F-CAD:一种基于CAD的快速持久化协议
2023-01-09刘靖宇李浩鹏牛秋霞武优西
刘靖宇,李浩鹏,牛秋霞,武优西
(河北工业大学 人工智能与数据科学学院 天津 300401)
0 引言
在大型分布式系统中,通常使用复制的方式来提高容错,然而,在并发操作的情况下,跨不同集群或遥远地理位置的数据中心维护一致的副本是一项复杂的任务。因此提出一致性协议来保证各个节点数据的一致性,例如Paxos[1]、Raft[2]等。
近年来,一致性协议取得了大量研究成果,如线性一致性[3]、最终一致性、因果一致性[4]、存在一致性[5]、可扩展的因果一致性[6]等,但现有协议在应对跨客户端单调读问题时,均难以给出一个高效的解决方案[7],在跨客户端读取数据时容易暴露陈旧的数据和读取。
研究发现实现跨客户端单调读的一个主要前提条件是数据持久化:同步持久化[8]和异步持久化[9]。同步持久化的额外限制虽然可以满足跨客户端单调读,但速度很慢,而异步持久化虽然具备高性能,但无法满足严格的单调性。
Ganesan等[10]基于异步持久化提出的一致性感知持久性(consistency aware durability,CAD)协议在读时强制数据持久化。但由于CAD需要超过半数节点,持久化写入全量数据才能读取新写入的数据,并且只能从已经持久化的节点读取数据,导致对于迫切想要读取最新写入的数据时,每次均需要一个持久化等待时间,并且可读节点相对较少。
针对以上问题,本文提出了F-CAD(fast CAD),一种可以快速持久化的一致性协议。F-CAD将纠删码和CAD结合,使得集群中F+k个节点仅需持久化写入全量数据的1/k个片段即可实现跨客端单调读,并保证和CAD相同的Liveness。此时节点存储唯一数据,如果用户当前仅希望读取某一数据片段,便会频繁访问对应数据节点,从而导致单节点负载过高。后续会通过增设一张索引表来解决数据节点负载过高的问题。
F-CAD的工作主要总结为三点:1) 高效结合纠删码快速持久化;2) 增设索引表针对数据节点做负载均衡;3) 保证索引表中数据的实时性。
1 相关工作
一致性协议可以提供高度可靠和可用的分布式服务,其中的持久化模型是确保用户单调读的关键因素。虽然少有专门针对持久化模型的研究,但它是一致性协议研究的重要部分,在已经提出的很多协议中均包含对持久化问题的研究。
实现强一致性需要同步持久化,例如文献[1]提出的线性一致性是分布式系统可以提供的最强保证。这种很强的一致性在实际生产中有着诸多应用,如LogCabin系统会引导程序同步复制到多数节点,并且将对应节点数据落盘。不过其缺点也很明显,研究表明在大型分布式系统中,完全异步配置要比同步多数复制和持久化的Redis快10倍[10]。
同步持久化对于实现单调读是必要的,不过单纯的同步持久化并不足以实现严格的单调性,还需要额外的机制。如文献[2]为了实现单调性,将读取限制到Leader节点,但是这样的限制严重影响了读吞吐量,并且它还阻止客户端从最近的副本读取数据,增加了读取延迟。
通常系统无法忍受同步持久化的低性能,特别是在实际生产中,因而很多人选择了异步持久化[11]。而一些较弱的一致性协议虽然具备高性能但无法做到严格的单调性,特别是在故障发生的时候[12]。Zab协议是一个工业级的实现,通过异步的方式进行复制和持久化实现了高性能,但复制过程中可能会丢失数据,导致较差的一致性[13]。
CAD一致性协议是由Ganesan等提出同时兼顾高性能和单调性的解决方案。CAD选择用异步写的高性能,在读时强制数据持久化,写时按Raft异步思想写入,读时会判断该写请求要访问的数据是否可以被用户读取,也就是该写入是否至少被F+1[13]个节点持久化写入,并且通过租约机制[14]创造一个有效集来对读请求做限制,持久化写入该数据的节点才能加入有效集,用户仅能对有效集中的节点进行读操作。
CAD协议中数据可读的前提条件是该数据是否已经被持久化写入至少F+1个节点。如果用户恰好要读取新写入的数据,此时系统需要频繁等待大多数节点全量数据持久化写入。特别是近年来,Raft和Paxos被应用于etcd、TiKV和FSS等真正的大型系统中,已用于复制TB级的用户数据,数据量的庞大使得用户等待时间显著增加[15]。在较坏的情况下,如果用户恰好频繁读取新写入的数据,此时CAD应对热读时性能和同步持久化类似,容易导致系统阻塞,甚至瘫痪。
2 F-CAD快速实现持久化
CAD一致性协议每次写入均需要等待持久化完成,从而导致CAD应对热读时性能较差,根本原因在于:1) 节点性能不统一,物理跨度较大,网络延迟等因素;2) 单节点单次必须持久化写入全量数据,并且需要保证持久化写入到至少F+1个节点,当单次写入的数据量较大时,性能缺陷愈加明显。本文针对第二点进行改进,通过减少单次写入的数据量进行优化。
2.1 F-CAD 结合纠删码
在已知的数据冗余方案中纠删码可以有效降低存储和网络成本[16],并保证高可靠性,如Reed-Solomon(RS)码[17]。RS码将数据切分为大小相等的k个片段,并通过编码计算得到m个奇偶校验片段,(k+m)个片段中任意k个都足以恢复原始数据。本文将使用RS码结合一致性协议[18],其参数k和m服从k+m=N=2F+1。
一致性协议通常具备Safety和Liveness两种特性[19],Safety表示:在非拜占庭[20]条件下,系统不会返回非正确的结果。Livenesss表示:只要大多数服务器都是活跃的,并且可以相互通信,也可以与客户端通信,它们就可以正常工作,则称这组服务器为健康服务器。诸如Raft和Paxos的Liveness是F,可以容忍F个节点的故障,而纠删码容忍m个节点的故障,但是经常存在m
|QW∪QR|=|QW|+|QR|-|QW∩QR|。
常见的将纠删码结合一致性协议的方式是通过增加交集大小,使得|QW∩QR|≥k,这样写操作的确认写入需由F+1变为F+k,才能保证F+1的Liveness,因为至少需要F+k个节点确定写入,即QW=F+k,而QW和QR的交集至少为k,根据包含-排斥原则得|QW∪QR|=|(F+k)∪QR|≥F+k,所以|QW|+|QR|-|QW∩QR|=F+k+|QR|-k=F+|QR|≥F+k,此时F+|QR|≥F+k,令QW=F+1,则N≥F+k必定成立,所以可以保证F+1的Liveness。
当写请求到达Leader节点后,如果当前集群中至少有F+k个节点可以互相通信,Leader收到至少F+k-1个确认请求,纠删码机制会先将该日志条目进行分片(日志索引不做分片),分为k个数据片段和m个校验片段,且k+m=N,其中每个片段均包含日志索引,然后再将这k+m个片段分别写入全部节点。当Leader节点收到至少F+k-1个确认写入且k个数据片段已经全部持久化写入,便允许读取该写入。如此写入的数据量由原来的F+1减少到(F+k)/k,大大减少了达到单调可读条件的数据写入量。
这里需要注意的一点是,如当前集群中互相通信节点数大于F,但小于F+k,则为了保证F级别的Liveness,选择按原CAD协议复制写入,保证了集群的可靠性。
接下来通过一个实例来说明F-CAD如何通过结合纠删码快速单调可读。如图1所示,图中是一个7节点集群,使用(3,4)-RS码。初始用户发出一个写请求a,如果Leader节点收到至少F+k-1个确认,纠删码机制会将a分为3个数据片段和4个校验片段,再分别将这7个片段持久化写入到对应的节点。Leader节点会选择性能较优的S1、S2、S3节点写入数据片段,其余节点写入校验片段,等待S1、S2、S3和其余任意三个节点持久化(颜色加深表示持久化完成)写入后便可以达到单调可读条件,此时需写入的数据量由原来的4减少为2,减少了50%。
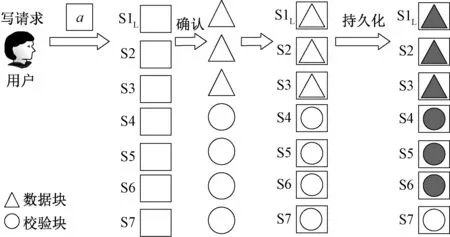
图1 CAD结合纠删码复制方案结构图Figure 1 CAD combined with erasure coding
但此时会暴露一个问题,因为数据片段唯一地存储于数据节点,如果此时多个用户恰好要热读的数据仅存在于S2节点,则很容易造成S2节点负载过高甚至故障,接下来将就这一问题给出一个解决方案。
2.2 F-CAD负载均衡方案
通常在分布式系统中解决单节点负载过高最有效的方案是负载均衡。但是传统的负载均衡是根据全局负载进行分流以达到均衡的效果[21],而CAD需要针对数据节点而非全部节点,如此性能才能得到最大提升。
本文方法是通过增设一个索引表来改变后续写入规则,Leader节点通过查询表中字段来判断具体该如何写入。索引表通过key-value的方式存储,其中key具有唯一性,value可为任意类型数据结构。表中key为Per字段,表示该节点性能,对于当前主流的分布式存储,如HDFS、Ceph等负载均衡时均会基于当前各个节点的CPU、内存、网络、地理位置等因素得到一个确切的值,这里我们调用原系统负载均衡接口得到这个值来作为当前节点的Per字段,并且依据key值对索引表进行排序。Value为其余字段,使用双向链表进行存储,分别为:Node字段,节点名;Log字段,该日志条目索引;Frag_S字段:片段信息,该片段在全量数据中的位置。
如图2所示,索引表已经按Per字段顺序排列,Leader节点可以直接通过指针访问表中数据。图中S5节点为性能最优节点,S1次之,……,如果多用户恰好读取数据片段2,会大大增加S2节点的故障概率,所以此时性能最优节点S5写入数据片段2,如此用户便可以通过读取节点5也可以读到数据片段2,然后由于S6节点为次差节点,但是由于S6节点是校验片段,所以S1节点不写入S6节点片段,为了防止空操作,S1节点顺序写入数据片段1。同理S3节点也不写入S7节点片段,而写入数据片段1。后续会进行数据补全操作,即S5、S1、S3、S4节点写入尚未写入的其余数据片段。
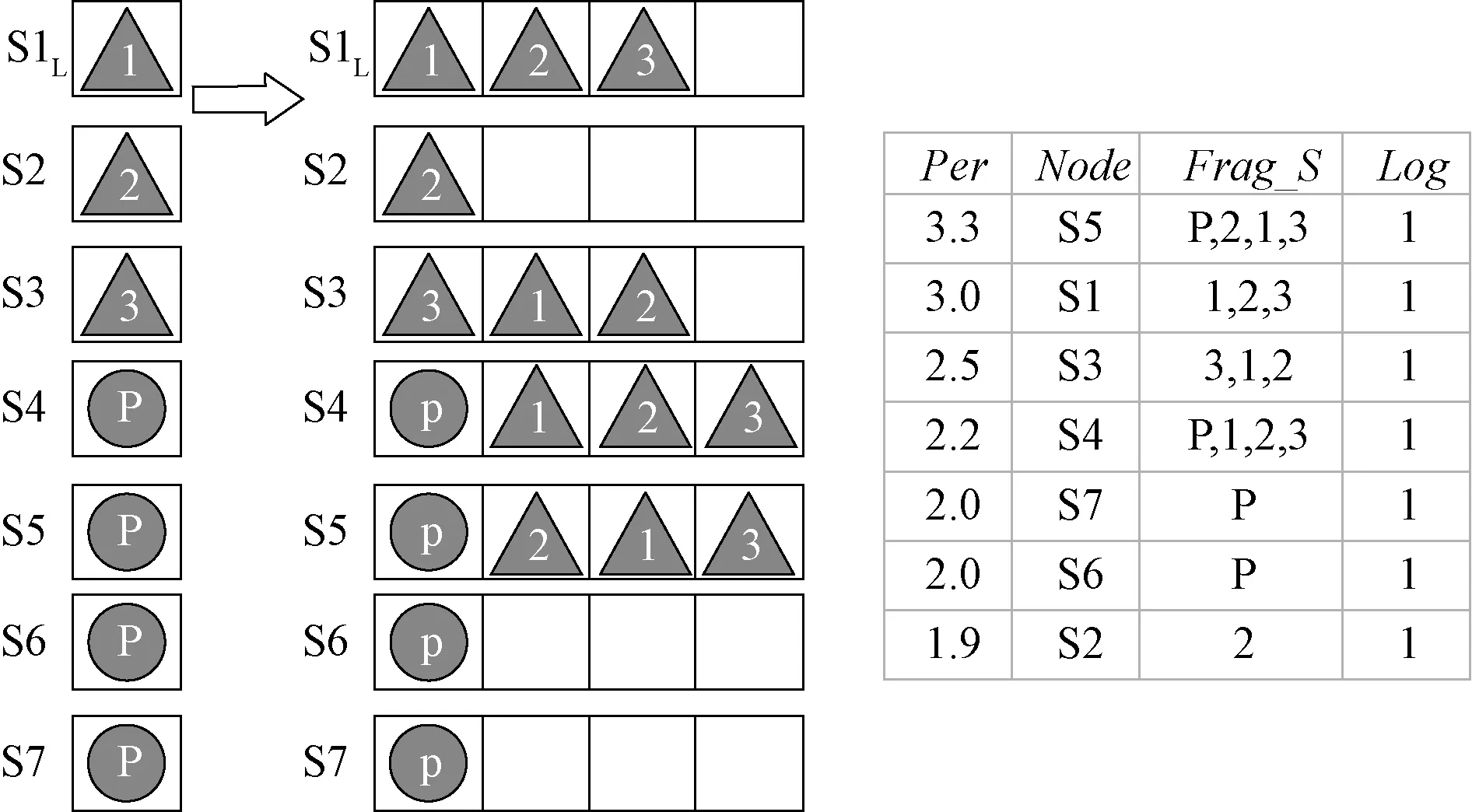
图2 负载均衡方案结构图Figure 2 Load balancing scheme
此时全量数据已经持久化写入到至少F+1个节点,系统可以提交该日志条目继续进行写入,用户也可以通过多个节点进行数据的读取,同时也有效地避免了单节点负载过高问题,达到了均衡效果,不过原来的CAD协议通过一轮远程过程调用(remote procedure call,RPC)即可实现持久化,在本一致性中需要多轮,因此在达到单调可读条件后可以选择一次请求包含多个数据块,如此两轮RPC便可以完成一次日志条目的复制。当数据量较大时,相较于数据写入量的减少,两轮RPC的耗费是可以容忍的。
F-CAD负载均衡的核心是实时维护分流索引表。当节点数目较少时,可以通过一些简单的数据结构和排序算法来实现基于Per字段的实时排序,但是在真实的分布式系统中节点数目往往超过了上万个,很难做到实时性,接下来就该问题给出一个高效的解决方案。
2.3 实时维护分流索引表
当节点数据较大时,需要实现对key、value存储的同时还要对key值排序。我们选择红黑树作为底层数据结构,因为无论是查找、插入还是排序,红黑树都有着很高的性能表现。我们使用CPP STL标准库中的map容器来实现,map底层是一棵红黑树,每一个唯一的key值对应一个value值,正好对应索引表的key-value结构。并且每次插入均会按自定义进行排序。
基于map的特性,将Per字段作为key值存储,但由于key唯一的特性,会出现key重复时value被覆盖的情况,如果为新节点,对应节点将无法加入索引表。因此如果重复则先判断Node字段是否一致,如果不一致则说明为新节点,新key默认最小单位自增,然后加入索引表中。value存储未交付日志条目信息(已经提交的日志条目直接按CAD写入规则进行存储、查询),由于需要频繁地插入和删除操作,这里选择使用插入和删除性能较高的双向链表list。List中第一个结点为Node字段,后续每组数据包含Log字段和Frag_S信息,为了方便区分,需要将Log字段做特殊标记。之所以会出现多组数据,是由于在达到持久化条件后便可以执行下轮复制。
因为Per字段需要实时更新,如果每轮RPC Leader节点依次去检测其余节点的Per字段是否改变,明显开销过大。因此,在本文协议中,Follower节点会定时主动判断自身Per字段是否发生变化,如果改变,会返回给Leader节点一个旧的Per值、一个新的Per值和对应的Node节点,根据旧的Per值,可以很快确定其在map中的位置,并找到value值,更新map。
如算法1所示,Leader节点通过定义一个二维数组Per_alter,存储Follower节点发来的旧Per值、新Per值和Node字段,map为索引表。Per_alter非空时需要先用一个临时数组Per_tmp存储Per_alter,然后置空Per_alter,如此便可以快速加入工作线程Project_runing中接收Follower节点发来的更新,操作Per_alter数组时需要对线程Project_runing加锁,防止拷贝给临时数组到置空的过程中有新的Follower节点发来信息导致丢失信息。接下来就是循环判断,新节点加入索引表,旧节点更新索引表中字段。
2.4 F-CAD节流方案
当达到图2所示的复制效果后,会继续对尚未写入全量数据的节点继续进行数据补全并且删除校验片段,但是如此先前写入的校验片段便是多余的写入,并且由于全量数据写入到F+1个节点,已经很大程度上实现了均衡和高性能,因此系统推荐用户用部分节点全量复制的方式以节省开支。通过定义一个整数参数x(0≤x≤F),以供用户在节能和高性能之间进行选择,用户可以选择F+x+1个节点全量复制,较小的x代表较小的写入资源和存储资源,但是也意味着较少的节点供用户可读,反之较大的x则代表用户在读取数据时表现出更高的性能。
算法1实时维护分流日志表
输入:Per_alter,map
#define min_double 0.01;
if(Per_alter.size() == 0)
break;
else{
∥工作线程加锁
Project_runing.mutex.lock();
vector
∥置空Per_alter
vector
if(Per_alter.size() == 0)
∥Per_alter置空后调用回调释放锁,开始检测Per字段的改变
基层医疗机构因发展空间、薪酬待遇、地理环境等特点难以吸引医学毕业生从事基层医疗工作,相关研究表明,只有五分之一的医学生愿意从事基层医疗[22]。关于免费医学生职业发展、专业认同影响因素也逐渐被研究者重视。有研究表明,生命意义感对免费医学生专业承诺存在影响[23],也有观点认为“从事基层医疗工作者工资高”、“不履约者记录诚信档案”对免费医学生留任基层医疗工作存在影响[24],也有教育者通过开设职业生涯规划课程,帮助免费医学生设计适宜的职业发展目标,对提升免费医学生专业认同取得较好的干预效果[25]。但目前这方面的研究还较为匮乏,未来还需进一步加强。
Project_runing.mutex.unlock();
for(int i = 0;i {∥通过迭代器寻找key对应的下标 auto it = map.find(Per_tmp[i]); ∥没有找到对应的key if(it == map.end()){∥开辟临时空间li暂存map索引表value值 list li.push_back(Per_tmp[i][2]); continue; } ∥找到了对应的key while(map.find(Per_tmp[i][0])!=map.end()) {∥防止重复的key Per_tmp[i][0] += min_double; } map[Per_tmp[i][0]] = it.second; } } 实验基于ebay的NuRaft一致性协议进行改进,本实验通过一台物理主机搭建了多个虚拟平台,物理主机的CPU为12核,内存为16 GB,硬盘为1 TB SSD。虚拟平台采用Ubuntu 14.04.6系统,CPU为2核、1GB内存,纠删码库为Jerasure 2.0。 为了体现加入纠删码之后的优缺点,分别在N=5、N=7的配置下进行了实验,当N=5时,使用(2,3)-RS码;当N=7时,使用(3,4)-RS码。 通过实验分别对比在不同节点个数下,同步持久化(sync)、CAD、F-CAD协议在达到单调可读条件时的写入延迟,由于异步持久化(async)无法满足严格的单调性,所以本实验无需对异步持久化进行对比。 图3和图4分别显示了N=5、N=7下不同写入负载大小对应的写入延迟。可以看到当单次写入负载小于2 kB时,3种协议延迟类似,此时延迟主要由磁盘I/O控制,由于写入的数据量太小,即使F-CAD可以节省刷新到磁盘的数据量,但由于F-CAD会增加I/O操作,所以三个协议在延迟上没有太大的区别。当单次写入负载变大时,可以看到F-CAD有明显的优势。此时网络流量和磁盘I/O都会影响延迟,由于F-CAD可以极大地节省网络成本和磁盘I/O,当N=5时,随着写入负载的增大,减少写入延迟增大,当负载为8 kB时有明显的区别,64 kB时与sync相比可减少47%的写入延迟,与CAD相比可减少33%的写入延迟,平均减少约35%的写入延迟。当N=7时,负载为64 kB时与sync相比可减少54%的写入延迟,与CAD相比可减少45%的写入延迟,平均可以减少约40%的写入延迟。 图3 5节点下不同一致性协议的写入延迟对比Figure 3 Five nodes write delay comparison 图4 7节点下不同一致性协议的写入延迟对比Figure 4 Seven nodes write delay comparison 通过写入延迟的对比可以看到,在5节点和7节点下延迟相差并不大,并且7节点时性能更优。因此图5仅对比7节点下3种协议的吞吐量。随着读写负载的增大,吞吐量先增加,达到峰值,然后下降,之所以会下降是达到阈值时由于网络拥塞造成的,属于不可避免的情况。可以看到当读写负载小于4 kB时,三种协议基本一致,此时系统写入的数据量太小,性能上无明显区别。当读写负载为64 kB时,sync和CAD率先达到峰值,而F-CAD还在继续上升,在512 kB时达到峰值,这是由于F-CAD方案单个节点所需写入的数据量相较于CAD和sync减少了近60%。总体而言,F-CAD较CAD和sync吞吐量提升了近120%。 图5 7节点下不同一致性协议吞吐量对比Figure 5 Throughput comparison of seven nodes F-CAD之所以能够快速持久化,最根本的原因是F-CAD与CAD相比,所达到持久化条件需要写入的数据量大大减少,接下来就达到持久化条件时不同节点数所需写入的数据量进行对比,此处设置N的值分别为5、7、9、…、21,其中:N=5时使用(2,3)-RS code;N=7使用(3,4)-RS code;…;N=21时纠删码为(10,11)-RS code。 单个节点达到持久化需要写入的数据量对比如图6所示,CAD和sync所需写入的数据量相同,由于CAD并未对单个节点做写入限制,仅在读取时进行限制以达到单调读的效果。从图中可以看到F-CAD单个节点所需写入的数据量明显要少于sync和CAD,并且随着节点数的增加,这一优点愈加明显,对于单个节点而言,所需写入的数据量变为原来的1/k,随着N的增大,纠删码预设的k值也需增大,所以所需写入的数据量逐渐减少。最后趋于稳定,减少90%,由于F+k确认节点的前置条件使得k不宜过大,因此会趋于稳定。 图6 单个节点所需写入的数据量对比Figure 6 The amount of data to be written to a single node 全部节点所需写入数据量对比如图7所示(预设x=0),以sync为基准进行对比。从图中可以看到CAD和F-CAD所需写入的数据量比sync有明显减少。随着节点个数的增加,CAD所需写入的数据量略有减少,而F-CAD所需的数据量有明显的减少,最后趋于稳定,约减少80%。因为CAD写入所需的数据量为F+1,而F-CAD所需写入的数据量为(F+k)/k,当k=F,F+1/((F+k)/k)=(F+1)/2,可以看到随着F的增大,F-CAD相较于CAD可以很大程度上减少总体数据写入量。 图7 总体写入数据量对比Figure 7 The total amount of data written F-CAD是针对CAD热读缺陷的改进,通过结合纠删码的方式减少热读所需的数据量,总体数据写入量减少为N/k,单个节点的数据写入量减少为1/k,从而达到快速持久化的效果。由于加入纠删码会增加单节点故障的概率,针对这一问题,提出一个高效的负载均衡方案。同时通过用户预设的x值减少了数据的总体写入量,可以减少(F+1+x+(F-x)N/k)/N的数据写入量,大量节省了网络和存储资源,并且随着节点个数的增加优势会愈加明显。 F-CAD虽然有效解决了CAD热读缺陷的问题。但是,由于结合纠删码,Leader节点写入所需确认节点数由F变为F+k,使得当前需要互相通信的节点数目增加,并且加入纠删码也会使得整体写入流程变得相对烦琐,未来将在这两方面进行改进。3 实验与结果分析
3.1 实验平台
3.2 实验结果



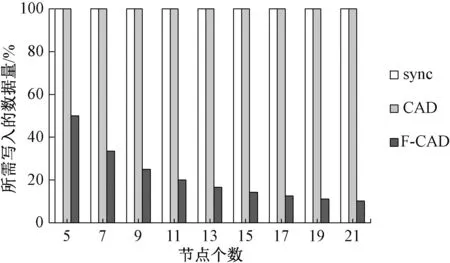

4 结论
