Sub-Regional Infrared-Visible Image Fusion Using Multi-Scale Transformation
2023-01-07YexinLiuBenXuMengmengZhangWeiLiRanTao
Yexin Liu, Ben Xu, Mengmeng Zhang, Wei Li, Ran Tao
Abstract: Infrared-visible image fusion plays an important role in multi-source data fusion, which has the advantage of integrating useful information from multi-source sensors. However, there are still challenges in target enhancement and visual improvement. To deal with these problems, a subregional infrared-visible image fusion method (SRF) is proposed. First, morphology and threshold segmentation is applied to extract targets interested in infrared images. Second, the infrared background is reconstructed based on extracted targets and the visible image. Finally, target and background regions are fused using a multi-scale transform. Experimental results are obtained using public data for comparison and evaluation, which demonstrate that the proposed SRF has potential benefits over other methods.
Keywords: image fusion; infrared image; visible image; multi-scale transform
1 Introduction
Due to the limitation of technical means, image obtained by a single-source sensor meets some specific application needs, but it can not adapt to the more complex environment and more widely used scenes [1]. In practical application, multisource information is integrated, which includes clear target and background, sufficient semantic information, wide application range, and more in line with human vision and machine recognition,and avoids redundant information and loss caused by using multiple imaging sensors.
In the military, aviation, and other fields,infrared sensors with visible sensors are used to monitor the same scene to obtain multi-source data. As shown in Fig. 1, on the one hand, visible images provide rich texture and color details,with high spatial resolution and clarity consistent with the human visual system. On the other hand, because of the characteristics of wavelength and thermal imaging, infrared images have a good imaging advantage in the case of insufficient light at night, fog, and so on, and there is high contrast between target and background,ignoring the influence of weather, light, and environment [2-4]. It is necessary to combine this complementary information through image fusion, and the fused image not only has good visual quality and texture details consistent with the visible image, but also the salient target.This is very important for the follow-up tasks,such as video surveillance, scene understanding,target detection, and recognition.
Clear, bright, prominent, and well-defined prospects (targets) are necessary for good fusion,and they are also core needs and concerns. In existing methods, there is a lack of obvious boundary and light-dark contrast, which makes it difficult to distinguish the target from the surrounding background. Generally speaking,infrared image is the main carrier of this information. Relatively, in most scenes, the target in visible image does not have this property. In addition, the advantage of infrared image over visible image lies in that some regions which are different from the surrounding background (light and dark change steeply or gradually) are well displayed (such as cars, clouds, etc.). It is hoped that these elements are well preserved in the final fusion image. Excellent image quality is also a shortage to existing methods, which means that,in addition to the requirements of pattern recognition for machines, images friendly to human vision, such as images with good clarity and color recognition, are also advantages of an image. The proposed method is based on these considerations and designed to improve these problems.
Contributions of the proposed sub-regional infrared-visible fusion (SRF) method include: 1)According to the characteristics of thermal imaging, a more reasonable target area extraction method is designed. 2) The reconstruction of the infrared background ensures better visualization.3) In most other fusion algorithms, image processing is not local, which means that target and background regions use the same fusion strategy,lack of pertinence. SRF improves this deficiency.4) Fusion strategies are designed that makes the target prominent and more conducive to visual perception, as well as helpful for subsequent target-specific visual tasks.
The rest of this paper is organized as follows.Section 2 introduces related works and skills of this paper. In Section 3, we describe the proposed approach in detail. Section 4 makes a comprehensive evaluation, including qualitative and quantitative comparison, as well as other evaluations. Section 5 includes discussion and conclusion.
2 Related Works
2.1 Existing Methods
In recent years, many algorithms including traditional methods and deep learning methods, have been proposed for infrared-visible image fusion and achieved good results [5]. Typical traditional methods are based on multi-scale transformation[6-11], sparse representation [12-16], subspace[17, 18] and saliency [19-22]. Deep learning methods are based on convolutional neural network[23-28]. These algorithms have achieved results,but at the same time, there are still some problems. First, noise in the image easily interferes with the fusion, especially the noise in infrared image is retained in the final fused image, even be magnified and enhanced. Second, There is no difference between target and background areas in fusion strategies, which leads to suppression of their own unique information, that is, clear background of visible image and prominent target of infrared image. Finally, there is usually a lack of consideration for the subsequent application,especially targets that need detection and tracking, because for many visual tasks, targets are often the regions of interest.
2.2 Morphology and Top-Hat Transformation
Morphology (or mathematical morphology) is used in image processing to extract, express, and describe useful image components in the shape of the region, that is, to extract connotation from the image [29]. Structural element (SE) is a basic concept in morphology, which is used to study the small set or sub-image of the content we are interested in. In gray-level morphology, if the origin of structure elementbis at (x,y), the erosion and dilation of structure elementbto imagefat(x,y)is as follows
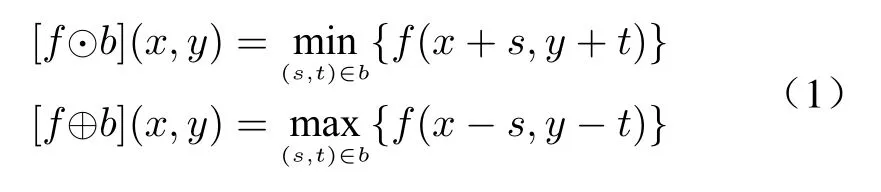
where⊙represents the erosion operation,⊕represents the dilation operation,sandtare coordinates inb. Furthermore, the opening operation and top-hat transformation of the imagefby the structural elementbare expressed as follows

where◦represents the opening operation, which is used to compensate for the uneven background brightness. After using a structural element to do the opening operation, the top-hat transformation is defined as subtracting the opening operation from the original image to get the image with balanced background. In practical application, top-hat transform is often used to correct the influence of uneven illumination.
2.3 Image Fusion Based on Multi-Scale Transformation(MST)
Multi-scale transformation (MST) is based on the theory of multi-resolution analysis, which was first proposed by S. Mallat [30]. If the size of objects is small and the contrast is low, they are usually studied with higher resolution. On the contrary, rough observation is enough.

Fig. 2 Schematic illustration of decomposition and reconstruction in MST
Image pyramid [31] is a structure that represents images with multiple resolutions. The approximate pyramid is based on the original high-resolution image, and the resolution gradually decreases from bottom to top. Series of images obtained by approximate pyramid are lossy compared with the original image. To reconstruct the original image, a prediction residual pyramid is introduced. By approximating the pyramid and predicting the residual pyramid, an image is decomposed and reconstructed without losing information. In the approximate pyramid,because these images are low-resolution approximate versions of the original image, they are regarded as base layers, that is, the low-frequency information, which contains the backbone and frame. Accordingly, the prediction residual pyramid contains detail layers, that is,the high-frequency information, including the texture, edge, and noise.
Image fusion based on MST relies on extracting the basic layer and detail layer, integrating them through different fusion strategies,and finally reconstructing the fused image. The basic framework is shown in Fig. 2. There are two key points in MST: decomposition-reconstruction method and fusion rule. Chen et al.used Gaussian-Laplacian pyramid to decompose and reconstruct the image and fused the base layer with a low-pass filter and the detail layer with absolute-max rule [32]. Bavirisetti et al.used a mean filter to decompose and reconstruct and fused the base layer with average strategy and the detail layer with a saliency method [19].In addition, the decomposition and reconstruction of MST are not limited to pyramid method,but also other transforms. For example, Naidu et al. used multi-resolution singular value decomposition to realize image decomposition and reconstruction [33].
3 Methodology
The overall architecture is shown in Fig. 3, which is divided into three modules in chronological order: infrared target extraction, infrared background reconstruction, and sub-regional fusion.First, the infrared target is extracted by the designed module. Second, the infrared background is reconstructed by the original two images and the infrared target. Finally, prefusion infrared images and visible images are fused in a sub-regional way.
3.1 Infrared Target Extraction
According to the principle of infrared image thermal radiation imaging, the area with high brightness is the target and the area with low brightness is the background. Classic OSTU threshold segmentation [34], or maximum inter-class variance method is usually used for binary segmentation, it assumes that the image is composed of foreground region and background region.Through traversing and calculating the gray histogram of foreground region and background region in segmentation results under different thresholds, variance between two regions is calculated, the pixel value which maximizes variance is the thresholdT

Fig. 3 Overall architecture of the proposed sub-regional infrared-visible fusion (SRF), including infrared target extraction, infrared background reconstruction, and sub-regional fusion

whereω0andω1indicate the percentage of pixels smaller and larger thanT,µ0andµ0indicate their average gray level.
To prevent possible noise of global processing, an improved OSTU of local adaptive is used.Use a horizontal sliding window of 21 columns,sliding pixel by pixel from left to right. For the pixels within the window, the local variance is calculated. If the variance is greater than the threshold, use the OTSU algorithm to calculate the local threshold within the window and binarize the pixels within that window; if the variance is less than the threshold, set all pixels within that window to zero.
For example, the first image in Fig. 4 shows the original infrared image. The target is pedestrian, and it is also the area with the highest pixel value. However, in global threshold segmentation and binarization, it is easy to be interfered with by regions with second-highest pixel value, such as background of doors and houses,which also have high pixel values, but not targets interested in (the second image in Fig. 4).At this time, the problem is improved by using the top-hat transform to strengthen target and expand the difference between target and background before the global threshold segmentation(the third image in Fig. 4). The changes in histograms and thresholds of the two can be known from Fig. 5.

Fig. 4 Comparison of segmentation of infrared images with or without top-hat transform: (a) infrared image; (b)infrared image segmented directly by OSTU threshold;(c) infrared image segmented by OSTU threshold after top-hat transform

Fig. 5 Comparison of histograms and thresholds: (a) with tophat transform; (b) without top-hat transform
At the same time, the image is not binarized, but regions below the threshold are set to 0, while regions above the threshold value are retained. that is:

wheref*(x,y) andf(x,y) are the pixel values off*andfat (x,y),Tis the threshold of imagefcalculated by OSTU, andf*is the image after processing. Even in the target regions of infrared image, there are still some texture details.
3.2 Infrared Background Reconstruction
In the previous step, target regions in infrared image have been obtained. According to the idea of infrared-visible image fusion, this is the information hoped in infrared images. However, it is not appropriate to discard the background part of infrared image directly, because the rest also contains other structural information. This information is not included in visible image to suppress background noise and other redundant information in infrared image.
As shown in Fig. 6, visible image is used to help smooth and filter infrared background noise.Through observation, it is found that bright spots in visible image are generally background,so the background part is estimated by their difference. Then, the difference component is subtracted by infrared characteristics to further enhance the contrast between target and background. Finally, in order to prevent the overexposure of the results, the pre-fused infrared image is obtained by multiplying the suppression ratioα

where the suffix (x,y) represents the pixel value of the image at coordinates (x,y), ir and vis are original infrared and visible images, respectively,and the residual imageris obtained by the difference operation, irTis infrared image that retains pixels above the threshold through tophat transformation and threshold segmentation,and then pre-fused infrared image irPis obtained by difference operation and multiplying the suppression ratio. By doing this, target region is brighter and more prominent than background compared with original image, and background region is smoother and less noisy compared with original image, and suppression ratioαis adjusted artificially.

Fig. 6 Framework of infrared background reconstruction
3.3 Sub-Regional Fusion
The framework of sub-regional fusion is shown in Fig. 7, it is divided into two parts, including subregional image processing and target region fusion based on MST. First, the threshold segmentation in infrared target extraction is further used and the target region of infrared image is binarized to generate the matrix mask for subregional image processing. Second, MST is used in the target region, because the pixel value of the main target region is high and the brightness is large, and the detail texture needs to be more effectively preserved.
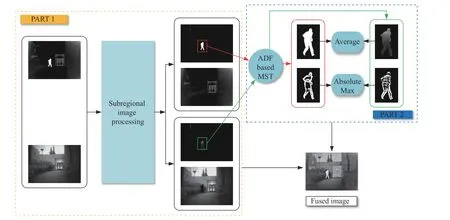
Fig. 7 Framework of the designed sub-regional fusion, including sub-regional image processing and ADF-based MST
Because infrared and visible images have been registered, the target region is applicable to all images. Matrix mask is used to separate target and background. The target region is retained and the background region is set to zero when extracting the target, that is, multiply by the mask matrix mask; the target region is set to zero and the background region is retained when extracting the background, that is, multiply by the mask matrix 1 -mask.
In the proposed method, MST is based on anisotropic diffusion filtering (ADF) [35]. It overcomes the shortcomings of isotropic diffusion filtering, which can not retain the edge information. As a contrast, anisotropic diffusion filtering uses a partial differential equation (PDE) to smooth the homogeneous region (non-edge) while maintaining the non-homogeneous region (edge).It uses inter-region smoothing to smooth the image and retains sharp details at edges.
In general, the anisotropic diffusion equation uses the conductivity coefficient to control the diffusion of input imageI, which is expressed as
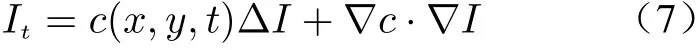
wherec(x,y,t) is the conductivity coefficient,tis the number of iterations. Δ is the Laplace operator and∇is the gradient operator. The concept of thermodynamic field is introduced as follows:The whole image is regarded as a heat field, and each pixel is regarded as a heat flux. The iterative solution of the partial differential equation is
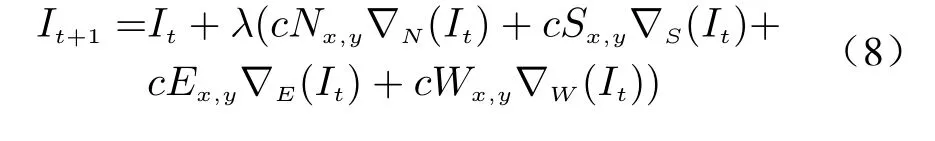
whereIt+1andItare the images of thet-th and(t+1)-th iterations,λis a stability constant and satisfy 0≤λ ≤1/4 ,∇N,∇S,∇E,∇Ware the nearest domain differences of the images in the North, South, East and West directions. They are defined as follows
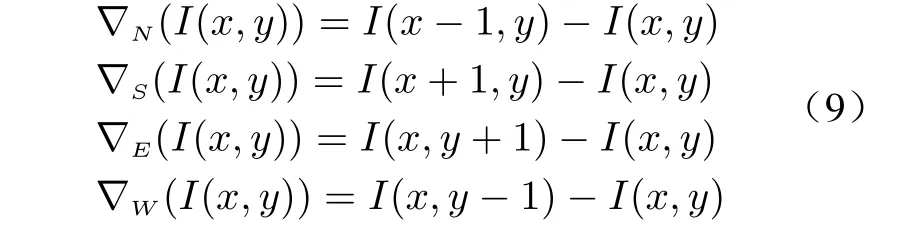
wherecNx,y,cSx,y,cEx,yandcWx,yare the conductivity coefficients in four directions, which are defined as
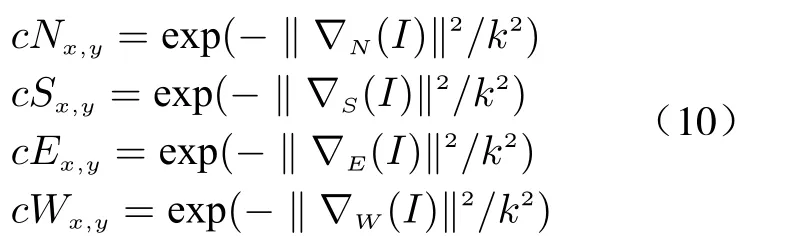
wherekis the thermal conductivity.
Anisotropic diffusion filtering is a balance between region smoothing and boundary preserving. In anisotropic diffusion filtering, there are three coefficients:t,k, andλ, which are set artificially.tis the number of iterations, which is set according to the actual demand;kis the thermal conductivity, and the larger the value is, the better the image smoothing effect is; andλis the stability coefficient, the larger the value is, the better the image smoothing effect is.
The original image is decomposed into two layers, the low-resolution approximation is the low-frequency information of the image, it is set as the base layer, the residual as the high-frequency information of the image, it is set as the detail layer of the image. Letfbecome ad(f)through the anisotropic diffusion filter, that is,
wherefbis the base layer andfdis the detail layer. The base layer image is a smooth version of the original image, which represents the main body of the image. According to the property of anisotropic diffusion filtering, that is, the region
where the pixel value changes gently. The detail layer image is the area where the pixel value changes dramatically, which constitutes the contour and noise of each element in the image. For the base layer, the average strategy is employed
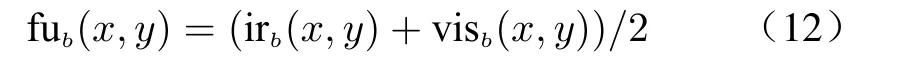
where the suffix (x,y) represents the pixel value of the image at coordinates (x,y). irband visbare the base layers of infrared and visible images,and the average result is taken as the base layer fubof the fused image. For the detail layer, the absolute max strategy is used
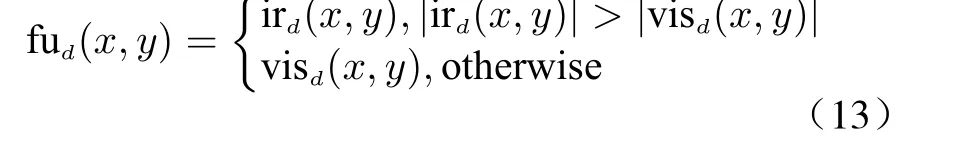
where irdand v isdare the detail layers of infrared and visible images, and fudis the detail layer of fused image. As a result, In target region, fused image fu can be reconstructed by adding fuband fud.
Finally, average strategy is used in other regions, and fused image fu is expressed as
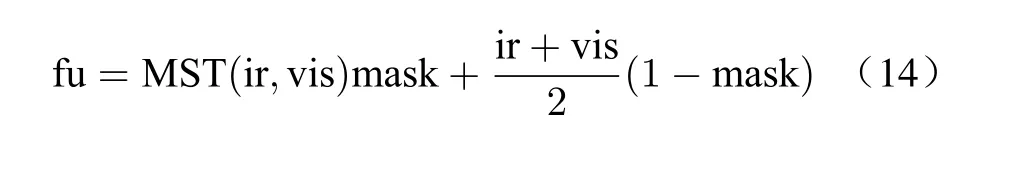
4 Experiments and Analysis
4.1 Experimental Data and Environment

MSS dataset (https://www.mi.t.u-tokyo.ac.jp/static/projects/mil_multispectral) and TNO dataset (https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029) are appropriate datasets for infrared-visible image fusion for both of them contain thermal images and RGB images, which have been registered already.The size of images in MSS dataset is 640×480,and the size of TNO dataset is abhorrent. Furthermore, we select 2 representative sets for visualization display.
The operating system is Windows 10, CPU is Intel Xeon E3-1 225 v6, algorithm platform is Matlab R2018a and Python 3.7.
4.2 Experimental Parameters
According to Bavirisetti [36], the optimal parameter settings for anisotropic diffusion filtering aret= 10,k= 30,λ= 0.15. The performance of the fusion varies with suppression ratioα, soαwere set 0.50,0.75, and 1.00 to find the best condition.
4.3 Experimental Results and Analysis
Four metrics are used to quantitatively evaluate the performances of different fusion methods:average gradient (AG) [37], edge intensity (EI)[38], QCV [39] and spatial frequency (SF) [40](Tab. 1).
AG is calculated without a reference to the image and the higher the value, the more details and the higher the image quality. For image g with the size ofM×N, average gradientGis defined as
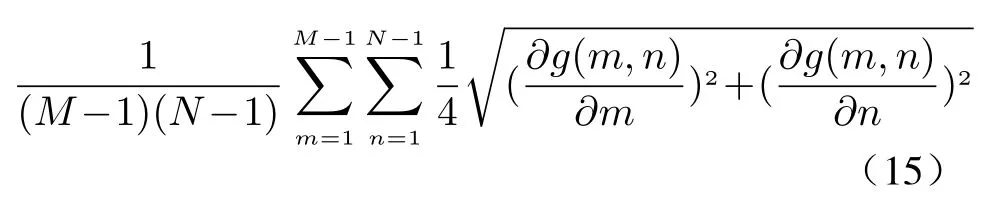
where (m,n) denotes coordinate of the image,∂g(m)/∂mand∂g(n)/∂nare horizontal and vertical gradient.
EI uses Sobel operator to estimate the edge of the image without a reference to the image,the higher the value, the more edges of the fused image are preserved. If imagefis measured by Sobel operatorS, edge intensity EI is defined as


Tab. 1 Average values of 4 metrics through Ablation methods
where fused image isg(x,y) and size isM×N.
Since one of the main contributions is to adopt sub-regional method to deal with different fusion regions, which is a local fusion way. Therefore, we design two ablation experiments. First,one uses the global fusion way and MST fusion strategy based on anisotropic diffusion filtering,which is recorded as experiment 1. Then another uses the global fusion way and the pixel addition fusion strategy, which is recorded as experiment 2. In contrast, SRF uses local fusion way and employs the two fusion strategies above.
The proposed SRF is compared with 5 fusion methods including convolutional neural network(CNN) [23], DenseFuse [24], generative adversarial network(FuseGAN) [41], gradient transfer fusion (GTF) [42], infrared feature extraction and visual information preservation (IFEVIP) [43].
Experiments on time cost was conducted. As we can see from Tab. 2, SRF saves cost because it does not require training, and on the other hand, the time cost is lower compared to traditional methods.
As listed in Tal. 3, Tab. 4, Tab. 5, and Tab. 6,the proposed SRF(α=0.75) achieves better results than other methods. This confirms three facts: SRF has achieved success in targetenhancement, its infrared background reconstruction has played a role in noise suppression, and it has achieved good time efficiency. SRF ranked first in no-reference image assessment AG and EI, these two metrics mainly focus on edges of the image. SRF also ranked first in SF and second QCV, this means good image quality and similarity with original images.
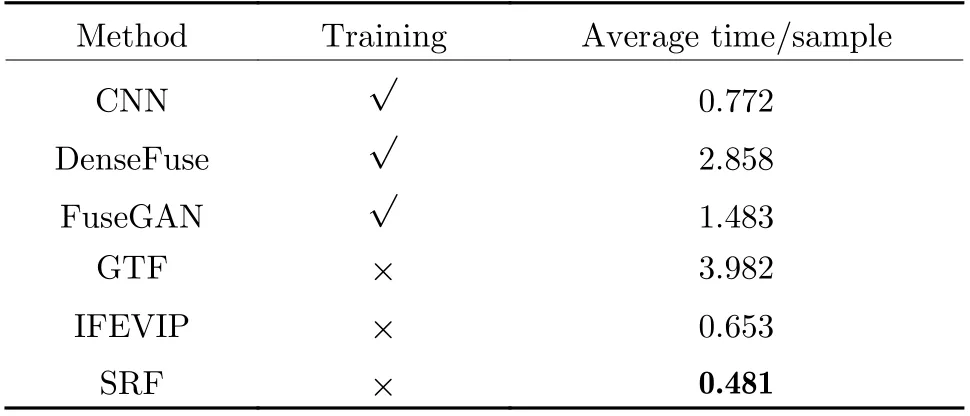
Tab. 2 Average running time of 6 methods

Tab. 3 Values of AG through different methods in MSS and TNO datasets
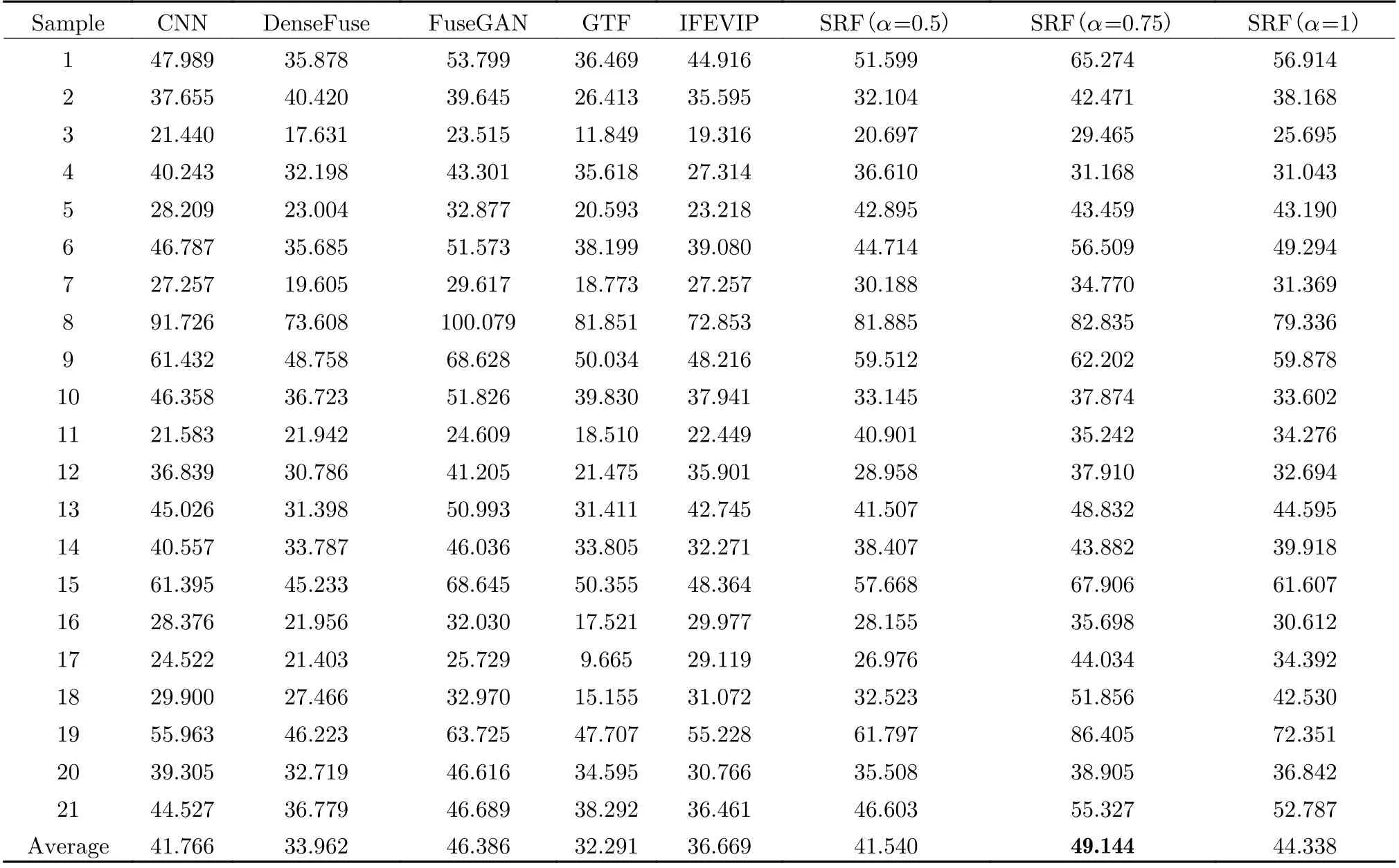
Tab. 4 Values of EI through different methods in MSS and TNO datasets
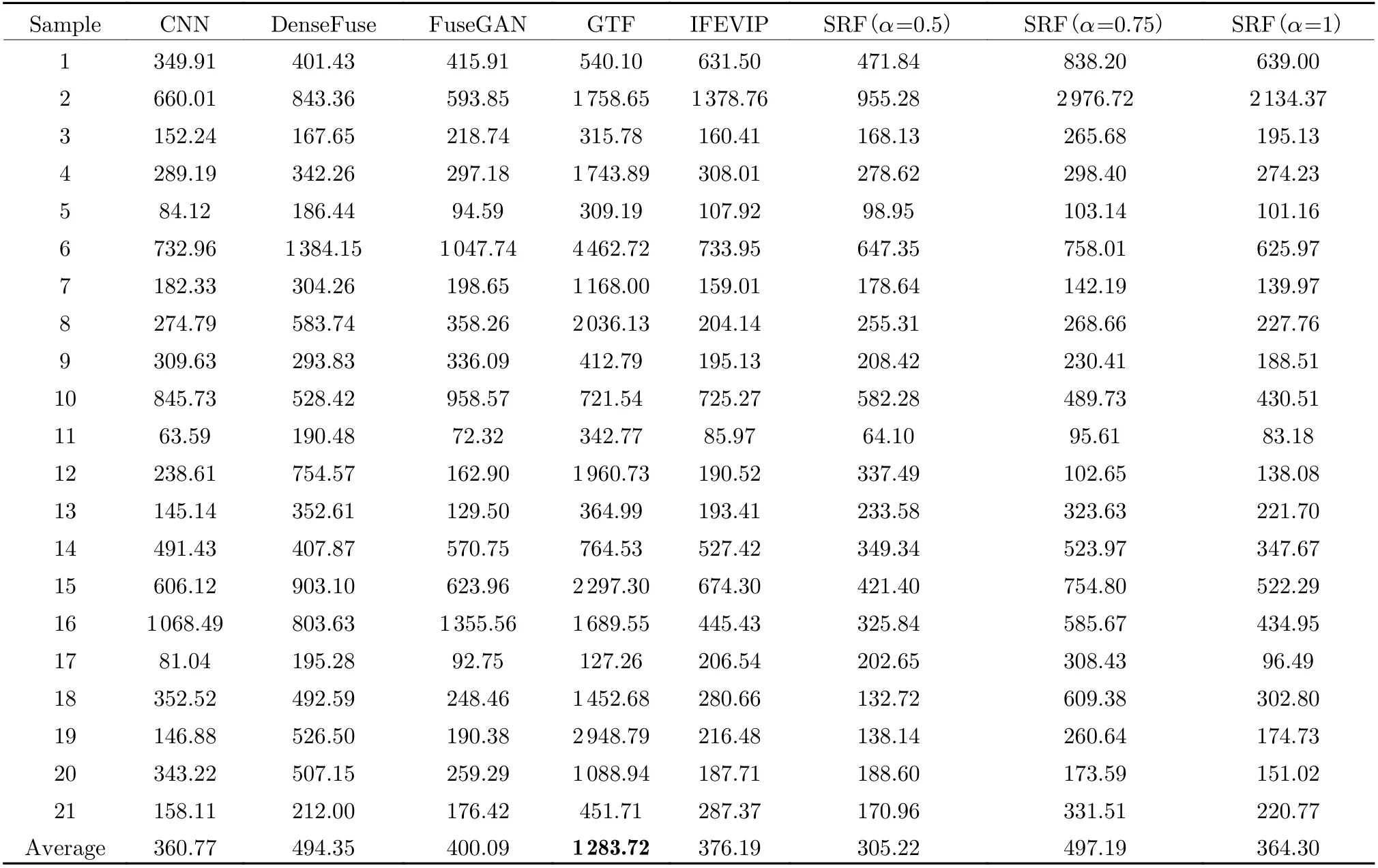
Tab. 5 Values of QCV through different methods in MSS and TNO datasets
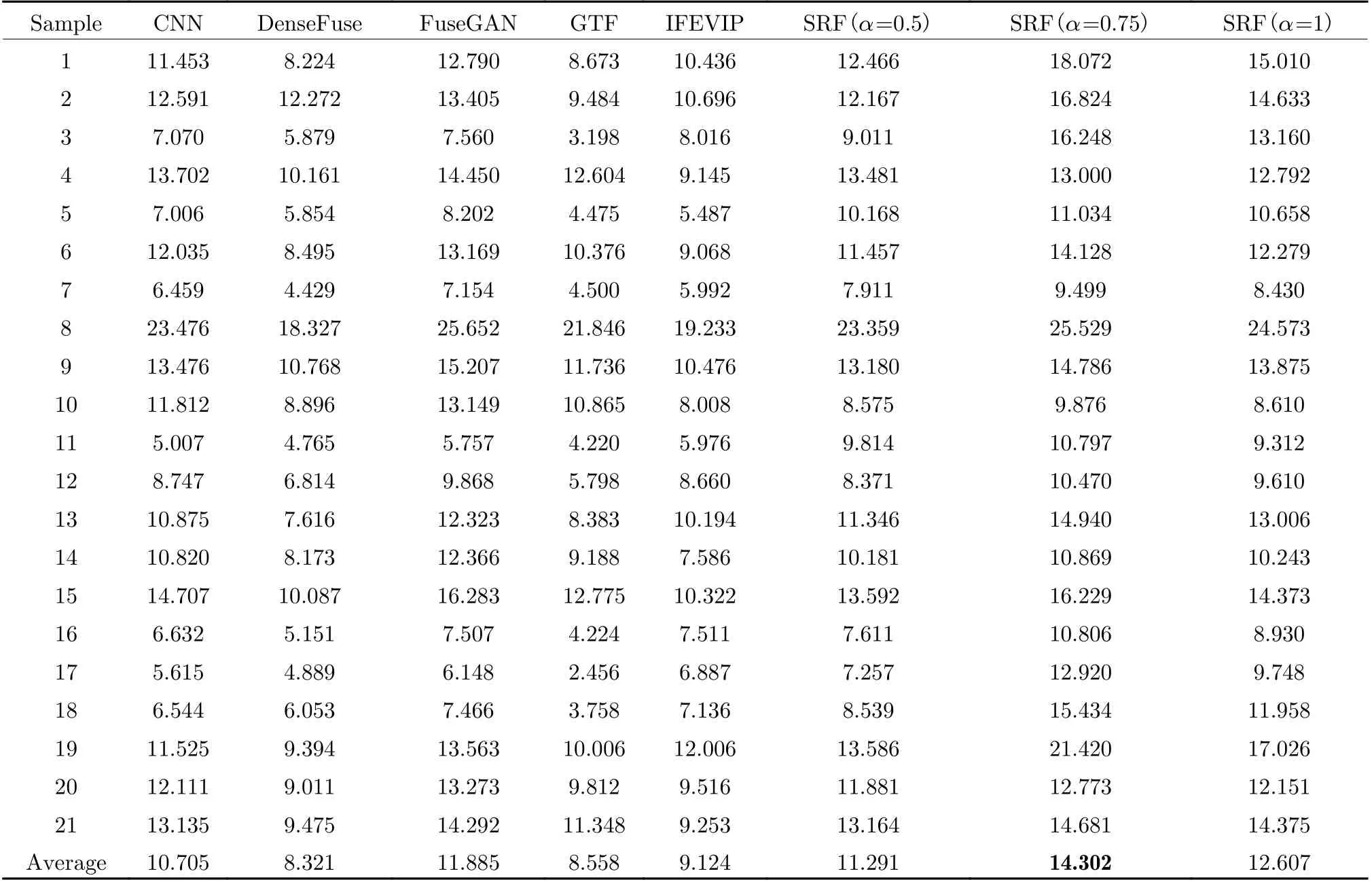
Tab. 6 Values of SF through different methods in MSS and TNO datasets

Fig. 8 Visualization results: (a)infrared; (b)visible; (c)CNN; (d)DenseFuse; (e)FuseGAN; (f)GTF; (g)IFEVIP; (h)SRF( α=0.5);(i)SRF( α=0.75); (j)SRF( α=1)
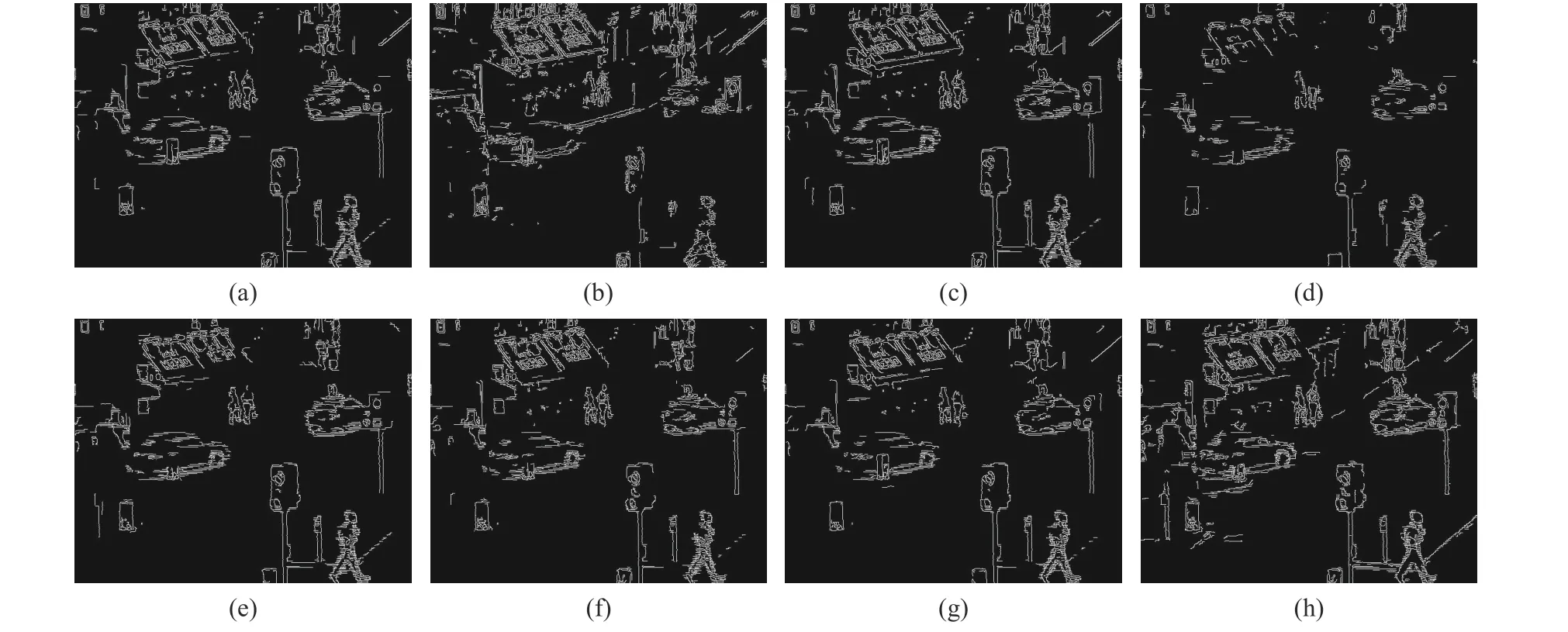
Fig. 9 Canny operator edge detection: (a)CNN; (b)DenseFuse; (c)FuseGAN; (d)GTF; (e)IFEVIP; (f)SRF( α=0.5);(g)SRF( α=0.75); (h)SRF( α=1)

Fig. 10 Visualization results: (a)infrared; (b)visible; (c)CNN; (d)DenseFuse; (e)FuseGAN; (f)GTF; (g)IFEVIP; (h)SRF( α=0.5);(i)SRF( α=0.75); (j)SRF( α=1)
As is shown in Figs. 8-11, two groups of representative data are selected to observe the visualization. At the same time, it also shows Canny operator edge detection. In the first set, the main observed target is the walking pedestrian, compared with other methods, the target of SRF fusion result is more prominent and has higher contrast with the environment. In the second set,the main observed thing is the texture details of clouds. These texture details are more prominent in SRF than those in other methods. It is considered to be target aware, at the same time,other parts also maintain good results. In both Canny operator edge detections, SRF shows the most lines, which shows the best effect on detection.
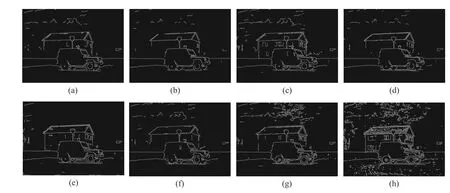
Fig. 11 Canny operator edge detection: (a)CNN; (b)DenseFuse; (c)FuseGAN; (d)GTF; (e)IFEVIP; (f)SRF( α=0.5)(g)SRF( α=0.75); (h)SRF( α=1)
5 Conclusion
In this paper, a novel method, i.e., SRF, has been proposed for infrared-visible image fusion. An infrared target extraction module is designed based on the top-hat transform, and the background of infrared image is reconstructed. For the fusion of target regions and other regions, a sub-regional strategy with multi-scale transformation is developed. Experimental results have demonstrated that the proposed SRF is effective to enhance targets and improve image quality,and is effective in the subsequent detection and tracking tasks. As a future plan, both deep learning and traditional methods will be taken advantage of to give full play to their respective superiorities.
杂志排行

Journal of Beijing Institute of Technology的其它文章
- Distributed Privacy-Preserving Fusion Estimation Using Homomorphic Encryption
- Adaptive Sampling for Near Space Hypersonic Gliding Target Tracking
- Distributed Radar Target Tracking with Low Communication Cost
- Power Plant Indicator Light Detection System Based on Improved YOLOv5
- Airborne GNSS-Receiver Threat Detection in No-Fading Environments
- Model Predictive Control Based Defensive Guidance Law in Three-Body Engagement