述
在当前开放域问答(Question Answering,QA)系统中,一个问题通常会有各种各样的答案。简单高效地从众多答案中择取合理、高质量的答案,同时排除无效、低质量的答案对于问答系统至关重要,也直接影响着系统的用户体验。随着大规模社区问答平台的兴起,答案选择问题引起了越来越多研究人员的关注[1-3]。与通常的单语句分析任务相比,答案选择任务的对象往往是两个及两个以上的句子,导致对输入对象的语义抽取与表征变得更加困难。
以往研究大多基于概率统计的机器学习方法,主要关注点在于对问答语句中各关系词对的抽取和细节描述[4],忽略了问答语句之间的整体语义与交互关系。近年来,基于神经网络的深度学习方法得到广泛应用,研究人员提出多种端到端的答案选择模型,减少了对特征工程的构建[5-7]。随着注意力机制的发展,研究人员提出将深度神经网络与注意力机制相结合的比较聚合模型,将语句的匹配、表征与交互融为一体,不仅突出语句本身需要表达的要点,同时还提升了问答语句之间的交互效果[8]。然而,现有研究大多只从词级或者句子级中的单一层面将问题与答案中的单词进行直接匹配,缺乏语义参照关系,导致损失一些可以捕捉的细节信息。比如对于问句“吃苹果?”与“吃苹果或梨?”,两个问句都是动宾结构,但回答却完全不同,前者关注点完全落在动词上,而后者的关注点完全落在名词上。由此可以发现,单一层面的匹配可能会因为对照关系的缺失导致语义匹配焦点的错位。
本文根据相邻相似原理,提出一种双匹配焦点融合的答案选择模型(DMFF)。基于问答任务多语句对象的特点,设计一种专门用于答案选择的词嵌入方式,保留词对在问答语句间承接关系的更多细节信息,并以此计算词级层面下的焦点矩阵。借鉴seq2seq 模型在语言翻译[9-10]和阅读理解[11-12]任务上的运用方式,利用带有注意力机制的Encoder-Decoder 翻译模型提取句子级层面的词对匹配,获取问答语句间的整体语义关系和对应的焦点矩阵。最后,将两个焦点矩阵对齐,计算问句中每一个单词在两个矩阵中的相对距离,以此融合词级与句子级匹配焦点,获得问答对匹配分值。
1 相关工作
随着开放域问答任务的兴起,答案选择得到了越来越多的研究。起初,主要通过概率统计的机器学习方法来构建答案选择模型。文献[13]提出一种利用问答连接依赖树之间的操作代价来衡量问答语句之间距离的方法,由于该方法引入了语法信息,因此比简单词袋模型的效果更优。文献[14]发现外部资源对模型的性能影响很大,增强的词汇语义信息可以提升答案选择模型捕捉语句间关系的能力。而文献[15]将逻辑回归模型应用于特征自动提取,减少手工操作的成本。上述方法的建模方式仅依赖于词汇关系,在效率和成本上存在显著缺陷。基于神经网络的深度学习方法对问题与答案的表征效果超越了多数基于概率统计的机器学习方法[4]。文献[5]将问题与答案连接成一个单词序列串,然后利用长短期记忆获取序列串的特征,得到问答语句的匹配值。文献[6-7]将每一个词汇展开成词向量后拼接成一个空间网格图像,然后用卷积神经网络捕捉图像之间的依赖程度。这些方法都不需要构建外部资源库,且能够从句子级层面对问答语句间关系进行匹配。多语句处理任务需要较高的语句间交互能力,注意力机制在突出语义表达的同时,也可用于提取语句间的交互关系。针对答案选择任务,文献[16]结合注意力机制提出多跳注意力网络模型,多次利用顺序注意力循环关注问题与答案中的不同话题点,并计算每一个话题下问答特征向量的相似度,然后对所有话题求和,得到最终的问答匹配得分。之后,在上述工作基础上,大部分学者以比较聚合模型为基础框架,分别就注意力机制[17]、聚合方式[18]、语素匹配[19]和交互模式[20]提出更加新颖的方法,其中文献[20]从单句、句对和句子列表3 个层级充分挖掘问答的交互信息,并将3 个层级上的信息进行融合得到最后的匹配分值。
随着词嵌入方式在自然语言处理中的成功运用,利用预训练方法改进模型成为一种趋势。文献[21]用分布式模型构建单词之间在局部语境中的表示关系,并以此得到一个单词对应的唯一向量表示。文献[22]利用一个局部到全局的转移矩阵增强词向量的全局语境特性。文献[23-24]结合上下文对单词进行语境化嵌入,根据上下文语境的变化对同一单词用不同的向量表示。相对来说,后面两种方法在预训练模型中更具优势。文献[25]利用Bert模型,使答案选择任务效果达到了现阶段最优。
2 本文模型
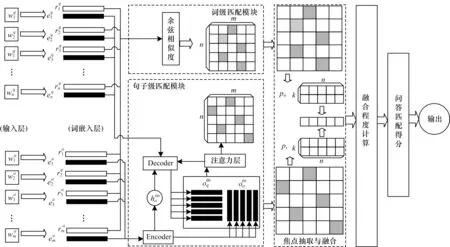
图1 本文模型的整体结构Fig.1 Overall structure of model in this paper
2.1 词级匹配模块
词级匹配是直接通过词嵌入向量进行词对余弦相似度匹配,其对应的词级匹配模块就是对问题中的每一个单词与答案中的每一个单词进行匹配,得到匹配焦点分布矩阵。为满足问答任务的需要,提出一种基于问题-正负答案对(Question to Positive and Negative Answer Pair,Q-PNAP)的词嵌入方式,如图2 所示。
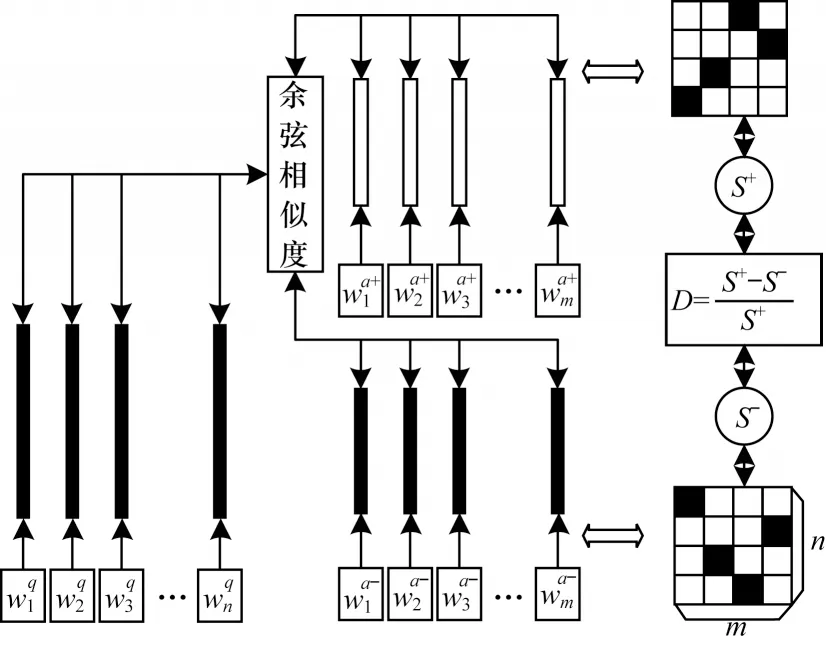
图2 问题-正负答案对词嵌入的示意图Fig.2 Schematic diagram of question to positive and negative answer pair word embedding
首先对问答语句中的每一个单词随机初始化一组向量。表示对问题中的第i(1 ≤i≤n)个单词进行随机向量初始化,表示对答案中的第j(1 ≤j≤m)个单词进行随机向量初始化。初始化后问题中的第i个单词与答案中的第j个单词所对应词对的词性相关程度sr(i,j)表达式如式(1)所示:

由于问题中的每一个单词与答案中的单词不存在一一对应关系,所以答案中可能会有多个单词同时与问题中的同一个单词产生关联,这时本文用K代表抽取出的词对个数。即取出问题中各单词对应答案中的前K个与之最相关的单词,并将这K个词对的词性相关程度大小之和作为对应单词的匹配得分其表达式如式(2)所示:
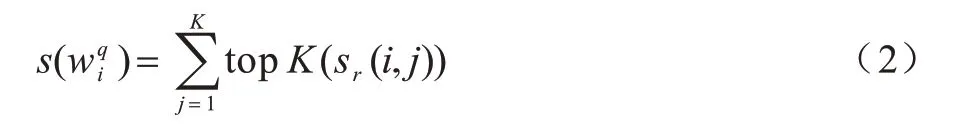
其中:topK(X)表示取出X数组中由大到小排序的前K个值。对问题中所有单词的匹配得分进行求和,得到问答对(q,a)的最终匹配得分S(q,a),其表达式如式(3)所示:

由于初始时刻随机初始化的词嵌入表示中不包含任何单词的语法语义信息,故需要结合问答语句训练出一组合适的词嵌入表示。对同一个问题q选取一对答案,其中一个是正确答案a+,另一个是与问题相关的同领域内的错误答案a-,此时的问答组合可以用一个三元组(q,a+,a-)表示,利用式(4)和式(5)分别计算在当前随机词嵌入表示情况下的问答匹配得分情况。
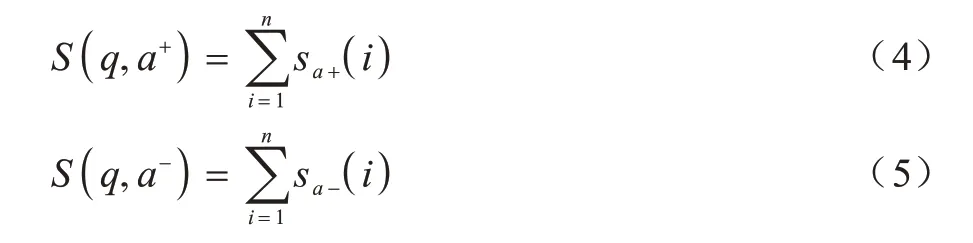
在前提假设下有:

定义一个D值表示同一问题下正确答案与错误答案的相离程度,如式(7)所示:
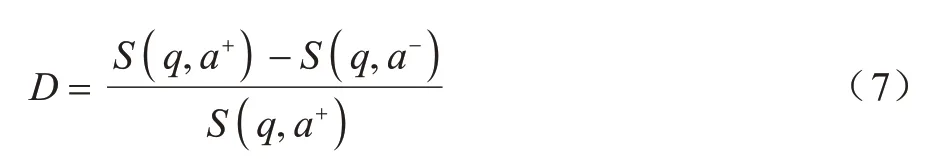
D值的合理取值区间为(0,1),当D 值超出此区间时,表示出现异常。当D值趋近于1 时,表示正确答案与错误答案相离程度最大,越符合实际情况。训练问题-正负答案对词嵌入表示模型的损失函数l(q,a+,a-)如式(8)所示:
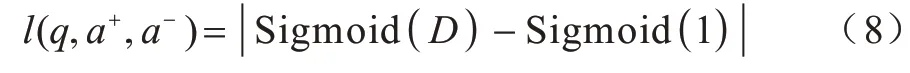
为防止异常情况导致损失函数输出过大或者过小的值,在式(8)中引入Sigmoid 函数对相离距离进行输出为(0,1)的规范化处理。
2.2 句子级匹配模块
句子级词对匹配是通过理解问题与答案之间的上下文衔接关系之后,计算问题中各单词与答案中各单词的匹配关系。该模块选取了带有注意力层的Encoder-Decoder 翻译模型来完成句子级词对匹配。Encoder 与Decoder 分别对答案和问题进行编码后输入注意力层,注意力层对输入的编码向量从语义层面上进行筛选和匹配,最终通过一个注意力矩阵保留问题在答案中的匹配焦点分布。具体步骤如下:
首先对输入的答案用BiGRU 进行编码,得到答案的编码矩阵与特征向量,表达式如式(9)所示:
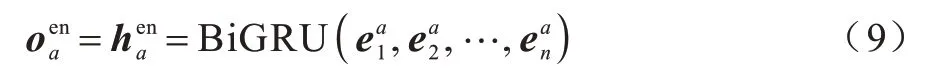
其中:为答案的第n个词嵌入向量,将编码器输出的编码矩阵与特征向量分别通过2 个全连接层将原来的编码状态过渡到解码状态,该过程的表达式如下:


此时已经得到句子级层面的词对匹配焦点分布,不过为了训练参数与,还需要利用解码器的解码输出与真实问题进行损失值计算。答案在编码状态的编码矩阵经过注意力层后变为问题在编码状态下的编码矩阵,表达式如式(14)所示:

连接问题编码状态与解码状态下的状态矩阵与,在经过两层全连接层后得到答案的解码输出wout,表达式如式(15)所示:

其中:为解码预测出第i个单词在词典中各单词的取值大小;pi为真实答案中第i个单词在字典中的位置。
2.3 问答词对筛选与融合层
通过上述2 个焦点匹配模块分别得到词级焦点分布矩阵sw∈Rn×m,其中sw矩阵第i行第j列的元素为=sr(i,j)。句子级焦点分布矩阵ss∈Rn×m,其中ss矩阵第i行第j列的元素为。对两个匹配焦点矩阵中的元素进行抽取与融合。首先,对问题中的某一个单词,选取答案中与其最相关的前K个单词,同时记录下这K个单词在答案句子中的位置。对于词级匹配问题中的每一个单词,在答案中,根据相关程度由高到低记录前K个最佳匹配单词的位置,如式(17)所示:

其中:topKp(X)表示取数组X中前K个最大值所在的位置。同理,对于句子级匹配问题中的每一个单词,在答案中根据相关程度由高到低记录前K个最佳匹配单词的位置如下:

无论是词级匹配还是句子级匹配,由相邻相似的原理可知,对于问题中的同一个单词,2 个视角匹配下的焦点位置应尽可能相邻。融合词级与句子级匹配的结果,定义两者的融合误差如下:

最终得到整个问答对的匹配得分情况:
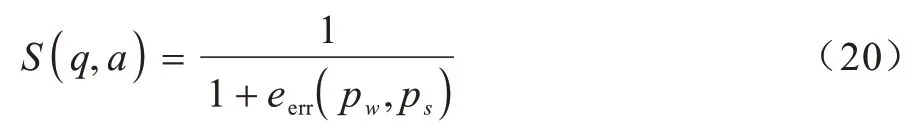
其中:S(q,a)为一个(0,1)之间的数。对于同一个问题,当S(q,a)为1 时说明匹配的情况最理想,问题与答案最相关,当S(q,a)趋近于0 时,说明eerr(pw,ps)越大,问题与答案越不匹配。
3 实验结果与分析
3.1 实验数据集及评估指标
本文选取了3个公开的问答数据,包括Yahoo!Answer、TREC-QA[26]和Wiki-QA[27],3 个数据集的基本信息如表1 所示,其中带“*”的数据集剔除了全为负面答案的问题,“—”表示无此项内容。
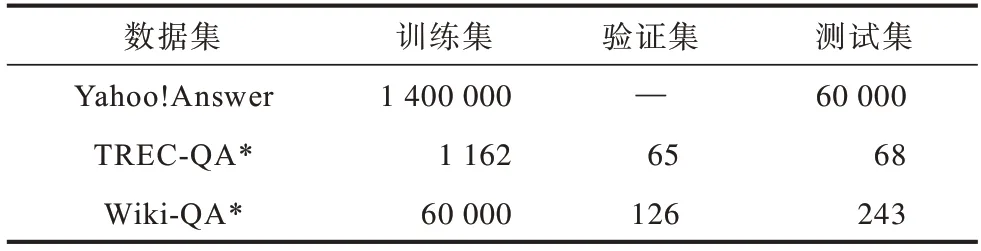
表1 数据集信息Table1 Dataset information
对于Yahoo!Answer 问答数据集来说,由于每一个问题有且只有一个最佳答案,因此为满足本次实验的需要,将每一个问题在其同领域下选取一个否定答案与原来的最佳答案构成一个正负答案对。
实验的评估指标采用平均准确率均值(mean Average Precision,mAP)和平均倒数排 名(Mean Reciprocal Rank,MRR),具体如下:
1)mAP,指所有问题的平均准确率均值。对于每一个问题的平均准确率,表达式如式(21)所示:
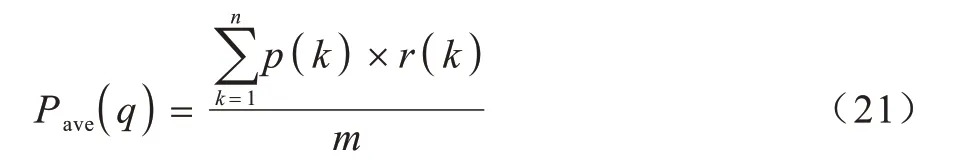
p(k)的表达式如式(22)所示:
其中:i=1,2,…,m;j=1,2,…,n;q代表单个问题;n代表单个问题下所有候选答案;m代表正确的答案个数;r(k)的取值为0 或1,当第k个候选答案是正确答案时,r(k)=1,否则r(k)=0。最终的mAP 表达式如式(23)所示:

当所有正确答案都在错误答案之前时,mAP 接近于1,当每个问题对应的所有正确答案都在错误答案之后时,mAP 接近于0。
2)MRR,指所有问答对在模型给出的位置排名列表中,第1 次出现相关答案位置倒数的平均值,表达式如式(24)所示:

3.2 实验环境
本文实验在Intel®CoreTMi5-9400@2.90 GHz 6 核CPU、24 GB 内存,6 GB 内存的Nividia GeForce GTX 1660 Ti GPU 上完成。预训练部分采用6B 版本的100 维GLoVe 词向量模型进行初始化词嵌入,Bert则直接使用在pytorch 框架下训练好的bert-largeuncased 模型。对于训练模型,采用自适应矩阵估计(adam)优化器更新参数,学习率设置为0.001,基于问答的词嵌入表示训练,Batch_size 设置为128,句子级匹配模块的训练采用Batch_size=64,当利用循环神经网络模型处理数据时,其隐藏层的大小均设置为128,其余参数为默认值。
3.3 不同词嵌入方法的对比
由于词级匹配是直接通过预训练好的词嵌入向量计算词对之间的相关程度,因此不同的词嵌入方法对词对相关性的计算存在一定的影响。图3 分别给出了在GLoVe 词嵌入方法、Bert 词嵌入方法与本文所提词嵌入方法Q-PNAP 在Yahoo!Answer 测试集上的预测精度。
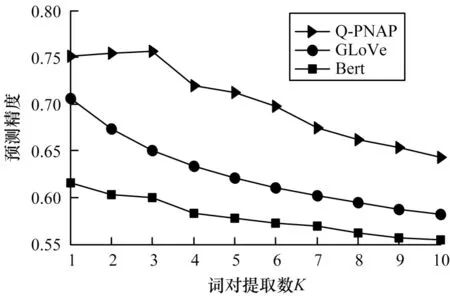
图3 不同词嵌入方法的预测精度对比Fig.3 Prediction accuracy comparison of different word embedding methods
由图3 可知,与其他方法相比,利用Q-PNAP 方法训练出的词嵌入表示预测精度最高,而利用Bert方法训练出的词嵌入表示预测精度最低。此外,随着筛选阈值K的增大,Q-PNAP 方法在K=3 时精度预测达到顶峰,表示一个问句中的单词平均可以与答案中3 个单词产生关联。而另外两种嵌入方法,其预测精度均随着K值的增大一直下降,这表明利用GLoVe 或者Bert 方法进行词嵌入表示时,问题中各单词平均仅与答案中的一个单词产生关联,说明以往仅利用单语境进行词嵌入的方式无法将问题与答案的承接关系保留,导致无法捕捉到这种联系的细节信息。
表2 所示为GLoVe 词嵌入方法与Q-PNAP 词嵌入方法训练出的词嵌入表示在3 个单词上的案例展示,对比可以发现,GLoVe 词嵌入方法得到的相似性单词是与之对应的近义词,而利用Q-PNAP 词嵌入方法得到的相似性单词,是具有问题承接关系的词汇。

表2 两种词嵌入方法获取近义词的结果对比Table 2 Results comparison of two word embedding methods to obtain synonyms
为对比不同词嵌入方法对句子级语义挖掘的影响,使用在当前答案选择任务中注意力机制使用效果较好的多跳注意力网络模型,验证不同词嵌入方法在Yahoo!Answer 测试集上识别正确答案的效果,结果如图4 所示。从图4 可以看出,GLoVe 方法的预测精度比Q-PNAP 方法的预测精度更高。
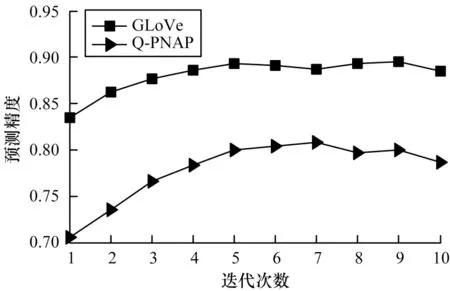
图4 不同词嵌入方法对句子级语义挖掘的影响Fig.4 Impact of different word embedding methods on sentence-level semantic mining
3.4 实验结果对比
由于词对的筛选个数对最后的焦点融合会产生一定的影响,为寻找最优的词对筛选个数,本文依次选取1~10 的整数作为抽取词对的个数K,验证模型性能与K值的关系。同时,为验证词级匹配在不同词嵌入形式下对整个模型效果的影响,在上文的验证结果下,选取GLoVe-GLoVe 和Q-PNAP-GLoVe 两种词嵌入组合方法,具体如下:
1)GLoVe-GLoVe 词嵌入组合方法。该组合方法中词级匹配利用GLoVe 词嵌入形式,句子级匹配也利用GLoVe 词嵌入形式。
2)Q-PNAP-GLoVe 词嵌入组合方法。该组合方法中词级匹配利用Q-PNAP 词嵌入形式,句子级匹配利用GLoVe 词嵌入形式。
实验结果如图5 和图6 所示。

图5 不同词嵌入组合方法在TREC-QA 数据集下的测试结果Fig.5 Test results of different word embedding combining methods under TREC-QA dataset
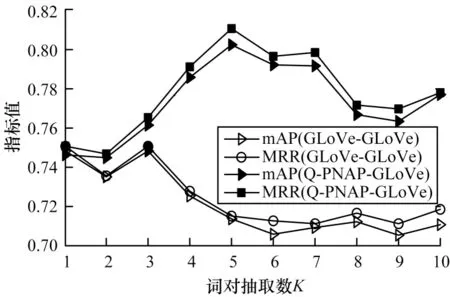
图6 不同词嵌入组合方法在Wiki-QA 数据集下的测试结果Fig.6 Test results of different word embedding combining methods under Wiki-QA dataset
从图5 与图6 可以看到,Q-PNAP-GLoVe 组合方法在总体效果上优于GLoVe-GLoVe 组合方法。GLoVe-GLoVe 组合方法的整体趋势随着选取词对个数K的增大,模型性能降低。而Q-PNAP-GLoVe组合方法在2 个数据集上的验证结果均呈现单峰趋势,这说明Q-PNAP-GLoVe 组合方法可以捕捉到一个问答对中更多关联词,从而使模型性能更优。问答语句间具有关联效应的词对个数也有上限,在抽取词对个数K=5 时,模型效果最好。
表3 与表4 分别为本文模型在TREC-QA 与Wiki-QA 两个答案选择公开数据集上与其他模型的对比结果。可以看到,本文模型在2 个数据集上的mAP 值均有明显提高。在TREC-QA 数据集上,本文模型对比多跳注意力网络模型[16]和层级排序模型[20],其mAP 值分别提高了0.086 1 与0.057 1,在Wiki-QA 数据集中,其提升幅度也分别达到了0.080 1与0.060 1。这说明对同一问题的所有答案进行排序时,融合了词级与句子级匹配焦点的模型可以增强问答语句间的信息抽取能力,捕捉到问题与答案之间更多的关联信息,能够区分答案之间具有的细微差别,而现有的注意力机制模型和融合了多层级句子语义的比较聚合模型无法做到。本文模型在MRR 指标上与多跳注意力[16]和层级排序[20]两种基线模型相比也有所提高,在Wiki-QA 数据集上的提升效果比TREC-QA 数据上的提升效果更明显,在TREC-QA 数据集上分别提升了0.017 6 与0.006 6,说明从两个层次对问答语句进行匹配可以增强模型对问答整体语义的理解能力。以上结果验证了本文模型在最佳答案选择上的有效性和可行性。
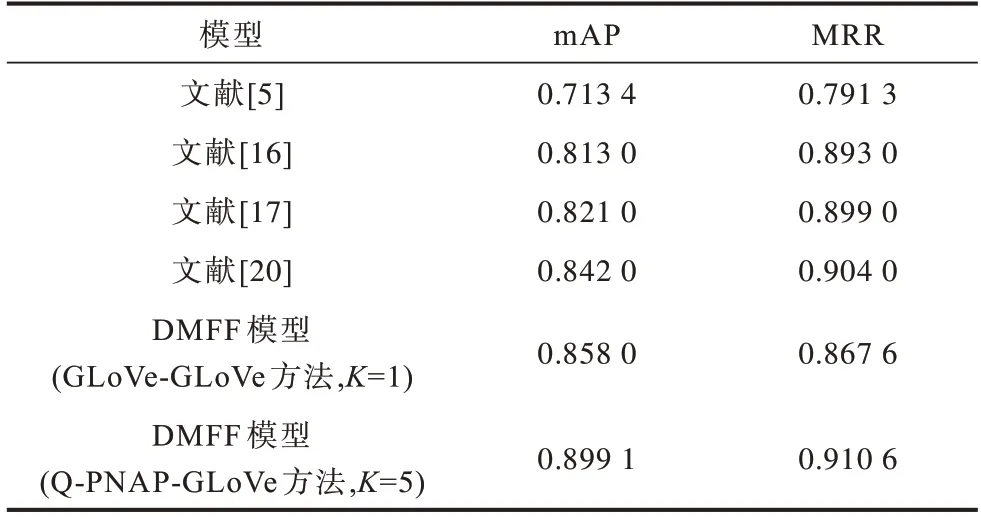
表3 不同模型在TREC-QA 数据集下的实验结果对比Table 3 Comparison of experimental results of different models under TREC-QA dataset

表4 不同模型在Wiki-QA 数据集下的实验结果对比Table 4 Comparison of experimental results of different models under Wiki-QA dataset
4 结束语
本文提出一种融合词级与句子级双层次匹配焦点的答案选择模型。结合问答任务的特点设计一种利用问题与正负答案对训练词向量的方式,以提高词级层面的匹配精度。利用带有注意力机制的翻译模型捕捉句子级的问答词对匹配,并将2 个匹配结果对齐计算相对距离,得到问答语句的相关性得分。实验结果表明,双层面匹配结果的对照融合提高了模型识别答案之间微小差别的能力,增强了模型对问答语句间关系的捕捉能力。与多跳注意力、层级排序等模型相比,本文模型在TREC-QA与Wiki-QA 公开问答数据集上的mAP 指标均具有较高幅度的提升,MRR 指标也有小幅提升。下一步将使用答案列表替换答案对,并将Bert 模型融合到句子级的匹配,以提高问答语句整体语义的捕捉抽取能力。
