基于TF-IDF 的食品风险分析模型的构建与应用
2023-01-12姚振民邢家溧承海郑睿行毛玲燕徐晓蓉张书芬沈坚
姚振民,邢家溧,承海,郑睿行,毛玲燕,徐晓蓉,张书芬,沈坚
(宁波市产品食品质量检验研究院(宁波市纤维检验所)浙江宁波 315048)
民以食为天,食品是人民生存最基本的物质保障。近年来,国民经济水平的大幅提升,人民生活水平大幅改善,食品质量成为消费者关注的重点。食品安全与人民身体健康息息相关,因此业内外各界都格外关注食品安全管理[1]。然而,“固体饮料冒充配方奶粉”“苏丹红”“红心鸭蛋” 等食品安全问题的报道屡见不鲜[2],这些频繁发生的食品安全事件既严重侵犯了消费者的合法权益,也对国家公信力有一定的影响,因此,食品安全问题引起我国政府与有关部门的高度重视[3]。以综合提升食品安全监管效能为建设目标,科学探索食品安全风险分析模型[4],积极推进风险监测与预警关口有效前移,实现食品安全源头防控和主动预防的相关研究必将被重点关注[5]。
目前,我国食品安全风险评估和风险监测中存在覆盖面窄,数据共享程度不高,资源投入较少等问题[6]。虽然我国食品安全风险评价已开始,但是与其他国家,尤其是发达国家相比仍存在显著差距,因此在评估中不断借鉴新的经验是必不可少的[7]。目前,国际上的主流方法是通过评级或赋值来对风险发生的可能性和严重程度进行等级排序[8]。基于这些不同的方法,研究人员探索出不少风险分级模型,包括定性、定量和半定量模型3 类[9]。如美国食品药品监督管理局(FDA)向公众开放的一个基于网络的定量风险评估系统——iRISK,被认为是最适合微生物风险分级的方法[10]。这些风险分级模型的分级效果与风险指标体系构建、初始数据形式、使用的方法等有关,其中定量风险分级模型的分级效果最好,然而,缺点是需要有充足的数据支持[11]。目前美国和欧盟的食品安全风险分级模型主要是针对食品中的微生物和化学污染物[12],国际上尚无通用的食品安全风险分级模型。
国务院 《促进大数据发展行动纲要》(国发[2015]50 号)提出:推动大数据应用,建立并不断完善涵盖基础、数据、技术、平台/工具、管理、安全和应用的大数据标准体系[13]。大数据时代的到来,为食品安全分析模型的建立提供了一种全新的思路。原先单一的食品数据分析方法,例如不合格率、超标率等,渐渐不能满足人们对食品安全信息的要求。基于食品安全大数据特点,开展食品安全大数据标准化研究,从而构建食品安全风险分析模型并做出深度分析,乃至进一步预测地区风险才是充分利用大数据特征,响应国家号召、顺应时代潮流的重点方向。
本文以2019 年12 月到2020 年12 月间某市蔬菜产品各项检测数据为研究对象,通过词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)方法建立指标权重体系,以对检测技术参数及标准限量值的客观认知,通过对结果数据矩阵的处理补全,进一步计算得到最终各个样品的具体风险指数。模型的建立将为我国蔬菜安全分级问题分析与风险预警提供理论依据,且可以推广到各类食品,并为深度挖掘食品安全数据信息,探索构建食品安全监测和风险评估新模式提供一种新的思路。
1 材料与方法
1.1 数据来源
连续收集2019 年12 月至2020 年12 月间某市蔬菜类农产品指标检测资料。样品抽检依据国家食品安全抽检计划并遵循“双随机”原则,检测方法按照2019-2020 国家食品安全检测方法标准进行。检测结果判定依据GB 2763-2019《食品安全国家标准 食品中农药最大残留限量》。
1.2 数据预处理
根据国家食品安全风险评估专家委员会的数据采集需求,单项检测项目未检出的占比低于60%的,检测值定义为1/2 检出限(Limit of detection,LOD),高于60%的定义为LOD。处理完检测结果为未检出的数据之后,将未检测定义为0,得到矩阵定义为G。
1.3 模型开发
采用TF-IDF 作为权重确定的数值统计方法。该方法原旨在反映单词对集合或者语料库中文档的重要性,在信息检索、文本挖掘和用户建模的搜索中常用作加权因子,其值与单词在文档中出现的次数呈正比的增加,并被包含该单词的语料库中的文档数量所抵消。其中,TF(term frequency)有多种表达方式,包括原始型、布尔型、对数标度型等,本文中TF 值以tf(t,d)表示,而IDF(inverse document frequency)是对单词提供多少信息的一种度量,即该信息在所有文档中是常见还是稀有(通过将文档总数除以包含该术语的文档数量,然后取该商的对数来获得),本文中IDF 值以idf(t,D)表示。
本质上来说TF-IDF 是基于信息论出发的一个统计方法,假定D={d1,…,dN}为一个文本集合,而W={w1,…,wM}为D 中的单词集合,其中M 和N分别表示为单词和文本的总数。分别用dj和wi表示D 和W 中的元素,用D 和W 表示为{d1,…,dN}和{w1,…,wM}中的随机变量,假定D 中所有元素取到的概率相等且为P(dj)=1/N,那么,每个文档计算的信息量为-lg(1/N),而随机变量D 的熵为:
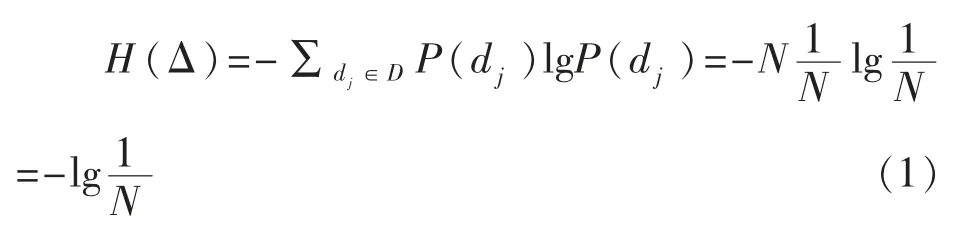
接下来考虑已知wi(∈W)的情况,令Ni为含有wi子集中的文档个数,假定各个文档取到的概率相同,则它们的信息量均为-lg(1/Ni),在给定wi的情况下,随机变量D 的熵为:
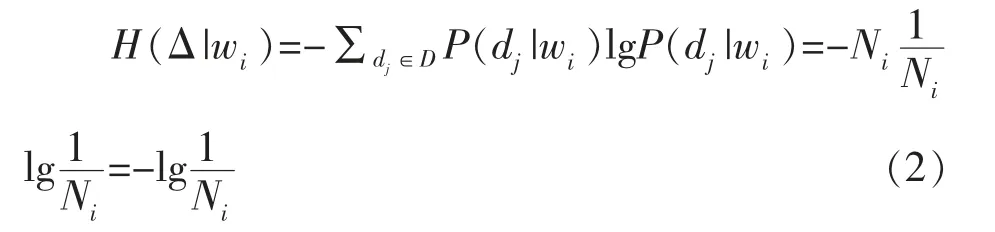
假设在选定子集中没有wi的文档的出现概率为零,即这些文件没有任何贡献,上述方程中不可能出现N-Ni。
现在,从整个文本中任取一个单词wi,将dj中wi的频率表示为fij,而整个文本中wi的频率表示为,该文本中的所有单词总数表示为F,则有如下等式成立:,那么交互信息值可以表示为:
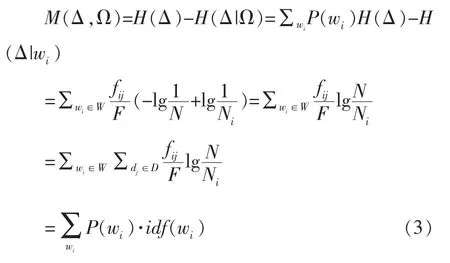
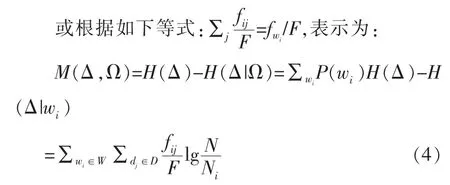
等式(3)和(4)分别为以fwi或fij形式表示TF和除以常数F 的IDF 的乘积。IDF 因子表示观察到特定单词后信息量的变化,而TF 因子表示实际观察到该单词的概率估计。(3)和(4)分别表示两个不同的方面,当TF 表示为fwi时,TF-IDF 意为单词选择的度量,而当TF 表示为fij时,TF-IDF 意为单词权重的度量[15]。
对比于本文或者语料库的结构构成,食品数据拥有类似的数据结构构成,同样的数据大量缺失、大量重复。将每个样品视为一句单句,每个检测项目作为构成单句的单词,以方法LOD 值作为衡量单词出现频率的基准线,从而得到一个类似于文本矩阵的数据矩阵,进一步对每个检测项目进行权重的赋值,最终进行风险值的评估。经尝试,从结果来看,该模型效果很好。
1.4 数据处理
以每个样品所做各个指标的检测方法的检出限为基准,假设某样品的某个指标检出为m,所用方法检出限为n,则定义该样品的该个指标为m/n,相当于检出m/n 次。若未检出,则由1.2 节所述,根据未检出的占比情况分别定义为1/2 和1次。若未检测则表现为0 次,最终得到一个频数矩阵,不妨定义为K。
1.5 权重的计算
权重的计算分为两个部分,首先计算TF 值:

式中:ft,d——某一指标t 在样品d 中出现的次数,即频数矩阵K 中第d 行,第t 列的值。∑t'∈dft',d——该样本所有频数之和,在K 上表现为第d 行所有数的和。
然后,计算IDF(inverse document frequency)值:
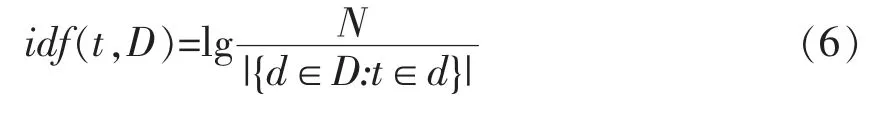
式中:N——样品数,即表现为K 的行数。上式的分母指N 个样品中,包含t 指标的样品的数量,在K 中表现为K 中第t 列不为0 的行数,如果分母为0,则变为|d∈D:t∈d|+1。
最终将所得的tf(t,d)与idf(t,D)相乘,得到权重矩阵W0,
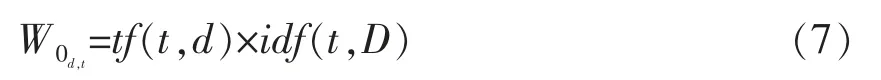
将其作归一化处理,得到:

1.6 风险程度的分析
重新处理得到的F 矩阵,为初步处理的结果矩阵,将其各个元素与对应的食品安全国家标准中的最高限量值MRL 作比值,即:

得到的矩阵M 为各样本的各项指标值,对于其对应的食品安全国家标准中最高限量值MRL的比值矩阵,反映各样本各个指标的检测值对应的风险程度。
1.7 风险指数的计算
将所得的权重矩阵与风险矩阵各个点对应相乘即:

将S0进一步处理:
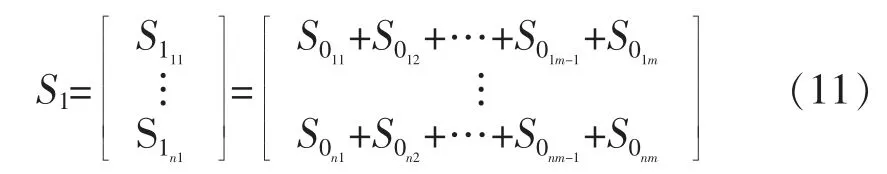
再将S1进一步处理:

其S 中大于0 的为不合格样品,小于0 的为合格样品,得到的最终评分越大,其风险程度越高。
2 结果与分析
2.1 基本情况
蔬菜属植物性农产品,是人体所需膳食纤维、维生素、植物化学物质、矿物质等的主要来源,在我国居民日常膳食中不可或缺的一种食材。本文中用到的数据包括2019 年12 月到2020 年12 月间共1 642 批次(12 872 项次,包括各类检测项次),其中包括豆类蔬菜、根茎类和薯芋类蔬菜、茎类蔬菜、叶菜类蔬菜等12 类50 种,检测项目包括阿维菌素、倍硫磷、敌敌畏、啶虫脒、毒死蜱、氟虫腈、腐霉利等26 类。当前可通过市场手段获得的主要蔬菜及种植业常用农药品类均已覆盖。表1为部分批次的部分项次。
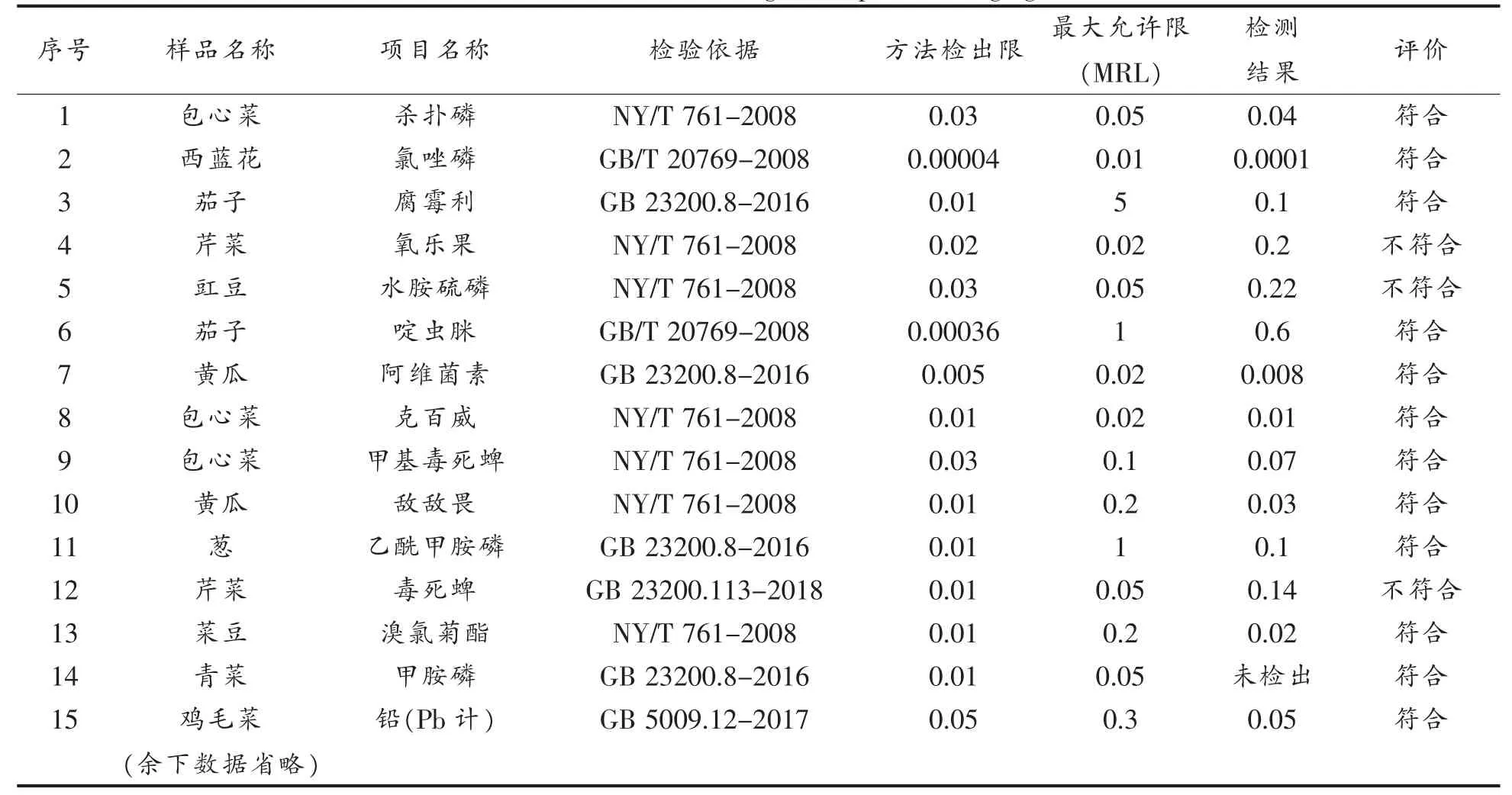
表1 蔬菜产品原始数据表(mg/kg)Table 1 Raw data of vegetable products(mg/kg)
2.2 数据初步处理情况
将原始数据按照上述步骤进行处理,并暂时舍去部分不需要因素(如检验依据等),可得到表2,即初步处理的结果(部分)
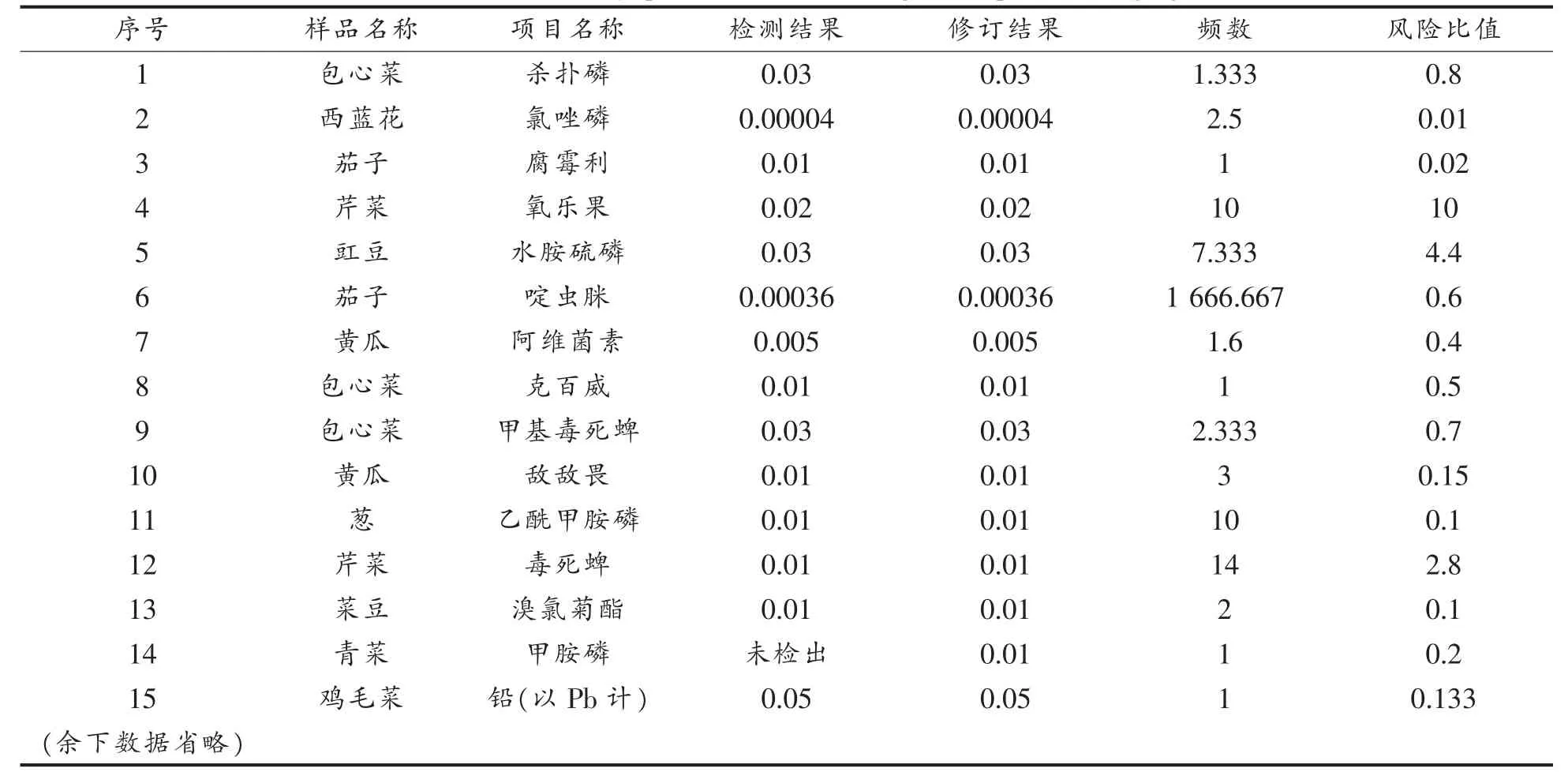
表2 蔬菜产品初步处理数据表(mg/kg)Table 2 Preliminarily processed data of vegetable products(mg/kg)
2.3 指标权重构建
权重的建立是整个模型构建的重中之重,权重设置的好、坏影响模型构建的结果以及最终风险评估的结果。方法学上来说,某一检测指标在该样品中的检测值越大,即上述计算得到的频数越大,则在该样品中所占的权重越大,其对该个样本的贡献度就越大[15],而包含该检测项目的样本数量越多,该项目整体权重被抵消的越多。通过计算得到各样品各个检测项目的权重如下表3 所示。
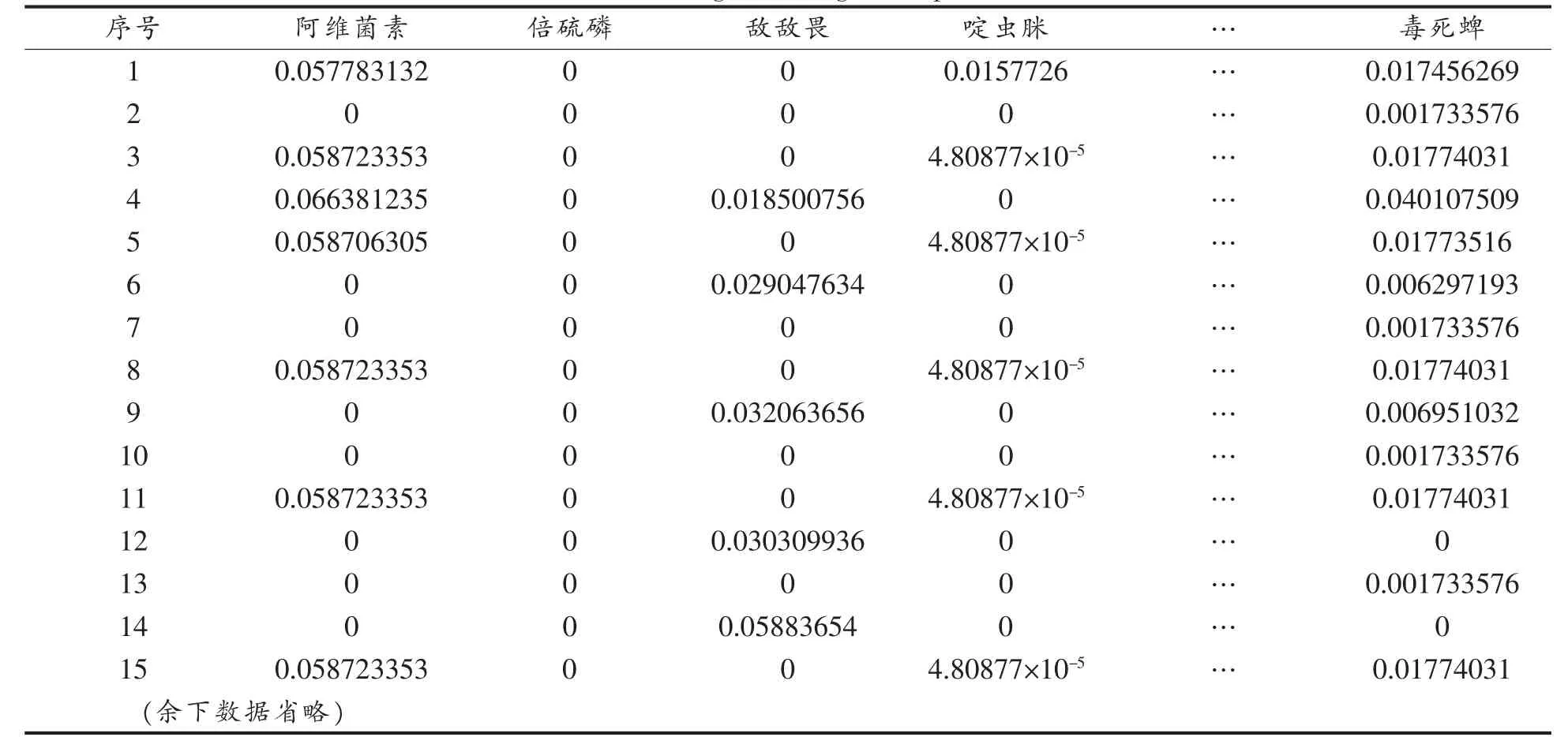
表3 蔬菜产品权重表Table 3 Weights of vegetable products
2.4 风险值计算
经计算得到各样本的单独风险值见表4(从高到低排序)。
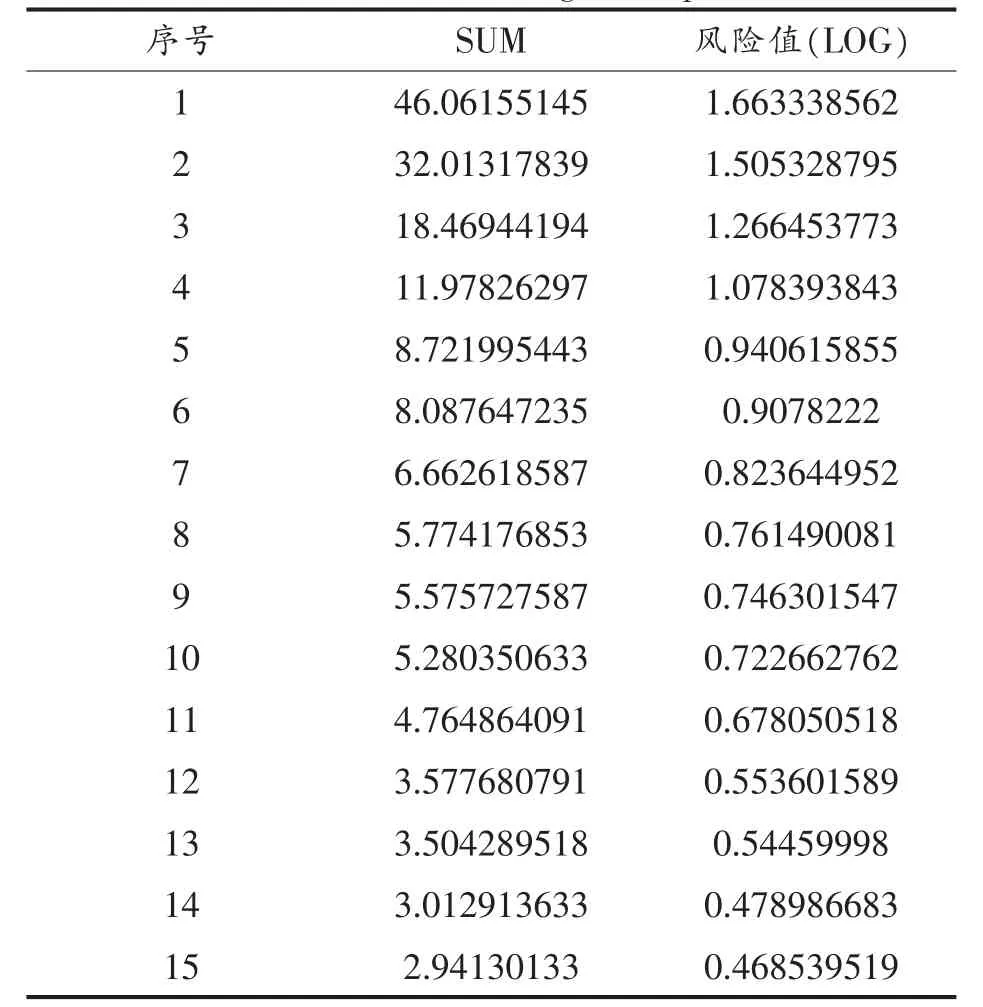
表4 蔬菜产品风险值表Table 4 Risk values of vegetable products
2.5 结果分析
最终得到的风险值越大该样本的风险程度越高,且以0 作为分界线,当最终的风险值大于0时,样本为不合格样本,小于0 时为合格样本。
2.5.1 单个样本情况分析 从单个样本来看,对于风险值最高的,数值为1.66333 的批次,样品名为芹菜,甲基异硫磷的检测结果为0.48 mg/kg,为国家标准最大允许限量值(0.01 mk/kg)的48 倍,该样品的各指标权重分布情况为:甲基异硫磷的权重占到该样本的0.95,其余26 个项目之和为0.05。风险值第二高的样品名为韭菜,经比对,检测指标中腐霉利的含量为6.8 mg/kg,为国家标准最大允许限量值(0.2 mg/kg)的34 倍,该样品的各个指标权重分布情况为:腐霉利的权重占到该样本的0.94,其余26 个项目权重之和为0.05。研究表明最终风险值大于1 的都有某项指标显著超过国家标准最大允许限量值。风险值仅为0.0586 的是青菜的样本,其啶虫脒超标了1.5 倍,相较于其它不合格产品,相对来说风险性较小。
最终的风险值情况并不是完全取决于某样品是否某个指标超标倍数。例如有一样本为茄子,氧乐果检测结果为0.36 mg/kg,超过国家标准最大允许限量值(0.02 mg/kg)的18 倍,比韭菜(毒死蜱超标了10 倍)风险值高。具体原因有很多种,根本原因是所有含有该检测项目的样本数不同,导致权重有一定的差异,以至于最后在计算风险值时有一定的差距。
通过以上分析,从较为关注的不合格批次来说,单项风险因子超标较多的批次,最终通过模型得到的风险值也较大,而部分合格批次最终风险值靠近0 的也有某一项风险因子被检出,其值甚至靠近定量限。综上,由单个样本的分析得出,该模型对于单项样本的风险度有较好的反馈。
总的来说,通过分析2019 年12 月到2020 年12 月间蔬菜产品单体数据情况,可以得出芹菜和韭菜是需重点关注的对象,而毒死蜱和腐霉利作为其中具有较高风险的项目需引起关注。
2.5.2 总体样本情况分析 本文采用数据共1 642 批次,各类风险因子检测12 871 项次,其中不合格批次为27 批,不合格率为1.64%。各类因子检出528 项次,检出率为4.10%,其中不合格项为27 项次,占检出项的5.30%。在统计的26 种风险因子中(表5),啶虫脒、腐霉利、氯氟氰菊酯和高效氯氟氰菊酯的检出率和不合格率分别为50.84%和0.63%,30.46%和2.65%,8.45%和0.20%,其中腐霉利不合格率显著高于蔬菜风险因子平均水平(P<0.01,卡方检验),且不合格批次都为鳞茎类蔬菜(芹菜),需特别关注,其余不合格率均正常分布。
由表5 可知,同一个风险因子,检出率与不合格率并无相关性,比如啶虫脒的检出率高达50.84%,而其不合格率处于正常水平,同样的甲拌磷检出率虽然较低,但是不合格率高居第二。
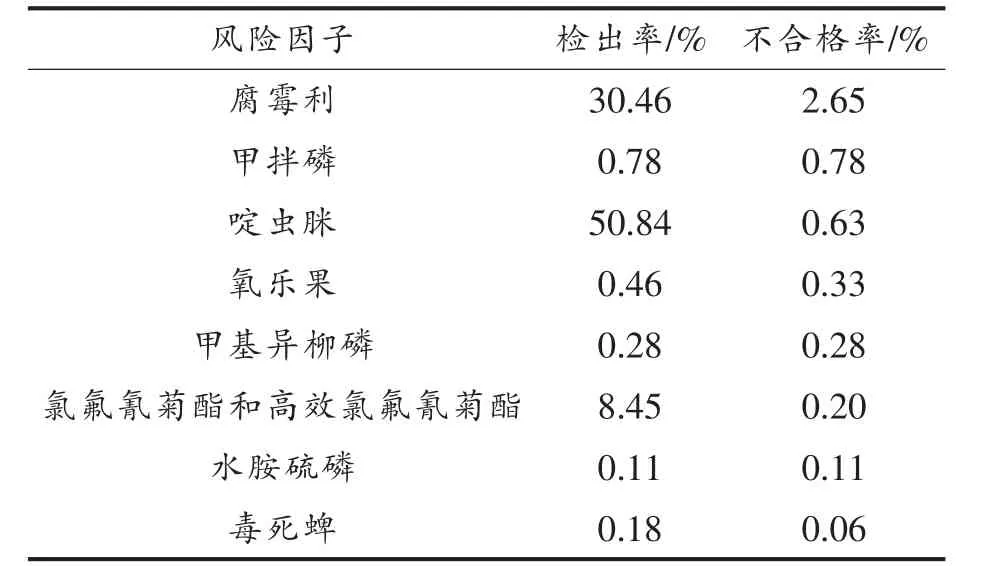
表5 风险因子分析表Table 5 Risk factor data
经过计算不合格批次的风险值均大于0,通过TF-IDF 权重确定方法以及模型最终得到的风险值如图1 所示(从高到低排序)。风险值在0 以上均为不合格,0 以下均为合格。可以看出绝大部分的蔬菜产品都为低风险甚至无风险产品。
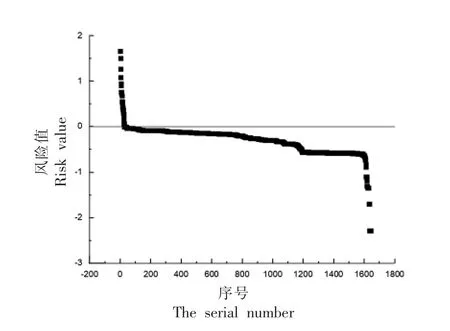
图1 最终风险值总体情况Fig.1 The overall performance of final value
考虑到蔬菜具有季节性等特点,为了更直观反映蔬菜产品风险值与时间的关系,以时间为横坐标,上文所得风险值作为纵坐标作图,分析蔬菜安全风险变化情况。图2 为2019.12 至2020.11 期间风险值(取每个月平均值)与时间关系图。总体来说,这段时间的蔬菜风险情况都维持在风险度较低的水平,2019 年12月至2020 年1 月,2020年12 月至2021 年1 月的风险趋势类似,同时也呈现出一定的季节性波动,夏季相对较低而春秋冬季相对较高,符合一般蔬菜的播种收获情况。此结果表明,基于TF-IDF 的权重确定模型,不仅单个样本在一定程度上反映具体的风险超标情况,而且对蔬菜整体的季节性有一定的反馈,反映该模型总体的评价效能,因此,该模型符合对风险概念的认知和应用。
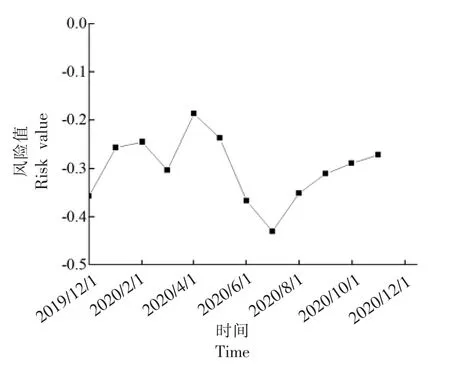
图2 蔬菜产品风险值与时间的关系Fig.2 Relationship of vegetable products between risk value and time
3 结论
鉴于食品检测数据的复杂性,为进一步探索能客观合理分配权重,能更好、更直观体现食品风险程度的方法模型,本文尝试权重赋值方法(TFIDF)在食品领域的重新架构应用。收集2019 年12 月至2020 年12 月间的蔬菜产品的各项检测指标,通过一系列计算分析,将该模型应用于食品风险研判。通过本模型的构建,原先模糊的食品安全风险概念变成具体的指数形式,这对于风险有了更加直观的定义。相较于传统单因素分析方法,该方法引入机器学习的内容,在大数据时代背景下,对于深入研究食品安全风险及其评价方法提供一条新路径。
