基于改进K-means聚类k值选择算法的配网电压数据异常检测
2023-01-14刘明群覃日升
刘明群,何 鑫,覃日升,姜 訸,孟 贤
(云南电网有限责任公司电力科学研究院,云南 昆明 650217)
近年来,配电网电压监测系统建设加强了对配电网电压、电流等数据的管理与计算分析,实现了电网故障预警、电压准实时在线监测等功能[1]。然而,由于配电网规模和配电网监测数据日益增大,传统在线监测方法已无法满足监测系统对数据挖掘的快速性和准确性要求。因此,为保障配电网安全可靠运行,配电网电压监测系统数据异常检测方法研究具有重要意义。
聚类算法通过对配电网电压数据聚类,挖掘数据特征、区分数据类型、实现实时故障预警。聚类算法可分为划分聚类法、层次聚类法和密度聚类法等,其中划分聚类法计算效率较高,但需事先假定聚类数值[2],包括K-means、K-medoids和CLARA算法。特别地,K-means算法原理简单且效率高,非常适合配电网电压数据在线监测;K-means算法仅在多项式时间内收敛到局部最优解[3],但合理地选择初值将有利于收敛到全局最优解。文献[4]采用K-means++算法选取K-means算法初值,但运用K-means算法要事先假定聚类数。聚类数可根据样本情况判断[5],然而,在相关经验不足或数据量过大等情况下无法给出最佳聚类数。对于静态数据库而言,聚类数不会改变,但当在线监测系统数据库是动态时,聚类数会随着配电网故障等问题的产生而动态变化,导致K-means算法的聚类效果变差[6],因而需要其他算法辅助选择聚类数。
为解决聚类数选择问题,目前已有学者提出多种聚类数选择算法。文献[7]提出轮廓系数法,算法原理简单且只需给定聚类数上限,对最佳聚类数估计效果很好,但计算速度较慢,不适合在线监测配电网电压;文献[8]运用DBI算法为K-means算法选取聚类数,DBI算法对最佳聚类数估计效果较好,但计算速度稍慢;文献[9]运用Canopy算法快速自适应选取聚类数,但该算法需根据交叉验证法或先验知识设定松阈值和紧阈值,且紧阈值严重影响聚类数的选取,因此算法自适应能力不够强;文献[10-11]运用elbow method选取聚类数,该方法因简单直观且计算速度快而被广泛应用,但常常因“肘部点”不明显而无法估计最佳聚类数。上述常用算法存在自适应能力不强、计算速度慢和准确率不够高等问题,不适合异常数据在线检测。
针对上述常用算法问题,本文提出一种快速选取聚类数的自适应算法。所提算法基于elbow method和轮廓系数法,首先利用自适应变化阈值求解聚类数下限,接着在聚类数上、下限内计算轮廓系数。为提高算法速度,提出“一个极大值”规则,避免计算所有轮廓系数。该算法充分考虑elbow method的快速性和轮廓系数法的高准确率特点,为K-means算法自动选取聚类数,使K-means算法在线监测成为可能。最后,为评价所提算法,以2个实际配网电压数据为例,通过仿真对比其他聚类数选择算法。结果表明,相比于所对比算法,所提算法能以最高准确率和最快计算速度自适应选取最佳聚类数。
1 K-means聚类算法
K-means是一种基于划分的无监督聚类算法,能将数据集分成k类,其中k是事先假定的。K-means算法随机产生k个聚类中心,根据最近邻原则将数据点归类离其最近的聚类中心,形成k个类,并重新计算各类的聚类中心,重复上述步骤直到聚类中心不再改变位置或达到规定的迭代次数。
K-means算法聚类的目标是使各类误差平方和(sum of the squared errors, SSE)最小,即
(1)
式中Ci为第i个聚类;p为Ci中的样本点;mi为Ci的聚类中心,即Ci中所有样本的均值;eSSE为所有样本的聚类误差,代表聚类效果的好坏。
根据拉格朗日定理和最小二乘法原理,确保SSE最小的聚类中心[3]应满足:
(2)
由式(2)可得:
(3)
其中,ni为第i聚类的样本总量。因此,聚类中心是该聚类数据的平均值。K-means算法每一次迭代将聚类中心取为该聚类样本的平均值,确保SSE在本次迭代内达到最小,交替采用最近邻原则和以均值计算聚类中心,使SSE不断下降,直到平衡收敛。
2 基于elbow method和轮廓系数的聚类数自适应确定
结合elbow method和轮廓系数,提出改进的elbow method和轮廓系数算法(improved elbow method and silhouette coefficient,IES),用于自适应确定聚类数,从而与K-means算法结合为自适应K-means算法。对于假定的聚类数上限kmax,首先,IES算法基于elbow method的聚类评价指标SSE值确定聚类数下限kmin;然后,在聚类数搜索范围[kmin,kmax]内基于轮廓系数搜寻最佳聚类数k*,并利用提出的“一个极大值”规则避免计算[kmin,kmax]内所有聚类数对应的轮廓系数。当最佳聚类数确定后,可用K-means算法进行聚类。
2.1 改进elbow method
IES算法的核心是在一定的定义域内利用轮廓系数寻找最佳聚类数。使轮廓系数最大的聚类数为最佳聚类数k*。轮廓系数法一般在定义域[2,kmax]内计算每一个聚类数k对应的轮廓系数,但轮廓系数计算速度慢,不满足配电网在线监测的快速性要求。因此,IES算法利用计算速度更快的SSE确定聚类数下限kmin,将定义域范围缩小为[kmin,kmax]。
聚类数为k时elbow method的误差平方和记为eSSE(k)。k=i时的相对SSE定义为
(4)
式中eSSE(1)为k=1时eSSE(k)的值,也是其最大值。
由于eSSE(k)、相对SSE单调递减且离散不可导,无法用极值点和拐点估计最佳聚类数,因此考虑设置阈值来估计聚类数下限。同时,由于不同数据集的手肘曲线不同,因而所设置阈值应随之自适应变化。
定义取值范围为(0,1)的常数Kelbow,称为手肘系数。随着k的增大,相对SSE从eSSE(1)%开始下降,当k=kmax时,相对SSE最大下降量为eSSE(1)%-eSSE(kmax)%,而当相对SSE下降量达到最大下降量的Kelbow倍时,对应的相对SSE定义为手肘阈值eSSE,elbow%,可计算如下:
eSSE,elbow%=eSSE(1)%-Kelbow(eSSE(1)%-
eSSE(kmax)%)=100%-Kelbow·
(100%-eSSE(kmax)%)
(5)
根据大量仿真经验,取Kelbow=0.5,则
(6)
利用式(6),将聚类数下限kmin取为使eSSE(k)%≤eSSE,elbow%成立的最小k值。
在聚类数上限为kmax以及Kelbow=0.5时,kmax对应人为限定的相对SSE最大下降量,所选的kmin使相对SSE下降量达到最大下降量的一半以上。应指出,IES算法解出的kmin≥2。
手肘阈值具有自适应性,因为当k>k*后eSSE(k)%变化缓慢,即使kmax较大,eSSE(kmax)%仍接近于eSSE(k*)%,而不同数据集的eSSE(k*)%不同,因此,由eSSE(kmax)%计算的手肘阈值也随之自适应变化。对不同数据集,当kmax等于样本总数时,均有eSSE(kmax)=eSSE(kmax)%=0[3],由式(6)可知,手肘阈值达到其最小值eSSE,elbow%=50%,手肘阈值恒为常数且不随数据集不同而变化,因此kmax可取值较大,但不应过大。
不同Kelbow取值影响IES算法计算时间和准确率(能否解出k*)。若降低Kelbow,手肘阈值将增大,使得解出的kmin变小,有利于IES算法解出k*(若kmin>k*,则IES算法无法解出k*),但kmin变小又会使得轮廓系数法的定义域[kmin,kmax]范围变大,不利于缩短轮廓系数法计算时间。同样分析Kelbow增大的情况,可知Kelbow不应过大或过小。由此也能看出,手肘阈值随数据集不同而自适应增大或减小,是在自适应兼顾IES算法对不同数据集的准确率和计算速度。实际应用中可根据配网电压历史数据进行测试,适当调整Kelbow取值。改进elbow method确定聚类数下限流程如图1所示。

图1 改进elbow method确定聚类数下限流程Figure 1 The flowchart of determinizing the lower limit of clustering number with the improved elbow method
具体步骤如下:
1)读取人为设定的kmax和数据集;2)对k=1、kmax分别进行K-means聚类,对聚类结果应用式(1)计算SSE,即eSSE(1)、eSSE(kmax);3)结合式(4)、(6)计算eSSE,elbow%,令k=2;4)对当前k值进行K-means聚类并计算eSSE(k);5)采用式(4)计算eSSE(k)%;6)判断eSSE(k)%≤eSSE,elbow%是否成立,不成立则令k自增1并返回步骤4),成立则跳出循环进入步骤7);7)记录此时的k为kmin,该流程结束。
2.2 “一个极大值”规则
聚类数为k时相应的轮廓系数记为S(k)。基于轮廓系数搜寻最佳聚类数,在[kmin,kmax]区间内利用轮廓系数算法搜寻最佳聚类数。然而,为确保大于最佳聚类数k*,聚类数上限kmax的设置可能会过大,而轮廓系数计算速度慢,对[kmin,kmax]区间内每一个聚类数k计算轮廓系数将消耗大量时间。
为提高算法速度,IES算法借鉴gap statistic算法中“一个标准错误”(1-standard-error)的规则[12](文献[13]也在其他算法中使用该规则),提出“一个极大值”规则,即令聚类数k在[kmin,kmax]区间内每次增加1,依次计算轮廓系数S(k),当S(k)首次出现极大值时停止计算S(k)。使用该规则得到多个轮廓系数,选其中最大值对应的k为最佳聚类数k*。当S(k)在定义域[kmin,kmax]内不存在极大值时,“一个极大值”规则失效,需计算定义域内所有S(k),选最大值对应的k为k*。本文中“一个极大值”规则在k=K生效是指:对于K>kmin,当k增大到K+1时,出现S(k)的极大值S(K),IES算法停止计算S(k)。S(K)为极大值是指:S(K)>S(K-1)且S(K)>S(K+1)。
“一个极大值”规则避免计算所有轮廓系数,相当于降低了实际假定的kmax,从而提高算法速度。
2.3 基于轮廓系数自适应确定聚类数
聚类数下限确定后应用“一个极大值”规则,在定义域[kmin,kmax]内利用轮廓系数法求解最佳聚类数。在已计算不同聚类数对应的轮廓系数中自动寻找最大轮廓系数,所对应聚类数为最佳聚类数k*,从而实现自适应确定聚类数。基于轮廓系数自适应确定聚类数流程如图2所示。
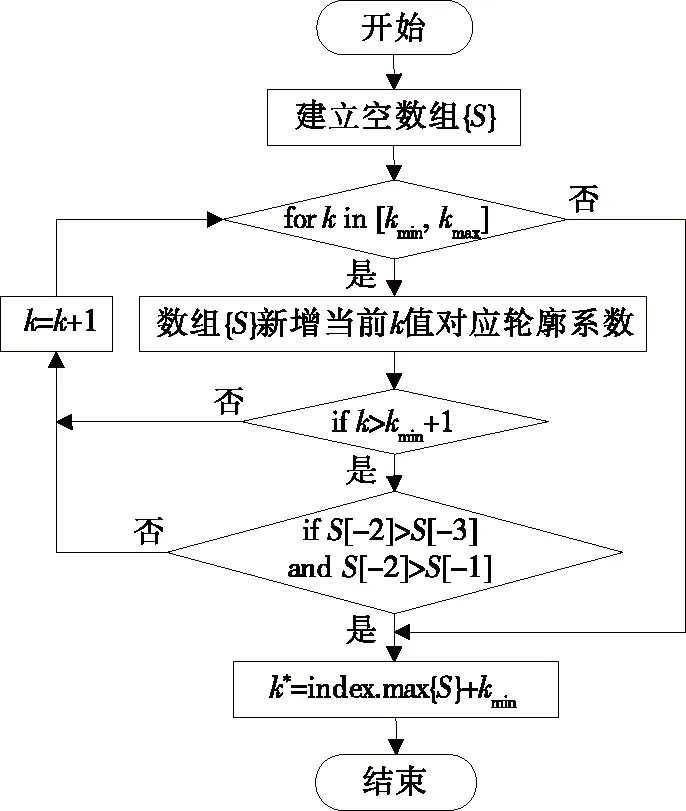
图2 基于轮廓系数自适应确定聚类数流程Figure 2 The flowchart of determinizing the clustering number with the improved elbow method based on the silhouette coefficient adaptive determination
具体步骤如下:
1)建立空数组{S},令k=kmin;2)对当前k值进行K-means聚类,接着对聚类结果计算轮廓系数并放入数组{S};3)若数组{S}中的元素已达3个及以上,则说明可以判断是否出现极大值,进入步骤4),否则令k自增1并回到步骤2);4)判断是否出现极大值,即S[-2]>S[-3]、S[-2]>S[-1]是否同时成立,其中S[-1]是数组{S}倒数第1个元素,即本次循环计算得到的轮廓系数;S[-2]、S[-3]分别是倒数第2、3个元素,若不出现极大值,令k自增1并回到步骤2),若出现极大值则跳出循环进入步骤5);5)在数组{S}中寻找最大轮廓系数,并记录对应的聚类数为最佳聚类数k*,IES算法结束。
2.4 基于自适应K-means的实时异常检测模型
IES算法从图1流程开始至图2流程结束。自适应确定聚类数的IES算法与K-means算法结合为自适应K-means算法。正常运行时配电网电压数据波动范围较稳定,因此,可利用K-means算法对正常运行数据聚类并得到聚类中心,通过判断新输入数据到聚类中心距离是否超过距离阈值H,从而判断数据是否异常。
H=(h1,h2,…,hk)表示各聚类的阈值,其中k是聚类数,聚类中数据到聚类中心距离的最大值乘以常数D作为H,综合考虑文献[14]、[15]的实验结果,取D=1.04。若某数据X到k个聚类中心Ci距离均超过相应阈值,则判定为异常数据,即异常数据满足:
|X-Ci|>hi,i=1,2,…,k
(7)
IES算法能在异常检测中更新正常数据最佳聚类数,并能在发生异常时帮助挖掘异常数据特征。随着历史正常运行数据的不断增多,正常数据的最佳聚类数可能改变,因此,每隔一段时间需用IES算法自适应求解并更新最佳聚类数。当发生异常时,在分析数据异常模式之前,为充分利用当前所有异常数据,可通过IES算法对当前所有正常和异常数据的最佳聚类数自适应快速求解,然后利用K-means算法将异常与正常数据一起聚类,为挖掘异常数据特征和探测异常来源提供信息。除上述基于自适应K-means聚类的方法,文献[14]还利用了其他方法分析数据异常模式。
基于自适应K-means的实时异常检测总流程如图3所示,具体步骤如下:
1)对配电网电压历史正常运行数据进行K-means聚类,并根据聚类得到的最优聚类中心和聚类结果更新距离阈值H;2)计算新输入数据到各个聚类中心的距离并与距离阈值比较;3)若新输入数据属于异常数据则标记为异常,否则将其加入历史正常运行数据;当历史正常运行数据新增数量达到一定量时,利用IES算法求解并更新最佳聚类数;4)将异常数据与历史正常运行数据共同作为新的数据集DS;5)IES算法根据事先假定聚类数上限计算数据集DS的最佳聚类数k*;6)用K-means将数据集DS分为k*个聚类;7)利用K-means聚类结果分析数据异常模式。
3 算例分析
3.1 数据集
以2个实际配电网电压数据集为例(记为D1和D2),与DBI算法和轮廓系数法进行仿真比较,验证所提IES算法的有效性。
D1有1 000个样本点,每个点对应一个时刻三相电压有效值。为体现所提IES算法的普适性,对A、B、C三相电压分别加入异常数据进行实验。对于A相电压,随机抽取10%,即100个正常数据,并加上4%~10%噪声,生成1个数据集,重复进行50次,生成50个数据集,记为A组数据(注意:每个数据集只含10%异常数据,其中50个正常数据加上正噪声4%~10%,50个正常数据加上负噪声-10%~-4%)。用同样方法对B、C相电压各生成50个数据集,分别记为B、C组数据。
D2有4 000个样本点,每个点对应一个时刻三相电压有效值。为说明选取不同聚类数对聚类效果的影响,对A、B、C三相电压均加入异常数据进行实验。对于A相,随机抽取15%,即600个正常数据,在±5%处加高斯分布随机函数G作为噪声。设正常数据值为Ndata,则加噪声后的值为Ndata·(1±0.05)+G。用同样方法处理B、C相电压,最终得到的数据集记为D2noise。
3.2 评价指标
各算法对最佳聚类数估计的准确率定义为
(8)
式中N为实验次数,对A、B、C三相电压的每一组数据实验50次,故N=50;NT为对最佳聚类数估计正确的次数。
对于A、B、C三相电压的3组数据,最佳聚类数为3,即分为1个正常数据聚类和2个异常数据聚类。用DBI算法、轮廓系数法和IES算法估计所有数据集的最佳聚类数k*,若k*=3则估计正确,若k*≠3则估计错误。
由于出现异常时需用自适应K-means算法对正常和异常数据聚类,聚类效果影响下一步分析数据异常模式,因此,需说明K-means对正常和异常数据聚类时不同最佳聚类数估计值对聚类效果的影响。为方便说明,简化为分析二分类异常检测效果,再给出异常检测效果评价指标。对于二分类异常检测,可根据真实和检测情况将检测结果分为4类,如表1所示,TN为实际正常且被检测为正常的样本,FP为实际正常但被检测为异常的样本,FN为实际异常但被检测为正常的样本,TP为实际异常且被检测为异常的样本。
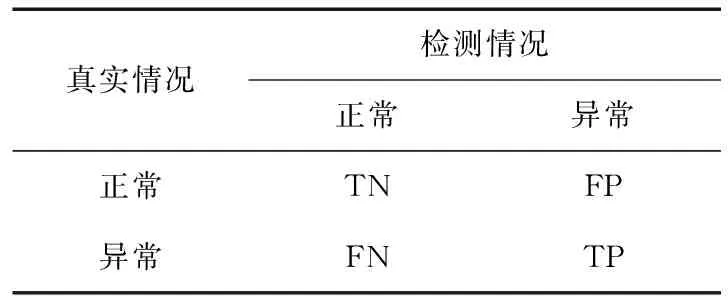
表1 检测结果分类Table 1 Classification of test results
对于异常检测,相比于不将正常样本判定为异常,更重要的是检测到更多的异常点[16]。因此,采用召回率评估异常检测效果,其值越高意味着检测到越多真实异常点,其最大值为1。召回率:
(9)
3.3 实验结果与分析
计算环境如下:计算机CPU为Core i7-10700,内存16 GB,主频2.90 GHz,操作系统为Windows 10(64 bit),数据分析工具为Python 3、Jupyter NoteBook。
对A、B、C三相电压的3组数据分别用3种算法进行最佳聚类数估计,为满足在线监测的自适应性,应取足够大的聚类数上限kmax,以保证其大于最佳聚类数,因此取kmax=20,实验结果如表2~4所示。

表2 对A组数据应用3种算法Table 2 Three algorithms are applied to group A data

表3 对B组数据应用3种算法Table 3 Three algorithms are applied to group B data
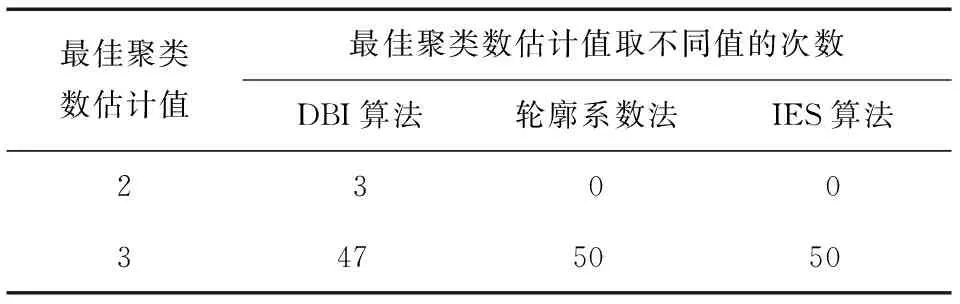
表4 对C组数据应用3种算法Table 4 Three algorithms are applied to group C data
由表2可以看出,轮廓系数法和IES算法对最佳聚类数的估计值稳定为3;DBI算法的估计值仅在2、3之间波动,其中,对于A组9个数据集,DBI算法解出k*=2,其余41个数据集解出k*=3。对表3、4不再赘述。根据表2~4,计算3种算法对A、B、C三相电压的3组数据最佳聚类数估计的准确率ω,如表5所示。
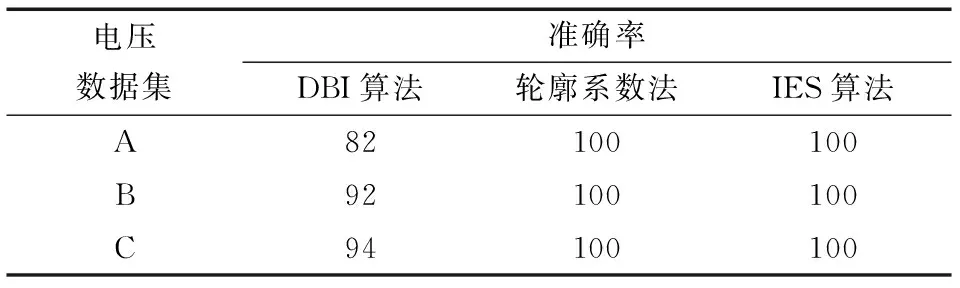
表5 3种算法准确率Table 5 Accuracy of three algorithms accuracy %
由于3种算法对k*的估计值只有2和3,因此分别取k*=2、3,对A、B、C三相电压的3组数据进行K-means聚类,其中,k*=3时将聚类后的2个异常数据聚类合并,从而得到正常和异常数据二分类(注意:实际中不将异常数据聚类合并,因为会损失异常数据特征信息,此处仅是为了计算召回率)。计算不同k*取值下各组数据召回率均值,如表6所示。

表6 不同k*取值下各组数据召回率均值Table 6 Mean recall rates of data in each group under different k* values
由表6可见,选取合适的聚类数能大幅提升异常检测效果。对于A、B、C三相电压的3组数据取k*=2显然不合适,而在表2~4中,DBI算法对k*的估计值多次为2,结合表5可知轮廓系数法对最佳聚类数估计的准确率比DBI算法更高,而IES算法保持了轮廓系数法的高准确率。
为进一步说明轮廓系数法和IES算法在准确率方面比DBI算法更适合为K-means选择最佳聚类数,对A组数据中某一数据集进行K-means聚类,取k*=3,聚类结果如图4所示,可明显区分3类数据,但对于该数据集,DBI算法解出k*=2,而轮廓系数法和IES算法解出k*=3。
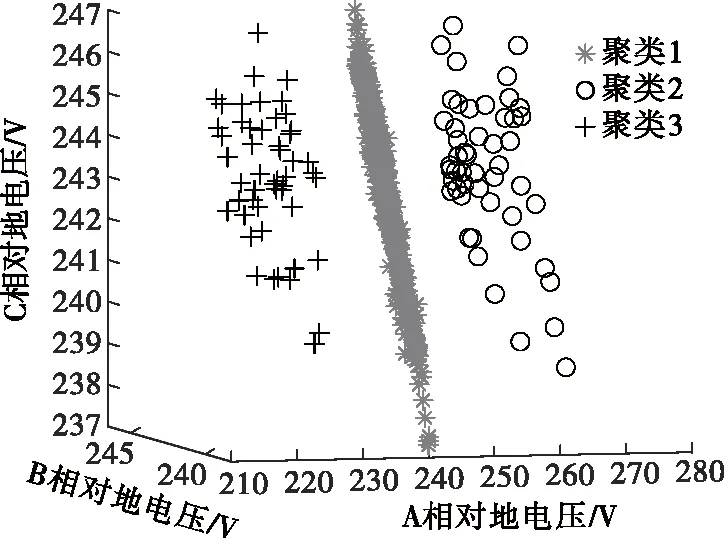
图4 k*=3时K-means算法聚类结果Figure 4 Clustering results of K-means algorithm when k* =3
图4中聚类2、3为异常数据类,聚类1为正常数据类,此时召回率的值为1,表明K-means算法适合对该数据集聚类,而轮廓系数法和IES算法比DBI算法更适合为K-means选择最佳聚类数。
为说明选取不同聚类数对聚类效果的影响,分别取聚类数为2~9,对数据集D2noise进行K-means聚类;为方便计算各聚类结果的召回率,人为将异常数据聚类合并,从而得到正常和异常数据二分类。数据集D2noise召回率随聚类数变化曲线如图5所示,可见召回率随着聚类数增大而增大,说明聚类效果越来越好,当聚类数为7、8、9时达到最大值1。应指出,3种聚类数选择算法对于D2noise的最佳聚类数估计值均为7。
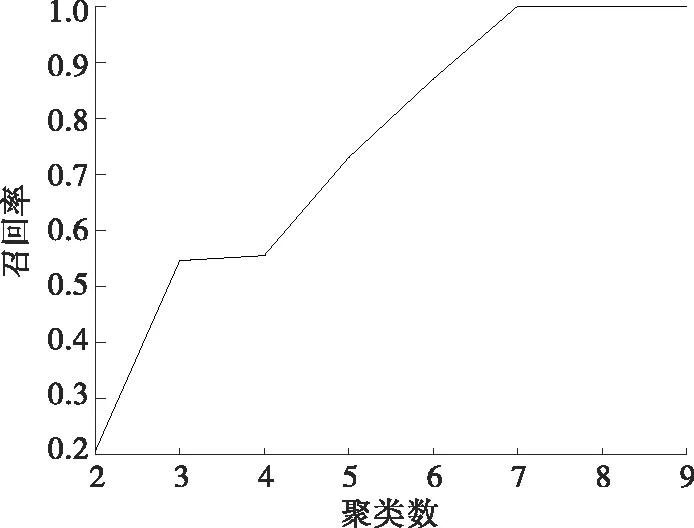
图5 数据集D2noise召回率随聚类数变化曲线Figure 5 The curve of recall rate of D2noise changing with clustering number
进一步分析发现,聚类数大于7时会发生模型过拟合。聚类数分别为7、8时数据集D2noise的K-means聚类结果如图6、7所示。对比图6、7可知,图6为最佳聚类,而图7中将正常数据过拟合为2个聚类(聚类4、7),不利于对数据进行分析。
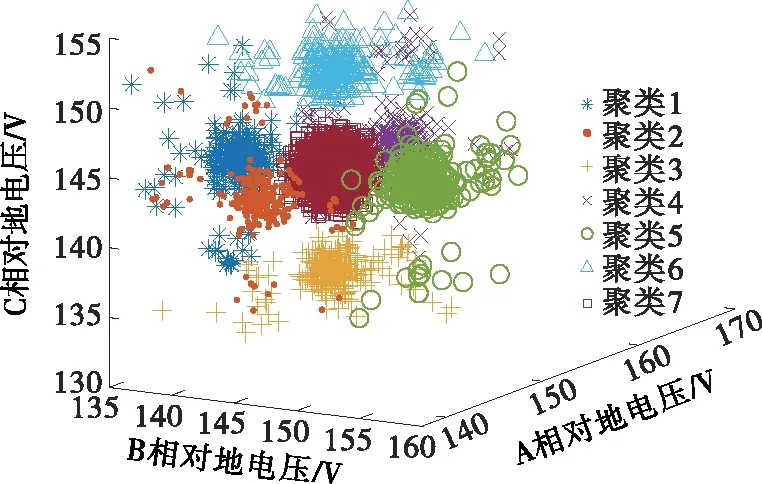
图6 聚类数为7时数据集D2noise的K-means聚类结果Figure 6 K-means clustering results of D2noise when the clustering number is 7
用3种算法对A组50个数据集估计最佳聚类数,记录平均运行时间和最小、最大运行时间,如表7所示,可见轮廓系数法的最小运行时间大于DBI算法最大运行时间,从运行时间均值也能看出DBI算法运行速度更快。IES算法的运行时间均值小于其他2个算法,计算速度最快,最符合在线监测的快速性。IES算法运行时间波动范围大于其他2个算法,是因为对于50个数据集,IES算法均解出kmin=3,但“一个极大值”规则在不同的聚类数k值(k>3)处生效,因此,不同数据集的计算量不同,导致运行时间波动。

表7 3种算法运行时间对比Table 7 Running time comparison of three algorithms
综上所述,尽管DBI算法计算速度稍快于轮廓系数法,但DBI算法准确率是3种算法中最低的。与DBI算法相比,IES算法不仅计算速度更快,而且准确率更高;与轮廓系数法相比,IES算法不仅保持相同的准确率,而且计算速度更快。因此,IES算法兼顾准确率和计算速度,在保证高准确率的前提下缩短了计算时间,提高了K-means算法在线监测的准确率和高效性。
4 结语
K-means聚类算法计算速度快、准确率高,适合配电网在线监测,但当假定聚类数不合适时,可能导致聚类结果不理想。本文提出了一种快速选取聚类数的自适应IES算法,为K-means算法自动选取聚类数,使K-means算法在线监测配电网成为可能。以召回率评价二分类异常检测效果为例,说明为K-means选取合适聚类数对异常检测的重要性。IES算法首先利用自适应变化阈值求解聚类数下限,接着在聚类数上、下限内计算轮廓系数。为提高算法速度,提出“一个极大值”规则,避免计算所有轮廓系数。所提IES算法有如下优点。
1)自适应能力强。IES算法只需给定聚类数上限这一参数,且该上限允许较大,即使动态数据库的最佳聚类数发生一定的改变,也能保证大于最佳聚类数。所提出用于确定聚类数下限的阈值可随数据集不同而自适应变化,从而自适应兼顾IES算法准确率和计算速度。
2)计算速度快。IES算法利用计算迅速的SSE求解聚类数下限,缩小了最佳聚类数的搜寻范围,又利用所提出的“一个极大值”规则减少计算量,提高了计算速度。
3)准确率高。IES算法充分利用了轮廓系数高准确率的特点。
算例表明,所提IES算法能自适应快速选取最佳聚类数,与轮廓系数法相比,IES算法准确率相同而计算速度更快,与DBI算法相比,IES算法不仅准确率更高,而且计算速度更快。因此,IES算法兼顾准确率和计算速度,更有利于应用于配电网在线监测。
