大数据相似重复记录检测算法在试题库中的运用
2023-01-09胡小琴潘锦锋
胡小琴,潘锦锋
(泉州信息工程学院 软件学院,福建 泉州 362000)
在试题库设计中,通常采用智能数据库信息处理技术,以提高试题库的智能抽选能力。由于重复记录的出现,试题库会出现大量冗余,需要优化试题库大数据相似重复记录(以下简称重复记录)检测模型,并结合大数据信息处理技术,对重复记录进行处理和删除,以提高试题库的精准筛选能力[1]。
重复记录检测是建立在大数据统计分析和融合处理基础上,构建重复记录的大数据分布模型,采用分布式链路重组方法进行重复记录特征挖掘和自适应结构重组,建立重复记录分布的检测统计量,实现重复记录检测[2]。传统方法中,重复记录检测的方法主要有主成分分析法和粒子群检测法[3-5]。采用主成分分析法分析重复记录的关联规则项,实现对重复记录的聚类中心定位检测,但计算开销较大,精准度不好。对此,本文提出面向试题库建设的重复记录检测算法。首先采用大数据分析方法,构建重复记录分布模型,用分布式链路重组方法进行重复记录相似度挖掘和自适应结构重组。构建重复记录的模糊信息特征分析模型,采用模糊特征检测方法实现重复特征分析。采用大数据融合和聚类检测方法实现重复记录的融合处理,对重复记录进行输出检测,然后将重复记录检测结果应用在试题库构造和抽取模型中,提高数据库的实时维护能力。最后进行仿真测试分析,展示了本文方法在提高重复记录检测能力方面的性能。
1 重复记录分布及特征结构分析
1.1 重复记录分布模型
在检测大数据相似重复记录前首先对重复记录分布及特征结构分析[6],得到试题库大数据相似重复记录检测的总体结构模型如图1所示。
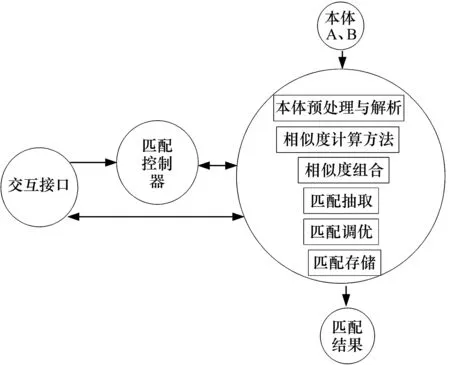
图1 重复记录检测的总体结构模型
构建重复记录分布模型,采用分布式链路重组方法进行重复记录相似度挖掘和自适应结构重组[7],得到相似度检测的关联规则向量集分布为:
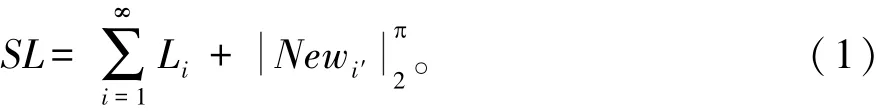
式中:Newi′表示重复记录自适应参数;Li表示相似度检测指标。在重组的随机链路模型中,进行重复记录分布大数据节点检测[8],节点集记为xR⇔yR,得到重复记录分布大数据负载量:
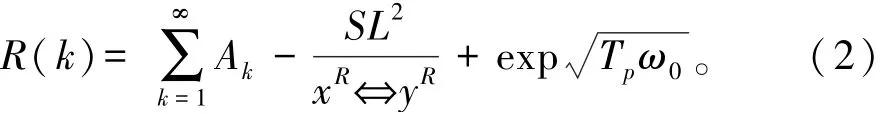
式中:ω0为重复记录分布大数据的负载预测误差;Tp为权重调整系数;Ak为重复记录分布大数据分布集。分析节点间层次关系相似度,将重复记录分布大数据进行信息重组,得到层次关系出度集的检测统计量:

式中:层次关系的入度集和出度集分别为yin和yout;ξi表示重复记录节点间隔函数;w表示节点间相似度变化参考值。
对数据进行初始化处理,当重复记录规模集趋于无穷大,得到重复记录的交叉分布可测集,构建重复记录分布模型:

式中:P(k)表示随机链路中重复记录的分布区间。提取重复记录统计时间序列的关联规则量,实现试题库大数据相似重复记录分布重组。
1.2 重复记录特征结构分析
构建重复记录的模糊信息特征分析模型,采用模糊特征检测方法实现对重复记录的特征分析,根据试题库的实体模型分析,得到重复记录的寻优特征量φ(k),给定本体O,xi为O的锚点概念,得到重复记录分布的主成分特征分布集为:

采用线性规划方法,构建试题库大数据相似重复记录结合和自适应调节模型,设W(k)中x的层次关系入度集为xin,得到核函数k(xi,yi),重复记录检测的加权马尔科夫检测特征核函数模型为:
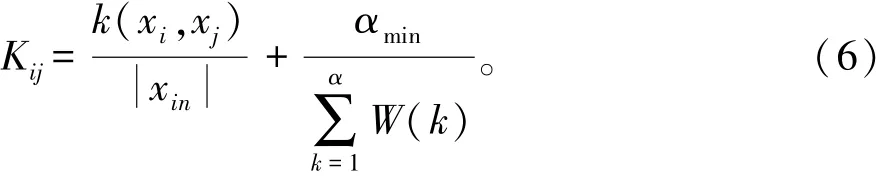
式中:αmin表示数据层次分布最低维度。对重复记录的状态特征进行自适应聚类,得到重复记录检测的可靠性分布函数为:
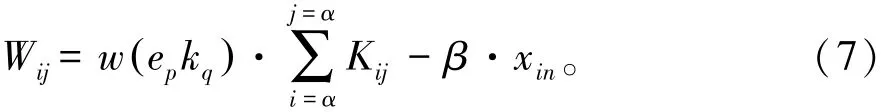
式中:β为自适应加权系数;w(epkq)表示重复记录检测的可靠性系数。设置重复记录的分布数据流,j=0,1,…,N-1},样本聚类权重为{c(j0)=0,j=0,1,…,N-1},采用层次关系入度集特征监测的方法,分析重复记录特征结构,得到重复记录的统计特征量:

在模糊信息特征分析模型中提取重复记录的统计特征量,由此实现对重复记录特征结构重组[9]。
2 重复记录检测
2.1 重复记录融合
建立重复记录的回归分析模型,基于空间网格聚类方法实现对重复记录融合处理[10],得到重复记录的平均信息量为:
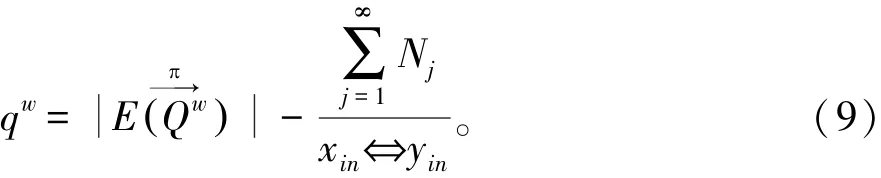
式中:E(Qw)表示重复记录分布大数据的量化分析函数。构建重复记录检测的大数据分析模型,xinyin={x|x∈xin,y∈yin}表示与x、y有层次关系的节点中可匹配的节点集,采用多分量调节方法进行重复记录检测的融合处理[11],得到重复记录分布大数据的关联融合项为:

式中:<x,y>为重复数据的一对锚点,此时关联规则分布结果满足OM(x,y)。对重复记录分布大数据进行聚类处理,得到的融合聚类输出为:

式中:Twk表示重复记录分布大数据的模糊辨识参数。根据重复记录分布进行多维结构重构,建立重复记录的残差融合向量,权重调整参数满足0<,由此对重复记录进行融合处理[12]:
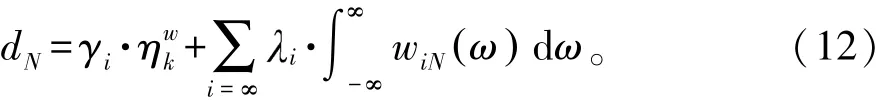
式中:wiN为第i个点的重复记录的融合加权值。
2.2 重复记录检测输出
根据数据聚类结果实现对重复记录的特征分离和差异性融合[13],设定的匹配阈值θ,在空间坐标系中实现对重复记录检测,得到重复记录的输出多维分布集为:

式中:ykj表示知识点;N为数据长度。在不同指标间实现重复记录检测的语义匹配,构建本体结构模型[14],由此得到重复记录检测的输出元组为:
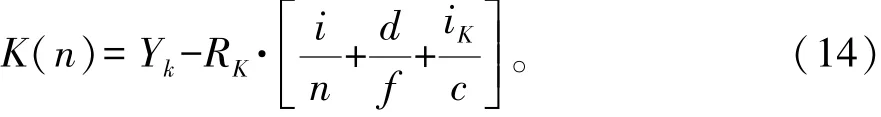
式中:i、n、d、f、c、iK、RK分别是试题库大数据知识点本体自适应加权系数。输出的稳态检测记录为:
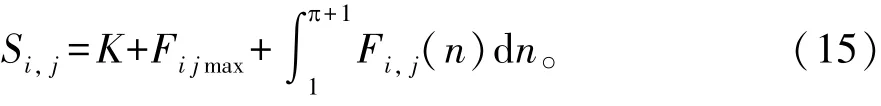
式中:Fi,j表示重复记录的多重线性匹配参数;Fijmax为本体图结构的相似性最大匹配范围。定义ki为重复记录检测的输出区间,在空间坐标系中构建重复记录检测输出函数为:
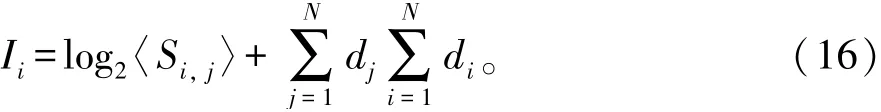
式中:di和dj为重复记录聚类调度的模糊规则输出量。综上,在空间坐标系中实现对重复记录检测[15]。
3 仿真实验与结果分析
实验中设定试题库大数据的分布数为120,相似度特征分布集为0.85,锚点节点的匹配系数为0.35,仿真时长为100 s,对试题库大数据相似重复记录采样的长度为800,特征分辨率为120,根据上述仿真参数设定,实现重复记录检测,得到数据检测的输出统计特征量分布如图2所示。
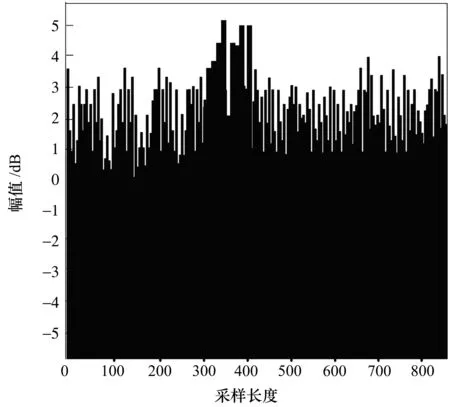
图2 统计特征量分布
根据图2的统计特征分布,构建重复记录检测的数据分析对象模型,得到重复记录检测的错误率如图3所示。分析图3得知,本文方法对重复记录检测的错误率较低。
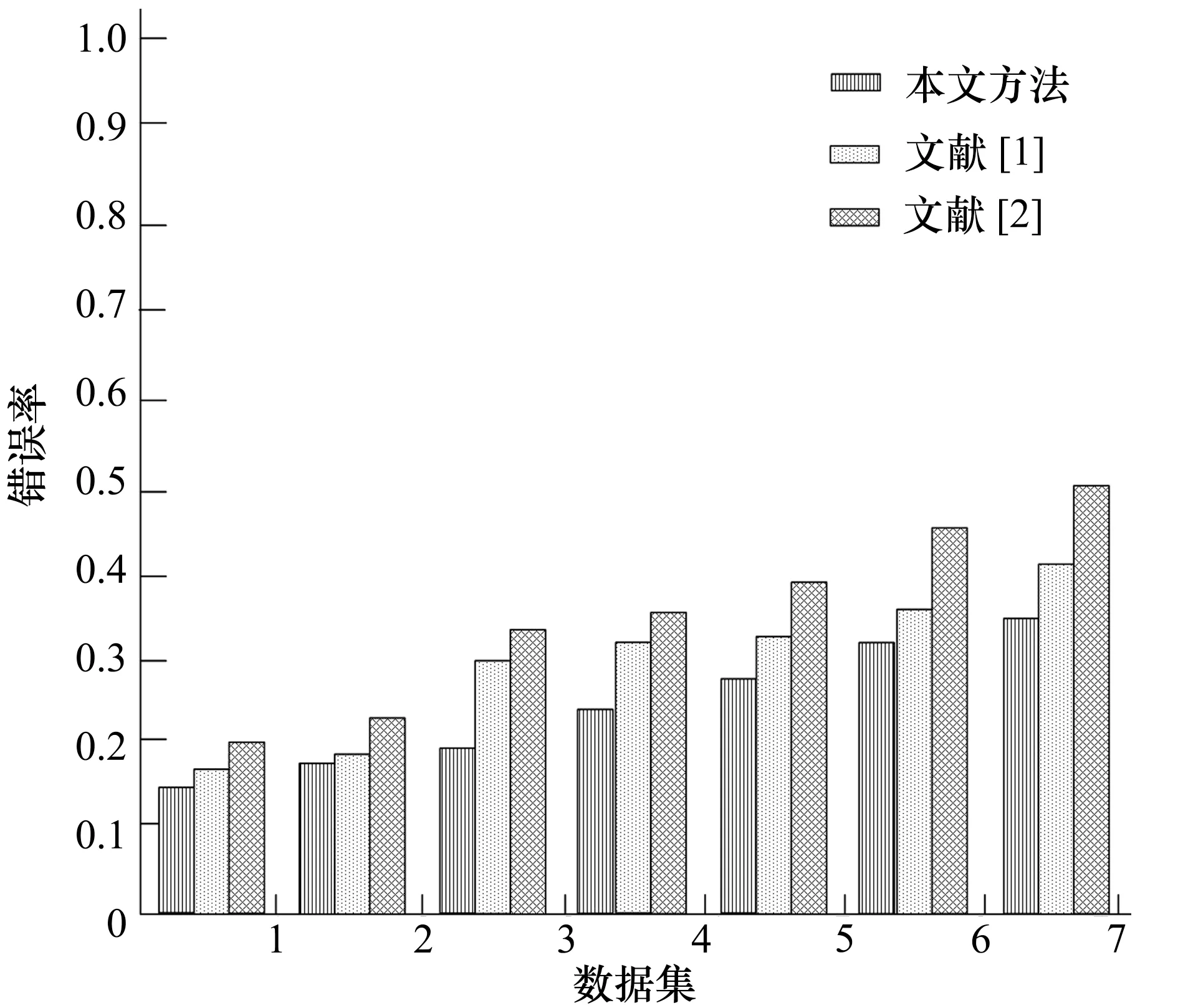
图3 重复记录检测的错误率
测试重复记录检测的时间结果如图4所示。

图4 大数据相似重复记录的时间开销
分析图4可知,本文方法对重复记录检测的时间开销较小,提高了试题库重复记录检测的收敛性水平。
4 结语
在试题库中针对传统的大数据相似重复记录检测算法存在检测错误率高、检测时间长的问题,本文提出面向试题库建设的大数据相似重复记录检测算法。通过重复记录检测的总体结构,对重复记录分布,根据重复记录分布的主成分特征分布集,分析重复记录特征结构,以分析结果为基础,采用空间网格聚类方法对重复记录融合,根据融合结果,在空间坐标系中实现对重复记录检测。根据实验结果可知,本文方法的试题库大数据相似重复记录检测错误率较低,检测效率较高。但是由于该方法的计算过程较复杂,致使试题库大数据相似重复记录检测效率未达到预期效果,因此,在接下来的研究中,将对算法进行改进,进一步提升试题库大数据相似重复记录检测效率。
