基于代价敏感的中文文本的情感-原因对提取研究*
2023-01-06胡朝晖潘伟民张海军韩连金
胡朝晖 潘伟民 张海军 韩连金
(新疆师范大学计算机科学技术学院 乌鲁木齐 830054)
1 引言
随着商品评论信息的增多,大量的评论信息参杂一起,在这些杂乱的评论中提取好评和差评有利于商家对商品更加全面的把握,挖掘出差评情感的原因,帮助卖家完善产品也具有重要意义。提取出差评和差评的原因就是情感-原因对提取,即ECPE(Emotion-Cause Pair Extraction)[1]。
但是在情感-原因对提取任务中因其数据集存在标签不平衡问题,故引入代价敏感的损失函数来减小标签不平衡问题带来的困扰。在前人的研究中,加入BERT在预训练模型中取得了较好的表现,本文采用哈工大讯飞联合发布中文BERT-wwm[2]。采用中文BERT-wwm是因为中文BERT-wwm选用的是中文语料库而且模型是基于中文分词训练,而谷歌发布的全词覆盖的BERT[3]模型的研究测试集中于国外公开数据集,缺乏一种中文语言的相关模型,且基于全词覆盖的BERT预训练模型,可能忽略了中文分词的作用[4]。
综上所述,本文提出代价敏感情感-原因对模型(Emotion-Cause Pair Extraction-BERT-wwm,ECPE-BW)。该模型运用基于代价敏感的损失函数和加入中文BERT-wwm的方法,通过实验得出在F1结果上有接近1%的提升。
2 相关工作
在前人的研究中有研究者通过一个模型直接提取出情感-原因对,也有研究者采用先提取出情感和原因句,再将情感和原因句配对的方法,所以本文将研究主要分为两类,一类是间接提取,另一类是直接提取。
在间接提取研究中,Xia等[1]提出ECPE模型,运用了ECPE模型和句子对过滤算法两步得到情感-原因对。Tang等[5]提出ED+ECPE联合模型,联合多层注意力机制提取情感-原因对。Dai等[6]提出EDGCNN模型,运用情感膨胀门控CNN提取提取情感-原因对。在间接提取中存在着上一步结果如有误将影响下一步,就会间接影响提取情感-原因对的精确度,所以直接提取的模型也应用而生。
在直接提取研究中,Fan等[7]提出基于转换的模型,将任务转换成一个类似分析有向图构建过程,从而直接提取出情感-原因对。Wu等[8]提出MTNECP模型,一种将位置感知情感信息加入原因提取的方法中用于情感-原因对提取的多任务学习神经网络。Wei等[9]提出对句子间的关系进行建模,一步提取情感-原因对。Song等[10]提出通过学习链接,从情感子句链接到原因子句的方法来端到端 的 提 取 情 感-原 因 对。Ding等[11]提 出 了ECPE-2D模型,利用二维矩阵表示情感-原因对,将二维、交互、预测集成到一个联合框架中一步提取情感-原因对。间接和直接提取研究中,存在着数据标签不平衡,考虑到这一问题,本文加入代价敏感的损失函数减少标签不平衡问题带来的影响,同时运用中文BERT-wwm模型进行预训练。
3 算法
本文基于代价敏感的损失函数,同时引入中文BERT-wwm。该模型输入层经过中文BERT-wwm预训练到达中间层,中间层是两个独立提取情感子句和原因子句的模型,提取出的特定句子和预测句子放在一张二维表中,经过加入代价敏感损失函数计算输出预测的情感-原因对。
3.1 模型结构
本文模型是利用二维矩阵表示情感-原因对,将二维,交互,预测集成到一个联合框架中。该框架输入层经过中文BERT-wwm预训练到达中间层,中间层是两个独立的组件,句子经过两个组件分别得到特定情感子句和特定原因子句,接着经过softmax函数分别得到预测的情感子句和原因子句。最后将特定情感子句、预测情感子句作为列与特定原因子句、预测原因子句作为行结合在同一张二维矩阵中,经过配对计算抽取出预测的情感-原因对。结构如图1所示。

图1 ECPE-BW模型图
3.2 针对代价敏感性问题的损失函数改进
在本实验数据集上,数据的分布存在标签不平衡问题,文中包含1个情感-原因对有89.77%,而包含超过2个情感-原因对只有1.13%。前人的研究取得了一定的成果,但数据集标签不平衡问题对实验结果会产生一定的影响。为了解决数据集标签不平衡问题,本文引入代价敏感的损失函数[12]。
下面的公式是Ding等定义的情感-原因对分类的损失函数:

考虑到ECPE-BW模型用的Softmax函数的输出且情感-原因对属于二分类,本文采用代价敏感的交叉熵损失二分类函数,上述公式可以重新写成:

为了获得更好的情感特定性表示和原因特定性表示,引入了辅助的情感预测和原因预测损失,其中和表示句子Ci特定的情感和原因。

最后模型的损失函数是在L2正则化下Lpair和Laux的权重之和,其中θ表示这个模型中所有的参数,λ1,λ2,λ3∈(0,1)。
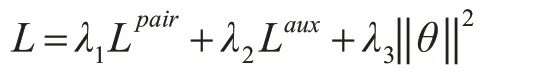
3.3 中文BERT-wwm模型
应用中文BERT-wwm模型作为本文预训练模型。由于谷歌官方发布的BERT中,中文是以字为粒度进行切分,没有考虑中文需要分词的特点。中文BERT-wwm模型考虑到中文分词的重要性,采用全词Mask法[2]。全词Mask是如果一个完整的词的部分WordPiece被[MASK]替换,则同属该词的其他部分也会被[MASK]替换[13]。表1是原始BERT的Mask和全词Mask的对比。

表1 原始BERT的Mask和全词Mask的对比
在数据集方面,由于谷歌的BERT模型的研究测试集中于国外公开数据集,缺乏一种中文语言的相关模型。而中文BERT-wwm模型采用了中文维基百科(包括简体和繁体)进行训练,本文研究是基于中文的情感-原因对提取,所以选择中文BERT-wwm更合适。
4 实验及结果分析
4.1 模型评价指标
在测试的时候本文实验采用正确率(Precision)、召回率(Recall)、F1值(F1-measure)作为评判[14],为了权衡预测率和误报率,本此实验采用不平衡数据分类算法评价常用的ROC(Receiver Operating Characteristic)曲线,该曲线是模型预测率和误报率之间折中的一种图形化方法[15]。AUC(Area Under the Curve)值是ROC曲线下方的面积[16],提供了评价模型平均性能的另一种方法。
4.2 实验设置
本文在(Xia和Ding)[1]公开可用的数据集上进行实验。本文采用十折交叉验证法。实验时字嵌入和相对位置嵌入的维度分别设置为200和50,我们所有窗口BiLSTM中隐藏单元的数量设置为100,转换器中隐藏状态、查询、键和值的维度都设置为30,批量大小和学习率分别设置为32和0.005,在正则化方面,词嵌入采用dropout,dropout率设为0.7。
4.3 实验结果及分析
本文将我们提出的模型ECPE-BW和Ding等的ECPE-2D模型[11]、Wu等MTNECP模 型[8]、Fan等[7]、Song等[10]的E2EECP模型进行实验结果对比。我们利用消融研究进一步探索代价敏感的损失函数和BERT-wwm的表现。单独加入代价敏感的损失函数(在表2中用“Inter-EC+代”表示)和中文BERT-wwm(在表2中用“Inter-EC+BERT-wwm”表示)对比其实验结果。结果对比见表2。
从表2中我们可以看出,单独加入代价敏感的损失函数在整体结果上有提升。单独加入中文BERT-wwm比谷歌的BERT取得更好的结果,尤其在F1值上提升了0.79%,在R值上达到了情感-原因对提取实验最佳结果。说明中文BERT-wwm更适用于本文的实验数据集。

表2 实验结果对比
同时加入代价敏感的损失函数和中文BERT-wwm的模型在情感-原因对抽取任务上,F1值提高了接近1%,在P和R值上均有提升。由上述我们分析单独加入代价敏感的损失函数和单独加入中文BERT-wwm在ECPE任务上分别都有提升,且我们的模型同时加入代价敏感的损失函数和中文BERT-wwm在ECPE任务上部分值达到了情感-原因对提取实验的最佳结果,可见代价敏感的损失函数和中文BERT-wwm的加入在ECPE任务上起到一定的效果。同时说明我们的模型加入代价敏感的损失函数和中文BERT-wwm对情感-原因对提取任务有效。
根据我们提出的ECPE-BW模型和ECPE-2D[11]模型,分别画出评价模型的ROC曲线,图2是ECPE-BW模 型ROC曲 线,图3是ECPE-2D模 型ROC曲线。从下图中我们对比可以看出我们模型的ROC曲线值比ECPE-2D模型ROC曲线要高,说明我们模型的灵敏度和特异性连续变量的综合指标比ECPE-2D模型要高。再比较AUC值,明显看出我们模型AUC比ECPE-2D模型的AUC值要高,说明我们模型比ECPE-2D模型好。

图2 ECPE-BW模型ROC曲线
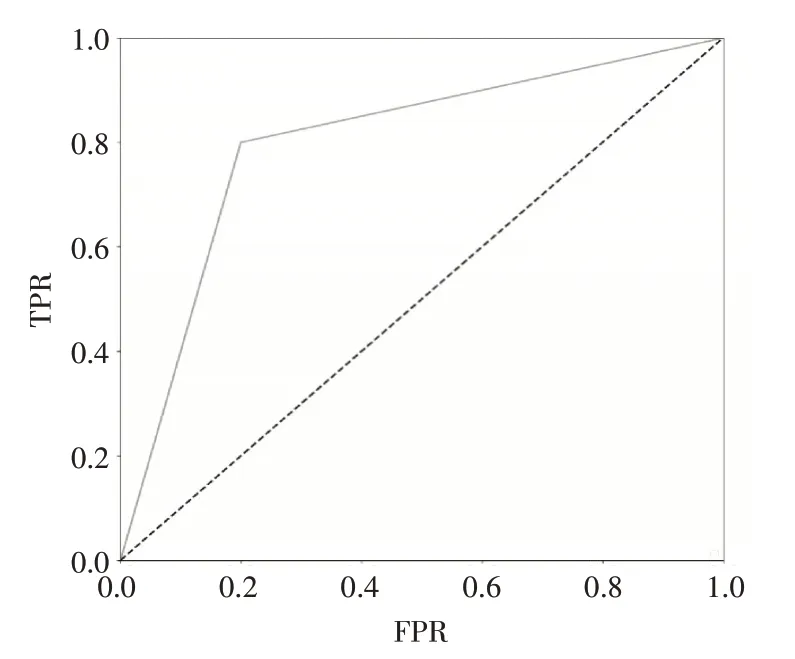
图3 ECPE-2D模型ROC曲线
综上所述,我们的模型加入代价敏感的损失函数和中文BERT-wwm对情感-原因对提取任务有效。
5 结语
在ECPE任务中,我们提出了ECPE-BW模型,该模型引入中文BERT-wwm和代价敏感的损失函数,最终结果在情感-原因对F1值上提升了接近1%。虽然我们取得了较好的结果,但是P、R、F1整体结果还是偏低。在未来的工作中,研究出一个能解决难提取隐含的情感-原因对的算法和模型来极大地提升整体结果。
