基于UV位置图的视频三维人脸表情克隆
2023-01-09崔时雨张满囤
崔时雨,申 冲,齐 畅,刘 川,张满囤,3
(1.河北工业大学 人工智能与数据科学学院 天津 300401;2.河北省数据驱动工业智能工程研究中心 天津 300401;3.天津市虚拟现实与可视计算国际联合中心 天津 300401)
0 引言
人脸表情的变化可以表达信息、传递情绪,如何逼真地克隆出三维人脸面部表情一直是计算机图形学及计算机视觉领域的研究热点。从20世纪70年代Parke[1]制作出第一个参数化三维人脸模型开始,国内外科研人员就逐渐对这项技术展开了深入的研究,三维人脸表情克隆技术也在不断发展。目前,人脸表情克隆技术已逐渐应用到影视制作、游戏互动、医学研究等多个领域,人脸表情的实时克隆不仅能大量降低相关工作的复杂程度与设备要求、减少工作人员数量,还能应用到许多常人无法完成的工作中。传统的三维人脸表情克隆生成一般都需要特殊的表情数据捕捉设备,比如光学式运动捕捉设备、Kinect体感设备等。利用Kinect设备可以获取低分辨率的RGB-D数据,从而得到人脸关键点的深度信息[2]。Nguyen等[3]使用Kinect体感设备,开发出针对面部损伤患者的实时头部及面部动画系统,用于模拟面部康复效果。但这种方法的缺点是相关数据捕捉设备价格昂贵,成本较高,而且使用场景受限,因此无法在平时生活中广泛使用。
基于生理结构模型的方法[4-5]不仅可以降低设备成本,还能通过模拟人脸的生理结构生成人脸表情动画,带来很好的真实感。这种方法基于解剖学的原理,通过构造面部肌肉模型、骨骼蒙皮模型等方式,模拟人脸骨骼的运动、肌肉的拉伸以及皮肤的弹性变化。但基于生理结构模型的方法不仅需要一定的解剖学基础,还需要大量的计算求解肌肉运动,不利于视频中人脸表情克隆的实施。
随着深度学习的不断发展,越来越多的研究人员将深度学习与此前的方法相结合进行人脸表情生成。Yi等[6]在三维形变模型(3D morphable model,3DMM)的基础上提出了多度量回归网络来回归模型参数。针对3DMM构建的训练数据克隆出的结果不够精细的问题,Zhu等[7]利用RGB-D图像构建大规模细粒度的3D数据,并构建了一个包含20万个样本的数据集,还提出了一个新的网络FGNet来进行形状修改,有效改善了面部重建的质量。
虽然结合深度学习的方法进行三维人脸表情克隆已经取得了一些优秀成果,但对于视频中的三维人脸表情克隆,算法的准确性、实时性仍需要提高。为解决以上问题,本文改进了位置图回归网络(position map regression network,PRNet)[8]的结构。使用更加轻量级的网络模块代替原网络中的残差模块,并在训练时使用Wing Loss损失函数代替常用的L2损失函数[9],提高了模型的准确率。参考面部表情编码系统(facial action coding system,FACS),根据人脸面部肌肉的分布与产生表情时人脸皮肤的变化,将人脸划分为四个区域,并设计了新的人脸分区权重。最后,本文以上述模型为基础,提出了一种基于UV位置图的视频三维人脸表情克隆方法,该方法通过改进的网络估计视频中每帧人脸图像对应的UV位置图,再从UV位置图中提取与三维模型顶点对应的关键点三维坐标,最后根据关键点三维坐标控制三维人脸模型产生变形,实现视频中的人脸表情克隆。
1 相关工作
数据驱动的三维人脸表情克隆一般都需要有一个基础模型,通过估计人脸的形状、表情、纹理参数来驱动三维模型变形,或通过融合一组不同的表情基来拟合表情。但由于人脸差异性明显,表情丰富多样,这种定义在三维空间的线性模型受到很多限制。若直接将三维人脸模型中的所有顶点连接成一个向量,再用网络估计该向量,虽然可以获得模型顶点的三维信息,但却丢失了顶点之间的空间信息。
为了解决以上问题,Feng等[8]提出了用UV位置图作为新的三维人脸表示方法。UV位置图将人脸关键点的三维坐标与UV空间中UV坐标进行对应,并将三维坐标存储在二维图像上,实现了三维到二维的映射。在左手笛卡尔坐标系中定义三维人脸位置,利用弱透视投影,建立三维空间与二维图像各个点之间的联系。将三维空间的原点与输入二维图像的左上角重叠,指向图像右侧为X轴正方向,这时三维人脸模型在XOY平面上的投影与二维人脸图像恰好重合。因此UV位置图P(ui,vi)可以表示为
P(ui,vi)=(xi,yi,zi),
(1)
其中:(ui,vi)表示三维人脸模型中第i个顶点的UV坐标;(xi,yi,zi)表示该顶点对应的三维空间坐标;同时(xi,yi)表示在输入的二维图像上对应的像素点位置,zi表示该点的深度。由于(ui,vi)和(xi,yi)对应的是该人脸模型上的同一个点,因此这种表示方法可以保留对齐信息。

图1 二维图像与UV位置图Figure 1 2D image and UV position map
将UV位置图上的每一个点的坐标(xi,yi,zi)用RGB值(范围0~255)来表示,可以得到一个包含三个通道的二维图像,该图像的每个通道分别表示三维空间坐标x、y、z,如图1所示。
2 本文方法
2.1 基于Ghost瓶颈的UV位置图回归网络
近年来,轻量级神经网络架构的设计得到了学术界和工业界的广泛关注[10]。对于卷积神经网络来说,除了准确度,效率问题也是在设计网络时需要考虑的重要指标。如MobileNet系列[11],使用深度可分离卷积(depthwise separable convolution)来减少运算量,ShuffleNet系列[12]提出了逐点群卷积(pointwise group convolutions)和通道混洗(channel shuffle),在降低复杂度的同时提高了网络的精度。目前经过良好训练的网络生成的特征图可以包含丰富的信息,这些信息保证对输入数据的全面理解,但网络产生的很多特征图都十分相似,Han等[13]将相似的特征图称为Ghost,并且提出了Ghost模块,试图通过更简单的操作来得到这些相似的特征图。
普通的卷积层是将输入的二维图像与卷积核进行卷积,直接得到该层的特征图。Ghost模块是将输入的二维图像先进行主卷积,得到内在特征图,再对这些内在特征图执行多个线性操作,得到最终的特征图。如图2所示。
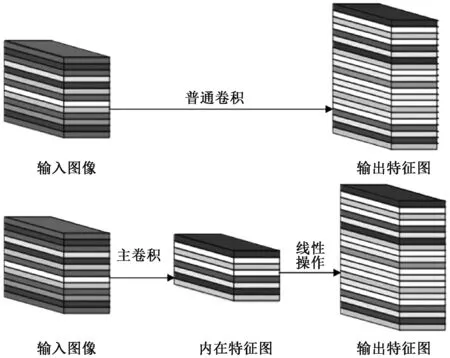
图2 普通卷积层与Ghost模块Figure 2 Convolutional layer and Ghost module
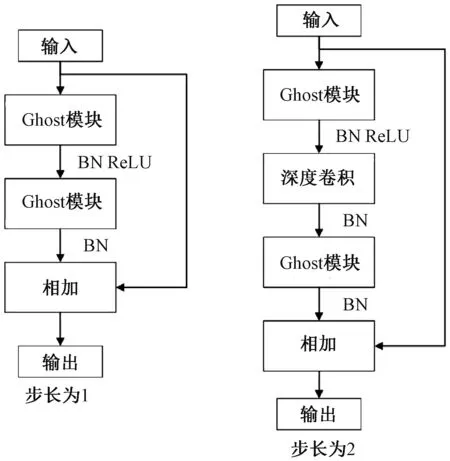
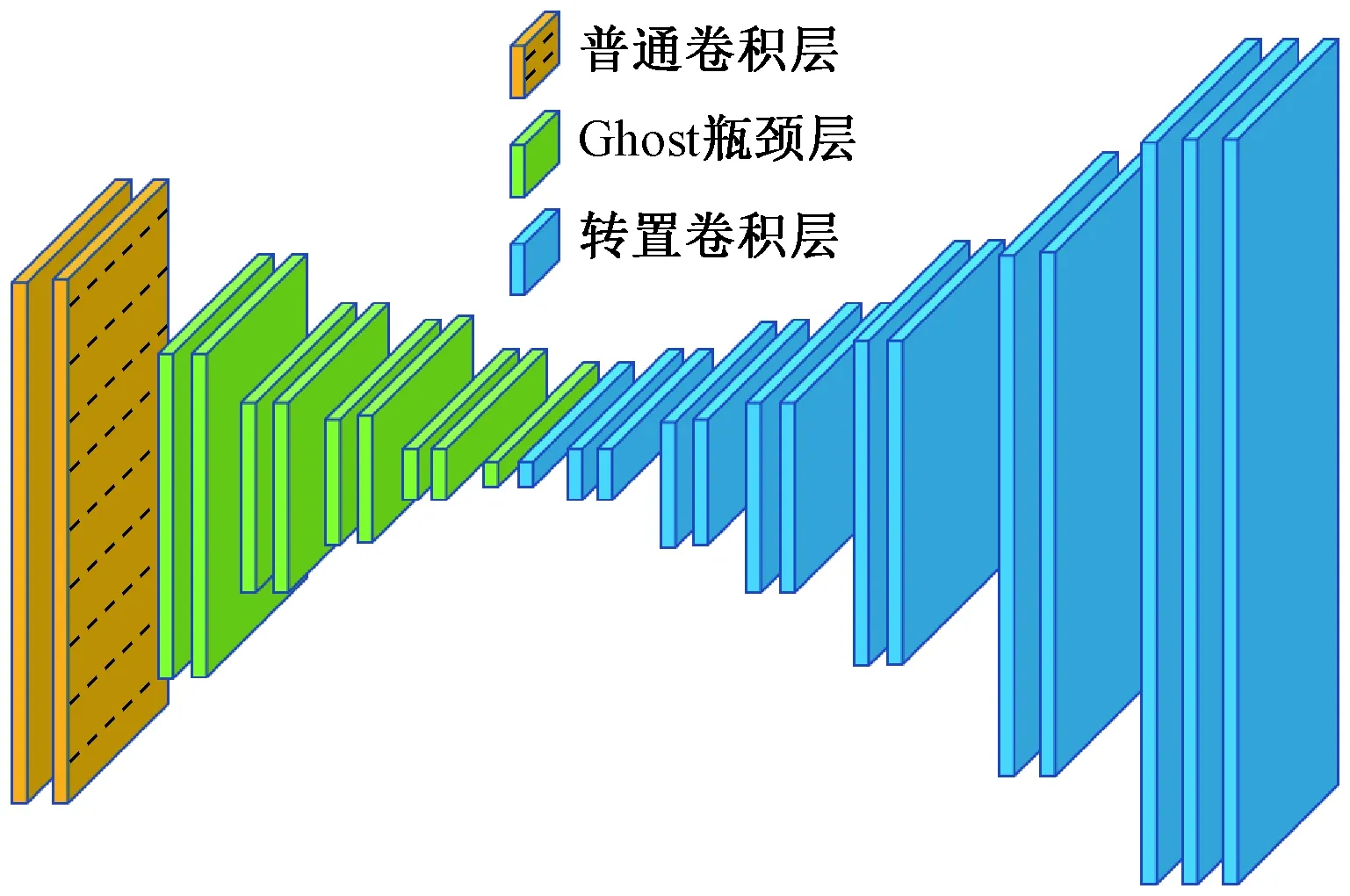
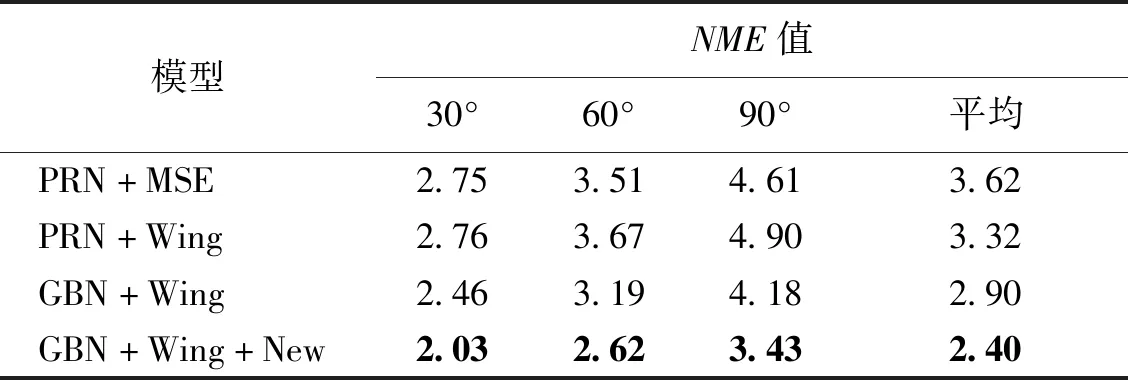
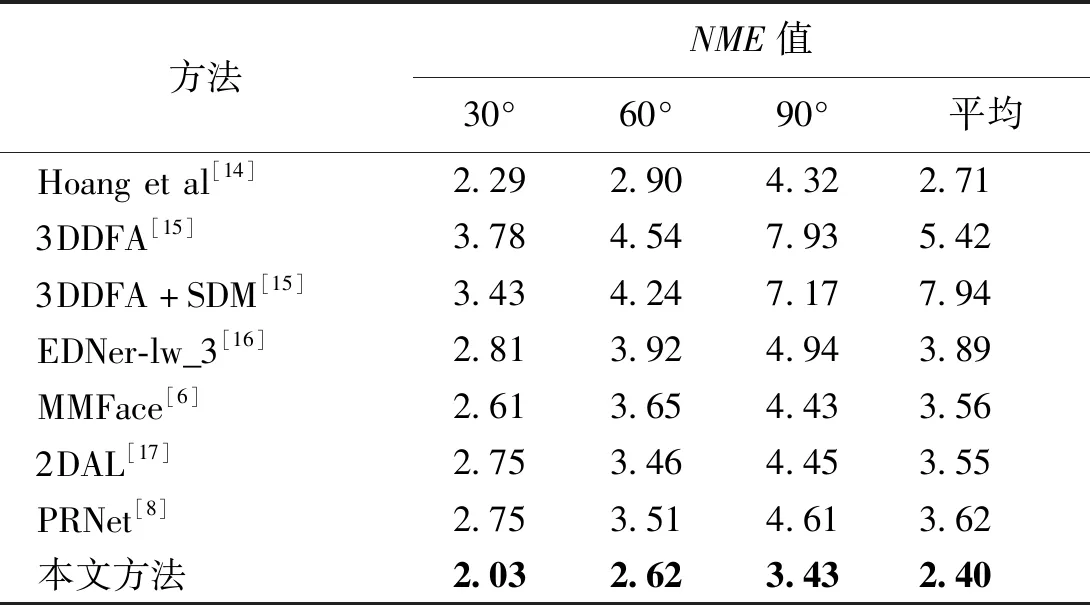
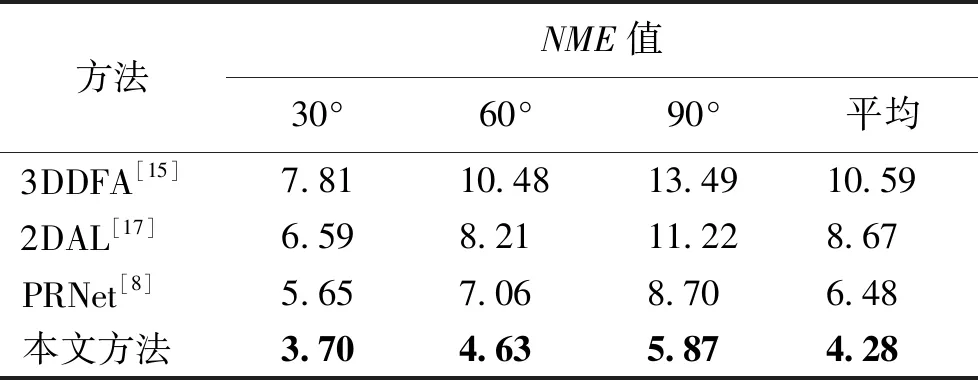
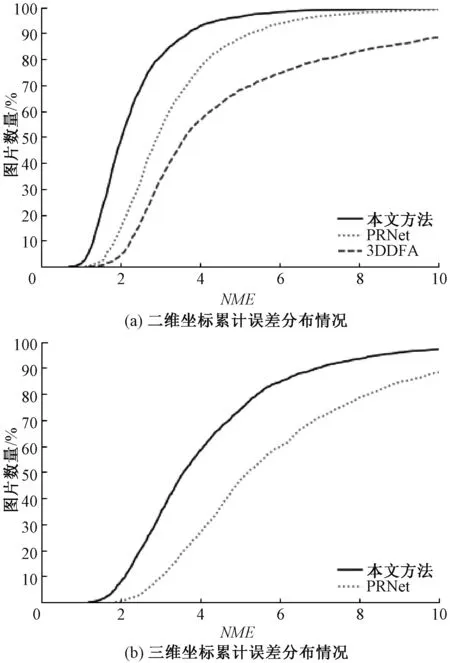
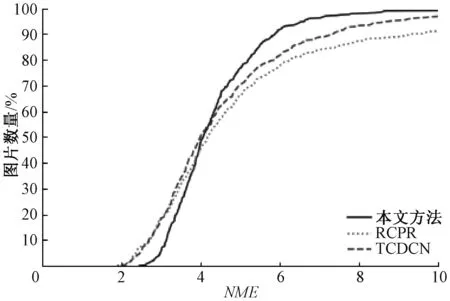
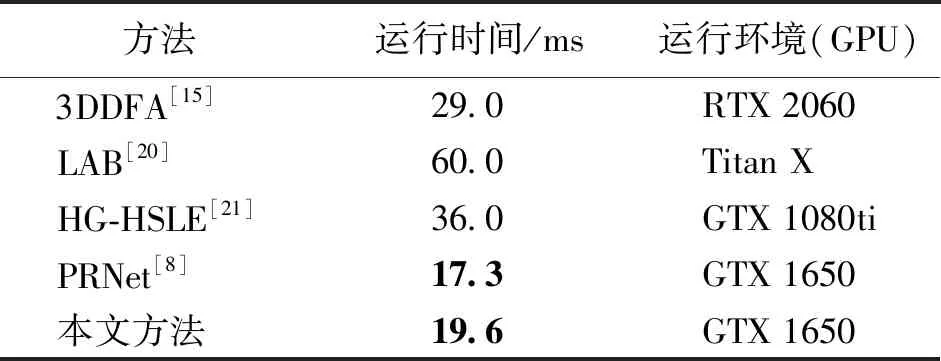
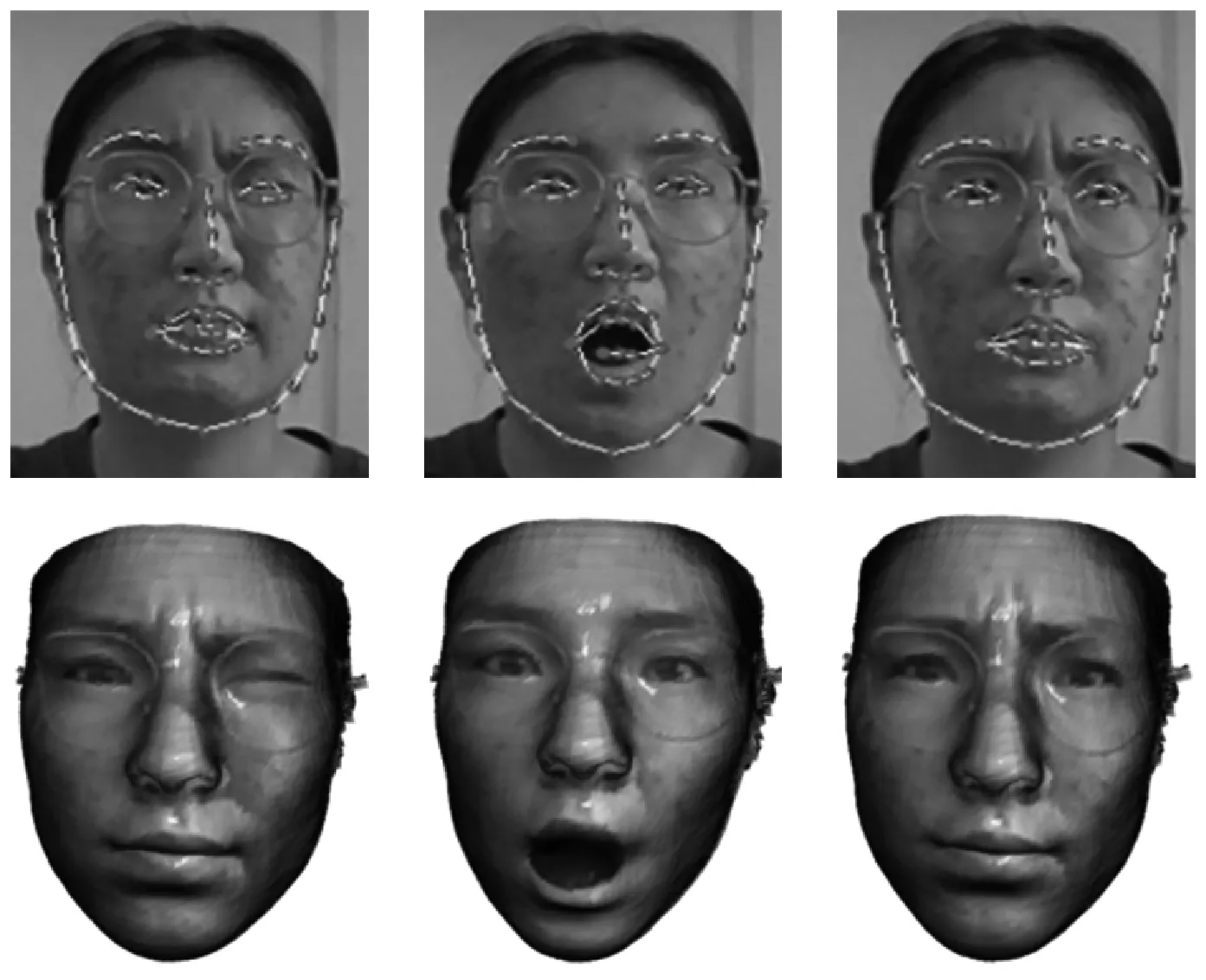
假设输入图像的尺寸为c*hin*win,c、hin、win分别表示输入图像的通道数、高度和宽度,普通卷积操作和主卷积操作的卷积核的尺寸均为k*k,线性操作的平均核尺寸为d*d,最终得到的特征图尺寸为n*hout*wout,n、hout、wout分别表示输出特征图的通道数、高度和宽度。当主卷积中卷积核的个数为m,线性操作的个数为s(s=n/m且s FConv=n*hout*wout*c*k*k, (2) FOrdi=m*hout*wout*c*k*k, (3) FLine=(s-1)*hout*wout*d*d, (4) (5) 仿照残差网络,将两个Ghost模块进行堆叠,可以得到步长为1和2两种结构,如图3所示。本文算法就是使用了这两种结构层。在Ghost瓶颈层中,对每个Ghost模块的输出进行一次批量归一化处理(batch normalization,BN),并在第一个Ghost模块后增加一个ReLU激活函数,此外,在步长为2的瓶颈层中,还在两个Ghost模块之间添加了一个深度卷积层,将该层的输出进行批量归一化处理后,再传递给第二个Ghost模块。 图3 瓶颈层Figure 3 Bottlencek layer 图4 UV位置图回归网络Figure 4 UV position map regression network 由于UV位置图回归网络是将RGB图像回归成位置图,因此PRNet使用了编码器-解码器结构。本文仍保留了这种结构,如图4所示。在编码器部分,先设置了两个普通卷积层对图像进行初步的特征提取,将其映射为256*256*16的特征图,再通过9个Ghost瓶颈层将该特征图映射为8*8*512的特征图。解码器部分是14个转置卷积层,最终将8*8*512的特征图映射为256*256*3的UV位置图。 根据FACS,人类面部有42块肌肉,不同的脸部肌肉运动产生了不同表情。通过参考FACS中对人脸区域的划分,并观察人脸产生表情时的肌肉运动及皮肤变化,可以得到眼睛与嘴是人脸表情变化最丰富的区域。因此,本文对人脸进行了新的区域划分,并设计了新的人脸分区权重。 1) 将人脸的68个关键点作为一个区域,并设置最高权重。 2) 将眼睛(包含眉毛)与嘴划分为一个区域,并设置次高权重。 3) 将眉毛以上的额头部分(包含印堂)、鼻子、嘴巴周围划分为一个区域,并设置中等权重。 4) 将人脸上除去上述区域的部分划分为一个区域,并设置一般权重。 此外,由于每帧图像可能含有非人脸区域,比如脖子、衣服、背景等,该部分不需要表情克隆,所以将图像上除去人脸区域的剩余区域划分为一个区域,并设置权重为零。本方法最终的人脸区域划分结果如图5所示。 图5 人脸分区与对应人脸区域Figure 5 Face partition and corresponding face region 通常的回归任务会采用L2损失函数,但在进行人脸关键点检测时,经常会处理一些极端姿态,这些姿态最初的检测误差可能非常大,而L2损失函数对这类异常值又很敏感,当某个点的预测值与真实值误差较大时,整个损失将由这个点所“主导”,不利于网络的训练。Wing Loss损失函数结合了分段函数和对数函数。对数函数的梯度是1/x,优化步长是x2,当误差接近0时,它的梯度逐渐增大,优化步长的变化较小,而当误差较大时,它的梯度较小,优化步长受误差的影响则更为明显。Wing Loss损失函数里具有正偏移的对数函数可以防止小误差点的过度补偿,避免在错误的方向上进行大的更新,可以兼顾大、小误差。因此,本文在网络训练时选择了Wing Loss损失函数,所用公式为 (6) (7) 其中:x表示真实的UV位置图与预测的UV位置图之间的顶点三维坐标误差;wing(x)表示损失;ω是一个正数,将该损失函数的非线性部分限制在[-ω,ω]之间;ε为约束非线性区域的曲率;C用来连接分段函数的线性部分和非线性部分。 将Wing Loss损失函数与人脸分区权重结合,最终整个网络的损失函数为 (8) 其中:Xm为真实的UV位置图中的一个顶点;P(Xm)表示该顶点在真实的UV位置图中的三维坐标(x,y,z);P*(Xm)表示该顶点在预测的UV位置图中的三维坐标(x*,y*,z*);wing(P(Xm)-P*(Xm))表示Wing Loss损失;W(Xm)表示该顶点的权重;M是UV位置图上的顶点数量。 结合以上各部分,本文的整体网络如图6所示。网络的输入为一段视频,也可以由摄像头直接捕获。由于在进行人脸表情克隆时,一般情况下演示视频中人脸的区域比较小,而且表情克隆与人物背景基本无关,所以需要确定人脸在背景中的位置并提取出来。因此先对视频的每一帧图像进行人脸检测,将检测器返回的第一张人脸作为表情克隆的目标人脸。根据检测结果确定图像上人脸所在位置,设置裁剪出的新图像大小为256*256,通过相似变换将原人脸图像变换裁剪成网络所需要的256*256*3大小的人脸图像。将变换裁剪好的每帧人脸检测结果输入改进后的轻量级位置图回归网络,得到该帧图像对应的UV位置图,并根据UV位置图上每一个点的RGB值,得到图像上每一个关键点的三维位置信息。最后,利用三维数据处理库Open3D中的三角网格数据结构TriangleMesh更新三维人脸模型上每一个顶点的三维坐标,再利用Visualization控件将网格模型进行可视化,完成人脸表情克隆。 图6 整体网络Figure 6 Overall network 本文实验使用300W-LP数据集进行训练,使用AFLW2000-3D数据集和COFW-68数据集进行测试。 300W-LP数据集包含了大量标注了3DMM系数的大角度人脸图像,AFLW2000-3D数据集包含了AFLW数据集中的前2 000张头像及三维信息。COFW-68数据集是COFW数据集的重新标注版本,测试集中共507张同时包含姿态和表情变化的人脸图像。 在进行网络训练时,由于300W-LP数据集不含真实的UV位置图,因此,需要对数据集进行处理。将每张图像按标注的人脸区域进行裁剪,并缩放到256*256大小,然后利用标注的3DMM参数生成相应的三维位置,并将其渲染到UV空间,获得尺寸也是256*256的真实UV位置图。此外,还对训练数据进行了数据增强处理,对每张图像进行了旋转角度分别为±15°、±30°、±45°、±60°的旋转,增加了网络对于大角度人脸的适用性。 实验采用的评价指标是标准化平均误差(normalized mean error,NME),该指标数值越小表示性能越优,计算公式为 (9) (10) 其中:dbbox表示人脸边界框大小;wbbox和hbbox分别表示人脸边界的宽和高。在用COFW-68数据集进行测试时,标准化参数为两眼外眼角间距离。 本实验主要采用的硬件是NVIDIA GeForce GTX 1650 GPU和Intel(R)Core(TM)i7-9750H CPU@2.60 GHz。 网络使用TensorFlow的深度学习框架,编程语言为Python3.6。训练时ω设置为10,ε设置为2。训练批次大小设置为4。采用Adam优化器,初始学习率设置为0.000 3,每5个周期后衰减为原学习率的0.9倍。 人脸分区权重设置为: 68个关键点∶眼睛和嘴部区域∶额头、鼻子及嘴部周围区域∶脸部其他区域∶图像其他区域=4∶3∶2∶1∶0。 3.3.1消融实验 为了验证本文提出的人脸分区的有效性,在公开的AFLW2000-3D数据集上对预测的68个稀疏人脸关键点准确度进行了消融实验,测试结果见表1。表中的PRN+MSE模型为PRNet使用均方差损失函数训练的模型,PRN+Wing模型为PRNet使用Wing Loss损失函数训练的模型,GBN+Wing模型为本文提出的网络使用Wing Loss损失函数训练的模型,这三种模型在训练时均采用了PRNet提出的人脸分区及权重,而最后一个GBN+Wing+New模型采用了本文提出的人脸分区及权重。表中第2~4列分别表示在小(0°~30°)、中(30°~60°)、大(60°~90°)偏航角下的NME,最佳结果加粗显示,在后文表中也是如此。根据表1可以看出,在训练时使用Wing Loss损失函数和新的人脸分区及权重设计是有效的。 3.3.2人脸关键点检测 为了验证本文提出的算法在人脸表情克隆时的准确性,首先在公开的AFLW2000-3D数据集上对预测的68个稀疏人脸关键点准确度与其他几种先进的算法进行了对比,表2表示二维关键点检测的对比结果,表3表示三维关键点检测的对比结果。可以看出,本文方法无论是在二维还是三维关键点检测上,都表现优异。具体来说,在二维关键点检测上,本文方法在小、中、大偏航角下的NME值及平均NME结果较表中次佳方法分别提高了11.35%、9.65%、20.6%和11.44%,在三维关键点检测上,本文方法在小、中、大偏航角下的NME值及平均NME结果较PRNet分别提高了34.5%、34.42%、32.53%和33.95%。 表1 不同模型在AFLW2000-3D 数据集上的对比结果Table 1 Comparison results of different models on AFLW2000-3D dataset 表2 不同方法在AFLW2000-3D数据集上的二维关键点检测对比结果Table 2 Comparison of 2D landmarks detection results of different methods on AFLW2000-3D dataset 表3 不同方法在AFLW2000-3D数据集上的三维关键点检测对比结果Table 3 Comparison of 3D landmarks detection results of different methods on AFLW2000-3D dataset 图7表示不同方法在AFLW2000-3D数据集上68个人脸关键点的二维坐标和三维坐标的累计误差分布,可以看出,本文方法在预测人脸关键点的二维和三维坐标上,明显优于3DDFA[15]和PRNet[8]。 图7 AFLW2000-3D数据集上的累计误差分布Figure 7 Cumulative error distribution on AFLW2000-3D dataset 为了验证本文提出的算法在人脸存在遮挡的情况下仍具有较高的检测水平,在COFW-68数据集上与其他几种算法对68个稀疏人脸关键点的二维坐标检测结果进行了对比实验,对比结果见表4。COFW-68数据集不仅包含大量由于头部旋转带来的自遮挡人脸图像,还包含由于墨镜、帽子等物品带来的人脸遮挡图像,这两种情况的存在导致图像中的有效人脸区域更小,增大了人脸关键点检测的难度,使基于图像的人脸关键点检测更具有挑战性。图8表示在COFW-68数据集上68个人脸关键点的二维坐标累计误差分布,可以看出,本文提出的算法尽管没有重点关注由于物品遮挡人脸的情况,但仍有不错的检测结果。 3.3.3视频人脸表情克隆 为了体现本文方法能够很好地完成视频人脸表情克隆任务,对不同算法的网络进行了模型运行时间的对比,并将最佳和次佳结果进行加粗显示,对比结果见表5,运行环境表示模型在运行时系统使用的GPU版本。由于部分运行时间来自文献,所以模型运行的GPU版本不同,但对比结果仍具有重要意义。可以看出,本文提出的模型运行时间为19.6 ms,一秒钟可以处理51张图像,满足了实时性的要求。 表4 不同方法在COFW-68数据集上的对比结果Table 4 Comparison results of different methods on COFW-68 dataset 图8 COFW-68数据集上的累计误差分布Figure 8 Cumulative error distribution on COFW-68 dataset 表5 模型运行时间对比结果Table 5 Comparison results of model running time 图9表示具体的视频人脸表情克隆结果。图中第一行表示实时视频中的演示者头部区域截图,标注的点及连线表示模型预测的68个人脸关键点的位置,第二行表示对应的克隆出的人脸表情。根据克隆结果可以看出,本文方法克隆的表情具有较高的真实性,对于皱眉、眨眼等细节都能很好地生成。总体上看,本文方法不仅能够完成人脸表情克隆的任务,还具有较高的实时性。 图9 表情克隆结果Figure 9 Expression cloning results 针对视频三维人脸表情克隆的实时性差与准确率低的问题,本文提出了一种基于UV位置图的视频人脸表情克隆方法。该方法使用Ghost瓶颈层构建轻量级网络,将每帧人脸图像回归为对应的UV位置图,结合新的人脸分区与权重设计使网络能够更加关注人脸变化更丰富的区域。再根据位置图提取人脸关键点三维坐标,驱动三维人脸模型产生变形,完成人脸表情克隆。最后,在AFLW2000-3D数据集和COFW-68数据集上进行了二维和三维的人脸关键点检测精度对比实验,还对不同的方法进行了模型运行时间的对比,实验结果充分体现了本文方法的优越性和有效性。
2.2 人脸分区设计

2.3 损失函数
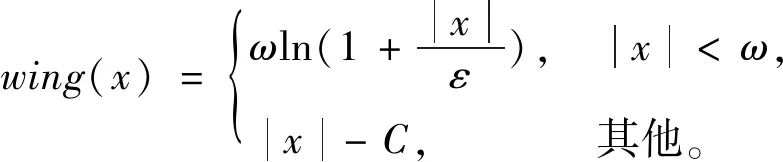
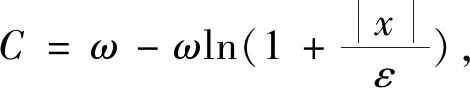
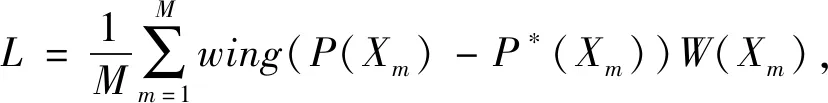
2.4 整体网络
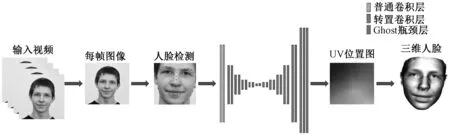
3 实验结果与分析
3.1 实验数据与评价指标
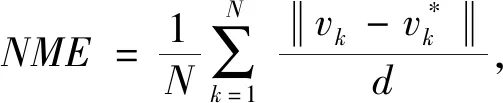
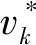
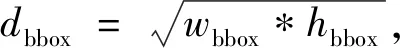
3.2 实验设置
3.3 实验结果分析

4 结束语
