具有能量收集的雾网络的建模与性能分析
2023-01-13于露露唐胜达
于露露,文 鹏,唐胜达
(1.广西师范大学数学与统计学院,广西 桂林 541006;2.桂林学院理工学院,广西 桂林 541006)
0 引言
雾网络(Fog Networking,Fogging)或雾计算(Fog Computing)是由思科(Cisco)在2011年首次提出的[1].雾网络或雾计算能够将计算需求分层次、分区域处理,以解决可能出现的网络拥塞等现象.相比要把所有数据集中运输到同一个中心的云计算,雾计算的模式是设置多个中心节点,即运用所谓的“雾节点”来处理数据,雾计算可以将一些并不需要放到云上的数据,直接在网络边缘层进行处理和存储,提高数据分析处理的效率,降低时延,减少网络传输压力,提升安全性.雾网络在人们生活的许多方面都具有重要作用,例如医疗保健、交通、农业、工业自动化和安全等方面.然而,雾网络节点处理数据,需要消耗大量的能源,为了延长节点的寿命,可以考虑能量收集.能量收集(Energy Harvesting,EH)指的是收集环境中易获得的能量(如太阳能、风能、机械振动、温度变化、磁场等)并将其转化为电能的过程.能量收集使能量来源更丰富,减少对自然界的碳排放,促进生态可持续发展,同时能量收集能够降低成本和提高系统寿命.能量收集在许多方面具有广泛的应用,比如通信方面[2-3]、工业方面[4-5].
近年来,许多学者对网络性能进行了研究.TANDO等[6]研究了能量收集通信系统,通过一个两阶段的虚拟排队系统,对能量到达过程和等待服务过程进行解耦,得出该虚拟排队系统中平均数据包延迟,以及由于缓冲区中数据的溢出而导致数据包丢失的概率的封闭表达式.PATIL等[7]研究了能量采集无线传感器网络中传感器节点的最优传输策略,将该系统建模为具有两个耦合队列的离散时间排队模型,能量获取过程为伯努利过程,采用策略迭代算法,获得最优的传输策略.JIANG等[8]研究了雾网络中塑造和监管数据流量的模型,通过漏桶模型利用Markov控制的流体源,反映了数据流量的突发性特性,推导出数据流量的四个性能指标.寇名扬等[9]研究了能量采集无线传感器网络,采用两状态 Markov调制的on-off流体模型,描述数据和能量到达的突发,利用虚拟队列刻画数据缓存的占用情况和能量状态之间的相关性,对虚拟队列进行排队分析,通过谱分析得到丢包率和平均延迟的表达.但是TANDO[6]和PATIL[7]研究的能量到达过程都是离散的,而能量一般是以电子流的形式收集,离散过程无法刻画能量收集的实际情况.JIANG等[8]只对数据进行了分析,没有考虑能量可收集的情况,但是对于数据的处理,需要大量的能量消耗,传统的电池已不能满足大数据时代数据处理所需求的能量;而且JIANG运用的方法都是谱分析,当特征值趋于0时,数值解会有很大波动,不利于数值的分析.寇名扬等[9]仅考虑了两状态Markov过程控制的流体模型,其求解方式无法推广到多状态求解.
本文主要讨论具有能量收集的雾网络节点,在雾节点中推广了上述对能量和数据的分析,同时考虑能量收集和数据到达为多种状态的情况,基于流体队列理论(Stochastic Fluid Queues,SFQ)运用矩阵分析方法得出雾网络节点中数据和能量的联合分布,以及缓冲区的溢出和闲置概率.
1 系统建模
本文使用下面的符号体系,[A]ij表示矩阵A的第(i,j)项元素,Aij表示矩阵A的分块矩阵.特别地,0、I和1分别表示适当维数的零矩阵(向量)、单位矩阵和单位列向量.
1.1 模型描述
如图1所示,本文描述具有能量收集的雾网络的工作原理:设备由能量缓冲区和数据缓冲区构成,其处理数据的能力受到能量采集速率的影响,数据经过处理后被传输到接收端,此处传输消耗的能量可以忽略不计.为了提高设备处理数据的能力,将能量收集设备收集的能量尽可能地用于数据处理.具体来讲,当数据缓存区中有数据时,收集到的能量将全部用于数据处理;当数据缓冲区中没有数据时,处理数据剩余的能量将被保存在能量缓冲区中,由于数据到达和能量收集的随机性,在缓冲区的大小都有限的情况下,不可避免地会发生数据丢失或即将收集的能量被丢弃.
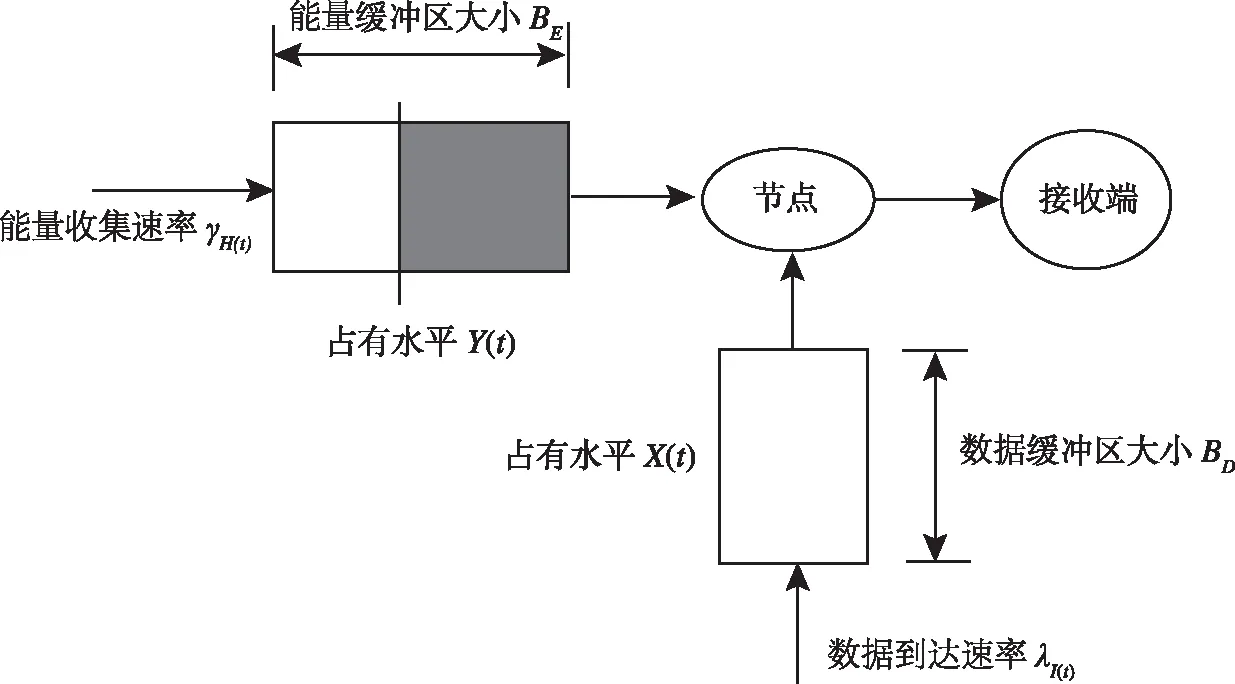
图1 雾节点工作原理简化图
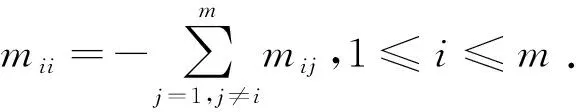
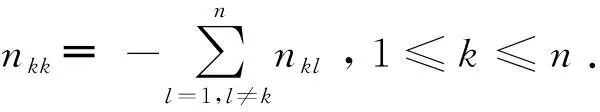
用随机变量X(t)和Y(t)分别表示在t时刻数据缓冲区中的数据水平和能量缓冲区中的能量水平.假设数据缓冲区和能量缓冲区的大小分别为BD和BE,则0≤X(t)≤BD和0≤Y(t)≤BE,且满足:
(i)当数据缓冲区为空(X(t)=0)时,能量缓冲区才有能量缓存(Y(t)>0),否则到达的数据将立即被储存在能量缓冲区中的能量处理.因此有X(t)=0,Y(t)>0.
(ii)类似地,当能量缓冲区为空(Y(t)=0)时,到达的数据才能被缓存到数据缓冲区(X(t)>0) 中,否则收集的能量将立即被用来处理数据.即Y(t)=0,X(t)>0.
根据(i)(ii)显然有X(t)Y(t)=0.
数据缓冲区中数据水平的变化过程:
(1)
能量缓冲区中能量水平的变化过程:
(2)
由式(1)和式(2)可知,数据缓冲区内缓存的数据与能量缓冲区内的能量相关,不易直接求出X(t)和Y(t)的个体统计量,但是可以先找到联合概率,然后再得出各自的统计量.按照ELWALID[10]的方法,通过将X(t)和Y(t)的两个缓冲区组合在一起,即二者的联合“虚拟队列”,定义V(t)表示虚拟队列中的水平容量,S表示状态空间,则有
V(t)=X(t)-Y(t)+BE,
(i)0≤V(t)≤B,B=BD+BE;
(ii)当0≤V(t)≤BE时,有X(t)=0,V(t)=BE-Y(t);
(iii)当BE≤V(t)≤B时,有Y(t)=0,V(t)=BE+X(t).
因此,可定义虚拟缓冲区的净流入速率为
经过上述分析,随后基于SFQ得出虚拟缓冲区中流体的变化情况,通过得到的V(t)密度函数,可以分析出数据缓冲区中数据水平和能量缓冲区中能量水平的变化.
1.2 模型转化
基于上述的分析,将模型转化为SFQ,分析云存储系统中数据和能量的分布特点.
将本文模型建模为随机过程{V(t),I(t),H(t)},定义随机过程J(t)={I(t),H(t)},根据实际情况,I(t)和H(t)是相互独立的CTMC,因而随机过程J(t)={I(t),H(t)}也是一个CTMC,将J(t)作为SFQ的背景过程,其状态空间S=SD×SE={1,2,…,mn},其生成元矩阵为T=M⊕N,其中,⊕是Kronecker和.随机过程V(t)表示虚拟缓冲区的水平变化过程,则得到SFM{V(t),J(t)}.
令dJ(t)=λI(t)-rH(t),不失一般性,假设λI(t)≠rH(t),即dJ(t)≠0.则SFM{V(t),J(t)}的净输入率矩阵D=Λ⊕-R.由于dJ(t)的不同,状态空间S可以分为两个不相交的子集:
S=S+∪S-,
(3)
其中,S+={j∈S|dj>0},S-={j∈S|dj<0}.
根据(3),矩阵T和D可以分别写成分块形式:
其中,D+=diag{dj>0,j∈S+},D-=diag{dj<0,j∈S-}.
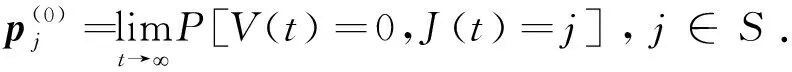
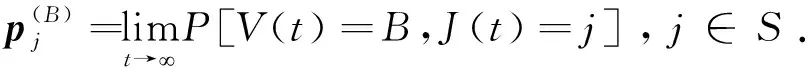
随后,本文提出SFQ{V(t),J(t)}的平稳分布,进而得出一些相关分析.
1.3平稳分布
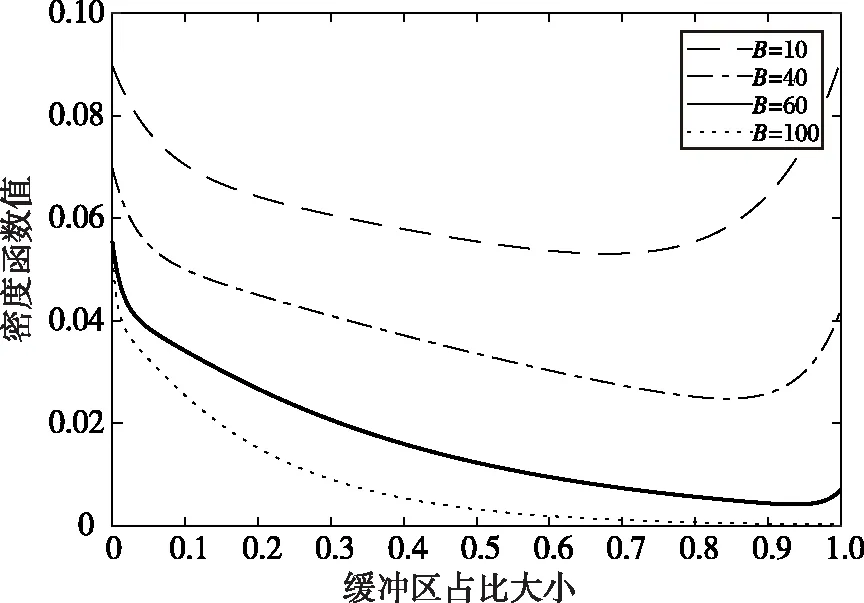
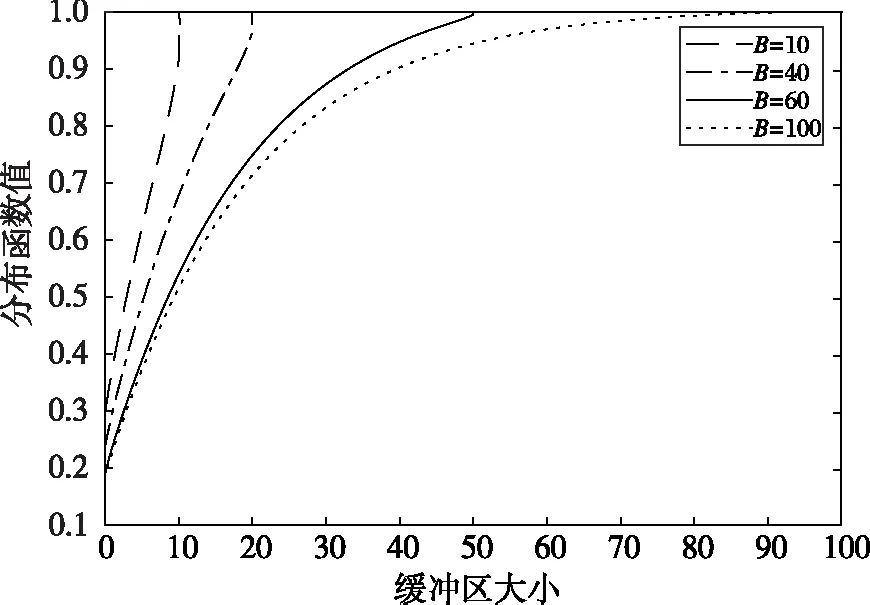
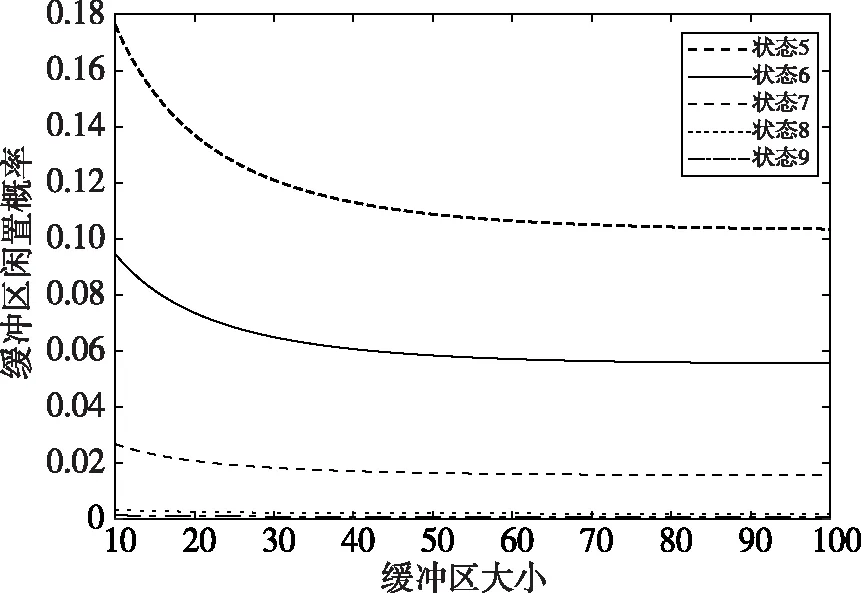
在SFQ模型中,当0 μ=ξ+D+1-ξ-D-1. (4) 其中,ξ+D+1表示长期情况下虚拟系统中流体流入的速率,ξ-D-1表示长期情况下虚拟系统中的流体流出的速率.μ的物理意义代表了长期的缓冲区中净流入率.因此,当μ<0时,V(t)有向下的趋势,即能量缓冲区为满;当μ>0时,V(t)有向上的趋势,即数据缓冲区为满的趋势,这种情况下,可能导致大量的数据溢出(丢失),所以假设μ<0,在SFM中存在平稳密度[11]. 下面对缓冲区的边界进行分析: (i)对于任意j∈S+,即数据到达速率大于能量收集速率,则数据缓冲区趋于满(X(t)→BD),能量缓冲区容量趋于空(Y(t)→0),因此, V(t)=X(t)-Y(t)+BE→BD+BE=B. (5) 对于这些状态集,虚拟队列为空的概率一定是0,则有 Πj(0)=P[V(t)≤0,J(t)=j]=0,j∈S+. (ii)对于任意j∈S-,即能量收集速率大于数据到达速率,则能量缓冲区趋于满(Y(t)→BE),数据缓冲区中趋于空(X(t)→0),故有 V(t)=X(t)-Y(t)+BE→0. (6) 对于这些状态集,虚拟队列为满的概率一定是0,则有 Πj(B)=P[V(t)=B,J(t)=j]=0,j∈S-. 经过上述分析,可以得出SFQ{V(t),J(t)}的平稳分布和边界概率,进而得出能量缓冲区能量水平和数据缓冲区中数据水平. 定义1 首达时(FPT): θ=inf{t>0:V(t)=0},ι=inf{t>0:V(t)=B}, 其中,θ表示首次到达水平0的时刻;ι表示首次到达水平B的时刻. 根据上述首达时定义,类似地定义下面首达概率矩阵[12]: 对于i∈S+,j∈S+,k∈S-,有 [Ψ]ik=P[θ<∞,J(θ)=k|V(0)=0,J(0)=i], 同理,对于i∈S-,k∈S-,j∈S+,有 并且,有矩阵Ψ满足下面的Riccati方程: ΨQ-+Ψ+Q++Ψ+ΨQ--+Q+-=0, (7) 根据文献[13-14]关于求解Ψ的算法可以求得Ψ. (8) (9) (10) (11) 证明过程类似于文献[11]. (12) 证明过程类似于文献[11]. 定理3 对于本文提出的SFQ{V(t),J(t)},其边界概率和平稳密度函数为 证明 为了确定α,则有下面事实成立: 下面运用数值计算数据和能量的联合分布,根据研究结果来说明缓冲区大小对于雾网络节点性能指标的影响. 根据本文的理论推导得出相应的数值结果,如图2至图5所示. 图2 缓冲区的平稳密度函数 图3 缓冲区的平稳分布函数 图4 缓冲区大小与溢出概率的变化趋势 图5 缓冲区大小与闲置概率的变化趋势 图2和图3显示了在联合缓冲区B的大小分别为10、40、60、100时对应的平稳密度函数以及分布函数.图2的横坐标是以联合缓冲区的大小为单位缩小绘制的,可以看出,当B=10时,处于两端的水平概率密度占比较大,这是由于漂移μ=-0.172 9<0,漂移影响着缓冲区容量水平变化的整体趋势.由于μ<0,流体水平整体趋势是递减的,这导致更易触碰到边界水平0,有流体的反馈,水平会上升,但此时缓冲区较小,也易接触上边界,所以处于两端的水平概率密度占比较大.随B的增大,触碰上边界B的可能性越来越小,因此处于上边界的概率密度逐渐减少,其平稳密度在区间(0,B)上的分布几近于一致,当缓冲区的大小增加时,处于水平0和水平B的概率质量减小.这是由于如果B是无限的,那么队列将接近于瞬态的;在B有限的情况下,平稳分布倾向于均匀地分布在整个状态空间上. 图4和图5分别显示了在不同状态下缓冲区大小分别与溢出概率和闲置概率的变化趋势图.根据式(5)可知,有4个状态下可能发生溢出,即联合缓冲区为满,也意味着数据缓冲区为满,即会发生数据溢出(数据丢失),如图4显示缓冲区大小对于数据丢失概率的影响.从图像可以看出,随缓冲区增大,其溢出概率越来越小,这意味着其数据丢失的概率越来越小,这是因为随缓冲区容量的增大,缓冲区内流体的含量几乎达不到上界B,达不到上界B也就不会发生数据丢失. 根据式(6)可知,有5个状态下可能发生闲置,即联合缓冲为闲置,意味着能量缓冲区为满,即数据缓冲区为空的概率(数据到达直接被能量缓冲区内缓冲的能量所服务),虚拟缓冲区为空,也意味着数据缓冲区为空,如图5展示了在不同状态下数据缓冲区闲置的概率,随着缓冲区容量的增大,缓冲区闲置的概率越来越小,最终闲置概率都会趋于一个常数.这是因为在缓冲区中流体量整体趋势下降的情况下,随着缓冲区容量的增大,缓冲区中流体的量几乎达不到上界B就已返回边界水平0,上界对流体水平变化的影响越来越小. 本文对雾网络节点的能量和数据同时进行分析,并将能量收集过程和数据到达过程建模为随机过程,状态空间是多个状态的随机过程,根据矩阵分析方法计算出缓冲区水平变化的平稳分布以及雾网络节点中数据缓冲区的溢出概率和闲置概率,分析雾网络节点中缓冲区大小对于数据的影响.在未来的工作中,可将本文提出的模型运用于更多通信模型,并应用在生产实践中;同时还可以强化系统的稳定性,如加入可支持电网,提供附加的数据处理能力,考虑数据服务的重要性等.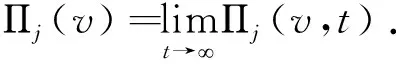
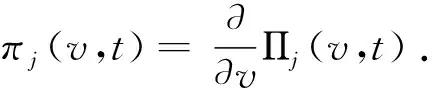
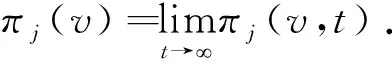
2 系统分析
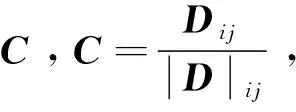
2.1 背景知识
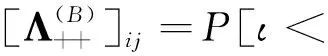
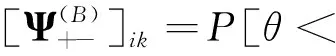
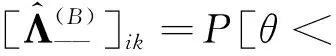
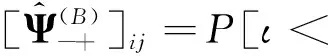
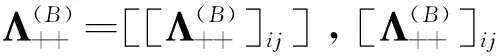
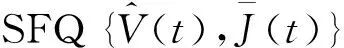
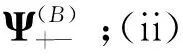
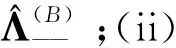
2.2 主要结论
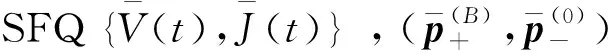
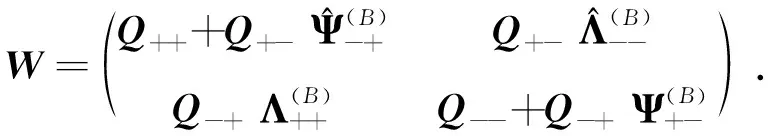
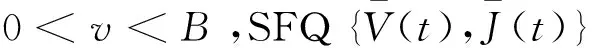
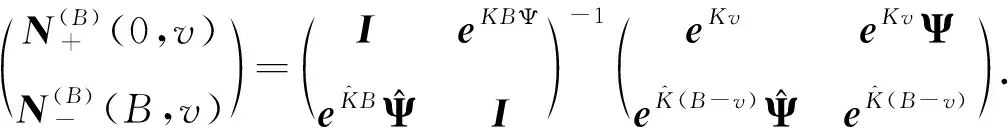
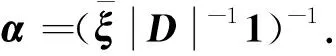
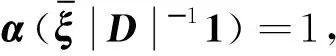
3 数值解释
3.1 数据设置
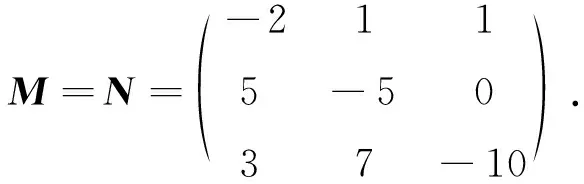
3.2 数值分析

4 结语
