基于图结构特征采样数据摘要的联邦知识图谱查询
2023-01-27高峰李秋顾进广
高峰,李秋,顾进广
(1.武汉科技大学计算机科学与技术学院,武汉 430065;2.湖北省智能信息处理与实时工业系统重点实验室,武汉 430065;3.武汉科技大学大数据科学与工程研究院,武汉 430065;4.国家新闻出版署富媒体数字出版内容组织与知识服务重点实验室,北京 100083)
0 概述
随着链接数据的发展,语义Web 上的RDF 数据集呈现大规模爆炸式增长,其包含的语义信息越来越丰富。对于这些大型语料库应用程序,亟须研发一种能够提取数据源概括信息的方法,以使系统做出更快速准确的反馈。近几年,研究人员提出了多种总结语义图[1-3]并评估其质量[4-6]的方法,同时在数据集配置文件[7-8]中提取各种特征。然而,一些集中式和分散式的查询引擎依赖细粒度的数据集描述文件来寻找高效的查询计划[9-11]。RDF数据集总结可标准化地表示RDF数据集的一组特征并且有助于处理下游任务[12-14]。CostFed[3]利用联邦系统中数据集中谓词的统计数据,通过这些统计数据来选择三元组模式的相关数据源并对子查询排序。CostFed方法中的数据摘要捕获了资源的权威性信息,能够区分相同URI下的不同数据集,并通过公共前缀,最大程度地捕获了与谓词相关的实体信息,同时考虑主语和宾语在谓词之间的倾斜分布,以不同的方式记录重要性不同的信息。因此,CostFed 非常适合用于执行有效的基数估计及其他下游任务。虽然数据摘要对应用程序非常有益,但它们的计算可能是一项具有挑战性的任务。首先,获取整个数据集来计算这些信息可能过于困难或代价太大。其次,在联邦查询中,数据转储并不总是可用的[15],而且数据集只能通过SPARQL 端点或TPF 服务器进行部分访问[16]。最后,大部分RDF 数据集中实际上只有很少的一部分(不到2%)的三元组用来回答查询[17],因此访问和处理来自所有联邦成员的全部数据对数据集生成通用索引是非必要的。
本文提出一种基于样图来生成近似数据摘要的方法,其仅依赖于原始数据集的一个样本,与CSPF[11]的技术思路类似,但更关注从样图中提取原始图的数据摘要。通过指定一个RDF 图,采样实体并计算谓词相关统计信息来构建样本的数据摘要。使用映射函数推断在样本中观察到的特征来近似原始图的数据摘要。为在近似的数据摘要上尽可能地还原谓词p的主语和谓语分布信息,需要将p的主语和谓语尽可能完整地捕获到样图上。
1 相关工作
数据源索引高度总结原始图的信息并应用于多种下游任务,而网络采样方法中随机节点、随机边选择等算法能得到原始图的部分样图。本文采用基于出度加权的图采样算法,为数据摘要生成定制样图。
1.1 数据源索引
ELLEFI 等[18]为数据集源索引文件中表示的数据集特性提供了一种分类方法,其中包括一般类别、定性类别、来源类别、链接类别、许可类别、统计类别和动态类别。为实现高效的RDF 数据结构、索引和压缩,FERNANDEZ 等[19]结合了RDF 图的特殊性,提出各种度量方法来表征RDF 数据集。AUER 等[20]提出一种基于语句流的方法LODStats,其包括32 个模式级统计标准。KHATCHADOURIAN 等[21]结合文本标签和二分收缩生成RDF 数据集摘要的工具ExpLOD。这些摘要包括类、谓语和互链接等统计信息。在本文方法中数据摘要不仅捕获了上述谓词、许可等统计信息,而且考虑了谓词的主语和宾语的不均匀分布。
1.2 图采样算法
DEBATISTA 等[22]提出基于样本的大型且变化数据集的近似特定质量指标。该文作者指出:某些质量指标的精确计算过于耗时,而质量的近似值通常已足够。因此,其应用蓄水池采样,并使用采样的三元组来估计URI 和与外部数据提供者的链接的可参考性。为获得包含与典型SPARQL 查询相同数量原始答案的样本:RIETVELD 等[17]重写RDF 图以计算节点的网络度量PageRank、入度和出度,并选择所有三元组中的前k个作为图的样本;SOULET 等[23]主要关注分析查询,这些查询通常成本较高,无法直接在SPARQL 端点上执行,因此通过在数据集的随机样本上执行这些查询来降低查询复杂度。这两种方法都需要本地访问整个数据集以生成样本,本文方法与其类似,在一些具有大型且变化数据集的分布式场景中无法对每个数据集进行本地访问,但本文的目标是对数据进行采样,以便使用单个样本来估计数据摘要的统计计数,而不依赖于重复采样所引起的收敛性。
1.3 网络采样算法
LESKOVEC 等[24]概述了适用于从大型网络中获取代表性样本的方法:通过选择随机节点,选择随机边或通过探索。为了评估样本的代表性,使用静态图模式,即结构网络特性的分布。原始图和样本之间的图模式一致性由Kolmogorov-Smirnov D-statistics 指标确定。在该文的实验结果中没有得到最佳方法,其性能取决于具体的应用。RIBEIRO 等[25]专注于有向图,并提出一种有向无偏随机游走算法(DURW)。将有向图建模为无向图,这样在执行随机游走时,边也可以向后遍历。将随机跳跃合并到节点,其概率取决于节点的向外度以及边的权重。与这些方法相比,本文方法旨在生成具有代表性的样本,以近似RDF 数据集的数据摘要,因此,采样方法需要针对此任务和RDF 图的特殊性进行定制。
2 问题及其定义
2.1 数据摘要相关定义
数据摘要在考虑了资源的偏差分布后的具体做法是:1)对一个谓词所连接的所有主语和宾语的频率降序排序;2)在降序的频率序列中迭代地找出3 个切割点,每个切割点都是当前序列中落差最大之处(第1 个切割点定义为0);3)在3 个切割点的划分下,资源被分为高、中、低频3 个桶,分别表示为b0、b1、b2,3 个桶的资源总数上限为100。
在数据摘要中,通过以下统计信息来表示一个谓词p0或者数据源的描述能力(capability),具体示例如图1 所示:

图1 数据摘要的描述能力示例Fig.1 Example of descriptive ability of data summary
1)唯一性描述信息
2)通用性描述信息
数据摘要中同样包含样图级别的统计信息:总主语数,总宾语数,总三元组数,用于未绑定谓词时的查询规划。但这并非本文研究的重点,在下文中将忽略相关的处理。
定义1一个数据源G的数据摘要D对不同谓词的描述能力的集合,即D(G)={ccapability}(p)|p∈S。联邦查询系统Λ的数据摘要D(Λ)是对系统中多个数据源的描述,D(Λ)={D(G)|G∈Λ}。
定义2通用性描述信息集合表示为L。
2.2 问题定义
由于访问整个数据集以生成其数据摘要可能太困难或是成本太高,例如,当数据集只能通过SPARQL 端点或TPF 服务器部分访问时,分布式查询可能就属于这种情况,因此为了解决这个问题,本文提出数据摘要近似概念,其目的是利用原始数据集的有限数据来生成近似的原始数据摘要。目标是生成一个近似的数据摘要,尽可能类似于原始数据摘要,但同时只需要访问部分数据。在该工作中,依赖于原始RDF 图的样本,并使用映射函数来估计真实的计数。
定义3给定一个RDF 图G,映射函数φ,一个子图S⊂G,以及S的数据摘要D(S),那么G的近似数据摘要D′(G)为:D′(G)=φD(S)。在理想情况下,近似数据摘要与真实数据摘要中的各个计数对应相同。然而,此类近似方法与原始特征的相似性受到待估计的计数类型、子图S和映射函数φ的影响。因此,本文基于子图S和映射函数φ生成近似的数据摘要,最大化了各项计数上与原始RDF 图的数据摘要的相似性。
3 近似数据摘要的生成模型
图2 给出了近似数据摘要的生成流程,首先基于CSPF 将采样应用于索引生成[11],从原始图G中抽取一个样图S⊂G。然后从S中生成所有谓词的描述信息集合,即数据摘要D(S)={ccapability(p)|p∈S},通过映射函数φ计算出近似的数据摘要D′(G)。最后汇总得到联邦系统中数据源索引文件。本节重点介绍RDF 图采样方法和由样图的数据摘要到原始图的近似数据摘要的映射方法。
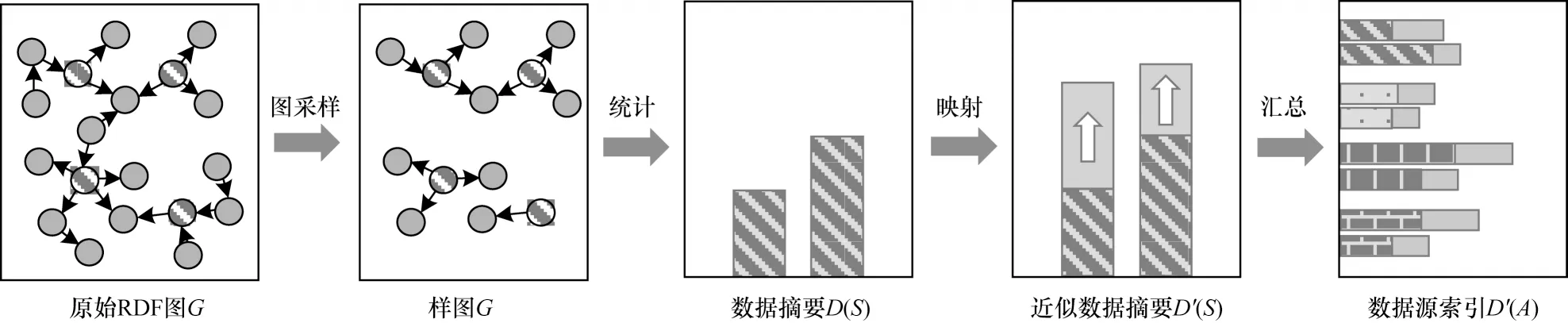
图2 近似数据摘要的生成流程Fig.2 Procedure of approximate data summary generation
3.1 RDF 图采样
<s,p,o>表示一个三元组,其中,s为主语,p为谓词,o为宾语,s、o统称为实体,由谓词将两者连接起来。在谓词很少的情况下,RDF 数据集中三元组的信息也可能很丰富,如LargeRDFBench[26]的其中一个数据集LinkedTCGA,唯一谓词数仅6 个,但三元组数有4 亿多个[22]。因此,本文方法首先是获得一个原始RDF 图的代表性样图,这为估计数据摘要提供了基础。为找到这个代表性样图,使用随机节点选择特定的节点(即RDF图的实体)进行采样。在选择一个实体之后,该实体相关的所有三元组都被并入样图。
数据摘要是对谓词相关主语和宾语的总结,也就是数据摘要对具有相同谓词的三元组能表现出更佳的总结能力。在出度或入度较高的实体的子图上,本文方法能获得更多的三元组。因此,笔者尝试基于出度和入度加权采样方法,但在本文的前期工作中,笔者观察到基于入度加权的方法表现很差,原因是选取到rdf:type 等公共谓词的宾语后,相关三元组会极大地增加样图的容量,并导致超时或内存溢出,而基于出度加权的方法可避免该问题。
由于找到一个相关样本是一个多目标优化问题,即选择一个足够小的样本,同时仍能实现足够高的召回率。为了找到相对有效的采样方法,本文将要采样的对象定义为给定图G中的实体集E={s|(s,p,o)∈G},并设定3 种以实体为中心的采样方法。这些采样方法是以G的一个样本量n为输入,其输出是一个由G的n个实体导出的子图S。假设E1⊂E为|E1|=n的采样实体集,那么样图S={(s,p,o)|(s,p,o)∈G∧s∈E1}。同时,设定不同的采样概率以在采样期间探索搜索空间的不同部分。
1)基本采样方法
在基本采样方法中,每个实体e被采样到的概率是一致的,如式(1)所示。实体是否被采样是独立的,与是否受用户偏向无关。

2)加权采样方法
加权采样方法是一种有偏采样方法,其中实体成为样本一部分的概率与其出度成正比。因此,实体在图中的中心度越高,就越有可能成为样本的一部分,即在主语位置出现多个三元组的实体被选中的概率更高。理论上,该方法只是提高出度高的实体被采样的概率,但不能保证它们中的每一个都能被采样到。给定deg+(e)=|{(e,p,o)|(e,p,o)∈G}|表示实体e的出度,那么e被采样的概率计算如式(2)所示:
3)混合采样方法
在一个平衡参数α的调和下,试图找到基本采样方法和加权采样方法的最佳组合。在原始图中,使用加权采样方法选择α·n个实体,使用基本采样方法选择(1-α)·n实体。在这种情况下,实体e被选择的概率计算如式(3)所示:

3.2 映射函数
映射函数的目标是从样图数据摘要生成原始图的数据摘要。由于采样过程选中一个实体时,会选取它所有相关的三元组,因此样图数据摘要的唯一性描述信息具有不可映射的特点。本文仅对通用性描述信息进行映射,对定义2 中所有计数C进行同等程度的放大。
1)基本映射函数
对于直接通过样图生成的数据摘要D1中的所有计数C,按照原始图与样图的三元组比例映射为原始图的近似数据摘要D′中的相应计数,如式(4)所示:

2)改进映射函数
考虑到原始图G中实体的不均匀分布,引入一个更细粒度的比值d来减少基数的高估。当C取值为<ds:distinctSubjs>或<ds:subjPrefixes>中的计数时,d取该描述能力中唯一主语数(<ds:distinctSubjs>)与三元组数(<ds:triples>)的比值。类似地,当C取值为<ds:distinctObjs>或<ds:objPrefixes>中的计数时,d取该描述能力中唯一宾语数(<ds:distinctObjs>)与三元组数(<ds:triples>)的比值。C取值为其他时保持基本映射函数不变,如式(5)所示:

此外,为充分考虑映射函数对查询基数估计的影响,设计一个对照组,即将样图S的所有计数直接用于下游任务,如式(6)所示:

4 实验与评估
本节介绍实验使用的测试集和环境设置,以及设计3 个实验分别研究在不同采样方法下近似数据摘要生成过程所需时间和内存开销、基于不同采样方法和映射函数生成的近似数据摘要的相似性、基于不同采样方法和映射函数生成的近似数据摘要作为索引文件对联邦系统的查询正确率和时间的影响。将CostFed 作为本文方法对比的基线,并实现了基于采样生成的近似数据摘要的联邦查询系统。
4.1 实验设置
在实验中使用联邦查询基准测试集LargeRDFBench[26]来验证本文方法的有效性。LargeRDFBench 内置了25 个查询,其中,14 个(CD1~CD7、LS1~LS7)用于SPARQL 端点联合方法,其他11 个查询(LD1~LD11)用于链接数据联合方法。LargeRDFBench 的9 个数据集分别加载到9 个单独的Virtuoso 7.1 服务中,并部署在一台配备了3.2 GHz i7处理器、16 GB RAM和100 GB硬盘的服务器上。对于LargeRDFBench 内置的25 个查询,每个查询执行10 次,结果取平均值。在实验中对选取的数据集进行如下操作:1)生成对应的原始数据摘要;2)按3 种不同的样本量采样,由于数据摘要的统计信息需要更多的信息,且所用数据集的三元组个数足够多,因此设置采样的实体比例为0.1%、0.5%、1%;3)按照3 种映射函数生成近似的数据摘要;4)在3 个数据摘要相似性指标和2 个运行时指标上进行评估,取α=0.5。
4.2 近似数据摘要生成实验
表1 给出了基于映射函数φ2的近似数据摘要生成结果,其中,AST 表示平均采样时间,AGT 表示平均摘要生成时间,TT 表示总耗时,size 表示索引文件大小,W 表示加权采样方法,H 表示混合采样方法,B表示基本采样方法。由表1 可以看出,在1%采样量和基本采样配置下平均摘要生成时间最慢,约0.6 h,本文方法比基线方法(在本文实验配置下原始数据摘要平均生成时间为2 h)最低节省了70%的摘要生成时间。在1%采样量和加权采样配置下,生成的索引文件最大,为4.620 MB,即本文方法比基线方法(9.550 MB)最低减少52%的存储空间。联邦引擎检索索引文件的时间因系统配置而异,在配置较高的情况下,检索时间仍可以忽略不计,因此文件大小对系统性能的影响不是最重要的,而其统计的计数准确性更重要。

表1 近似数据摘要的生成时间和内存开销Table 1 Generation time and memory overhead of approximate data summarization
4.3 数据摘要相似性实验
4.3.1 评估指标
实验从各个指标上量化原始图直接生成的数据摘要D与通过样图近似得到的数据摘要D′的相似程度。
1)谓词覆盖率相似性
由于样本大小的限制,采样过程中可能会丢失部分谓词,因此计算在原始图直接生成的D与近似的D′在原始图G上的谓词覆盖率相似性,如式(7)所示,其中D在原始图上的谓词覆盖率为100%。

2)三元组覆盖率相似性
数据摘要通过相关主语和宾语的计数来描述谓词,因此采样图中包含一个谓词在原始图中主语或谓语的数量越多,数据摘要越能准确描述该谓词。三元组覆盖率相似性指标反映了近似的数据摘要中主语和宾语对原始图的涵盖情况,定义为D′涉及到的三元组个数与原始数据摘要D涉及到的三元组总数之比,如式(8)所示:
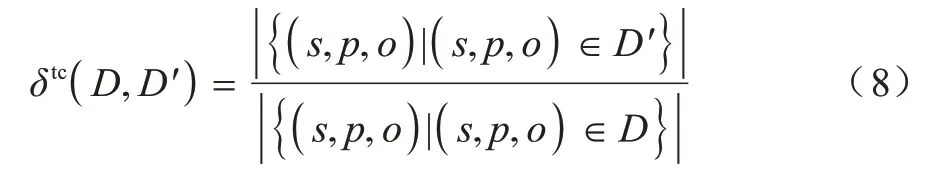
3)能力计数相似性
由于原始图中实体的分布,因此导致估计计数的准确性具有很大的挑战性。在一个谓词的描述能力中,有的计数可能会被准确估计,而有的则可能被严重低估或高估。q-error 是真计数和估计数之间比值的最大值[27]。q-error 越高,表示真实值与估计值之间的差异越大,q-error 误差为1,表示估计是正确的。为观测估计计数的准确性,给出q-error 的计算公式如式(9)所示:

其中:v和v2分别是D与D′描述能力中的同一种计数C的值。描述能力中包含多个计数,将这些计数的q-error聚合为描述能力的q-error,计算公式如式(10)所示:

q-error 仅测量估计误差的大小,但并不表明值是高估还是低估。因此,当聚合给定描述能力集合P上的计数相似性时,该属性将被高估的计数与被低估的计数相互抵消。描述能力的计数相似性定义如式(11)所示:
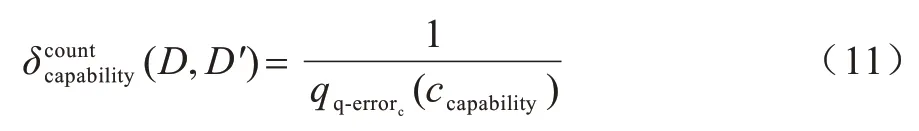
4.3.2 实验结果
表2 给出了不同采样量下3 种采样方法的谓词覆盖率相似性(-δpc)和三元组覆盖率相似性(-δtc)。比较不同的样本量,结果显示在所有情况下,随着样本量的增加,相似性指标有所提高。更重要的是,观察到改进程度取决于原始图的性质。在大部分图中,尽管三元组数在剧烈下降,不同样本量下近似的数据摘要都能做到谓词的高度或完全覆盖,但在SWDF 数据集中,实验所设的最大样本量也不能收集其60%的谓词,对于这类数据集,基于采样生成数据摘要的方法效果更不理想。
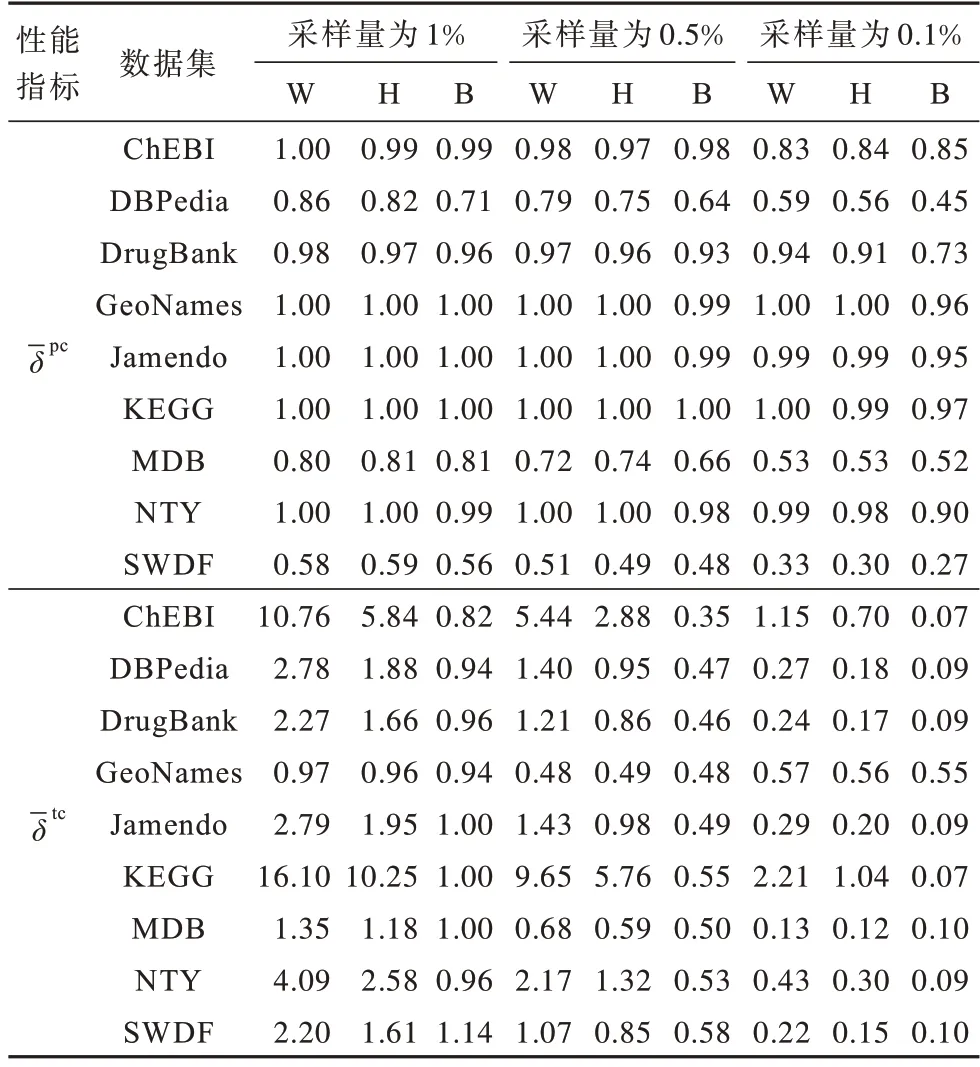
表2 谓词覆盖率相似性和三元组覆盖率相似性计算结果Table 2 Calculation results of predicate coverage similarity and triple coverage similarity
比较不同的采样方法,结果显示在多数情况下,混合采样方法次于加权采样方法且优于基本采样方法。在不同的采样量下,加权方法通常能获得更多的三元组,混合方法次之,基本采样方法获得的三元组最少且比例上与采样量接近。更重要的是,加权方法的优势在更小的样本量上更明显。
例如,在KEGG 数据集中,在0.1%样本量下,加权方法获取到的三元组数是基本方法的32 倍,而在1%样本量下这个比值为16。但是,加权方法在链接数量更少的图上效果越佳。例如,在大数量级的GeoNames数据集上,不同采样方法的效果相当,而在数量级更小的ChEBI 数据集和KEGG 数据集上,加权方法明显优于其他方法。
图3 给出了部分RDF 图、采样方法、样本量和映射函数的结果。在10 个样图上生成计数相似性的平均值Q-error,即给定10个样本的描述能力集合P,如式(12)所示。由于能力计数相似性直接与Q-error 相关,为更加直观,评估时使用Q-error 而不是。

图3 部分数据集上的Q-error 值分布Fig.3 Distribution of Q-error values on partial datasets

与表2 中的两个指标结果类似,Q-error 结果表明,样本量越大,估计值的误差越小。对于不同映射函数:首先观察到φ1和φ2相对于φ3提升了10~100倍;其次观察到φ2相对于φ1在中位数上平均减少了8.4% 的估计误差,具体而言,φ2除在Jamendo、Drugbank 数据集上表现差于φ1外(中位数分别平均增加了1.4%和1.3%),其他数据集上都表现更好;最后对于映射函数φ1和φ2,观察到增加样本量并不一定会减少Q-error。
通过比较不同的抽样方法,观察到加权方法的估计精度最低,而基本方法的估计误差最小。但是,观察KEGG 和ChEBI 发现这两个数据集的Q-error约为其他数据集的10 倍。考虑由样本量诱导的采样的三元组覆盖率相似性,发现KEGG 和ChEBI 加权方法捕获的三元组分别约为基本方法的13 倍和16 倍。对于数据分布差异较大的数据集,φ1和φ2都不能产生较好的结果。
由所有数据集的计算Q-error 的结果可知,样本量的增加导致Q-error 降低。在大多数情况下,基本采样方法产生的Q-error最低,而φ2显示了平均Q-error的最佳结果(较低中位数)。
综上所述,从采样方法到RDF 图的结构,各种因素都会影响近似数据摘要的质量。因此,在查询性能实验中,将研究近似数据摘要如何在特定应用程序中发挥作用以及如何影响应用程序的性能。
4.4 查询性能实验
4.4.1 评估指标
与原始数据摘要相同,任何一个资源都可能被生成的近似数据摘要收集(字面量和空值除外),但由于样本的不完整性以及摘要生成算法的分桶机制,一些重要的资源可能会在收集过程中遗漏,从而影响源选择和查询规划等下游任务。本文提出两个简单的指标来评估生成的近似数据摘要对联邦系统运行时的影响:1)相对执行时间δex=基于近似数据摘要的平均查询时间/基线平均查询时间,在相对执行时间为1 的情况下,生成的近似数据摘要和原始数据摘要表现一致,相对执行时间越高,则说明使用近似的数据摘要辅助的联邦系统的查询时间越快;2)结果正确率δrc=基于生成的近似数据摘要的查询结果数/实际查询结果数,当实际结果数为0 时,δrc取1(理论上,在2 种情况下的结果数都为0),当结果正确率为1 时,本文方法能查询到完整的结果。
4.4.2 实验结果
在10 种实验配置(3 种样本量、3 种采样方法和1 种基线方法)上对25 个基准查询语句(表示为集合Q)中的每一个查询执行10 次,取平均执行时间为一个查询语句的执行时间,并计算这些语句的平均相对执行时间δex及平均结果正确率δrc,如式(13)和式(14)所示:
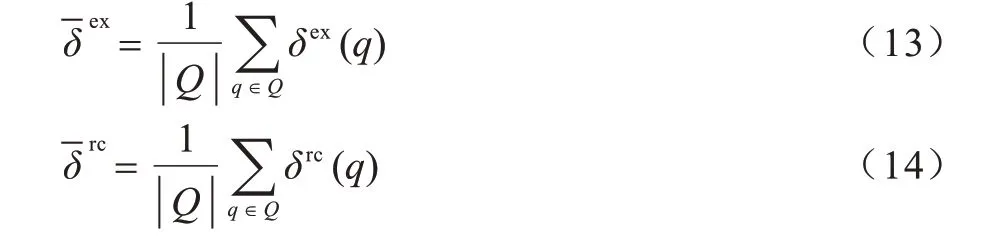
为获得准确查询时间,在实验中停用了系统中的ASK 缓存机制。由于映射函数φ1和φ2的估计计数精度相差不大,实验仅给出φ2和φ3的实验结果及相应分析。表3 给出了查询性能的相似性指标计算结果以及LargeRDFBench 所有内置查询的平均源选择个数。
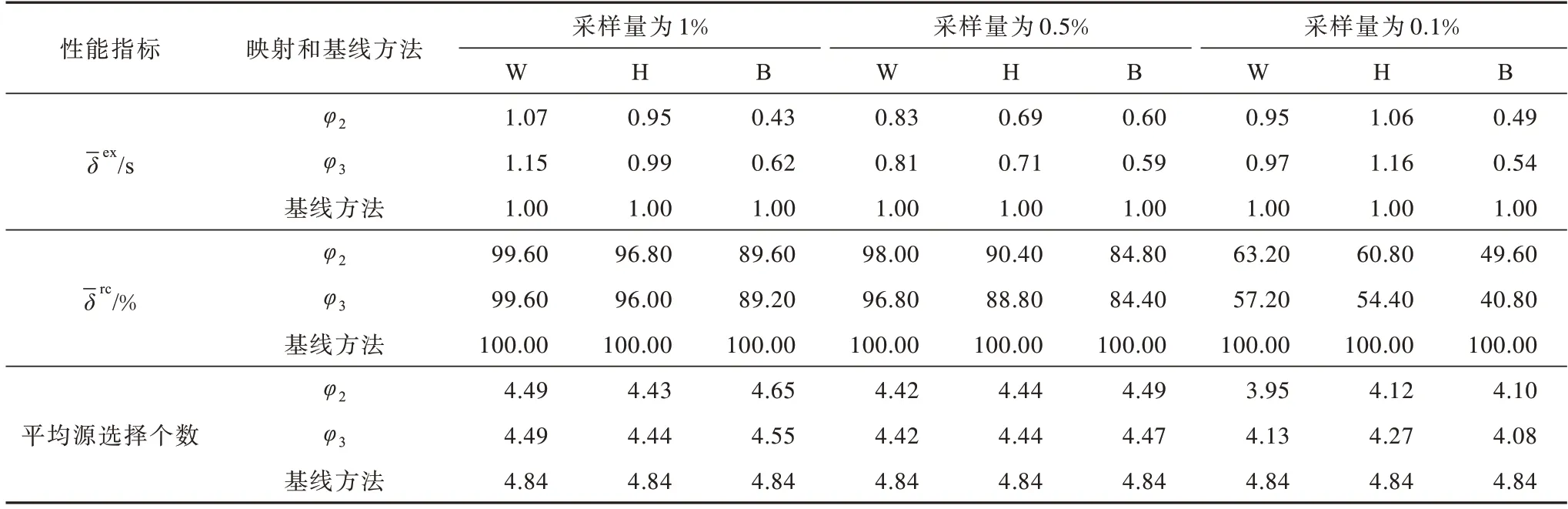
表3 查询性能实验的相似性指标计算结果Table 3 Calculation results of similarity index of query performance experiment
由表3 可以看出,对于使用通过映射样图的数据摘要而生成的近似数据摘要,联邦查询系统能更准确地得到多数查询结果。通过比较不同采样量发现,采样量较大的近似数据摘要得到了更多的正确查询结果,同时整体上消耗更多时间,并且随着采样量减少到0.1%,耗费时间也逐渐增加。通过对比φ2方法下选择的源个数发现当0.1%采样量配置时,平均源选择个数比基线方法约少0.8 个,而该值在1%采样量下约为0.3 个。通过比较不同的采样方法发现,加权方法效果最佳,在1%采样量和加权方法的配置下能到达99.60%的最高正确率。此外,0.5%采样量和加权方法的这种配置能得到98%的最高正确率,同时在执行时间上优于前一种配置和基线方法。通过对比不同的映射方法发现,φ2和φ3的结果正确率在1%采样量下相差不大,但随着样本量减小,这种差别逐渐变大。此外,不同映射函数对查询执行时间的影响可以忽略不计(平均变化在0.05 s内)。对于查询计划生成而言,数据摘要生成的计数提供了初始的谓词间的相对关系。通过加权采样方法获取的样图很大程度上反映了这种相对关系,因此在计算三元组模式的基数之后,映射前后相对关系不会变化,但随着样本量的减少,这种相对关系的真实性得不到保证,因此结果正确率有所降低。
综上所述,加权采样方法获得的样图能捕获原始图的更多信息,在1%采样量的配置下表现出最高的查询正确性,在0.5%采样量的配置下在损失部分正确性的同时花费了更少的查询时间。此外,本文提出的映射函数在样本量越小的情况下效果越明显。
5 结束语
知识图谱规模日益增大,从知识图谱中充分挖掘语义数据的概括信息有助于提供更快速更准确的联邦查询性能。本文利用谓词与实体的关系获取数据源关键信息并生成数据摘要索引文件,同时通过采样的方式捕获关键谓词,并以出度加权强化谓词的重要性,以此提高数据摘要的表达能力。实验结果表明,本文方法在1%采样量和加权方式的配置下能达到99.60%的查询正确率。后续将分析并研究谓词多重性等RDF 图结构特征来抽取概括信息,以更好地捕获样图的关键谓词,进一步扩展本文近似数据摘要生成方法的应用范围。
